文章目录
- 前言
- 1. 环境配置与文件
- 2. 安装步骤
- 2.1 安装相关依赖
- 2.2 安装官方驱动
- 2.3 禁用nouveau并且关闭图形化界面(Xserver)
- 2.4 安装驱动
- 2.5 安装cuda
- 2.6 cudnn安装
- 3. BUG处理
- 3.1. 循环登陆or无法进入Xserver
- 3.2. 显卡驱动丢失,nvidia-smi报错
前言
说实话,笔者毕业后已经从业多年了,但是仍然有很多开发环境配置的问题让人懵圈,好在笔者一直有写笔记的习惯,之前一直是记录在私人云,如今整理出来分享给各位,并且除了说明步骤,还会尽可能解释这么做的原因,方便读者厘清逻辑。
注意:本文针对linux系统
1. 环境配置与文件
本文所使用的环境配置为:
- 显卡驱动:nvdia430
- 文件名:NVIDIA-Linux-x86_64-430.14
- cuda:cuda-10.0
- 文件名:cuda_10.0.130_410.48_linux
- cudnn:cudnn7.5
- 文件名:cudnn-10.0-linux-x64-v7.5.0.56
可以发现我们使用的显卡驱动是430版本的,和cuda10.0 中自带410版本驱动不匹配,但是并无大碍,430驱动和cuda-10之间是完全兼容的。不过要注意的是,如果安装的显驱和cuda默认的显驱版本相差过大有是否会出现不兼容尚不清楚。
另外,关于不同cuda和cudnn版本的选择是很重要的,因为可能最新的版本各大深度学习框架支持并不理想,比如tensorflow的预编译安装包只支持cuda10.0,其他版本需要自己手动编译;在cuda10刚出的时候,pytorch的libtorch也只支持到cuda9,因此请根据自己的需求选择。
2. 安装步骤
2.1 安装相关依赖
sudo apt-get install build-essential #这是编译环境,包含make,GCC G++等
笔者的电脑只安装了编译环境就能正常安装显卡驱动了,但是查阅资料发现不同作者给出的依赖各不相同,以下为部分汇总,如果只安装编译环境无法正常安装显卡驱动,请尝试安装以下软件包
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install libopenblas-dev liblapack-dev libatlas-base-dev
sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
2.2 安装官方驱动
前往nvidia的官方网站下载对应驱动 https://www.nvidia.com/Download/index.aspx?lang=cn
选择与自己显卡对应的驱动进行下载即可
2.3 禁用nouveau并且关闭图形化界面(Xserver)
Nouveau是由第三方为NVIDIA显卡开发的一个开源3D驱动,也没能得到NVIDIA的认可与支持。虽然Nouveau Gallium3D在游戏速度上还远远无法和NVIDIA官方私有驱动相提并论,不过确让Linux更容易的应对各种复杂的NVIDIA显卡环境,让用户安装完系统即可进入桌面并且有不错的显示效果,所以,很多Linux发行版默认集成了Nouveau驱动,在遇到NVIDIA显卡时默认安装。企业版的Linux更是如此,几乎所有支持图形界面的企业Linux发行版都将Nouveau收入其中。
不过对于个人桌面用户来说,处于成长阶段的Nouveau并不完美,与企业版不一样,个人用户除了想让正常显示图形界面外很多时候还需要一些3D特效,Nouveau多数时候并不能完成,而用户在安装NVIDIA官方私有驱动的时候Nouveau又成为了阻碍,不干掉Nouveau安装时总是报错。
Xserver就是Linux的图形化界面
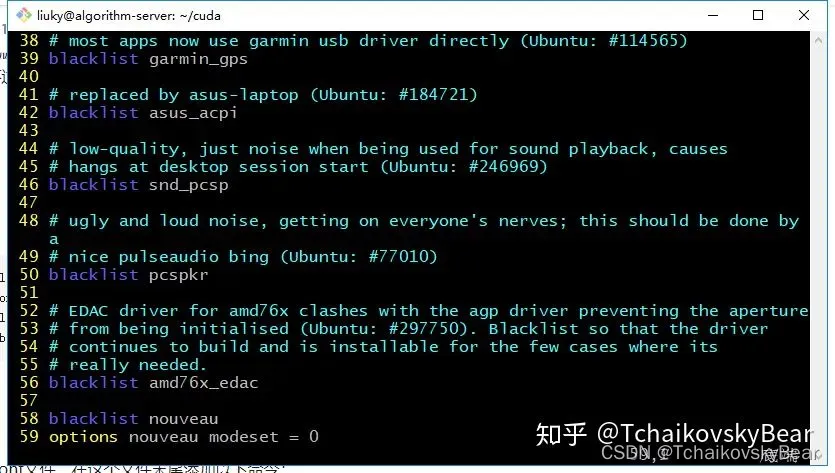
修改//etc/modprobe.d/blacklist.conf文件,在这个文件末尾添加以下命令:
blacklist nouveau
options nouveau modeset = 0
修改后如图:
然后执行命令更新启动文件后重启:
sudo update-initramfs -u
sudo reboot
重启后检查nouveau是否关闭,输入以下命令:
lsmod | grep nouveau
如果没有输出,表示nouveau已经禁用。
最后关闭图形界面:
service lightdm stop
注意你的电脑可能没有安装lightdm图形界面,而使用的是gdm3,这种情况下你需要执行
service gdm3 stop
或者安装lightdm后再关闭它(推荐这个,因为从经验来说你很可能以后还是要装它的),安装命令如下:
sudo apt install lightdm
2.4 安装驱动
