提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
YOLO v5加入注意力机制、swin-head、解耦头部(回归源码)
提示:这里可以添加本文要记录的大概内容:
在YOLO v5的backbone和head引入全局注意力机制(GAM attention)、检测头引入解耦头部、SwinTransformer_Layer层,部分commom.py代码参考地址为:
https://github.com/iloveai8086/YOLOC
提示:以下是本篇文章正文内容,下面案例可供参考
一、YOLO v5 简介
YOLO v5由输入端、Backbone、Neck、Head四部分组成。YOLO v5输入端是对图像进行预处理操作,达到对输入图片进行数据增强的效果;Backbone采用了Conv复合卷积模块、C3模块以及SPPF模块组成,Neck部分主则采用 FPN+PAN的特征金字塔结构,增加多尺度的语义表达,从而增强不同尺度上的表达能力;Head部分采用三种损失函数分别计算位置、分类和置信度损失。
二、全局注意力机制的引入
在YOLO v5 d的commom.py加入以下全局注意力机制的代码。
class GAM_Attention(nn.Module):
# https://paperswithcode.com/paper/global-attention-mechanism-retain-information
def __init__(self, c1, c2, group=True, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(c1, int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(c1 / rate), c1)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(c1, c1 // rate, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(c1, int(c1 / rate),
kernel_size=7,
padding=3),
nn.BatchNorm2d(int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(c1 // rate, c2, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(int(c1 / rate), c2,
kernel_size=7,
padding=3),
nn.BatchNorm2d(c2)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
# x_channel_att=channel_shuffle(x_channel_att,4) #last shuffle
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
x_spatial_att = channel_shuffle(x_spatial_att, 4) # last shuffle
out = x * x_spatial_att
# out=channel_shuffle(out,4) #last shuffle
return out
def channel_shuffle(x, groups=2): ##shuffle channel
# RESHAPE----->transpose------->Flatten
B, C, H, W = x.size()
out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()
out = out.view(B, C, H, W)
return out
三、引入SwinTransformer_Layer层
在commom.py加入以下代码。代码较多
def window_reverse(windows, window_size: int, H: int, W: int):
"""
将window还原成一个feature map
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size(M)
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
# view: [B*num_windows, Mh, Mw, C] -> [B, H//Mh, W//Mw, Mh, Mw, C]
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
# permute: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B, H//Mh, Mh, W//Mw, Mw, C]
# view: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H, W, C]
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class PatchMerging(nn.Module):
""" Patch Merging Layer
Args:
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x, H, W):
""" Forward function.
Args:
x: Input feature, tensor size (B, H*W, C).
H, W: Spatial resolution of the input feature.
"""
B, C, H, W = x.shape
# print('------------------------PatchMErging input shape:',x.size())
# H=L**0.5
# W=H
# assert L == H * W, "input feature has wrong size"
# assert H==W , "input feature has wrong size"
x = x.view(B, int(H), int(W), C)
# padding
pad_input = (H % 2 == 1) or (W % 2 == 1)
if pad_input:
x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C 左上
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C 左下
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C 右上
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C 右下
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x) # B H/2*W/2 2*C
# print('PatchMerging output shape:',x.size())
return x
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class WindowAttention(nn.Module):
""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.,
meta_network_hidden_features=256):
super().__init__()
self.dim = dim
self.window_size = window_size # [Mh, Mw]
self.num_heads = num_heads
head_dim = dim // num_heads
