作者:思宏、易相、乐慷、染冉、常龙
随着预训练模型的不断发展,深度学习的泛化和迁移能力得到了显著提升。这种能力不仅体现在同一任务的不同领域的数据上,还体现在模型对不同任务的统一解决能力上。本文将为大家介绍一种基于Prompt的通用信息抽取框架,使用相同的思想框架集来解决不同情况下的不同任务。
在CCKS2022通用信息抽取竞赛(业界首个通用的信息抽取评测)中,共有1049人报名,共计152支队伍参加,达摩院NLP应用算法团队在A榜和B榜中都取得了第一名,获得冠军和创新奖,下面本文将为大家分享CCKS2022冠军方案。
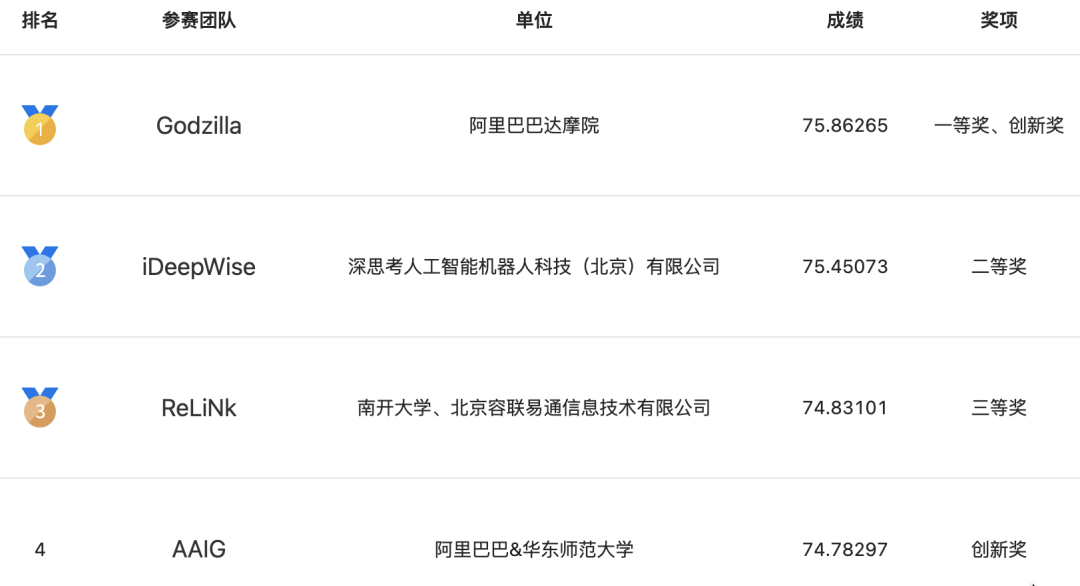
图:CCKS2022 通用信息抽取竞赛获奖榜单
一、背景介绍
多年来,随着预训练模型的不断发展,深度学习的泛化和迁移能力得到了显著提升。这种能力不仅体现在同一任务的不同领域的数据上,还体现在模型对不同任务的统一解决能力上。
信息提取是从非结构化文本中自动检索与选定主题相关的特定信息。一般来说,很多NLP任务都可以归类为信息抽取任务,例如命名实体抽取(NER)、关系抽取(RE)、事件抽取(EE)等。考虑到信息抽取任务的复杂性,经常使用不同的模型来进行信息抽取,处理不同的任务,即使这些任务之间有很多相似之处。为了缓解这一痛点,Y Lu [1] 提出了基于预训练机制和提示学习的统一文本到结构生成框架,即UIE。实验表明,UIE在有监督和低资源场景下均达到了SOTA。
Seq2Seq方案是一个自由度很高的模型,理论上所有的NLP问题都可以用这个方案解决。但是,这种自由度也导致了模型在实际应用中可能会输出一些意想不到的结果。为了增强UIE的可用性,基于提示学习和机器阅读理解提出了另一个版本的UIE [2]。根据我们的实验,我们发现这个版本的UIE确实具有更强的零样本学习能力,但同时也带来了推理时间成本的增加。
受上述工作的启发,我们提出了一种基于提示的UIE框架,使用相同的思想框架集来解决不同情况下的不同任务。
二、任务介绍
本次竞赛不局限于传统的单任务信息抽取的评测范式,而是将多种不同的信息抽取任务用统一的通用框架进行描述,着重考察相关技术方法在面对新的、未知的信息抽取任务与范式时的适应与迁移能力,从而满足当下信息抽取领域快速迭代、快速迁移的实际需求,更贴近实际业务应用。
