***************************************************
码字不易,收藏之余,别忘了给我点个赞吧!
***************************************************
———Start
首先参考上一篇的训练过程,因为测试需要用到训练获得的权重。
1、检查相关文件
1.1 检查test_vol.txt的内容是否是测试用的npz文件名称
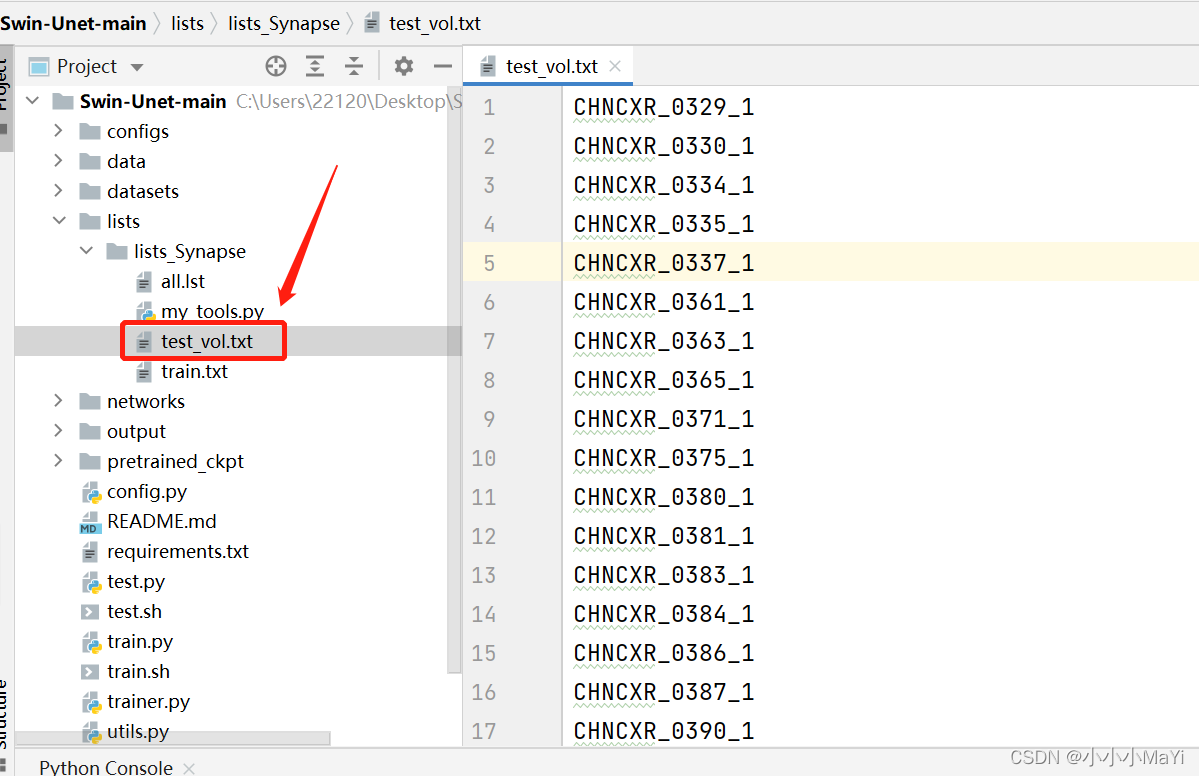
测试集的npz文件
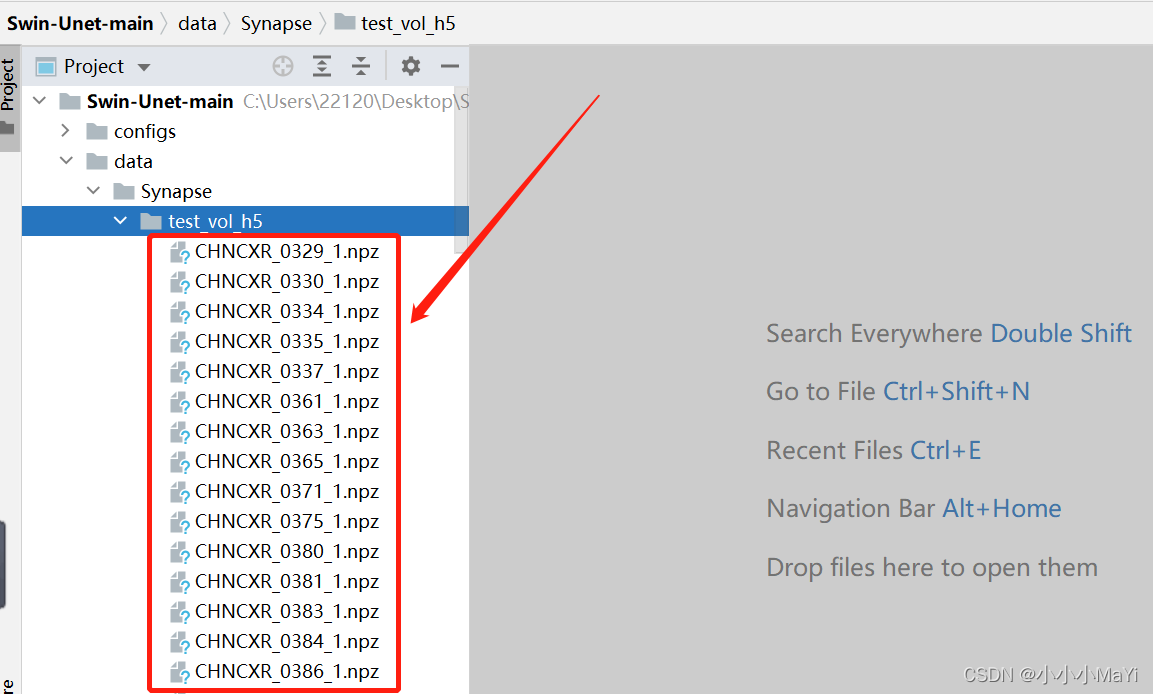
1.2 检查模型权重文件
2、修改部分代码
2.1 修改dataset_synapse.py
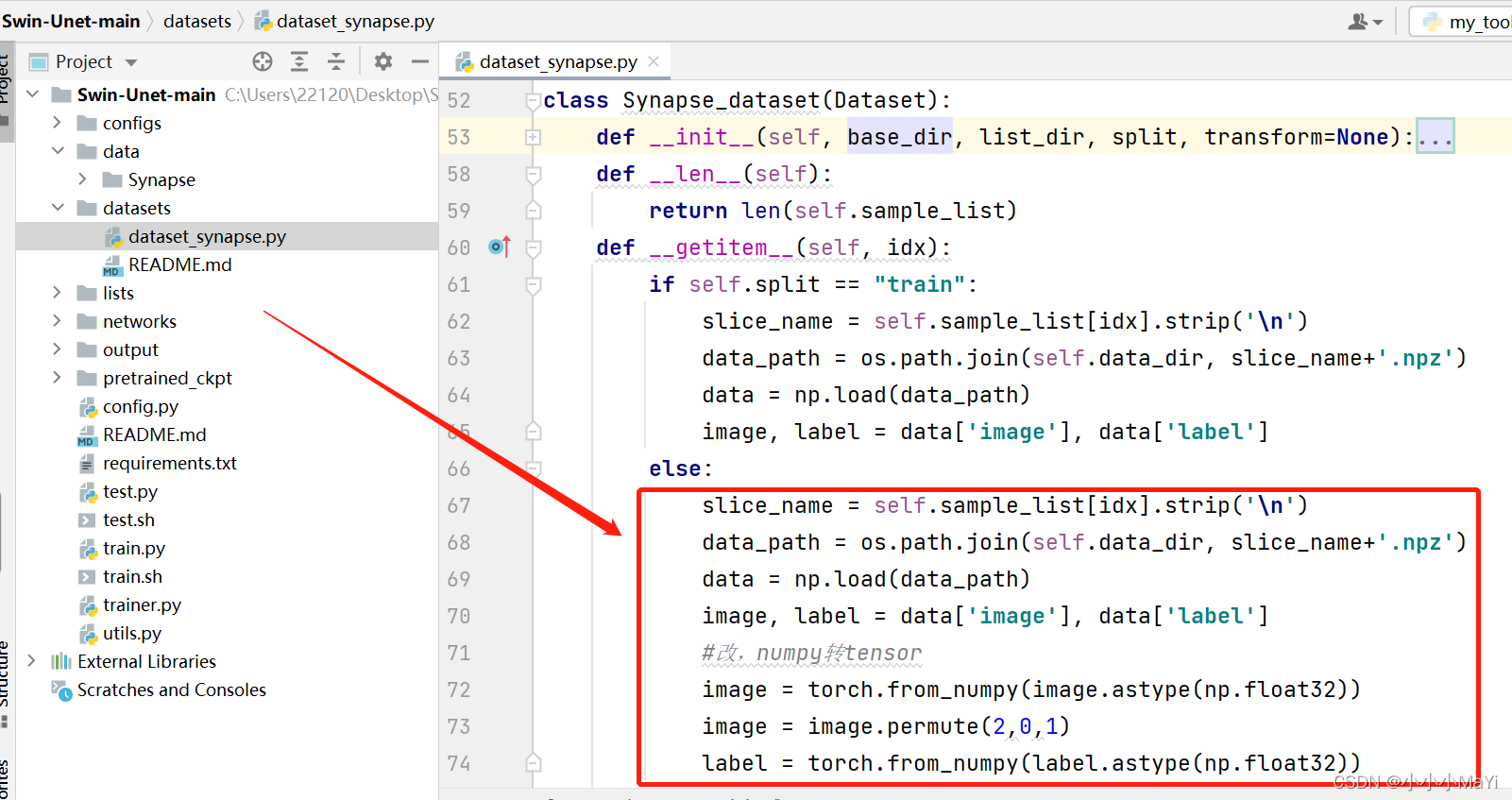
slice_name = self.sample_list[idx].strip('\n')
