🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 – 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋

目录
在上一章中,我们展示了如何使用 RNN 为文本提供情感分类。然而,RNN 并不是唯一可用于 NLP 分类任务的神经网络架构。卷积神经网络( CNN ) 是另一种这样的架构。
RNN 依赖于顺序建模,保持一个隐藏状态,然后逐字逐句逐句遍历文本,在每次迭代时更新状态。CNN 不依赖于语言的顺序元素,而是尝试通过单独感知句子中的每个单词并学习其与句子中围绕它的单词的关系来从文本中学习。
虽然出于此处提到的原因,CNN 更常用于对图像进行分类,但它们已被证明在文本分类方面也很有效。虽然我们确实将文本视为一个序列,但我们也知道句子中单个单词的含义取决于它们的上下文和它们旁边出现的单词。尽管 CNN 和 RNN 以不同的方式从文本中学习,但它们都被证明在文本分类中是有效的,并且在任何给定情况下使用哪一种取决于任务的性质。
在本章中,我们将探讨 CNN 背后的基本理论,以及从头构建一个用于对文本进行分类的 CNN。我们将涵盖以下主题:
- 探索 CNN
- 构建用于文本分类的 CNN
让我们开始吧!
探索 CNN
CNN 的基础来了来自计算机视觉领域,但在概念上也可以扩展到 NLP。人脑处理和理解图像的方式不是逐个像素的,而是作为图像的整体图以及图像的每个部分与其他部分的关系。
CNN 的一个很好的类比是人类大脑处理图片的方式与处理句子的方式。考虑这句话,这是一个关于猫的句子。当您阅读该句子时,您会阅读第一个单词,然后是第二个单词,依此类推。现在,考虑一张猫的照片。通过查看第一个像素,然后查看第二个像素来吸收图片中的信息是愚蠢的。相反,当我们看某物时,我们会立即感知整个图像,而不是一个序列。
例如,如果我们采用黑白表示的图像(在本例中为数字 1),我们可以看到我们可以将其转换为矢量表示,其中每个像素的颜色由 0 或1: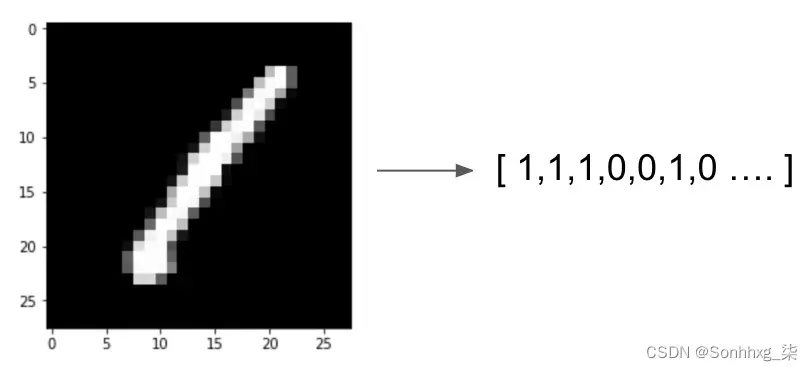
图 6.1 – 图像的矢量表示
但是,如果我们从机器学习的角度考虑这一点,并将这个向量视为我们模型的特征,那么任何单个像素是黑色或白色的事实是否会或多或少地使图片具有给定数字的可能性?右上角的白色像素是否会使图片更有可能是 4 或 7?想象一下,如果我们试图检测更复杂的东西,例如一张图片是狗还是猫。屏幕中间是否有一个棕色像素使照片更有可能是猫或狗?直观地说,我们看到单个像素值在图像分类方面并不重要。然而,我们感兴趣的是像素之间的关系。
在我们的数字表示案例中,我们知道一条长的垂直线很可能是 1,任何带有闭合环的照片都更有可能是 0、6、8 或 9。通过识别和学习图像中的模式,而不仅仅是查看单个像素,我们可以更好地理解和识别这些图像。这正是 CNN 旨在实现的目标。
卷积
基本概念CNN 后面是卷积。卷积本质上是一个滑动窗口函数,它应用于矩阵以捕获来自周围像素的信息。在下图中,我们可以看到卷积的示例: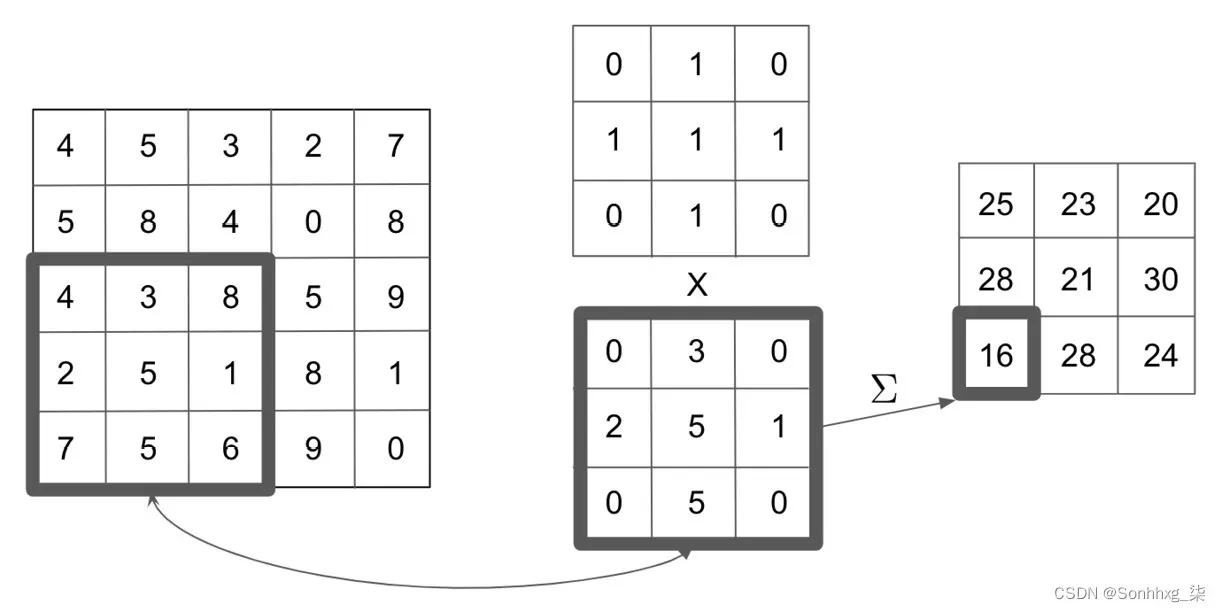
图 6.2 – 卷积作用
在左边,我们有我们正在处理的图像,而在顶部,我们有我们希望应用的卷积核。对于我们图像中的每个 3×3 块,我们将其乘以我们的内核,得到我们的卷积矩阵底部。然后,我们对卷积矩阵求和(或平均),以获得初始图像中这个 3×3 块的单个输出值。请注意,在我们的 5×5 初始图像中,我们可以覆盖九个可能的 3×3 块。当我们对初始图像中的每个 3×3 块应用此卷积过程时,我们会得到最终处理的 3×3 卷积。
在大图像(或复杂句子,在 NLP 的情况下)中,我们还需要实现池化层。在我们前面的示例中,对 5×5 图像应用 3×3 卷积会产生 3×3 输出。但是,如果我们对 100×100 像素的图像应用 3×3 卷积,这只会将输出减少到 98×98。这并没有将图像的维度降低到足以有效地执行深度学习(因为我们必须在每个卷积层学习 98×98 个参数)。因此,我们应用了一个池化层来进一步降低该层的维数。
