目录
- 使用须知
- 复习笔记
- 写在最后
- 总结
使用须知
动机:对我来说,整理这个笔记一方面是yq不敢出门,呆在家太闲了。另一方面,明年暑假,又或者12月可能会用到,其他专业课都打算整理下,现在前途未卜,只好做两手准备。
如果你是卷王,想直接看考试怎么考的,目录翻到最后,有我的考试回忆,不完全准确,仅供参考。
这个笔记是根据我备考整理的,比较适合对PPT已经比较熟悉的人。如果直接拿这个学,也不是不可以,但应该会比较吃力。此外,里面有一些自己的理解,可能不准确,欢迎探讨。
总的来说可以分成四部分
第1部分 第1讲 划水摸鱼
第2部分 第2-7讲 距离和线性分类器
第3部分 第8-13讲 概率论相关
第4部分 第14-15讲 划水摸鱼
复习笔记
第一讲 绪论
没啥好说的,没考。PPT主要是模式识别要学啥,祖师爷是谁,有哪些顶级会议、期刊,丁老师的经历。了解即可。
第二讲 距离分类器
一般形式和预备知识
范数
- 相似度与距离的负相关关系
最近邻分类器
原理
大二下的机器学习都学过了,不再赘述。
优缺点
- 训练样本数量较多时效果良好
- 计算量大(需要同所有训练样本计算距离)
- 占用存储空间大(需要保存所有的训练样本)
- 易受样本噪声影响
改进:模板匹配
选择模板,即每个类别构造出一个代表,即求解如下式子,
是d维特征空间,
用的欧氏距离。
接下来求,误差平方和作为准则函数
求导
其中用到了公式
最终解得
结论:每个类别训练样本的均值作为匹配模板
衍生:多模板匹配
一个类别可以有多个模板,具体看PPT,理解就行
核心:,总共
类,第
类有
个模板。
K-近邻分类器
原理
大二下的机器学习都学过了,核心。提下k的取值:
- 过小:算法的性能接近于最近邻分类
- 过大:距离较远的样本也会对分类结果产生作用,引起分类误差
- 适合的K值需要根据具体问题来确定
对于非平衡样本集,样本数多的类别总是占优势
优缺点
优点
- 易于理解和实现
- 训练时间短,有用的测试工具
- 容易处理多分类
- 非参数化
缺点 - 测试阶段的计算成本高
- 易受数据分布的影响
- 高维数据会降低 KNN 的精度
K-D树
K-D树用来解决计算成本的问题。
- 一维特征
退化为排序查找问题,快排+折半查找 - 多维特征
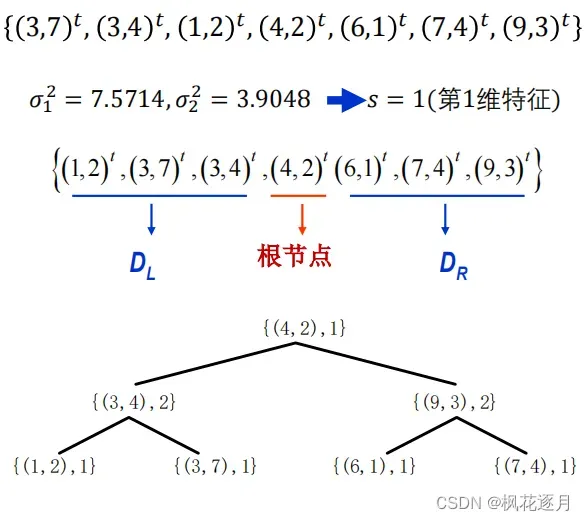
建树算法
(1) 计算得到方差最大的第s维特征
(2) 根据第s维特征,对D升排序
(3) 选择中间样本为根节点、记录s,小于根节点放入左子集DL,大于根节点放入右子集DR
(4) DL、DR递归建树,得到K-D树
例子
距离和相似度度量
满足以下4个性质即可作为距离
- 非负性:
- 对称性:
- 自反性:
当且仅当
- 三角不等式:
常见的距离
- 欧式距离
- 街市距离
- 车比雪夫距离
- 汉明距离
(二值矢量)
- 加权距离 不同距离赋不同权重
相似性度量
角度相似性
当两个样本之间的相似程度只与它们之间的夹角有关、与矢量的长度无关时,可以使用矢量夹角的余弦来度量相似性
(注:若特征已经归一化,分母为1,直接计算内积即可,归一化在后面讲)
相关系数
特征归一化、标准化
均匀缩放
假设各维特征服从均匀分布
高斯缩放
假设各维特征服从高斯分布
分类器评价
评价指标

