目录
相比较于2D数据(图像数据),三维点云数据大多是非规则化、非结构化并且无序的,保留了原始的几何信息在三维空间中,虽然可以获取对象的形状大小,但对其空间位置、几何属性、实质属性等特征的分割也带来了更多的问题。加上其采集过程中,光线以及设备角度变化的速率造成采集的点数据的密度分布不均,点云语义分割仍面临一系列的问题。
早期也有不少人尝试在点云分割领域做研究,这些传统的分割方法也取得了一定的效果,但大多受限于特定的场景和先验知识,无法推广应用,并且比较耗时。
随着近些年来深度学习的快速发展,点云语义分割的研究重点也转移到以深度学习为首的相关方法上。这些方法相较于早期的传统方法,分割的准确度有了极大的提升,尤其是直接在点云上处理数据的思想被提出以后,越来越多的人开始倾向于直接在点云上进行处理,来充分利用3D点云中所包含的丰富的空间信息。
1 传统方法
在深度学习应用于点云分割领域之前,已经有相当多的方法在尝试点云的分割,这些传统的点云分割方法主要依赖于几何约束和统计规则来人工设计物体的特征,将原始的点云数据分为不重叠的几组区域,来对应场景中的各个对象,虽然效果不太理想,但思想仍然有可借鉴的地方,这些方法可分以下四个方面。
1.1基于边缘信息的分割
基于边缘的分割方法是通过识别亮度突变点来识别边缘信息,从而描述物体的形状,再对这些边缘信息点进行分组来确定最终的分割结果。
该方法分割速度较快,但缺点是准确度比较低,对于密度不均匀或稀疏的点云很敏感,还会受到噪声的干扰。
1.2基于模型拟合的分割
基于模型拟合的分割是以点云数据的分类和几何形状为基础的,将点云与已知的几何图形进行对比匹配(如圆柱体、圆锥体、球体等)将具有相同数学特征的点划为一类,从而在点云中分割出已知的几何形状,
该方法主要是基于数学原理的分割方法,与基于边缘信息的分割相比,不仅受噪声干扰小,还有较快的计算速度。
1.3基于区域增长的分割
以区域为基础的分割方法就是对点云区域进行分割,根据一定的差异准则,将差异性小的点云归为同一区域。具体分为种子和非种子区域方法。
种子区域首先需要选取多个种子点作为起始点,依据设定好的生长规则,在种子周围添加特征相似度高的邻域点,使其邻域空间生长扩散,再以此邻域点作为新的种子点重复以上生长过程。种子区域分割受噪声影响较大,计算时间较长。另外,该方法的分割精度很大程度受初始种子点选取的影响,因此,如何选择合适的初始种子点是该方法的关键点和难点。
非种子区域则是先将空间域所有的点归为同一区域,再对该区域进行进一步细分。和种子区域相比,非种子区域分割的缺点在于难以细分位置,而且存在分割过度的情况,分割的精度对先验知识的要求较高。
1.4基于属性的分割
先根据点云属性进行计算,将计算得到的点的属性进行聚类,为每一个点定义一个特征向量,相似的特征向量将会被归于一类,以此来完成分割。
该方法可以较好的解决噪声和异常值的影响,但缺点是对点云密度要求高且计算时间较长。
1.5基于图优化的分割
基于图的分割方法通过建立点之间的关系,将点云数据转变为图数据,再对这个图数据进行卷积计算,即选用合适的图卷积神经网络对其进行表征学习。
该方法的优点是图卷积能够聚合物体的点集特征,并且保持其三维空间的平移不变性,但怎么合适地建立点与点之间的关系还是一个待解决地难题。
2基于深度学习的方法
随着深度学习的发展,计算机视觉的各个领域已经越来越离不开深度学习。利用深度学习处理2D图像数据的技术已经十分成熟并且取得了很好的效果。近年来越来越多的研究者将目光投向利用深度神经网络处理点云。
二维的数字图像是由像素组成矩阵构成的,很容易的在计算机中进行表示。但三维的点云数据由空间中无序的点构成,很难在计算机中直接处理。因此需要将点云转化适合卷积神经网络(Convolutional Neural Network,CNN)处理的规则结构。
