官方文档链接:MultiheadAttention — PyTorch 1.12 documentation
目录
多注意头原理
MultiheadAttention,翻译成中文即为多注意力头,是由多个单注意头拼接成的
它们的样子分别为:👇
单头注意力的图示如下:
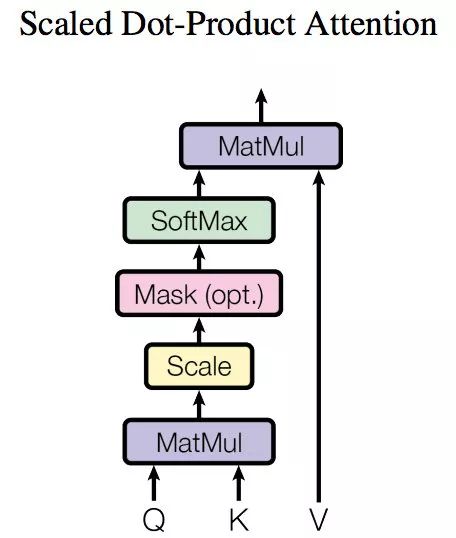
整体称为一个单注意力头,因为运算结束后只对每个输入产生一个输出结果,一般在网络中,输出可以被称为网络提取的特征,那我们肯定希望提取多种特征,[ 比如说我输入是一个修狗狗图片的向量序列,我肯定希望网络提取到特征有形状、颜色、纹理等等,所以单次注意肯定是不够的 ]
于是最简单的思路,最优雅的方式就是将多个头横向拼接在一起,每次运算我同时提到多个特征,所以多头的样子如下:
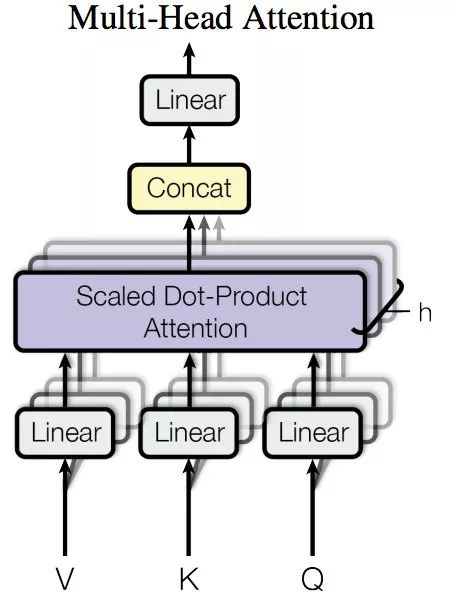
其中的紫色长方块(Scaled Dot-Product Attention)就是上一张单注意力头,内部结构没有画出,如果拼接h个单注意力头,摆放位置就如图所示。
因为是拼接而成的,所以每个单注意力头其实是各自输出各自的,所以会得到h个特征,把h个特征拼接起来,就成为了多注意力的输出特征。
pytorch的多注意头

首先可以看出我们调用的时候,只要写torch.nn.MultiheadAttention就好了,比如👇
import torch
import torch.nn as n
# 先决定参数
dims = 256 * 10 # 所有头总共需要的输入维度
heads = 10 # 单注意力头的总共个数
dropout_pro = 0.0 # 单注意力头
# 传入参数得到我们需要的多注意力头
layer = torch.nn.MultiheadAttention(embed_dim = dims, num_heads = heads, dropout = dropout_pro)解读 官方给的参数解释:
embed_dim – Total dimension of the model 模型的总维度(总输入维度)
所以这里应该输入的是每个头输入的维度×头的数量
num_heads – Number of parallel attention heads. Note that embed_dim will be split across num_heads (i.e. each head will have dimension embed_dim // num_heads).
num_heads即为注意头的总数量
注意看括号里的这句话,每个头的维度为 embed_dim除num_heads
也就是说,如果我的词向量的维度为n,(注意不是序列的维度),我准备用m个头提取序列的特征,则embed_dim这里的值应该是n×m,num_heads的值为m。
【更新】这里其实还是有点小绕的,虽然官文说每个头的维度需要被头的个数除,但是自己在写网络定义时,如果你在输入到多注意力头前到特征为256(举例),这里定义时仍然写成256即可!!,假如你用了4个头,在源码里每个头的特征确实会变成64维,最后又重新拼接成为64乘4=256并输出,但是这个内部过程不用我们自己操心。
还有其他的一些参数可以手动设置:
-
dropout – Dropout probability on
attn_output_weights. Default:0.0(no dropout). -
bias – If specified, adds bias to input / output projection layers. Default:
True. -
add_bias_kv – If specified, adds bias to the key and value sequences at dim=0. Default:
False. -
add_zero_attn – If specified, adds a new batch of zeros to the key and value sequences at dim=1. Default:
False. -
kdim – Total number of features for keys. Default:
None(useskdim=embed_dim). -
vdim – Total number of features for values. Default:
None(usesvdim=embed_dim). -
batch_first – If
True, then the input and output tensors are provided as (batch, seq, feature). Default:False(seq, batch, feature).
