1.前言
对于yolov5一直在更新优化,这个自然不用多说,在目标检测领域占有量很大;所以写一下相关原理及代码方面的笔记也是有意义的对于自己和想了解yolov5的小伙伴。
2.模型原理
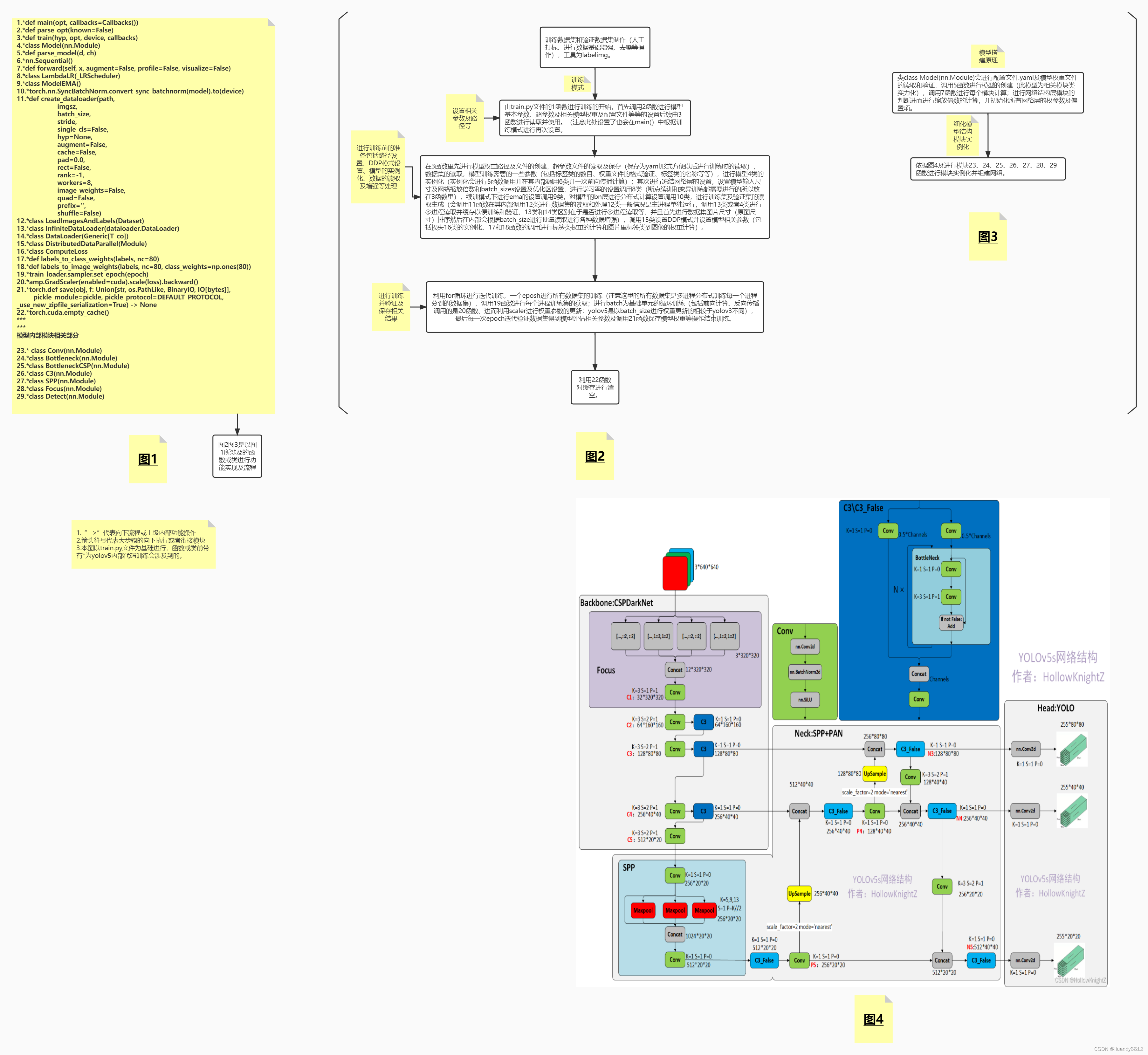
1)首先附上网络模型结构,如下图:
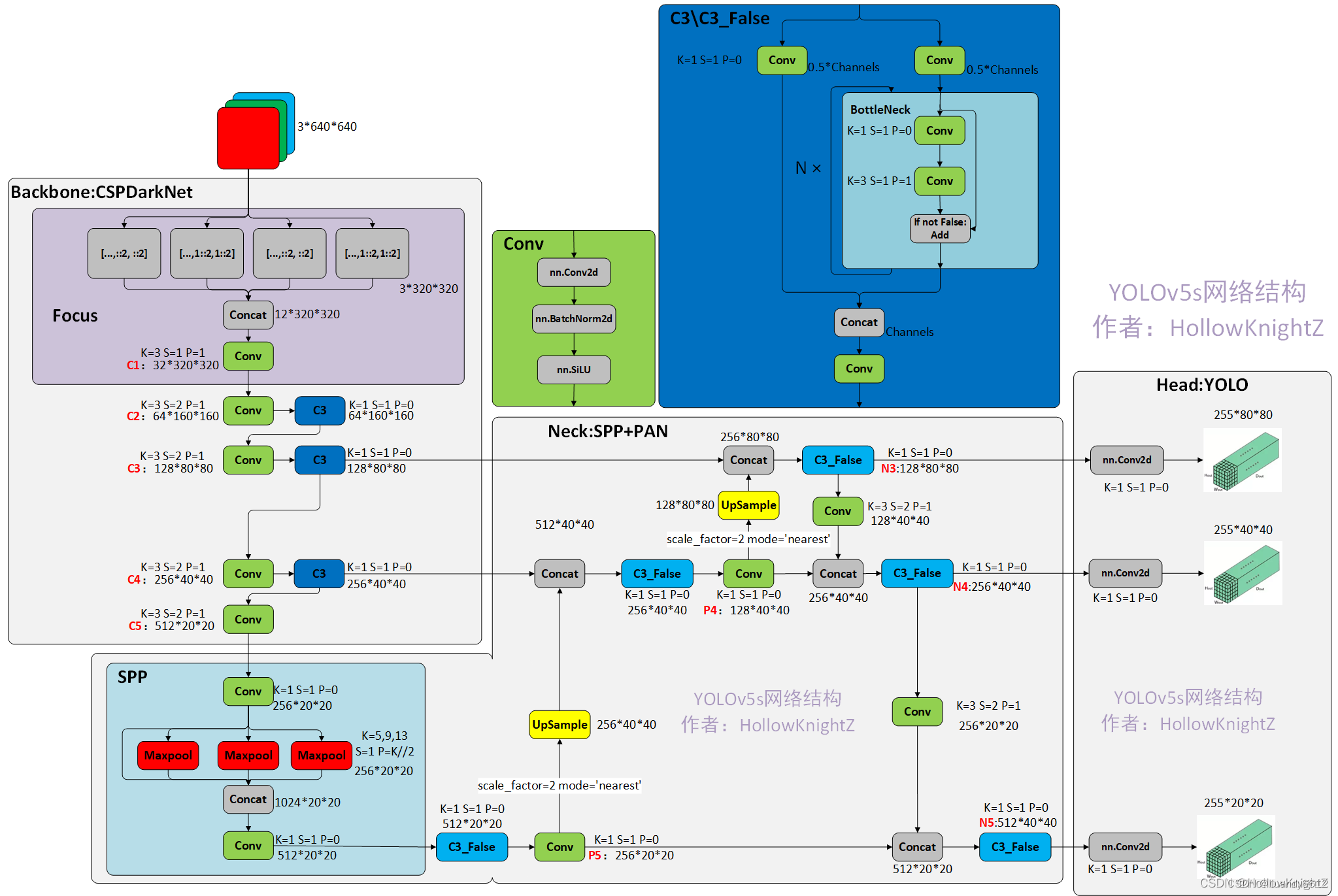
(注:图片借鉴网上相关领域大佬制作的图片,如有侵权请联系本人删除处理)
2)模型主要结构分为:Input、Backbone、Neck、Head_yolo;我们着重讲后三个(Input层就是图片或视频帧输入,模型尺寸默认3*640*640)。
