轴承数据读取及信号处理专题[一]:EMD分解及统计特征提取
新年新气象,2023会更美好
趁着2023年新的一年的到来,祝大家万事皆胜意,所求得所愿!
距离上一次的博文更新过去了好久了,煽情的话就不说了,下面开始进入正题。
今天要更新的内容是PHM2012轴承数据集的信号处理第一篇——基于Python的EMD分解加统计特征提取。
EMD分解基本原理
经 验 模 态 分 解 (Empirical Mode Decomposition,EMD)是一种自适应的数据处理方法,最早是由Huang等人于1998年提出的。主要应用于非平稳和非线性数据处理方面。对于复杂的原始信号其内部的波动是非线性的,EMD 旨在将原始信号按照这些波动分解成一系列具有不同特征尺度的 IMF 分量,近周期的固有模态函数(intrinsic mode function,IMF)1。
对给定数据序列 ,按如下步骤进行 EMD:
1)确定给定数据序列 的所有极值点,用 1条光滑曲线连接所有的极大值,再利用三次样条插值法拟合该曲线得到上包络线
;同理连接所有的极小值点,得到下包络线
。并计算上、下包络线的平均包络线
:
2)计算原始数据 与平均包络线
之差
:
3) 若 满足 IMF 分量的条件, 那么
为所 求得的第一个 IMF 分量
; 否则, 将
作为新 的原始数据重复步骤 (1) 、步骤 (2), 直到满足 IMF 分量的条件为止。
4) 将 从原始数据
中分解出来, 得到残 差分量
:
5)分解后的 重复步骤
, 得到第 2 个 IMF 分量
和残差分量
。以此类推, 得到第
个 IMF 分量
, 直到残差分量
不能再分 解。此时, 原始数据
可表示为:
式中: 可看作是原始数据
的趋势或均值;
为 IMF 分量, 代表了原始数据的高频分量到低频分量。
EMD分解的Python的代码实现
import os
import sys
import csv
import pyhht
import numpy as np
import matplotlib.pyplot as plt
test_folder ='D:/FeigeDownload/实验数据/PHM2012/Learning_set/Bearing1_1/acc_02803.csv'
# 读取 CSV 文件
data = []
with open(test_folder, 'r') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
data.append(row[4]) # 将 CSV 文件中的第5列存入 data 列表,也就是水平振动数据
# 将数据转换为 numpy 数组
data = np.array(data, dtype=float)
# 设置 EMD 参数
max_imf = 5 # 最多分解出 3 个 IMF
maxiter = 500 # 最多迭代 500 次
# 进行经验模态分解
decomposer = pyhht.EMD(data, n_imfs=max_imf, maxiter=maxiter)
imfs = decomposer.decompose()
def plot_imfs(signal, imfs, time_samples=None, fignum=None, plotname=None):
if time_samples is None:
time_samples = np.arange(signal.shape[0])
n_imfs = imfs.shape[0]
#设置图幅的整体大小
plt.figure(num=fignum, figsize=(6,8))
axis_extent = max(np.max(np.abs(imfs[:-1, :]), axis=0))
# Plot original signal
#调整子图间距
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=0.5)
ax = plt.subplot(n_imfs + 1, 1, 1)
ax.plot(time_samples, signal)
ax.axis([time_samples[0], time_samples[-1], signal.min(), signal.max()])
# ax.tick_params(which='major', left=False, bottom=False, labelleft=False,
# labelbottom=False)
ax.grid(False)
ax.set_ylabel('Signal')
#可以不要这一行
# ax.set_title('Empirical Mode Decomposition')
# Plot the IMFs
for i in range(n_imfs - 1):
print(i + 2)
ax = plt.subplot(n_imfs + 1, 1, i + 2)
ax.plot(time_samples, imfs[i, :])
ax.axis([time_samples[0], time_samples[-1], -axis_extent, axis_extent])
# ax.tick_params(which='major', left=False, bottom=False, labelleft=False,
# labelbottom=False)
ax.grid(False)
ax.set_ylabel('imf' + str(i + 1))
# Plot the residue
ax = plt.subplot(n_imfs + 1, 1, n_imfs + 1)
ax.plot(time_samples, imfs[-1, :], )
#设置坐标轴范围
ax.set_xlim(0,2560)
# ax.axis('tight')
# ax.tick_params(which='both', left=False, bottom=False, labelleft=False,
# labelbottom=False)
ax.grid(False)
ax.set_ylabel('res.')
