一、Controlable Text Generation(CTG)定义与应用
1. 什么是CTG
Controlable Text Generation,可控制的文本生成,就是能够在传统的文本生成的基础上,增加对生成文本一些属性、风格、关键信息等等的控制,从而使得生成的文本符合我们的某种预期。如果给一个明确的定义的话,文中引用了另一篇更早的综述的定义:
A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models[1]
论文中给出了两个简单的例子: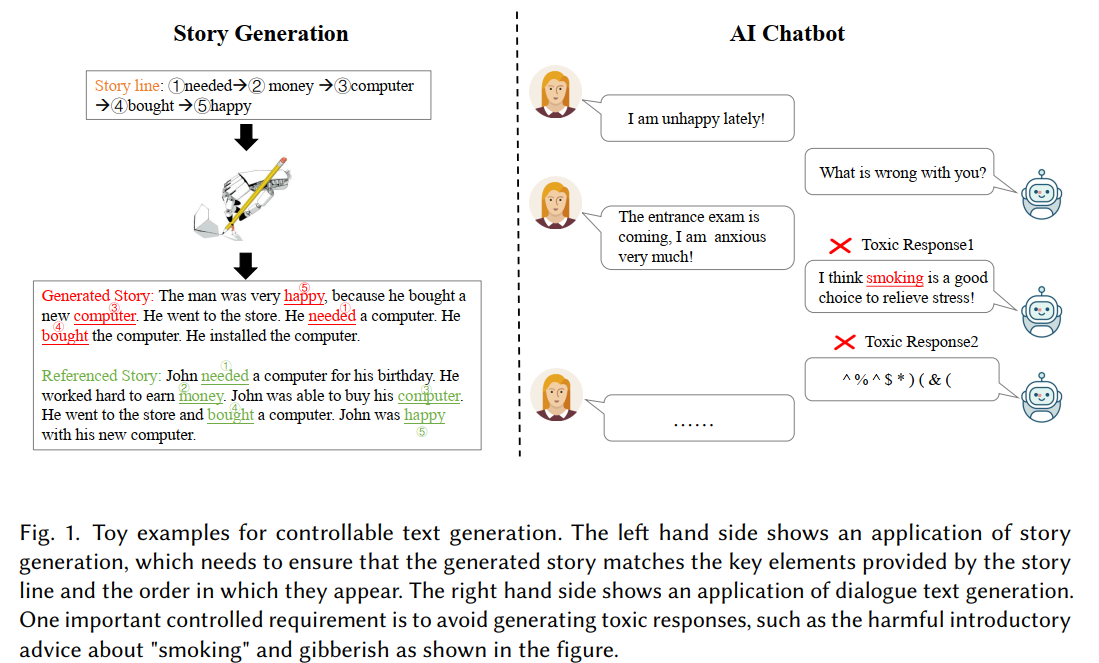
第一个例子就是给定一个故事线,要求模型按照这样的思路去生成。第二个例子是关于传统人机对话中如果机器生成文本时不受控制可能带来的问题,比如会给出有害的建议,甚至说脏话,这个时候就需要我们在模型生成的时候加以控制。
作者对CTG总结了这么一个Input-Process-Output的总体框架,简称IPO:
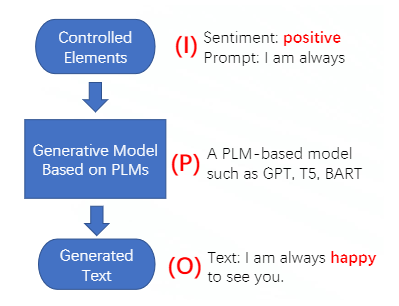
跟传统NLG的区别就在于我们会在输入的时候加入某些控制因素,从而让最终的输出满足某种条件。
2. CTG的应用场景
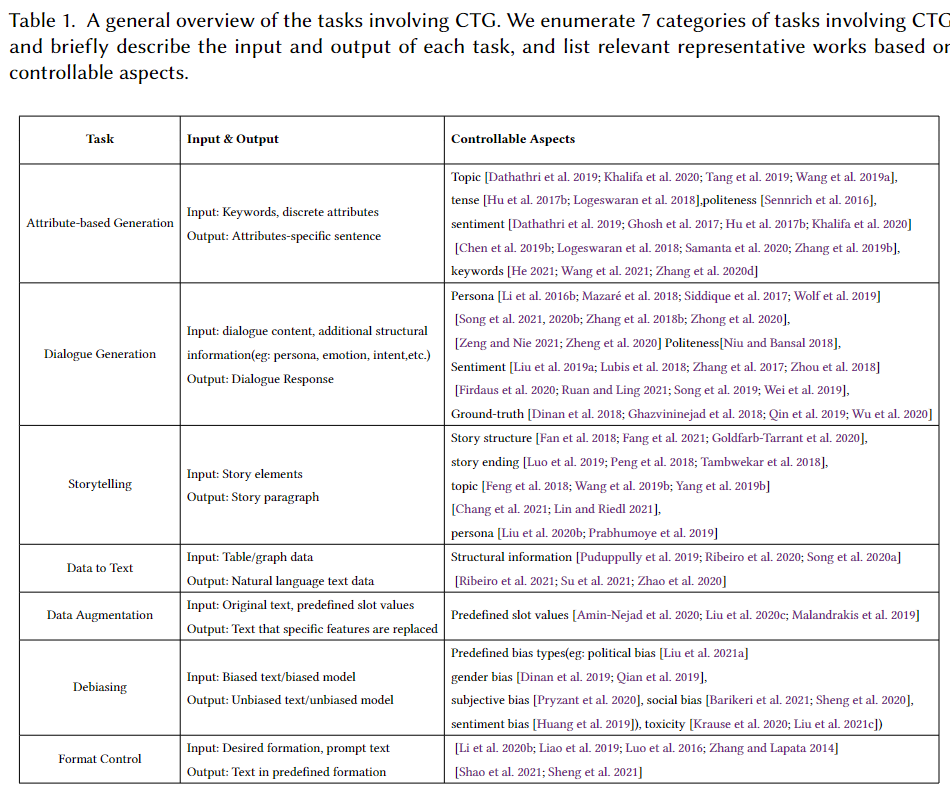
CTG可以应用的场景非常广泛:
Attribute-based Generation,基于某种属性的自然语言生成,比如生成特定情感/口吻/风格的文本
Dialogue Generation,对话系统对NLG有更高的要求,因此CTG的应用就不言而喻了
Storytelling,用CTG来辅助文学创作,想想就很爽,而传统的NLG,基本给了开头你就无法控制了
Data to Text,使用一些结构化数据(table,graph)来生成自然语言,可用于给定每天的天气数据,来自动生成天气播报,或者把老板看不懂的表格数据用CTG技术翻译成人话给他听