Ⅰ.Backbone:借鉴了CSPNet的思想,于是有了CSPDarkNet;CSP结构主要应用在Backbone(CSP1_X)和Neck(CSP2_X),CSP1_X、CSP2_X区别参考下图:
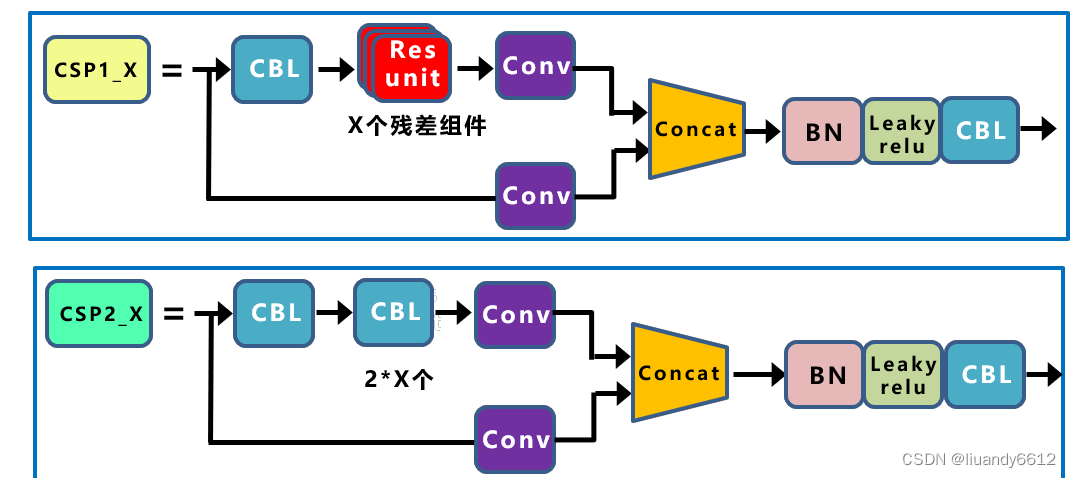
Focus结构:主要实现的是切片操作,举例:以Yolov5s的结构为例,原始640*640*3的图像输入Focus结构,采用切片操作,先变成320*320*12的特征图,再经过一次32个卷积核的卷积操作,最终变成320*320*32的特征图。
Ⅱ.Neck结构:结构包括SPP、FPN、PAN(在yolov5优化过程中添加,之初是没有的)。