评测的具体任务由以下两类组成:
Seen Schema 可根据平台数据构建模型,该赛道主要评测现有技术基于标记数据构建模型的能力。包含以下六个领域的抽取任务:
-
人生信息:抽取(关系类型,主体span,客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
-
机构信息:抽取(关系类型,主体span,客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
-
金融信息:抽取(事件类型,论元角色,论元span)事件论元三元组
-
体育竞赛:抽取(事件类型,论元角色,论元span)事件论元三元组
-
影视情感:抽取(情感极性,意见对象span,情感表达span)情感三元组
-
灾害意外:抽取(事件类型,论元角色,论元span)事件论元三元组
Unseen Schema 仅提供少量的验证数据,用与参赛者进行抽取需求确认和模型验证,该赛道主要评测现有技术面向新的抽取需求的迁移能力。包含以下四个领域的抽取任务:
-
金融舆情:抽取(事件类型,论元角色,论元span)事件论元三元组
-
金融监管:抽取(关系类型, 主体span, 客体span)关系三元组
-
医患对话:抽取(关系类型, 主体span, 客体span)关系三元组、抽取(实体提及span,实体类型)实体二元组
-
流调信息:抽取(事件类型,论元角色,论元span)事件论元三元组
A榜只考察Seen Schema中六个领域的抽取任务,而最终的B榜将考察Seen Schema + Unseen Schema一共10个领域的抽取任务。
三、技术方案
3.1 统一的抽取框架
当我们根据任务类型,具体地对这次的UIE任务进行归类分析,我们会发现,这次的评测主要由一下四种类型的任务:
-
NER:文本 -> (实体类型,实体span)两元组
-
Relation Extraction:文本 -> (主体span,关系类型,客体span)三元组
-
Event Extraction:文本 -> (事件类型,论元角色,论元span)三元组
-
