本篇为《基于Python的微信聊天记录分析》系列的第三篇,主要讲解在Python环境下对聊天记录进行进一步的可视化,并对聊天内容进行初步挖掘,涉及聊天记录可视化方法、主题模型构建等内容。希望和大家多多交流,共同进步!
一. 聊天记录可视化
在上一篇中,我们将聊天记录统计分析的结果进行了初步可视化,包括按日期统计聊天频次、按每天不同时段统计聊天频次、高频词汇统计战士等内容,总体来说,可视化的是一些数学统计结果。在本章中,我将深入到聊天记录内容中,在文本级别对聊天记录做进一步的可视化,比如词云、聊天热力图等,主要内容如下:
1. 词云
(1)Wordcloud介绍与安装
在Python环境中,第三库——wordcloud可以便捷地实现文本中关键字的可视化展现,通过词云分析,可以直观地突出文本中的主旨,在本篇内容中,即可以展现双方聊天的主要内容和口头禅,下面简单介绍一下wordcloud库:
- Wordcloud(用于词云图生成):wordcloud是一个用于生成词云图的Python库,用于展示文本数据中出现频率较高的词汇,通过将文本中的词汇按照其出现的频率进行大小排序,然后将这些词汇以特定的形状、颜色等元素组合成一个图形,从而直观地展示文本的主题和关键词。该库在文本分析中较为用。
wordcloud在Anaconda Prompt中的安装命令如下:
pip install wordcloud安装好之后import一下,如果不报错就是安装成功啦,安好之后首先我们要对之前的数据进行简单的处理,便于wordcloud库直接加载数据生成词云。
(2)基于wordcloud的词云展示
回顾一下,上一篇博客(文末有引用~)中分词之后的数据为“result_word_new”,本篇对该数据继续进行处理。
- 第一步,去掉聊天记录中的“\n”换行符无效数据
word_data = result_word_new.drop(index=result_word_new[(result_word_new.labels == '\n')].index.tolist())大家需要检查一下自己的聊天记录经过jieba分词之后,里面是否有“\n”,如果有的话需要过滤掉,否则会报错:ValueError: anchor not supported for multiline text
- 第二步,将数据转换为dict格式
word_dict = dict(zip(word_data['labels'],word_data['counts'])) # labels和counts按自己设置的列名- 第三步,停用词过滤,将自己不想展示的词汇滤除,比如各种单个汉字、语气词、符号之类,这里建议可以使用网上开源的停用词集合:中文常用停用词表,注意:如果word_dict是字典,那么无法使用generate,需要使用generate_from_frequencies或者fit_words,此时配置参数中填写stopwords无效,因此我们将数据中的停用词提前过滤掉。
- 第四步,设置词云相关参数,比如字体、长、宽、背景色等,这里我用的阿里巴巴普惠体2.0字体,别的也可以啦。
- 第五步,生成词云,wc.fit_words()或wc.generate_from_frequencies()都可以。
# 加载下载好的停用词表
with open("D:\\Projects\\chatmsg-analysis\\哈工大停用词表.txt", "r", encoding="utf-8") as fp:
stopwords = [s.rstrip() for s in fp.readlines()]
# 将数据中的停用词过滤掉
word_dict_result = []
for i in dict.keys(word_dict):
if i not in stopwords:
word_dict_result[i] = word_dict[i]
# 加载字体
font = "D:\\Projects\\chatmsg-analysis\\AlibabaPuHuiTi-2-45-Light.ttf"
# wordcloud配置参数
wc = wordcloud.WordCloud(
font_path=font,
width=1000,
height=1000,
background_color="skyblue",
max_words=50) # 词数,可改
# 生成词云
wc.fit_words(word_dict_result)
# 或
wc.generate_from_frequencies(word_dict_result)最后我们可以用如下代码将词云显示
plt.imshow(wc)
plt.axis("off")
plt.show()结果如下:

另外,wordcloud还支持更换背景,这样有更多的可玩性,比如我们自己做一张爱心图片作为mask~若想用图片作为背景,需要先安装imageio(一个用于读/写图像的库):
pip install imageio词云的配置参数需要进行微调:
from imageio.v2 import imread
# 加载一张爱心图片
background = imread('D:\\Projects\\chatmsg-analysis\\heart.png')
# 配置参数时加上mask项
wc = wordcloud.WordCloud(
font_path=font,
width=1000,
height=1000,
background_color="skyblue",
max_words=50,
mask = background)爱心图片示例和词云结果如下:


到此词云就生成完毕啦,wordcloud的配置参数中还有很多有趣的选项,大家可以多多探索。
2. 聊天热力图
(1)热力图介绍
在这节开始前,先普及一下热力图(Heatmap),实际上就是通过颜色的深浅来反应数据的统计结果,比如:在某一色系下,一般较大的值由较深的颜色表示,较小的值由较浅的颜色表示。
(2)基于matplotlib实现聊天热力图展示
本节主要基于上一篇博客(文末有引用~)中按天统计聊天频次的结果“result_total_day”,做一些简单的处理,然后通过matplotlib实现聊天热力图的展示。整体代码如下:
import matplotlib.pyplot as plt
# 对result_total_day数据进行处理
# 变量初始化
msg_dict = dict()
week_array = []