- f1 score:即调和平均数
曲线
其他指标
敏感性,表示真正阳性能被检测出来的能力,就是召回率
特异性,表示实际阴性不被误诊的能力,就是1-假阳率
两者结合有ROC曲线,了解
评价方法
- 留出法
- 交叉验证
- 嵌套交叉验证
- Bootstrap(有放回)
偏差、方差、欠拟合、过拟合间的关系
第三讲 线性判别函数分类器(1)
线性判别函数和线性分类界面
线性判别函数

时,𝐱 处于 𝐻 上方 。
时,𝐱 处于 𝐻 上 。
时,𝐱 处于 𝐻 下方。
- 权矢量𝐰垂直于分类面 𝐻,指向
的区域
- 坐标原点到分类界面 𝐻 的距离:
性质1和3线性代数都学过。主要是性质2的证明。注意图中框出来的部分,应该理解前提,即是根据
的方向来构造的,在一开始就应该说明,PPT写的比较奇怪。

判别函数的学习
样本规范化与增广
直接看图,根据标签和偏置进行调整

梯度下降算法
前置知识:导数、偏导、梯度、泰勒展开
准则函数的一阶近似
充分小,在 a 点附近可以用一阶展开式近似函数
学习率
也称为迭代步长,控制增量矢量 Δa 的长度
学习率过小,算法的收敛速度慢
学习率过大,算法有可能不收敛(振幅过大)
可以设置为常数,也可以设置为迭代次数 𝑘 的函数

感知器算法
感知器算法的准则函数怎么选用?
第一种 直接以被错误分类的样本数量为准则优化
令 𝒴 为被判别函数错误分类的规范化增广训练样本集合
此方法问题较大
是一个不连续函数,不连续点不可求导
- 可以求导的区域,梯度为0,无法采用梯度法优化
第二种 以错误分类样本到判别界面“距离”之和作为准则
样本规范化之后,被错误分类的训练样本
当所有训练样本被正确识别时,,取得最小值
综上所述,这个准则函数是可以用梯度下降算法优化的
梯度为
带入梯度下降公式的时候注意两个负号抵消了
例题
学会PPT上的例题即可,考试考了类似的题。

第四讲 线性判别函数分类器(2)
LSME算法
第三讲里面我们用的不等式来判断样本是否分对,第4讲改为等式。《最优化方法》这门课专门讲了下面这些东西,虽然是考查课,还是可以好好听听的,对数模等比赛都有帮助。
线性不等式组的求解可以转化为线性方程组的求解
注意上式都规范化了。
写成矩阵形式就是
即
一般来说这是一个超定方程组,只能求近似解。
- 公式法
定义误差矢量
定义准则函数(LSME)
目标是找到
将LMSE准则函数展开:
注意是个1*1矩阵,动手推一下比啥都强
求梯度和极值点
解得
矩阵称为伪逆矩阵
所以最后就只要代个公式算一下,形式很简单,但是矩阵求逆计算量很大,考试时候丁老师会直接给逆矩阵,至少我们这届是。
例题

