目录
说明
如果是单个GPU或CPU可通过torch.cuda.is_available()来设置是否使用GPU
# 单GPU或者CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
对于多GPU设备而言,如果要定义设备,则需要使用torch.nn.DataParallel来将模型加载到多个GPU中
# 判断GPU设备大于1,也就是多个GPU,则使用多个GPU设备的id来加载
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model,device_ids=[0,1,2])
也可以使用DistributedDataParallel分布式计算实现多机多卡的计算。
单GPU/CPU情况
在pytorch中可以通过.cuda()以及.to(device)两种方式将模型和数据复制到GPU的显存中计算。以下说明是在单GPU或者CPU中的情况。
.to(device)方法可以指定CPU或者GPU。也就是可以定义设备,然后将数据或者模型加载到设备中,代码如下:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 或device = torch.device("cuda:0")
# 或device = torch.device("cuda:1")
print(device)
# 需要提前初始化一下model
model.to(device)
# 计算的时候将数据加载到device
for batch_idx, (img, label) in enumerate(train_loader):
img=img.to(device)
label=label.to(device)
.cuda()只能通过os.environ['CUDA_VISIBLE_DEVICE']来指定GPU
#指定某个GPU
os.environ['CUDA_VISIBLE_DEVICE']='1'
# 判断GPU是否能用,如果能用,则将数据和模型加载到GPU上
if torch.cuda.is_available():
data = data.cuda()
model = model.cuda()
多GPU
为了加速训练过程,往往会使用多个GPU设备来进行并行训练,常见的多GPU应用场景如下:
- 数据并行(data parallel):该方案可加速模型的训练速度。该方案将模型复制,并加载到每一个GPU上,对数据集进行划分,分别在不同的GPU上同时训练。
- 模型并行(model parallel):该方案中模型需要的显卡内存很大,一张GPU显存不足以加载整个模型,需要将模型划分为多个部分,每个部分放到不同的GPU设备中。这种情况下一般不能加速模型的训练。
在Pytorch中,实现多GPU的方法有torch.nn.DataParallel 和torch.nn.parallel.DistributedDataParallel :
torch.nn.DataParallel是单进程多线程的方法,仅能工作在单机多卡的情况下。torch.nn.parallel.DistributedDataParallel方法是多进程多线程的,适用于单机多卡和多机多卡的情况(在单机多卡的情况下DistributedDataParallell也比DataParallel的速度更快)
在pytorch中,单机多卡和多级多卡的训练教程可参考:PyTorch Distributed Overview
DataParallel
参考:torch.nn.DataParallel Optional: Data Parallelism教程