Opinion Extraction:文本 ->(意见对象span,情感表达span,情感极性)三元组
同时,这次任务包含了两类场景,分别是:
-
SeenSchema:有充分训练数据(Rich-Resource)
-
UnseenSchema:仅有少量训练数据 (Low-Resource)
我们可以发现,无论是哪一种场景下的哪一种任务,都可以转化为:
-
输入:文本+Schema;
-
输出:若干「抽取片段」和「分类类型」组成的多元组的集合;
因此,为了更灵活地解决不同的信息抽取问题,我们将信息抽取任务所需的模型拆分为三个模块,包括抽取模块(Extraction Module)、分类模块(Classification Module)和组合模块(Combination Module)。
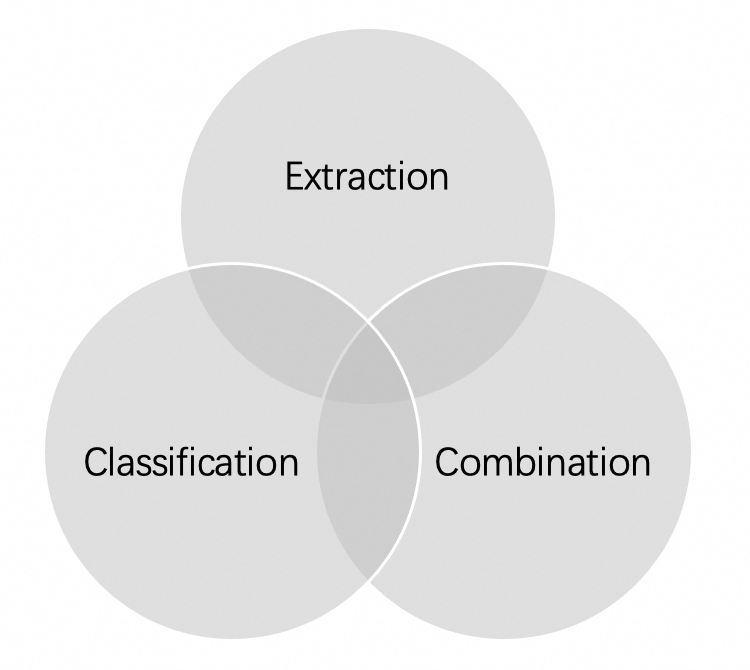
接下来将会具体介绍我们使用的模块:
3.1.1 Extraction Module
最常用的抽取span方法是基于BIO模式和CRF的序列标注模型。这种方案的优点是可以很好地利用标签之间的依赖关系,但是CRF的维特比解码比较耗时,且无法解决嵌套问题。因此,我们选择指针网络方法来解决span抽取的问题,不仅可以解决嵌套问题,还可以根据数据的分布动态调整阈值,以平衡精度和召回率。
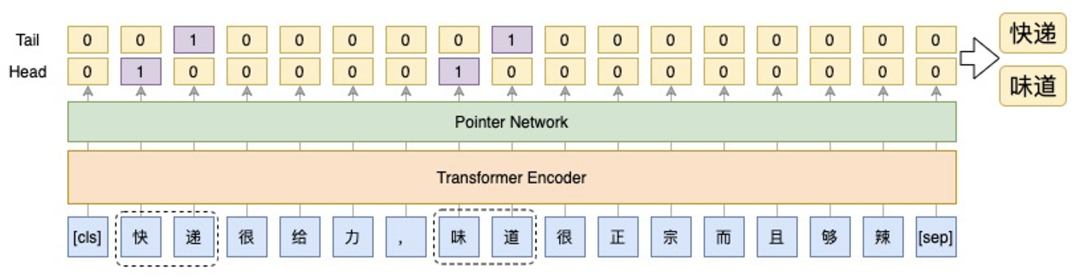
Fig. 1. The extraction module used in our framework
3.1.2 Classification Module
我们的框架包括两种分类方法:常规分类和基于匹配的分类。在训练数据充足的情况下,我们将使用常规的分类方法,而在资源不足的情况下,我们将使用基于匹配的方法,以更好地利用预训练模型的迁移能力。
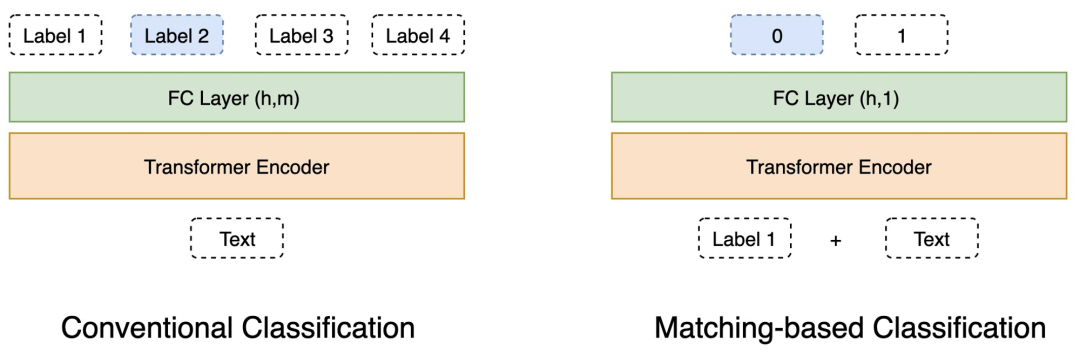
Fig. 2. The illustration of two methods of classification, in which h means the hidden size of the encoder and m means the number of labels.
