目录
引入
AI的表现依赖大数据。曾经一段时间,对于图像识别的准确率只能达到60%~70%,这其中有机器学习算法和计算机硬件性能的局限,但是重要的时缺少数据。2009年斯坦福大学教授李飞飞、普林斯顿大学教授李凯建立一个项目收集5000万张高清图片,标注8万多个单词,并举办ImageNet图像识别竞赛,促进计算机视觉的发展。随后一个课题组给出基于大数据的深度学习模型,进一步促进了图像识别的准确率。
大数据不仅可用来描绘客户行为和商业规律,也是训练AI模型的基本原料。但是,AI对数据有着严苛要求,不是所有数据都行,数据必须是完整的、大量的、有业务含义的、有特征标签的。有的数据需要加工和处理、分析和挖掘。
一、大数据概述
“大数据”的概念早在20世纪被提出,麦肯锡公司定义它为“一种规模大到在获取、存储、管理、分析方面大大超出传统数据库软件工具能力范围的数据集合”。今天大数据含义在不同语境下含义不同,既指复杂且大量的数据集合、也指一系列海量数据处理技术,还能代表一种由数据驱动的商业模式。
大数据的“大”是相对的,没有确切的界定,大数据并不单指数据容量的大小,还要看对这些数据按照特定需求进行处理的难度。大数据不仅指大量数据,还要看数据类型丰富度、处理速度快、价值密度低等特点。“大”也带来一些问题——大数据中真正有价值的数据少,这种现象称价值洼地。数据的体量越大,挖掘有效数据难度越大,数据中的错误可能越多,面临的技术难度越大。

二、数据处理的流程&方法
数据使用的两种基本方式:①数据面向“结果”:直接对数据进行分析和处理,找到数据关联关系,挖掘有价值的信息。②数据面向“过程”:通过机器学习的方式处理数据或构建AI模型,此时数据不再是直接分析的对象而是模型训练的输入。实际情况两种可混合使用。
下面主要介绍的是第①种方式,第②种会在后续章节机器学习算法中谈及:
1、数据收集——“从无到有”
本步骤最难也最重要,很多人误以为AI的关键是算法,其实不是,AI的大部分算法已经发展的较为成熟,很多研究工作是放在算法改进和优化上,底层逻辑与十几年前并无本质区别,但是数据收集则不同,这是前提和关键。——“数据决定了机器学习的上限,算法只是尽可能逼近这个上限!”
数据收集渠道:①一手数据:直接调查的原始数据,是数据源头,最新也最有价值;②二手数据:别人调查的数据,或将原始数据建工和汇总后公布的数据,可能掺杂错误。
不仅对科学研究,数据收集对AI的发展也至关重要。很多领域,研究人员回公开自己的算法但很少公开自己的数据,如谷歌首席科学家诺维格这样评价谷歌产品:“我们没有更好的算法,有的只是更多的数据。”
2、数据加工——“从有到能用”
a、ETL
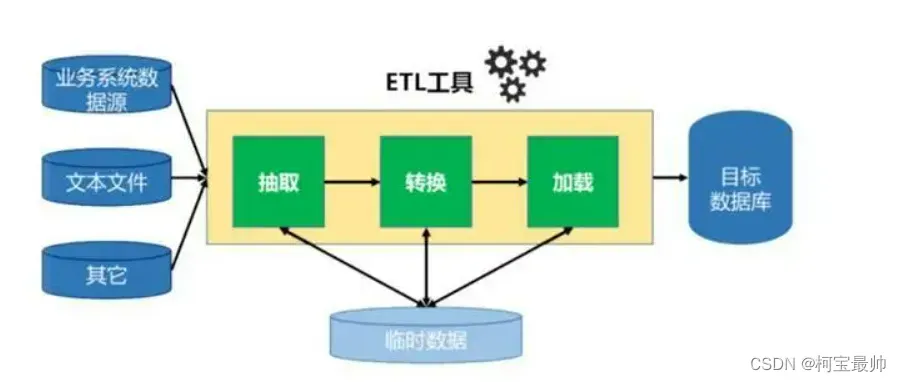
数据加工分为3步骤:抽取、转换、加载,简称ETL。目的是将很多分散、零乱、标准不统一的数据整合到一起,为分析决策提供数据支撑。
数据抽取:难点在于数据源多样,数据保存在不同地方,可能涉及不同的数据库软件产品、不同的数据类型格式,因此需要挑选不同的抽取方法。
数据转换:数据按特定需求进行聚合、统计、汇总。数据加工环节中花费时间最长的,总工作量的6~7成,工作量很多,比如将字符型变量变成数字型变量,或处理缺失值、处理异常数据、剔除重复数据、检查数据一致性等。该过程之所以复杂,是因为数据质量、种类、保存类型各不相同,现实中多数数据存在口径不一致、不完整、格式混乱等问题——都是“脏数据”,需要清洗一下,例如男病人的病例记录中出现了卵巢癌!!
