以下内容来自官网教程
DEAP Basic tutorials:进化计算框架,提供了多种算法所需模块(GA, GP, DE, PSO…)
gplearn Welcome to gplearn’s documentation:python GP库,提供了符号回归,分类等方法
1.gplearn
1.1 Introduction(介绍)
gplearn用python实现Genetic Programming,和scikit-learn一样提供了可兼容API,GP在很多领域得到了广泛应用,gplearn主要用于解决Symbolic regression(符合回归)问题。Symbolic regression是一种机器学习技术,用于找到描述某种关系的基础数学表达式。它首先构建一组朴素的随机公式来表示已知自变量与其因变量之间的关系,基于公式可以为输入预测输出,通过与实际目标值对比 ,从种群中选择最适合的个体进行遗传操作,进化得到下一代程序。gplearn保留了scikit-learn中的fit/predict API,简单的用法如:
est = SymbolicRegressor()
est.fit(X_train, y_train)
y_pred = est.predict(X_test)
为了能定制化解决问题,gplearn提供了很多更细分的模块。gplearn主要致辞以下三类问题:
SymbolicRegressor:符号回归SymbolicClassifier:二分类SymbolicTransformer:自动化特征工程的转换
1.1.1 Representation(表达)
正如前面提到,GP想要找到一种数学表达式能代表某种关系,假设现在有两个变量x0和x1,其数学表达式和树存储的前序表达式如下
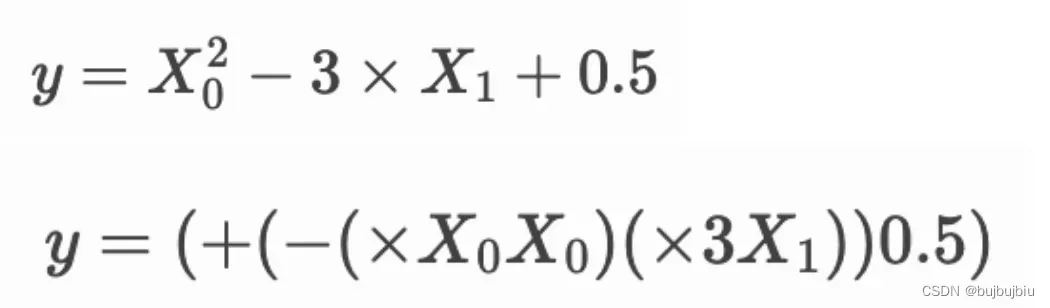
每个表达式中,有variables(变量),constants(常数)和functions(函数),在上面的例子中,函数有add,sub,mul,变量为x1和x0,常数为3.0和5.0。variables和constants称为terminals,terminals和functions称为primitive set(原始集)。用树表示表达式,如图深色点为functions,叶子结点为terminals。可以通过对树回溯得到原始表达式,从叶子结点开始,x0x0以及3.0x1,然后两个结果相减,相减结果与0.5相加(用栈处理)
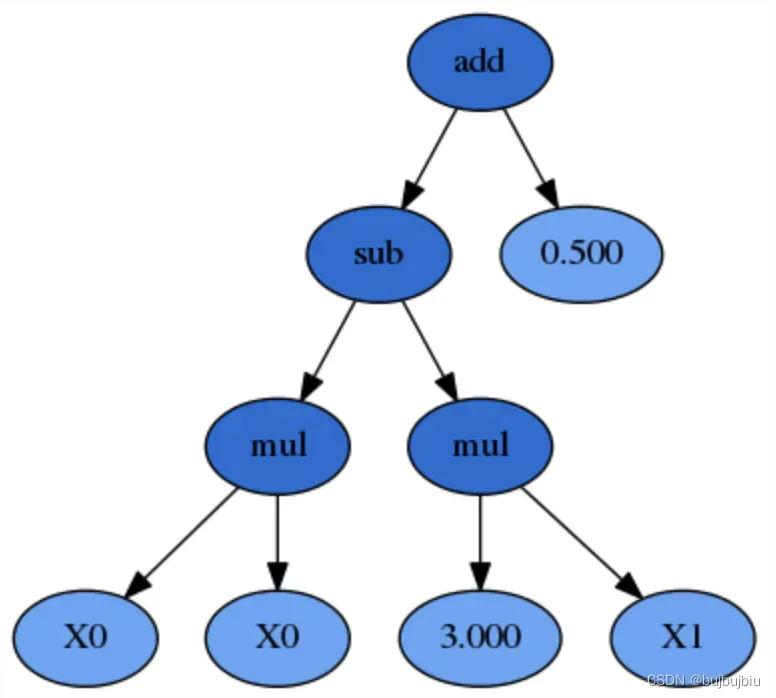
对于 GP,子表达式或子树可以替换为任何其他计算结果为数字的有效表达式,包括常量。 该子表达式,以及任何更大的子表达式,例如减法函数下面的所有内容,都在前序表达式中彼此相邻,也就是python列表中是相邻的,比如3.0和x1一定相临,这样即便进行交叉和变异也能容易通过编程实现。
每个function有一个属性称为arity,也就是传入参数的数量,大部分function需要传入两个参数,比如sub需要x和y才能执行相减,有一些比如np.abs()取绝对值只需要一个。在明确我们的函数集里所有function所需的arity后,用python列表就很容易能计算前序表达式。
gplearn中可用的函数集由初始化时的参数设置,默认包括addition, subtraction, division 和 multiplication,可以选择的function如下

只需在传入参数function_set选择即可,如果有自定义的function,可以通过functions.make_function()实现,比如自定义一个函数logical
gp = SymbolicTransformer(function_set=['add', 'sub', 'mul', 'div'])
def _logical(x1, x2, x3, x4):
return np.where(x1 > x2, x3, x4)
logical = make_function(function=_logical, name='logical', arity=4)
gp = SymbolicTransformer(function_set=['add', 'sub', 'mul', 'div', logical])
1.1.2 Fitness(适应度)
每个公式都是一段可执行的程序,我们需要确定它的执行结果。 从达尔文进化角度来看,用来评价每个个体的称为适应度,这和机器学习中的score,error,loss类似。在GP中,通过对某些指标的最小化或者最大化选择合适的程序进化。
