
通常可以使用pytorch中的torch.nn.functional.interpolate()实现插值和上采样。上采样,在深度学习框架中,可以简单理解为任何可以让你的图像变成更高分辨率的技术。

input(Tensor):输入张量
size(int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int]) :输出大小
scale_factor (float or Tuple[float]) : 指定输出为输入的多少倍数。如果输入为tuple,其也要制定为tuple类型
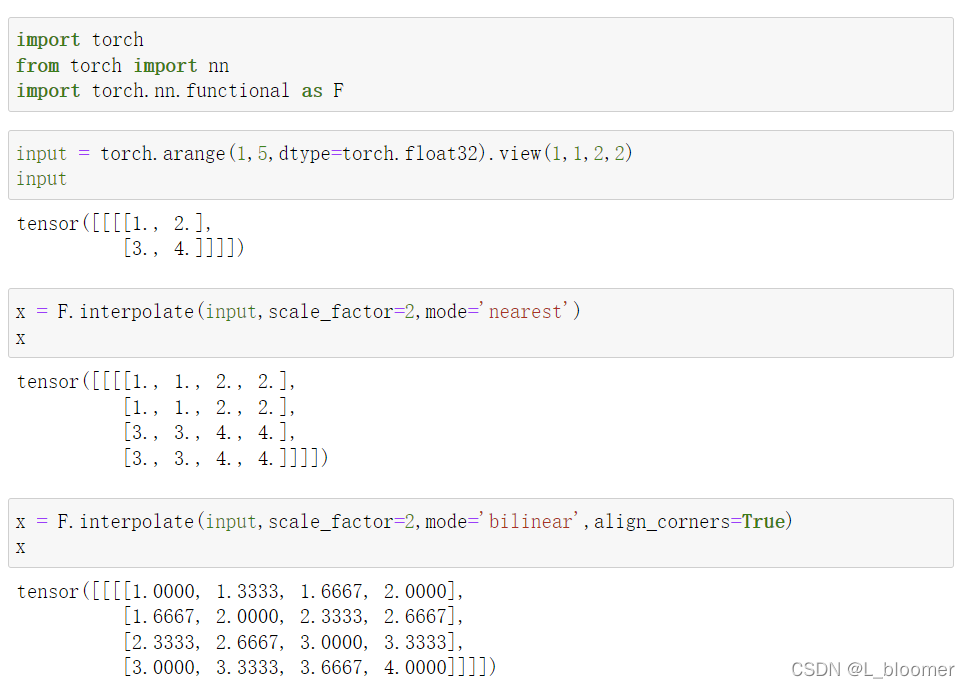
mode (str) : 可使用的上采样算法,有’nearest’, ‘linear’, ‘bilinear’, ‘bicubic’ , ‘trilinear’和’area’. 默认使用’nearest’
注:使用mode='bicubic’时,可能会导致overshoot问题,即它可以为图像生成负值或大于255的值。如果你想在显示图像时减少overshoot问题,可以显式地调用result.clamp(min=0,max=255)。
align_corners (bool, optional):几何上,我们认为输入和输出的像素是正方形,而不是点。如果设置为True,则输入和输出张量由其角像素的中心点对齐,从而保留角像素处的值。如果设置为False,则输入和输出张量由它们的角像素的角点对齐,插值使用边界外值的边值填充;当scale_factor保持不变时,使该操作独立于输入大小。仅当使用的算法为’linear’, ‘bilinear’, 'bilinear’or 'trilinear’时可以使用。默认设置为False
如果 align_corners=True,则对齐 input 和 output 的角点像素(corner pixels),保持在角点像素的值. 只会对 mode=linear, bilinear 和 trilinear 有作用. 默认是 False.
作用:
根据给定的size或scale_factor参数来对输入进行下/上采样
使用的插值算法取决于参数mode的设置
支持目前的temporal(1D, 如向量数据), spatial(2D, 如jpg、png等图像数据)和volumetric(3D, 如点云数据)类型的采样数据作为输入,输入数据的格式为minibatch x channels x [optional depth] x [optional height] x width,具体为:
对于一个temporal输入,期待着3D张量的输入,即minibatch x channels x width
对于一个空间spatial输入,期待着4D张量的输入,即minibatch x channels x height x width
对于体积volumetric输入,期待着5D张量的输入,即minibatch x channels x depth x height x width
举例:
参考:
文章出处登录后可见!