数据加载:一旦数据转换完成,数据就会经过加载最终写入数据仓库,将数据集中存储。集中存储数据有很多途径,如可以把各种类型的数据关联起来分析,也可对它们执行批量查询和计算。
不同场景对数据处理的需求不同,有离线、实时等方法。离线处理:实时性要求低,处理总量大(总数据量),需更多存储资源。实时处理:实时性要求高,处理速度快(单位时间数据量),需要更多计算资源。
数据加工过程是让数据发挥价值的基础工作,市面很多ETL工具,,只看一个数据加工任务这些工具很好用,但是企业一般这样的任务成百上千,保证所有任务都不出错仍有巨大挑战!
b、独热编码和特征工程
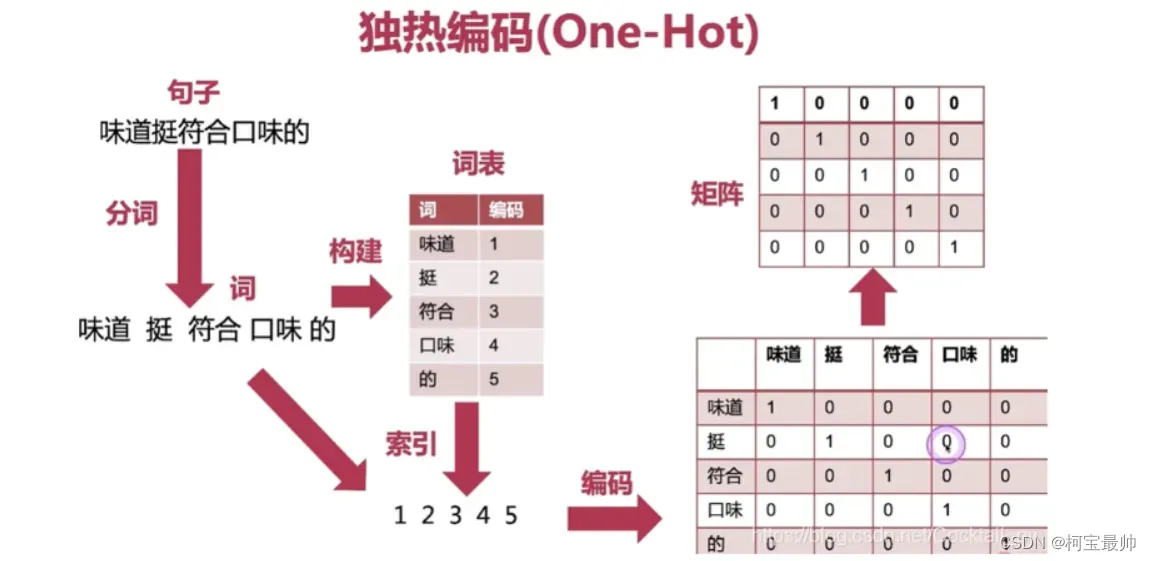
例如有ABC三个人,A:32岁,男,程序员;B:28岁,女,老师;C:38岁,男,医生。
用计算机可识别的语言数字描述,年龄就是数字不用变;性别女0或男1;职业类型用向量表示,
比如世界上有30000种职业,编号程序员1,老师2,医生3,用30000维的向量表示为[1,0,0,0...,0]、
[0,1,0,0...,0]、[0,0,1,0...,0]。ABC三个人可用一个30002维的向量表示:
[32,1,1,0,0,0...,0]、[28,0,0,1,0,0...,0]、[38,1,0,0,1,0...,0],有点类似前面的老鼠试毒的例子。但是实际数据类别很多,机器学习要处理海量数据的海量维度,这需要大量存储和计算资源。“维度灾难”也是我们必须在选择算法和模型阶段要考虑的因素——简单说,有些特征需要转换编码,有些特征需要进一步做降维处理,还有些特征可能不必要(可剔除和整合)。
使用机器学习算法之前需要数据预处理,一个重要步骤是——特征工程。特征工程就是把实体对象特征化,它是把原始数据转变为模型训练数据的过程,对原始数据进行去除重复、填充空缺、修正异常值等,要找到具有代表性的数据维度,刻画解决问题的关键特点。如描绘一辆车,“形状”更有代表性,“颜色”则不行。
特征选择是一个复杂的组合优化问题,特征太多会带来“维度灾难”,特征太少会让模型表现差。特征工程的目的是获取好数据,本步骤做的好,简单的算法就可取得不错效果。
3、数据分析
数据分析、数据科学、数据挖掘、知识发现等术语有时会混用,无明确界定。数据分析的目的是帮助决策,常见的分析场景有:①问题已知,答案未知。如当月销售额多少?哪个卖的最好?;②问题和答案都未知。如超市人员不知道货架商品有无更好的摆放方式,只能通过用户购物数据尝试性寻找规律,这种情况并不确定一定能找出答案,甚至不清楚要哪些数据。①是用数据给出解释,②是对数据进行探索!