gplearn中的评价标准通过metric参数设置,对于SymbolicRegressor包括mse,rmse,对于SymbolicTransformer包括pearson,spearman,对于SymbolicClassifier包括log loss等。如果有自定义的适应度可以通过fitness.make_fitness()实现,比如想要使用MAPE (mean absolute percentage error)误差
def _mape(y, y_pred, w):
"""Calculate the mean absolute percentage error."""
diffs = np.abs(np.divide((np.maximum(0.001, y) - np.maximum(0.001, y_pred)),
np.maximum(0.001, y)))
return 100. * np.average(diffs, weights=w)
mape = make_fitness(function=_mape, greater_is_better=False)
est = SymbolicRegressor(metric=mape, verbose=1)
1.1.3 Closure
在函数计算过程中,有一些function是需要保护的,比如division,如果除数刚好为0,就会出现error,因此这些functions需要适当调整保证能输出一个有效值。在gplearn中
有以下被保护的函数:
- division:分母介于-0.001和0.001,就返回1.0
- 平方根返回参数绝对值的平方根
- log 返回参数绝对值的对数,或者对于小于 0.001 的非常小的值,它返回 0.0
- 相反数,如果参数介于 -0.001 和 0.001 之间,则返回 0.0。
如果用的自定义的functions.make_function()一定要保证不会出现无效的操作
1.2 Genetic operators
1.2.1 Initialization(初始化)
运行GP首先需要一群初始化种群,初始化需要考虑以下参数
init_depth:树的深度范围,init_depth包括两个整数代表初始树的深度,树的深度产生的约束效果与初始化方法有关(后面描述),通常来说设置2-6population_size:初始化种群大小(树的多少),如果你的变量,函数集很少,小的种群便可以,如果有很多变量,就需更大的种群数init_method:初始化方法有三种,'grow','full', 和'half and half'。在'grow'方法中,每次可以随机从函数集和终端集中选择结点,这可能会出现比init_depth更小的树,因此终端集只能出现在叶子结点,这种方法生成的树也是非对称的。如果你的数据中有很多变量,那么更大可能会出现初始深度更小的树,相反如果变量少,函数多,那么程序更可能到达最大深度。在'full'方法中,依次从函数集中选择结点,除非遇到最大深度,从终端集中选择一个作为叶子结点,这样生成的树比较拥挤和对称。默认为'half and half'方法,也就是种群中一半通过'grow',,一半通过'full',下面分别为full和grow
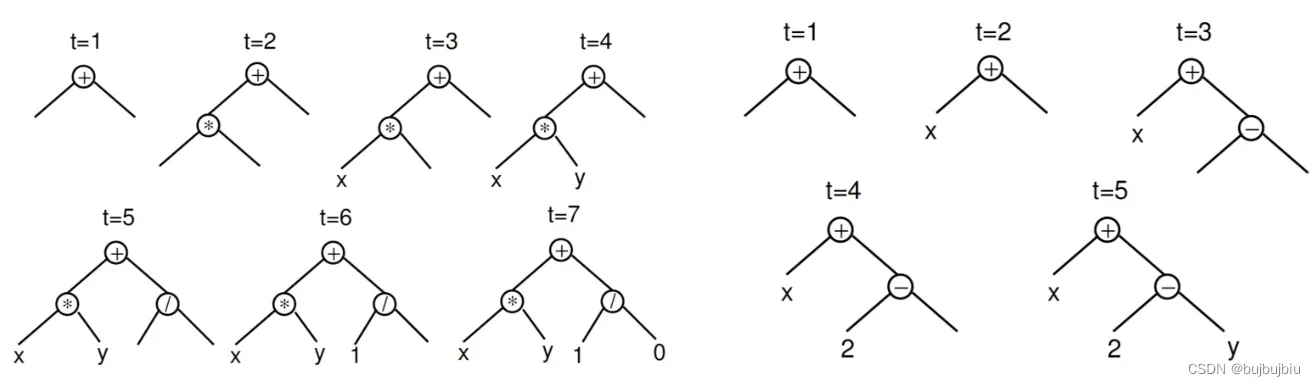
1.2.2 Selection(选择)
在有了一群程序后,我们需要决定哪些能进化到下一代,在gplearn中是通过tournaments的方式,从种群中随机选择一个小子集,彼此竞争,子集的大小由tournament_size参数决定,其中适应度最高的个体会选择进入下一代。tournament_size越大,越容易找到更合适的程序,进化越快收敛到某个解,tournament_size越小,可以保留种群的多样性,但是进化也更耗费时间。使用适应度值找到最合适的个体生存后,这些个体并不是直接进入下一代,而是先进行遗传操作
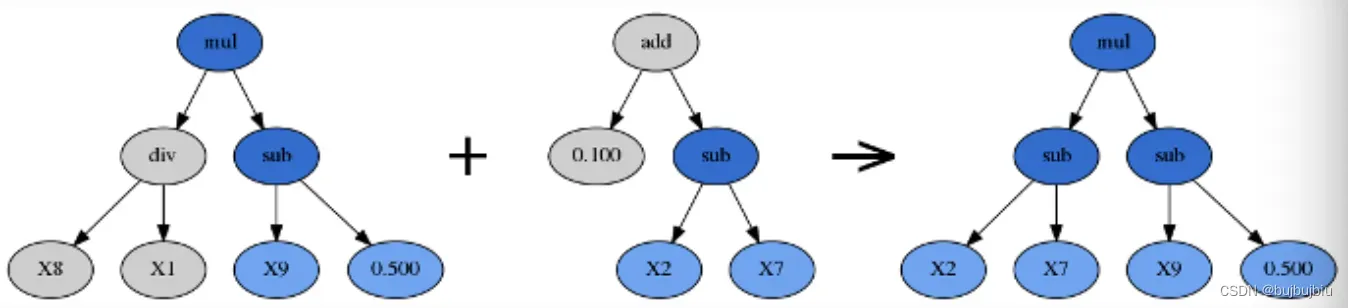
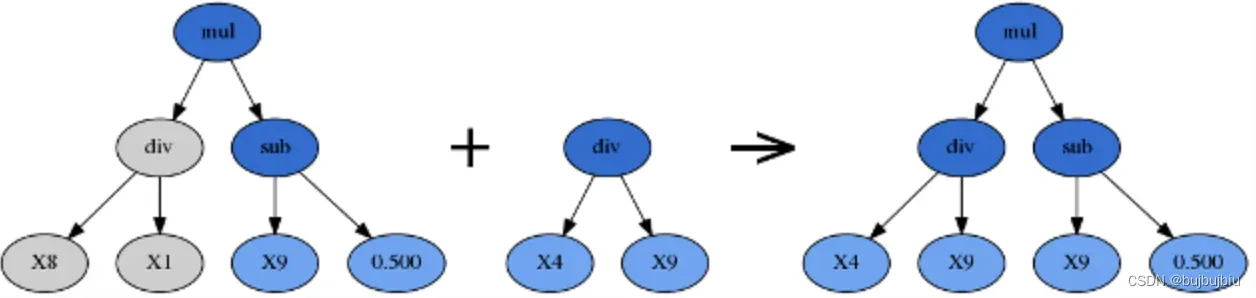
1.2.3 Crossover(交叉)
交叉是为了混合基因,通过参数p_crossover决定。需要执行两次tournaments找到两个赢家,第一个作为父代,第二个作为捐赠者,从父代中随机选择一个子树用捐赠者的随机子树代替
1.2.4 Mutation(变异)
- Subtree Mutation(子树变异)