ax.set_xlabel('Bearing1_1EMD分解_2803',fontsize = 14)#, fontweight ='bold'
dirs = 'D:/PredictiveMaintenance/notebooks/全RUL_预测/'
if not os.path.exists(dirs):
os.makedirs(dirs)
plt.savefig(dirs + plotname+".png", bbox_inches='tight',dpi=300,format='png') # dpi=300
plt.show()
t = np.linspace(0, 2560, 2560)
plot_imfs(data, imfs, t,plotname='Bearing1_1EMD分解_2803')
得到的EMD分解的效果如图所示

统计特征提取
当然单纯的将EMD分解后的IMF分量当作特征,数据量不太够的,因此,可以采用的一种思路就是对IMF分量进行统计特征的提取如下列的表1和表22,比如能量啊,熵啊,时域统计特征,频域统计特征等。
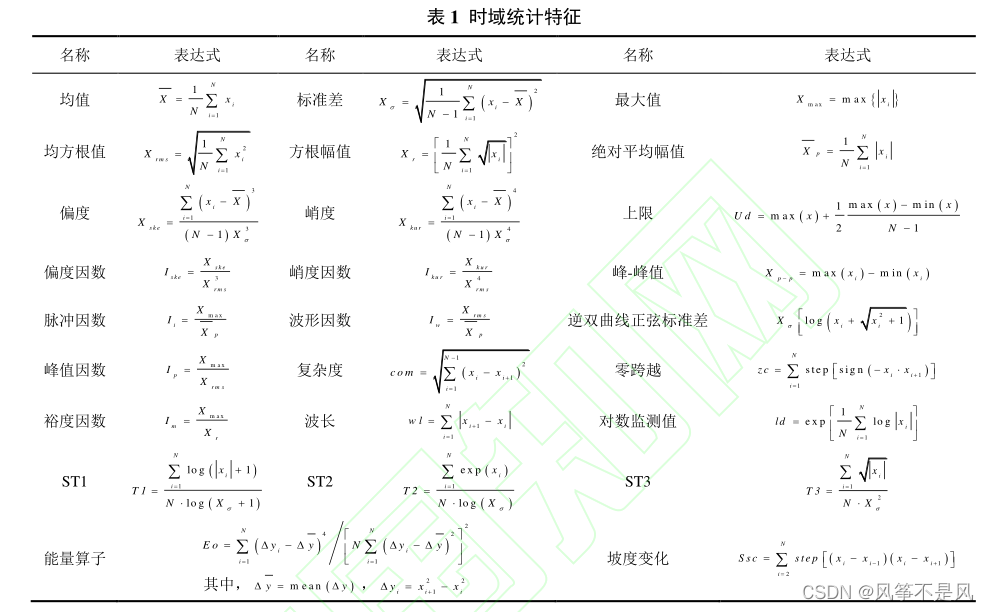

import os
import glob
import pandas as pd
import numpy as np
import csv
import matplotlib.pyplot as plt
from scipy.fftpack import fft
import pywt
import pywt.data
from scipy import signal, stats
from scipy.signal import savgol_filter
''' 函数获取当前使用的文件夹输入foldernumber(int),集合的路径(str)
逐个打开文件夹的输出路径'''
def get_folder(foldernumber, path = "D:/FeigeDownload/实验数据/PHM2012/Learning_set"):
folders = os.listdir(path)
folder = folders[foldernumber]
folder_path = path + "/" + folder
return folder_path
'''逐个加载acc文件。
输入:账号(str),当前方位的路径(str)
输出:一个csv文件的pandas数据帧'''
def get_accfile(filenumber,folder_path):
os.chdir(folder_path)
file_list = glob.glob("*.csv")
delimiter = ""
with open (file_list[filenumber], 'r') as f: #checks if the csv is seperated by ',' or ';'
dialect = csv.Sniffer().sniff(f.readline())
f.seek(0)
delimiter = dialect.delimiter
acc_data = pd.read_csv(file_list[filenumber], header = None, delimiter = delimiter)
return acc_data
'''获取Pandasfile的加速度
输入:pandas数据帧
输出:具有x-y加速度的Numpy数组'''
def get_acceleration(acc_data):
acc_horiz = acc_data.iloc[:,[4]]#csv文件的第4列|水平振动
acc_vert = acc_data.iloc[:,[5]]#csv文件的第5列|垂直振动
acc_horiz = acc_horiz.to_numpy()
acc_vert = acc_vert.to_numpy()
return acc_horiz, acc_vert
#计算RMS
def root_mean_square(data):
X = data
length = X.size
sum = np.sum(data**2)
return np.sqrt(sum/length)
#计算能量
def energy(data):
E = np.absolute((data))**2
E = np.sum(E)
return E
##FFT变换数据
def calculate_fft(data):
yf = fft(data)
yf = abs(yf)
return yf
'''
通过加速度并计算维纳熵
1.百科:维纳熵是功率谱宽度和均匀性的度量。噪音是典型的宽频带,在噪音范围内声音能量被抹得相当平滑,
而动物的声音,即使是多谐的,其频率结构也不太均匀。维纳熵是一个纯数,也就是说,它没有单位。
在0-1的尺度上,白噪声的熵值为1且为全序,纯音的熵值为0。
2.为了扩展动态范围,维纳熵以从0到负无穷大的对数刻度进行测量(白噪声:log 1 = 0;完整阶数:log 0 =负无穷大)。多谐波声音的维纳熵取决于功率谱的分布;
3.窄的功率谱(极端是纯音)具有较大的负Wiener熵值;宽功率谱的维纳熵值接近零
'''
def wiener_entropy(data, f=1.0, minimum = 1e-12 ):
_, power_spectrum = signal.welch(data)
power_spectrum = np.maximum(power_spectrum,minimum)
length = power_spectrum.size
log_data = np.log(power_spectrum)
log_data_sum = log_data.sum()/length
geomMean = np.exp(log_data_sum)
sum = power_spectrum.sum()
aritmeticMean = sum/length
wiener_entropy = geomMean/aritmeticMean
return wiener_entropy
#计算峭度
def calculate_kurtosis(data):
kurtosis = stats.kurtosis(data, axis = 0, fisher = False, bias = False)