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
- module:表示定义的模型,也就是需要加载到GPU上的模型对象
- device_ids:表示训练时候需要使用的GPU设备集合
- output_device:表示输出的结果在该设备上,默认是第一块GPU卡上,所以第一块卡的显存占用比其他卡要多一些。
该方法的优势在于实现简单,不涉及多进程操作,主要在于使用torch.nn.DataParallel将模型wrap(包装)一下:
>>> net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
>>> output = net(input_var) # input_var可以在任何设备上,包括CPU上
该代码实现过程是:首先在前向传播过程中,将输入的数据划分为多个子部分送到不同的device中进行计算,而模型是在每个GPU上都复制一份。也就是说将数据分为device个的子数据输入到各个
device_ids中,然后将模型复制加载到每个device中对该GPU上的数据进行训练,训练结束后,将每个GPU上计算出来的数据收集到output_device上合并计算。概括来说就是:DataParallel 会自动帮我们将数据切分并 load 到相应 GPU上,并在每个GPU上都加载模型进行正向传播计算梯度,并汇总到output_device。
可以看出,torch.nn.DataParallel方法不改变模型的输入和输出,因此只需要将模型用函数torch.nn.DataParallel将模型wrap(包装)一下即可,无需其他操作。非常方便。但是后续的loss计算只会在output_device上进行,没法并行,因此会导致负载不均衡的问题。并且,对于后续的loss计算,由于来自与多个GPU中,因此需要取一下平均(多维的):
if gpu_count>1:
loss = loss.mean()
其实在使用torch.nn.DataParallel这个方法使用多GPU的时候,一般可以设置os.environ['CUDA_VISIBLE_DEVICES']来限制使用的GPU个数:
# 使用编号第0个和第2个的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0,2'
需要注意的是,该该参数设置需要在模型加载到GPU之前,一般是在程序最开始,导包之后设定。一般加载方式如下:
# 加载模型
model = torch.nn.DataParallel(model)
model.cuda()
# 加载数据
inputs = inputs.cuda()
labels = labels.cuda()
在官方教程中,加载模型和加载数据方式不是使用.cuda()方式,但是基本原理差不过,查看DataParallel内部实现发现其实差不多。
DistributedDataParallel
由于DataParallel会存在负载不均衡问题。官方提供的解决方案是使用torch.nn.parallel.DistributedDataParallel来代替。而且DistributedDataParallel运行更快,现存分配更加均衡,功能更加强悍。
- 单机多卡:直接使用DistributedDataParallel
- 多机多卡:需要使用DistributedDataParallel和运行脚本来设计。官方提供的一个例子:examples/README.md at main · pytorch/examples · GitHub