子树变异是比较激进的变异方法,通过参数p_subtree_mutation决定,首先选择一个tournaments赢家,随机选择其子树被替代,另一个捐赠子树是随机生成的,再插入到原来的树中,由于变异的部分是完全随机的,因此也保留了种群的多样性
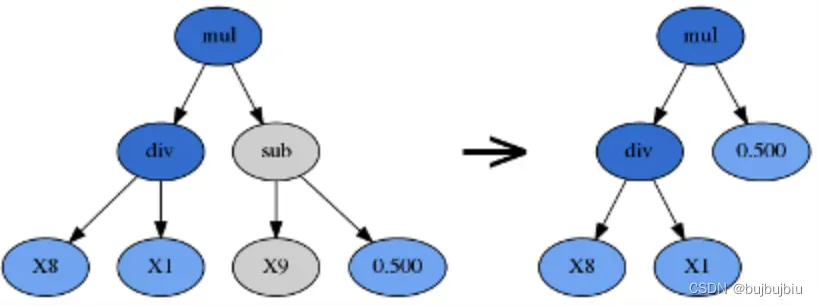
- Hoist Mutation(提升变异)
Hoist Mutation是一种对抗膨胀的变异操作,由p_hoist_mutation 参数控制。这种变异是去除掉tournaments赢家的部分基因。从tournaments赢家中选择一个随机子树。 然后选择该子树的随机子树,并将其“提升”到原始子树的位置以形成下一代。
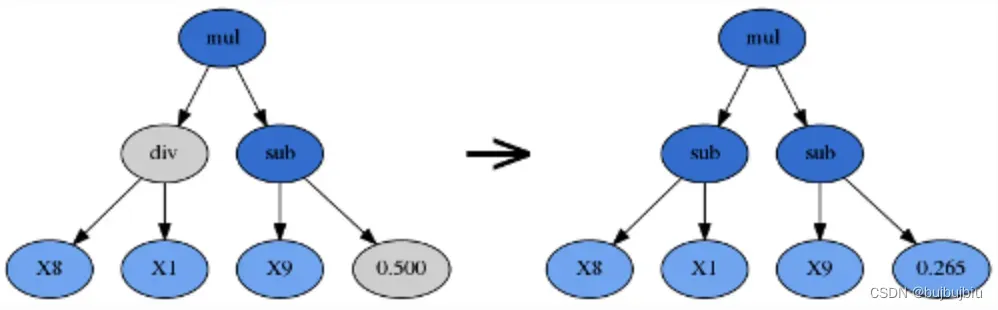
- Point Mutation(点变异)
点变异是GP中比较常用的变异方法,p_point_replace决定了替代的结点数量,和子树变异一样,它会将没有使用的函数和运算符重新引入种群以保持多样性。选择一个tournaments赢家,然后随机替代其中的一些结点,终端结点用终端集代替,函数结点用函数集代替
- Reproduction(重组)
如果上述遗传操作的概率之和小于一,则遗传操作的平衡将落在重组上。 也就是说,锦标赛获胜者被克隆并进入下一代未修改。
1.2.5 Termination(结束)
有两种方式进化过程会终止,第一种是到达最大迭代数,通过参数generations控制,另一种是种群中至少有一个个体适应度超过了stopping_criteria,表明已经找到了一个比较好的解
1.3 Bloat
一个程序的大小主要指:深度和长度。深度是根结点到叶子结点的最远距离,只有一个值的程序深度为0,长度是数学表达式元素的个数,等于总结点数。在GP中,并不是程序越大越好,相反程序越来越大,增加计算时间,但是适应度可能没有任何提升,这种现象称为bloat。
在GP中,选择过程中对于更大但是适应度更差的个体使用penalized fitness作为标准,因此如果两个个体适应度一样,优先选择更小的程序。parsimony_coefficient参数控制了惩罚程度,最近文献中提出的covariant parsimony method方法可以通过设置parsimony_coefficient='auto'实现,这种方法根据适应度值和程序大小关系自动调整惩罚因子,另一种可以通过基因操作实现,比如hoist mutation会去掉程序的一个部分。也可以在你的数据里增加子采样使种群更丰富,参数max_samples控制,默认不使用。
1.4 Symbolic Regressor(case)
假设现在要拟合的一个表达式如下
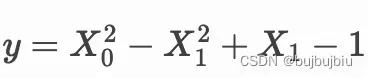
首先生成一些随机合成数据展示图像
import numpy as np
import matplotlib.pyplot as plt
x0 = np.arange(-1, 1, 1/10.)
x1 = np.arange(-1, 1, 1/10.)
x0, x1 = np.meshgrid(x0, x1)
y_truth = x0**2 - x1**2 + x1 - 1
ax = plt.figure().add_subplot(projection='3d')
ax.set_xlim(-1, 1)
ax.set_ylim(-1, 1)
surf = ax.plot_surface(x0, x1, y_truth, rstride=1, cstride=1, color='green', alpha=0.5)
plt.show(
创建训练数据集
from sklearn.utils import check_random_state
rng = check_random_state(0)
x_train = rng.uniform(-1, 1, 100).reshape(50, 2)
y_train = x_train[:, 0]**2 - x_train[:, 1]**2 + x_train[:, 1] - 1
x_test = rng.uniform(-1, 1, 100).reshape(50, 2)
y_test = x_test[:, 0]**2 - x_test[:, 1]**2 + x_test[:, 1] - 1
训练数据
est_gp = SymbolicRegressor(population_size=5000,
