参考文章:AI菌的 从yolov1至yolov5
目标检测-Yolo系列发展
截止2023.1.17,Yolo系列已经出到了Yolo v8
Yolo中,目标检测=目标分类+目标定位
分类:得类别; 回归:得边界框(边界框回归模型)、置信度
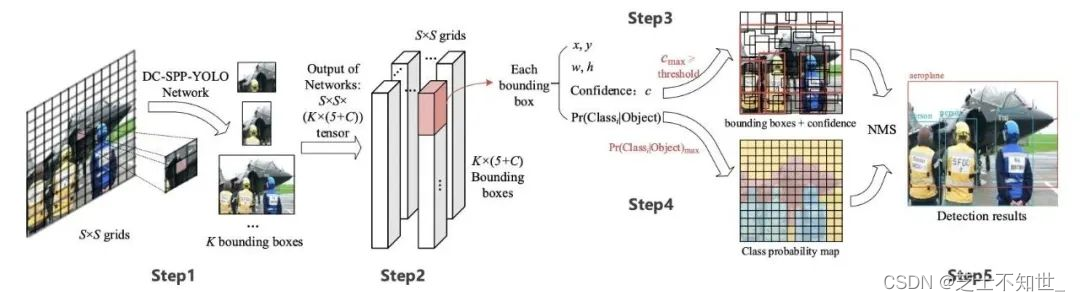
将图片分割成SxS个网格,head学到的特征图是SxSx(5+5+class_num),其中5=(x, y, w, h, confidence),两个5表示,每个网格有两个先验框Anchor 。
- Bounding box预测框:起点(预测值)
- Anchor box先验框:中介
- Ground trueth box真值框:终点(标签)
先验框/锚框/候选框 Anchor机制
为什么引入先验框Anchor(锚框/候选框)?
由于真实框ground trueth的数据分布非常不统一,直接预测框bounding box的(x,y,w,h)(即直接对预测框bounding box做回归),容易导致了学习到的参数变化大,模型难收敛的问题。
怎么引入Anchor?
虽然我们不能约束预测框的位置,但是可以统一真实框的位置。我们将假设我们将每个网格点的中心坐标不变,长宽都改变为128,把这个长宽都为128的框叫做先验框(Anchor),也就是图中蓝色的框。那么这样模型学习到的系数都会偏向这个先验框。

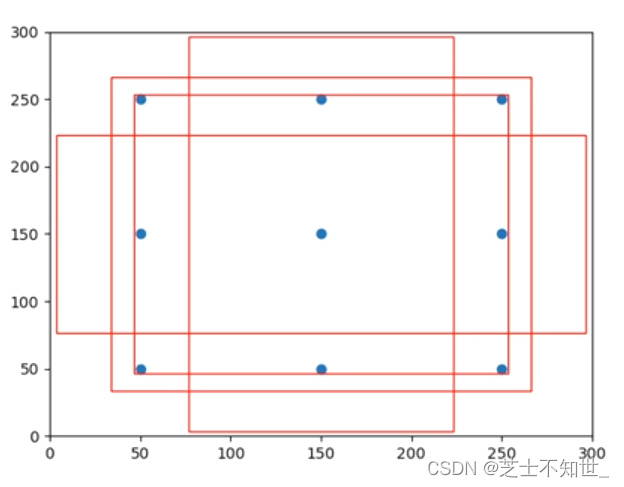
但实际上,为了尽可能地覆盖更多的面积和区域,需要设定多种尺度的先验框,为了后续与真实框(标注的框)尽可能接近。中心坐标不变,不同的长宽比例的先验框。
面对多种尺度的先验框,真实框如何选择合适的anchor又成了一个问题。一般我们选择IOU最大的作为先验框。
固定尺度的anchor也会有缺陷,不能很好的适应所有数据集,所以YOLOv2这一类的目标检测模型使用k-means算法对所有真实框进行筛选,选出最有代表性的几个尺度作为anchor。
一个模型内可能有不同大小的特征层(将原图分割成SxS个格子),分别用于检测不同尺度的物体,其中心点的数量不一样。如:
YOLOv1的目标检测网络只有
7x7的输出特征层。
YOLOv2的目标检测网络只有13x13的输出特征层。
YOLOv3的目标检测网络就有52x52,26x26,13x13的输出特征层。(3尺度)
YOLOv4的目标检测网络就有76x76,38x38,19x19的输出特征层。(3尺度)
…
YOLOv1的每个格子有2个先验框anchor。
YOLOv2的每个格子有5个先验框anchor。
YOLOv3的每个格子有3x3=9个先验框anchor。(每个尺度上3个先验框)
YOLOv4的每个格子有3x3=9个先验框anchor。(每个尺度上3个先验框)
…
总之,先验框Anchor机制就是通过设定众多的候选框,然后针对候选框进行分类和微调,找到目标中最接近的真实框,实现目标检测。这里的候选框也就是锚框。
Anchors Base原理
得到的特征图长宽,可以理解为对图片进行patch切分密集采样(不符合人看的规律)
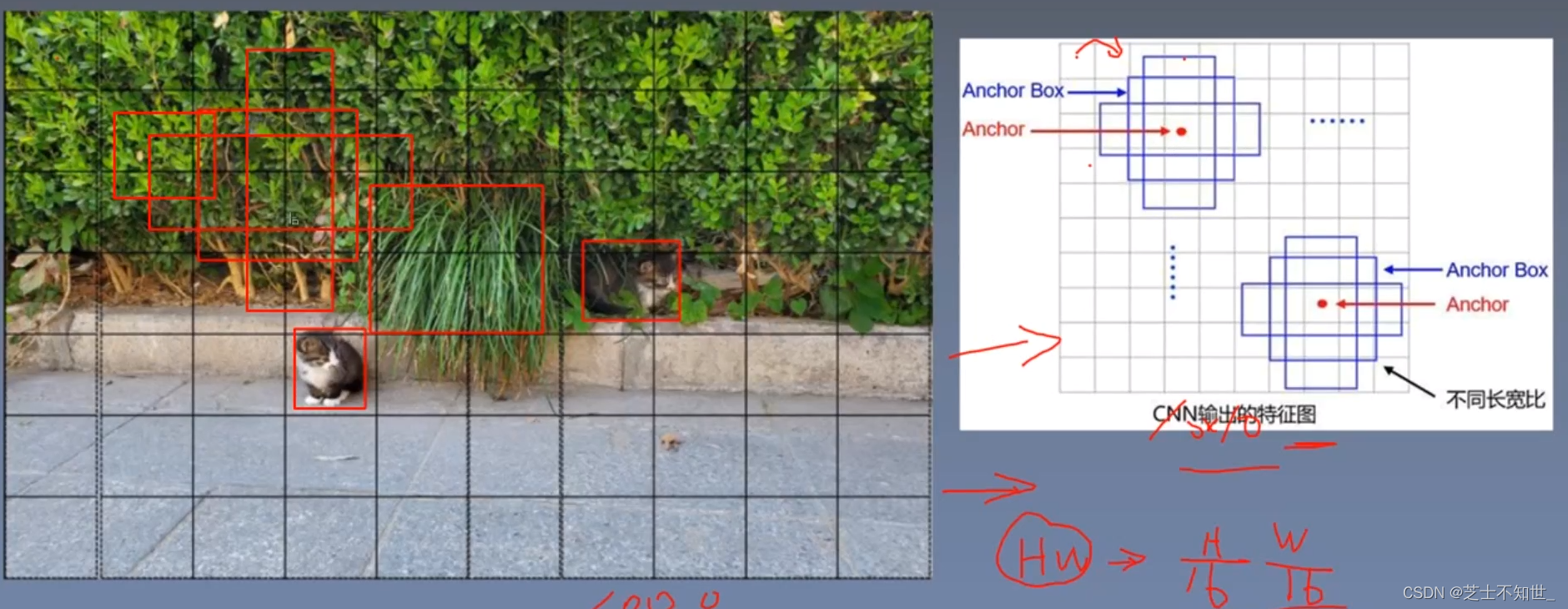
anchor解释为先验/预选框,后面的分类和定位都是基于anchor来做的,其中定位就是对anchor box做一个线性变换。也可以将Anchor box先验框 理解为连接Bbox预测框和GTbox真值框的桥梁。对于每个anchor,有四个代表位置信息的预测值,在yolo v3中这四个值分别是对anchor中心点的偏移量和宽高缩放量。根据anchor坐标和这四个值就可以计算出Bbox预测框的位置,然后用预测框和GT真值框做损失计算,这种理解更符合“学习”的思维方式:正向传播、计算损失、反向传播、梯度下降、正向传播…
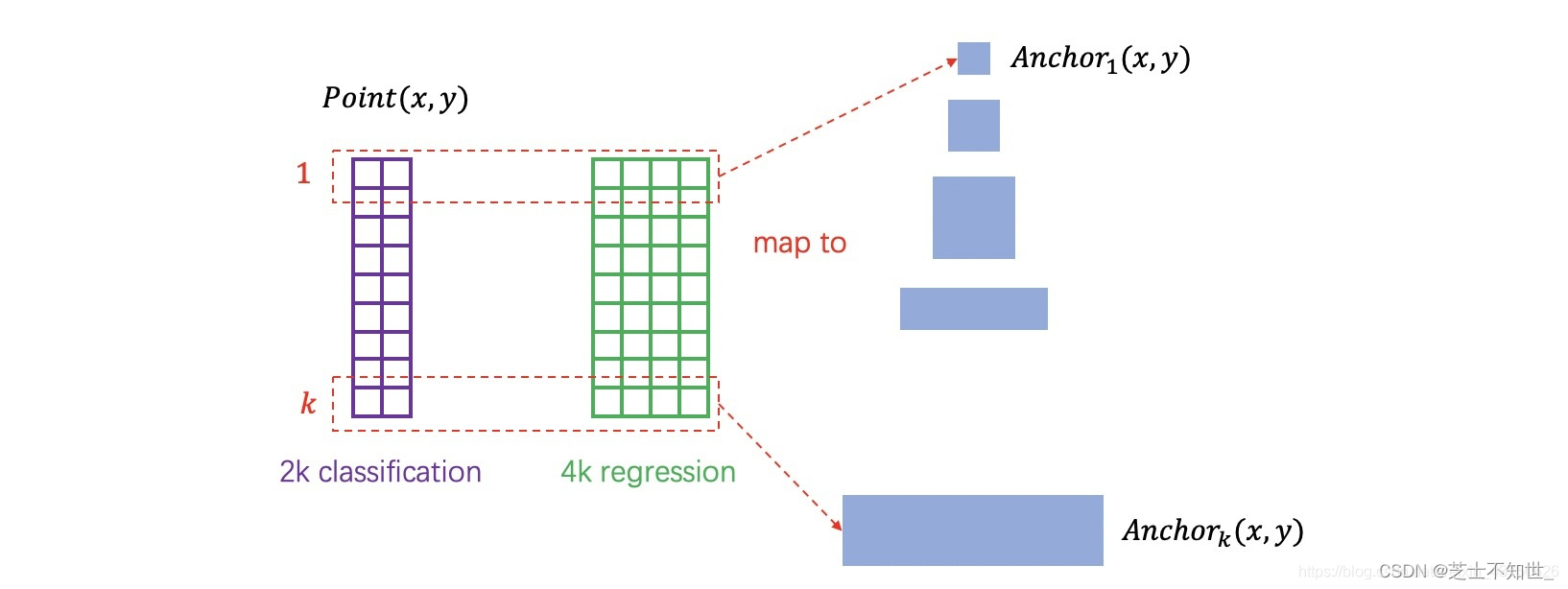
step1:生成数万个矩形框,矩形框就是anchor。
step2:特征图映射回原图,特征图中每个点的k个分类特征与k个回归特征,与k个anchor逐个对应即可,这实际是一种“人为设置的逻辑映射”。
step3:特征提取,判断类别。
step4:回归位置,判断有无目标。
Anchors Free原理
回归计算目标检测框左上和右下角的坐标。
以yolo-v1为例,最后输出一个7×7的网络,然后每个网格预测2个结果,注意不管这里预测多少个结果,其分类只有一个。换句话说每个网格只会负责一个分类,至于边界框可以有多个(Yolo里2个)。
所以,对于anchor-free而言,在特征图中,每个网格负责预测出一个分类,而anchor-base的网络,在特征图中每个节点存储的是以该节点为中心的数个子图的特征,这些特征分别进行分类。本质上来讲:anchor-free根据网格代表的那块图像的特征计算出了分类,而anchor-base则根据周围预设的子图的特征计算分类,而达到这点的手段就是groundtruth的设置规则。
在anchor-free中,物体落到哪个网格,哪个网格就是正样本,其余都是负样本。anchor-base则计算每个anchor和gt的IoU,超过多少阈值就算正。
YOLO v1
YOLO 的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。
Yolov1网络结构

现在看来,YOLOv1的网路结构非常明晰,是一种传统的one-stage的卷积神经网络:
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
Yolov1实现方法
step1: 将一幅图像分成 S×S个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。
step2: 每个网格要预测 B (B=2)个bounding box,每个 bounding box 要预测 (x, y, w, h, c) 共5个值,c是confidence置信度。
step3: 每个网格还要预测一个类别信息,记为 C 个类。
step4: 总的来说,S×S 个网格,每个网格要预测 B个bounding box ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C) 的张量。
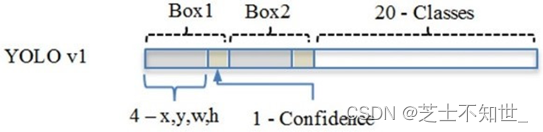 在实际过程中,YOLOv1把一张图片划分为了7×7个网格,并且每个网格预测2个Box(Box1和Box2),20个class类别。所以实际上,S=7,B=2,C=20。那么网络输出的shape也就是:7×7×30。
在实际过程中,YOLOv1把一张图片划分为了7×7个网格,并且每个网格预测2个Box(Box1和Box2),20个class类别。所以实际上,S=7,B=2,C=20。那么网络输出的shape也就是:7×7×30。
Yolov1损失函数
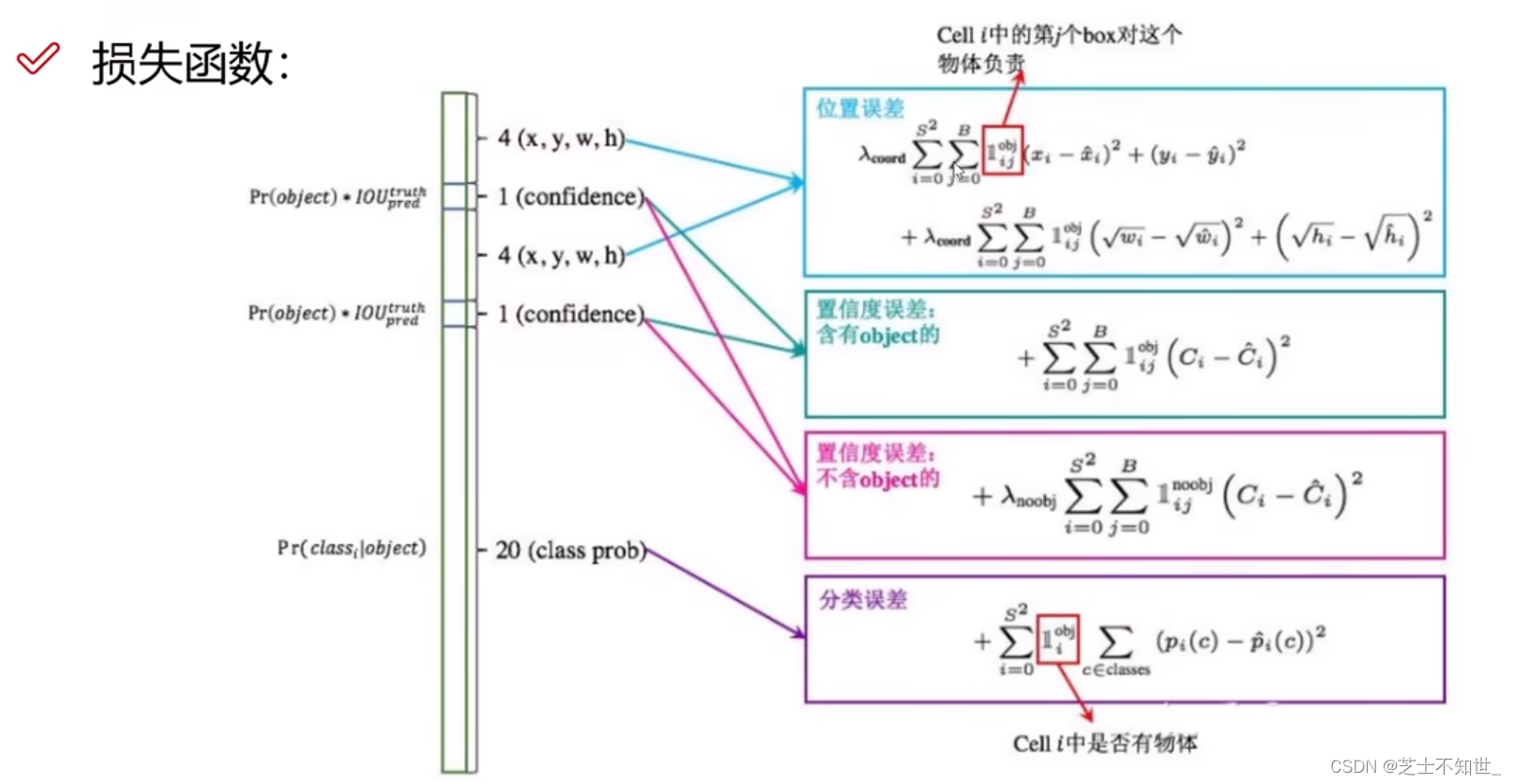
将图片分割为SxS个格子,每个格子有B个先验框。IOU:框的交并比。
误差损失=对每个格子的 IOU最大的先验框,计算MSE损失(wh加根号,解决小物体偏移不敏感问题)
置信度损失=对每个格子的每个先验框,计算有obj损失(前景与GT框的IOU>0,真实值=1),或计算无obj损失(背景与GT框的IOU=0,真实值=0),因为前景多背景少,求和后样本比例不均衡,所以加权重系数调整比例。
分类损失=对每个有obj的格子,计算交叉熵CE损失。