池化层将一个函数(通常是一个最大函数)应用于卷积层的输出,以降低其维数。此函数应用于滑动窗口,类似于我们的卷积被执行,除了现在我们的卷积不重叠。假设我们的卷积层具有 4×4 的输出,并且我们将 2×2 最大池化函数应用于我们的输出。这意味着对于我们层中的每个较小的 2×2 网格,我们应用一个最大值函数并保留结果输出。我们可以在下图中看到这一点: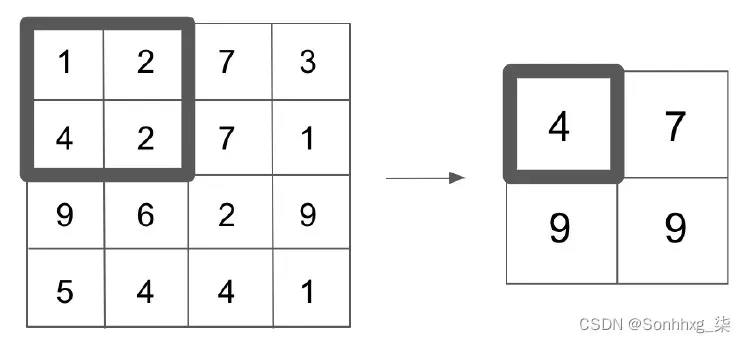
图 6.3 – 池化层
这些池化层已被证明可以有效地降低我们数据的维数,同时仍保留来自卷积层的大部分基本信息。
卷积层和池化层的这种组合本质上是 CNN 从图像中学习的方式。我们可以看到,通过应用其中的许多卷积过程(也称为卷积层),我们能够捕获有关任何给定像素与其相邻像素的关系的信息。在 CNN 中,我们旨在学习的参数是卷积核本身的值。这意味着我们的模型有效地学习了它应该如何在图像上进行卷积,以便能够提取进行分类所需的必要信息。
主要有两个在这种情况下使用卷积的优势。首先,我们能够将一系列低级特征组合成一个高级特征;也就是说,我们初始图像上的 3×3 补丁是组成一个单一的值。这有效地充当了特征减少的一种形式,并允许我们仅从图像中提取相关信息。使用卷积的另一个优点是它使我们的模型位置不变。在我们的数字检测器示例中,我们不注意数字是出现在图像的右侧还是左侧;我们只是希望能够检测到它。由于我们的卷积将检测图像中的特定模式(即边缘),这使得我们的模型位置不变,因为理论上卷积将拾取相同的特征,无论它们出现在图像中的什么位置。
虽然这些原则有助于理解卷积在图像数据中的工作原理,但它们也可以应用于 NLP 数据。我们将在下一节中讨论这一点。
NLP 的卷积
正如我们在本书中多次看到的那样,我们可以将单个单词用数字表示为向量,并且将整个句子和文档表示为一系列向量。什么时候我们将句子表示为向量序列,我们可以将其表示为矩阵。如果我们有一个给定句子的矩阵表示,我们会立即注意到这类似于我们在图像卷积中卷积的图像。因此,我们可以以与图像类似的方式将卷积应用于 NLP,前提是我们可以将文本表示为矩阵。
让我们首先考虑使用这种方法的基础。当我们之前查看 n-gram 时,我们看到句子中单词的上下文取决于它前面的单词和后面的单词。因此,如果我们能够以一种允许我们捕获一个单词与其周围单词的关系的方式对一个句子进行卷积,我们理论上可以检测语言中的模式并使用它来更好地对我们的句子进行分类。
还值得注意的是,我们的卷积方法与我们对图像的卷积略有不同。在我们的图像矩阵中,我们希望捕获单个像素相对于它周围的上下文的上下文,而在一个句子中,我们希望捕获整个词向量的上下文,相对于它周围的其他向量。因此,在 NLP 中,我们希望在整个词向量上执行卷积,而不是在词向量内。这是如下图所示。
我们首先代表我们的句子作为单个词向量:
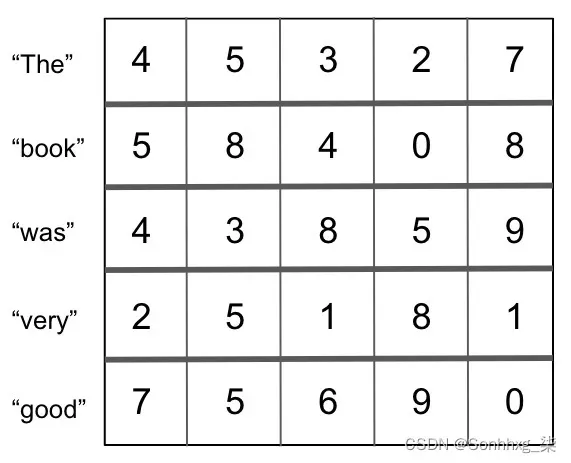
图 6.4 – 词向量
然后我们在矩阵上应用 (2 x n ) 卷积(其中n是我们的词向量的长度;在本例中,n = 5)。我们可以使用 (2 x n ) 滤波器对四个不同的时间进行卷积,从而减少为四个输出。你会注意到这类似于二元词模型,在一个五个单词的句子中有四个可能的二元词: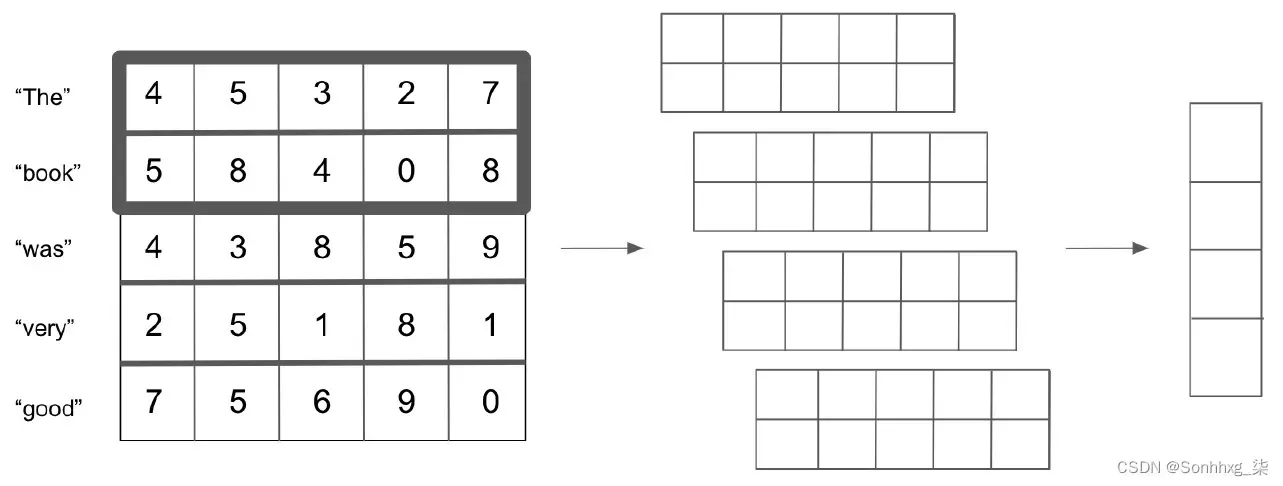
图 6.5 – 将词向量卷积成二元组
同样,我们可以对任意数量的 n-gram 执行此操作;例如,n =3: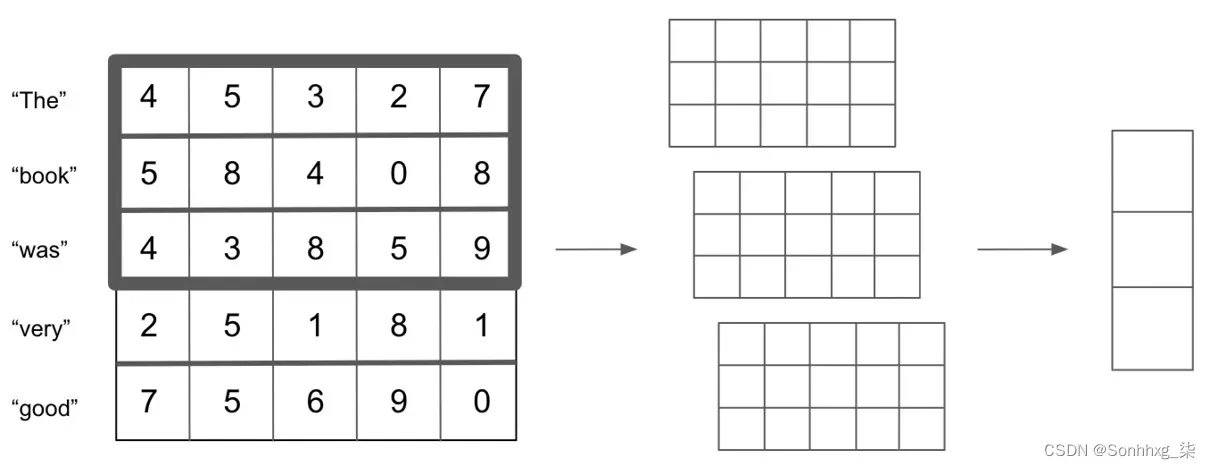
图 6.6 – 将词向量卷积成 n-gram
的好处之一像这样的卷积模型是没有数量限制的我们可以对 n-gram 进行卷积。我们还能够同时对多个不同的 n-gram 进行卷积。因此,为了同时捕获二元组和三元组,我们可以像这样设置我们的模型: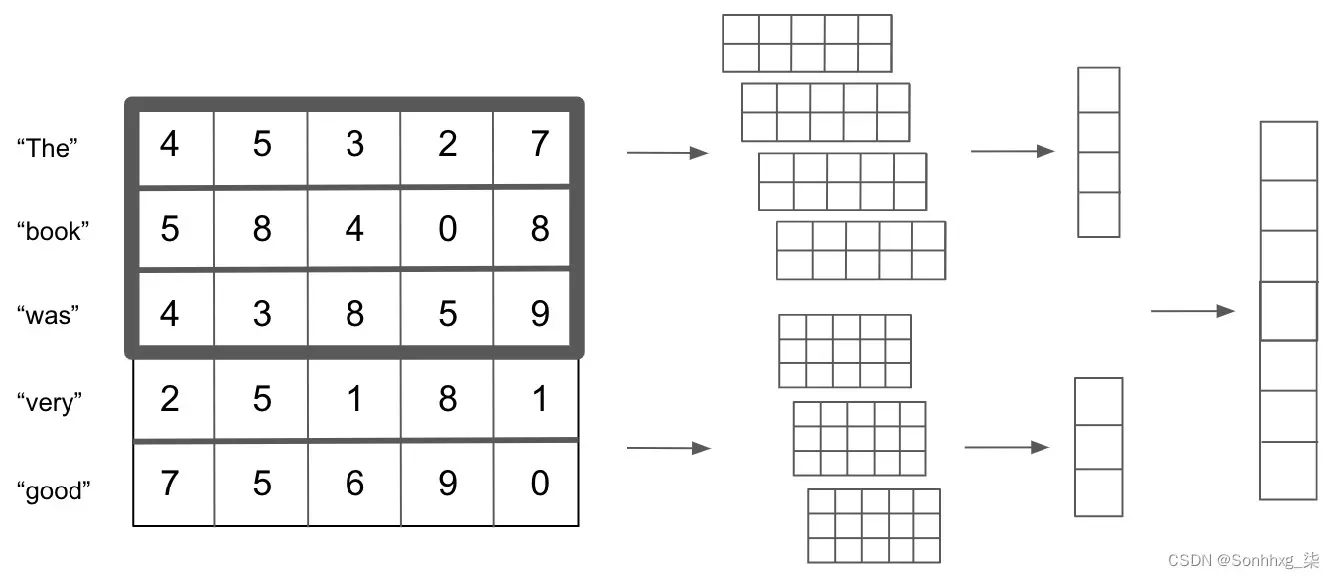
图 6.7 – 将词向量卷积为二元组和三元组
尽管用于 NLP 的 CNN 具有如前几节所述的优点,但它们也有其缺点。
在图像的 CNN 中,假设一个给定的像素可能与周围的像素相关是合理的。当应用于 NLP 时,虽然这个假设是部分正确的,但单词可以在语义上相关,即使它们彼此不直接接近。句首的词可以与句尾的词相关。