generations=20, stopping_criteria=0.01,
p_crossover=0.7, p_subtree_mutation=0.1,
p_hoist_mutation=0.05, p_point_mutation=0.1,
max_samples=0.9, verbose=1,
parsimony_coefficient=0.01, random_state=0)
est_gp.fit(x_train, y_train)
| Population Average | Best Individual |
---- ------------------------- ------------------------------------------ ----------
Gen Length Fitness Length Fitness OOB Fitness Time Left
0 38.13 458.578 5 0.320666 0.556764 1.10m
1 9.97 1.70233 5 0.320202 0.624787 36.56s
2 7.72 1.94456 11 0.239537 0.533148 33.74s
3 5.41 0.990157 7 0.235676 0.719906 29.37s
4 4.66 0.894443 11 0.103946 0.103946 27.59s
5 5.41 0.940242 11 0.060802 0.060802 26.33s
6 6.78 1.09536 11 0.000781474 0.000781474 23.92s
输出最优解
print(est_gp._program)
sub(add(-0.999, X1), mul(sub(X1, X0), add(X0, X1)))
2.DEAP
2.1 Creating Types
如何使用creator创建算法中需要的各个模块;初始化使用toolbox
2.1.1 Fitness
Fitness类需要传入参数weights,最小化用负数,最大化用正数,create()函数至少需要传入两个参数,一个是创建的类的名字,一个是基类。个体的适应度值会通过toolbox中的evaluate计算出来,此处创建Fitness类是表明优化方向。
# 单目标最小化
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
# 多目标:最小化,最大化
creator.create("FitnessMulti", base.Fitness, weights=(-1.0, 1.0))
2.1.2 Individual
由于各种算法GA, GP, ES, PSO, DE等个体类型多样,不可能提供所有的个体编码,以下是能用creator创建的个体以及使用toolbox初始化这些个体。主要包括以下个体类型:列表形式的数字,排列组合,树,进化策略,粒子等
- List of Floats
个体是简单的包含浮点数的列表,首先用creator创建Individual类,类型为list,属性为前面定义的适应度
import random
from deap import base
from deap import creator
from deap import tools
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
IND_SIZE=10
toolbox = base.Toolbox()
toolbox.register("attr_float", random.random)
toolbox.register("individual", tools.initRepeat, creator.Individual,
toolbox.attr_float, n=IND_SIZE)
使用register()方法在工具箱中添加了两个别名,attr_float和individual,register()方法需要至少传入两个参数:别名和与其相关的函数功能。attr_float代表random.random函数,也就是随机生成个体的方法,individual创建了initRepeat()快捷方式,通过attr_float方法生成前面定义的个体。
- Permutation
与前面方法类似,只是每个个体是一个排列组合,因此用的indices,从给定序列里随机采样IND_SIZE个数
import random
from deap import base
from deap import creator
