测试结果
测试平台:
显卡:影驰金属大师4090
cpu:i7 12700k

测试方法
测试
1.矩阵计算速度
transformer的核心操作是矩阵乘法,通过测试矩阵计算的tflops可以得到硬件的计算上限。
matmul_tflops = defaultdict(lambda: {})
for n in [128, 512, 2048, 8192]: #四种大小的矩阵
for dtype in (torch.float32, torch.float16):
a = torch.randn(n, n, dtype=dtype).cuda()
b = torch.randn(n, n, dtype=dtype).cuda()
t = walltime('a @ b', var_dict(a, b)) #计算两个矩阵相乘的时间
matmul_tflops[f'n={n}'][dtype] = 2*n**3 / t / 1e12 #计算TFLOPS:两个n*n的矩阵相乘会继续2*n**3次计算,再除以计算的时间,和1e12(1tplops=1e12),得到tflops
del a, b
pd.DataFrame(matmul_tflops)结果:
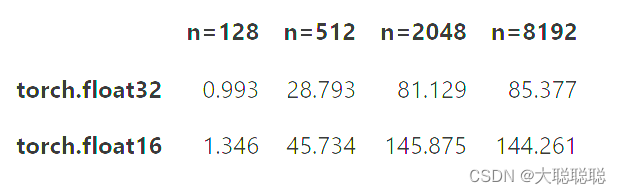
对比:

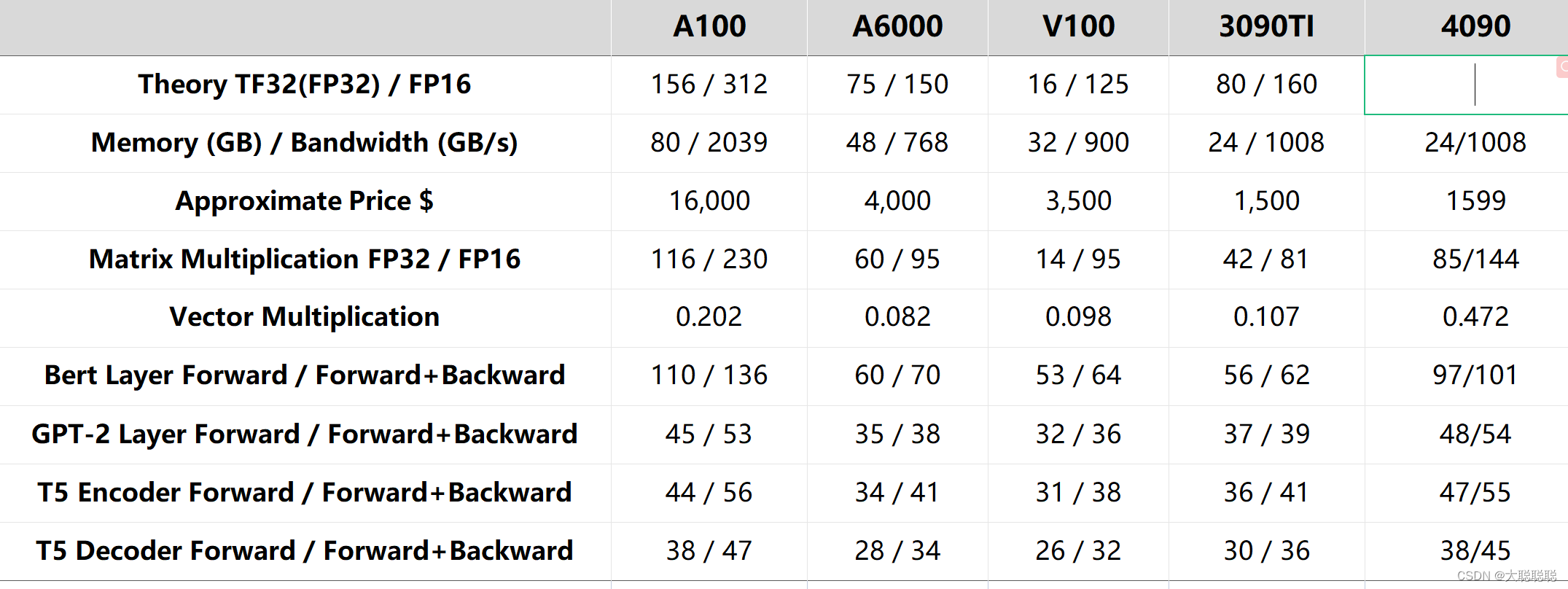
可以得出单精度4090tflops为85TFLOPS是3090的两倍,半精度下是为144TFLPOPS是3090的1.77倍,半精度下因为Tensor Cores的原因,性能相比单精度有很大的提升。
2.向量乘法速度、带宽
深度学习训练中,带宽会限制你的训练速度。
网络训练过程中的激活函数会做的事情计算步骤类似向量乘法,这种操作会很慢,而减慢你的训练速度。
vector = defaultdict(lambda: {})
for n in [1024*64, 1024*256, 1024*1024, 1024*1024*4]:
a = torch.randn(n).cuda()
t = walltime('a * 1.2', var_dict(a)) #进行向量乘法操作
vector[n]['TFLOPS'] = n / t / 1e12 #计算TFPLOS
vector[n]['GB/s'] = 8 * n / t / 1e9 #计算带宽:进行一个向量乘法需要将数据从gpu拿得到计算单元(4byte),再从计算单元再拿回来(4byte),所以是8*n
pd.DataFrame(vector)结果:
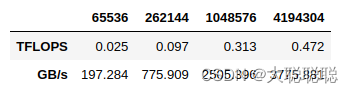
可以看出TFLOPS仅为0.462
对比:

可以看出4090向量乘法操作大约是3090ti的四倍。
3.Bert Layer Forward / Forward+Backward速度
def layer_benchmark(layer, hidden_size, seq_lens, batch_sizes, cross_attention=False):
h = hidden_size
results = defaultdict(lambda: {})
encoder_state = 'encoder_hidden_states=X' if cross_attention else ''
for s in seq_lens:
for b in batch_sizes:
ffn = 16*b*s*h*h / 1e12 #计算一个ffn层的TFLOPS
atten = (4*b*h*s*s + 8*b*s*h*h) / 1e12 #计算一个attention层的TFLOPS
forward = ffn + (2 if cross_attention else 1) * atten
X = torch.randn(b, s, h).half().cuda()
results[f'batch={b}'][f'fwd seq_len={s}'] = forward / walltime(
f'layer(X, {encoder_state})', var_dict(layer, X))
results[f'batch={b}'][f'fwd+bwd seq_len={s}'] = 3 * forward / walltime(
f'layer(X, {encoder_state})[0].sum().backward()', var_dict(layer, X))
return pd.DataFrame(results)总结:
矩阵计算的硬件的计算上限来说,单精度4090为是3090ti的两倍,半精度下是3090ti的1.77倍。4090bertForward操作的性能是 3090ti的1.79倍,Forward+Backward是3090ti的1.63倍。
因为内存带宽、Nvidia提供的矩阵库的效率、中间的缓存的的大小,我们日常训练当中一般不可能达到理论的速度,而这些都是我们难以解决的,我们能做的是提高批量的大小、将多个按元素计算的操作合并成一个单个操作用CUDA重新实现一次。
文章出处登录后可见!
已经登录?立即刷新