系列文章目录
第一章:Visual Studio 2019 动态链接库DLL建立
第二章:VS动态链接库DLL调试
第三章:VS2019 OpenCV环境配置
第四章:C++部署pytorch模型Libtorch
第五章:C++部署pytorch模型onnxruntime
目录
前言
环境:visual studio 2019;OpenCV4.5.5;pytorch1.8;onnxruntime1.8.1;
一、C++部署pytorch?
pytorch模型在C++部署,上一章是使用pytorch对应版本的Libtorch部署。其实转onnx部署可能更方便,之前语义分割精度相差太大是因为数据预处理的问题,一般图像在输入网络之前需要标准化和转RGB等相关操作。onnx部署的好处是微软中间格式,兼容各种平台,比较方便。如果部署平台有GPU可能用tensorRT会更好。
二、onnxruntime配置
注意事项:注意pt模型转onnx时的版本,onnxruntime版本对应
1.下载onnxruntime
onnxruntime-win-x64-1.8.1链接如下:
2.VS2019配置onnxruntime
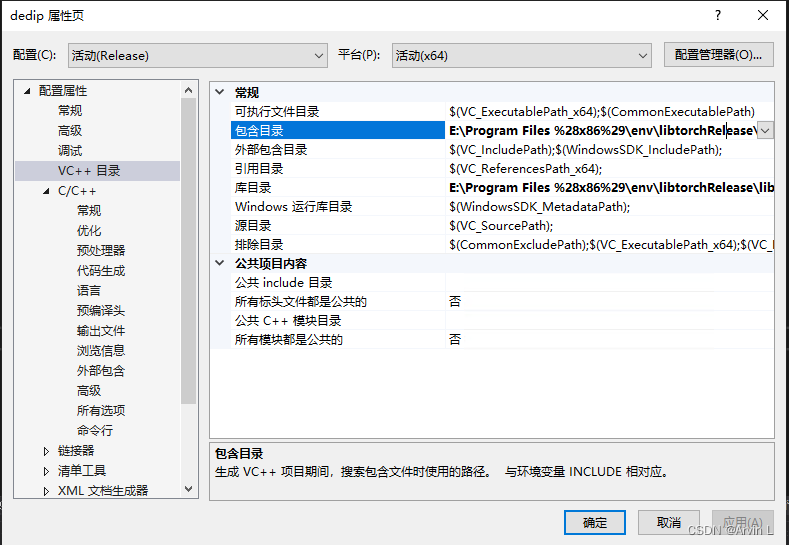
2.1配置VC++目录
首先配置包含目录和库目录,对应opencv一样的方法。
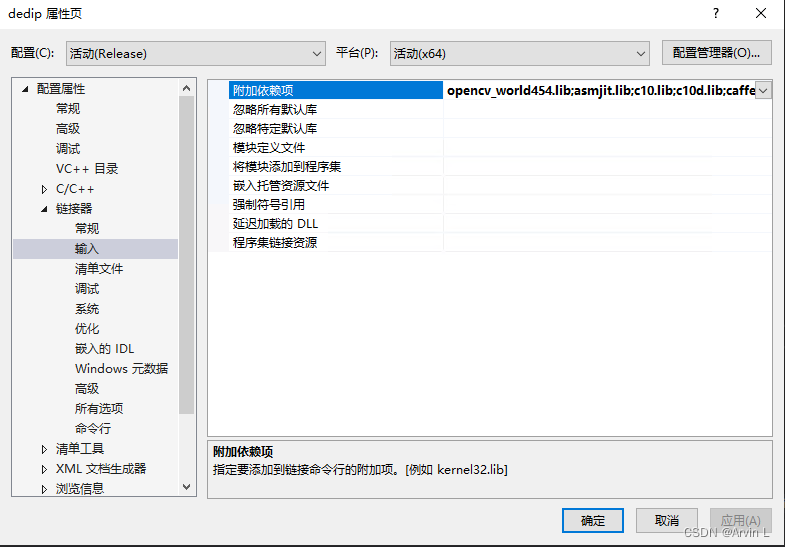
2.2配置链接器
依赖项添加所有lib,cmd中进入lib目录,使用dir /b *.lib>1.txt命令可生成目录,复制使用。
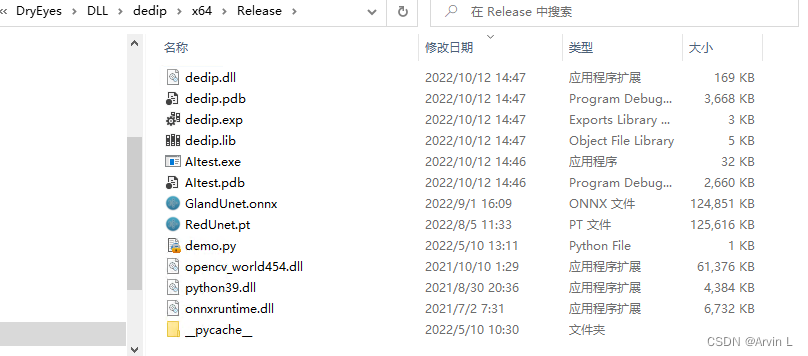
2.3 onnxruntime环境变量配置
把所有DLL复制进Release或者Debug目录。
三、pytorch模型转换为onnx
注意事项:模型输入BCHW,推理模式model.eval(),输出版本opset_version=11
import torch
x = torch.randn(1, 3, 512, 512, device="cpu")
model = torch.load('best_model.pth', map_location=torch.device('cpu'))
model.eval()
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model, x, "GlandUnet.onnx", verbose=True, input_names=input_names, output_names=output_names, opset_version=11)四、C++中onnxruntime的使用
注意事项:1,一定要注意图像输入模型之前的预处理,是否标准化,是否转RGB
2,C++中onnxruntime推理输出为数组的首地址,可以用指针取出生成Mat
/****************************************
@brief : 分割onnxruntime
@input : 图像
@output : 掩膜
*****************************************/
void SegmentAIONNX(Mat& imgSrc, int width, int height)
{
模型信息/
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "OnnxModel");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1);
#ifdef _WIN32
const wchar_t* model_path = L"GlandUnet.onnx";
#else
const char* model_path = "RedUnet.onnx";
#endif
Ort::Session session(env, model_path, session_options);
Ort::AllocatorWithDefaultOptions allocator;
size_t num_input_nodes = session.GetInputCount(); //batchsize
size_t num_output_nodes = session.GetOutputCount();
const char* input_name = session.GetInputName(0, allocator);
const char* output_name = session.GetOutputName(0, allocator);
auto input_dims = session.GetInputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape(); //输入输出维度
auto output_dims = session.GetOutputTypeInfo(0).GetTensorTypeAndShapeInfo().GetShape();