from deap import tools
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", list, fitness=creator.FitnessMin)
IND_SIZE=10
toolbox = base.Toolbox()
toolbox.register("indices", random.sample, range(IND_SIZE), IND_SIZE)
toolbox.register("individual", tools.initIterate, creator.Individual,
toolbox.indices)
- Arithmetic Expression
主要用于GP中基于树的个体,个体类型为PrimitiveTree,创建前先确定原始集PrimitiveSet,传入两个参数,一个是集合命名,一个是变量个数,如下原始集中有3个function和一个变量,其表达式生成方式设置为genHalfAndHalf()
import operator
from deap import base
from deap import creator
from deap import gp
from deap import tools
pset = gp.PrimitiveSet("MAIN", arity=1)
pset.addPrimitive(operator.add, 2)
pset.addPrimitive(operator.sub, 2)
pset.addPrimitive(operator.mul, 2)
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", gp.PrimitiveTree, fitness=creator.FitnessMin,
pset=pset)
toolbox = base.Toolbox()
toolbox.register("expr", gp.genHalfAndHalf, pset=pset, min_=1, max_=2)
toolbox.register("individual", tools.initIterate, creator.Individual,
toolbox.expr)
除此还有Evolution Strategy,Particle,A Funky One等个体定义方式
2.1.3 Population
种群方式有以下:包Bag,网格Grid,群Swarm,子种群Demes,Seeding a Population等
- Bag
Bag种群是最常用的类型,没有特定的顺序,通常使用列表来实现。 由于Bag没有特定属性,因此不需要任何特殊类。 直接使用工具箱和 initRepeat() 函数初始化种群。比如遗传算法种群就是各个个体一起存放在列表里。先在工具箱里注册,然后调用toolbox.population()会返回种群,n为种群大小
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.population(n=100)
2.2 Operators and Algorithms
在创建完个体种群后,还需要对这些个体执行基因操作。随机创建一个个体用于后面的示例,个体为列表存储的浮点数,适应度值目前为空,因此还没有评估。
import random
from deap import base
from deap import creator
from deap import tools
IND_SIZE = 5
creator.create("FitnessMin", base.Fitness, weights=(-1.0, -1.0))
creator.create("Individual", list, fitness=creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register("attr_float", random.random)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_float, n=IND_SIZE)
ind1 = toolbox.individual()
print(ind1)
print(ind1.fitness.valid)
[0.6383518264585538, 0.6825024981834429, 0.3265116106141692, 0.9671414417759829, 0.6941481904147978]