# self.scale = head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_weight = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # [2*Mh-1 * 2*Mw-1, nH]
# 获取窗口内每对token的相对位置索引
# get pair-wise relative position index for each token inside the window
# coords_h = torch.arange(self.window_size[0])
# coords_w = torch.arange(self.window_size[1])
# coords = torch.stack(torch.meshgrid([coords_h, coords_w] )) # [2, Mh, Mw]indexing="ij"
# coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw]
# # [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
# relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]
# relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh*Mw, Mh*Mw, 2]
# relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
# relative_coords[:, :, 1] += self.window_size[1] - 1
# relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
# relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
# self.register_buffer("relative_position_index", relative_position_index)
# Init meta network for positional encodings
self.meta_network: nn.Module = nn.Sequential(
nn.Linear(in_features=2, out_features=meta_network_hidden_features, bias=True),
nn.ReLU(inplace=True),
nn.Linear(in_features=meta_network_hidden_features, out_features=num_heads, bias=True))
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_position_bias_weight, std=.02)
self.softmax = nn.Softmax(dim=-1)
# Init tau
self.register_parameter("tau", nn.Parameter(torch.zeros(1, num_heads, 1, 1)))
# Init pair-wise relative positions (log-spaced)
indexes = torch.arange(self.window_size[0], device=self.tau.device)
coordinates = torch.stack(torch.meshgrid([indexes, indexes]), dim=0)
coordinates = torch.flatten(coordinates, start_dim=1)
relative_coordinates = coordinates[:, :, None] - coordinates[:, None, :]
relative_coordinates = relative_coordinates.permute(1, 2, 0).reshape(-1, 2).float()
relative_coordinates_log = torch.sign(relative_coordinates) \
* torch.log(1. + relative_coordinates.abs())
self.register_buffer("relative_coordinates_log", relative_coordinates_log)
def get_relative_positional_encodings(self):
"""
Method computes the relative positional encodings
:return: Relative positional encodings [1, number of heads, window size ** 2, window size ** 2]
"""
relative_position_bias = self.meta_network(self.relative_coordinates_log)
relative_position_bias = relative_position_bias.permute(1, 0)
relative_position_bias = relative_position_bias.reshape(self.num_heads,
self.window_size[0] * self.window_size[1], \
self.window_size[0] * self.window_size[1])
return relative_position_bias.unsqueeze(0)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, Mh*Mw, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# [batch_size*num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = torch.einsum("bhqd, bhkd -> bhqk", q, k) \
/ torch.maximum(torch.norm(q, dim=-1, keepdim=True)
* torch.norm(k, dim=-1, keepdim=True).transpose(-2, -1),
torch.tensor(1e-06, device=q.device, dtype=q.dtype))
# transpose: -> [batch_size*num_windows, num_heads, embed_dim_per_head, Mh*Mw]
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, Mh*Mw]
# q = q * self.scale
# cosine -->dot?????? Scaled cosine attention:cosine(q,k)/tau 也许理解的不准确: 控制数值范围有利于训练稳定 (残差块的累加 导致深层难以稳定训练)
# attn = (q @ k.transpose(-2, -1))
# q = torch.norm(q, p=2, dim=-1)
# k = torch.norm(k, p=2, dim=-1)
# attn /= q.unsqueeze(-1)
# attn /= k.unsqueeze(-2)
# attn=attention_map
# print('attn shape:',attn.size())
# print('attn2 shape:',attention_map.size())
attn /= self.tau.clamp(min=0.01)