主要有以下方式:基于投影、基于体素和基于点的分割。
2.1基于投影的分割
2.1.1多视图表示
早期的深度学习方法尝试将3D点云投影到2D平面上,然后基于CNN的网络模型来对数据进行处理。这个方法解决了三维点云数据难以处理的问题,利用CNN提取平面投影的特征,将多视图的平面投影特征聚合在一起,通过全连接层和池化层得到语义分割的结果。
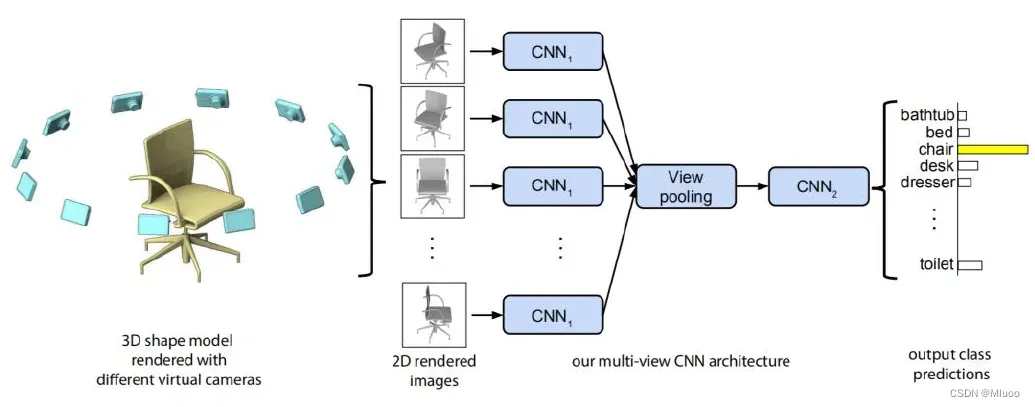
图2.1 基于多视图表示的代表性网络结构
Fig.2.1 Representative network structure based on multi-view approach
由于三维点云被投影到二维图像上会受到不同视点选择和投影角度的影响,导致图像丢失部分可用的空间集合信息,一定程度上会造成分割精度的下降,而这个缺点是该算法难以避免的。
2.1.2球状表示
激光雷达扫描后的点云的几何形状类似一个空心圆柱体,从垂直与圆柱体主轴的方向来看空心圆柱时,可以将其理解为一个环绕的平面图像,这样就可用球状投影图像来表示三维点云。
此方法突出特点是速度快,相较于多视图投影,球面投影方式保留了更多的点云信息,但对于多视图存在的遮挡物问题,球面投影方式仍无法解决。
2.2基于体素的分割
体素(occupancy voxels)是一种结构化的表示方法,即将原始的点云数据分成具有一定空间大小的体素。

图2.2 基于多视图表示的代表性网络结构
Fig.2.2 Representative network structure based on voxel approach
总体来看,体素化表示点云能较好保留原始点云的邻域结构,体素化表示的结构也具有良好的可扩展性,具有较好的分割效果。但体素化本身会带来离散伪影和信息丢失等问题,虽然点云体素化将点云转变为了规则数据,但选择高分辨率的同事也带来了计算效率低与占用内存大的问题,导致难以选择适合的网格分辨率来满足各方面的均衡。
2.3基于点的分割
由于基于投影和基于体素的方法都存在空间信息丢失和结构分辨率下降等局限性,因此需要一种更加有效的方法来处理点云。基于点的分割方法,不仅能够更充分利用点云的几何结构信息,还提升了计算效率。
目前基于点的分割方法大致分为逐点MLP方法、点卷积方法、基于RNN的方法和基于图的方法。
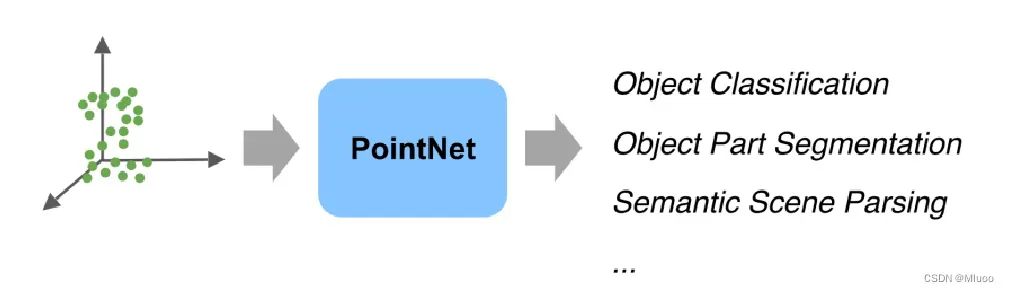
图3 基于点云方法的代表性网络结构
Fig.2.3 Representative network structure based on point
2.3.1 逐点MLP方法
PointNet:直接在点云数据上进行处理,使用共享多层感知机(MLP)提取输入点云数据中每个点的特征,经由最大池化得到全局特征。其核心在于T-Net网络,先利用第一个T-Net对点云构造转换矩阵进行空间对齐,解决点云转换不变性的问题,再用一个T-Net对点云构造转换矩阵进行特征空间对齐。
PointNet通过点云的全局特征完成了点云的分类与分割,但也忽略了局部特征,后续为了解决这一问题,PointNet++被提出,通过将点分层,在每层内分组来学习特征,这允许网络从更大的局部区域内来逐步学习点特征。另外,为了解决点云中密度不均匀的问题,设计了一种多分辨率组合算法,由两部分向量组成,一部分是对这部分所有点进行特征提取所得到的向量,即为局部的全局特征向量;另一部分是对子集进行特征提取,即为局部的局部特征向量。该算法较好地提升了多尺度组合算法的计算速度。后续的改进也大多集中在如何学习到更为丰富的每个点关联的上下文信息和局部结构,主要发展为以下几个方法,包括相邻特征池,基于注意力的聚合以及局部全局特征串联的方法。