3.1.3 Combination Module
对于复杂的信息抽取任务,最重要的是如何对提取和分类模块的输出进行组合。在我们的框架中,我们实现了基于提示和多任务学习的每个子模块之间的组合。将模型上一步预测的结果与原文显式连接,即提示学习的方法,是最通用的组合方案。它基本上可以用于所有信息抽取子任务的组合,也可以更好地利用预训练模型的编码能力。
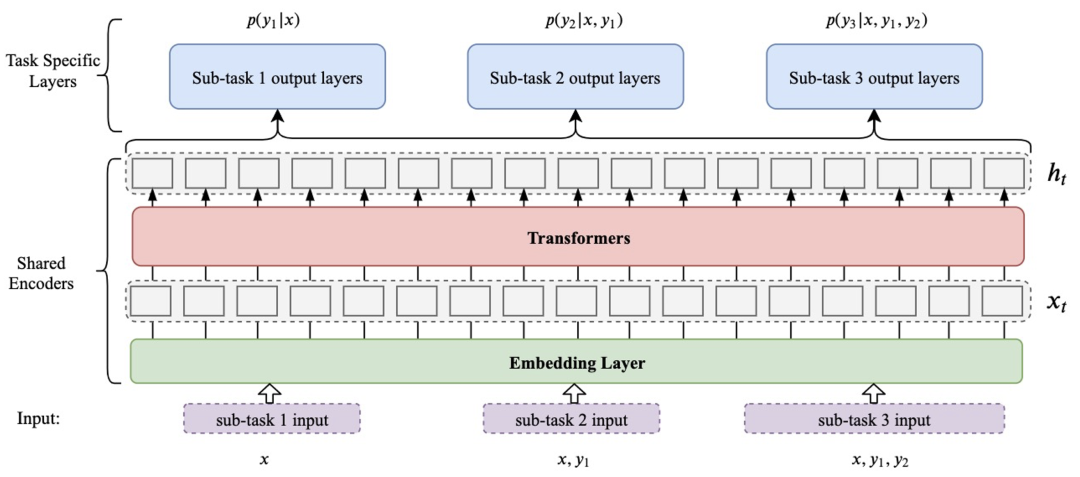
Fig. 3. The illustration of combination module
3.2 解决方案
在本节中,我们将介绍如何根据我们的框架组合三个子模块来解决实践中的不同信息抽取问题。
3.2.1 Named Entity Extraction Task
NER是信息抽取任务中相对简单的任务。首先,我们使用预训练模型作为编码器。然后对于每种类型的实体,我们使用相应的指针网络来提取span。
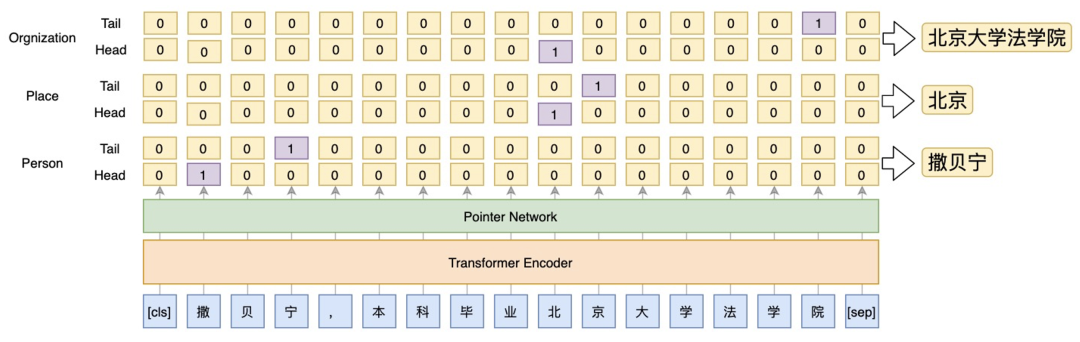
Fig. 4. The model oriented to NER Task based on our framework
3.2.2 Relation Extraction Task
我们将关系抽取任务分为三个步骤,主体抽取、客体抽取和关系分类,分别对应我们框架中的两个抽取模块和一个常规分类模块。具体来说,首先将输入句子输入主体提取模块,提取所有主体。然后将提取的主体与句子连接起来,并将它们输入客体提取模块以提取所有客体,这样我们就可以得到(主体,客体)的映射。最后,我们将(主体,客体)二元组与句子连接起来,并将它们输入关系分类模块以获得关系三元组。
3.2.3 Event Role Extraction Task
根据章节2中介绍的评测指标,对于事件抽取任务,主办方并没有对触发词进行评测,而是仅仅考察(事件类型,论元角色,论元span)三元组。因此,我们可以通过将事件类型和论元角色连接起来,简单地将这个任务转换为NER问题。例如可以将(夺冠,时间,2月8日)三元组转换成(夺冠的时间,2月8日)二元组的形式,从而变成了一个NER任务。
3.2.4 Low-resources Task
在4个Unseen Schema上,主办方只给了少部分数据(50~100条数据),为了充分利用预训练模型的优势,我们主要采用了抽取模块和组合模块来解决,整体上可以视作一个MRC的模型。