进入显卡驱动安装文件所在的目录下执行以下命令安装:
sudo ./NVIDIA-Linux-x86_64-430.14.run –no-opengl-files
由于各位下载的驱动版本可能和我的并不一样,请以自己的文件名为准,另外参数 –no-opengl-files表示不安装OpenGL文件,这个参数能够避免无法进入图形界面的问题
安装过程中一路accept或者continue下去就行,安装完成后 执行以下命令看是否安装成功:
nvidia-smi
成功的话会有如下显示:
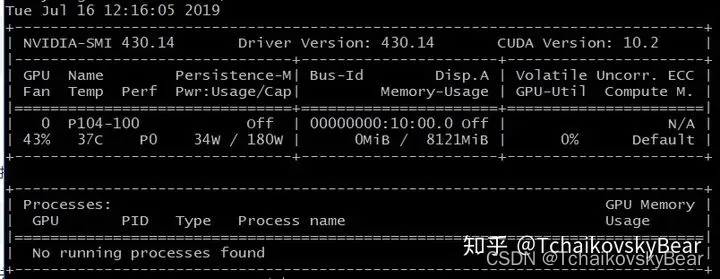
你会发现显驱的cuda 版本是10.2,不过好像并不会和我们即将安装的cuda10.0发生冲突。
然后启动Xserver并重启检查是否有bug:
service lightdm start
sudo reboot
如果你的Xserver没有办法正常启动,或者卡在登陆界面循环登陆,那么很有可能是在上面的安装步骤中没有正确关闭Xserver或者驱动安装时没够添加参数–no-opengl-files,请检查一下,报错的处理方法集中在后文bug处理章节。
2.5 安装cuda
安装完显卡驱动后开始安装cuda,同样需要去nvidia的cuda页面下载对应的安装包。
cuda下载页面:https://developer.nvidia.com/cuda-downloads
首页默认提供的是10.1版本的,我们需要的是10.0,点击legacy releases下载早期版本:
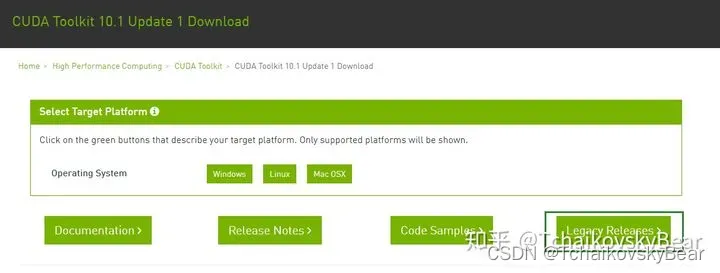

根据自己的系统版本下载,笔者使用的是ubuntu18
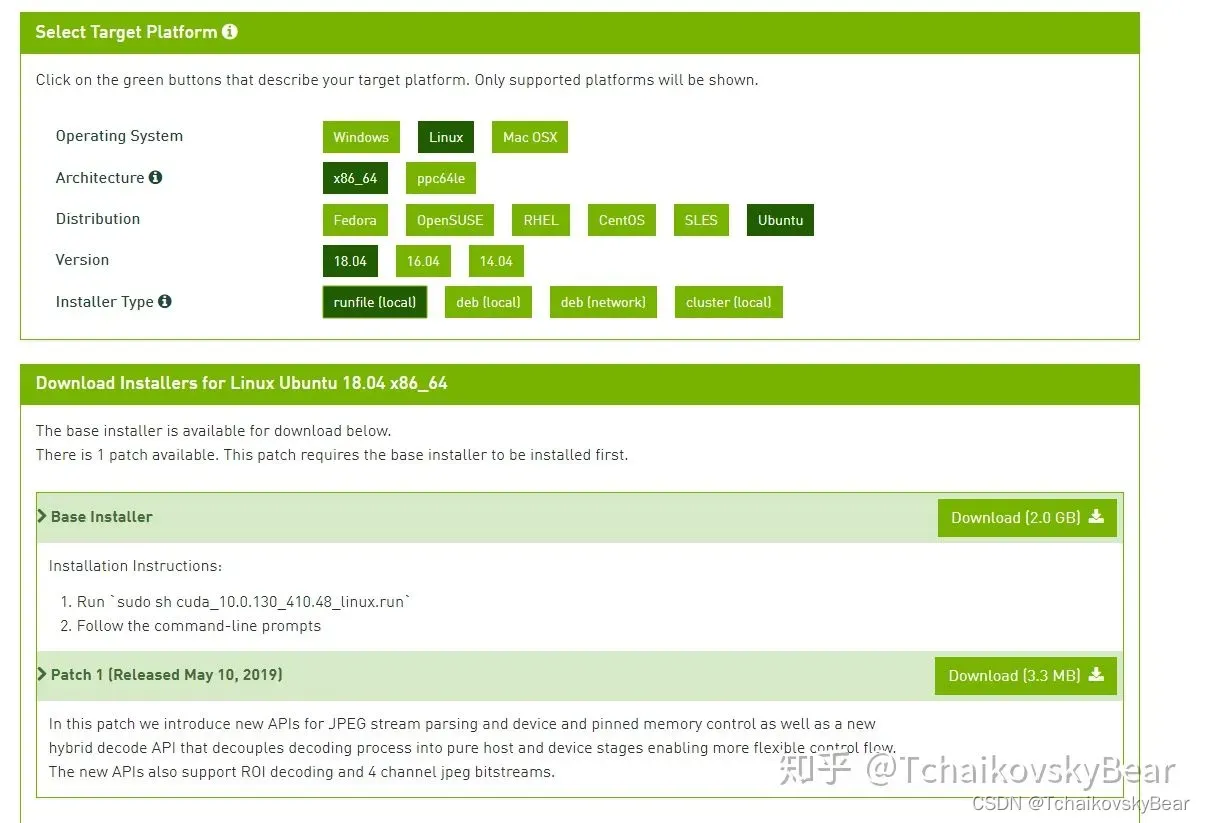
其中下载第一个Base Installer就可正常使用,patch 1是补丁,有需要也可以下载.
接下来开始安装,注意这里同样需要先关闭Xserver,然后执行cuda10的安装文件:
service lightdm stop
sudo ./cuda_10.0.130_410.48_linux.run
这个时候会有很多提示需要你确认,由于上文中已经成功安装了显卡驱动,所以这里就不需要再次安装了
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 XXX.XX ?