Data Augmentation,使用CTG可以把已有的文本的某些信息给重新生成,变成我们想要的属性
Debiasing,这也非常重要,可以帮助我们把带有某些偏见的文本转化成无偏见的文本,让机器也符合伦理道德
Format Control,风格、格式的转换,比如中国古诗词就有明确的格式,这就需要在生成的时候加以控制
作者很详细地把这些方面总结在下表中:
3. CTG使用的主要PLM结构
本文主要是调查基于Pre-trained Language Model(PLM)的CTG方法,所以了解主要的PLM也很重要:
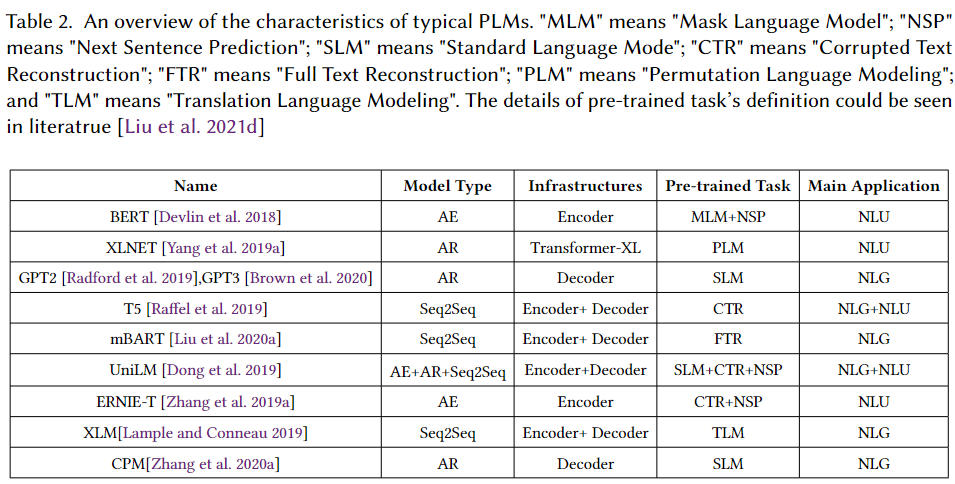
上面我们主要关注一下各种PLM针对语言的生成,设计使用的何种预训练任务。首先我们最熟悉的BERT,主要使用的是MLM,所以使用BERT的话你只能做完形填空。而GPT家族则使用的经典的causal LM,本文称为SLM,因此可以不断生成流利的句子。T5/UniLM/ERINE等都使用了CTR(corrupted text reconstruction)任务,mask掉的是一个span,可以是连续的很多词,然后让模型学习去复原,因此比BERT的MLM能力更强。而mBART则更是使用了FTR(full text reconstruction),让模型的复原能力更进一步。
二、CTG的不同方法流派
论文把目前基于PLM的CTG的各种方法流派做了个总结,上图看得十分清晰。我把它们形象地分为三派:
改良派:在已有PLM的基础上继续预训练
革命派:另起炉灶,重新训练一个大型预训练模型
保守派:连PLM都不想动,直接在PLM的输出上做后处理
1. 改良派——Fine-tuning
改良派,实际上就是沿用了PLM最经典的使用方法——Fine-tuning,虽然原始的PLM在训练的时候,并没有对某些属性、特点、要素进行控制,但是PLM预训练中学习的大规模知识是很有用的,所以我们使用特定的语料,让PLM进一步去学习我们希望的某种控制效果,就可以实现CTG的目的。