使用DistributedDataParallel(简称DDP)来进行分布式计算需要考虑:
- 数据集如何在不同设备间分配
- 误差梯度如何在不同设备之间通信
- Batch Normalization如何在不同设备之间同步
而DDP使用流程如下:
- 使用 torch.distributed.init_process_group 初始化进程组
- 使用 torch.nn.parallel.DistributedDataParallel 创建分布式并行模型
- 创建对应的 DistributedSampler和BatchSampler,制作dataloader
- 使用 torch.multiprocessing/torch.distributed.launch 开始训练
1. 使用 torch.distributed.init_process_group 初始化进程组
首先可通过os.environ['CUDA_VISIBLE_DEVICES']来设置指定的GPU来使用。然后初始化:
torch.distributed.init_process_group(backend='nccl', init_method='tcp://localhost:23456', rank=0, world_size=1)
- backend:后端,实际上是多个机器之间交换数据的协议。用于分布式训练时,多个计算设备之间的集合通信,常见的有
Open MPI(不怎么用)、NCCL、Gloo等。后端选择好了之后, 因为多个主机之间需要通过网络进行数据交换,需要设置网络接口, 对于nccl和gloo一般会自己寻找网络接口, 但是某些时候, 可能需要自己手动设置:import os # 说明,其中网卡名字需要自己去找,如果是linux可通过ifconfig来查看。 # 使用gloo后端需要设置的 os.environ['GLOO_SOCKET_IFNAME'] = 'eth0' # 使用nccl需要设置的 os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
init_method:机器之间交换数据, 需要指定一个主节点, 而这个参数就是指定主节点的。有TCP和共享文件系统等方式设置。使用TCP格式为tcp://ip:端口号,ip是主节点的ip地址,rank参数为0的那个主机ip地址,然后选择一个空闲的端口号即可。
rank:rank是标识主机和从机的, 主节点为0, 剩余的为了1-(N-1), N为要使用的机器的数量。
world_size介绍说是进程个数,其实就是机器的个数,如果有两台机器一起训练的话,world_size就是2
2. 使用 torch.nn.parallel.DistributedDataParallel 创建分布式并行模型
模型的处理其实和上面的单机多卡没有多大区别, 还是下面的代码, 但是注意要提前想把模型加载到gpu, 然后才可以加载到DistributedDataParallel
model = model.cuda()
model = nn.parallel.DistributedDataParallel(model)
3. 创建对应的 DistributedSampler和BatchSampler,制作dataloader
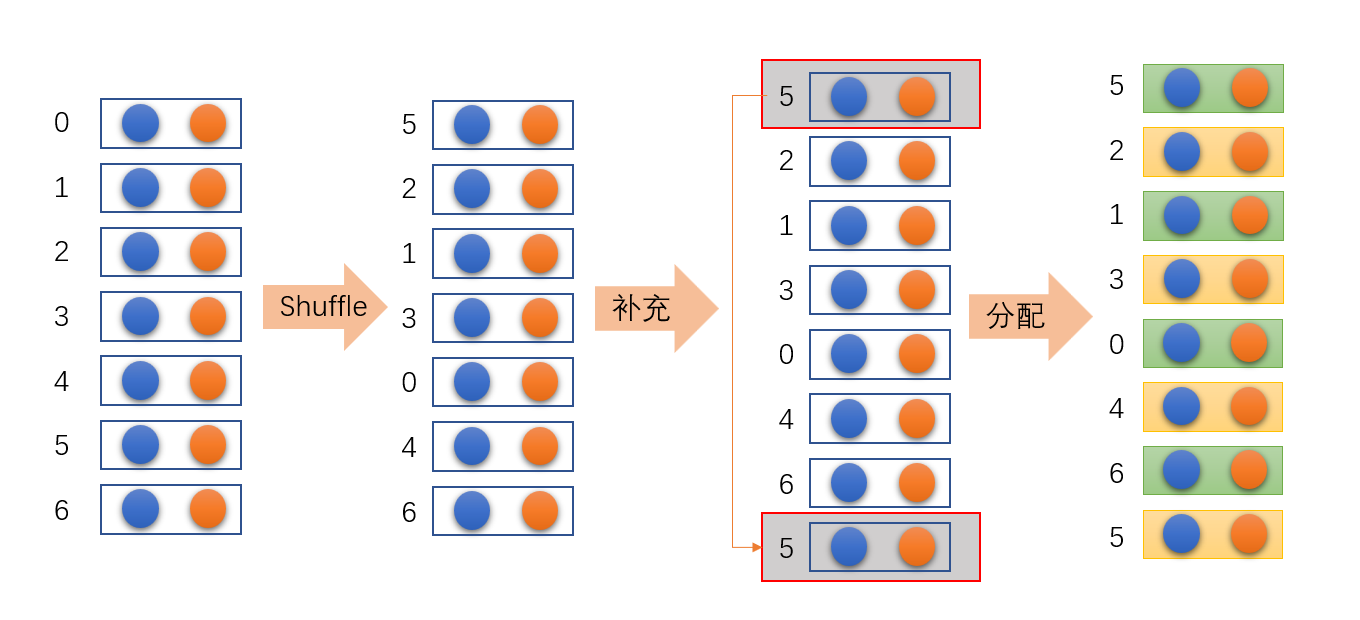
对于torch.utils.data.distributed.DistributedSampler方法的作用是将数据集进行打乱,然后根据GPU的个数自行补充数据,并对补充后的数据分配到不同的GPU设备上。如图:
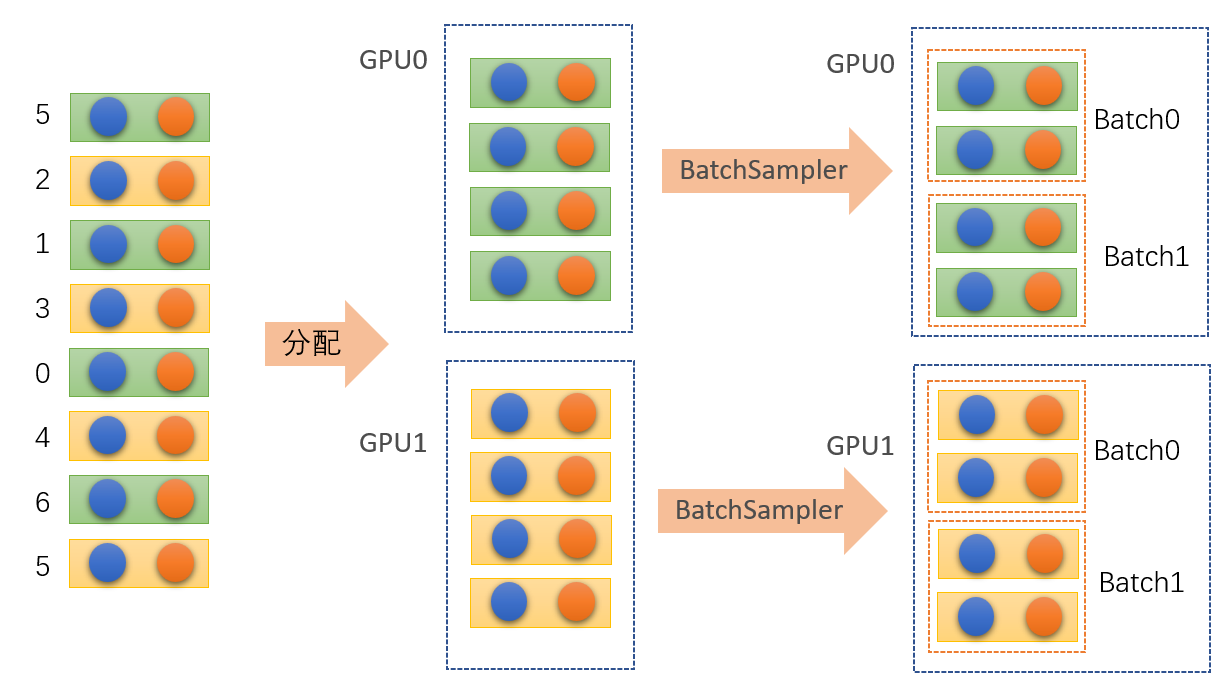
对于torch.utils.data.BatchSampler方法的作用是将torch.utils.data.distributed.DistributedSampler分配给GPU的数据按照batch_size分配成一个个的batch。
# 实例化训练数据集
train_data_set = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_data_set = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
# 给每个rank对应的进程分配训练的样本索引
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data_set)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_data_set)
# BatchSampler是对train_sampler做进一步的处理,组成一个一个的batch
train_batch_sampler = torch.utils.data.BatchSampler(train_sampler,
batch_size,
drop_last=True)
val_batch_sampler = torch.utils.data.BatchSampler(val_sampler,
batch_size,
drop_last=True)
4. 使用 torch.multiprocessing/torch.distributed.launch 开始训练
在Pytorch中使用多GPU的常用启动方式一种是
torch.distributed.launch一种是torch.multiprocessing模块。这两种方式各有各的好处,在我使用过程中,感觉torch.distributed.launch启动方式更方便,而且我看官方提供的多GPU训练FasterRCNN源码就是使用的torch.distributed.launch方法,所以我个人也比较喜欢这个方法。但在官方的教程中主要还是使用的torch.multiprocessing方法,官方说这种方法具有更好的控制和灵活性。在自己使用体验过程中确实和官方说的一样。
这里提醒下要使用torch.distributed.launch启动方式的小伙伴。训练过程中如果你强行终止的程序,在开启下次训练前建议你通过nvidia-smi指令看下你GPU的显存是否全部释放了,如果没有全部释放,需要手动杀下进程。在我使用过程中发现强行终止程序有小概率出现进程假死的情况,占用的GPU的资源并没有及时释放,如果在下次训练前没有及时释放,会影响你的训练,或者直接提示通信端口被占用,无法启动的情况。
对BN层进行同步处理
# 使用SyncBatchNorm后训练会更耗时
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
当然以上总结是我遇到的问题,没有在多机多卡上调试过,主要介绍多机多卡是因为torch.nn.parallel.DistributedDataParallel在很多开源代码中使用了,因为该方法可以在单机单卡上很好运行,但是在调试代码的时候可能会出现一些关于torch.nn.parallel.DistributedDataParallel方法的错误。这里简单介绍一下。后续如果遇到问题,可能还会继续补充。
补充知识点:
问题一:为什么要使用os.environ?