这里选择 no,其余都是yes或者accept
安装成功后开始添加系统变量,这里可以选择在profile中添加,或者添加在自己用户下的.bashrc文件中:
vim ~/.bashrc #打开配置文件
添加以下变量:
export PATH=/usr/local/cuda-10.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda-10.0
添加完成后的效果如图:
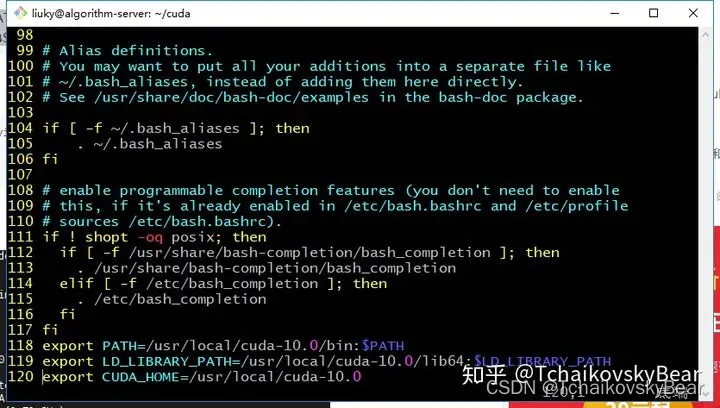
这些变量可以让python找到cuda的库和头文件,避免出现no find之类的错误
执行source命令使bashrc文件生效:
source ~/.bashrc
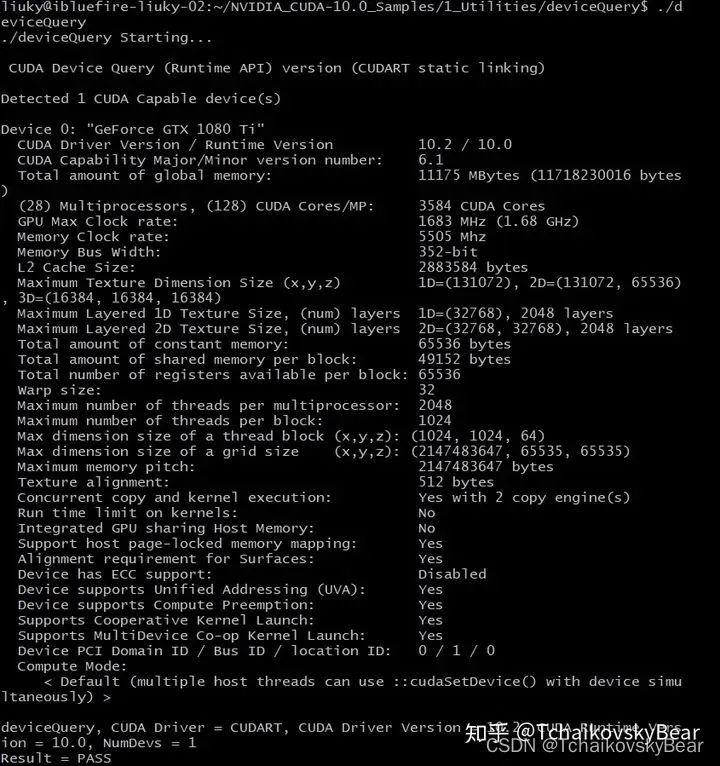
最后验证cuda是否安装成功,注意这里需要在安装cuda的时候安装了相关sample,如果完全按照本文教程则sample也已成功安装:
cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
若看到以下信息则安装成功:
2.6 cudnn安装
安装完cuda后, 我们还需要安装cudnn: https://developer.nvidia.com/cudnn
要注意的是cudnn需要注册后才能下载,笔者使用的是7.5版本的cudnn,因此也需要选择早期版本下载:
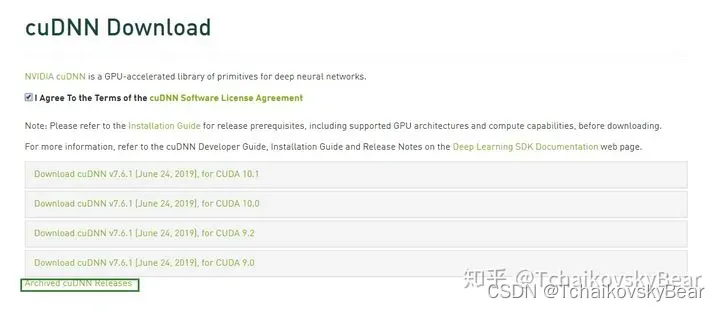
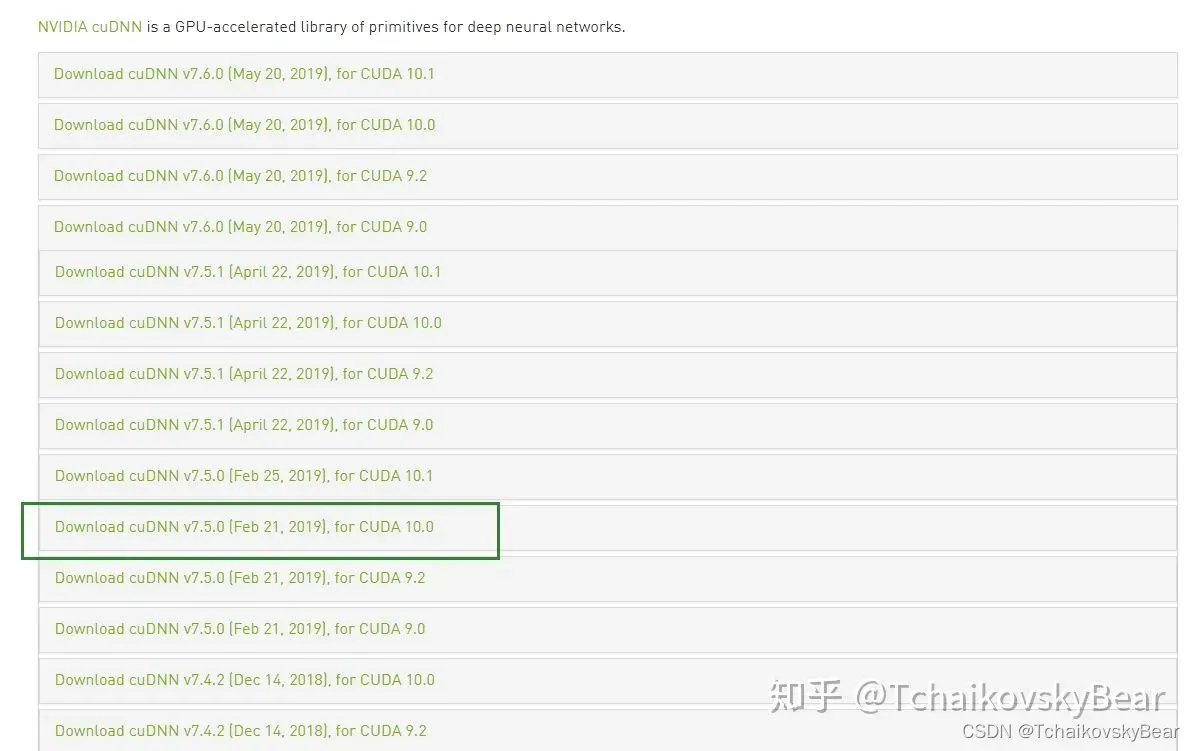
安装cudnn:
cudnn很容易安装,只需要将文件解压后拷贝进cuda根目录即可:
tar -zxvf cudnn-10.0-linux-x64-v7.5.0.56.tgz #解压
cd cudnn-10.0-linux-x64-v7.5.0.56 #进入cudnn文件夹
sudo cp -r cuda/* /usr/local/cuda-10.0/ #将文件夹下的所有文件拷贝进cuda10下
至此就大功告成全部安装成功了。
3. BUG处理
这里介绍一下笔者在显驱和cudnn出现过的相关bug和处理方法:
3.1. 循环登陆or无法进入Xserver
