前言
VoxCeleb1 是广泛使用的 说话人识别、验证 数据集。由于是从 YouTube 视频中提取,有比较丰富的噪声。(有空补介绍)
如果可以使用谷歌表单和翻译软件应该就可以顺利下载,私下分发数据集有侵权风险。
正文
官网如下:
VoxCeleb![]() https://www.robots.ox.ac.uk/~vgg/data/voxceleb/
https://www.robots.ox.ac.uk/~vgg/data/voxceleb/
但是很神奇的是现在(2022-7-12),这个网站所有的下载链接被取消了。
VoxCeleb![]() https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html
https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html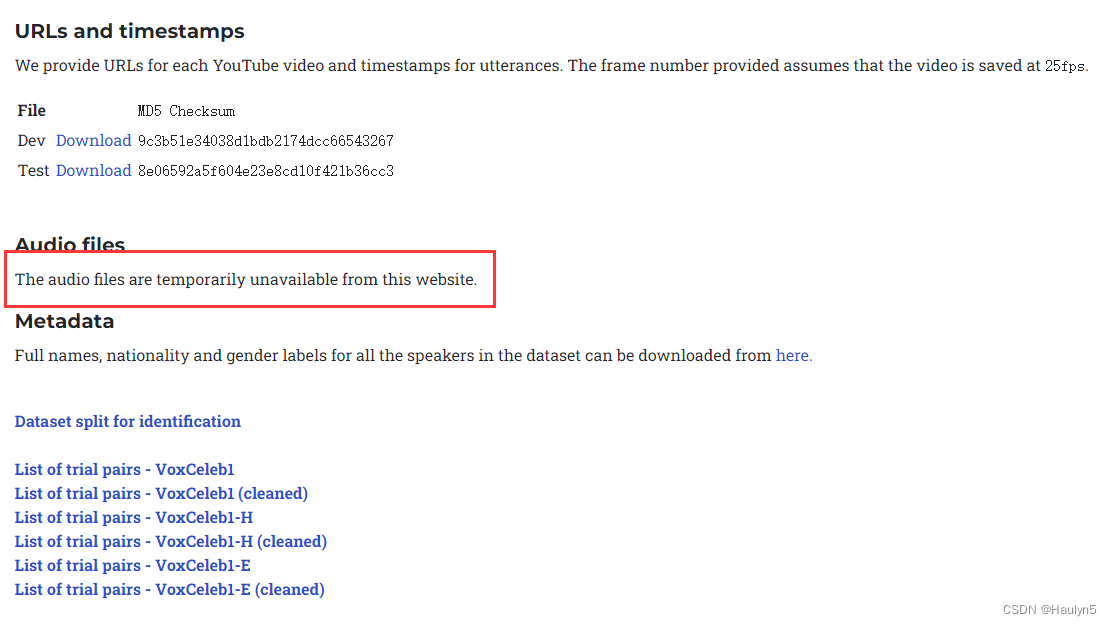
可以看到,只能下载到 Metadata,音频文件暂时不可用。
搜了好久后发现在下面的链接可以下载,一开始担心不是官网,后面发现这是一个韩国的实验室,承接了第四次的 VoxCeleb Speaker Recognition Challenge (VoxSRC)
VoxCeleb![]() https://mm.kaist.ac.kr/datasets/voxceleb/下载前需要填个 Google Form,填入单位姓名等。由于是自动流程,所以填完不久就可以检查邮箱收件箱了,会看到一个邮件给出了 用户名和口令。
https://mm.kaist.ac.kr/datasets/voxceleb/下载前需要填个 Google Form,填入单位姓名等。由于是自动流程,所以填完不久就可以检查邮箱收件箱了,会看到一个邮件给出了 用户名和口令。
这里有说明,给出的身份只能使用 1 个月。
获得用户名和口令之后就好办了,使用 Windows 和浏览器的可以直接在下面的链接找到对应的数据集下载,因为过大所以官方做了分片,具体的操作官网有详细说明,下载的时候点击链接,会弹出需要填入用户名和口令,输入即可开始下载。VoxCeleb![]() https://mm.kaist.ac.kr/datasets/voxceleb/
https://mm.kaist.ac.kr/datasets/voxceleb/
额外补充一下,Linux 环境的下载命令。
wget http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox1_test_wav.zip --http-user=username--http-passwd=password将 链接 `http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox1_test_wavip` 切换为你需要下载的文件,然后 username 和 password 做替换即可。
官网给出了 md5,可以顺手校验一下。
md5sum vox1_dev_wav.zip然后是解压,用 unzip 命令。
unzip -d vox1_dev_wav vox1_dev_wav.zip然后就大工搞成了,数据集的使用可以参照 GitHub 找 voxceleb trainer,此外用 Pytorch 的用户可以参照 torchaudio.datasets.voxceleb1 — Torchaudio nightly documentation。这个 API 比较新,比较古早的版本可能没有。
补充
对于将要使用这个数据集 Train 模型的同学补充说明一下,Identification 任务的训练也是要下载 Test 数据的。
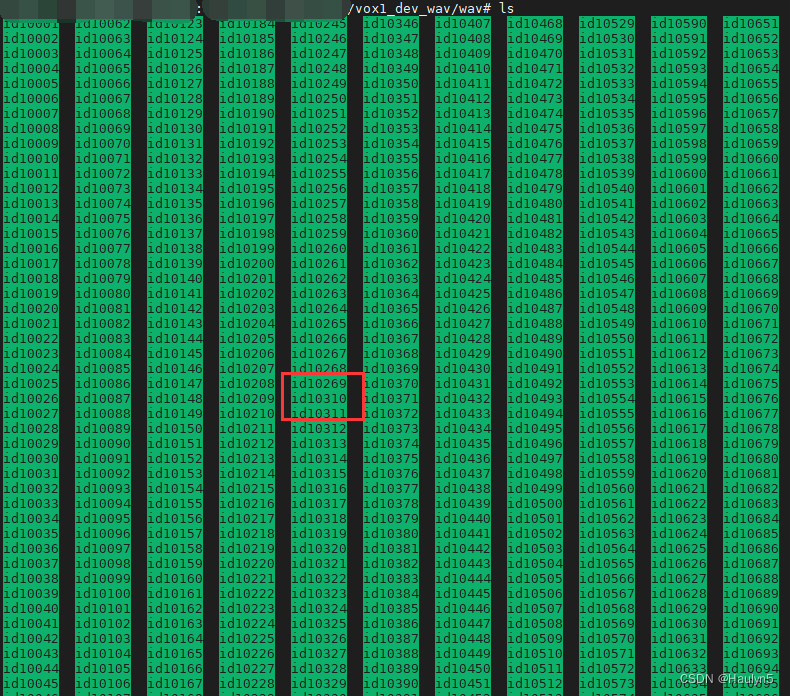
直接用 https://mm.kaist.ac.kr/datasets/voxceleb/meta/iden_split.txt 这个文件读取数据集,会报错,id10270-id10309 的数据是缺失的,但是 iden_split 这个文件却标注了一些 id 在这个范围的说话人的数据为 Training,我本以为只用 Training Data (因为不是做 ASV)所以没有下载 Test……结果就报错了,找不到音频文件。

文章出处登录后可见!