在python中,environ是一个字符串所对应环境的映像对象,怎么理解呢,就是可以通过os.environ获取有关系统的各种信息(比如环境变量),常用用法如下:
# 设置
os.environ['环境变量名称']='环境变量值' #其中key和value均为string类型
os.putenv('环境变量名称', '环境变量值')
os.environ.setdefault('环境变量名称', '环境变量值')
# 修改
os.environ['环境变量名称']='新环境变量值'
# 获取
os.environ['环境变量名称']
os.getenv('环境变量名称')
os.environ.get('环境变量名称', '默认值') #默认值可给可不给,环境变量不存在返回默认值
# 删除
del os.environ['环境变量名称']
del(os.environ['环境变量名称'])
# 判断
'环境变量值' in os.environ # 存在返回 True,不存在返回 False
在linux和window中存在一些常见的环境变量名称,这部分可以自行去查看API,对于pytorch中,使用os.environ['CUDA_VISIBLE_DEVICES'] = '0,2'表示指定使用GPU。
问题二:在训练网络的时候,其说明文档会出现CUDA_VISIBLE_DEVICES=0,1,2,3 python trainer.py 执行运行语句训练。但是该方法在window上会报错,如何解决?
在Linux系统上,直接使用就可以了,但是如果在Window系统上,会报错:
‘CUDA_VISIBLE_DEVICES’ 不是内部或外部命令,也不是可运行的程序或批处理文件。
解决方案有几种:
- 在运行程序中,也就是
train.py文件中加入os.environ['CUDA_VISIBLE_DEVICES'] = '0,2',并通过python train.py来运行 - 将
CUDA_VISIBLE_DEVICES加入到环境变量中,然后通过python train.py来运行 - 在cmd中输入
set CUDA_VISIBLE_DEVICES=0,2来设置临时变量到环境变量中,然后通过python train.py来运行
问题三:在window系统中,使用语句python -m torch.distributed.launch --help 提示NOTE: Redirects are currently not supported in Windows or MacOs.错误。那么对于执行语句中有该语句如何解决?
说明:
-m参数,m是module的缩写,表示将后面的模块当作脚本去运行,可通过python --help查看相关知识
# https://github.com/microsoft/Swin-Transformer/blob/main/get_started.md
# swin_transformer中提示的执行语句
python -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py --eval \
--cfg configs/swin/swin_base_patch4_window7_224.yaml --resume swin_base_patch4_window7_224.pth --data-path <imagenet-path>
上述表示使用模块torch.distributed.launch来运行main.py文件。会报错,在官方中有讨论:What does “NOTE: Redirects are currently not supported in Windows or MacOs.” mean in PyTorch? – PyTorch Forums
在window系统中版本1.10的torch版本中,可以运行,但是在版本1.13.0的torch中会报错,应该是版本问题。在pytorch对新版的改动中,将torch.distributed.launch替换为torchrun。因此考虑是否可以使用torchrun来替换。
> python -m torch.distributed.launch train.py
# 等价于
> torchrun train.py
在版本
1.11.0的pytorch版本中使用语句python -m torch.distributed.launch --help后有提示:FutureWarning: The module torch.distributed.launch is deprecated and will be removed in future. Use torchrun. Note that –use_env is set by default in torchrun. If your script expects ‘–local_rank’ argument to be set, please change it to read from ‘os.environ[‘LOCAL_RANK’]’ instead. See https://pytorch.org/docs/stable/distributed.html#launch-utility for further instructions.
翻译就是:未来警告:模块torch.distributed.launch已弃用,将被删除并使用torchrun。并且注意在torchrun中–use_env是默认被设置了的。如果你的script需要设置–local_rank参数,请使用’os.environ[‘LOCAL_RANK’]’ 来替代。更多请参考https://pytorch.org/docs/stable/distributed.html#launch-utility
参考:
文章出处登录后可见!