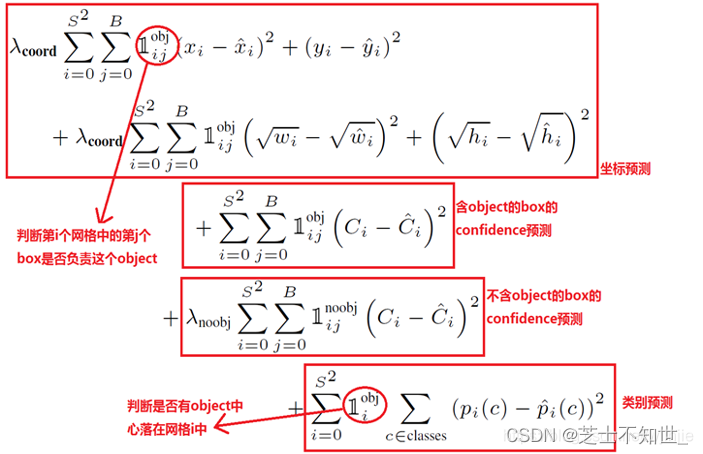
- 总的损失由三部分组成,分别是:坐标预测损失、置信度预测损失、类别预测损失。
- 使用的是差方和误差MSE loss。需要注意的是,w和h在进行误差计算的时候取的是它们的平方根,原因是对不同大小的bounding box预测中,相比于大bounding box预测偏一点,小box预测偏一点更不能忍受。而差方和误差函数中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将bounding box的w和h取平方根代替原本的w和h。
- 定位误差比分类误差更大,所以增加对定位误差的惩罚,使λcoord=5。
- 在每个图像中,许多网格单元不包含任何目标。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失,使 λnoobj=0.5。
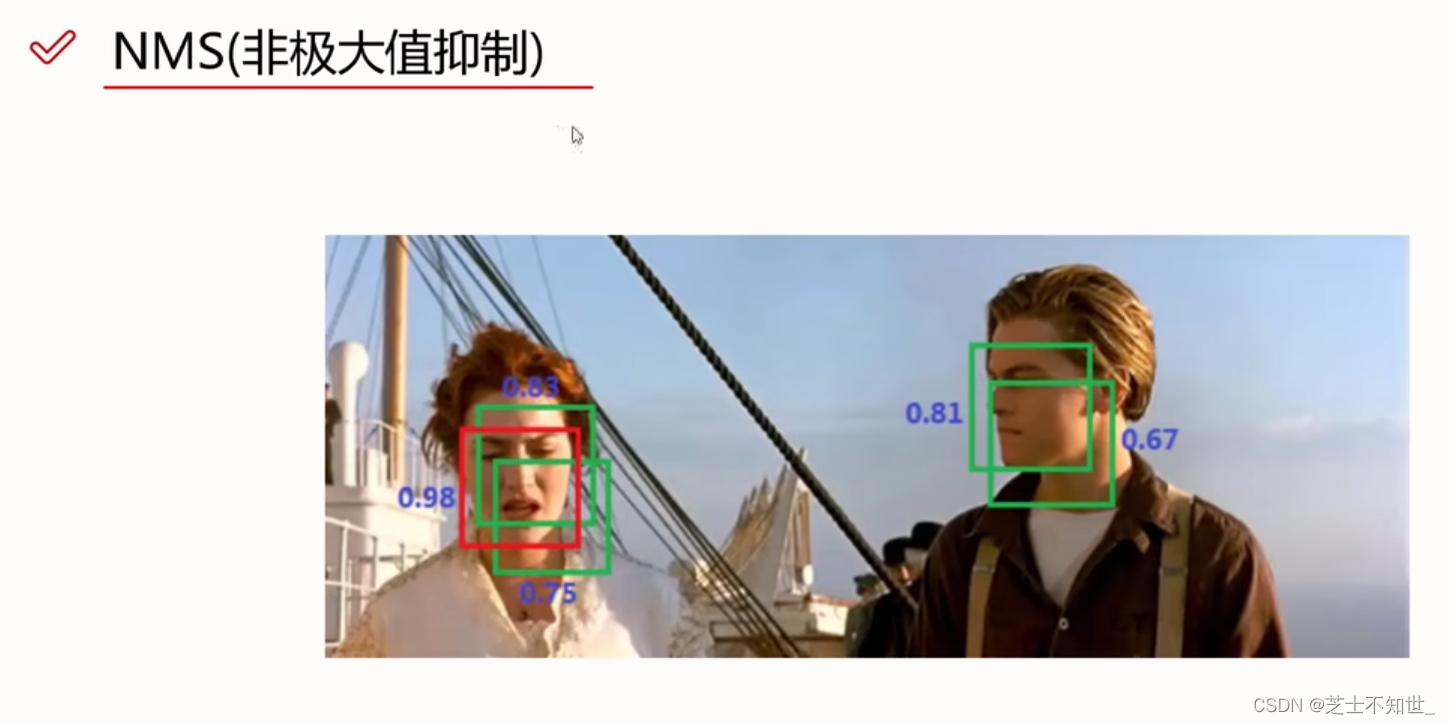
非极大抑制NMS:
IOU>阈值的先验框,按置信度进行排序,只取confidence最大的先验框,其他的框舍弃。
Yolov1总结

YOLO v2
- 重点解决YOLOv1召回率和定位精度方面的不足。
- 高精度与速读:YOLOv2 是一个先进的目标检测算法,比其它的检测器检测速度更快。除此之外,该网络可以适应多种尺寸的图片输入,并且能在检测精度和速度之间进行很好的权衡。
- 高召回率:相比于YOLOv1是利用全连接层直接预测Bounding Box的坐标,YOLOv2借鉴了Faster R-CNN的思想,引入Anchor机制。利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率。
- 适合小目标:同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
- 识别类多:YOLO9000 使用 WorldTree 来混合来自不同资源的训练数据,并使用联合优化技术同时在ImageNet和COCO数据集上进行训练,能够实时地检测超过9000种物体。
Yolov2网络结构

Backbone:Darknet-19
- 与VGG相似,使用了很多3×3卷积核;并且每一次池化后,下一层的卷积核的通道数 = 池化输出的通道 × 2。
- 在每一层卷积后,都增加了批量标准化(Batch Normalization)进行预处理。
- 采用了降维的思想,把1×1的卷积置于3×3之间,用来压缩特征。
- 在网络最后的输出增加了一个global average pooling层。
- 整体上采用了19个卷积层,5个池化层。
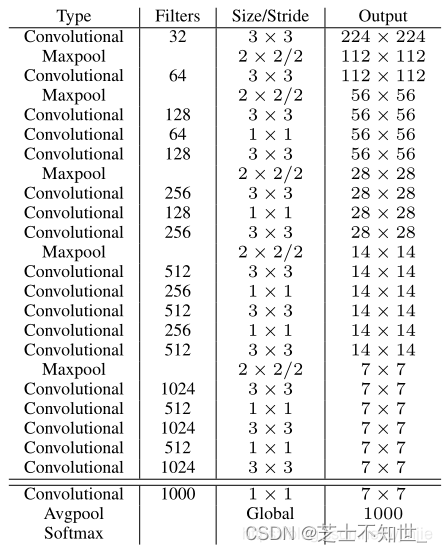
Darknet-19 与 YOLOv1、VGG16网络对比:
VGG-16: 大多数检测网络框架都是以VGG-16作为基础特征提取器,它功能强大,准确率高,但是计算复杂度较大,所以速度会相对较慢。因此YOLOv2的网络结构将从这方面进行改进。
YOLOv1: 基于GoogLeNet的自定义网络(具体看上周报告),比VGG-16的速度快,但是精度稍不如VGG-16。
Darknet-19: 速度方面,处理一张图片仅需要55.8亿次运算,相比于VGG306.9亿次,速度快了近6倍。精度方面,在ImageNet上的测试精度为:top1准确率为72.9%,top5准确率为91.2%。
Yolov2改进细节

1.Batch Normalization批归一化
每层输入时,对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。基于此,YOLOv2 对每一层输入的数据都进行批量标准化,这样网络就不需要每层都去学数据的分布,收敛会变得更快。
BN算法实现:在卷积或池化之后,激活函数之前,对每个数据输出进行标准化,减去均值,除以方差。
2.Anchor Box 先验框生成机制
在YOLOv1中,作者设计了端对端的网路,直接对边界框的位置(x, y, w, h)进行预测。这样做虽然简单,但是由于没有类似R-CNN系列的推荐区域,所以网络在前期训练时非常困难,很难收敛。于是,自YOLOv2开始,引入了 Anchors box 机制,希望通过提前筛选得到的 具有代表性先验框Anchors,使得网络在训练时更容易收敛。
在 Faster R-CNN算法中,是通过预测 bounding box(预测框) 与 ground truth(真值标签) 的位置偏移值 tx, ty,间接得到bounding box的位置。其公式如下:
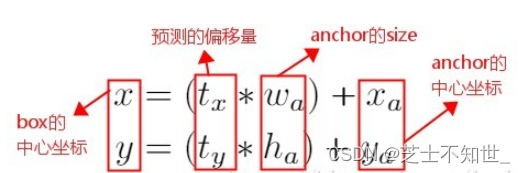
这个公式是无约束的,预测的边界框很容易向任何方向偏移,应防止偏移量太大大,导致此格子不在其预测框内(将tx,ty转换为相对grid cell的偏移,并约束在一个小范围[0,1])。因此,每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性。
因此 YOLOv2 在此方法上进行了一点改变:预测边界框中心点相对于该网格左上角坐标( Cx , Cy )的相对偏移量tx,ty,同时为了将bounding box的中心点约束在当前网格中,使用 sigmoid 函数将 tx, ty归一化处理,将值约束在0-1,这使得模型训练更稳定。
下图为 先验框Anchor box 与 预测框bounding box 转换示意图,其中蓝色的是要预测的bounding box,黑色虚线框是Anchor box。
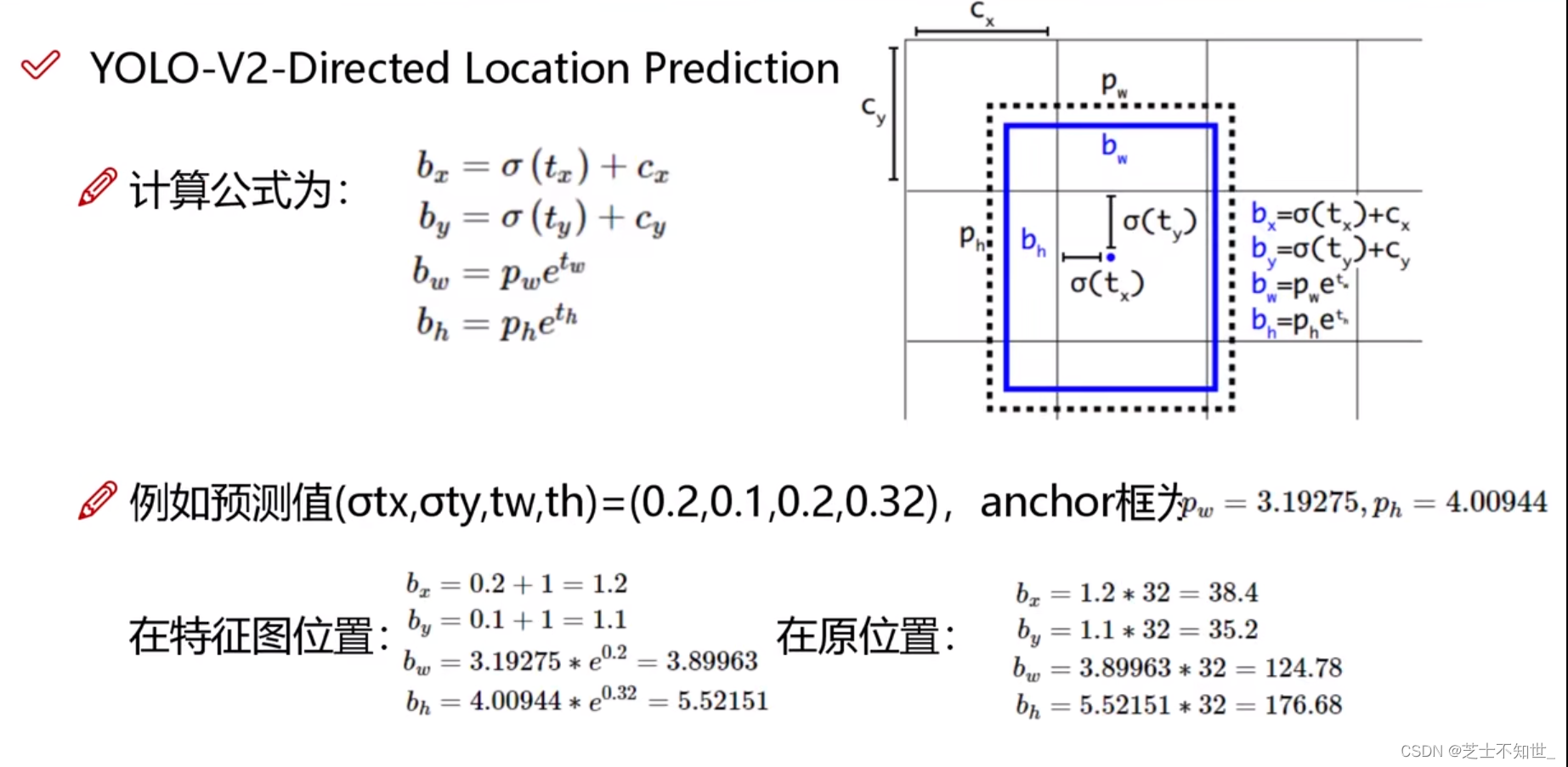
YOLOv2 在最后一个卷积层输出 13×13 的 feature map,意味着一张图片被分成了13×13个网格。每个网格有5个anchor box来预测5个bounding box,每个bounding box预测得到5个值tx、ty、tw、th、to (类似YOLOv1的confidence)。引入Anchor Box 机制后,通过间接预测得到的 bounding box 的位置的计算公式如上图。
置信度 to 的计算公式为:
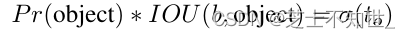
3.Convolution With Anchor Boxes卷积 替换 全连接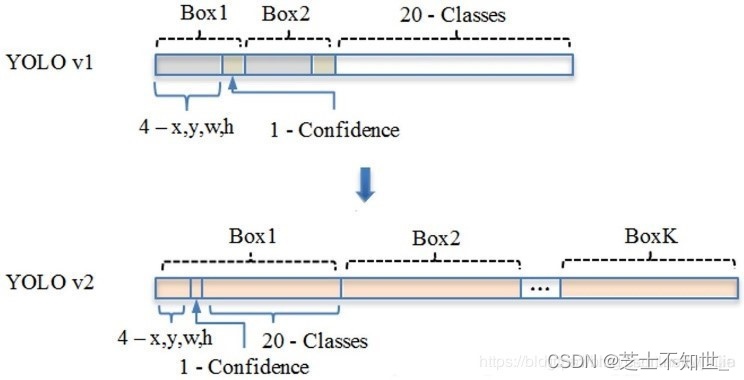
YOLOv1 有一个致命的缺陷就是:一张图片被分成7×7的网格,一个网格只能预测一个类,当一个网格中同时出现多个类时,就无法检测出所有类。针对这个问题,YOLOv2做出了相应的改进:
- 首先将YOLOv1网络的FC层和最后一个Pooling层去掉,使得最后的卷积层的输出可以有
更高的分辨率特征。 - 然后缩减网络,用416×416大小的输入代替原来的448×448,使得网络输出的特征图有奇数大小的宽和高,进而使得每个特征图在划分单元格的时候只有一个中心单元格(Center Cell)。YOLOv2通过5个Pooling层进行下采样,得到的输出是
13×13的像素特征。 - 借鉴Faster R-CNN,YOLOv2通过引入
Anchor Boxes,预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。 - 采用Faster R-CNN中的方式,
每个Cell可预测出9个Anchor Box,共13×13×9=1521个(YOLOv2确定Anchor Boxes的方法见是维度聚类,每个Cell选择5个Anchor Box)。比YOLOv1预测的98个bounding box 要多很多,因此在定位精度方面有较好的改善。
4.Kmean聚类 选择先验框Anchors
Faster R-CNN 中 Anchor Box 的大小和比例是按经验设定的,不具有很好的代表性。若一开始就选择了更好的、更有代表性的先验框Anchor Boxes,那么网络就更容易学到准确的预测位置了!(5类)
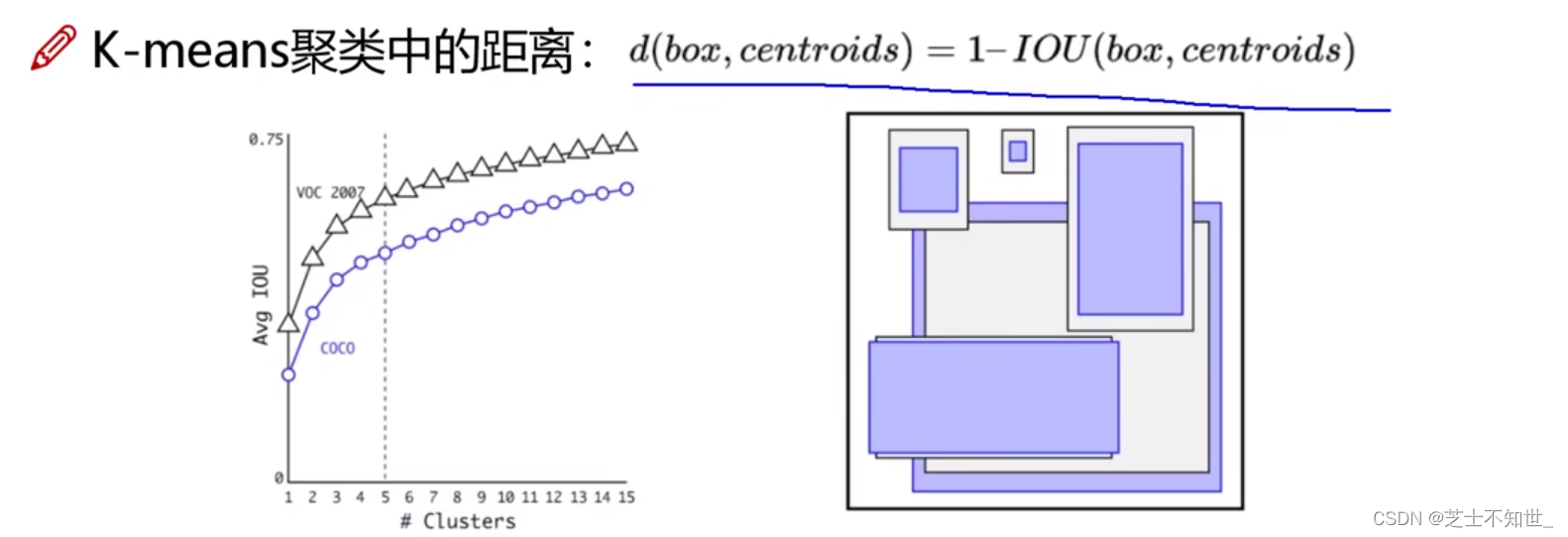
YOLOv2 使用 K-means 聚类方法得到 Anchor Box 的大小,选择具有代表性的尺寸的Anchor Box进行一开始的初始化。传统的K-means聚类方法使用标准的欧氏距离作为距离度量,这意味着大的box会比小的box产生更多的错误。因此这里使用其他的距离度量公式,不是欧式距离,而是(1-IOU)。聚类的目的是使 Anchor boxes 和临近的 ground truth boxes有更大的IOU值,因此自定义的距离度量公式为 :
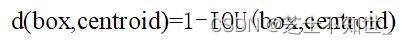
到聚类中心的距离越小越好,但IOU值是越大越好,所以使用 1 – IOU;这样就保证距离越小,IOU值越大。
YOLOv2采用5种 Anchor 比 Faster R-CNN 采用9种 Anchor 得到的平均 IOU 还略高,并且当 YOLOv2 采用9种时,平均 IOU 有显著提高。说明 K-means 方法的生成的Anchor boxes 更具有代表性。为了权衡精确度和速度的开销,最终选择K=5。
5.细粒度特征 Fine-Grained Features

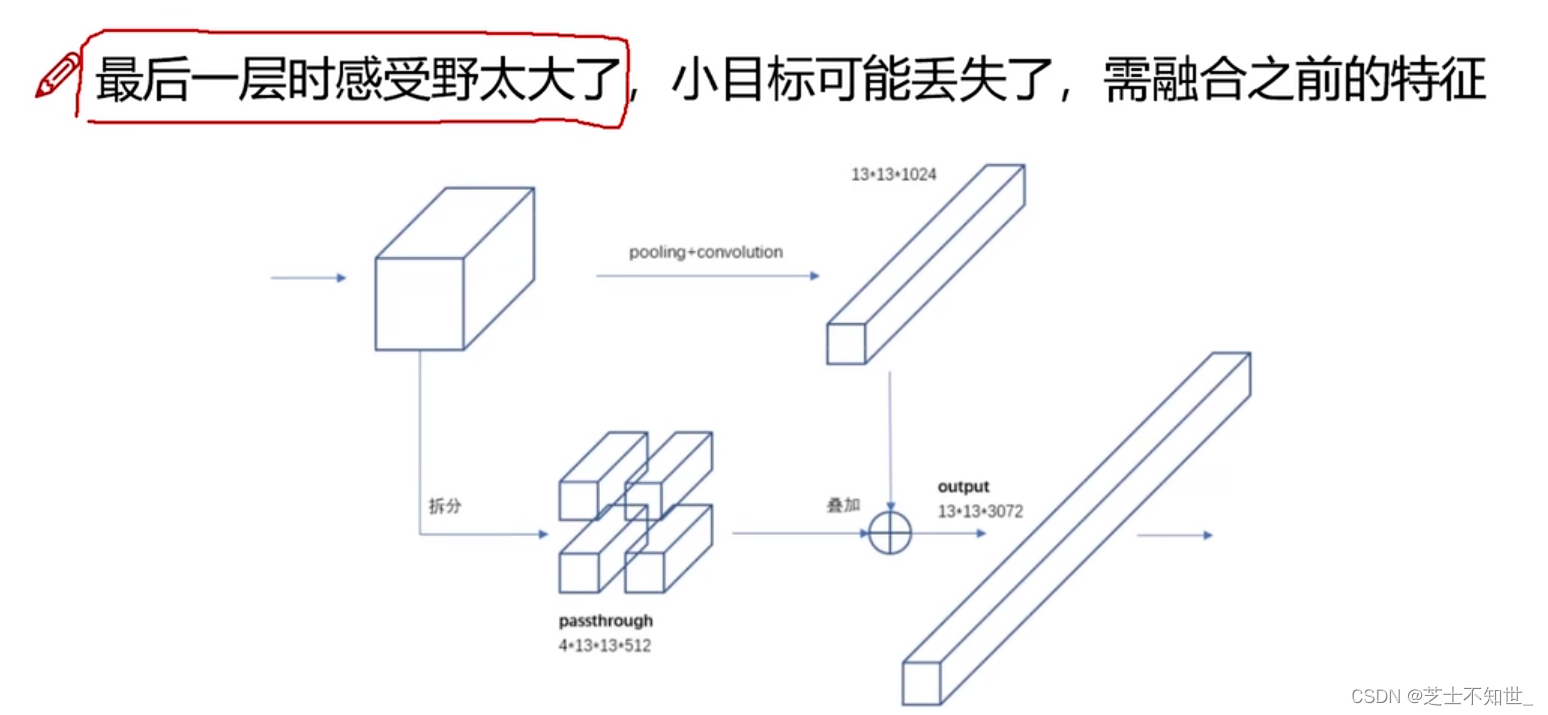
如何得到细粒度特征?
可理解为将不同层(不同尺度特征/不同感受野特征/不同分辨率特征)之间的特征融合。YOLOv2通过添加一个Passthrough Layer,把高分辨率的浅层特征拆分 连接到低分辨率的深层特征(把特征堆积在不同Channel中)而后进行融合和检测。
具体操作是:先获取前层的26×26的特征图,将其同最后输出的13×13的特征图进行连接,而后输入检测器进行检测(而在YOLOv1中网络的FC层起到了全局特征融合的作用),以此来提高对小目标的检测能力。
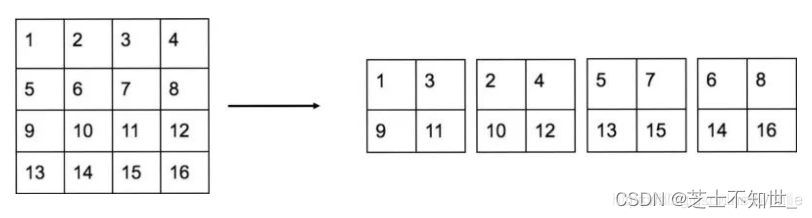
Passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个2×2的局部区域,然后将其转化为channel维度,对于26×26×512的特征图,经Passthrough层处理之后就变成了13×13×2048的新特征图(特征图大小降低4倍,而channles增加4倍),这样就可以与后面的13×13×1024特征图连接在一起形成13×13×3072的特征图,然后在此特征图基础上卷积做预测。示意图如下:
6.多尺度输入
输入不同尺度:输入不同分辨率大小的图片。