- 梯度下降法
既然刚才用公式法已经算出了梯度公式
那不妨代入梯度下降算法的迭代式,这对计算机来说友好的多

由线性到非线性
以上所有线性分类器都只适用于线性可分问题,无法解决非线性问题
著名的“异或问题”就无法解决
实现非线性分类的途径
广义线性判别函数(利用已有特征增加高次项,可能导致维数灾难)
分段线性判别函数(典型的有决策树)
多层感知器
核函数方法
多类别线性分类
以上讨论的都是二分类
接下来讨论三种多类别线性分类方法
一对多或一对一
这个考试考判别条件了
一对多
省流:c类需要c个分类面
每一类都有一个判别函数把自身和其他类区分开,第 i 类与其它类别之间的判别函数:
准则:存在使
则判别
属于
;如果不存在则拒识
一对一
省流:c类需要c(c-1)/2个分类面
第 i 类与第 j 类之间的判别函数为:
准则:如果对任意,有
,则判别
属于
一对一判别特例:最大值判别
每个类别构造一个判别函数:
准则:
拓展的感知机算法
基于上面的最大值判别,出现错分样本要同时修正多个权值矢量。

感知器网络
这个跟神经网络就很接近了
先说输出的编码方式,方法1类似onehot编码,方法2类似二进制编码

第五讲 支持向量机
这部分明确说不考推导,就考了计算,一个小插曲是SVM的考题出错了,不过无伤大雅。功利点直接看例题,但是尝试理解推导很重要,如果《最优化方法》好好听的话会比较轻松,基本都讲过。
推导
推导过程
设分类面为
函数间隔定义为
几何间隔定义为,说白了就是欧氏距离
支持向量和支持面的定义

对偶问题的优点
做到这里可以发现转化为对偶问题的优点
- 不直接优化权值矢量
与样本的特征维数无关,只与样本的数量有关
当样本的特征维数很高时,对偶问题更容易求解 - 只用内积,不用坐标
训练样本只以内积的形式出现
优化求解过程中,只需计算内积
SVM解的讨论
事实上,样本里真正重要的是那些作为支持向量的样本。在拉格朗日乘数法中,只有支持向量的才不为0,其他均为0。
例题
很简单,记住结论直接套公式

软间隔SVM
实际应用中,对于线性不可分的训练集,不等式约束不可能全部被满足(找不到解)。
于是引入了松弛变量(每个样本对应一个松弛变量),将不等式约束变为
只要选择一系列适合的松弛变量,不等式约束条件总是可以得到满足的。好的判别函数能够正确分类更多的样本,因此希望更多松弛变量满足。对于那些被错分的样本,引入惩罚系数
,于是软间隔SVM问题可以表述为


核函数
由来
第四讲提到了广义线性判别函数:将低维特征向量映射到高维空间中,学习线性判别函数。
根据已有的特征无法使用线性分类器,但可以根据已有特征构建高维特征,如建立非线性映射,下图经过转换后在三维空间就线性可分了。

核函数需要满足的条件
Mercer 条件,了解
常用的核函数
RBF(又称高斯核)
Poly
Sigmoid
带核技巧的SVM
引入非线性后,SVM要强大得多。

第六讲 特征选择与特征提取(1)
刚才的核技巧是升维,但是有时候特征过多并不是好事。可能导致
- 增大了分类学习过程和识别过程计算和存储的复杂程度
- 降低了分类器的效率
- 识别特征维数过大使得分类器过于复杂
这一讲主要是选择特征
好的特征应当使得不同类别之间差异大(距离远),同一类别之间差异小(距离近)
类别可分性判据
基于距离的可分性判据
类内距离准则
用每个样本与其所属类别中心之间的距离平方和来度量
类间距离准则
用每个类别的中心到样本整体中心之间的加权距离平方和度量
基于散布矩阵的可分性判据
第 j 类内散布矩阵
总的类内散布矩阵
类间散布矩阵
总体散布矩阵
基于上述矩阵,一般有如下判据,值越大说明特征越好
tr是矩阵的迹,对角线之和,忘了可以翻翻线性代数课本。
例题

特征选择
分支定界法
上面的例题一共给了三个特征,要选出最好的两个,这样就有种选择。如果从100个特征中选择10个时,组合数则变为
,显然难以计算。
当判据满足单调性时(加入新的特征后至少判据值不会更小),可以构建搜索树来选择特征。
例题