而Finetuning中又分为三种方式:
Adapted Module方式,通过额外添加一个控制模块,用于添加属性控制,然后连同PLM一起进行训练。代表方法包括 Auxiliary Tuning[2],DialGPT[3]。
Prompt方式,包括prompt Learning、prompt tuning[4]等方法,实际上基于prompt的方法,本身就是对PLM的生成加入了额外的控制,如果使用有监督的风格、属性数据集进行训练,就可以直接得到基于prompt的CTG模型。也有更新的工作Inverse Prompt[5],用模型生成的句子来反过来去预测代表风格、主题等的prompt,从而让prompt对文本生成的控制力更强。
基于强化学习RL的方法。
总之,这些基于finetuning的方法,基本都要求我们有一个下游任务的有监督数据集,从而帮助我们学习某种控制性,比如你希望控制生成文本的情感属性,那么就需要你有情感分类的数据集,让模型去学习[指定情感]——>[该情感的文本]的映射。
2. 改革派——Retrain/Refactor
改革派的目标都更加宏大,单纯的Finetuning在具体任务上小打小闹一下是可以的,但如果想有一个更加通用的CTG,还是得预训练,或者修改PLM的结构。
代表性方法之一是CTRL[6],由Salesforce团队带来,背后是Richard Socher大佬。CTRL收集了140GB的数据,涵盖了很多个domain的语料(百科、reddit、影评、新闻、翻译、问答…),每个domain都设置有一个control code,从而训练一个大型的包含1.63B参数量的conditional language model:
具体训练上,CTRL使用的是经典的Transformer结构,那些control code是预定义好的,直接插入在sequence的开头。更多训练细节见原文。CTRL取得了比较明显的控制生成效果:

甚至可以编造一个URL作为control code就可以生成一段新闻:

另一个由南洋理工大学带来的工作Content-Conditioner (CoCon)[10]既改造了GPT模型,并在250K个样本上进行了对GPT进行了微调。CoCon跟CTRL和PPLM的区别在于:

以CTRL为代表的方法只能从一个总体的层面对生成文本增加限制,比如某种风格主题,但无法对具体内容进行精细控制,CoCon则是直接以原文中的部分内容作为condition,来预测下文,CoCon的结构图如下:
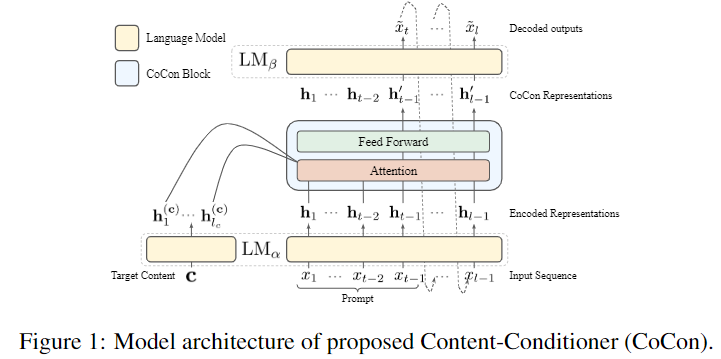
然后为了训练这个模型,作者设计了多种自监督的loss:Self Reconstruction Loss, Null Content Loss, Cycle ReconstructionLoss, Adversarial Loss. 核心思想就是使用文本的一部分作为condition,让模型对剩余部分进行复原,具体方法如下图:
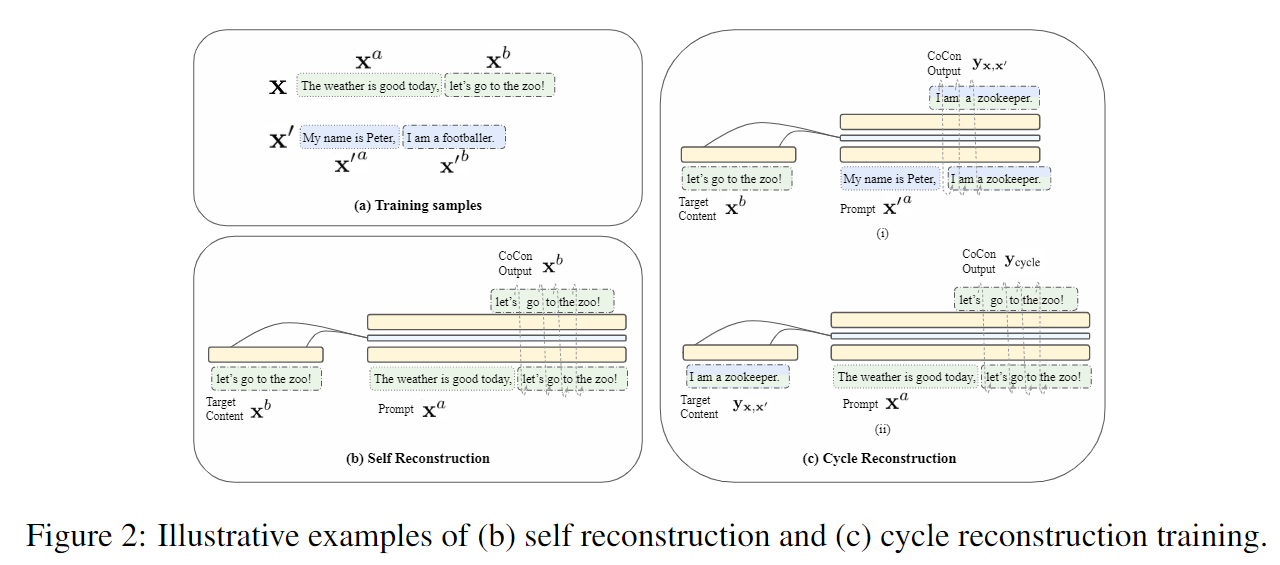
最终也取得了比较优秀的控制效果,并且支持多个控制:

上面列举的CTRL和CoCon的对NLG添加的实际上是比较soft的限制,并不强制要求模型一定要输出什么元素,而有一些工作则会使用hard的限制,要求模型必须输出给定的某些关键词。
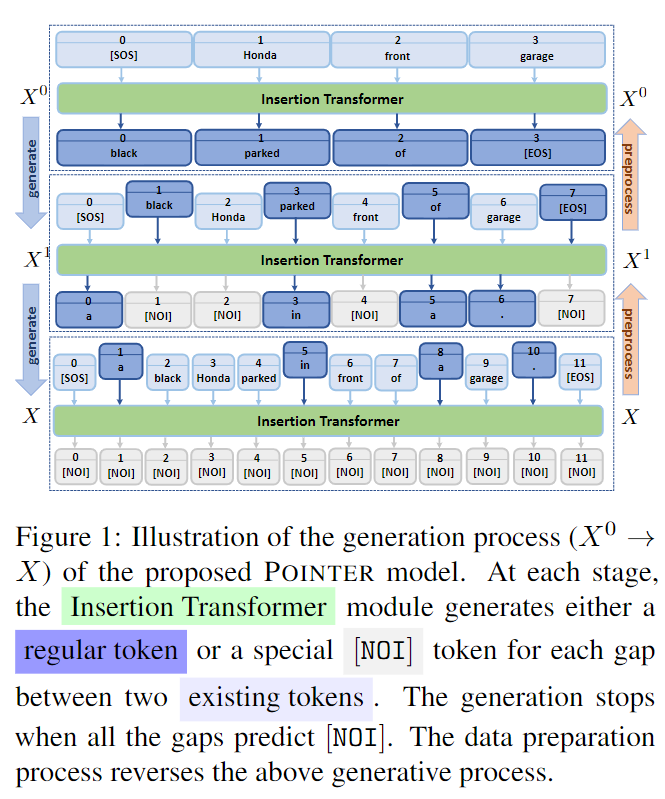
代表性工作之一是POINTER[7],出自MSR。POINTER的主要目的是训练根据指定词汇然后生成包含这些词汇的模型,采用的是一种基于插入的、渐进生成的方法:
POINTER的生成是一种迭代式地生成,先生成给定的关键词,然后每一轮都按照重要性不断插入新的词,直到把句子给补齐。POINTER中使用的一种Transformer结构叫做Insertion Transformer[8],下图则展示了POINTER是如何渐进生成的:
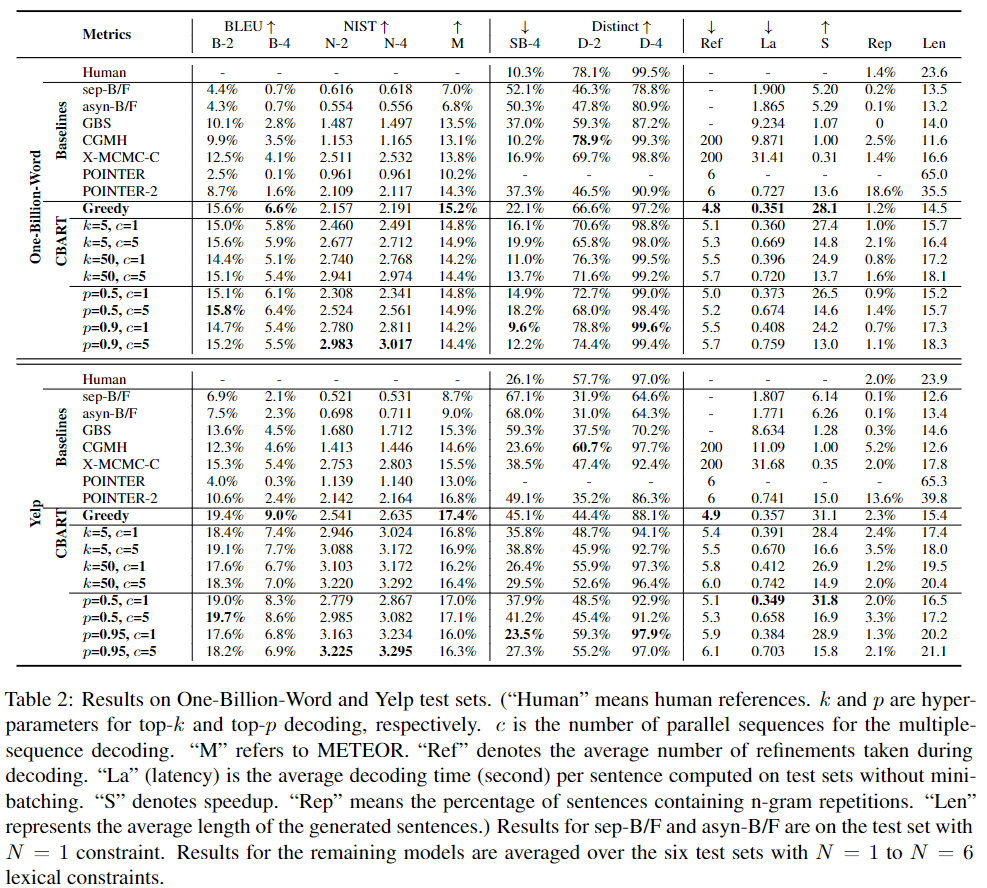
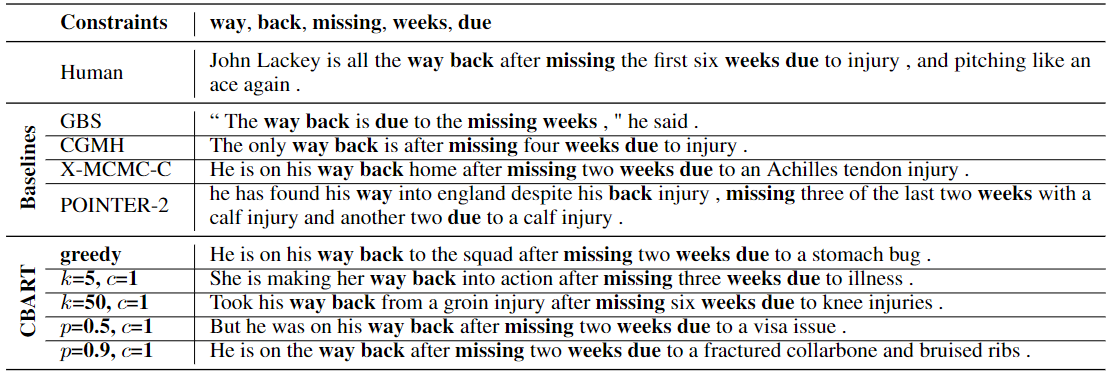
类似的一个受限生成的工作是Constrained BART (CBART)[9],来自香港大学,对BART进行了改造,通过在encoder上面添加一个token-level classifier来指导decoder在生成的时候应该进行replace还是insert,最终取得了比POINTER更好的效果:
3. 保守派——Post-Process
保守派则认为,干嘛要这么麻烦,直接后处理不就完事儿了。
最知名的工作,要数来自Uber AI的Plug and Play Language Models (PPLM)[11]了。
PPLM不希望去训练PLM,而是通过额外的一个attribute model来对PLM的输出加以修正,从而符合某种预期。这里的attribute model,既可以是一个bag of words来代表某个topic,也可以是一个训练好的小模型来对某个topic进行打分,然后通过这个attribute model向PLM的hidden states传递梯度,从而对hidden states进行一定的修正,然后PLM的输出就会往我们希望的topic倾斜了。

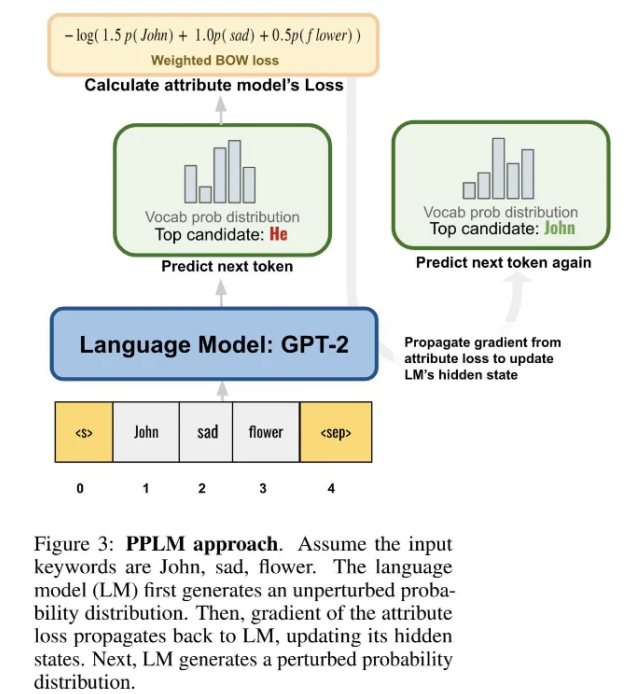
基于PPLM,Stanford CS224N的一个project作业中,某学生提出了Ranked Keywords to Story Generation,该工作的目标是给定一个排序的关键词,让模型能够按照重要性在生成句子的时候把这些关键词都包括在内,具体则是在PPLM的基础上进行了改进:
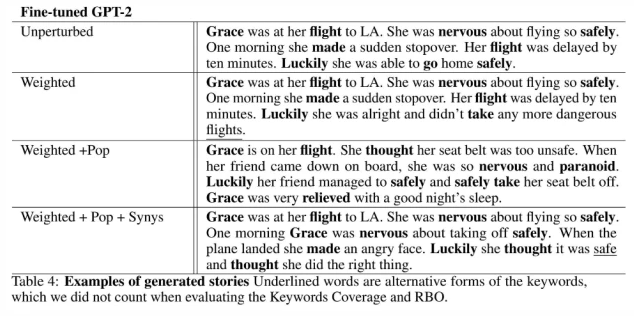