data_path = os.path.join(self.data_dir, slice_name+'.npz')
data = np.load(data_path)
image, label = data['image'], data['label']
#改,numpy转tensor
image = torch.from_numpy(image.astype(np.float32))
image = image.permute(2,0,1)
label = torch.from_numpy(label.astype(np.float32))
2.2 修改test.py代码
修改相关参数和文件路径
is_savenii:是否保存预测结果图片
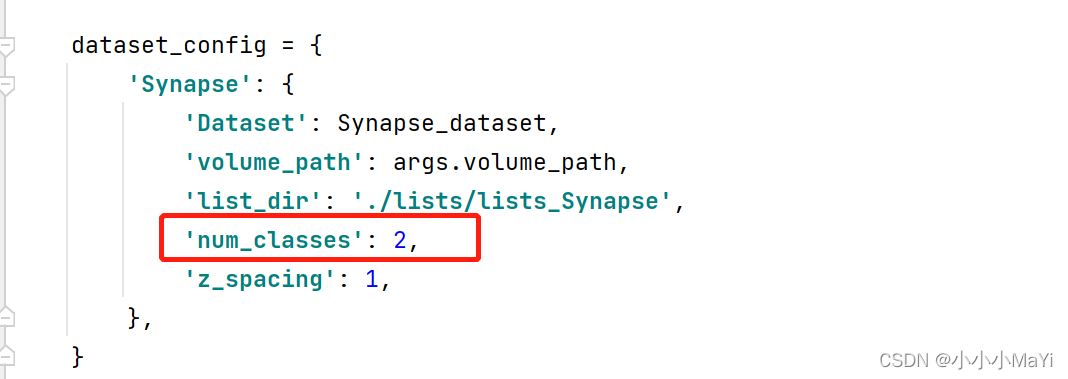
num_classes:预测的目标类别数+1
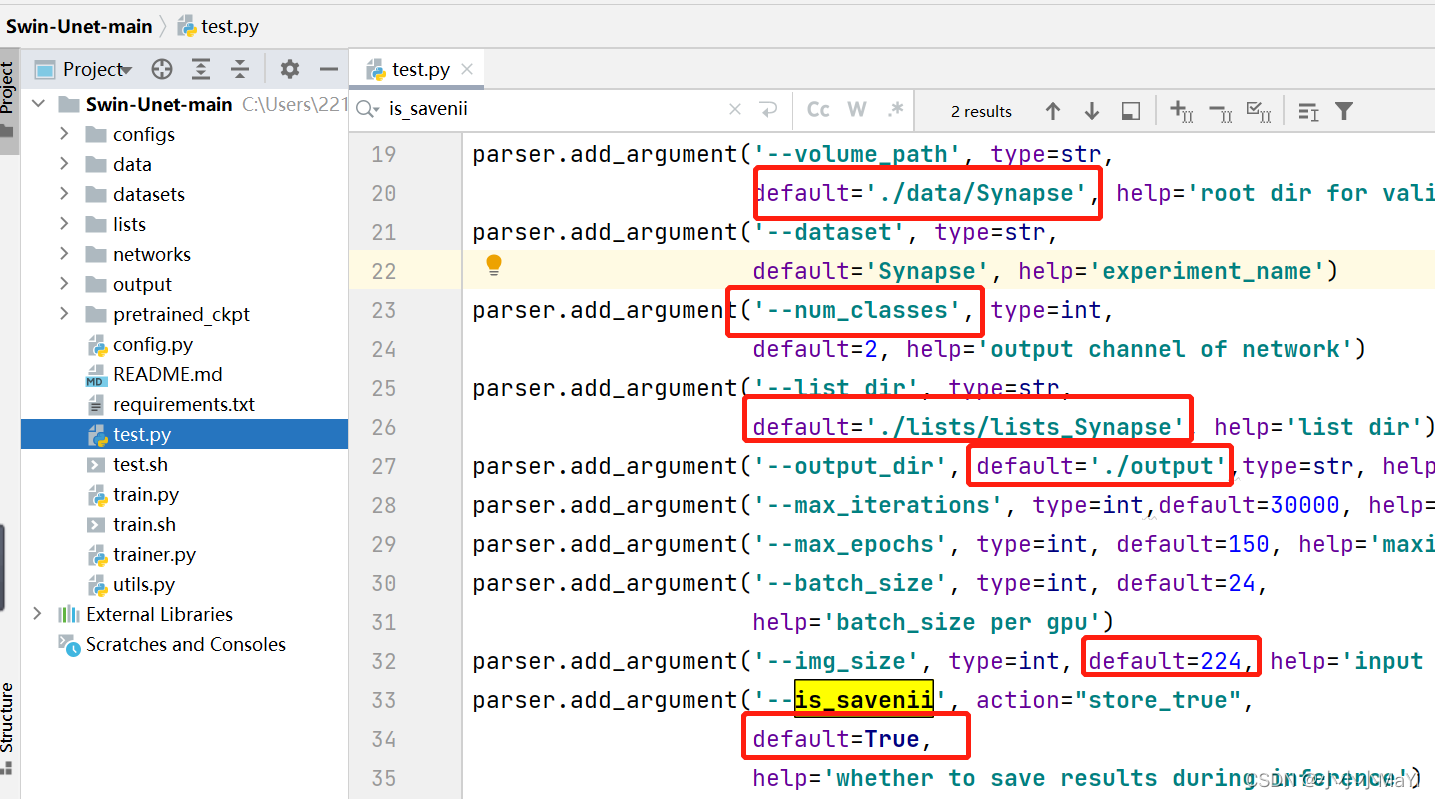