std::vector<const char*> input_names{ input_name };
std::vector<const char*> output_names = { output_name };
输入处理//
Mat imgBGR = imgSrc; //输入图片预处理
Mat imgBGRresize;
resize(imgBGR, imgBGRresize, Size(input_dims[3], input_dims[2]), InterpolationFlags::INTER_CUBIC);
Mat imgRGBresize = imgBGRresize;
//cvtColor(imgBGRresize, imgRGBresize, COLOR_BGR2RGB); //smp未转RGB
Mat resize_img;
imgRGBresize.convertTo(resize_img, CV_32F, 1.0 / 255); //divided by 255转float
cv::Mat channels[3]; //分离通道进行HWC->CHW
cv::split(resize_img, channels);
std::vector<float> inputTensorValues;
float mean[] = { 0.485f, 0.456f, 0.406f }; //
float std_val[] = { 0.229f, 0.224f, 0.225f };
for (int i = 0; i < resize_img.channels(); i++) //标准化ImageNet
{
channels[i] -= mean[i]; // mean均值
channels[i] /= std_val[i]; // std方差
}
for (int i = 0; i < resize_img.channels(); i++) //HWC->CHW
{
std::vector<float> data = std::vector<float>(channels[i].reshape(1, resize_img.cols * resize_img.rows));
inputTensorValues.insert(inputTensorValues.end(), data.begin(), data.end());
}
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
vector<Ort::Value> inputTensors;
inputTensors.push_back(Ort::Value::CreateTensor<float>(memoryInfo, inputTensorValues.data(), inputTensorValues.size(), input_dims.data(), input_dims.size()));
//clock_t startTime, endTime; //计算推理时间
//startTime = clock();
auto outputTensor = session.Run(Ort::RunOptions{ nullptr }, input_names.data(), inputTensors.data(), 1, output_names.data(), 1); // 开始推理
//endTime = clock();
打印模型信息/
//printf("Using Onnxruntime C++ API\n");
//printf("Number of inputs = %zu\n", num_input_nodes);
//printf("Number of output = %zu\n", num_output_nodes);
//std::cout << "input_name:" << input_name << std::endl;
//std::cout << "output_name: " << output_name << std::endl;
//std::cout << "input_dims:" << input_dims[0] << input_dims[1] << input_dims[2] << input_dims[3] << std::endl;
//std::cout << "output_dims:" << output_dims[0] << output_dims[1] << output_dims[2] << output_dims[3] << std::endl;
//std::cout << "The run time is:" << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << std::endl;
//输出处理//
float* mask_ptr = outputTensor[0].GetTensorMutableData<float>(); //outtensor首地址