kurtosis = np.asarray(kurtosis)
return kurtosis
#计算偏斜(偏度)
def calculate_skewness(data):
skewness = stats.skew(data,axis = 0, bias = False)
return skewness
#计算方差
def calculate_variance(data):
variance = np.var(data)
return variance
#计算峰峰值
def peak_to_peak(data):
ptp = np.ptp(data, axis = 0)
return ptp
#计算脉冲因子
def impulse_factor(data):
impulse_factor = np.max(np.absolute(data))/(np.mean(np.absolute(data)))
return impulse_factor
#计算裕度因子(边际系数)
def margin_factor(data):
mf = np.max(np.absolute(data))/(root_mean_square(data))
return mf
#波形因子(波形系数)
def wave_factor(data):
data = np.absolute(data)
wave_factor = np.sqrt(np.mean(data))/(np.mean(data))
return wave_factor
#计算波形的标准差
def standard_derivation(data):
std = np.std(data)
return std
#离散系数(变异系数/变差系数):概率分布离散程度的归一化量度
def variation_coefficient(data):
vc = np.std(data)/np.mean(data)
vc = np.nan_to_num(vc) #如果平均值为零,则向量返回必须用0替换的nan值
return vc
#计算均值
def mean(data):
return np.mean(data)
#计算最大值
def maximum(data):
return np.max(data)
#计算绝对平均值
def absolute_average(data):
absolute = np.abs(data)
absolute_average = np.mean(absolute)
return absolute_average
'''从路径中读取轴承号并返回一个字符串
输入:文件夹路径(str)
输出:轴承编号(str)'''
def get_bearing_number(path):
bearing_path = os.path.dirname(path)#返回文件路径
bearing = os.path.basename(bearing_path)#返回文件名
bearing = bearing.replace("Bearing", "")
return bearing
'''通过加速度或小波数组进行小波变换
a=低通滤波器后的数据
d=高通滤波器后的数据
aad=信号通过低通滤波器时是高通滤波器的两倍
'''
def wavelet_transform(data, wavelet = 'db10', level = 3):
wp = pywt.WaveletPacket(data=data, wavelet= wavelet, mode='symmetric', maxlevel=level)
x = wp['aad'].data
return x
# 在数据的结尾进行零填充
# 输入:Fetures的numpay数组
# 返回:带有后填充数据的numpay数组
def post_padding_multiple(data):
finished_vector = np.zeros((len(data)*len(data[0]),max(len(x[0]) for x in data)))
for i,j in enumerate(data):
#print(finished_vector[len(training_data[0])*i:i*len(training_data[0])+len(training_data[0])][0:len(training_data[i][0])].shape)
finished_vector[j.shape[0]*i:i*j.shape[0]+j.shape[0],0:j.shape[1]] = j
return finished_vector
# 在数据开头进行零填充(优于后填充)
# 输入:Fetures的numpy数组
# 返回:带有后填充数据的numpay数组
def pre_padding_multiple(data):
finished_vector = np.zeros((len(data)*len(data[0]),max(len(x[0]) for x in data)))
for i,j in enumerate(data):
#print(finished_vector[len(training_data[0])*i:i*len(training_data[0])+len(training_data[0])][0:len(training_data[i][0])].shape)
finished_vector[j.shape[0]*i:i*j.shape[0]+j.shape[0],-j.shape[1]:] = j
return finished_vector
# 对每个feature的数据逐个应用“最小-最大缩放”
# 输入:列出轴承文件夹的每个特征
# 返回:具有缩放值的numpy数组
def scaling_single(data):
for i,bearing in enumerate(data):
for y in range(len(data[0])):
maximum = np.max(data[i][y])
minimum = np.min(data[i][y])
data[i][y] = (data[i][y]-minimum)/(maximum-minimum)