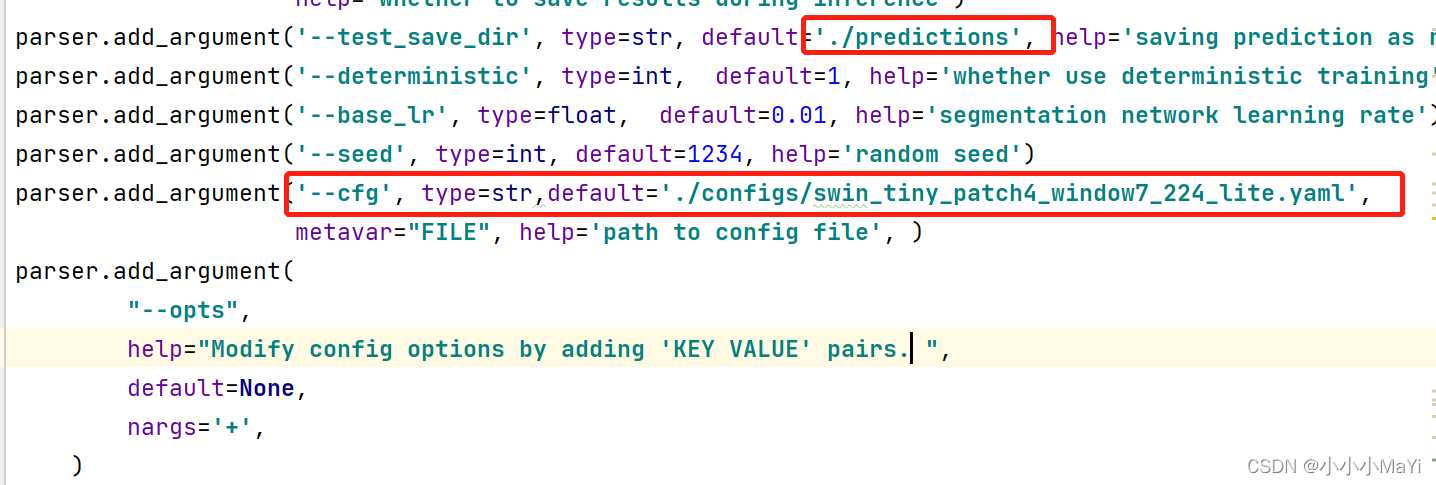
cfg:swinUnet网络结构配置文件
test_save_dir:保存预测结果文件夹
num_classes:预测的目标类别数+1
2.3 修改util.py代码(分两种情况)
第一种情况:保存预测原图,保存的结果是一张灰度图,每个像素的值代表该像素属于哪个类别。例如(0:背景,1:目标1,2:目标2…),这是一张全黑图。
def test_single_volume(image, label, net, classes, patch_size=[256, 256], test_save_path=None, case=None, z_spacing=1):
image, label = image.squeeze(0).cpu().detach().numpy(), label.squeeze(0).cpu().detach().numpy()