推测造成循环登录或者无法进入图形化界面的主要原因是openGL发生错误,反映到操作上就是安装过程中没有禁用Xserver或者没有禁用nouveau(但是理论上没有禁用nouveau是无法执行安装程序的,会报错),所以解决办法就是卸载目前的显卡驱动后重新按照教程安装一遍,这里给出卸载显驱的命令:
service lightdm stop #关闭Xerver服务
sudo /usr/bin/nvidia-uninstall #nvidia自带的卸载程序
sudo apt-get install autoremove --purge nvidia* #通过apt来卸载
上面两个命令可以都执行一遍,避免没卸干净。
3.2. 显卡驱动丢失,nvidia-smi报错
如果发现cuda没有正常启动,输入nvidia-smi报错:
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
这里有两种可能,先说第一种:如果你是刚装好驱动就报这个错误,那么是由于nvidia驱动没有被内核加载,可以尝试执行以下命令查看是否有内核文件:
cd /lib/modules
find . -name "*.ko" | grep -i nvidia
正常情况下的输出应为:
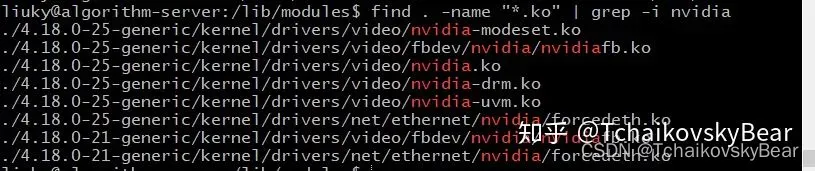
比对看一下自己是否缺少了nvidia.ko(也有可能是nvidia_xxx.ko)这个文件。
如果缺少了,则需要安装kernel source:
sudo apt-get install linux-source
sudo apt-get install linux-headers-4.18.0-25-generic
其中:4.18.0-25-generic来自于命令 uname -r 的输出
第二种情况是正常安装后使用了一段时间,突然某一天报错,这种情况一般是最近有对cuda环境进行过更改,导致显卡驱动损坏。
这种情况下最简单粗暴的方法就是将cuda和显卡驱动全部卸载重装:
service lightdm stop #关闭Xserver服务
sudo /usr/bin/nvidia-uninstall #nvidia自带的卸载程序
sudo apt-get autoremove --purge nvidia* #通过apt来卸载
sudo /usr/local/cuda-10.0/bin/uninstall_cuda_10.0.pl #卸载cuda
卸载完成后重新装一遍即可。
文章出处登录后可见!