vector< unsigned char >results(512 * 512);
for (int i = 0; i < 512 * 512; i++)
{
if (mask_ptr[i] >= 0.5)
{
results[i] = 0;
}
else
{
results[i] = 255;
}
}
unsigned char* ptr = &results[0];
Mat mask = Mat(output_dims[2], output_dims[3], CV_8U, ptr);
resize(mask, imgSrc, Size(imgBGR.cols, imgBGR.rows));
//原图展示分割结果//
//cvtColor(imgSrc, imgSrc, COLOR_GRAY2BGR);
//Mat imgAdd;
//addWeighted(imgBGR, 1, imgSrc, 0.3, 0, imgAdd);
}五、python中onnxruntime的使用
# -*- coding:utf-8 -*-
import cv2
import numpy as np
import onnxruntime as ort
import imgviz
import time
class_names = ['_background_', 'conjunctiva_area']
### 定义一些数据前后处理的工具
def preprocess(input_data):
# convert the input data into the float32 input
img_data = input_data.astype('float32')
# normalize
mean_vec = np.array([0.485, 0.456, 0.406])
stddev_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(img_data.shape).astype('float32')
for i in range(img_data.shape[0]):
norm_img_data[i, :, :] = (img_data[i, :, :] / 255 - mean_vec[i]) / stddev_vec[i]
# add batch channel
norm_img_data = norm_img_data.reshape(1, 3, 512, 512).astype('float32')
return norm_img_data
def softmax(x):
x = x.reshape(-1)
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def postprocess(result):
return softmax(np.array(result)).tolist()
session = ort.InferenceSession('GlandUnet.onnx')
img0 = cv2.imread('test.bmp')
h0, w0 = img0.shape[0:2]
img = cv2.cvtColor(img0, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, [512, 512])
image_data = np.array(img).transpose(2, 0, 1) # HWC->CHW
input_data = preprocess(image_data)
time_start = time.time() # 记录开始时间
raw_result = session.run([], {'input': input_data})
time_end = time.time() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print(time_sum)
# label_result = np.argmax(raw_result, dim=1) # 缺argmax
# out = np.squeeze(raw_result)
# result_img = np.array(out, dtype=np.uint8)
# result_img = cv2.resize(result_img, (w0, h0))
out1 = raw_result[0][0]
cv2.imshow('2', out1[1])
cv2.waitKey(0)参考文献
https://onnxruntime.ai/
https://github.com/leimao/ONNX-Runtime-Inference/blob/main/src/inference.cpp
神经网络语义分割模型C++部署(VS2019+ONNXRuntime+OpenCV)_Shijunfeng00的博客-CSDN博客
文章出处登录后可见!