False
2.2.1 Evaluation
对解进行评价获得适应度值是算法应用时最需要定制化的模块,也就是自己写,通常来说evaluate模块输入一个个体,输出一个元组,代表该个体的适应度值,每个个体的fitness都有valid属性,代表该个体是否已经被评价。返回元组是因为多目标优化问题需要多个适应度值。
def evaluate(individual):
a = sum(individual)
b = len(individual)
return a, 1.0/b
ind1.fitness.values = evaluate(ind1)
print(ind1.fitness)
print(ind1.fitness.valid)
(3.389497314678003, 0.2)
True
2.2.2 Mutation
在deap.tools里提供了很多变异操作,注意在变异时会改变自身,因此如果要保留原来的个体,先复制再变异,同时删除变异后个体的适应度值,因为发生了改变
mutant = toolbox.clone(ind1)
ind2, = tools.mutGaussian(mutant, mu=0.0, sigma=0.2, indpb=0.2)
del mutant.fitness.values
print(ind2 is mutant)
print(mutant is ind1)
True
False
2.2.3 Crossover
同变异一样,deap.tools里也提供了很多,交叉算子的一般规则是它们只与个体交配,这意味着如果必须保留原始个体或参考其他个体,则必须在与个体交配之前制作独立副本。
child1, child2 = [toolbox.clone(ind) for ind in (ind1, ind2)]
tools.cxBlend(child1, child2, 0.5)
del child1.fitness.values
del child2.fitness.values
2.2.4 Selection
选择操作需要传入两个参数:需要选择的个体列表和选择的数量
ind1 = toolbox.individual()
ind2 = toolbox.individual()
selected = tools.selBest([ind1, ind2], 2)
print(ind1 in selected)
通常在选择之后或变异之前对整个种群进行复制
selected = toolbox.select(population, LAMBDA)
offspring = [toolbox.clone(ind) for ind in selected]
2.2.5 Using the Toolbox
toolbox包含了所有的进化工具,从目标初始化到评估个体,toolbox能够很简单的配置一个算法需要的模块,有两个方法,register() 和 unregister(),分别是添加和移除工具。使用toolbox注册进化工具,通常包括以下内容:mate(), mutate(), evaluate() and select()。将tools中的进化算子直接封装注册到toolbox中。
from deap import base
from deap import tools
toolbox = base.Toolbox()
def evaluateInd(individual):
# Do some computation
return result,
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selTournament, tournsize=3)
toolbox.register("evaluate", evaluateInd)
2.2.6 Algorithms
在algorithms模块中提供了好几种算法,首先为算法组建好toolbox,也就是定义好了个体编码,基因算子,种群等,然后就可以运行算法。通常需要5个传入参数:种群,toolbox,交叉率,变异率,迭代数
from deap import algorithms
algorithms.eaSimple(pop, toolbox, cxpb=0.5, mutpb=0.2, ngen=50)
2.3 Computing Statistics
2.3.1 Single-objective Statistics