return data
# 对整个数据应用最小-最大缩放。每个功能都按相同的值缩放!
# 输入:列出轴承文件夹的每个特征
# 返回:一个带有缩放值的numpy数组
def scaling_multiple(data):
maximum = 0
minimum = 0
for i in range(len(data[0])):
maximum = max(np.max(x[i]) for x in data)
minimum = min(np.min(x[i]) for x in data)
for y ,x in enumerate(data):
data[y][i] = (data[y][i]-minimum)/(maximum-minimum)
return data
# 对整个数据应用savgol_过滤器。不建议LSTM使用用于筛选器的小波变换
# 输入:功能的numpay数组
# 返回:一个带有过滤值的numpy数组
def filtering(data):
for i in range(len(data)):
print("here")
print(data[i].shape[0])
for j in range(data[i].shape[0]):
data[i] = savgol_filter(data[i],101,2)
return data
# 统计每个文件夹中的man csv(时间段)情况
# 输入:填充前的numpy特性数组
# 返回:包含每个数据计数的序列列表'
def get_sequencelist(data):
sequence_list = []
for i, bearing in enumerate(data):
sequence_list.append(len(data[i][0]))
return np.asarray(sequence_list)-1
###########################################大调用#############################################
# 这个函数调用上面的函数
# 1它打开给定路径中的每个文件夹,
# 2打开文件夹后逐个读取每个csv
# 3.创建特征
# 4最小-最大缩放它们
# 5向数据添加零填充
# 6将数据集另存为.npy文件
def get_data_from_path(path,name):
folderlist = os.listdir(path)
folderlist.sort()
features_vector = []
training_data = []
temp_vector = []
#acc_vector_x = []
for i, folder in enumerate(folderlist):
folder_path = get_folder(i,path)
#print(folder)
os.chdir(folder_path)
acc_file_list = glob.glob("*.csv")
for i, acc_file in enumerate(acc_file_list):#这里修改一下以对应get_current_RUL的寿命百分比计算
if "acc" in acc_file:
print(acc_file)
acc_data = get_accfile(i,folder_path)
acc_x, acc_y = get_acceleration(acc_data)
acc_x = acc_x.ravel()
wavelet_x = wavelet_transform(acc_x)
acc_y = acc_y.ravel()
wavelet_y = wavelet_transform(acc_y)
#acc_vector = np.append([acc_x],[acc_y], axis = 0)
#acc_vector_x.append(acc_x)
rms_x = np.asarray(root_mean_square(acc_x))
rms_y = np.asarray(root_mean_square(acc_y))
wavelet_rms_x = root_mean_square(wavelet_x)
wavelet_rms_y = root_mean_square(wavelet_y)
features_vector.append(rms_x)
features_vector.append(rms_y)
features_vector.append(wavelet_rms_x)
features_vector.append(wavelet_rms_y)
kurtosis_x = calculate_kurtosis(acc_x)
kurtosis_wavelet_x = calculate_kurtosis(wavelet_x)
kurtosis_y = calculate_kurtosis(acc_y)
kurtosis_wavelet_y = calculate_kurtosis(wavelet_y)
features_vector.append(kurtosis_x)
features_vector.append(kurtosis_y)
features_vector.append(kurtosis_wavelet_x)
features_vector.append(kurtosis_wavelet_y)
margin_x = margin_factor(acc_x)
margin_y = margin_factor(acc_y)
features_vector.append(margin_x)
features_vector.append(margin_y)
variance_x = calculate_variance(acc_x)
variance_y = calculate_variance(acc_y)
features_vector.append(variance_x)
features_vector.append(variance_y)
std_x = standard_derivation(acc_x)
std_y = standard_derivation(acc_y)
features_vector.append(std_x)
features_vector.append(std_y)
vc_x = variation_coefficient(acc_x)
vc_y = variation_coefficient(acc_y)
features_vector.append(vc_x)
features_vector.append(vc_y)
skewness_x = calculate_skewness(acc_x)