下面简单介绍一些数据分析的常见算法:
a:关联分析算法
很多APP会以“最佳组合”的形式推荐商品,让消费者看到自己感兴趣的商品,有一种高效的算法可以处理此类问题——Apriori算法(先验算法)。它是一种经典的关联规则挖掘算法,用于找出经常一起出现的集合——频繁项集。
Apriori算法提出两个概念:支持度和置信度。支持度代表了某个商品或商品的集合在整个数据集中出现的比例,如100次购买记录中,人们购买A商品30次,30%就是支持度。置信度代表了在购买某种商品后,同时购买其他商品的概率,假设所有买A商品的30人中,有15人同时购买了B商品,则15/30=50%是商品B对A的置信度。
支持度和置信度都是重要的度量指标。以门店运营,通过支持度先滤掉一部分购买量本省就很少的商品;置信度表示两种商品的关联规则,置信度等同于条件概率,越高关联性越强,借此可找到关联性很强的商品组合。
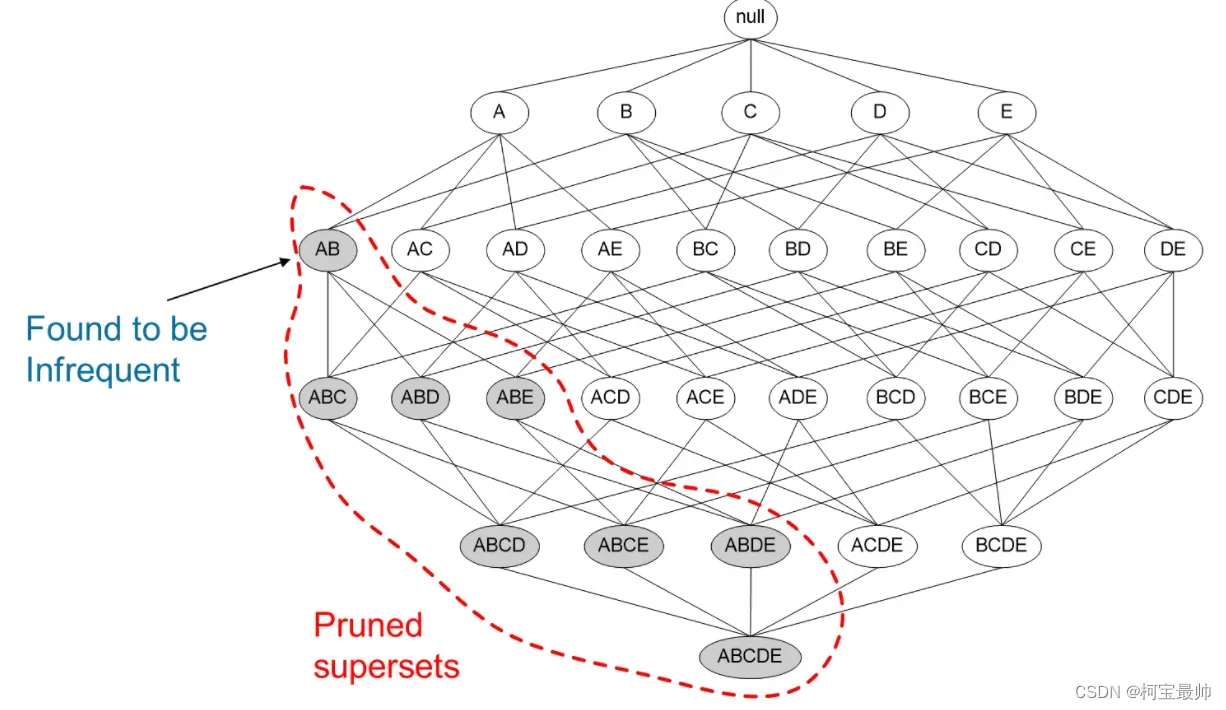
Apriori算法在计算关联规则时,有一个先验原则:如果某个集合是频繁的(经常出现),那么它的所有子集也是频繁的。这个原则很直观,但如果反过来看会发现另一层含义:如果某个集合不是频繁的,那么它的所有超集也不是频繁的。即如果{A}不是频繁的,那么所有包括A的集合如{A,B}也是非频繁的。这个结论会大大简化计算过程:
举例,假设我们拥有一批顾客购买商品的清单,Apriori算法计算过程如下:
第1步:设定支持度、置信度的阈值。
第2步:计算每个商品的支持度、去除小于支持度阈值的商品。
第3步:将商品(或项集)两两组合,计算支持度,去除小于支持度阈值的商品(或项集)组合。
第4步:重复上述步骤,直到把所有非频繁集合都去掉,剩下的频繁项集,就是经常出现的商品组合。
第5步:建立频繁项集的所有关联规则,计算置信度。
第6步:去掉所有小于置信度阈值的规则,得到强关联规则。对应的集合就是我们要找的具有
高关联关系的商品集合。
第7步:针对得到的商品集合,从业务角度分析实际意义。
由上可看出,Apriori算法的本质是“数数”,它循环检验哪些组合频繁地一起出现,并把它们找出来。Apriori算法通过支持度和置信度两个阈值,对原始数据集合做出层层筛选,每次筛选都淘汰一些不合条件的组合,直到找到最佳组合。
b:用户画像和商品推荐
除了关联分析,数据分析的另一种常见的应用场景是构建用户画像。用户画像是企业通过数据抽象出的关于用户的商业全貌,刻画了消费者的社会属性、消费习惯、消费行为,为产品设计、广告推送提供依据。如抖音通过点赞收藏等数据刻画用户,推送他们感兴趣的内容。