虽然PointNet没有关注局部特征信息,难以适用于复杂或点云密度不均匀的场景,但由于其开创性的思想,为后来的点云语义分割研究提供了很好的借鉴意义。
2.3.2 点卷积方法
卷积操作的优点是能够很好的提取规则数据的空间信息,但点云数据本身所固有的不规则性使普通的卷积操作无法直接应用于原始点云数据。
PointCNN:设计了一种Xtransformation先对点云数据进行规则化处理,重新加权和排列各点的相关联特征,保留点云的空间位置信息,然后对处理过的点云进行传统的卷积操作。PointCNN能够利用数据中以网格形式密集表示的空间局部相关性,因此在点云分割和分类上取得了比较好的表现,但在这些点关联的特征上直接求核的卷积会导致部分形状信息的丢失,还存在因点云顺序不同导致计算结果存在差异的问题。
除此之外,也有直接对传统的卷积操作进行改进的方法,Thomas等人[15]提出的核点卷积网络KPConv,将点云空间中的三维点作为卷积中心,坐标点之间的相对位置信息使用欧氏距离,通过多个卷积中心和根据距离赋予每个点不同的权重值来保存实际三维空间的位置信息。通过两种不同的卷积中心,一种刚性的Rigid Kernel处理均匀分布的简单任务,一种可变的Deformable Kernel处理位置变化的复杂任务。
2.3.3 基于RNN的方法
循环神经网络(RNN)用于点云语义分割主要是为了获取点云本身固有的上下文特征,空间上下文信息对于分割性能的提高很重要。
Ye等人[17]提出一种用于非结构化点云语义分割的新型端到端方法,构建了一个高效的金字塔池化模型来提取3D点云的局部信息,再通过一个双向的RNN提取空间的点云全局依赖性。两个RNN通过不同的方向扫描3D空间提取信息,通过使用两个方向上的层级顺序RNN来融合不同尺度的局部信息以获得更大范围的上下文信息,最终达到良好的3D语义分割的效果。但过多的融合局部特征会丢失原始点云的丰富的几何特征。
2.3.4 基于图优化的分割
基于图的分割方法,是通过建立点之间的关系,将点云数据转变为图数据,再对这个图数据进行卷积计算,即选用合适的图卷积神经网络对其进行表征学习。
基于图的方法的思想是将点云中每个点视为图的顶点,与其领域点构成图的有向边,以此来捕获点云的底层形状和几何结构。
该方法的优点是图卷积能够聚合物体的点集特征,并且保持其三维空间的平移不变性,但怎么合适地建立点与点之间的关系还是一个待解决地难题。
3 总结
点云数据与普通图像相比具有稀疏性、不规则性、无序性等特点,且对算法效率、内存占用等方面的要求较高,传统的算法难以对三维点云数据进行处理和建模。相比传统方法,基于深度学习对点云数据进行特征提取能够应用于更多的场景,分割效果也更好,基于图卷积神经网络的三维点云分类和分割算法也得到越来越多人的关注和研究。
基于点的网络是目前最常用的研究方法,也有一些点-体素或其他表示方式的联合方法也表现出良好的分割性能,多方法的融合为点云分割领域带来了更多的可能性,目前已有一些工作试图结合不同深度学习方法的优点,但还未取得较好的效果。因此,未来对于不同方法之间的融合是点云数据语义分割仍研究的难点和重点。
参考文献
- Y. H. Qu, Q. Pan, J.G. Yan. Flight path planning of UAV based on heuristically search agenetic algorithmns Industrial Electronics Society, 2005C]. IECON 2005. 31st Annt Conference of IEEE.IEEE,NC,USA,2005.