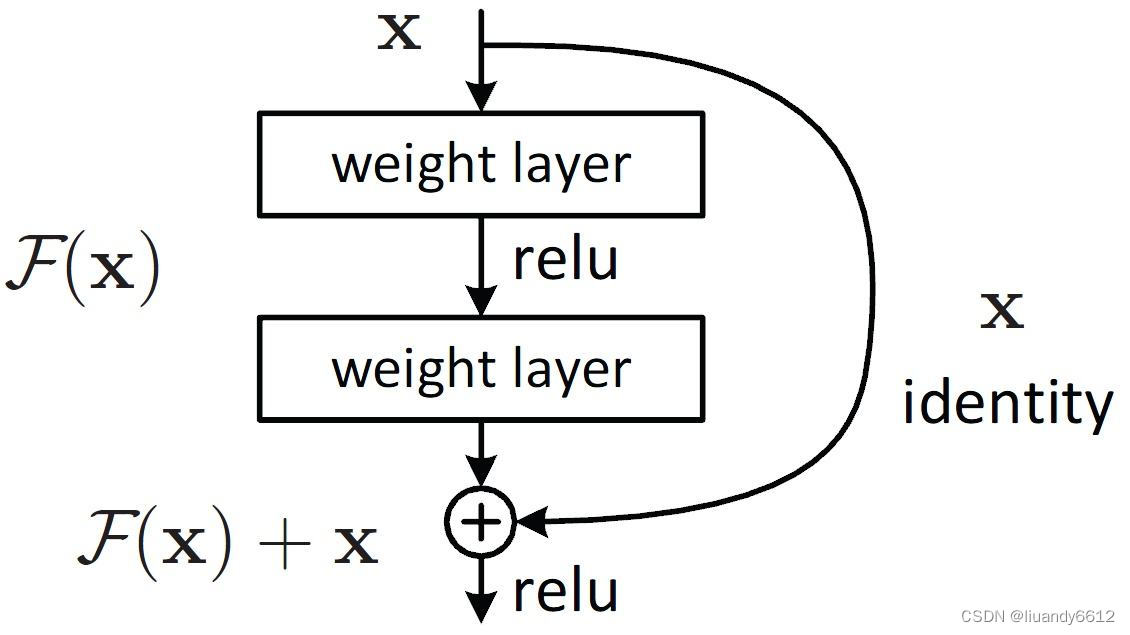
SPP:借鉴了残差网络的思想,提高的网络面临深度的增加使网络退化的问题,缓解了梯度消失;其结构示意图如下:
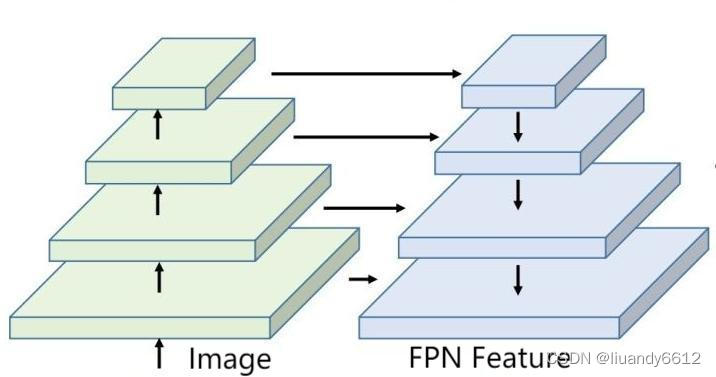
FPN: 结合多层级特征来解决多尺度问题的特征金字塔模型,浅层或者说前级过来的特征图利于定位,深层特征图(此级特征图)包含高级语义信息,这是利于小目标的(但是效果不是那么好);结构示意图如下:
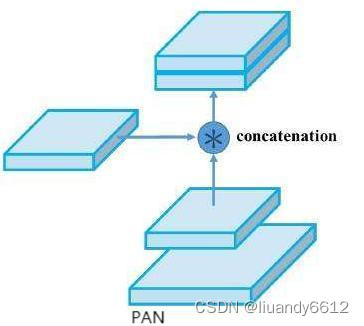
PAN:为了解决小目标的效果,对FPN网络进行了补充(补充点主要为对于定位信息),FPN属于下采样,PAN属于上采样;结构示意图如下:
Ⅲ.Head_yolo结构:输出网络模型的结果:255*80*80,255*40*40,255*20*20三层网络输出分别对应目标大小顺序为;小,中,大。
3)总结:1.yolov5在训练阶段进行损失计算时采用的是聚焦损失函数,并且采用的是CIOU_Loss;
2.在预测阶段nms非极大值抑制采用的是DIOU_nms并加权,所达到的效果会有所提高。
3.代码流程及说明(主要以train.py进行)
附上流程图片结合train.py进行理解,流程图如下:
(注:以上图片有任何侵权请联系本人账号,进行删除操作,具体细节问题需要小伙伴们自己摸索理解,这里只概括性描述!!!)
文章出处登录后可见!