多注意头的pytorch使用
如果看定义的话应该可以发现:torch.nn.MultiheadAttention是一个类
我们刚刚输入多注意力头的参数,只是’实例化‘出来了我们想要规格的一个多注意力头,
那么想要在训练的时候使用,我们就需要给它喂入数据,也就是调用forward函数,完成前向传播这一动作。
forward函数的定义如下:
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None, average_attn_weights=True)
下面是所传参数的解读👇
前三个参数就是attention的三个基本向量元素Q,K,V
-
query – Query embeddings of shape
for unbatched input,
when
batch_first=Falseor
翻译一下就是说,如果输入不是以batch形式的,query的形状就是,
是目标序列的长度,
就是query embedding的维度,也就是输入词向量被变换成q后,q的维度,这个注释说是embed_dim, 说明输入词向量和q维度一致;
若是以batch形式输入,且batch_first=False 则query的形状为,若
batch_first=True,则形状为。【batch_first是’实例化‘时可以设置的,默认为False】
-
key – Key embeddings of shape
for unbatched input,
when
batch_first=Falseorwhen
batch_first=True, where S is the source sequence length,is the batch size, and
is the key embedding dimension
kdim. See “Attention Is All You Need” for more details.
key也就是K,同理query,以batch形式,且batch_first=False,则key的形状为。
是key embedding的维度,默认也是与
相同,
则是原序列的长度(source sequence length)
-
value – Value embeddings of shape
for unbatched input,
when
batch_first=Falseorwhen
batch_first=True, whereis the source sequence length,
is the value embedding dimension
vdim. See “Attention Is All You Need” for more details.
value是V,与key同理
其他的参数先不赘述
-
key_padding_mask – If specified, a mask of shape (N, S)(N,S) indicating which elements within
keyto ignore for the purpose of attention (i.e. treat as “padding”). For unbatched query, shape should be (S)(S). Binary and byte masks are supported. For a binary mask, aTruevalue indicates that the correspondingkeyvalue will be ignored for the purpose of attention. For a byte mask, a non-zero value indicates that the correspondingkeyvalue will be ignored. -
need_weights – If specified, returns
attn_output_weightsin addition toattn_outputs. Default:True. -
attn_mask – If specified, a 2D or 3D mask preventing attention to certain positions. Must be of shape (L, S)(L,S) or (N\cdot\text{num\_heads}, L, S)(N⋅num_heads,L,S), where NN is the batch size, LL is the target sequence length, and SS is the source sequence length. A 2D mask will be broadcasted across the batch while a 3D mask allows for a different mask for each entry in the batch. Binary, byte, and float masks are supported. For a binary mask, a
Truevalue indicates that the corresponding position is not allowed to attend. For a byte mask, a non-zero value indicates that the corresponding position is not allowed to attend. For a float mask, the mask values will be added to the attention weight. -
average_attn_weights – If true, indicates that the returned
attn_weightsshould be averaged across heads. Otherwise,attn_weightsare provided separately per head. Note that this flag only has an effect whenneed_weights=True. Default:True(i.e. average weights across heads)
层的输出格式:
-
attn_output – Attention outputs of shape
when input is unbatched,
when
batch_first=Falseorwhen
batch_first=True, whereis the target sequence length,
is the embedding dimension
embed_dim.
以batch输入,且batch_first=False,attention输出的形状为,
是目标序列长度,
是batch的大小,
是embed_dim(第一步实例化设置的)
-
attn_output_weights – Only returned when
need_weights=True. Ifaverage_attn_weights=True, returns attention weights averaged across heads of shape) when input is unbatched or
, where NN is the batch size,
average_weights=False, returns attention weights per head of shapewhen input is unbatched or
.
只有当need_weights的值为True时才返回此参数。
完整的使用代码
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output, attn_output_weights = multihead_attn(query, key, value)文章出处登录后可见!