Yolov2总结

YOLO v3
在 YOLOv2 的基础上做了一些改进:
- 取消池化和全连接,只用卷积,下采样通过stride=2实现
- 特征提取部分采用darknet-53网络结构代替原来的darknet-19
- 利用特征金字塔网络结构实现了多尺度检测(3 scale)
- 分类方法使用逻辑回归代替了softmax,在兼顾实时性的同时保证了目标检测的准确性。
从YOLOv1到YOLOv3,每一代性能的提升都与backbone(骨干网络)的改进密切相关。在YOLOv3中,不仅提供了darknet-53,还提供了轻量级的tiny-darknet。
Yolov3网络结构

Darknet-53
主要由1×1和3×3的卷积层组成,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。卷积层、批量归一化层以及Leaky ReLU共同组成Darknet-53中的基本卷积单元DBL。因为在Darknet-53中共包含53个这样的DBL,所以称其为Darknet-53。
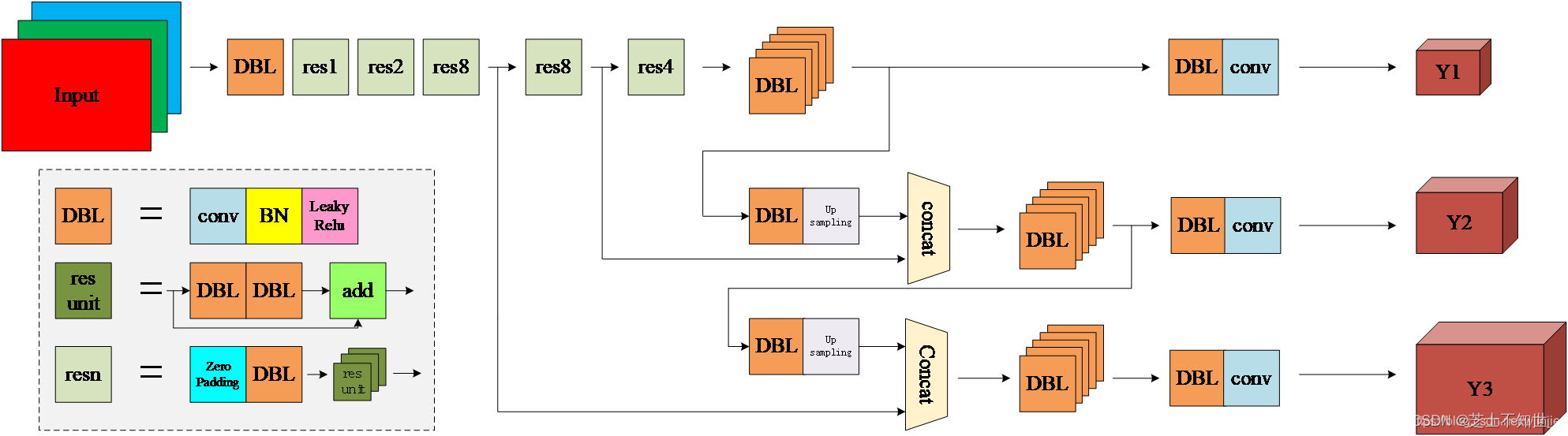
名词解释:
DBL: 一个卷积层、一个批量归一化层和一个Leaky ReLU组成的基本卷积单元。
res unit: 输入通过两个DBL后,再与原输入进行add;这是一种常规的残差单元。残差单元的目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
resn: 其中的n表示n个res unit;所以 resn = Zero Padding + DBL + n × res unit 。
concat: 将darknet-53的中间层和后面的某一层的上采样进行张量拼接,达到多尺度特征融合的目的。这与残差层的add操作是不一样的,拼接会扩充张量的维度,而add直接相加不会导致张量维度的改变。
Y1、Y2、Y3: 分别表示YOLOv3三种尺度的输出。
输出三个尺度的特征图:
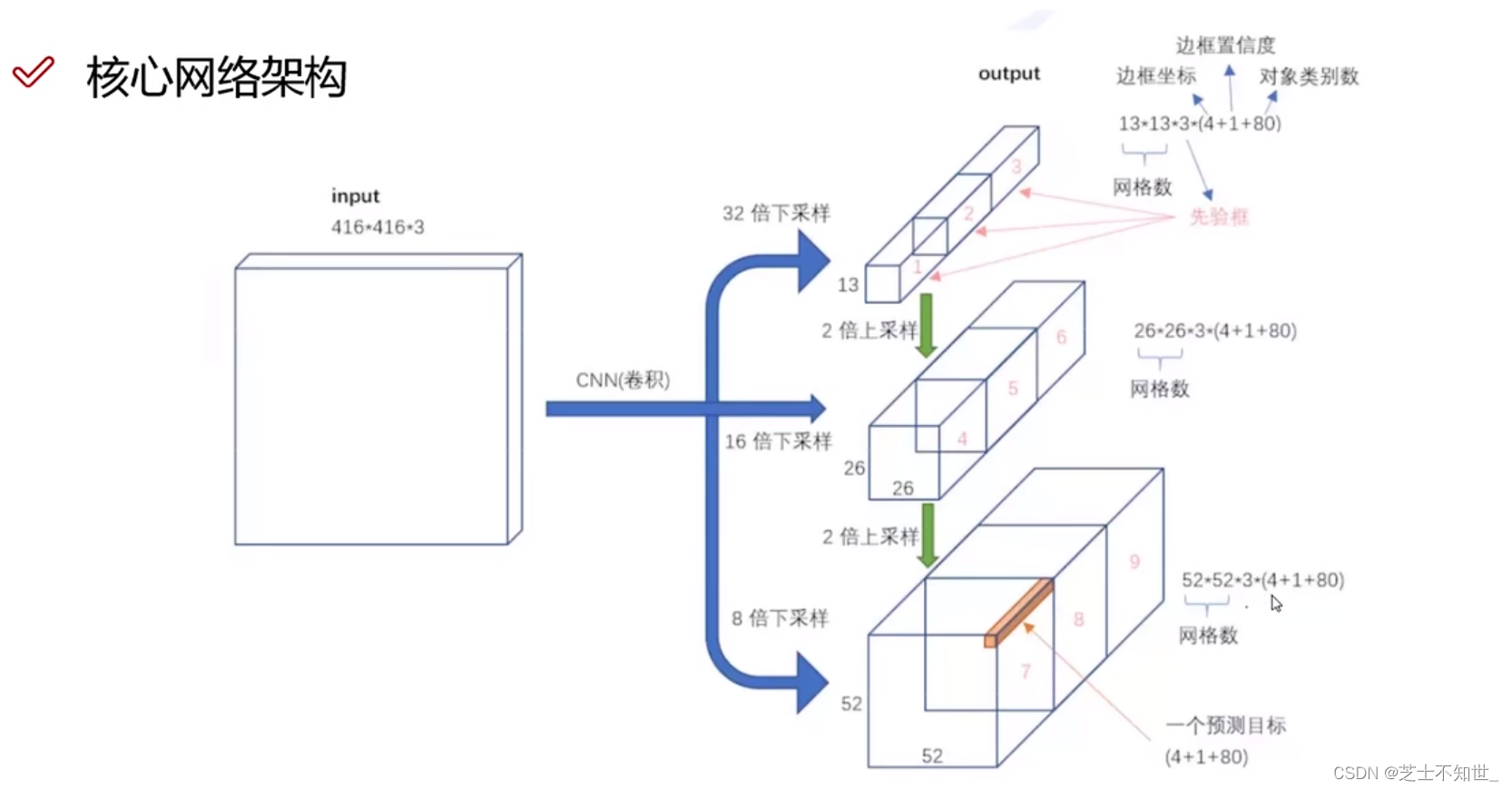
每个尺度特征图的格子上设置3个先验框,共9个。