tools中的Statistics能用于统计训练数据,Statistics对象首先需要传入一个关键词,作用到数据上,获得数据集,比如统计个体的适应度值,然后通过register方法注册一些方法可以得到数据的统计值,比如均值,方差等。
stats = tools.Statistics(key=lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean)
stats.register("std", numpy.std)
stats.register("min", numpy.min)
stats.register("max", numpy.max)
在添加完Statistics中的工具后,对运行后的种群进行统计,使用compile方法
以前面的toolbox为例,
pop, logbook = algorithms.eaSimple(pop, toolbox, cxpb=0.5, mutpb=0.2, ngen=0, stats=stats, verbose=True)
record = stats.compile(pop)
print(record)
{'avg': 1.0280724547834108, 'std': 0.9585341482492478, 'min': -0.5192935690712837, 'max': 3.2460831125587752}
2.3.2 Multi-objective Statistics
如果是多目标,在注册时可选择维度
stats = tools.Statistics(key=lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean, axis=0)
stats.register("std", numpy.std, axis=0)
stats.register("min", numpy.min, axis=0)
stats.register("max", numpy.max, axis=0)
>>> print(record)
{'std': array([ 4.96]), 'max': array([ 63.]), 'avg': array([ 50.2]),
'min': array([ 39.])}
2.3.3 Multiple Statistics
也可以统计不同的属性,使用tools.MultiStatistics方法将每个属性数据结合一起
stats_fit = tools.Statistics(key=lambda ind: ind.fitness.values)
stats_size = tools.Statistics(key=len)
mstats = tools.MultiStatistics(fitness=stats_fit, size=stats_size)
mstats.register("avg", numpy.mean)
mstats.register("std", numpy.std)
mstats.register("min", numpy.min)
mstats.register("max", numpy.max)
record = mstats.compile(pop)
>>> print(record)
{'fitness': {'std': 1.64, 'max': 6.86, 'avg': 1.71, 'min': 0.166},
'size': {'std': 1.89, 'max': 7, 'avg': 4.54, 'min': 3}}
2.3.4 Logging Data
产生的数据也可以保存下来,使用tools中的Logbook实现
logbook = tools.Logbook()
logbook.record(gen=0, evals=30, **record)
logbook.header = "gen", "avg", "spam"
>>> print(logbook)
gen avg spam
0 [ 50.2]
2.4 Artificial Ant Problem(case)
完整代码见ant.py,使用GP求解Artificial Ant Problem,首先定义原始集,其中有一些自定义的function
def progn(*args):
for arg in args:
arg()
def prog2(out1, out2):
return partial(progn, out1, out2)
def prog3(out1, out2, out3):