从抽取流程中,我们可以发现,模型需要遍历schema去生成Prompt进行推理。当schema比较庞大时,模型的推理效率会比较低。但实验表明,这种方式可以充分利用预训练的优势,在低资源场景下表现出优异成绩。
四、实验结果
4.1 Seen Schema
我们按照上一节中描述的方法进行实验,并在排行榜A中取得了最好的成绩。结果见表1,其中“Official Baseline”基于UIE方法 [1]和“ReLink”是排行榜的第二名队伍。
Tabel 1. Comparison between Models on seen Schemas (Leaderboard A)

4.2 Unseen Schema
4.2.1 Comparison of two UIE models
Unseen Schema主要考察模型少样本学习的能力。如4.2节介绍的,我们比较了两种不同的两种通用信息提取模型,实验结果如表 2 所示。
Tabel 2. Results for two UIE models on Unseen Schemas

由于比赛上传次数的限制,我们没有测试单个模型的性能,表中的结果就是模型集成的结果。根据实验结果对比可以发现,span-based UIE的性能在Unseen Schema的数据集上明显优于Generation-based UIE。所以接下来我们主要优化基于span-based UIE,也就是在3.2.4中介绍的模型。
4.2.2 Is pre-training necessary for UIE?
如网站[2]所述,uie-base经过了大量数据训练,可以实现零样本快速冷启动,并具备优秀的小样本微调能力,快速适配特定的抽取目标。然而,考虑到开源的UIE模型只是一个base版本,我们认为还有很大的提升空间。因此,我们用其他预训练模型也进行了测试,结果如表 3 所示。
Tabel 3. Results on Unseen Schemas.TBSS means trained by Seen Schema data.
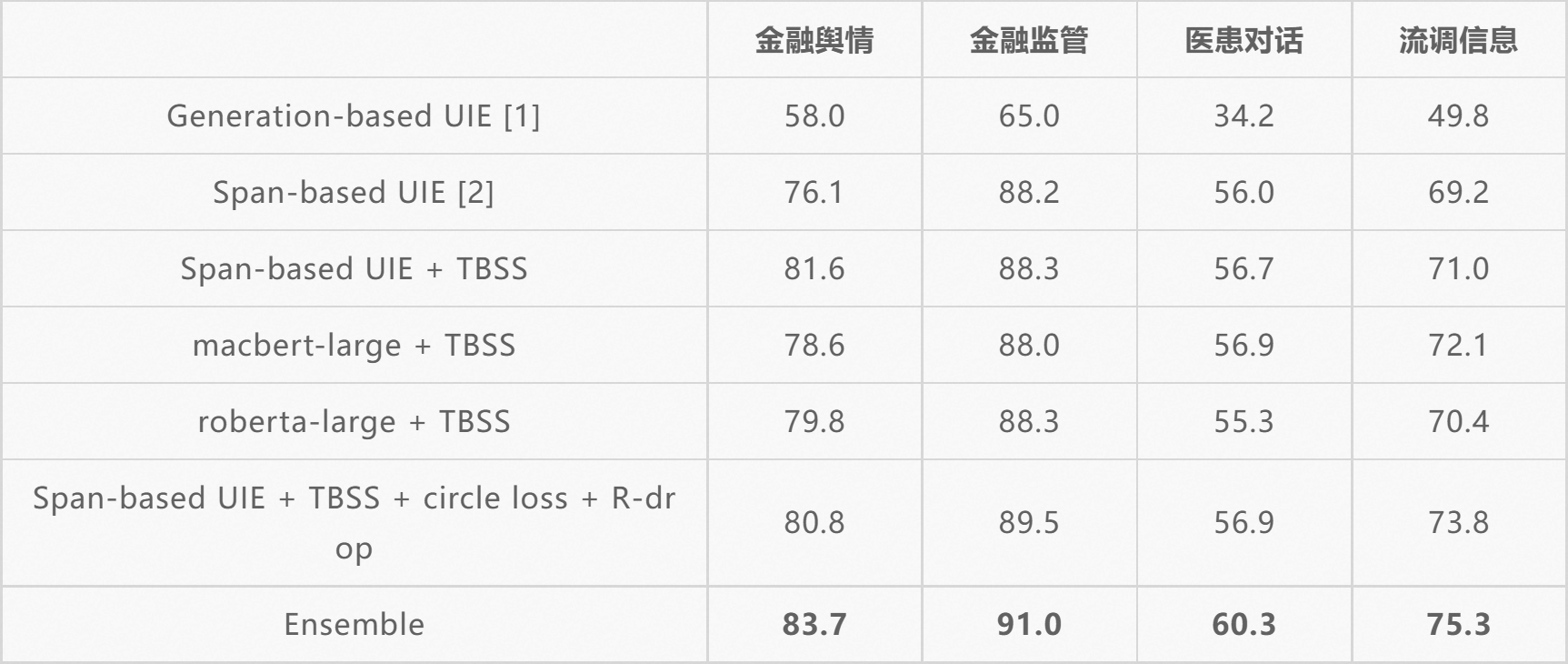
实验表明,虽然macbert和roberta没有像uie-base那样进行预训练,但在使用Seen Schema数据集进行预训练后,它们在Unseen Schema上表现出的性能与uie-base相比还是十分有竞争力的。
4.2.3 Some optimization methods
由于比赛时间和提交次数的限制,我们没有机会尝试很多优化策略。我们只尝试使用circle loss [3] 和R-drop [4] 来优化模型性能,结果如表3所示。