Yolo v3改进
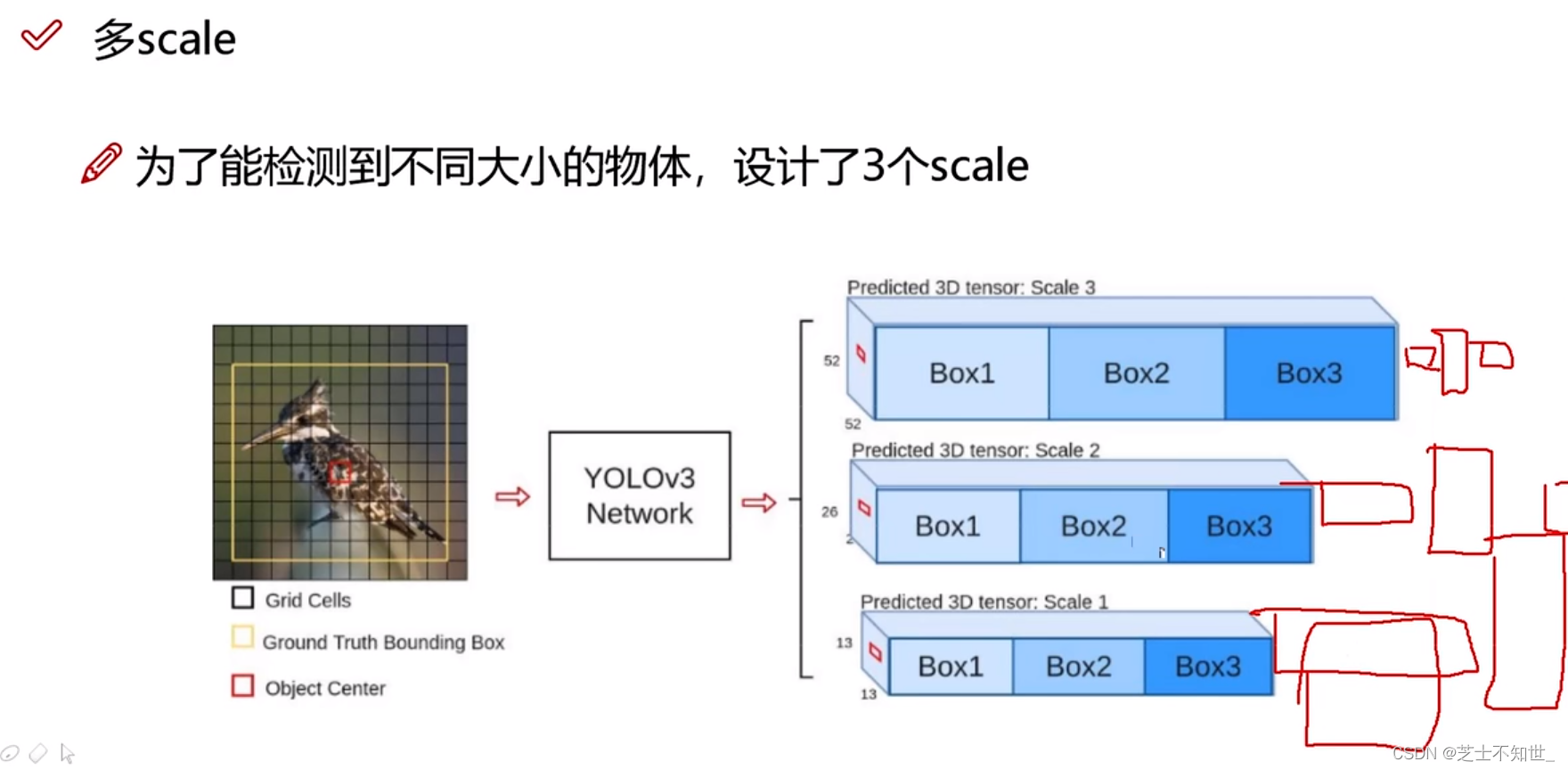
1.多尺度检测
输出不同尺度的特征图,分别用于不同大小物体的检测。
大特征图 感受野小,在Yolo Network的浅层提取,用于预测小目标。
小特征图 感受野大,在Yolo Network的深层提取,用于预测大目标。
2.金字塔结构提取多尺度特征
上面的多尺度特征并不是从不同层直接拿出来,因为单纯的浅层特征图的眼界(感受野)比较小,不能直接用,要将深层特征图融入浅层特征图,得到新的浅层特征图(拓宽眼界/感受野),从而使得浅层特征更好的预测小目标。
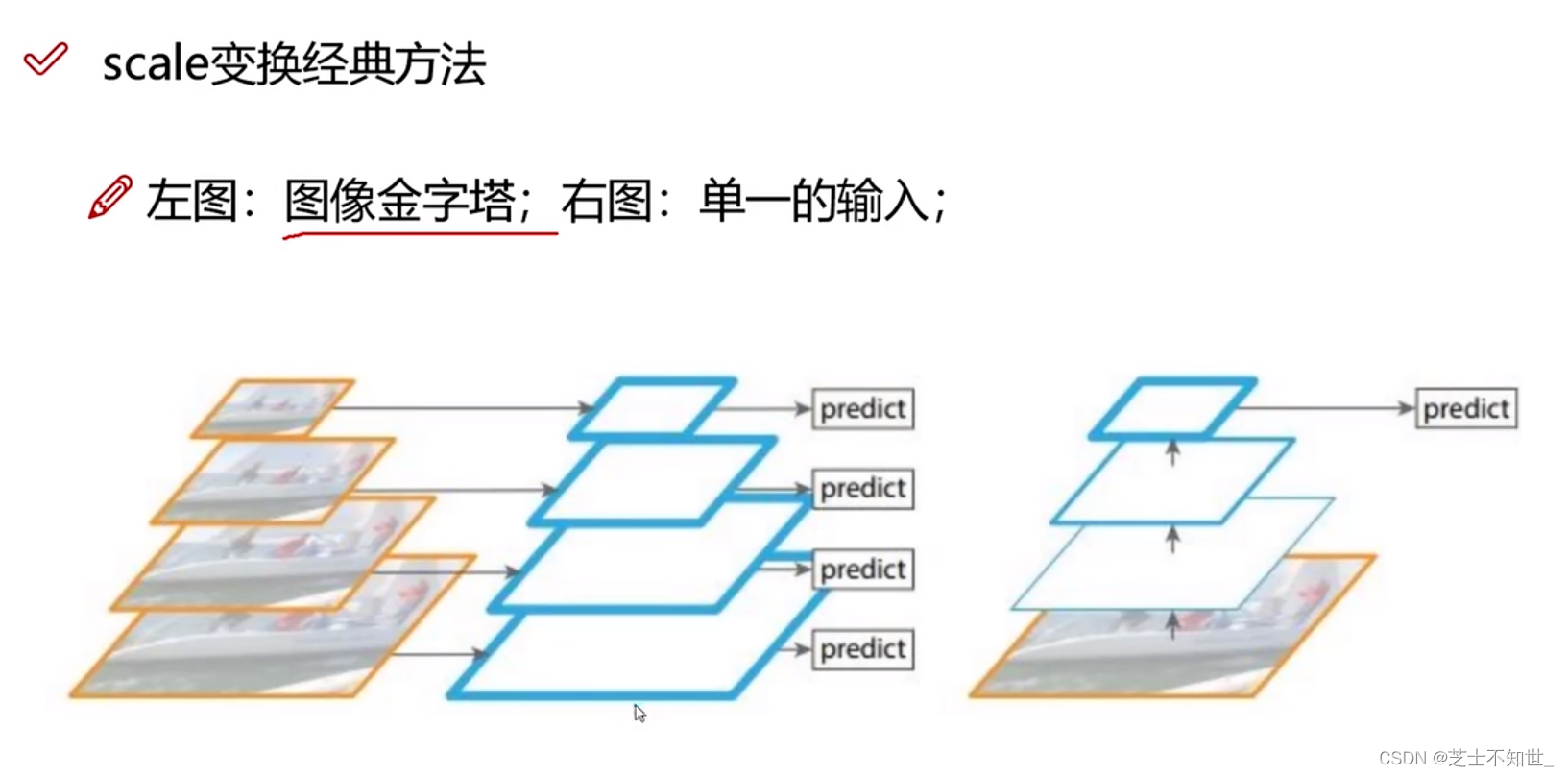
金字塔结构大全:
①图像金字塔(左图):输入图片,resize成不同分辨率大小,分别输入网络进行预测。
②单一输入输出(右图 Yolov1):输入图片一条龙预测,不考虑多尺度特征。
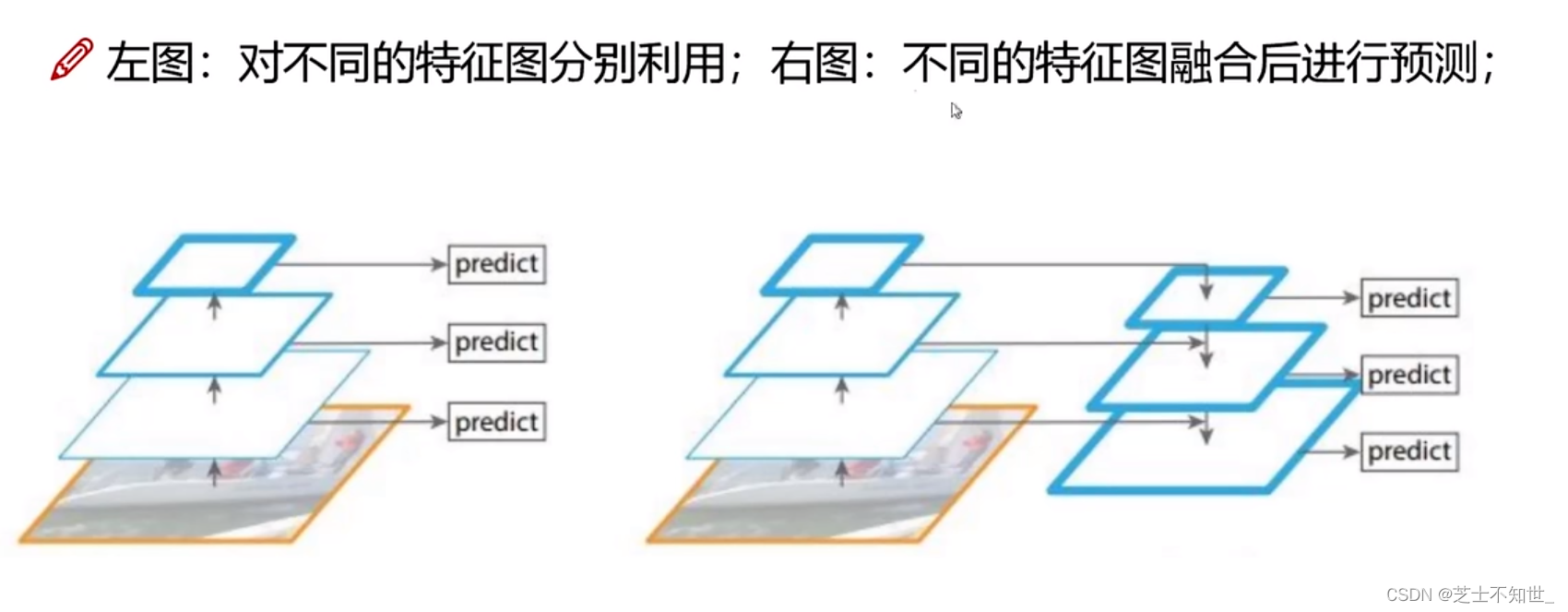
③左图:提取不同尺度的特征,分别进行预测,不融合
④FPN(右图 Yolov3):提取不同尺度的特征,将深层特征经过上采样upsample(插值),变换特征图大小,融入浅层特征,分别进行预测大/小目标。
现在还有很多新的多尺度融合方式,如PAN等,大家可以自行查阅学习。
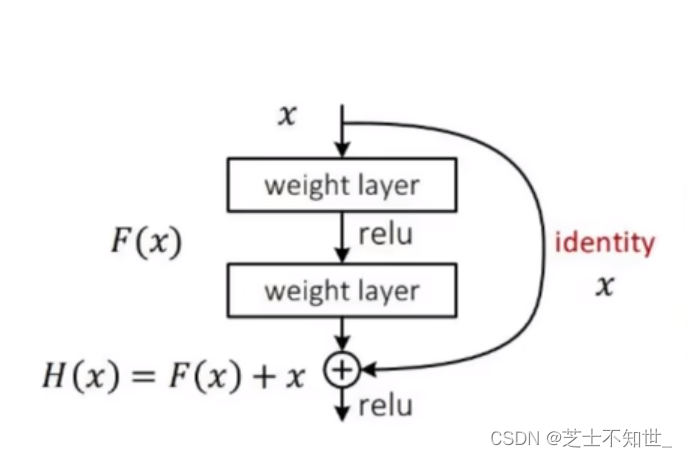
3.残差连接模块
在卷积块中引入残差边(恒等映射:就是不改变原来的特征),就算这次卷积得到的特征变差了,有了残差边,将卷积后的特征+原来的特征,可以保证原来好的特征不会丢失。
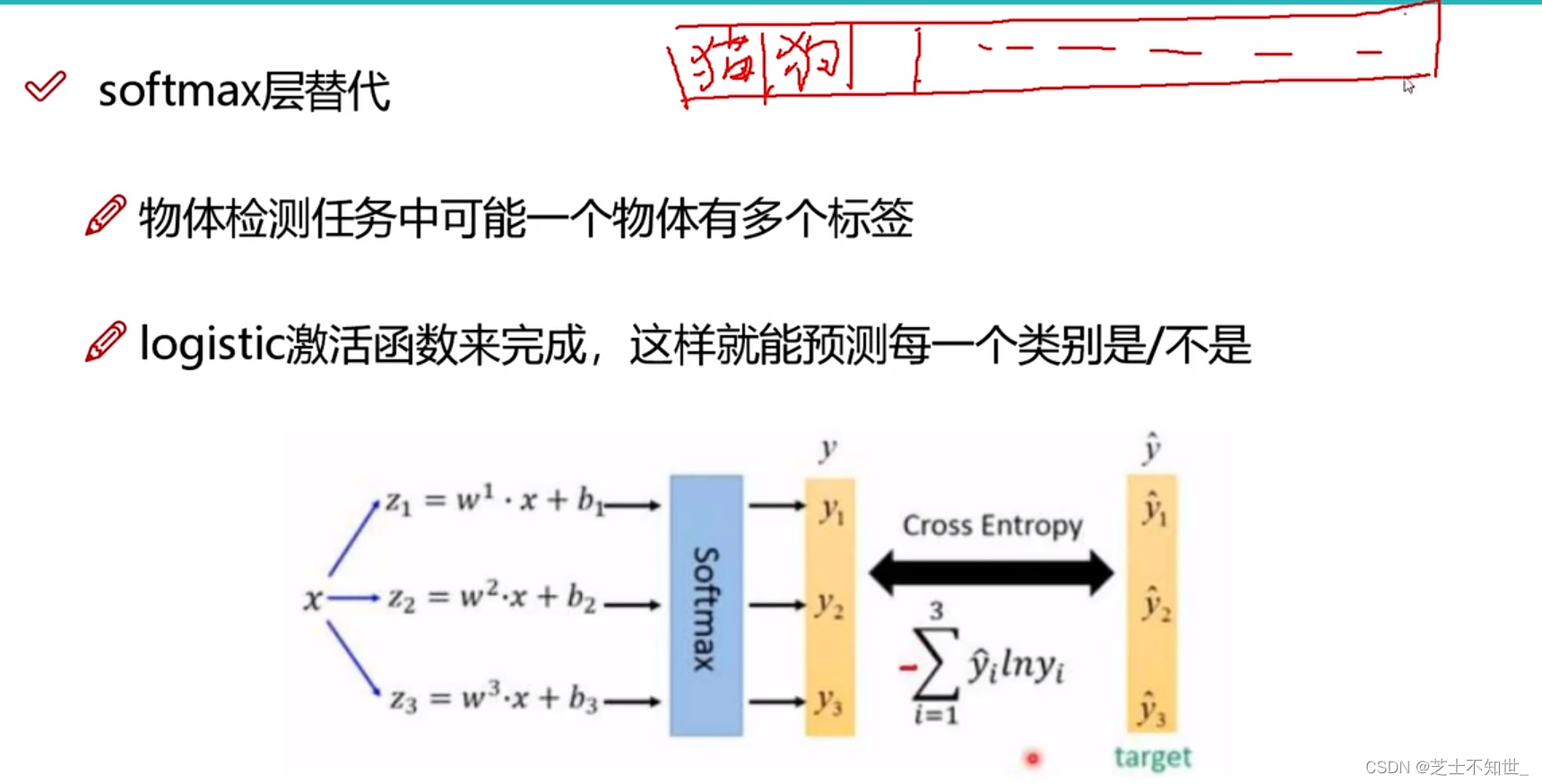
4.改进softmax层
一个物体可能有多个标签,引入logistic,完成每种class类别是/否预测。(多标签任务)
具体的:softmax预测得到改物体属于每个class的概率 如(0.7, 0.1, 0.8, 0.4),logistic函数判断>0.6就属于改class,那么结果就是(是,否,是,否)。
YOLO v4
YOLOv4对深度学习中一些常用Tricks进行了大量的测试,最终选择了这些有用的Tricks:WRC、CSP、CmBN、SAT、 Mish activation、Mosaic data augmentation、CmBN、DropBlock regularization 和 CIoU loss。YOLOv4在传统的YOLO基础上,加入了这些实用的技巧,实现了检测速度和精度的最佳权衡。
YOLOv4的独到之处在于:
- 是一个高效而强大的目标检测网咯。它使我们每个人都可以使用 GTX 1080Ti 或 2080Ti 的GPU来训练一个超快速和精确的目标检测器。这对于买不起高性能显卡的我们来说,简直是个福音!
在论文中,验证了大量先进的技巧对目标检测性能的影响,真的是非常良心! - 对当前先进的目标检测方法进行了改进,使之更有效,并且更适合在单GPU上训练;这些改进包括CBN、PAN、SAM等。
Yolov4网络结构
YOLOv4 = CSPDarknet53(主干) + SPP附加模块(颈) + PANet路径聚合(颈) + YOLOv3(头部)
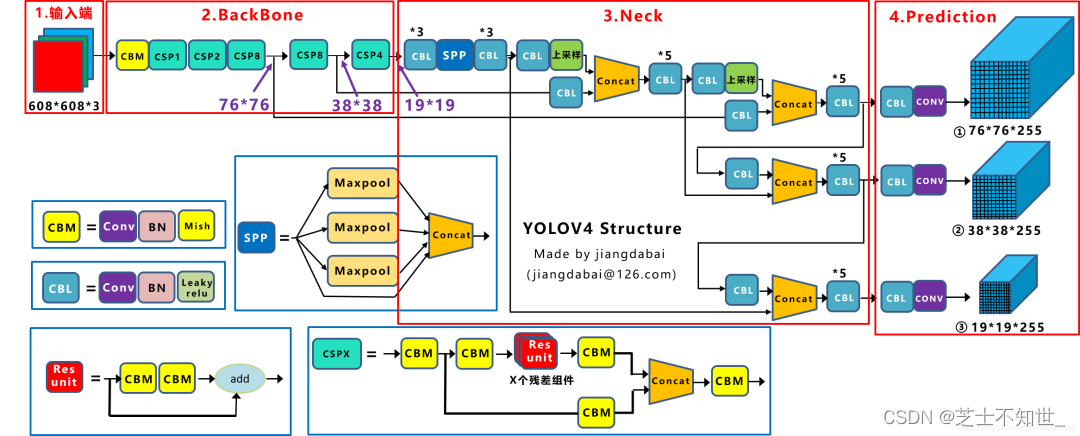
CBM卷积块:卷积+标准化+激活函数
ResBlock残差块(Res Unit):两个卷积块+残差
ResBlock_Body残差体(CSPX):主卷积分支(包含X个ResBlock)+残差辅卷积分支
CSPDarknet:CBM和ResBlock_Body的堆叠
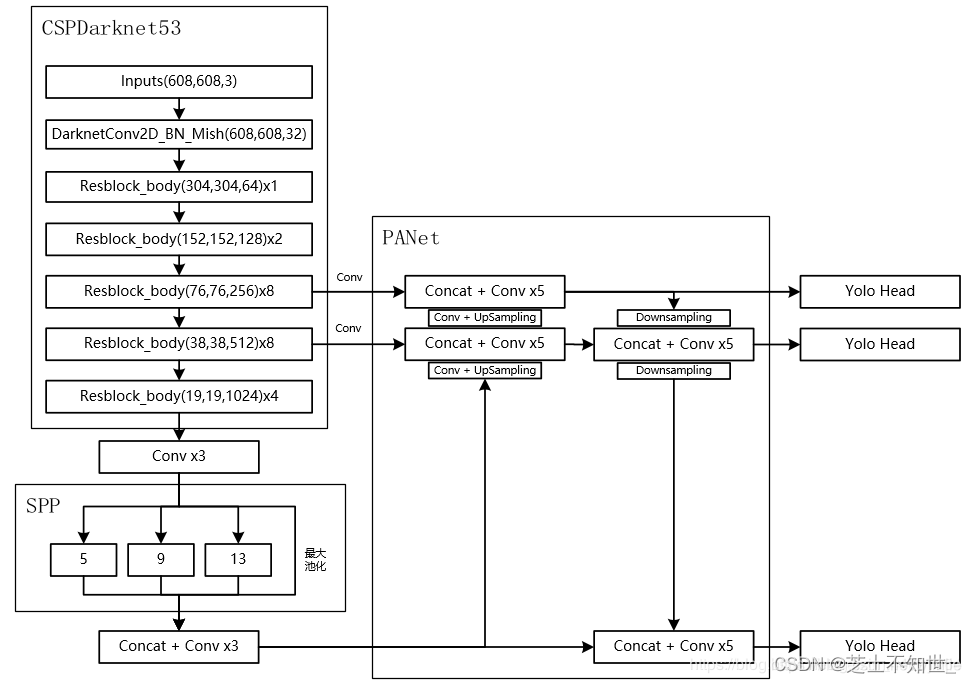
CSPDarknet53
在YOLOv4中,将CSPDarknet53(Cross Stage Partial Darknet53)作为主干网络。解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题, 有效缓解梯度消失问题,,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。
两点改进:
1.使用了Mish激活函数。
2.在Draknet基础上使用了CSPNet结构。
为了增大感受野,作者还使用了SPP-block,使用PANet代替FPN进行参数聚合以适用于不同level的目标检测。
SPP结构
SPP-Net全称Spatial Pyramid Pooling Networks(空间金字塔池化网络),当时主要是用来解决不同尺寸的特征图如何进入全连接层的,直接看下图,下图中对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
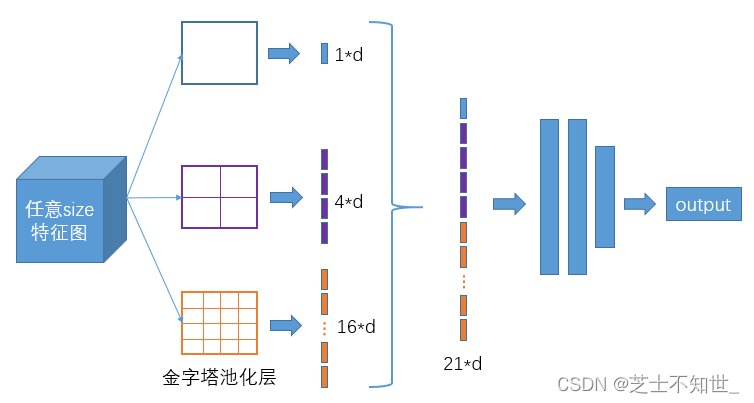
如上图,以3个尺寸的池化为例,对特征图进行一个最大值池化,即一张特征图得取其最大值,得到1d(d是特征图的维度)个特征;对特征图进行网格划分为2×2的网格,然后对每个网格进行最大值池化,那么得到4d个特征;同样,对特征图进行网格划分为4×4个网格,对每个网格进行最大值池化,得到16*d个特征。 接着将每个池化得到的特征合起来即得到固定长度的特征个数(特征图的维度是固定的),接着就可以输入到全连接层中进行训练网络了。用到这里是为了增加感受野。
PAN结构
使用CSPDarknet得到的三个有效特征层进入PANet(Pat h Aggregation Network)代替FPN进行参数聚合以适用于不同level的目标检测, 先进行自顶向下特征融合,再进行自底向上的特征融合。上采样upsample:使特征图的H和W变为2倍。下采样downsample(就是卷积):使特征图的H和W变为原来的1/2。PANet论文中融合的时候使用的方法是Addition,YOLOv4算法将融合的方法由加法改为Concatenation。如下图:
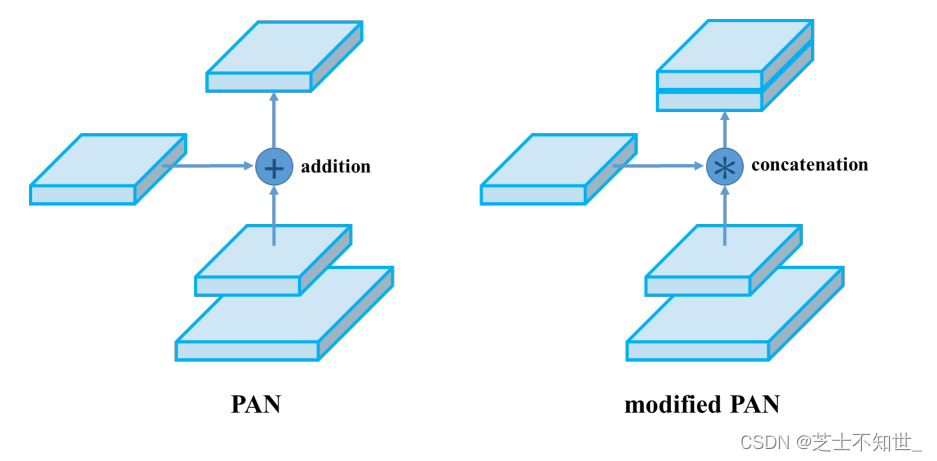
YOLOv4 BackBone训练策略
数据增强
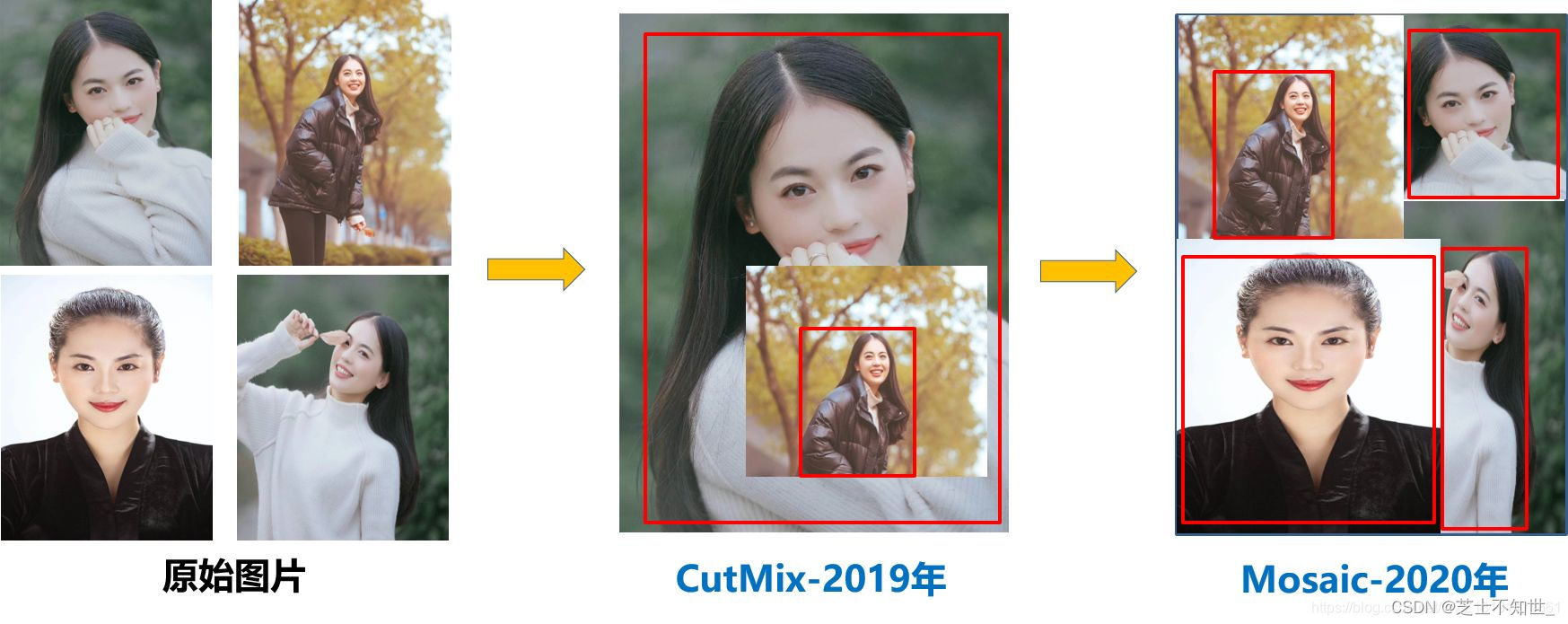
1.CutMix
CutMix的处理方式也比较简单,同样也是对一对图片做操作,简单讲就是随机生成一个裁剪框Box,裁剪掉A图的相应位置,然后用B图片相应位置的ROI放到A图中被裁剪的区域形成新的样本,ground truth标签会根据patch的面积按比例进行调整,比如0.6像狗,0.4像猫,计算损失时同样采用加权求和的方式进行求解。这里借CutMix的地方顺带说下几种类似的增强方式:无、Mixup、Cutout、CutMix
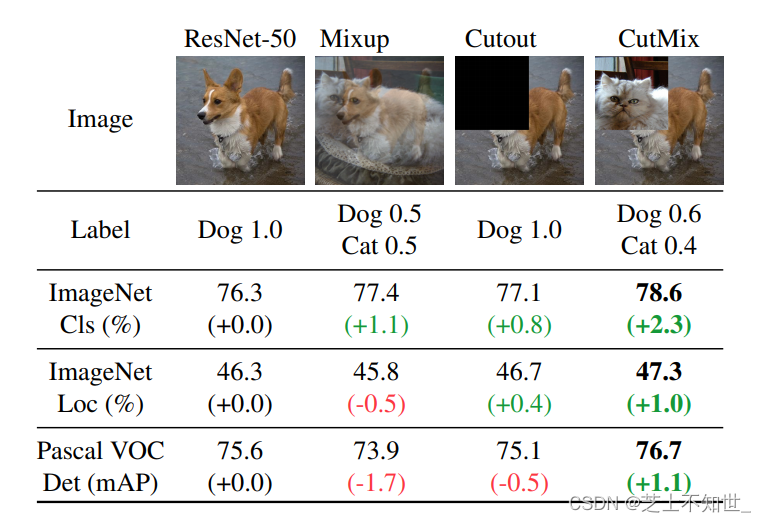
CutMix的增强方式在三个数据集上的表现都是最优的。其中Mixup是直接求和两张图,如同附身,鬼影一样,模型很难学到准确的特征图响应分布。Cutout是直接去除图像的一个区域,这迫使模型在进行分类时不能对特定的特征过于自信。然而,图像的一部分充满了无用的信息,这是一种浪费。在CutMix中,将图像的一部分剪切并粘贴到另一个图像上,使得模型更容易区分异类。
2.Mosaic
Mosaic数据增强是参考CutMix数据增强,理论上类似。区别在于Mosaic是一种将4张训练图像合并成一张进行训练的数据增强方法(而不是CutMix中的2张)。这增强了对正常背景(context)之外的对象的检测,丰富检测物体的背景。此外,每个小批包含一个大的变化图像(4倍),因此,减少了估计均值和方差的时需要大mini-batch的要求,降低了训练成本。如下图:

DropBlock正则化
正则化技术有助于避免数据科学专业人员面临的最常见的问题,即过拟合。对于正则化,已经提出了几种方法,如L1和L2正则化、Dropout、Early Stopping和数据增强。这里YOLOv4用了DropBlock正则化的方法。
DropBlock方法的引入是为了克服Dropout随机丢弃特征的主要缺点,Dropout被证明是全连接网络的有效策略,但在特征空间相关的卷积层中效果不佳。DropBlock技术在称为块的相邻相关区域中丢弃特征。这样既可以实现生成更简单模型的目的,又可以在每次训练迭代中引入学习部分网络权值的概念,对权值矩阵进行补偿,从而减少过拟合。如下图:
YOLOv4 BackBone推理策略
Mish激活函数
对激活函数的研究一直没有停止过,ReLU还是统治着深度学习的激活函数,不过,这种情况有可能会被Mish改变。Mish是另一个与ReLU和Swish非常相似的激活函数。正如论文所宣称的那样,Mish可以在不同数据集的许多深度网络中胜过它们。公式如下:
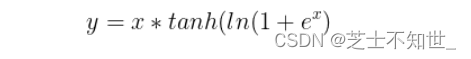
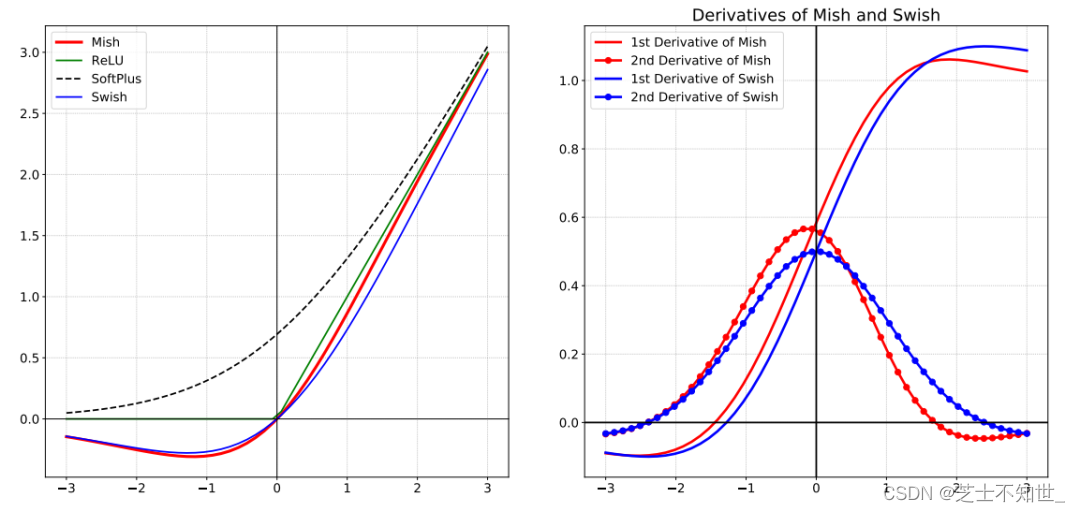
Mish是一个平滑的曲线,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化;在负值的时候并不是完全截断,允许比较小的负梯度流入。实验中,随着层深的增加,ReLU激活函数精度迅速下降,而Mish激活函数在训练稳定性、平均准确率(1%-2.8%)、峰值准确率(1.2% – 3.6%)等方面都有全面的提高。如下图:
MiWRC策略
MiWRC是Multi-input weighted residual connections的简称, 在BiFPN中,提出了用MiWRC来执行标尺度级重加权,添加不同尺度的特征映射。我们已经知道FPN和PAN作为例子。下面的图(d)显示了另一种被称为BiFPN的neck设计,根据BiFPN的论文,该设计具有更好的准确性和效率权衡。
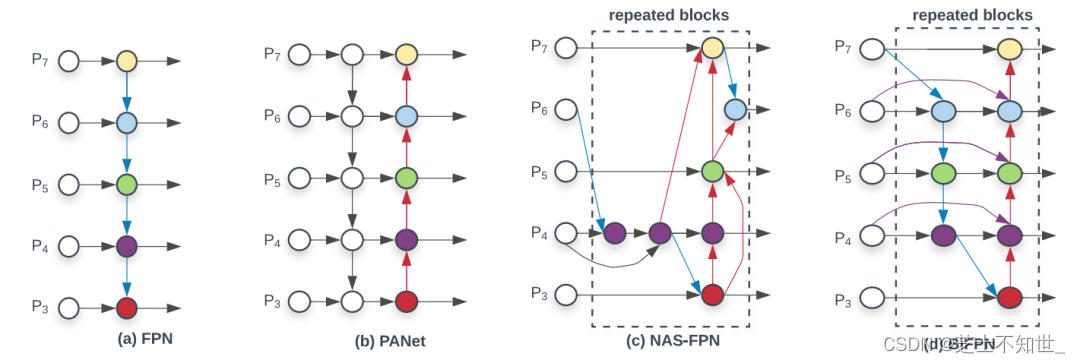
上图中 (a)FPN引入自顶向下的路径,将多尺度特征从3级融合到7级(P3-P7);(b)PANET在FPN之上增加一个额外的自下而上的路径;©NAS-FPN使用神经网络搜索找到一个不规则的特征拓扑网络,然后重复应用同一块拓扑结构;(d)是这里的BiFPN,具有更好的准确性和效率权衡。将该neck放到整个整个网络的连接中如下图:
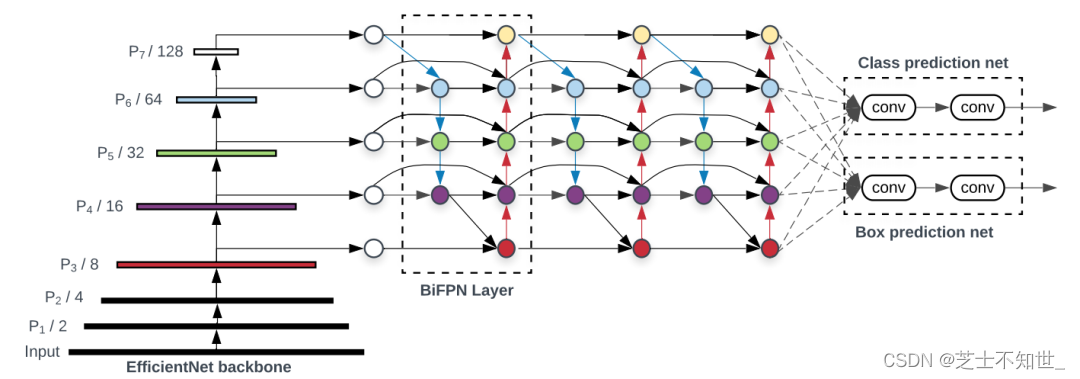
YOLOv4 检测头训练策略
CIoU-loss
损失函数给出了如何调整权重以降低loss。所以在我们做出错误预测的情况下,我们期望它能给我们指明前进的方向。但如果使用IoU,考虑两个预测都不与ground truth重叠,那么IoU损失函数不能告诉哪一个是更好的,或者哪个更接近ground truth。这里顺带看下常用的几种loss的形式,如下:
1.经典IoU loss
IoU算法是使用最广泛的算法,大部分的检测算法都是使用的这个算法。
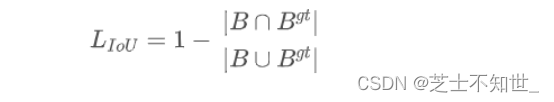
可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。

问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
因此2019年出现了GIOU_Loss来进行改进。
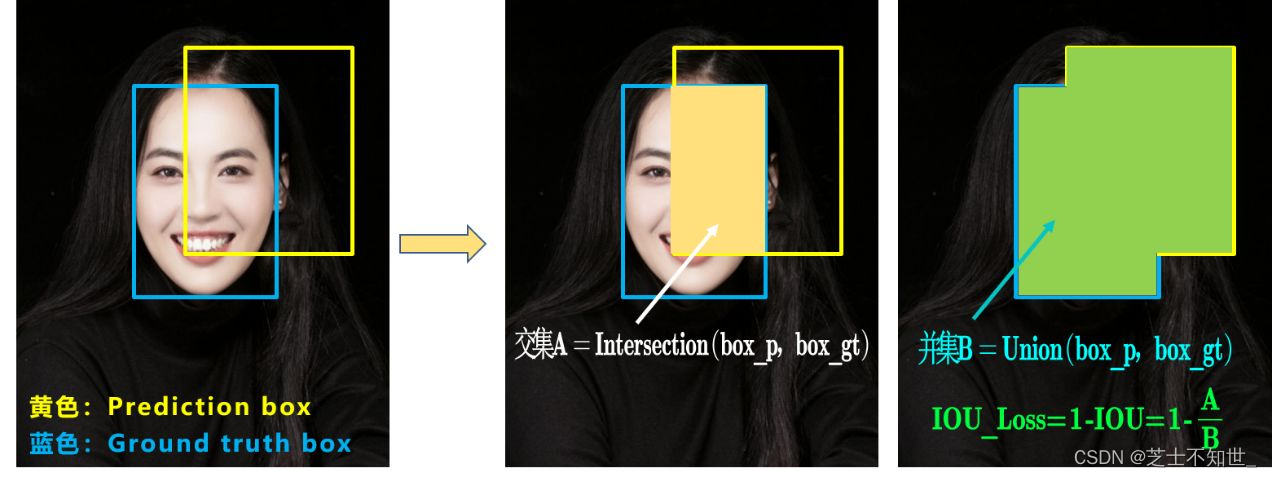
2. GIoU:Generalized IoU
GIoU考虑到,当检测框和真实框没有出现重叠的时候IoU的loss都是一样的,因此GIoU就加入了C检测框(C检测框是包含了检测框和真实框的最小矩形框),这样就可以解决检测框和真实框没有重叠的问题。其中,C是指能包含predict box和Ground Truth box的最小box。
可以看到上图GIOU_Loss中,增加了相交尺度的衡量方式,缓解了单纯IOU_Loss时的尴尬。但为什么仅仅说缓解呢?因为还存在一种不足:

问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
基于这个问题,2020年的AAAI又提出了DIOU_Loss。
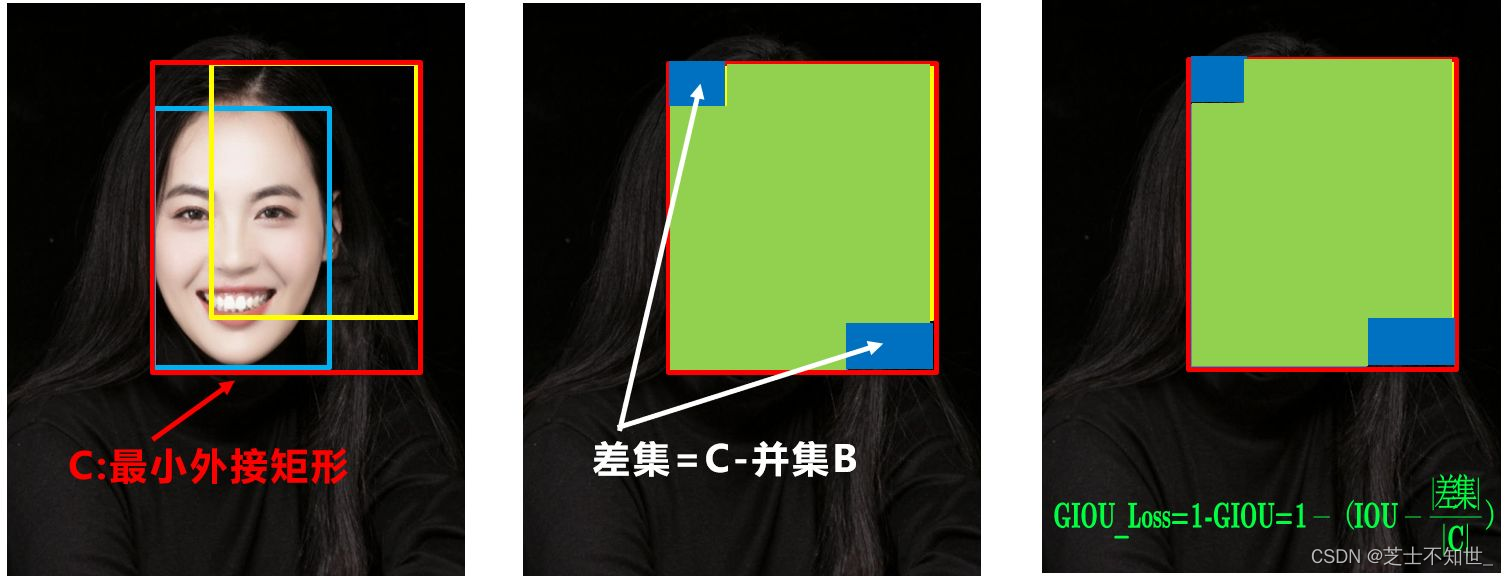
3.DIoU:Distance IoU
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。针对IOU和GIOU存在的问题,作者从两个方面进行考虑
(1):如何最小化预测框和目标框之间的归一化距离?
(2):如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题,提出了DIOU_Loss(Distance_IOU_Loss)
DIOU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。
但就像前面好的目标框回归函数所说的,没有考虑到长宽比。
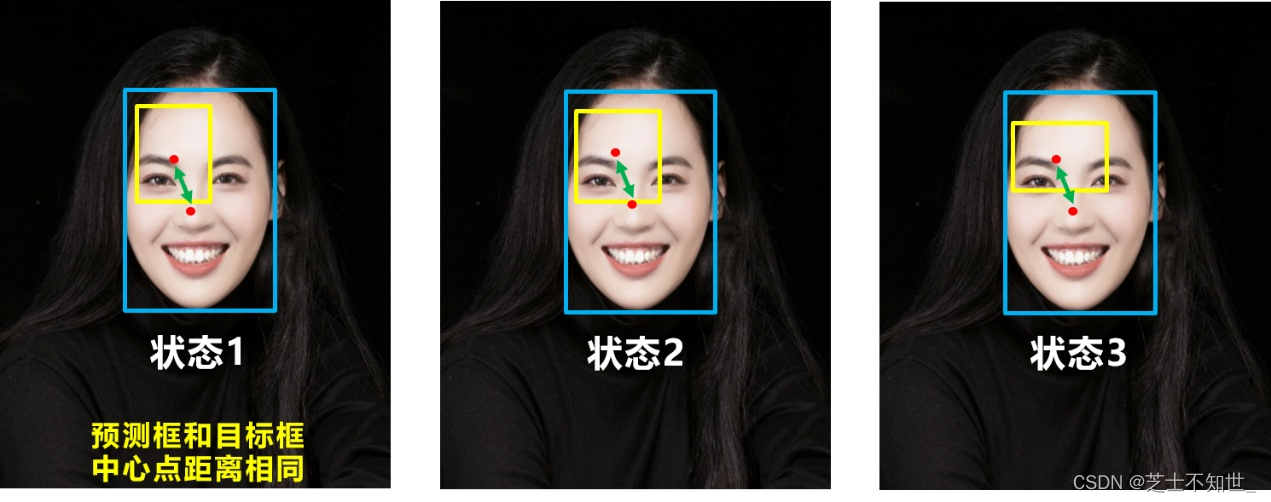
比如上面三种情况,目标框包裹预测框,本来DIOU_Loss可以起作用。但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。针对这个问题,又提出了CIOU_Loss
4.CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。