c:广告心理学和AB测试
当你拿着商家给你的优惠券尝试各种凑单、拼单等得到一定的优惠,但是因此你花出了更多的钱,买了很多非必要的物品。这背后就是商家在运用大数据分析、广告心理学、行为经济等手段,引导用户做出某些决策和行为。
心理学锚定现象:当人估算未知价格时,最初的数值(锚点)会在人的心里起到标杆和起点的作用。如订机票时,在推荐航班列表时,也不是所有航班都是最实惠的,很有可能明显高于其他推荐航班,它起的作用就是不被选而衬托出其他票价的实惠;再如在名表商店门口放一块价值100万的表,你不选择买它,但是它已在你的心中定下锚点,你的期望消费会变得比没看到之前高(低于100万范围内)。
虚拟商店的算法会不断试错,尝试找到最佳的推荐方案。“不断试错”经常在互联网产品开发中使用,如当产品面临多个选择方案时,可采用A/B测试的方法做出选择:即让一部分用户使用方案A,另一部分用户使用方案B。但是实际上,公司使用A/B测试不会仅仅两个版本,如设计广告标题,它的字体、粗细、大小、颜色、背景、语气、句式、布局等有着无数变化。
拓展:人是视觉动物,对图像信息最为敏感,视觉反应区占了大脑皮层的40%。数据可视化设计要平衡好信息量和可读性之间的关系,做到——信(真实)、达(清晰)、雅(简洁美观)。
三、大数据改变了什么
它改变了人们的生活习惯,所有的经验、时间、记忆在大数据时代将被重新定义!
大数据正在改变着人类发现问题、解决问题的方式。以前对于海量数据只能采用抽样的方法,但大数据时代可以直接分析全量数据,得到某些传统方法得不到的规律和结论。
人们思考问题从专家经验驱动到数据驱动,AlphaGo需要上亿棋局数据,智能汽车需要大量行驶过程中的实景路况数据,人脸识别也需要大量的人脸图像!
“知道数据在哪里,比知道数据本身更有价值!”
例如比起记忆圆周率,知道如何查到圆周率结果的资料显然更有用!用理解取代记忆,这是大数据给我们的另一个改变!
结语:海量丰富、高质量的数据是AI的基础,它帮助AI不断自我学习,改进性能!可以说——大数据赋予了AI“智能”,而让机器实现“智能”学习的过程,必须依赖强大的机器学习算法!请继续关注后续章节…
往期精彩:
【AI底层逻辑】——篇章3(下):信息交换&信息加密解密&信息中的噪声
【AI底层逻辑】——篇章3(上):数据、信息与知识&香农信息论&信息熵
【机器学习】——续上:卷积神经网络(CNN)与参数训练
【AI底层逻辑】——篇章1&2:统计学与概率论&数据“陷阱”
文章出处登录后可见!