虽然我们的 RNN 模型可能能够通过长期记忆依赖来检测这种关系,但我们的 CNN 可能会遇到困难,因为 CNN 只能捕获目标单词周围单词的上下文。
话虽如此,用于 NLP 的 CNN 已被证明在某些任务中表现非常出色,即使我们的语言假设不一定成立。可以说,使用 CNN 进行 NLP 的主要优势是速度和效率。卷积可以在 GPU 上轻松实现,从而实现快速并行计算和训练。
捕获单词之间关系的方式也更加有效。在真正的 n-gram 模型中,模型必须学习每个 n-gram 的单独表示,而在我们的 CNN 模型中,我们只学习卷积核,它会自动提取给定词向量之间的关系。
既然我们已经定义了我们的CNN 将从我们的数据中学习,我们可以开始从头开始编写模型。
构建用于文本分类的 CNN
现在我们了解了 CNN 的基础知识,我们可以开始从头开始构建一个。在上一章中,我们建立了一个情感预测模型,其中情感是一个二元分类器;1表示正,0表示负。然而,在这个例子中,我们的目标是构建一个用于多类文本分类的 CNN. 在多类问题中,一个特定的例子只能被归类为几个类中的一个。如果一个例子可以被分类为许多不同的类别,那么这就是多标签分类。由于我们的模型是多类的,这意味着我们的模型将旨在预测我们的输入句子被分类为几个类别中的哪一个。虽然这个问题比我们的二元分类任务困难得多(因为我们的句子现在可以属于多个类别之一,而不是两个类别之一),但我们将证明 CNN 可以在这项任务上提供良好的性能。我们将首先定义我们的数据。
定义多类分类数据集
在上一章中,我们看到了一个选择评论并学习二进制根据评论是正面还是负面的分类。对于这项任务,我们将查看来自TREC ( Text REtrieval Conference (TREC) QA Data ) 数据集,这是用于评估模型文本分类任务性能的常用数据集。该数据集由一系列问题组成,每个问题都属于我们训练的模型将学习分类的六大语义类别之一。这六类如下: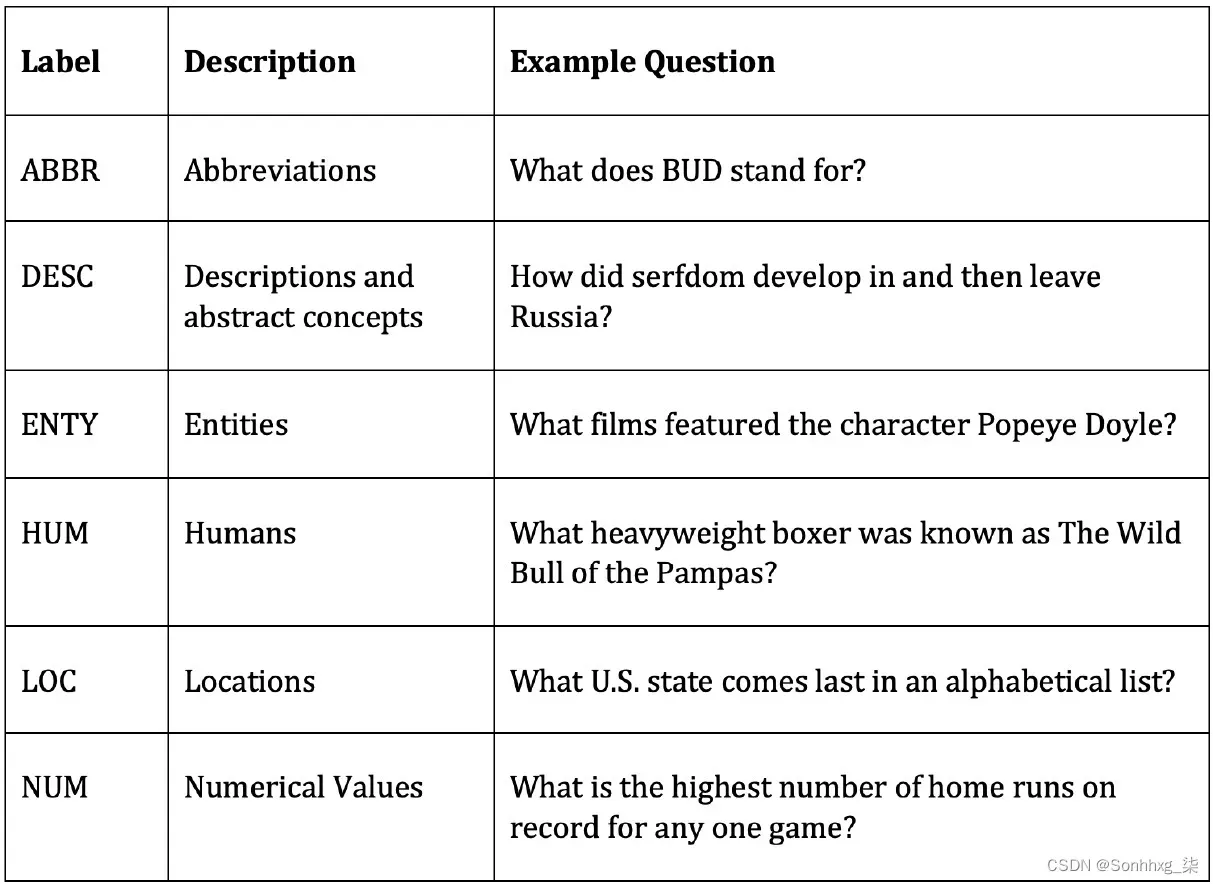
图 6.8 – TREC 数据集中的语义类别
这意味着与我们之前的分类类,我们的模型输出是0和1之间的单个预测,我们的多类预测模型现在返回一个六个可能类别中的每一个的概率。我们假设所做的预测是针对具有最高预测的类:
图 6.9 – 预测值
通过这种方式,我们的模型现在将能够对多个类别执行分类任务,并且我们不再局限于我们之前看到的 0 或 1 二元分类。具有多个模型类别可能会在预测方面受到影响,因为有更多不同的类别需要区分。
在二元分类模型中,假设我们有一个平衡的数据集,如果只是执行随机猜测,我们希望我们的模型具有 50% 的准确率,而多类具有五个不同类别的模型的基线准确度仅为 20%。这意味着仅仅因为多类模型的准确率远低于 100%,这并不意味着模型本身天生就不擅长进行预测。当涉及从数百个不同类别进行预测的训练模型时尤其如此。在这些情况下,一个只有 50% 准确率的模型会被认为表现得非常好。
现在我们已经定义了多类分类问题,我们需要加载数据来训练模型。
创建迭代器来加载数据
在我们的 LSTM 模型中上一章,我们简单地使用了一个.csv文件,其中包含我们用来训练模型的所有数据。然后我们手动将这些数据转换为输入张量,并将它们一一输入到我们的网络中以对其进行训练。虽然这种方法是完全可以接受的,但它并不是最有效的方法。
在我们的 CNN 模型中,我们将改为从我们的数据中创建数据迭代器。这些迭代器对象使我们能够轻松地从输入数据中生成小批量数据,从而使我们能够使用小批量训练模型,而不是将输入数据一个一个地输入网络。这意味着我们网络中的梯度是针对整批数据计算的,并且参数调整发生在每批数据之后,而不是在每一行数据通过网络之后。
对于我们的数据,我们将从 TorchText 包中获取数据集。这不仅具有包含大量用于模型训练的数据集的优点,而且还允许我们使用内置函数轻松标记和矢量化我们的句子。
按着这些次序:
- 我们首先从 TorchText 导入数据和数据集函数:
from torchtext import data from torchtext import datasets - 接下来,我们创建一个可以与TorchText包一起使用的字段和标签字段。这些定义了我们的模型将用于处理数据的初始处理步骤:
questions = data.Field(tokenize = ‘spacy’, batch_first = True) labels = data.LabelField(dtype = torch.float)在这里,我们设置 tokenize 等于 spacy来设置我们的输入句子将如何被标记。TorchText然后使用spacy包自动标记输入句子。spacy由英语语言的索引组成,因此任何单词都会自动转换为相关的标记。您可能需要安装spacy才能使其正常工作。这可以通过键入以下命令在命令行中完成:
pip3 install spacy python3 -m spacy download en这会安装spacy并下载英文单词索引。
- 我们还将标签的数据类型定义为浮点数,这将允许我们计算损失和梯度。在定义了我们的字段之后,我们可以使用它们来分割我们的输入数据。使用TorchText中的TREC数据集,我们传递我们的问题和标签字段,以便相应地处理数据集。然后我们调用split函数,以便自动将我们的数据集划分为训练集和验证集:
train_data, _ = datasets.TREC.splits(questions, labels) train_data, valid_data = train_data.split()请注意,通常,我们可以通过简单地调用训练数据来在 Python 中查看我们的数据集:
train_data
但是,在这里,我们处理的是TorchText数据集对象,而不是我们可能习惯看到的加载到 pandas 中的数据集。这意味着我们前面代码的输出如下:
![]()
图 6.10 – TorchText 对象的输出
我们可以查看个人数据在此数据集对象内;我们只需要调用.examples参数。这些示例中的每一个都有一个文本和一个标签参数,我们可以像这样检查文本:
train_data.examples[0].text这将返回以下输出:
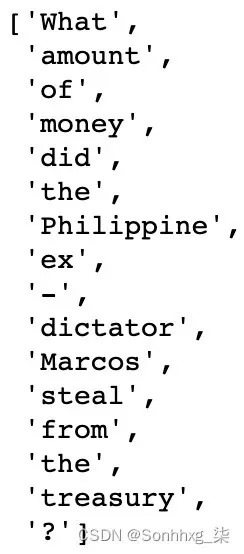
图 6.11 – 数据集对象中的数据
标签代码运行如下:
train_data.examples[0].label这给了我们以下输出:
![]()
图 6.12 – 数据集对象的标签
所以,我们可以看到我们的输入数据由一个标记化的句子组成,我们的标签由我们希望分类的类别组成。我们还可以检查训练集和验证集的大小,如下所示:
print(len(train_data))
print(len(valid_data))这将产生以下输出:
![]()
图 6.13 – 训练集和验证集的大小
这表明我们的训练与验证比率约为 70% 到 30%。值得注意的是我们的输入句子是如何被标记的,即标点符号被视为它们自己的标记。
现在我们知道我们的神经网络不会将原始文本作为输入,我们必须找到某种方法将其转化为某种形式的嵌入表示。虽然我们可以训练自己的嵌入层,但我们可以使用我们在第 3 章执行文本嵌入中讨论的预先计算的手套向量来转换我们的数据。这还具有使我们的模型更快地训练的额外好处,因为我们不需要从头开始手动训练我们的嵌入层:
questions.build_vocab(train_data,
vectors = “glove.6B.200d”,
unk_init = torch.Tensor.normal_)
labels.build_vocab(train_data)在这里,我们可以看到,通过使用build_vocab函数并将我们的问题和标签作为训练数据传递,我们可以构建一个由 200 维 GLoVe 向量组成的词汇表。请注意,TorchText 包将自动下载并抓取 GLoVe 向量,因此在此实例中无需手动安装 GLoVe。我们还定义了我们希望如何对待未知我们词汇表中的值(也就是说,如果模型传递了一个不在预训练词汇表中的标记,它会做什么)。在这种情况下,我们选择将它们视为具有未指定值的正常张量,尽管我们稍后会更新。
我们现在可以通过调用以下命令看到我们的词汇表由一系列预先训练的 200 维 GLoVe 向量组成:
questions.vocab.vectors这将产生以下输出:
图 6.14 – 张量内容