其中v是衡量长宽比一致性的参数,我们也可以定义为:
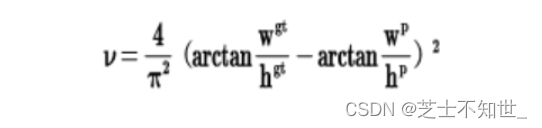
这样CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
再来综合的看下各个Loss函数的不同点:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
YOLOv4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
CmBN策略
BN就是仅仅利用当前迭代时刻信息进行norm,而CBN在计算当前时刻统计量时候会考虑前k个时刻统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销,训练速度不会影响很多,但是训练时候会慢一些,比GN还慢。
CmBN是CBN的改进版本,其把大batch内部的4个mini batch当做一个整体,对外隔离。CBN在第t时刻,也会考虑前3个时刻的统计量进行汇合,而CmBN操作不会,不再滑动cross,其仅仅在mini batch内部进行汇合操作,保持BN一个batch更新一次可训练参数。
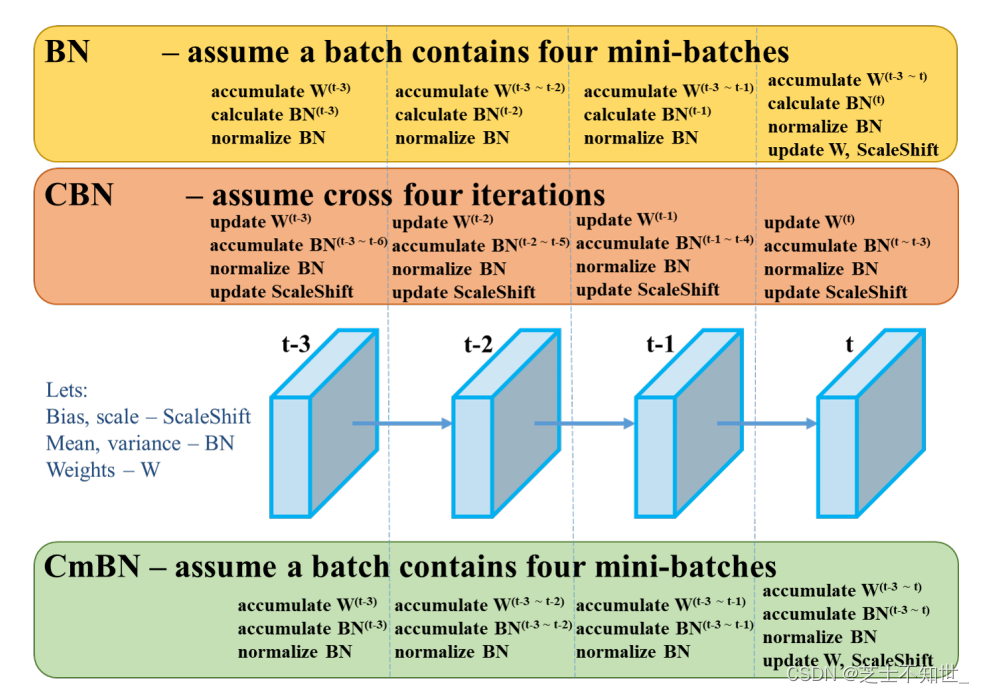
BN:无论每个batch被分割为多少个mini batch,其算法就是在每个mini batch前向传播后统计当前的BN数据(即每个神经元的期望和方差)并进行Nomalization,BN数据与其他mini batch的数据无关。
CBN:每次iteration中的BN数据是其之前n次数据和当前数据的和(对非当前batch统计的数据进行了补偿再参与计算),用该累加值对当前的batch进行Nomalization。好处在于每个batch可以设置较小的size。
CmBN:只在每个Batch内部使用CBN的方法,个人理解如果每个Batch被分割为一个mini batch,则其效果与BN一致;若分割为多个mini batch,则与CBN类似,只是把mini batch当作batch进行计算,其区别在于权重更新时间点不同,同一个batch内权重参数一样,因此计算不需要进行补偿。
自对抗训练(SAT)
SAT为一种新型数据增强方式。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对其自身进行一种对抗式的攻击,改变原始图像,制造图像上没有目标的假象。在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
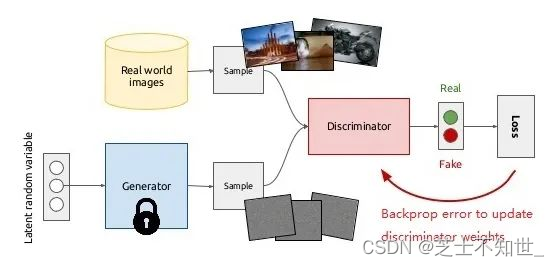
Self-Adversarial Training是在一定程度上抵抗对抗攻击的数据增强技术。CNN计算出Loss, 然后通过反向传播改变图片信息,形成图片上没有目标的假象,然后对修改后的图像进行正常的目标检测。需要注意的是在SAT的反向传播的过程中,是不需要改变网络权值的。 使用对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。因此这种数据增强方式被越来越多的对象检测框架运用。
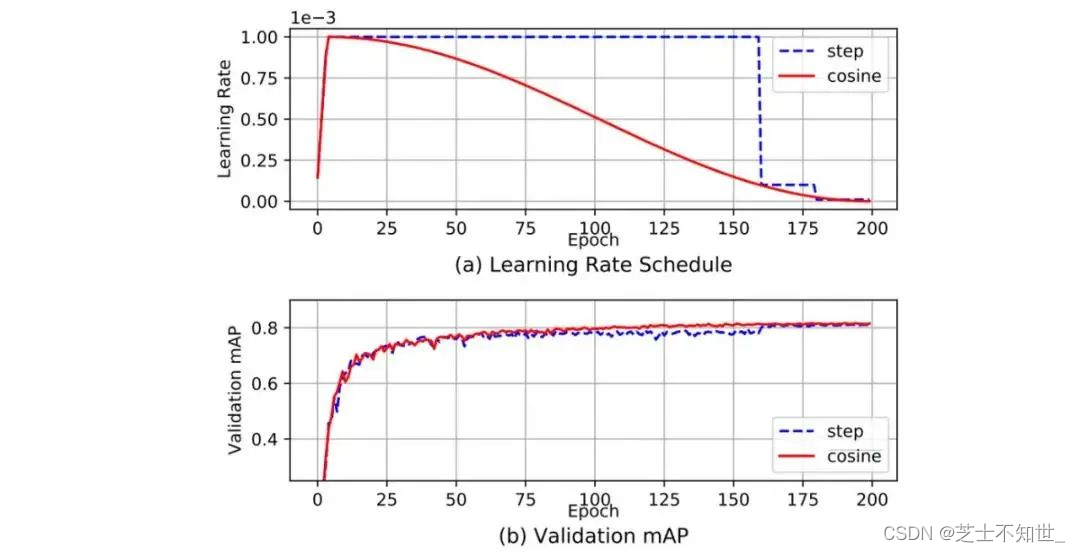
余弦模拟退火
余弦调度会根据一个余弦函数来调整学习率。首先,较大的学习率会以较慢的速度减小。然后在中途时,学习的减小速度会变快,最后学习率的减小速度又会变得很慢。
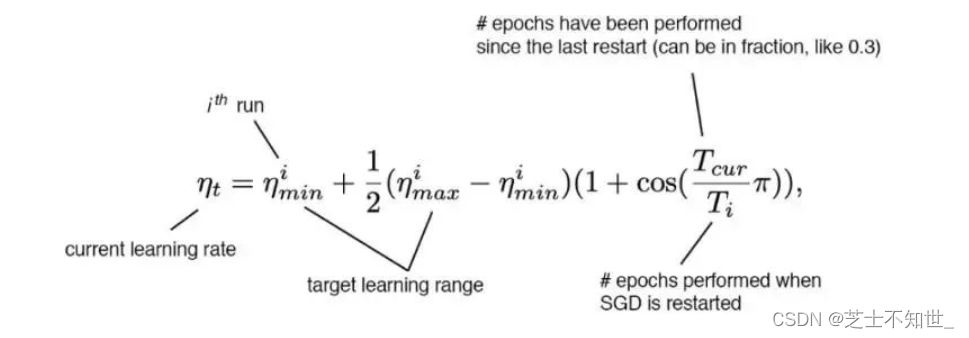
这张图展示了学习率衰减的方式(下图中还应用了学习率预热)及其对mAP的影响。可能看起来并不明显,这种新的调度方法的进展更为稳定,而不是在停滞一段时间后又取得进展。
YOLOv4 检测头推理策略
SAM模块
注意力机制在DL设计中被广泛采用。在SAM中,最大值池化和平均池化分别用于输入feature map,创建两组feature map。结果被输入到一个卷积层,接着是一个Sigmoid函数来创建空间注意力。
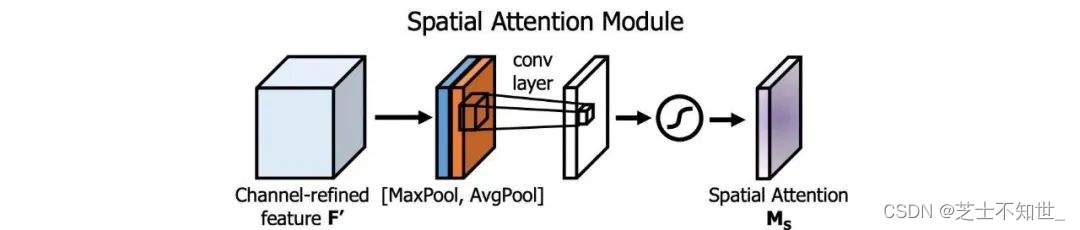
将空间注意掩模应用于输入特征,输出精细的特征图.
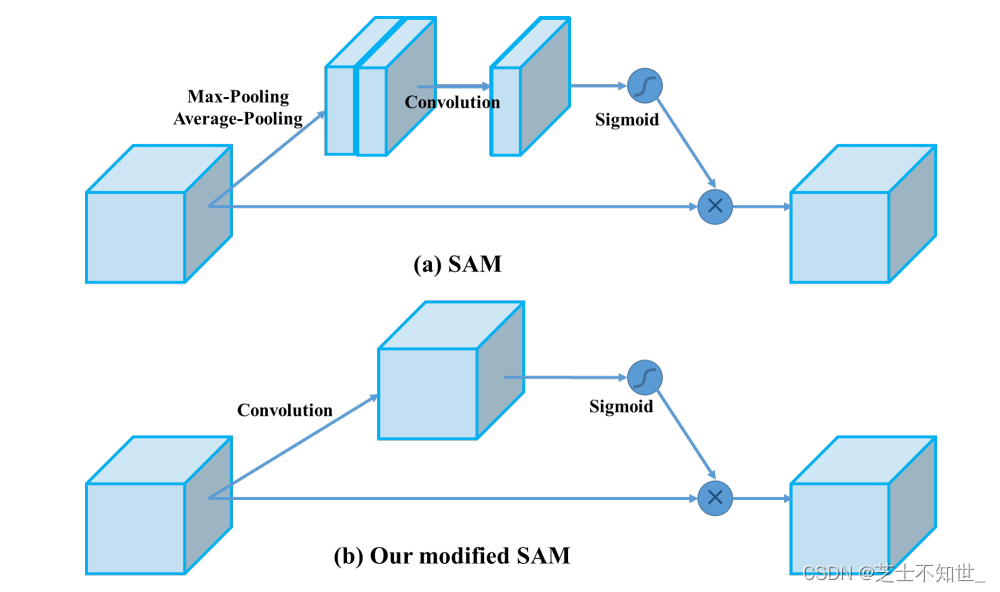
在YOLOv4中,使用修改后的SAM而不应用最大值池化和平均池化。
DIoU-NMS
NMS过滤掉预测相同对象的其他边界框,并保留具有最高可信度的边界框。
DIoU(前面讨论过的) 被用作非最大值抑制(NMS)的一个因素。该方法在抑制冗余框的同时,采用IoU和两个边界盒中心点之间的距离。这使得它在有遮挡的情况下更加健壮。
YOLO v5
在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
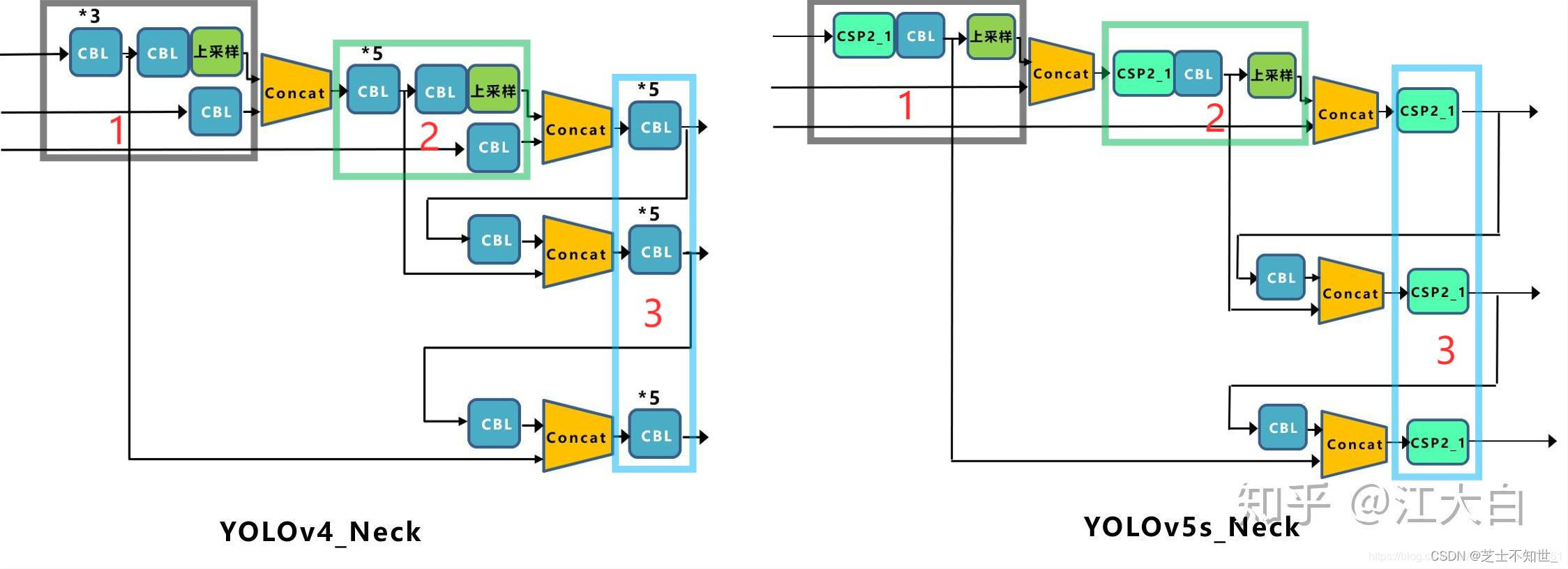
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
Yolov5网络结构
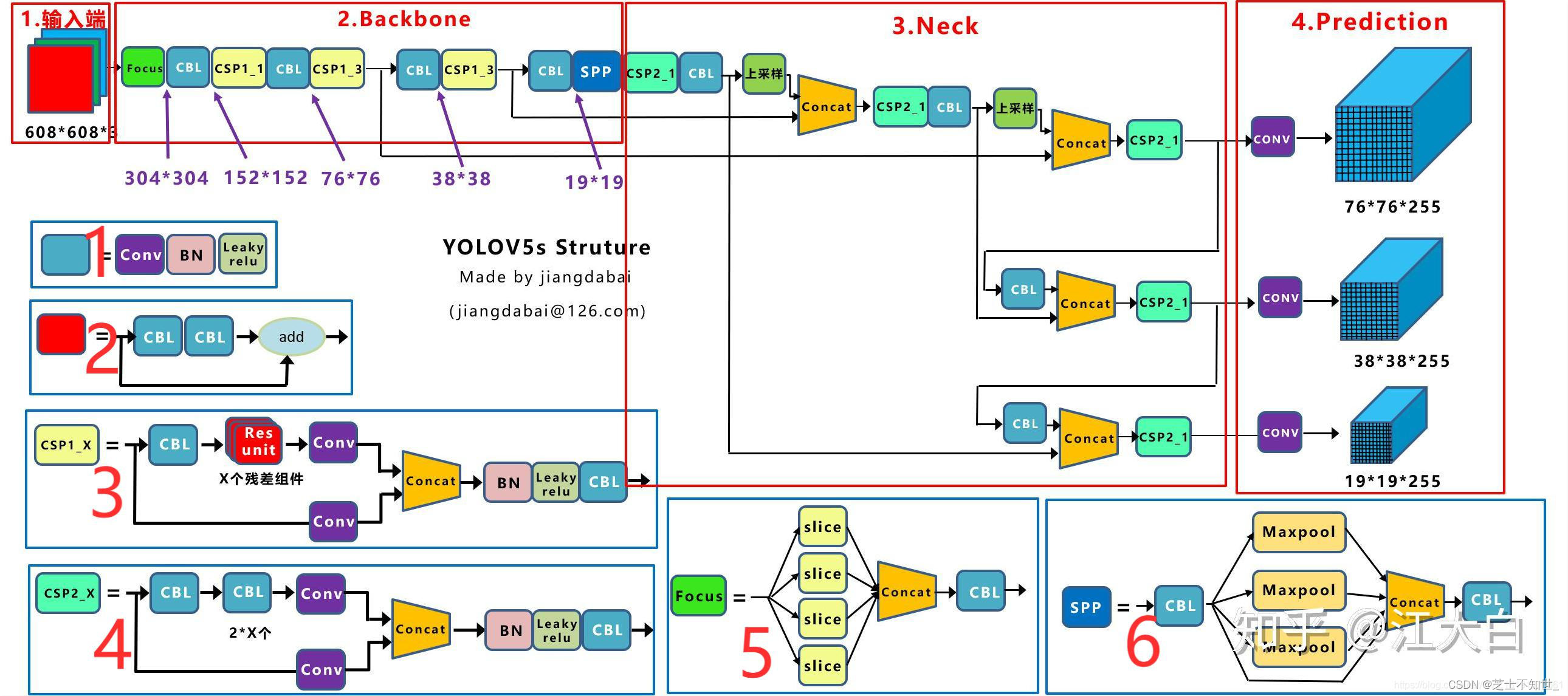
基础组件:
- CBL-CBL模块由Conv+BN+Leaky_relu激活函数组成,如上图中的模块1所示。
- Res unit-借鉴ResNet网络中的残差结构,用来构建深层网络,CBL是残差模块中的子模块,如上图中的模块2所示。
- CSP1_X-借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成而成,如上图中的模块3所示。
- CSP2_X-借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成,如上图中的模块4所示。
- Focus-如上图中的模块5所示,Focus结构首先将多个slice(取图像像素的奇行偶列、偶行奇列、偶行偶列、奇行奇列)结果Concat起来,然后将其送入CBL模块中。
- SPP-采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合,如上图中的模块6所示。
YOLOv5算法具有4个版本,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种,本文重点讲解YOLOv5s,其它的版本都在该版本的基础上对网络进行加深与加宽。
- 输入端:输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
- 基准网络:基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
- Neck网络:Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
- Head输出端:Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。YOLOv4利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
Yolov5输入端细节详解
- Mosaic数据增强-YOLOv5中在训练模型阶段仍然使用了Mosaic数据增强方法,该算法是在CutMix数据增强方法的基础上改进而来的。CutMix仅仅利用了两张图片进行拼接,而Mosaic数据增强方法则采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,具体的效果如下图所示。这种增强方法可以将几张图片组合成一张,这样不仅可以丰富数据集的同时极大的提升网络的训练速度,而且可以降低模型的内存需求。
- 自适应锚框计算-在YOLOv5系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。在YOLOv3和YOLOv4检测算法中,训练不同的数据集时,都是通过单独的程序运行来获得初始锚点框。YOLOv5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,具体的指令为parser.add_argument(’–noautoanchor’, action=‘store_ true’, help=‘disable autoanchor check’),如果需要打开,只需要在训练代码时增加–noautoanch or选项即可。
- 自适应图片缩放-针对不同的目标检测算法而言,我们通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO系列算法中常用的尺寸包括416*416,608 *608等尺寸。原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLOv5算法的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。
Yolov5基准网络细节详解
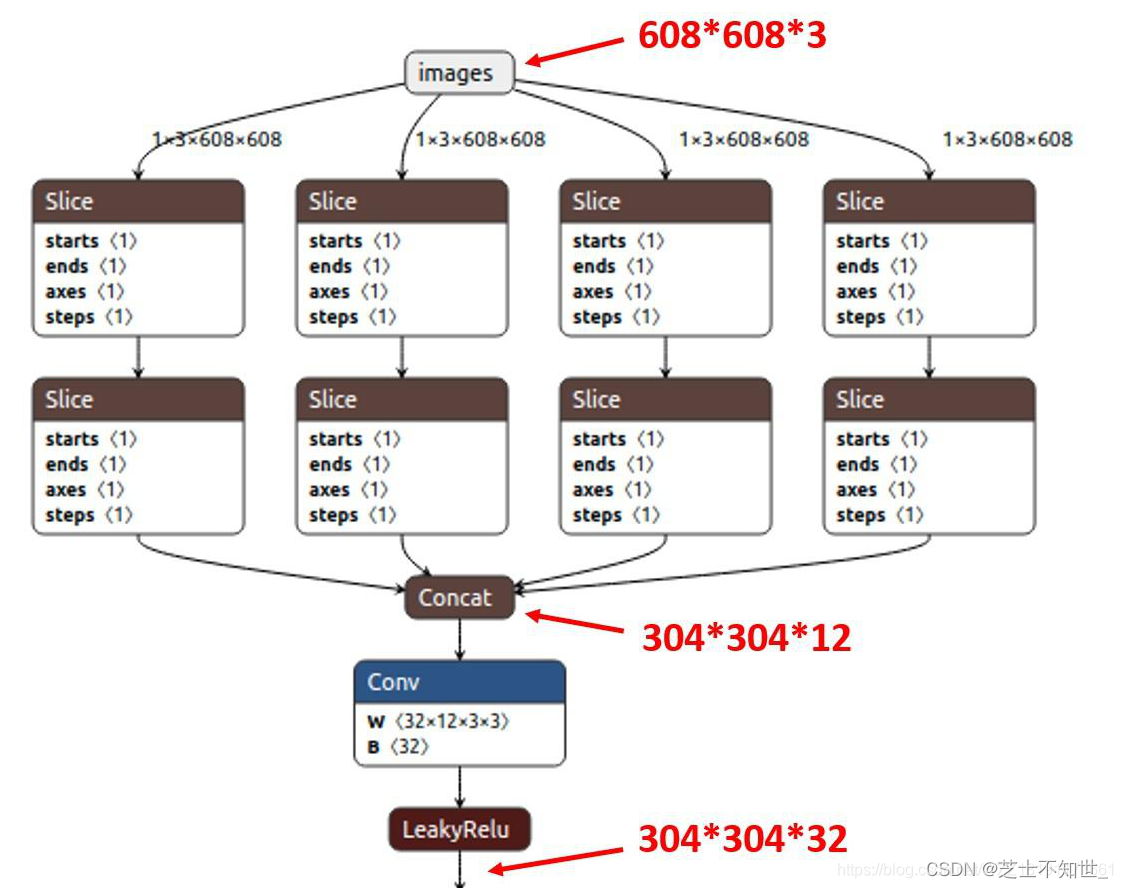
- Focus结构-该结构的主要思想是通过slice操作来对输入图片进行裁剪。如下图所示,原始输入图片大小为6086083,经过Slice与Concat操作之后输出一个30430412的特征映射;接着经过一个通道个数为32的Conv层(该通道个数仅仅针对的是YOLOv5s结构,其它结构会有相应的变化),输出一个30430432大小的特征映射。
- CSP结构-YOLOv4网络结构中,借鉴了CSPNet的设计思路,仅仅在主干网络中设计了CSP结构。而YOLOv5中设计了两种CSP结构,以YOLOv5s网络为例,CSP1_X结构应用于Backbone主干网络中,另一种CSP2_X结构则应用于Neck网络中。CSP1_X与CSP2_X模块的实现细节如3.1所示。
Yolov5Neck网络细节详解
- FPN+PAN-YOLOv5的Neck网络仍然使用了FPN+PAN结构,但是在它的基础上做了一些改进操作,YOLOv4的Neck结构中,采用的都是普通的卷积操作。而YOLOv5的Neck网络中,采用借鉴CSPnet设计的CSP2结构,从而加强网络特征融合能力。下图展示了YOLOv4与YOLOv5的Neck网络的具体细节,通过比较我们可以发现:(1)灰色区域表示第1个不同点,YOLOv5不仅利用CSP2_\1结构代替部分CBL模块,而且去掉了下方的CBL模块;(2)绿色区域表示第2个不同点,YOLOv5不仅将Concat操作之后的CBL模块更换为CSP2_1模块,而且更换了另外一个CBL模块的位置;(3)蓝色区域表示第3个不同点,YOLOv5中将原始的CBL模块更换为CSP2_1模块。
YOLOX
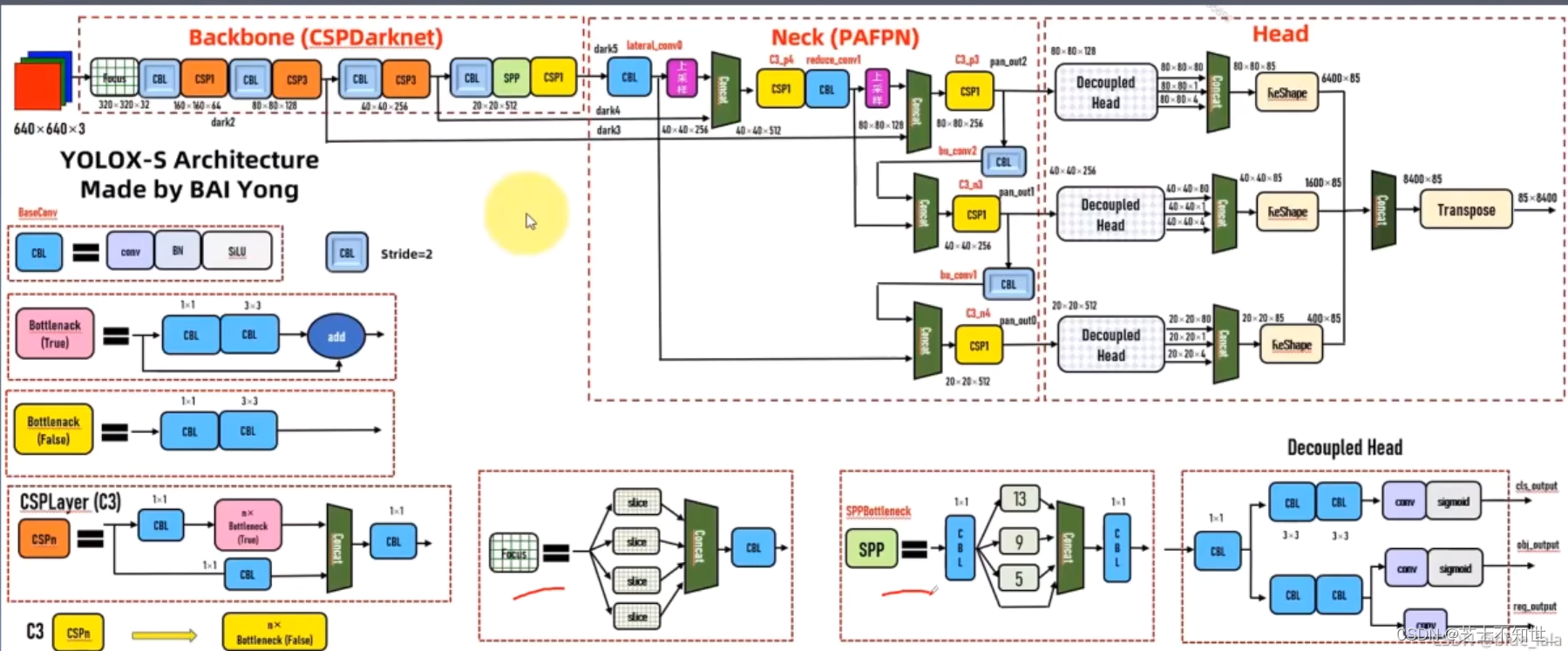
创新:之前的Yolo都是将特征耦合为三个部分,YoloX将特征解耦融合。
YOLO v6

