知乎:Vision Transformer 超详细解读 (原理分析+代码解读)
CSDN:vit 中的 cls_token 与 position_embed 理解
Vision Transformer在一些任务上超越了CNN,得益于全局信息的聚合。在ViT论文中,作者引入了一个class token作为分类特征。
如果没有cls_token,我们使用哪个patch token做分类呢?
根据自注意机制,每个patch token一定程度上聚合了全局信息,但是主要是自身特征。ViT论文还使用了所有token取平均的方式,这意味每个patch对预测的贡献相同,似乎不太合理。实际上,这样做的效果基本和引入cls_token差不多。
ViT引入class token机制,究其原因:
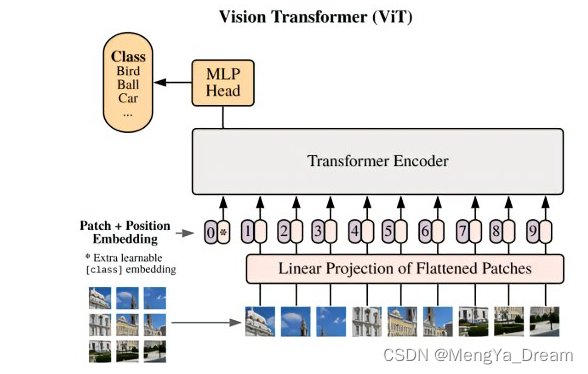
Transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后要总结为一个类别的判断。
- 可以用avg pool,把所有的patch feature 都考虑算出image feature,如上述不太合理。。
- 作者引用类似flag的class token,其输出特征加上一个线性分类器就可以实现分类。
- 训练的时候,class token的embedding被随机初始化并与pos embedding相加,因此从图可以看到输入transformer的时候【0】处补上一个新embedding,最终输入长度N+1.
第n+1个token(class embedding)的主要特点是:不基于图像内容;位置编码固定。
优势:
- 该token随机初始化,并随着网络的训练不断更新,它能够编码整个数据集的统计特性;
- 该token对所有其他token上的信息做汇聚(全局特征聚合),并且由于它本身不基于图像内容,因此可以避免对sequence中某个特定token的偏向性;
- 对该token使用固定的位置编码能够避免输出受到位置编码的干扰。
ViT中作者将class embedding视为sequence的头部而非尾部,即位置为0。这样即使sequence的长度n发生变化,class embedding的位置编码依然是固定的,因此,更准确的来说class embedding应该是第0个而非第n+1个token。
另外“将前n个token做平均作为要分类的特征是否可行呢”,这也是一种全局特征聚合的方式,但它相较于采用attention机制来做全局特征聚合而言表达能力较弱。因为采用attention机制来做特征聚合,能够根据query和key之间的关系来自适应地调整特征聚合的权重,而采用求平均的方式则是对所有的key给了相同的权重,这限制了模型的表达能力。
The class token:与 input token 并在一起输入 Transformer block 的一个向量,最后的输出结果用来预测类别。这样一来,Transformer相当于一共处理了 N+1 个维度为 D 的token,并且只有最后一个token的输出用来预测类别。这种体系结构迫使patch token和class token之间传播信息。
遗留:
- class embedding应该是第0个而非第n+1个token。
- 只有最后一个token的输出用来预测类别。
- 两者是否矛盾?做何理解?
文章出处登录后可见!