接下来,我们创建数据迭代器。我们为我们的训练和验证数据创建单独的迭代器。我们首先指定一个设备,以便我们能够使用支持 CUDA 的 GPU(如果可用)更快地训练我们的模型。在我们的迭代器中,我们还指定迭代器返回的批次大小,在本例中为64。您不妨尝试一下为您的模型使用不同的批量大小,因为这可能会影响训练速度以及模型收敛到其全局最优值的速度:
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
train_iterator, valid_iterator = data.BucketIterator.splits(
(train_data, valid_data),
batch_size = 64,
device = device)构建CNN模型
现在我们有了加载数据,我们准备创建模型。我们将使用以下步骤来做到这一点:
- 我们希望构建我们的 CNN 的结构。我们像往常一样将模型定义为继承自nn.Module的类:
class CNN(nn.Module): def __init__(self, vocab_size, embedding_dim,n_filters, filter_sizes, output_dim, dropout,pad_idx): super().__init__() - 我们的模型使用几个输入进行初始化,所有这些都将在稍后介绍。接下来,我们单独定义网络中的层,从嵌入层开始:
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)嵌入层将包含我们词汇表中每个可能单词的嵌入,因此层的大小是我们的词汇表的长度和我们的嵌入向量的长度。我们使用的是 200 维 GLoVe 向量,因此在本例中长度为200。我们还必须传递填充索引,这是我们嵌入层的索引,用于让嵌入填充我们的句子,使它们的长度都相同。稍后我们将在初始化模型时手动定义此嵌入。
- 接下来,我们定义实际我们网络中的卷积层:
self.convs = nn.ModuleList([nn.Conv2d(in_channels = 1, out_channels = n_filters, kernel_size = (fs, embedding_dim)) for fs in filter_sizes]) - 我们首先使用nn.ModuleList定义一系列卷积层。ModuleList将模块列表作为输入,当您希望定义多个单独的层时使用。由于我们希望在输入数据上训练几个不同大小的不同卷积层,我们可以使用ModuleList来做到这一点。我们理论上可以像这样分别定义每一层:
self.conv_2 = nn.Conv2d(in_channels = 1, out_channels = n_filters, kernel_size = (2, embedding_dim)) self.conv_3 = nn.Conv2d(in_channels = 1, out_channels = n_filters, kernel_size = (3, embedding_dim))
这里,过滤器大小分别为2和3。但是,在单个函数中执行此操作更有效。此外,我们的层如果我们将不同的过滤器大小传递给函数,它将自动生成,而不是每次添加新层时都必须手动定义每一层。
我们还将out_channels值定义为我们希望训练的过滤器的数量;kernel_size将包含我们嵌入的长度。因此,我们可以向ModuleList函数传递我们希望训练的过滤器的长度和每个过滤器的数量,它会自动生成卷积层。该卷积层如何查找给定变量集的示例如下:
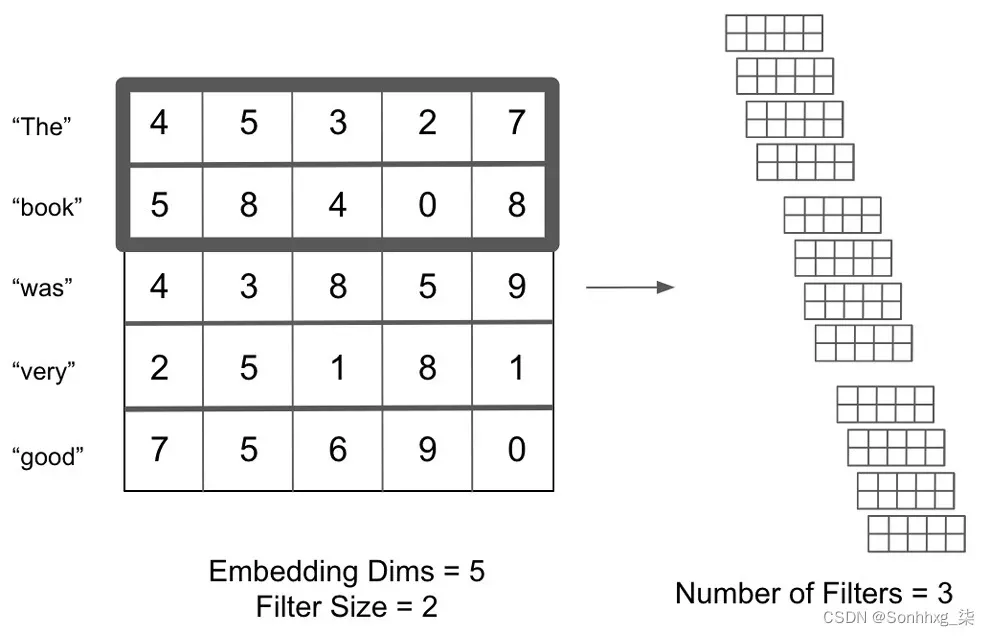 图 6.15 – 寻找变量的卷积层
图 6.15 – 寻找变量的卷积层
我们可以看到我们的ModuleList函数适应了过滤器的数量和我们希望训练的过滤器的大小。接下来,在我们的 CNN 初始化中,我们定义了剩余的层,即线性层,它将对我们的数据进行分类,以及 dropout 层,它将规范我们的网络:
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)请注意,在过去,我们的线性层的大小始终为1,因为我们只需要一个输出节点来执行二进制分类。因为我们现在正在处理多类分类问题,我们希望对每个潜在类别进行预测,因此我们的输出维度现在是可变的,而不仅仅是1。当我们初始化我们的网络时,我们将输出维度设置为6,因为我们正在预测我们的句子来自六个类别中的哪一个。