week_count = 1
for index, row in result_total_day.iterrows():
# 将每天的聊天记录数量写入每周统计数组中
week_array = np.append(week_array, int(row["count"]))
# 因为一周有七天,所以我们这边七天将结果写入一次,重置一下数组(week_array),更新周数(week_count )
if len(week_array) == 7:
msg_dict[week_count] = week_array
week_count += 1
week_array = []
# 获取我们后续制热力图需要的纵轴坐标(周数)和热力图中的值(聊天记录数量)
y_labels = list(msg_dict.keys())
values = list(msg_dict.values())
# 自定义横轴坐标(周一到周日,顺序大家根据数据修改一下)
x_labels = ["周一", "周二", "周三", "周四", "周五", "周六", "周日"]
# 绘图
fig, axe = plt.subplots(figsize=(15, 15)) # size可以调整
axe.set_xticks(np.arange(len(x_labels)))
axe.set_yticks(np.arange(len(y_labels)))
axe.set_xticklabels(x_labels)
axe.set_yticklabels(y_labels)
im = axe.imshow(values, cmap=plt.cm.Reds) # 颜色可更改,我这里是红色
# 是否开启参考刻度,如不需开启,注释下面这行代码
axe.figure.colorbar(im, ax=axe)
plt.show()聊天热力图结果如下:

到此热力图就做完啦,根据热力图中的深浅结果结果,可以直观看出每周/每天的聊天频次~
二. 聊天主题模型构建
本章的目的是通过构建LDA主题模型,推断聊天记录中隐含的主题分布,包括LDA主题模型介绍、基于Python的主题模型构建等内容。
1. LDA主题模型
LDA主题模型概念如下:
LDA主题模型:LDA为Latent Dirichlet Allocation(隐含狄利克雷分布)的缩写,是一种概率主题模型,由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,用来推测文档的主题分布。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。
2. Gensim介绍与安装
在Python环境中,已经有可以直接拿来用的LDA主题模型第三方包,比如我们这次使用的Gensim:
Gensim:Gensim是一款开源的第三方Python库,在做NLP相关项目中这个库的使用频率是比较高的,它用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。一方面,它包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型,另一方面,它支持流式训练,并提供了一些常用操作的API接口。
gensim在Anaconda Prompt中的安装命令如下:
pip install gensimLDA主题模型相关可视化库pyLDAvis,有助于分析和创建由LDA创建的簇的高度交互式可视化,并且友好的是它有着gensim的数据接口API,更利于可视化分析,pyLDAvis的安装命令如下:
pip install pyldavis同样, 安装好之后import一下,不报错就ok。
3. 基于Gensim的LDA主题模型构建
本节主要基于上一篇博客(文末有引用~)中jieba分词之后的结果“msg_word_total”,做预处理和向量化,然后通过Gensim库中的LdaModel函数进行训练,最后获取主题词的分布并展示。
(1)预处理
预处理环节主要将“msg_word_total”中的“word”字段(分词结果)由dataframe转换为list格式,便于后续gensim加载处理,代码如下:
# 加载gensim库
from gensim.models import LdaModel
from gensim.corpora import Dictionary
# 新建list空间
data_cut = []
for index, row in msg_word_total.iterrows():
data_cut.append(row["word"]) # 将word字段的值写入list里如果觉得数据质量不高,还需要做进一步清洗,比如用正则表达式将文本中数字、符号过滤掉,或加载第一章中的停用词表,将停用词过滤掉,这部分不细讲了。
(2)文本向量化
LDA采用了词袋模型(BOW ——Bag of words),所以我们将每一条聊天记录分词的结果转化为词袋向量,这里我把一些频率过高的词过滤掉了(主要为了防止频率过高的语气词干扰训练结果)。代码如下:
data_cut_dict = Dictionary(data_cut)
data_cut_dict.filter_n_most_frequent(300) # 300次以上的过滤
corpus = [data_cut_dict.doc2bow(text) for text in data_cut](3)LDA主题模型训练
将向量化之后的文本加载到LDA模型中,设定好主题的个数(聚类方法,需要指定主题的个数),这里我随机设置了20个,大家可以根据数据情况任意修改,运行下方代码开始训练:
model = LdaModel(corpus, id2word=data_cut_dict, iterations=500, num_topics=8, alpha='auto')(4)结果可视化
最后我们要将训练好的model可视化,直接用上文提到的pyLDAvis就可以,代码如下:
import pyLDAvis.gensim
result_vis = pyLDAvis.gensim.prepare(model, corpus, data_cut_dict)
pyLDAvis.show(result_vis)但一开始用 pyLDAvis可视化时,遇到了以下错误:

此时只需要点击报错的_display.py,将下图中226行local=True改为local=False就可以啦!