skewness_y = calculate_skewness(acc_y)
features_vector.append(skewness_x)
features_vector.append(skewness_y)
ptp_x = peak_to_peak(acc_x)
ptp_y = peak_to_peak(acc_y)
features_vector.append(ptp_x)
features_vector.append(ptp_y)
impulse_factor_x = impulse_factor(acc_x)
impulse_factor_y = impulse_factor(acc_y)
features_vector.append(impulse_factor_x)
features_vector.append(impulse_factor_y)
WE_x = wiener_entropy(acc_x)
WE_y = wiener_entropy(acc_y)
features_vector.append(WE_x)
features_vector.append(WE_y)
aa_x = absolute_average(acc_x)
aa_y = absolute_average(acc_y)
features_vector.append(aa_x)
features_vector.append(aa_y)
maximum_x = maximum(acc_x)
maximum_y = maximum(acc_y)
features_vector.append(maximum_x)
features_vector.append(maximum_y)
mean_x = mean(acc_x)
mean_y = mean(acc_y)
wavelet_mean_x = mean(wavelet_x)
wavelet_mean_y = mean(wavelet_y)
features_vector.append(mean_x)
features_vector.append(mean_y)
features_vector.append(wavelet_mean_x)
features_vector.append(wavelet_mean_y)
wave_factor_x = wave_factor(acc_x)
wave_factor_y = wave_factor(acc_y)
features_vector.append(wave_factor_x)
features_vector.append(wave_factor_y)
wavelet_energy_x = energy(wavelet_x)
wavelet_energy_y = energy(wavelet_y)
features_vector.append(wavelet_energy_x)
features_vector.append(wavelet_energy_y)
bearing_number = get_bearing_number(folder_path + "/" + acc_file)
RUL = get_current_RUL(bearing_number,i,path)
print(RUL)
features_vector.append(RUL)#38(19×2)个特征加上一个RUL,RUL也可以自己注释掉不要,最后自己直接保存到npy文件里面就可以了
###############################################################################################################
#this list contains all features of a csv file:包含所有文件的特征
features_vector = np.asarray(features_vector).reshape(1,-1)
#this numpy array contains the complete feature data of a bearing folder
#这个numpy数组包含一个bearing文件夹的完整特征数据
"""这里将features_vector计算好的特征传递给temp_vector,然后将features_vector重置为空列表"""
temp_vector.append(features_vector.reshape(-1))
features_vector = []###单次内循环结束
#print(kurtosis.shape)
#print(len(feature_vector))
# 单次中间循环结束
temp_vector = np.asarray(temp_vector)
print("转置前的形状:",temp_vector.shape)
#temp_vector[:,-1] = np.flip(temp_vector[:,-1])
temp_vector = np.transpose(temp_vector)
print("转置后的形状:",temp_vector.shape)
####################该矩阵包含每个轴承文件夹的每个特征#######################################################
"""最终,我们将只包含一个轴承的特征依次添加到training_data中,最后获得所有轴承的特征"""
training_data.append(temp_vector)
temp_vector = []
# 单次外循环结束,并保存数据
sequence_name = "sequences"+ "_" + name
sequence_list = get_sequencelist(training_data)
print(sequence_list)
scaled_vector = scaling_single(training_data)
finished_vector = pre_padding_multiple(scaled_vector)
完整的统计特征提取代码如下:
见博客的代码资源,不需要充值,不要任C币即可下载。
IMF分量统计特征提取
这里进行8层分解得到8个IMF和一个Res.。得到这些数据后,再计算其11个统计特征,就可以得到99维度的原始特征集数据。EMD分解的分量统计特征可以配合上述的统计特征混合使用,我目前只选择这些,有兴趣可以自己去试试。当然EMD也可以换成任意的信号分解的方法。
特征的可视化
这里对工况三的测试集数据分量得到的其中11维统计特征进行归一化处理,其可视化如下:

文章出处登录后可见!