- 可分性判据必须具有单调性,否则不能保证得到最优选择
- 最优解分支位置决定计算复杂度(看脸,脸好就快)
- 当原始的特征维数很大时,搜索到最优解的计算量仍可观
次优搜索算法
思想类似局部最优,具体看ppt,了解算法和计算量就行。
- 顺序前进法
- 顺序后退法
- 广义顺序前进(后退)法
- 增 𝑙 – 减 𝑟 法(𝑙−𝑟法)
第七讲 特征选择与特征提取(2)
这部分老师说了不考推导,考试考了两个算法的区别
PCA
思想
建立新的坐标系,用更少的坐标重新表示数据,理想情况下,新的坐标表示可以完美地恢复数据
推导比较复杂,建议看PPT
算法
就考试来说,特征值是要会算的,忘了就去看线性代数课本。协方差矩阵会给。

例题

解的讨论
特征值描述了变换后各维特征的重要性,特征值为 0 的各维特征为冗余特征
PCA降维后各特征是不相关的(正交,独立)
PCA是无监督的,可以看到整个计算过程不需要样本标签值
LDA
Fisher 线性判别准则的思想

算法
要用到上一讲的散布矩阵,PPT这一讲给的的散布矩阵有点不一样,没取均值,不影响特征值计算。

解的讨论
与PCA不同,降维后的特征非正交
有监督,需要标签(散布矩阵那边)
新的坐标至多c-1维(c为类别数),即 至多存在 c-1 个大于 0 的特征值
其他方法
了解
PCA 与 LDA 的结合
LDA 作为线性分类器学习方法
PCA 的神经网络实现:AE(Auto-Encoder)
统计学方法
- 独立成分分析 ( ICA, Independent Component Analysis )
- 多维尺度变换 (MDS, Multidimensional Scaling)
- 典型相关分析 (CCA, Canonical Correlation Analysis)
- 偏最小二乘 (PLS, Partial Least Square)
核方法 - 引入核函数,将线性方法推广为非线性方法
流形学习(Manifold Learning) - “非线性流形”在局部用“线性流形”近似,如 Isomap 和 Locally Linear Embedding(LLE)
第八讲 贝叶斯决策理论
从这里开始就都是概率论的东西了,开始新篇章。
概率论与统计学习
先复习下概率论
类别的先验概率
后验概率
类条件概率密度(似然)
样本的先验概率密度
联合概率
联合概率公式
全概率公式
贝叶斯公式
例题

贝叶斯决策理论
直接看题吧,不是什么新东西,最小风险稍微注意下
基于最小错误率的贝叶斯决策

基于最小风险的贝叶斯决策
表示把第i类识别成j类的风险。如果i和j相等,也就是识别对了,那当然没有风险,直接设为0,计算时忽略。
例题的表示把第1类识别成2类的风险,即把癌症识别成正常人,漏诊了,要出人命肯定不行,风险设大一点为100。反过来把正常人识别成癌症要好不少,虚惊一场不出人命,风险设小一点为25。这样算出来是符合常识的。

第九讲 正态分布的贝叶斯分类器
贝叶斯分类器最重要的无疑是类条件概率密度函数,光靠统计比较困难,处理连续类的问题也比较困难。
判别函数和判别边界
判别函数的性质
判别函数不是唯一的
如果是一组判别函数,
对于任意的,
是一组等价的判别函数
对于任意的,
是一组等价的判别函数
对于单调上升函数,
是一组等价的判别函数
等价的判别函数具有相同的决策区域和判别边界
判别边界
判别区域之间的边界称为判别边界,在判别边界上相邻的两个判别函数值相等
正态分布贝叶斯
预备知识
一维正态分布
多维正态分布
其中
均值矢量
协方差矩阵
最大熵定理:在均值、方差确定的各种分布中,正态分布的熵最大
中心极限定理:大量小的、独立随机分布的总和等效为正态分布
推导
根据判别函数的性质
最小错误率贝叶斯判别函数的对数表示为
假设类条件概念概率函数满足正态分布
故有
(其中,是与类别无关的常数项,可以省略)
情况一
各类别的先验概率相同(常数):
各类别的协方差矩阵相同,且各向同性(常数): (
是单位矩阵)
化简并去掉常数项