4.2.4 Ensemble
考虑到每个预训练语言模型会因预训练语料的不同而产生不同的认知偏差,因此对于Unseen Schema的任务,我们着重于不同预训练模型之间的集成。涉及的基本预训练语言模型包括 uie-base、macbert-large、roberta-large 和 structbert-large。每个模型都会先在Seen Schema数据集上进行训练,接着用Unseen Schema中的所有数据继续训练,之后再进行推理,最后通过投票获得最终结果。
五、总结
本次比赛涉及的schema很多,同时包括了NER、RE和EE任务。由于B榜评估的时间十分紧张(1个星期),如果没有通用的信息提取模型,将很难完成所有任务。在本文中,我们介绍了一种基于Prompt的通用信息抽取框架,在Unseen Schema上的处理流程类似于机器阅读理解模型。实验表明,该模型具备优秀的小样本微调能力,在Unssen Schema上达到了state-of-the-art的结果,但同时也带来了推理时间成本的增加,需要对schema中的每一个实体、关系和事件都生成相应的样本来进行推理。在未来的工作中,有必要优化其推理效率以应用于实际场景。
参考文献
[1] Lu Y, Liu Q, Dai D, et al. Unified Structure Generation for Universal Information Extraction[J].arXiv preprint arXiv:2203.12277(2022).
[2] https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
[3] Sun Y, Cheng C, Zhang Y, et al. Circle loss: A unified perspective of pair similarity optimization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 6398-6407.
[4] Wu L, Li J, Wang Y, et al. R-drop: Regularized dropout for neural networks[J]. Advances in Neural Information Processing Systems, 2021, 34: 10890-10905.

文章出处登录后可见!