_, x, y = image.shape
# 缩放图像符合网络输入大小224x224
if x != patch_size[0] or y != patch_size[1]:
image = zoom(image, (1, patch_size[0] / x, patch_size[1] / y), order=3)
input = torch.from_numpy(image).unsqueeze(0).float().cuda()
net.eval()
with torch.no_grad():
out = torch.argmax(torch.softmax(net(input), dim=1), dim=1).squeeze(0)
out = out.cpu().detach().numpy()
# 缩放预测结果图像同原始图像大小
if x != patch_size[0] or y != patch_size[1]:
prediction = zoom(out, (x / patch_size[0], y / patch_size[1]), order=0)
else:
prediction = out
metric_list = []
for i in range(1, classes):
metric_list.append(calculate_metric_percase(prediction == i, label == i))
if test_save_path is not None:
#保存预测结果
prediction = Image.fromarray(np.uint8(prediction)).convert('L')
prediction.save(test_save_path + '/' + case + '.png')
return metric_list
第二种情况:保存可见图像,将不同类别映射成不同的颜色。只需要将上面代码的if test_save_path is not None:里面的内容替换成下面的代码即可。
#将不同类别区域呈彩色展示
#2分类 背景为黑色,类别1为绿色
if test_save_path is not None:
a1 = copy.deepcopy(prediction)
a2 = copy.deepcopy(prediction)
a3 = copy.deepcopy(prediction)
#r通道
a1[a1 == 1] = 0
#g通道
a2[a2 == 1] = 255
#b通道
a3[a3 == 1] = 0
a1 = Image.fromarray(np.uint8(a1)).convert('L')
a2 = Image.fromarray(np.uint8(a2)).convert('L')
a3 = Image.fromarray(np.uint8(a3)).convert('L')