情况二
各类别的协方差矩阵相同,但非各向同性

情况三
任意
是与类别无关的常数项,可以省略,故有

朴素贝叶斯分类器
协方差矩阵经常很难估计
特征的维数较高、训练样本数量较少时,无法有效估计协方差矩阵
假设各维特征独立且服从相互独立的高斯分布
根据概率论知识就可以拆成各个独立特征的乘积
取对数并化简,删掉常数项,得
改进二次判别函数(MQDF)了解,不考
第十讲 非参数估计和参数估计
独立同分布假设
训练集 中的样本抽样自同一分布,
每个样本的抽样过程是相互独立的
独立同分布假设是统计学的一个基本假设
非参数估计
非参数估计的一般性描述
不需要任何关于分布的先验知识,适用性好
取得准确的估计结果,需要的训练样本数量远多于参数估计方法
令 是包含样本点
的一个区域,体积为
;
个训练样本中有
个落在区域
中,可对
的概率密度作出估计
Parzen 窗法
Parzen 窗法估计的是每个类别的条件概率
定义
这个就是《信号处理》里的东西
Parzen 窗法使用窗函数来划定区域
以为中心,边长为
的窗函数
判断样本是否在超立方体
之内
超立方体内的样本数
代入求概率密度函数
算法

近邻分类器
定义
近邻法估计的是每个类别的后验概率
构造一个以待识别模式 为中心的区域
,体积为
类联合概率的估计:
类后验概率的估计:
算法

参数估计
参数估计方法需要关于分布形式的先验知识,估计的准确程度依赖于先验知识是否准确
由于有先验知识的存在,参数估计方法使用比较少的训练数据就可以得到较好的估计结果
最大似然估计
考试考了计算,建议翻看概率论课本找找例题
一维正态分布的最大似然估计
构造对数似然函数:
计算偏导数:
求解
解得
多维正态分布的最大似然估计
推导跟上面类似,变成矩阵而已。
结论
贝叶斯估计
没讲,愉快略过hhh
第十一讲 高斯混合模型
介绍
刚才的最大似然估计需要训练数据符合何种分布的先验知识,得先知道分布类型才能算参数
实际应用中一般不知道分布类型,GMM 可以看作是一种“通用”的概率密度函数,只要数量 𝑀 足够大,GMM 可以任意精度逼近任意分布密度函数
说人话,假设样本A、B来源于这个正态分布,样本C、D来源于
这个正态分布,ABCD又是同一类标签,GMM要做的就是把这两个正态分布以加权的形式统一起来。
高斯混合模型(GMM)由多个高斯(正态分布)函数的组合构成,即多个高斯函数以不同的权重叠加起来
例子

推导
GMM 需要估计的参数:
如果取对数求导极值点方程是复杂的超越方程组,很难直接求解
一般使用 EM 算法
如何理解?
GMM就是在估计每个样本究竟来源于哪个高斯分布(标签,或者理解为PPT里的隐变量)并给出参数的估计结果,是一种聚类算法,下面的过程和KMeans聚类非常像,实际上KMeans就是退化后的GMM。
先将随机初始化,这个初始化实际上是有讲究的,后面说。
E步
如果是第一次E步,
就拿随机初始化的计算标签,开启迭代滚雪球。否则拿M优化调整过的参数。
我的理解是,这玩意儿说白了就是最小错误率贝叶斯估计。
可以理解为类别先验概率
可以理解为类条件概率密度
M步
E步计算完了标签,那就把各个正态分布的参数重新计算下,并且根据各不同类别的数量计算概率
公式里的是指示函数
接着把更新好的参数丢回E步迭代
KMeans与GMM的关系
如果进一步假设,每个聚类的先验概率相同,协方差矩阵均为
则
这就是大名鼎鼎的KMeans
刚刚提到的初始化问题,我记得sklearn库的GMM源码就是拿KMeans做初始化的。提一句,GMM对初始化的参数非常敏感。

算法

一般形式的EM算法
伪代码

例题
硬币具体情况看PPT

第十二讲 隐马尔可夫模型(1)
我们讲到的隐马尔可夫模型都指一阶马尔可夫链
基本假设
假设1:马尔可夫假设(状态构成一阶马尔可夫链)
假设2:不动性假设(状态转移概率与具体时间无关)
假设3:输出独立性假设(输出仅与当前状态有关)
模型图