接下来,与我们所有的神经网络一样,我们必须定义我们的前向传递:
def forward(self, text):
emb = self.embedding(text).unsqueeze(1)
conved = [F.relu(c(emb)).squeeze(3) for c in self.convs]
pooled = [F.max_pool1d(c, c.shape[2]).squeeze(2) for c in conved]
concat = self.dropout(torch.cat(pooled, dim = 1))
return self.fc(concat)在这里,我们首先将输入文本通过嵌入层,以获得句子中所有单词的嵌入。接下来,对于我们将嵌入句子传递到的每个先前定义的卷积层,我们应用一个relu激活函数并压缩结果,删除结果输出的第四维。这对我们定义的所有卷积层都重复,因此conved包含在我们所有卷积层的输出列表中。
对于这些输出中的每一个,我们应用一个池化函数来降低卷积层输出的维数,如前所述。然后,我们将池化层的所有输出连接在一起并应用一个 dropout 函数,然后将其传递给我们的最终全连接层,这将进行我们的类预测。在完全定义了我们的 CNN 类之后,我们创建模型的一个实例。我们定义超参数并使用它们创建 CNN 类的实例:
input_dimensions = len(questions.vocab)
output_dimensions = 6
embedding_dimensions = 200
pad_index = questions.vocab.stoi[questions.pad_token]
number_of_filters = 100
filter_sizes = [2,3,4]
dropout_pc = 0.5
model = CNN(input_dimensions, embedding_dimensions, number_of_filters, filter_sizes, output_dimensions, dropout_pc, pad_index)我们的输入维度将始终是我们词汇的长度,而我们的输出维度将是我们希望预测的类的数量。在这里,我们从六个不同的类别进行预测,因此我们的输出向量的长度为6。我们的嵌入维度是 GLoVe 向量的长度(在本例中为200)。填充索引可以从我们的词汇表中手动获取。
接下来的三个超参数可以手动调整,因此您可能希望尝试选择不同的值,看看这如何影响您的网络的最终输出。我们传递了一个过滤器大小列表,以便我们的模型将使用大小为2、3和4的卷积来训练卷积层。我们将为每个过滤器大小训练 100 个过滤器,因此总共将有 300 个过滤器。我们还为我们的网络定义了 50% 的 dropout 百分比,以确保其充分正规化。如果模型似乎容易过度拟合或欠拟合,则可以提高/降低此值。一般的经验法则是,如果模型拟合不足,则尝试降低 dropout 率,如果模型似乎过拟合,则尝试提高 dropout 率。
初始化模型后,我们需要将权重加载到嵌入层中。这可以很容易地完成,如下所示:
glove_embeddings = questions.vocab.vectors
model.embedding.weight.data.copy_(glove_embeddings)这将产生以下输出:
图 6.16 – 降低 dropout 后的张量输出
接下来,我们需要定义我们的当我们的模型考虑不包含在嵌入层中的未知标记时,模型处理实例以及我们的模型如何将填充应用于我们的输入句子。幸运的是,考虑这两种情况的最简单方法是使用由全零组成的向量。我们确保这些零值张量与我们的嵌入向量长度相同(在本例中为200):
unknown_index = questions.vocab.stoi[questions.unk_token]
model.embedding.weight.data[unknown_index] = torch.zeros(embedding_dimensions)
