1. Series的索引和切片
1.1 Series的索引:
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时
返回的仍然是一个Series类型)。分为显示索引和隐式索引:
(1) 显式索引:
使用index中的元素作为索引值
使用.loc[ ]
s = pd.Series({'Python': 150, 'NumPy': 100, 'Pandas': 130})
s
NumPy 100
Pandas 130
Python 150
dtype: int64
# 显示索引: 使用索引名
print(s['Python']) # 值,int类型
print(s.NumPy)
# 使用2个中括号得到的类型:Series
# 一次取多个元素
s[['Pandas', 'NumPy']]
s[['Pandas']]
# 使用 loc[]
print(s.loc['Python'])
print(s.loc[['Pandas', 'NumPy']])
s.loc[['Pandas']]
150
100
150
Pandas 130
NumPy 100
dtype: int64
Pandas 130
dtype: int64(2) 隐式索引:
使用整数作为索引值
使用.iloc[ ]
# 隐式索引:使用数字下标
print(s[0])
print(s[[0, 2]])
print(s[[0]])
# 使用 iloc[]
s.iloc[0]
print(s.iloc[[0, 2]])
print(s.iloc[[0]])
# 下面这2个写法是错误的
# s.iloc['Python']
# s.loc[0]
100
NumPy 100
Python 150
dtype: int64
NumPy 100
dtype: int64
NumPy 100
Python 150
dtype: int64
NumPy 100
dtype: int641.2 Series的切片
s = pd.Series({
'语文': 100,
'数学': 150,
'英语': 110,
'Python': 130,
'Pandas': 150,
'NumPy': 150
})
# 切片
# Series是一维数组
# 隐式切片: 左闭右开
s[1 : 4]
s.iloc[1 : 4]
# 显式切片: 左闭右闭
s['数学' : 'Python']
s.loc['数学' : 'Python']
数学 150
英语 110
Python 130
dtype: int642. DataFrame的索引与切片
2.1 DataFrame的索引
(1) 对列进行索引:
通过类似字典的方式;通过属性的方式。
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name
属性也已经设置好了,就是相应的列名。
df = pd.DataFrame(
data=np.random.randint(10, 100, size=(4, 6)),
index=['小明', '小红', '小黄', '小绿'],
columns=['语文', '数学', '英语', '化学', '物理', '生物']
)
df.语文 # Series类型
df['语文']
# 使用2个中括号得到的类型:DataFrame
df[['语文', "化学"]]
df[['语文']]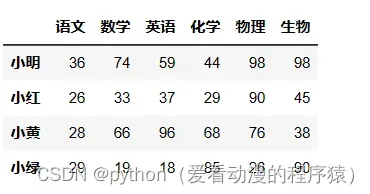
(2) 对行进行索引:
使用.loc[ ]加index来进行行索引
使用.iloc[ ]加整数来进行行索引
同样返回一个Series,index为原来的columns。
# 不可以直接取行索引
# df['小明']
# df.小明
# DataFrame默认是先取列索引
# 取行索引
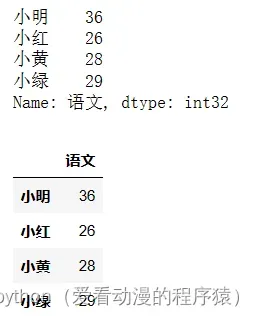
print(df.loc['小明']) # Series类型
df.iloc[0]
# 使用两个中括号: DataFrame类型
print(type(df.loc[['小明', '小绿']]))
df.loc[['小明']]
print(df.iloc[[0, -1]])
df.iloc[[0, 3]]
df.iloc[[0]]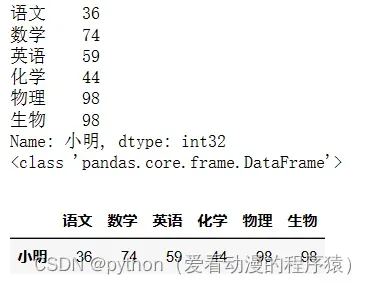
(3) 对元素索引的方法:
使用列索引;使用行索引(iloc[3,1]相当于两个参数;iloc[[3,3]] 里面的[3,3]看做一个参数);
使用values属性(二维NumPy数组)。
# 先取列,再取行
print(df['语文']['小明'])
df['语文'][0]
df.语文[0]
df.语文.小明
# 先取行,再取列
df.loc['小明']['语文']
df.loc['小明'][0]
print(df.iloc[0][0])
df.iloc[0]['语文']
df.iloc[0, 0]
df.loc['小明', '语文']
36
36
362.2 DataFrame的切片
直接用中括号时:
索引优先对列进行操作;切片优先对行进行操作
# 行切片
print(df[1: 3]) # 左闭右开
df['小红' : '小黄'] # 左闭右闭
print(df.iloc[1: 3]) # 左闭右开
df.loc['小红' : '小黄'] # 左闭右闭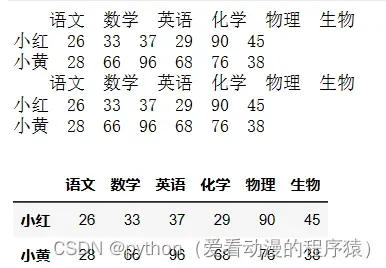
# 列切片
# 对列做切片,也必须先对行切片
df.iloc[ : , 1: 4]
df.loc[:, "数学": "化学"]总结:
取一行或一列 : 索引;取连续的多行或多列 : 切片;取不连续的多行或多列 : 中括号
3. 多层索引操作
(1) 隐式构造
最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组
data = np.random.randint(0, 100, size=(6, 6))
index = [
['1班', '1班', '1班', '2班', '2班', '2班'],
['张三', '李四', '王五', '鲁班', '张三丰', '张无忌']
]
columns = [
['期中', '期中', '期中', '期末', '期末', '期末'],
['语文', '数学', '英语', '语文', '数学', '英语']
]
df = pd.DataFrame(data=data, index=index, columns=columns)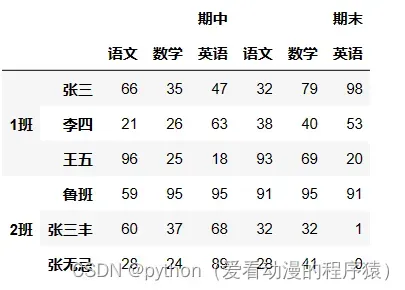
Series也可以创建多层索引:
data = np.random.randint(0, 100, size=6)
index = [
['1班', '1班', '1班', '2班', '2班', '2班'],
['张三', '李四', '王五', '鲁班', '张三丰', '张无忌']
]
s = pd.Series(data=data, index=index)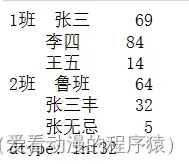
(2) 显示构造pd.MultiIndex
使用数组:
data = np.random.randint(0, 100, size=(6, 6))
index = pd.MultiIndex.from_arrays( [
['1班', '1班', '1班', '2班', '2班', '2班'],
['张三', '李四', '王五', '鲁班', '张三丰', '张无忌']
])
columns = [
['期中', '期中', '期中', '期末', '期末', '期末'],
['语文', '数学', '英语', '语文', '数学', '英语']
]
df = pd.DataFrame(data=data, index=index, columns=columns)
df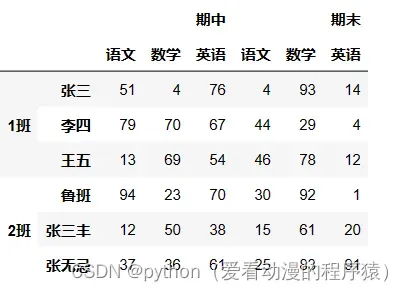
使用tuple:
data = np.random.randint(0, 100, size=(6, 6))
index = pd.MultiIndex.from_tuples(
(
('1班', '张三'), ('1班', '李四'), ('1班', '王五'),
('2班', '鲁班'), ('2班', '张三丰'), ('2班', '张无忌')
)
)
columns = [
['期中', '期中', '期中', '期末', '期末', '期末'],
['语文', '数学', '英语', '语文', '数学', '英语']
]
df = pd.DataFrame(data=data, index=index, columns=columns)
df使用product:
data = np.random.randint(0, 100, size=(6, 6))
# 笛卡尔积: {a, b} {c, d} => {a, c}, {a, d}, {b, c}, {b, d}
index = pd.MultiIndex.from_product( [
['1班', '2班'],
['张三', '李四', '王五']
])
columns = [
['期中', '期中', '期中', '期末', '期末', '期末'],
['语文', '数学', '英语', '语文', '数学', '英语']
]
df = pd.DataFrame(data=data, index=index, columns=columns)
df注意:除了行索引index,列索引columns也能用同样的方法创建多层索引
4. 多层索引对象的索引与切片
4.1 Series的操作
对于Series来说,直接中括号[]与使用.loc()完全一样
索引:
# 显式索引
s['1班']
s.loc['1班']
s[['1班']]
s[['1班', '2班']]
s['1班']['张三']
s.loc['1班']['张三']
s.loc['1班', '张三']
s['1班', '张三']
# 隐式索引
s[0]
s[1]
s.iloc[1]
s.iloc[[1, 2]]
切片:
# 切片
# 显式切片
s['1班' : '2班']
s.loc['1班' : '2班']
s.loc['1班'][:]
# 建议使用隐式索引
s[1 : 5]
s.iloc[1 : 5]
1班 李四 84
王五 14
2班 鲁班 64
张三丰 32
dtype: int324.2 DataFrame的操作
索引:
# 列索引
df['期中']
df['期中'][['数学']]
df['期中']['数学']
df['期中', '数学']
df.期中.数学
df.iloc[:, 2]
df.iloc[:, [0, 2, 1]]
df.loc[:, ('期中', '数学')]
# 行索引
df.loc['2班']
df.loc['2班'].loc['张三']
df.loc['2班', '张三']
df.loc[('2班', '张三')]
df.iloc[1]
df.iloc[[1]]
df.iloc[[1, 3, 4, 2]]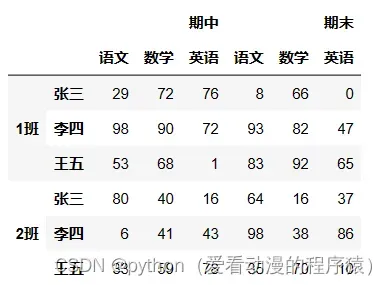
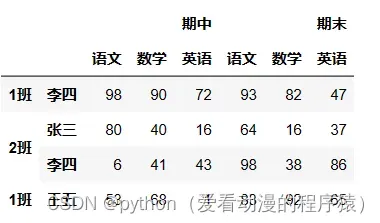
获取元素:
# 获取元素
df['期中']['数学']['1班']['张三']
df['期中']['数学']['1班'][0]
df.iloc[0, 1]
df.loc[('1班', '张三'), ('期中', '数学')]
72切片:
# 行切片
df.iloc[1 : 5]
df.loc[('1班', '李四') : ('2班', '李四')]
df.loc['1班' : '2班']
# 列切片
df.iloc[:, 1: 5]
df.loc[:, '期中': '期末']
# df.loc[:, ('期中', '数学') : ('期末', '数学')] # 报错
# 建议切片使用隐式索引5. 索引的堆叠
stack():使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里。
unstack():使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里。
# stack: 将列索引变成行索引
df.stack() # 默认是将最里层的列索引变成行索引
df.stack(level=-1)
df.stack(level=1)
df2 = df.stack(level=0)
df2 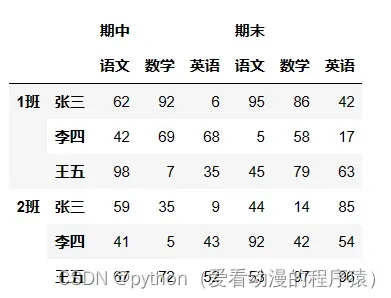

# unstack: 将行索引变成列索引
df2.unstack()
df2.unstack(level=-1)
df2.unstack(level=2)
df2.unstack(level=1)
df2.unstack(level=0)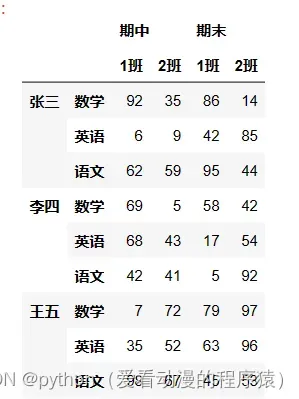
使用fill_value填充:
df.unstack()
df.unstack(fill_value=0)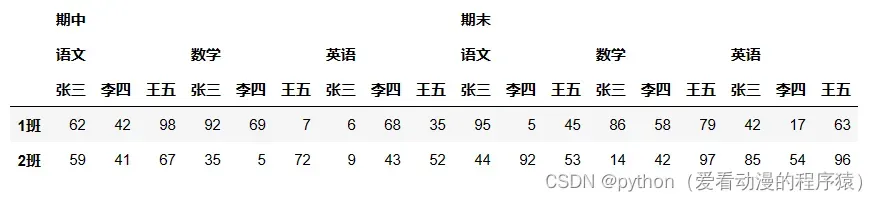
文章出处登录后可见!