估值问题
呃,考试考了个最简单的估值问题
前向迭代算法
跟朱东杰讲的《算法》一模一样的,披个皮而已

例题
直接看题吧,上复习笔记,别算错就行。

第十三讲 隐马尔可夫模型(2)
解码问题
本质就是动态规划
跟朱东杰讲的那啥街区一模一样的
Viterbi算法
动规表达式
例题

学习问题
比较难,且明确不考
愉快跳过
第十四讲 聚类分析
这一部分《机器学习》讲得比较全了,基本都有,只是多讲了些指标啥的。考试考了无监督有监督的区别,送分。
直接看笔记吧,结合PPT看看就行。(博客越写越水了属于是

第十五讲 集成学习
Bagging
典型的比如随机森林,多棵树投票表决,多数通过

Boosting
Bagging 算法属于并行化的集成学习方法,基分类器之间互无关联
而Boosting 算法是序列化的集成学习,下一个基分类器的学习需要根据之前的学习结果来调整,比较有名的是AdaBoost
其思想是对样本进行加权抽样,根据前一个分类器的训练结果,下一个分类器抽到之前错误样本的概率增加,正确样本的概率减小。

Stacking
基本思想:与其使用普通函数(如:hard voting)来集成多个分类器的预测,为什么不训练一个模型来进行集成?