# relative_position_bias_table.view: [Mh*Mw*Mh*Mw,nH] -> [Mh*Mw,Mh*Mw,nH]
# relative_position_bias = self.relative_position_bias_weight[self.relative_position_index.view(-1)].view(
# self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
# relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [nH, Mh*Mw, Mh*Mw]
# print("net work new positional_enco:",self.__get_relative_positional_encodings().size())
# print('attn shape:',attn.size())
# attn = attn + relative_position_bias.unsqueeze(0)
attn = attn + self.get_relative_positional_encodings()
if mask is not None:
# mask: [nW, Mh*Mw, Mh*Mw]
nW = mask.shape[0] # num_windows
# attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]
# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
# transpose: -> [batch_size*num_windows, Mh*Mw, num_heads, embed_dim_per_head]
# reshape: -> [batch_size*num_windows, Mh*Mw, total_embed_dim]
# x = (attn @ v).transpose(1, 2).reshape(B_, N, C) ## float()
x = torch.einsum("bhal, bhlv -> bhav", attn, v)
# x = self.proj(x)
# x = self.proj_drop(x)
# print('out shape:',x.size())
return x
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, Global=False):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
# patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias,
attn_drop=attn_drop, proj_drop=drop)
# if Global else Global_WindowAttention(
# dim, window_size=(self.window_size, self.window_size),input_resolution=() num_heads=num_heads, qkv_bias=qkv_bias,
# attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim, act_layer=act_layer,
drop=drop)
def forward(self, x, attn_mask):
# H, W = self.H, self.W
# print("org-input block shape:",x.size())
x = x.permute(0, 3, 2, 1).contiguous() # B,H,W,C
B, H, W, C = x.shape
# B, L, C = x.shape
# assert L == H * W, "input feature has wrong size"
shortcut = x
# H,W=int(H), int(W)
# x = self.norm1(x)
# x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
# 把feature map给pad到window size的整数倍
# if min(H, W) < self.window_size or H % self.window_size!=0:
# Padding = True
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # [nW*B, Mh*Mw, C]
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # [B, H', W', C]
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
# 把前面pad的数据移除掉
x = x[:, :H, :W, :].contiguous()
x = self.norm1(x) # pos-norm.1
# x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.norm2(self.mlp(x))) # pos-norm.2
x = x.permute(0, 3, 2, 1).contiguous()
# print("swinblock ouput——shape:",x.size())
return x
def window_partition(x, window_size: int):
"""
将feature map按照window_size划分成一个个没有重叠的window
Args:
x: (B, H, W, C)
window_size (int): window size(M)
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
# permute: [B, H//Mh, Mh, W//Mw, Mw, C] -> [B, H//Mh, W//Mh, Mw, Mw, C]
# view: [B, H//Mh, W//Mw, Mh, Mw, C] -> [B*num_windows, Mh, Mw, C]
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
class SwinTransformer_Layer(nn.Module):
"""
A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size: 7 or 8
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, depth, num_heads, last_layer=False, window_size=7,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=PatchMerging, use_checkpoint=False):
super().__init__()
self.dim = dim
self.depth = depth
self.last_layer = last_layer
self.window_size = window_size
self.use_checkpoint = use_checkpoint
self.shift_size = window_size // 2
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
Global=False)
for i in range(depth)])
# patch merging layer
if self.last_layer is False:
# print('开始进行patchmergin------打印层深度:',depth)
self.downsample = downsample(dim=dim, norm_layer=norm_layer)
else:
# print('最后1层默认没有Patchmerging:',depth)
# self.norm = norm_layer(self.num_features)
# self.avgpool = nn.AdaptiveAvgPool1d(1)
self.downsample = None