![]()
可视化结果如下:
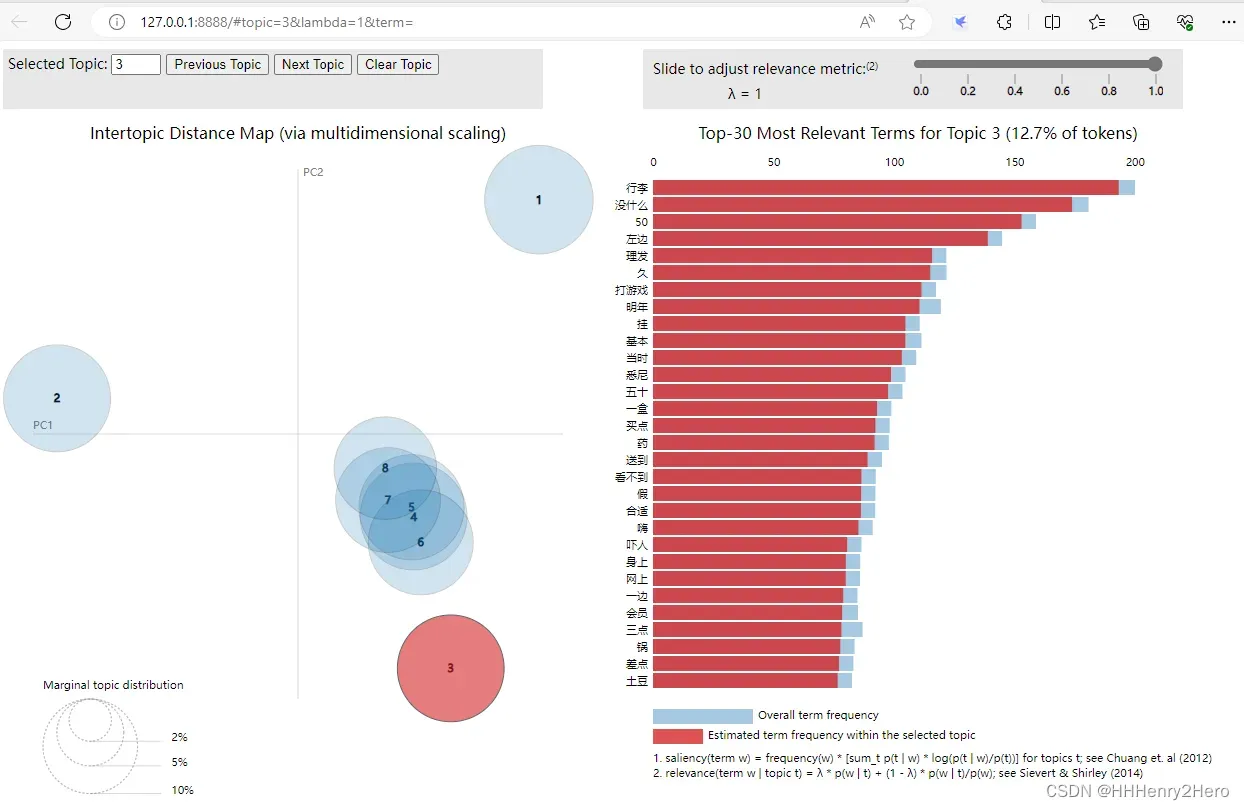
三. 学习后记
本篇我基于Python环境开展聊天记录可视化和主题模型构建的学习和研究,在第一章中,利用wordcloud构建词云,基于matplotlib生成聊天热力图;在第二章中,利用gensim构建LDA主题模型聚类生成聊天记录主题,并利用pyLDAvis生成可视化结果。学习过程中的部分代码还有优化空间,望大家包容、见谅!在后续学习中,打算做进一步的文本挖掘。
与诸君共勉~
如何获取聊天记录数据可参考:
基于Python的微信聊天记录分析——数据获取
如何对聊天数据进行数据处理和分析可参考:
基于Python的微信聊天记录分析——数据处理与分析
版权声明:本文为博主作者:HHHenry2Hero原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Henryli1202/article/details/135853665