- F. J. Lawin, M. Danelljan, P. Tosteberg, G. Bhat, F. S.landM.Felsberg,“Deep projective 3D semantic segmtion,”inCAIP,2017.
- Chen X,Ma H,Wan J,et al. Multi-view 3d object detection nProceedings of the IEEE conference on Computer Vision and Pattern Recognition.2017:1907-1915
- Isacson D,Smedh K,Nikberg M, et al. Long – term follow – up of the AVOD ramdomized trial of antibiotic avoidance in uncomplicated diverticulitis[J]. British Journal of Surgery,2019,106(11):1542-1548
- Boulch A, Guery J, Le Saux B, et al SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks[J].Computers & Graphics,2018,71:189-198.
- Wu, A. Wan, X. Yue, and K. Keutzer,“SqueezeSeg: Convolutional neural nets with recurrent CRF for real-time road object segmentation from 3D LiDAR point cloud,”in Proc.IEEE Int. Conf. Robot.Autom.,2018,pp.1887-1893.
- Milioto, I. Vizzo, J. Behley, and C. Stachniss“RangeNet+ +:Fast and accurate LiDAR semantic segmentation,”in Proc. IEEE/ RSJInt. Conf.Intell.Robots Syst.,2019, pp. 4213-4220.
- J. Huang and S. You, “Point cloud labeling using 3D convolutional neural network,inICPR,2016.
- Liu B,Wang M,Foroosh H,et al Sparse convolutional neural networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition.2015:806-814
- Klokov R, Lempitsky V. Escape from cells: Deep kd-networks for the recognition of 3d point cloud models[C]. Proceedings of the IEEE International Conference on Computer Vision.2017:863-872.
- Riegler G,Osman Ulusoy A,Geiger A. Octnet: Learning deep 3d representation at high resolutions[C]. Proceedings of the IEEE conference on computer vision and pattern recognition 2017:3577-3586.
- Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C] //Proceedings of the IEEE conference on computer vision and pattern recognition.2017:652-660
- Qi C R, Yi L, Su H, et al. Pointnet+ +: Deep hierarchical feature learning on point sets in a metric space. Proceedings of the Advances in Neural Information Processing Systems[C]2017: 5099-5108.
- Li, Yangyan, et al. “Pointcnn: Convolution on x-transformed poin-ts.”Advances in neural information processing systems31 (2018).
- Thomas, Hugues, et al. “Kpconv: Flexible and deformableconvolution for point clouds.”? Proceedings of the IEEE/CVF international conference on computer vision. 2019.
- F.Engelmann,T.Kontogianni,A.Hermans,and B.Leibe,“Exploring spatial context for 3D semantic segmentation of point clouds,”in Proc. IEEE/CVF Int.Conf.Comput.Vis.,2017,pp. 716-724.
- L. Landrieu and M.Simonovsky, “Large-scale point cloud sem-antic segmentation with superpoint graphs,” in Proc. IEEE/ CVFConf. Comput. Vis. Pattern Recognit, 2018,pp.4558-4567
- L. Landrieu and M. Boussaha, Point cloud oversegmentationwith graph-structured deep metric learning,”in Proc. IEEE/CVFConf. Comput. Vis. Pattern Recognit., 2019, pp. 7432-7441.
文章出处登录后可见!