具体方式是构造这样的语料,然后对GPT-2进行finetune,然后再利用PPLM的思想,使用改进的BoW的方法来控制生成,也得到了比较好的效果:
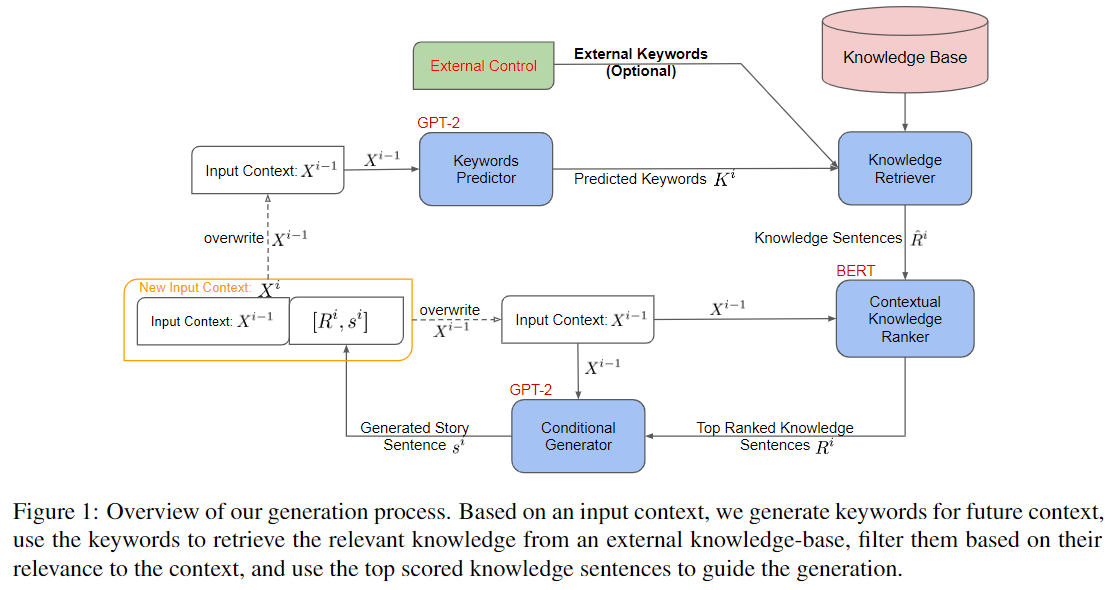
MEGATRON-CNTRL[13]则选择利用外部知识库来辅助生成,给定一个context,MEGATRON-CNTRL会首先使用一个predictor生成一批关键词,然后通过一个retriever从知识库中找到跟这些关键词匹配的句子,然后通过一个ranker进行筛选,最后再输入PLM进行句子的生成:
还有工作比如PAIR[14]则是先生成一个包含关键词和位置信息的模板,然后对模板进行填空,从而进行控制性生成;GeDi[15]则是训练一个小型的discriminator来引导PLM的生成。
终于把三个派别的代表方法都介绍了一遍,Survey中总结了这个表,方便大家查阅:

References:
[1] A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models
[2] Technical report: Auxiliary tuning and its application to conditional text generation (2020)
[3] DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation (ACL-20)
[4] The Power of Scale for Parameter-Efficient Prompt Tuning (EMNLP-21)
[5] Controllable Generation from Pre-trained Language Models via Inverse Prompting (KDD-21)
[6] CTRL: A Conditional Transformer Language Model for Controllable Generation (2019)
[7] POINTER: Constrained Text Generation via Insertion-based Generative Pre-training (EMNLP-20)
[8] Insertion Transformer: Flexible Sequence Generation via Insertion Operations (2019)
[9] Parallel Refinements for Lexically Constrained Text Generation with BART (EMNLP-21)
[10] CoCon: A Self-Supervised Approach for Controlled Text Generation (ICLR-21)
[11] Plug and Play Language Models: A Simple Approach to Controlled Text Generation (ICLR-20)
[12] Ranked Keywords to Story Generation (2021, Stanford Student Project)
[13] MEGATRON-CNTRL: Controllable Story Generation with External Knowledge Using Large-Scale Language Models (EMNLP-20)
[14] PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long Text Generation (EMNLP-20)
[15] GeDi: Generative Discriminator Guided Sequence Generation (EMNLP-21-findings)
文章出处登录后可见!