return partial(progn, out1, out2, out3)
def if_then_else(condition, out1, out2):
out1() if condition() else out2()
pset = gp.PrimitiveSet('Main', 0)
pset.addPrimitive(ant.if_food_ahead, 2)
pset.addPrimitive(prog2, 2)
pset.addPrimitive(prog3, 3)
pset.addTerminal(ant.move_forward)
pset.addTerminal(ant.turn_left)
pset.addTerminal(ant.turn_right)
构建toolbox
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", gp.PrimitiveTree, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register("expr_init", gp.genFull, pset=pset, min_=1, max_=2)
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.expr_init)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evalArtificialAnt)
toolbox.register("select", tools.selTournament, tournsize=7)
toolbox.register("mate", gp.cxOnePoint)
toolbox.register("expr_mut", gp.genFull, min_=0, max_=2)
toolbox.register("mutate", gp.mutUniform, expr=toolbox.expr_mut, pset=pset)
其中evaluate部分需要自定义,定义一个仿真环境,用于求解每个解的适应度值,定义evalArtificialAnt函数
class AntSimulator(object):
def if_food_ahead(self, out1, out2):
return partial(if_then_else, self.sense_food, out1, out2)
def run(self,...)
.........
def evalArtificialAnt(individual):
# Transform the tree expression to functional Python code
routine = gp.compile(individual, pset)
# Run the generated routine
ant.run(routine)
return ant.eaten,
主循环
def main():
random.seed(69)
with open("Other/ant/santafe_trail.txt") as trail_file:
ant.parse_matrix(trail_file)
pop = toolbox.population(n=300)
hof = tools.HallOfFame(1)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean)
stats.register("std", numpy.std)
stats.register("min", numpy.min)
stats.register("max", numpy.max)
algorithms.eaSimple(pop, toolbox, 0.5, 0.2, 5, stats, halloffame=hof)
return pop, hof, stats
if __name__ == "__main__":
main()
gen nevals avg std min max
0 300 1.71667 3.00273 0 14
1 178 5.08667 4.65107 0 31
2 196 7.66667 6.08568 0 31
3 185 9.7 8.11809 0 36
4 164 14.5833 11.2376 0 44
5 172 18.3233 14.0275 0 44
文章出处登录后可见!