model.embedding.weight.data[pad_index] = torch.zeros(embedding_dimensions)最后,我们定义优化器和标准(损失)函数。请注意我们如何选择使用交叉熵损失而不是二元交叉熵,因为我们的分类任务不再是二元的。我们还使用.to(device)来使用我们指定的设备训练我们的模型。这意味着我们的训练将在支持 CUDA 的 GPU 上进行(如果有的话):
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss().to(device)
model = model.to(device)训练 CNN
在我们定义我们的训练过程之前,我们需要计算一个性能指标来说明我们的模型的性能(希望如此!)如何随着时间的推移而增加。在我们的二元分类任务中,准确率是我们用来衡量性能的一个简单指标。对于我们的多分类任务,我们将再次使用准确率,但计算它的过程稍微复杂一些,因为我们现在必须计算出我们的模型预测的六个类别中的哪一个以及六个类别中的哪一个是正确的。
首先,我们定义一个名为multi_accuracy的函数来计算:
def multi_accuracy(preds, y):
pred = torch.max(preds,1).indices
correct = (pred == y).float()
acc = correct.sum() / len(correct)
return acc在这里,对于我们的预测,我们的模型使用torch.max函数为所有预测返回具有最高值的索引。对于这些预测中的每一个,如果这个预测索引与我们标签的索引相同,则将其视为正确预测。然后我们计算所有这些正确的预测,并将它们除以预测的总数,以获得多类准确度的度量。我们可以在我们的训练循环中使用这个函数来测量每个时期的准确性。
接下来,我们定义我们的训练函数。我们最初将 epoch 的损失和准确率设置为0,然后调用model.train()以允许我们训练模型时要更新模型中的参数:
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()接下来,我们遍历迭代器中的每批数据并执行训练步骤。我们首先将梯度归零,以防止从前一批计算累积梯度。然后,我们使用模型的当前状态从当前批次中的句子进行预测,然后将其与标签进行比较以计算损失。使用我们在上一节中定义的准确度函数,我们可以计算给定批次的准确度。然后我们反向传播我们的损失,通过梯度下降更新我们的权重并逐步通过我们的优化器:
for batch in iterator:
optimizer.zero_grad()
preds = model(batch.text).squeeze(1)
loss = criterion(preds, batch.label.long())
acc = multi_accuracy(preds, batch.label)
loss.backward()
optimizer.step()最后,我们将这个批次的损失和准确率添加到我们整个时期的总损失和准确率中。在我们循环之后epoch 内的所有批次,我们计算 epoch 的总损失和准确率并返回:
epoch_loss += loss.item()
epoch_acc += acc.item()
total_epoch_loss = epoch_loss / len(iterator)
total_epoch_accuracy = epoch_acc / len(iterator)
return total_epoch_loss, total_epoch_accuracy类似地,我们可以定义一个名为eval的函数,该函数在我们的验证数据上调用,以计算我们在模型尚未训练的数据集上训练的模型性能。虽然这个函数与我们之前定义的训练函数几乎相同,但我们必须做两个关键的补充:
model.eval()
with torch.no_grad():这两个步骤将我们的模型设置为评估模式,忽略任何 dropout 函数,并确保不计算和更新梯度。这是因为我们希望在评估性能时冻结模型中的权重,并确保我们的模型不使用我们的验证数据进行训练,因为我们希望将其与我们用于训练模型的数据分开.