self.avgpool = nn.AdaptiveAvgPool1d(1)
def create_mask(self, x, H, W):
# calculate attention mask for SW-MSA
# 保证Hp和Wp是window_size的整数倍
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # [nW, Mh, Mw, 1]
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [nW, Mh*Mw]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [nW, 1, Mh*Mw] - [nW, Mh*Mw, 1]
# [nW, Mh*Mw, Mh*Mw]
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
# print('swinlayers input shape:',x.size())
B, C, H, W = x.size()
# H=int(L**0.5)
# W=H
# assert L == H * W, "input feature has wrong size"
attn_mask = self.create_mask(x, H, W) # [nW, Mh*Mw, Mh*Mw]
for blk in self.blocks:
blk.H, blk.W = H, W
if not torch.jit.is_scripting() and self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
if self.downsample is not None:
x = self.downsample(x, H, W)
H, W = (H + 1) // 2, (W + 1) // 2
# if self.last_layer:
# x=x.view(B,H,W,C)
# x=x.transpose(1,3)
# x = self.norm(x) # [B, L, C]
# x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]
# x = x.view(B,-1,H,W)
# x = window_reverse(x, self.window_size, H, W) # [B, H', W', C]
# x = torch.flatten(x, 1)
x = x.view(B, -1, H, W) #
# print("Swin-Transform 层 ------------------------输出维度:",x.size())
return x
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path_f(x, self.drop_prob, self.training)
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
四、引入解耦头部层
引入解耦头部的方法,就不在讲述了,其他比我厉害的博主也都有些写引入解耦头部的方法,大家可以去网上查看别的博客。
五、修改模型yaml文件
这里是我修改的模型yaml文件如下: 自己添加的注意力机制层数稍微多点。从下面可以看出在在head部分每一层的SwinTransformer_Layer都加了一层注意力机制。最后一层Detect部分采用Decoupled_Detect解耦头部。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]], # 2
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 1, SwinTransformer_Layer, [128,2,8,True,8]], # 4
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 1, SwinTransformer_Layer, [256,2,8,True,8]], # 6
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SwinTransformer_Layer, [512,2,8,True,4]], # 8
[-1, 1, GAM_Attention, [512,512]], # 9
[-1, 1, SPPF, [1024, 5]], # 10
]
head:
[[-1, 1, Conv, [512, 1, 1]], # 11
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 12
[[-1, 6], 1, Concat, [1]], # 13
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]], # 15
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 16
[[-1, 4], 1, Concat, [1]], # 17
[-1, 3, C3, [256, False]], # 18
[-1, 1,GAM_Attention, [128,128]], # 19
[-1, 1, Conv, [512, 3, 2]], # 20
[[-1, 6, 13], 1, Concat, [1]], # 21
[-1, 3, C3, [512, False]], # 22
[-1, 1, SwinTransformer_Layer, [256,2,2,True,8]], # 23
[-1, 1,GAM_Attention, [256,256]], # 24
[-1, 1, Conv, [1024, 3, 2]], # 25
[[-1, 10], 1, Concat, [1]], # 26
[-1, 3, C3, [1024, False]], # 27 (P4/16-medium)
[-1, 1, SwinTransformer_Layer, [512,2,2,True,4]], # 28
[-1, 1,GAM_Attention, [512,512]], # 29
[[19, 24, 29], 1,Decoupled_Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
六、运行代码
1.train.py报错问题
在修改后的YOLO v5中运行上述修改的yaml模型文件时候训练会报错,因为精度的问题,报错内容如下:RuntimeError: expected scalar type Half but found Float
在train.py的def parse_opt(known=False)中增加下面的最后一行代码:

添加上述代码还会继续报错,还是同样的问题,在对train.py文件进行继续修改,在下面两个部分添加half=not opt.swin_float这句代码修改后部分如下:
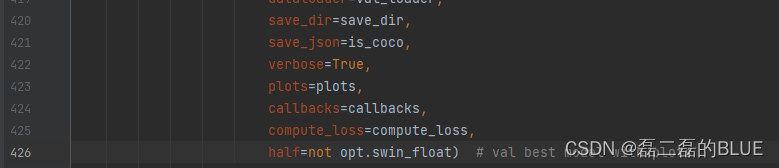

2.再次运行train.py
再次运行代码,–data部分是我自己的数据集yam文件,–cfg部分是上述修改后的模型yaml文件,这里权重设置为空,训练为200次,批次大小为4。终端运行训练代码如下:
python train.py --data huo.yaml --cfg yolov5s_swin_head.yaml --weights ' ' --epoch 200 --batch-size 4 --swin_float
3.自己数据集实验结果
| 模型文件 | mAP | mAP@.5:.95 |
|---|---|---|
| YOLO v5 | 75.8% | 45.9% |
| YOLO swin-head | 76.1% | 47.9% |
总结
第一次写这个,奈何自己才疏学浅,后期有新的想法会继续更新。还望大家积极批评指正。
commom.py部分代码参考:
链接: [link] (https://github.com/iloveai8086/YOLOC)
文章出处登录后可见!