Yolov6网络结构
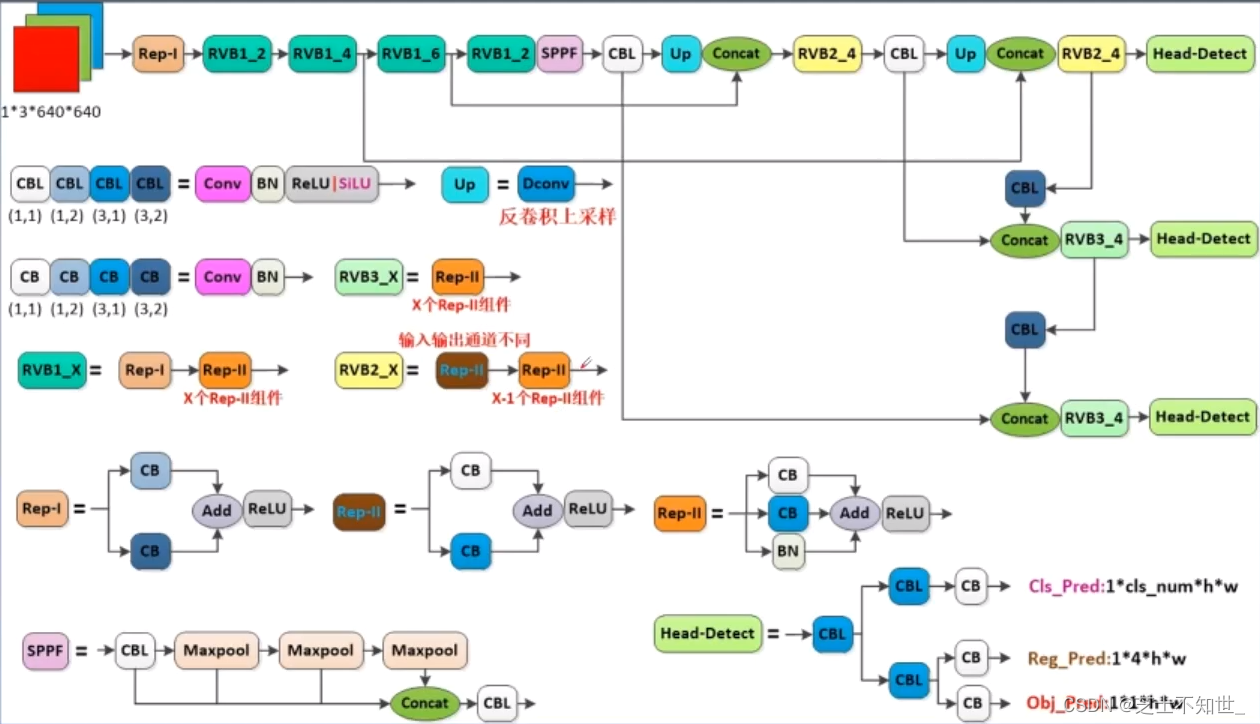
Bancbone:EfficientRep Bancbone
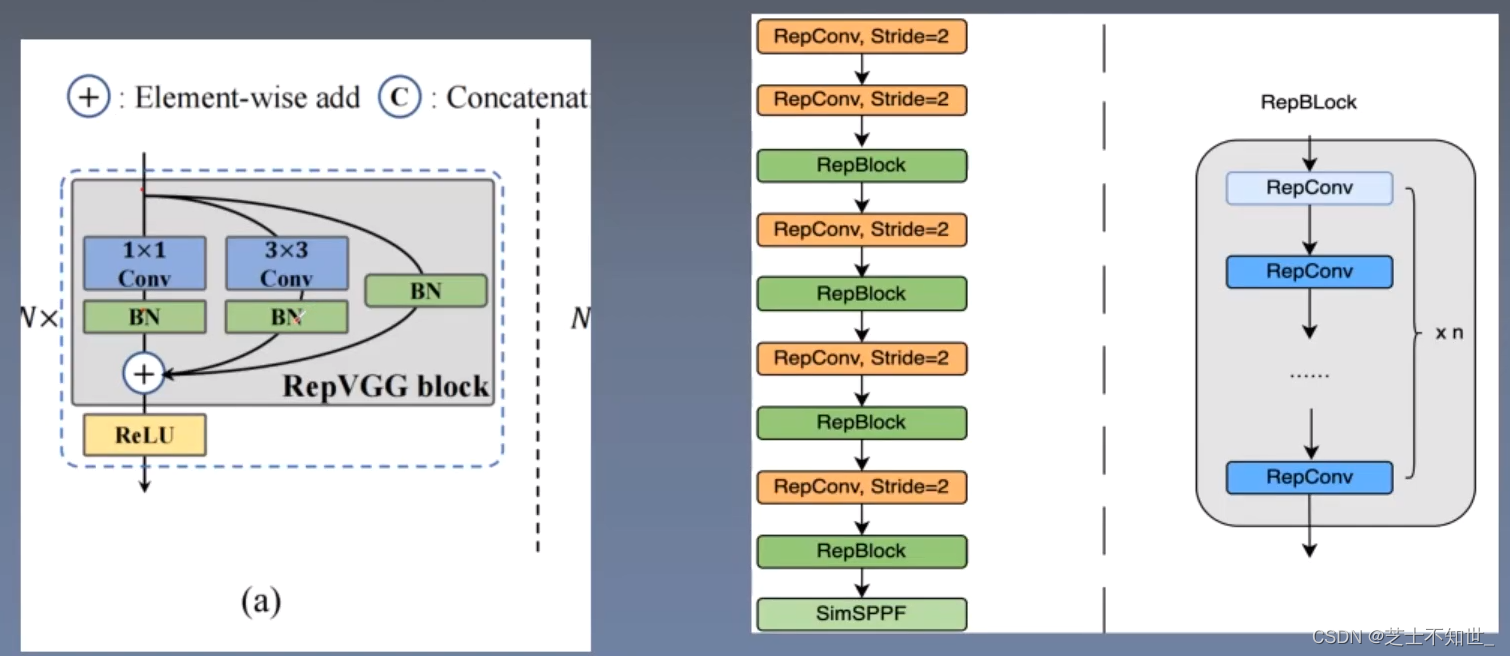
Neck:RepPAN Neck
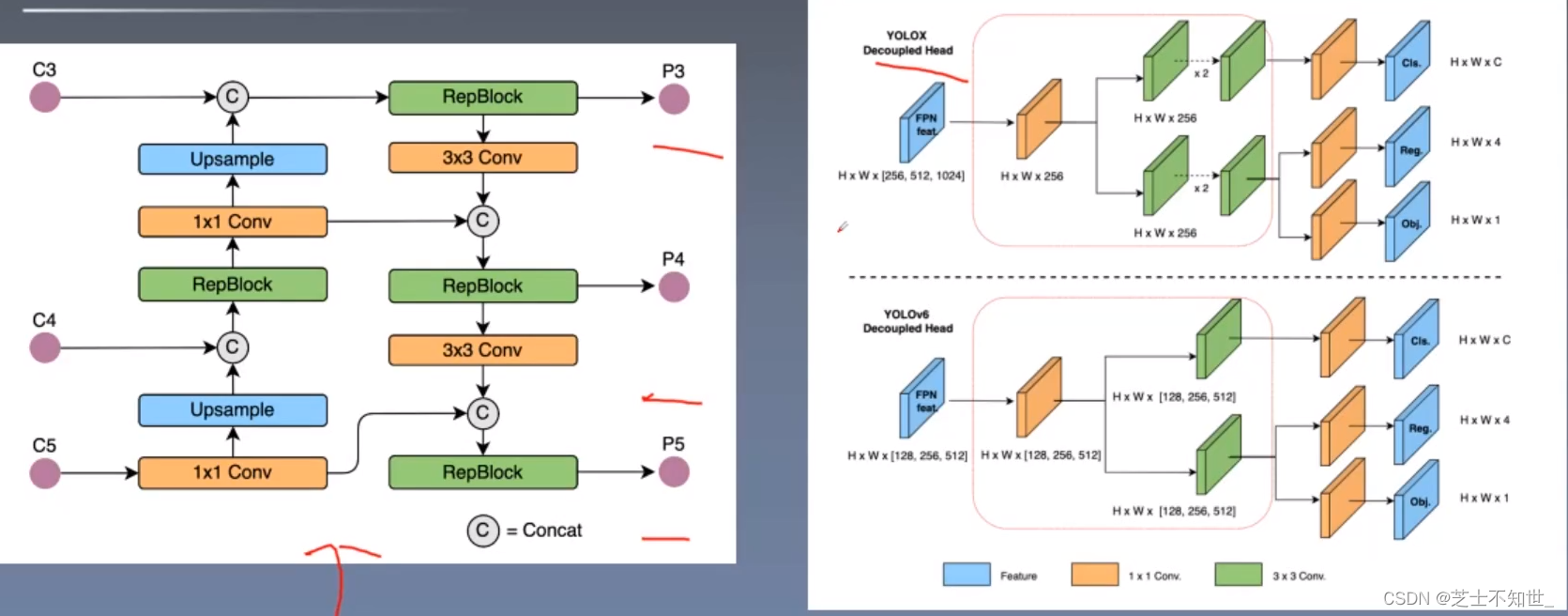
训练策略:
- Anchorless
- SimOTA标记策略
- SIoU盒回归的损失
YOLO v7
Yolov7网络结构
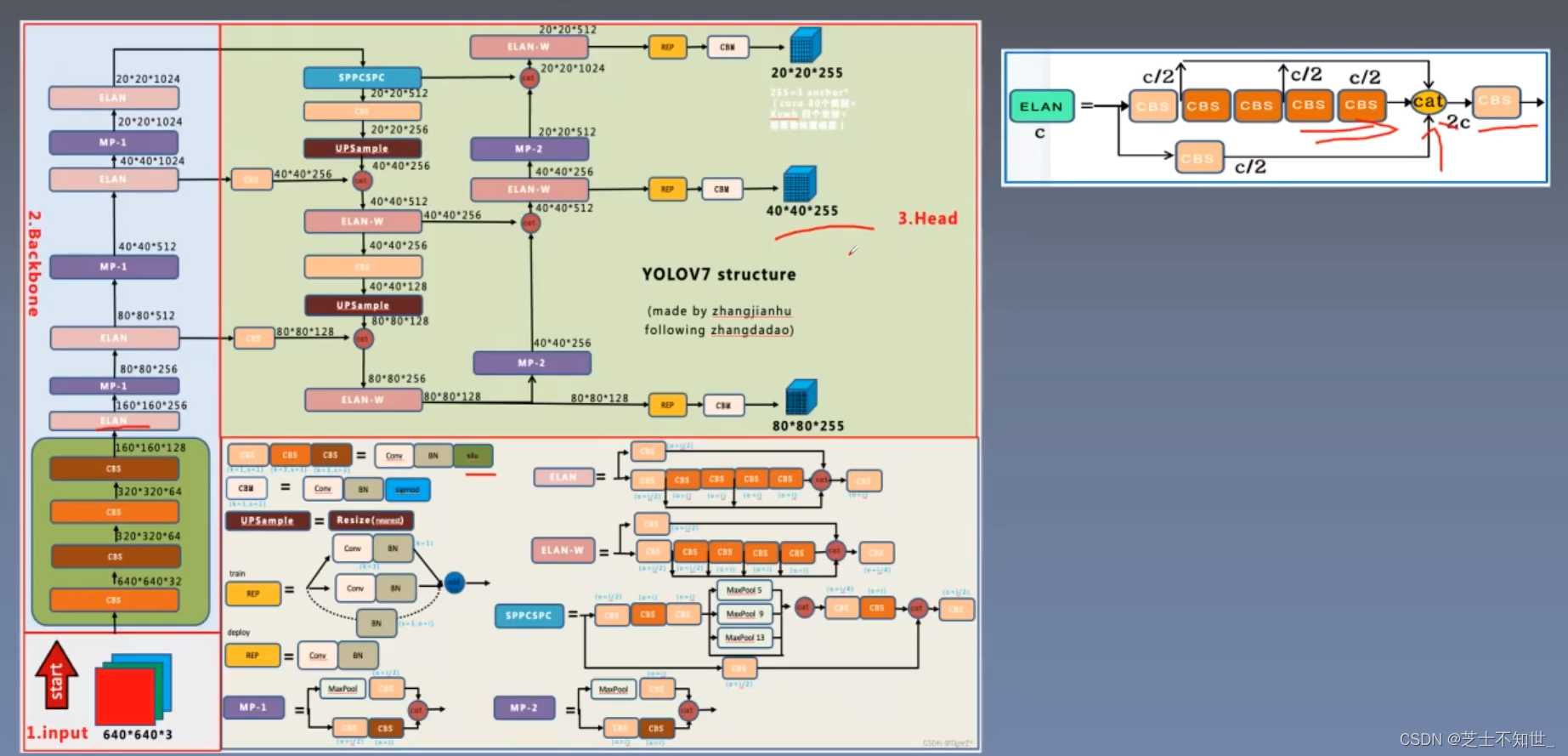
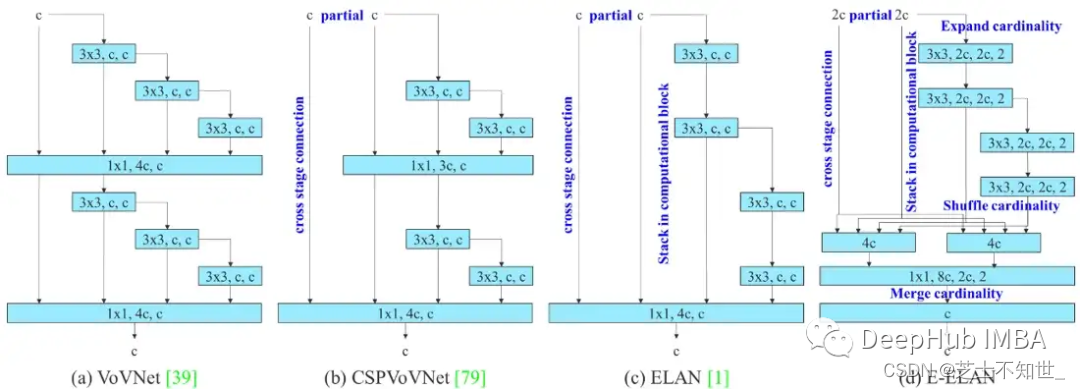
E-ELAN(扩展高效层聚合网络)
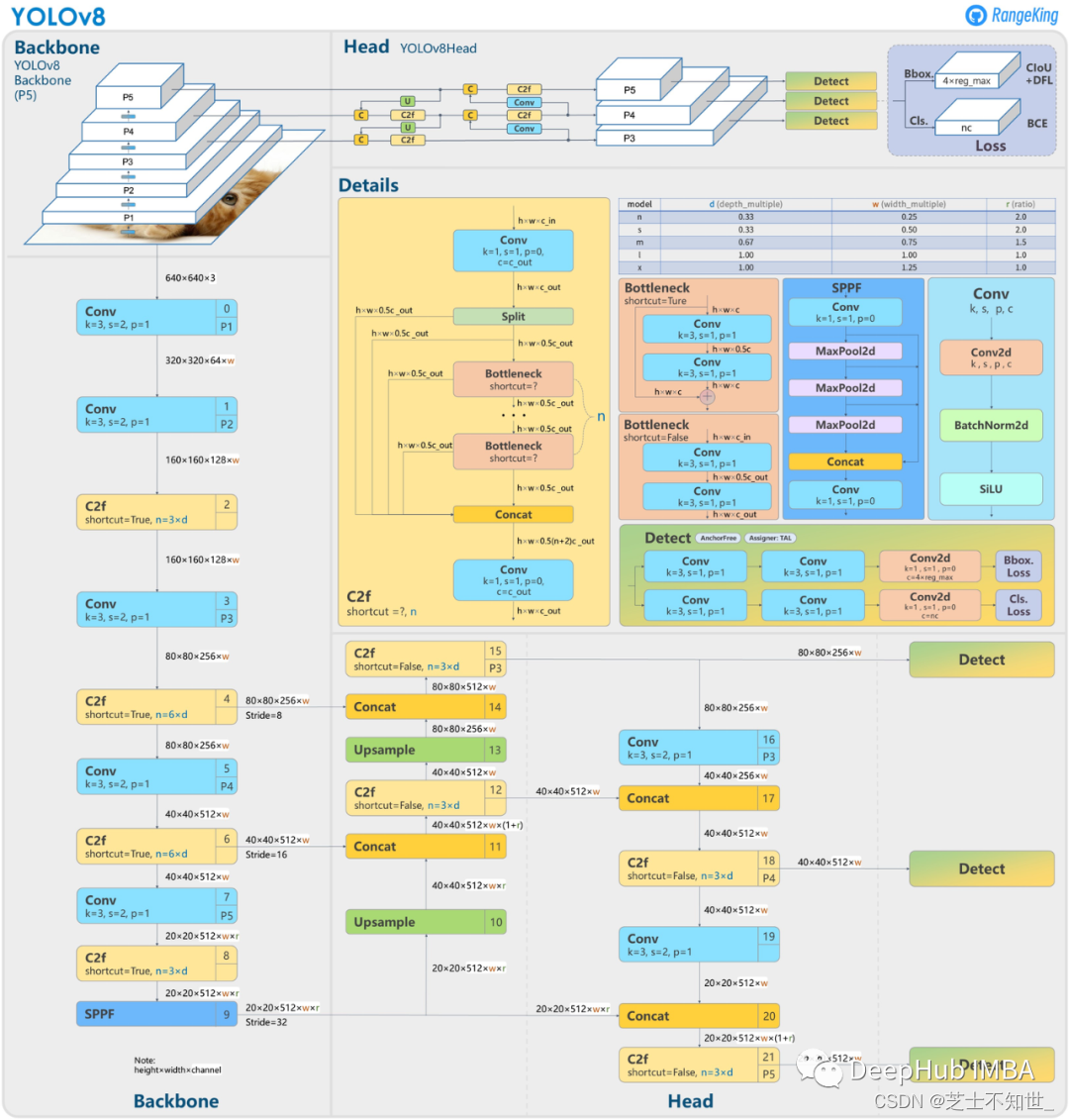
YOLO v8
Yolov8网络结构
无锚点
YOLOv8是一种无锚点模型,这意味着它直接预测对象的中心,而不是已知锚框的偏移量。锚点是早期YOLO模型中众所周知的很麻烦的部分,因为它们可能代表目标基准框的分布,而不是自定义数据集的分布。
无锚点减少了预测框的数量,从而加快了非最大抑制(NMS)的速度。下图为V8的检测头部分的可视化:
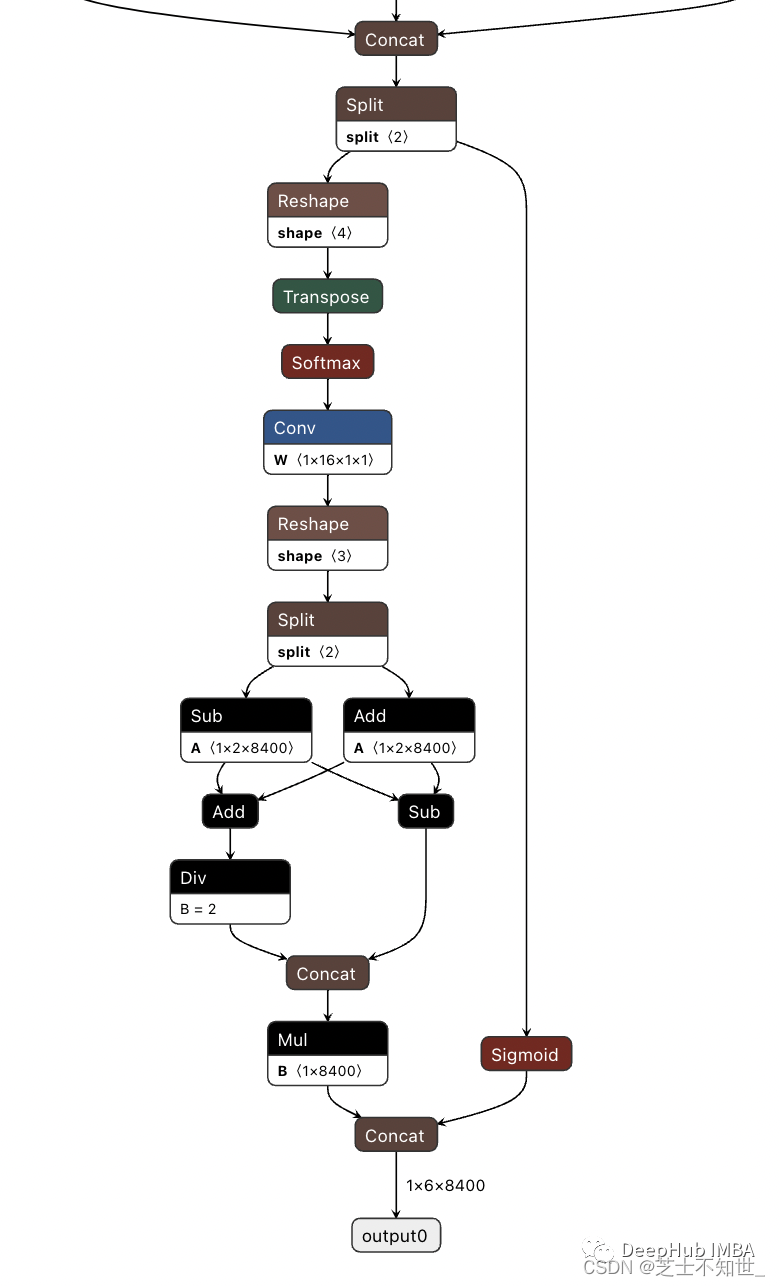
新的卷积
stem 的第一个 6×6 conv 变为 3×3,主要构建块也使用C2f 取代了 C3。该模块总结如下图,其中“f”是特征数,“e”是扩展率,CBS是由Conv、BatchNorm和后面的SiLU组成的块。
在 C2f 中,Bottleneck 的所有输出(两个具有剩余连接的 3×3 卷积)都被连接起来。而在 C3 中,仅使用了最后一个Bottleneck 的输出
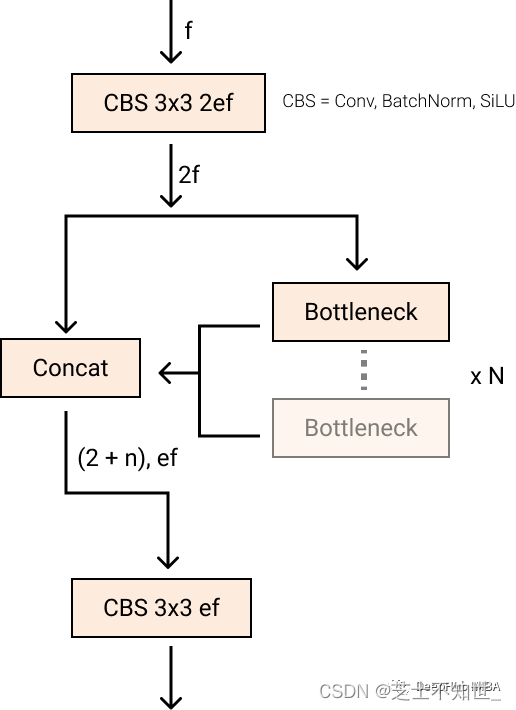
Bottleneck 与YOLOv5中相同,但第一个conv核大小从1×1更改为3×3。我们可以看到YOLOv8开始恢复到2015年定义的ResNet块。
neck部分,特征直接连接,而不强制相同的通道尺寸。这减少了参数计数和张量的总体大小。
总结
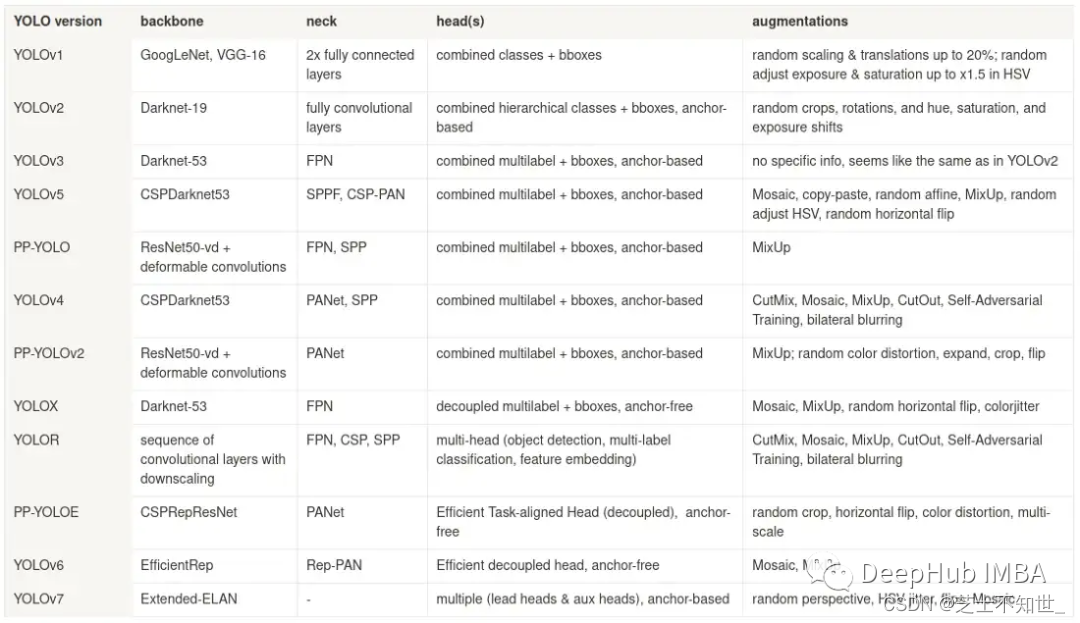
虽然上表并未提及所有提高性能的改进和发现。但是YOLO的发展我们可以看到一些模式。
Backbone 最初由一个分支(GoogLeNet、VGG、Darknet)组成,然后过渡到包含跳跃连接的架构(Cross-Stage Partial connections — CSPDarknet、CSPRepResNet、Extended-ELAN)。
Neck 最初也由一个分支组成,然后以特征金字塔网络的各种修改形式逐步发展,这样可以在不同尺度下保持物体检测的准确性。
Head:在早期版本中只有一个 head,它包含所有输出参数——分类、bbox 的坐标等。后面的研究发现将它们分成不同的头会更有效率。从基于锚点到无锚点也发生了转变(v7 除外——出于某种原因,它仍然有锚点)。
数据增强:仿射变换、HSV 抖动和曝光变化等早期增强非常简单,不会改变对象的背景或环境。而最近的一些——MixUp、Mosaic、CutOut 等改变了图像的内容。平衡这两个方向增强的比例对于神经网络的有效训练都很重要。
目标检测面试提问总结
1.规范化(包括归一化,标准化,正则化)
数据的规范化包括归一化、标准化、正则化,是一个统称。
数据规范化是数据挖掘中的数据变换的一种方式,数据变换将数据变换或统一成适合于数据挖掘的形式,将被挖掘对象的属性数据按比例缩放,使其落入一个小的特定区间内,如[-1, 1]或[0, 1]。
标准化(standardization):
数据预处理,数据标准化是将数据按比例缩放,使其落入到一个小的区间内,标准化后的数据可正可负,但是一般绝对值不会太大,一般是z-score标准化方法:减去期望后除以标准差。使得不同度量之间的特征具有可比性,同时不改变原始数据的分布。