现在,我们只需要结合我们的数据迭代器在循环中调用我们的训练和评估函数来训练模型。我们首先定义我们希望模型训练的 epoch 数。我们还定义了我们的模型迄今为止实现的最低验证损失。这是因为我们只希望保持训练后的模型具有最低的验证损失(即性能最佳的模型)。这意味着,如果我们的模型训练了许多 epoch 并开始过度拟合,则只会保留这些模型中表现最好的模型,这意味着选择大量 epoch 的后果更少。
我们将最低验证损失初始化为无穷大:
epochs = 10
lowest_validation_loss = float(‘inf’)接下来,我们定义我们的训练循环,步进一次通过一个时代。我们记录训练的开始和结束时间,以便计算每一步需要多长时间。然后,我们只需使用训练数据迭代器在我们的模型上调用我们的训练函数来计算训练损失和准确率,同时更新我们的模型。然后,我们使用验证迭代器上的评估函数重复此过程,以计算验证数据的损失和准确性,而不更新我们的模型:
for epoch in range(epochs):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator,criterion)
end_time = time.time()在此之后,我们确定我们的模型在当前 epoch 之后是否优于我们迄今为止表现最好的模型:
if valid_loss < lowest_validation_loss:
lowest_validation_loss = valid_loss
torch.save(model.state_dict(), ‘cnn_model.pt’)如果此 epoch 之后的损失低于迄今为止的最低验证损失,我们将验证损失设置为新的最低验证损失并保存我们当前的模型权重。
最后,我们只需在每个 epoch 后打印结果。如果一切正常,我们应该会看到我们的训练损失在每个 epoch 之后都会下降,我们的验证损失也有望效仿:
print(f'Epoch: {epoch+1:02} | Epoch Time: {int(end_time - start_time)}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_ acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_ acc*100:.2f}%')这将产生以下输出:
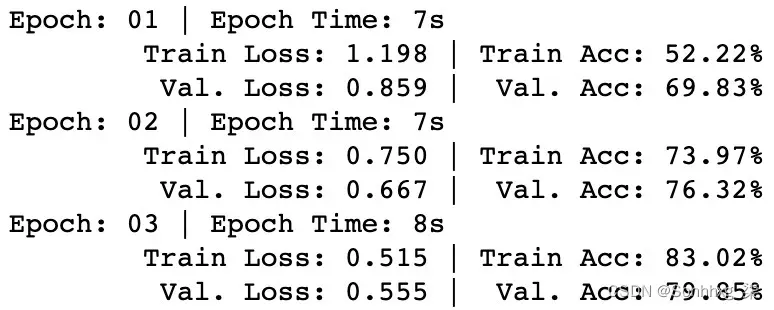
图 6.17 – 测试模型
值得庆幸的是,我们看到这确实似乎是这样。每个 epoch 后训练和验证损失都下降,准确率上升,表明我们的模型确实在学习!经过多次训练后,我们可以采用我们最好的模型并使用它来进行预测。
使用经过训练的 CNN 进行预测
幸运的是,使用我们训练有素的模型进行预测是一项相对简单的任务。我们首先使用load_state_dict函数加载我们最好的模型:
model.load_state_dict(torch.load(' cnn_model.pt '))我们的模型结构已经定义好了,所以我们只需从之前保存的文件中加载权重。如果这工作正常,您将看到以下输出:
图 6.18 – 预测输出
接下来,我们定义一个函数,它将一个句子作为输入,对其进行预处理,将其传递给我们的模型,并返回一个预测:
def predict_class(model, sentence, min_len = 5):
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
if len(tokenized) < min_len:
tokenized += [‘<pad>’] * (min_len - len(tokenized))
indexed = [questions.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(0)我们首先将输入句子传递到我们的标记器中以获取标记列表。然后,如果它低于最小句子长度,我们会在该句子中添加填充。然后,我们使用我们的词汇表来获取所有这些单个标记的索引,然后最终创建一个由这些索引的向量组成的张量。如果它可用,我们将其传递给我们的 GPU,然后解压缩输出,因为我们的模型需要一个 3 维张量输入而不是单个向量。
接下来,我们进行预测:
model.eval()
prediction = torch.max(model(tensor),1).indices.item()
pred_index = labels.vocab.itos[prediction]
return pred_index我们首先将我们的模型设置为评估模式(就像我们在评估步骤中所做的那样),这样我们的模型的梯度不会被计算并且权重不会被调整。然后我们将句子张量传递给我们的建模并获得长度为6的预测向量,由六个类别中的每一个类别的单独预测组成。然后我们获取最大预测值的索引,并在我们的标签索引中使用它来返回预测类的名称。
为了进行预测,我们只需在任何给定句子上调用predict_class函数。让我们使用以下代码:
pred_class = predict_class(model, “How many roads must a man walk down?”)
print(‘Predicted class is: ‘ + str(pred_class))这将返回以下预测:
![]()
图 6.19 – 预测值
这个预测是正确的!我们的输入问题包含How many,表明这个问题的答案是一个数值。这也正是我们的模型所预测的!您可以继续在您可能希望测试的任何其他问题上验证模型,希望得到类似的积极结果。恭喜——您现在已经成功训练了一个多类 CNN,它可以定义任何给定问题的类别。
概括
在本章中,我们展示了如何使用 CNN 从 NLP 数据中学习,以及如何使用 PyTorch 从头开始训练。虽然深度学习方法与 RNN 中使用的方法非常不同,但从概念上讲,CNN 以算法方式使用 n-gram 语言模型背后的动机,以便从相邻单词的上下文中提取句子中单词的隐含信息。现在我们已经掌握了 RNN 和 CNN,我们可以开始扩展这些技术以构建更高级的模型。
在下一章中,我们将学习如何构建利用卷积和循环神经网络元素的模型,并将它们用于序列以执行更高级的功能,例如文本翻译。这些被称为序列到序列网络。
文章出处登录后可见!