神经网络的集成
直接集成困难,因为训练一个神经网络模型计算量大,时间长
使用Dropout
写在最后
关于考试
考试占总成绩的60%,全是大题,总体来说非常简单,我的卷面是100。一查教务系统发现排第3,说明还有两个卷王连实验带卷子都是满分,果然我是废物。基本都是课上讲过的例题,稍微复习下有点印象都会做,丁老师老好人了。
以下是回忆,不一定准确
1、(1)计算准确率召回率f1(2)计算正确率错误率
2、(1)监督学习和非监督学习的区别(2)用kmeans对样本分类
3、(1)证明后验概率满足逻辑回归的分类面是线性(2)求泊松分布的最大似然估计函数
4、(1)画出HMM模型图(2)HMM估值问题
5、(1)感知器多分类算法中一对一和一对多的分类准则(2)感知器算法计算题(3)SVM计算题
6、(1)PCA降维和LDA降维哪些区别(2)PCA计算题
关于实验
实验占40%,总共4个实验,一个10分,前三个挺简单,好好做基本都能拿满。最后一个实验打榜赛,准确率越高分数就越高,我应该是这里扣了一分,最后这门课总分99hhh。给的Fashion-Mnist数据集,数据集经过了丁老师独家处理,经过了PCA降维(784到76维),每个维度做了随机线性变换,相当于加密处理了吧,因为是公开数据集,不然就都知道答案了。
这个实验个人感觉意义不大,最后大家几乎都是SVM调调参数,网格搜索下,最后测试集听天由命。因为特征是给死的,所以也整不出新活,建议不要做无用功。说下自己的情况,神经网络都试了,没啥用,因为特征是一维,神经网络效果不佳意料之中。当时还想了歪主意,想把这些PCA处理过的还原成784(28*28)维,毕竟2D特征肯定更适合CNN。有些大佬还试过transformer和GAN,都没用,这么少数据量直接劝退。某许姓男子还给我推荐了autolearning的深度学习框架,确实🐂🍺,一键训练了20多个机器学习模型,决策树、随机森林、boosting等等等一大堆,还自带超带参数搜索的,但是这些模型都不如SVM,最好的还是差了SVM一个多百分点。
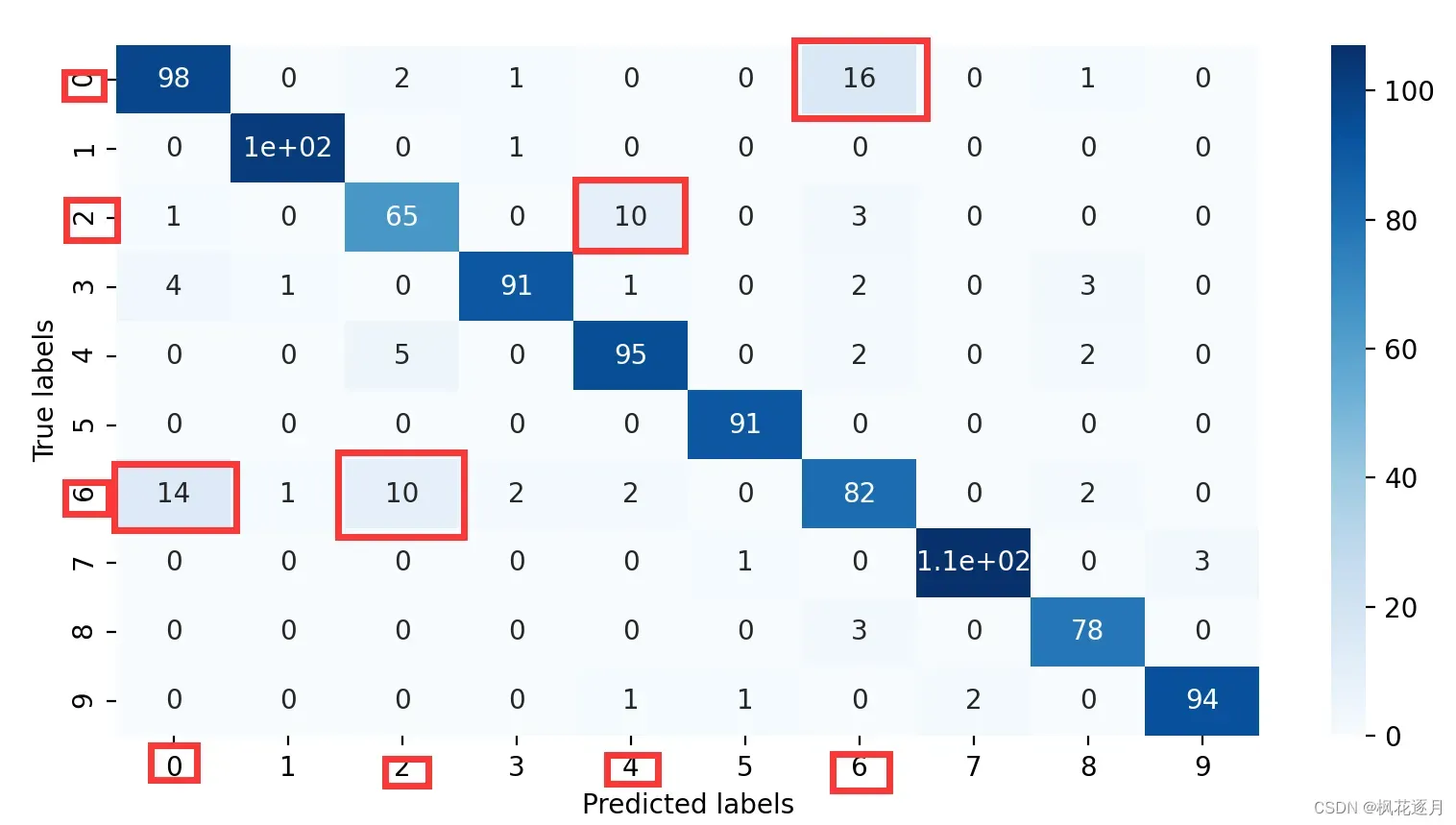
至于原因吗,无疑是一维的特征没活可整。如果你细究原因的话会发现,一维特征很难区分Fashion-Mnist里相近的一些服装,比如T恤、衬衫,当时我记得是有3种极易混淆的,自己看下面的混淆矩阵热力图体会下。一维特征+机器学习算法几乎束手无策,至少班上没人做出来。去paper with code上看排行榜,最强的想都不用想是2D特征,先做了个锐化,然后效果出奇的好。
总结
祝大家都能学有所成,取得好成绩。
文章出处登录后可见!