prediction = Image.merge('RGB', [a1, a2, a3])
prediction.save(test_save_path+'/'+case+'.png')
至此,设置完毕,右键run运行,若控制台出现下面的结果,则表示运行正确,我这里的权重只训练了一个epoch,所以预测的都是0。
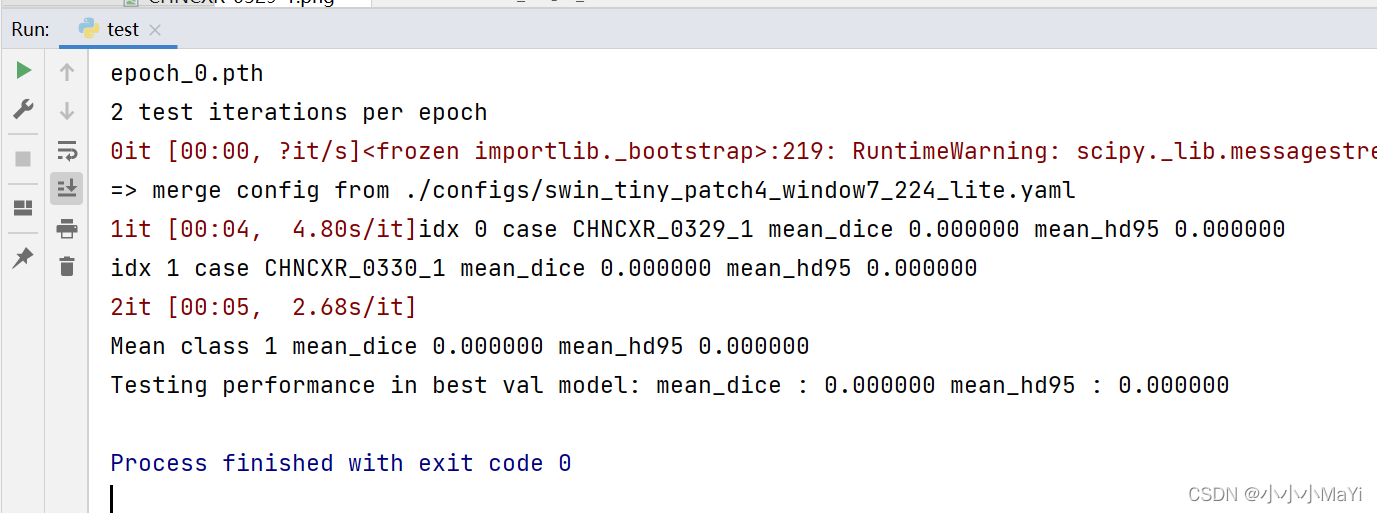
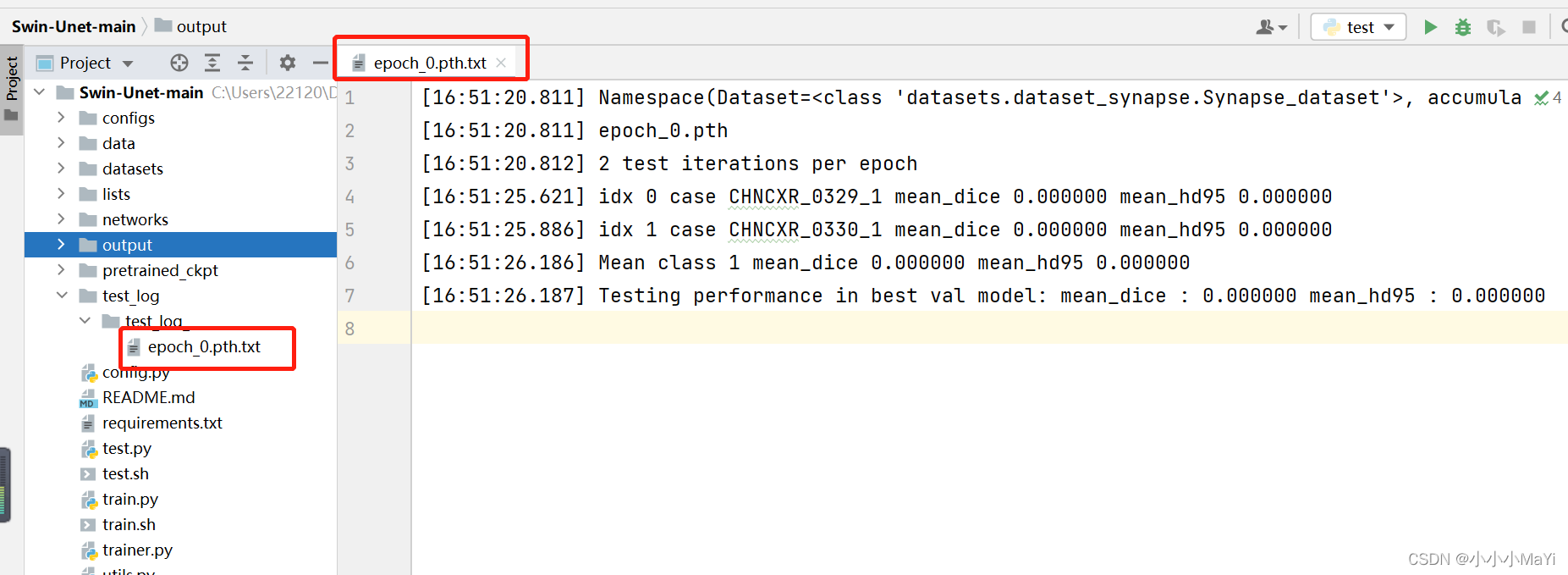
3、查看预测结果
查看日志文件
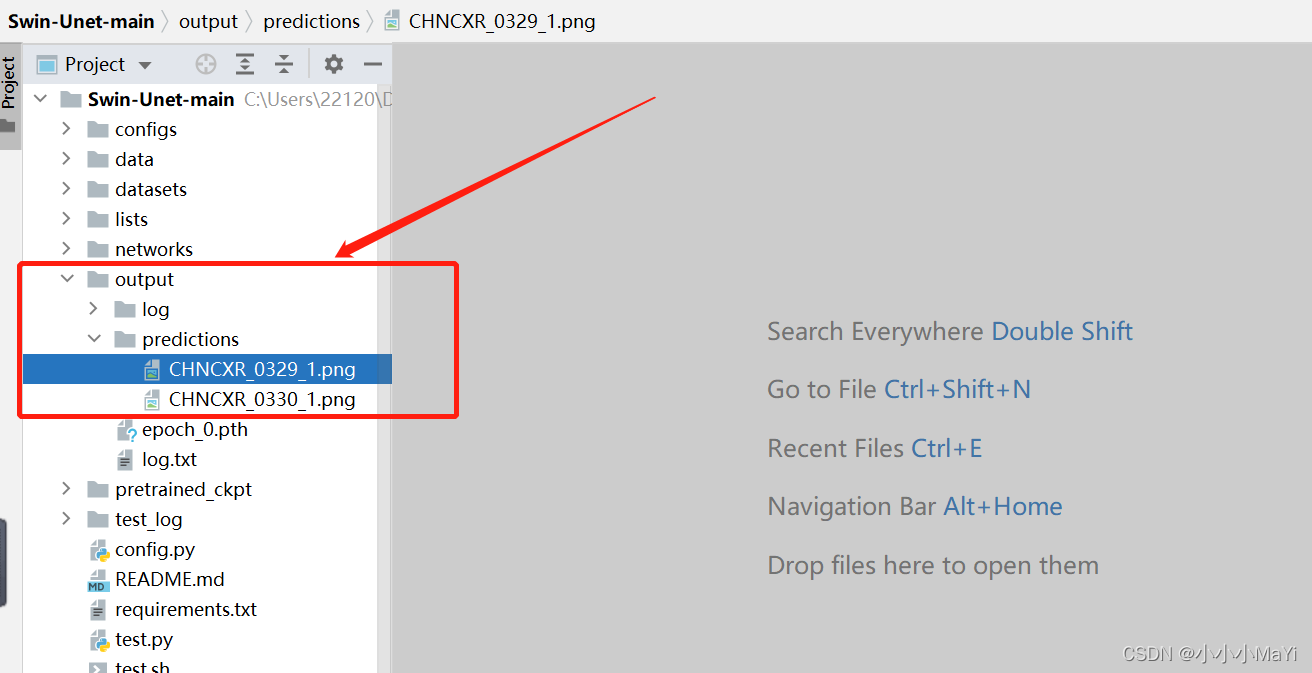
查看预测结果图
总结: swinUnet主要由swin_transform模块构成,数据量太少的时候训练效果很差,跟TransUnet不能比。由于仅文字表述某些操作存在局限性,故只能简略描述,有任何疑问可下方留言评论或私信,回复不及还望见谅,感激不尽!
文章出处登录后可见!
已经登录?立即刷新