归一化(normalization):
数据预处理,把数值放缩到0到1的小区间中(归到数字信号处理范畴之内),使得数据无量纲化、避免不同列数据的数量级相差过大、满足梯度下降法(小学习率)需要、加快参数的收敛速度。

正则化(regularization):
模型的loss的一项 ,在求解最优化问题中,调节拟合程度的参数一般称为正则项,越大表明欠拟合,越小表明过拟合。
正则化的一般形式是在整个平均损失函数的最后增加一个正则项(L1/L2范数正则化),限制其较高次项的参数大小不能过大。
正则项越小,惩罚力度越小,极端等于0表示不做惩罚,则会造成过拟合问题;正则化越大,惩罚力度越大,则容易出现欠拟合问题。
2.Dropout和BN批归一化
Dropout和BN都是防止过拟合的一种模型内部结构。
-
Dropout是一种随机删除网络中隐藏和可见单元的技术,可以以防止数据过拟合(通常删除20%内的节点)。它使收敛网络所需的迭代次数增加。
-
Batch Normalization是一种通过对每一层的输入进行
标准化,变为平均为0,标准差为1的正态分布,从而提高神经网络性能和稳定性的技术,减小对参数初始值的依赖,避免过拟合。
BN和预处理的标准化不同:预处理作用在模型输入之前,BN作用在模型内部,当输入一个Batch数据时,经过模型的BN层对该批数据进行标准化,使得新的分布更切合数据的真实分布,保证模型的非线性表达能力。
不同时期的BN:
在训练时,我们会对同一批batch的数据的均值和方差进行求解,进而进行归一化操作。
对于预测阶段时所使用的均值和方差,其实也是来源于训练集每个batch的均值和方差期望值。比如我们在模型训练时我们就记录下每个batch下的均值和方差,待训练完毕后,我们求整个训练样本的均值和方差期望值,作为我们进行预测时,对单张图像进行BN的的均值和方差:
BN的使用位置:在CNN中一般应作用与非线性激活函数之前,s型函数s(x)的自变量x是经过BN处理后的结果。
3.过拟合与欠拟合
本质是数据集(数量/噪声),模型参数(复杂度),正则化,训练策略(迭代次数/EarlySTopping/其他超参数)4方面的适配!
Underfitting欠拟合:泛化能力差,Train训练集、Val验证和Test测试集准确率都低。
原因:训练样本数量少,模型复杂度过低,参数还未收敛就停止循环。
解决方法:①增加样本数量、②增加模型参数,提高模型复杂度、③增加循环次数、④查看是否是学习率过高导致模型无法收敛
Overfitting过拟合:泛化能力差,Train训练集准确率高,Val验证和Test测试集准确率低。
原因:数据噪声太大、特征太多、模型太复杂。
解决方法:①减少模型参数,降低模型复杂度、②增加惩罚因子(正则化),保留所有的特征,但是减少参数的大小(magnitude)、③清洗数据、④Early Stopping!!、⑤Dropout和BN。
合适的拟合程度:泛化能力强,训练集准确率高,验证和测试集也准确率高。
4.Loss函数
loss函数描述模型的预测值与真实值之间的差距大小,指导模型在训练过程中朝着收敛的方向前进。
常见loss:
均值平方差MSE(回归损失)
数理统计中演化而来,均方误差是指参数估计值和参数真实值之差平方的期望值。在此处其主要是对每个预测值与真实值作差求平方的平均值,具体公式如下所示:
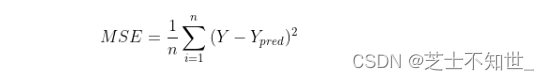
MSE越小代表模型越好,类似的算法还包括RMSE和MAD。
交叉熵Cross Entropy(分类损失)
交叉熵(crossentropy)刻画了两个概率分布之间的距离,更适合用在分类问题上,因为交叉熵表达预测输入样本属于某一类的概率。其公式如下所示:
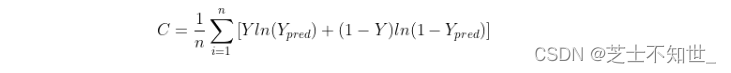
与MSE一样,交叉熵也是值越小代表模型精度越高。
5.梯度消失与梯度爆炸
斜率(梯度/导数)可能会变得太小或太大,这使得训练非常困难,导致训练时间长,性能差,精度低。
梯度消失:当斜率太小接近0时,训练时loss一直为0,少见。
原因:网络太深、损失函数不合理。
梯度爆炸:当坡度趋向于指数增长特别大时,训练时模型无法从训练数据中获得更新,或loss变化不稳定,或loss一直是NaN,常见。
原因:网络太深、初始值不合理。
解决:预训练+微调、减少网络层数、使用 ReLU 激活函数、使用梯度截断Gradient Clipping(检查误差梯度的值是否超过阈值,如果超过,则截断梯度,将梯度设置为阈值)、使用权重正则化Weight Regularization、引入残差、BN。
6.激活函数作用
非线性变换激活函数的主要作用是使网络具有非线性拟合能力,如果没有激活函数,那么神经网络只能拟合线性映射,即便是有再多的隐藏层,整个网络跟单层神经网络是等价的。因此,只有加入激活函数后,神经网络才具备了非线性的学习能力.
7.FLOPS
FLoating point Operations Per Second的缩写,即前向推理过程中,每秒浮点乘加运算次数,或表示为计算速度。是一个衡量硬件性能的指标。通俗点讲 模型计算量。FLOPS越大,模型推理时延越长。
8.Anchor机制(Yolov3及以后的)
yolov1每个格子只有1个Anchor,yolov2每个格子只有2个Anchor,且均为单一尺度。
先验框Anchor发音(类似uncle叔叔)
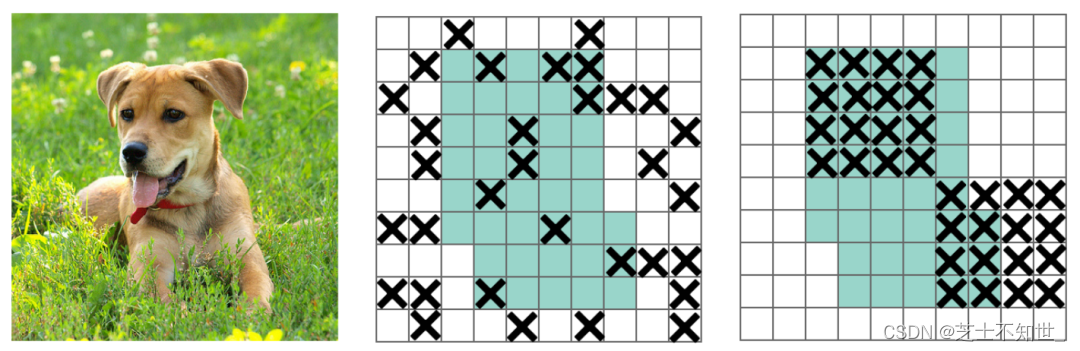
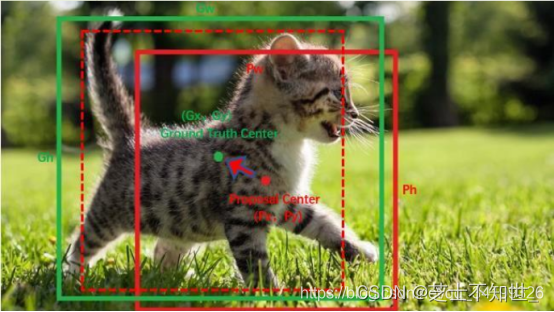
如下图人和车的中心点都位于同一网格grid_8中,如果没有anchor机制的话,grid_8就存在属于哪一类的问题,如果属于车类,那只能用来预测车,人类就会被忽略,如果属于人类,那么车类将会被忽略。
为了解决同一网格属于两个类的问题,引入了anchor机制,一个grid可以有3个anchor(对于yolo3),图中的紫色框为anchor,那么横着的anchor框就被用于预测车类,竖着的预测人类,从而解决了同一grid包含两类的问题。说白了,anchor就是来确认正负样本的,也就是样本的类别。

在训练时,从训练集中根据真实框Ground true box聚类得到的几个不同尺寸的框,在每一个网格附近找出这k种形状,计算Anchor box与Ground true box计算IOU,取最合适的先验框,然后平移加尺度缩放微调,作为物体的预测框Bounding box。
例如,对于Yolov3来说,输出为3个尺度的特征图,分别为13×13、26×26、52×52,对应着9个anchor,每个尺度均分3个anchor。
最小的13×13特征图上由于其感受野最大,应该使用大的anchor(116×90),(156×198),(373×326),这几个坐标是针对原始输入的,即416×416的,因此要除以32把尺度缩放到13×3下使用,适合较大的目标检测。
中等的26*26特征图上由于其具有中等感受野故应用中等的anchor box (30×61),(62×45),(59×119),适合检测中等大小的目标。
较大的52*52特征图上由于其具有较小的感受野故应用最小的anchor box(10×13),(16×30),(33×23),适合检测较小的目标。
具体使用就是每个grid cell都有3个anchor box。
每个格子3个anchor,哪个anchor负责匹配该格子里的物体呢?
和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的3个anchor box负责预测它,具体是哪个anchor box预测它,需要在训练中确定,即由3格anchor box中,那个与ground truth的IOU最大的anchor box预测它,而剩余的2个anchor box不与该ground truth匹配。YOLOv3需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的anchor box计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的anchor box只计算置信度误差(此时target为0)。
有了平移(tx,ty)和尺度缩放(tw,th)才能让anchor box经过微调与grand truth重合,得到预测框Bounding box。 如上图,红色框为anchor box,绿色框为Ground Truth,平移+尺度缩放可实线红色框先平移到虚线红色框,然后再缩放到绿色框。边框回归最简单的想法就是通过平移加尺度缩放进行微调。
anchor其实就是对预测的对象范围进行约束,并加入了尺寸先验经验,从而实现多尺度学习的目的。
8.NMS非极大抑制
作用:筛选框,去重叠。
操作:①在输出框间进行置信度排序,②将其他框与置信度最大的框,计算重叠度IOU,删除大于阈值的框(置信度置0),③除了最大框和删除框,在剩下框中,继续①②操作,每进行一次①②操作,就有一个置信度最大的框被保留下来。④最后得到每轮中置信度最大的框作为输出。
NMS(Non Maximum Suppression,非极大值抑制)是目前检测算法常用的后处理操作,在目标检测算法中,我们希望每个目标都有一个预测框可以准确地圈出目标的位置并给出预测类别。检测模型的输出预测框之间可能存在重叠,比如图中针对某一个目标可能存在多个可能是车辆的矩形框,此时我们需要判断哪些框有用,哪些框无用。

非极大值抑制的方法是先假设有6个矩形框,根据分类器的分类概率排序,从小到大属于车辆的概率分别为A、B、C、D、E、F。
从最大概率矩形框F开始,依次判断A~E与F的重叠度IoU是否大于某个设定的阈值。假设B、D与F的重叠度超过阈值,则抛弃B、D,保留第一个矩形框F。
从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,则抛弃A、C,并标记E是我们保留下来的第二个矩形框。
就这样一直重复上述过程,直到找到所有被保留下来的矩形框即F和E两个框。
总结来说,排序、选最大、依次算IOU、删除、重复上述。
9.如何将目标检测算法封装成一个detector类
项目部署时,不需要demo中很多操作,只需要载入模型,进行推理,返回结果。
class Yolo_detector:
def __init__(self,
weigth: str, # 训练好的模型权重路径
confidence: float = 0.5, # 置信度阈值
iou_thresh: float = 0.45, # IoU阈值
device: str='', # 推理设备
img_size: int = 640 # 推理图片大小
) ->None:
self.model= Yolo()
...
def start_video(self, video_path):
...
def start_image(self, image_path):
...
推理时:
文章出处登录后可见!