视频链接:https://www.bilibili.com/video/BV1J3411C7zd?vd_source=a0d4f7000e77468aec70dc618794d26f
代码:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
FCN是2015年提出的首个端对端的针对像素级预测的全卷积网络。
如今的pytorch实现的FCN都是基于ResNet-50的backbone,不是论文中的VGG16,且使用的是空洞卷积(也叫膨胀卷积)
pytorch官方实现的FCN网络结构图
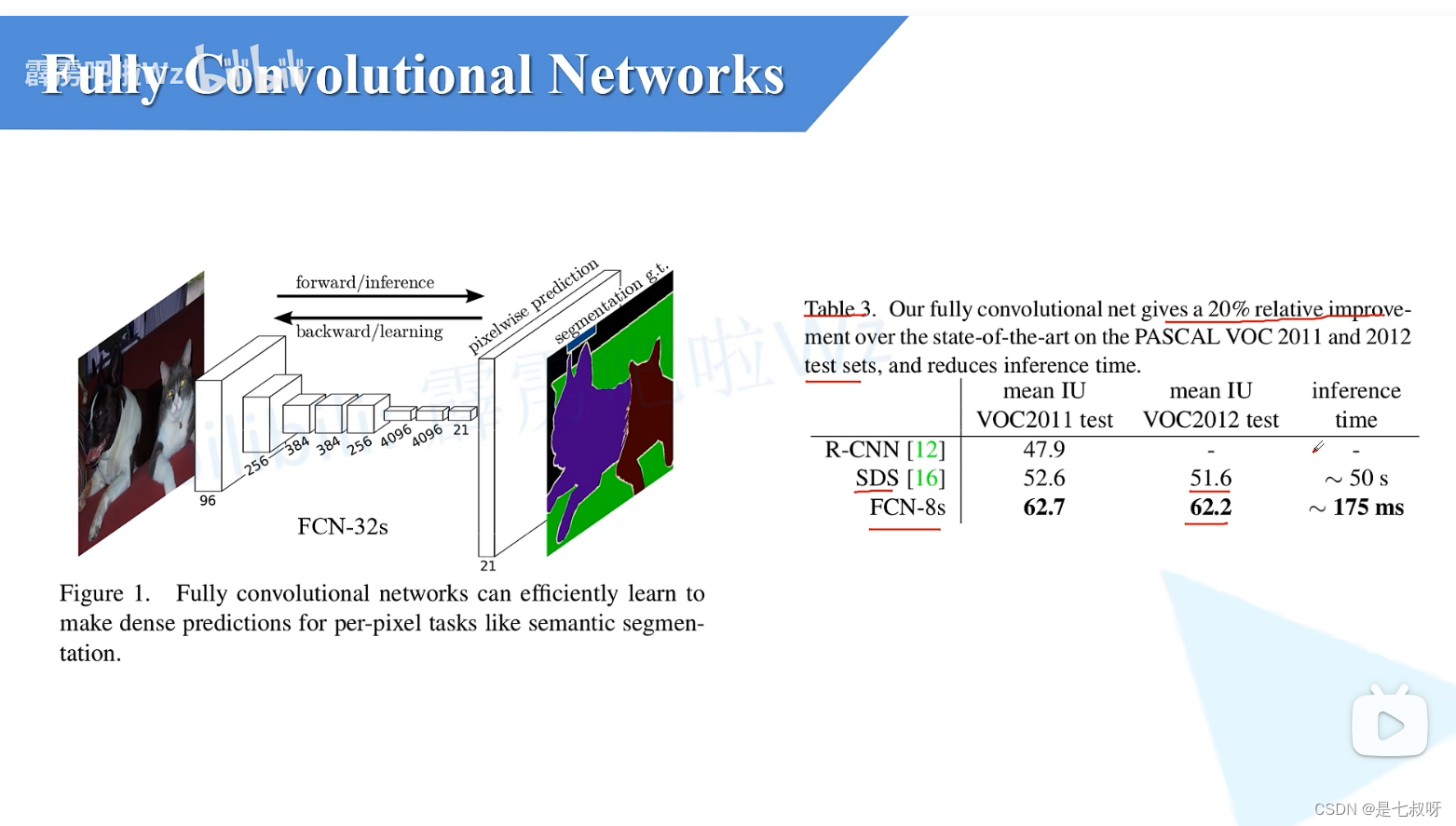
一、相比以前网络的巨大提升:
二、传统使用池化层最后得到的其实是一个长度为1000的向量:
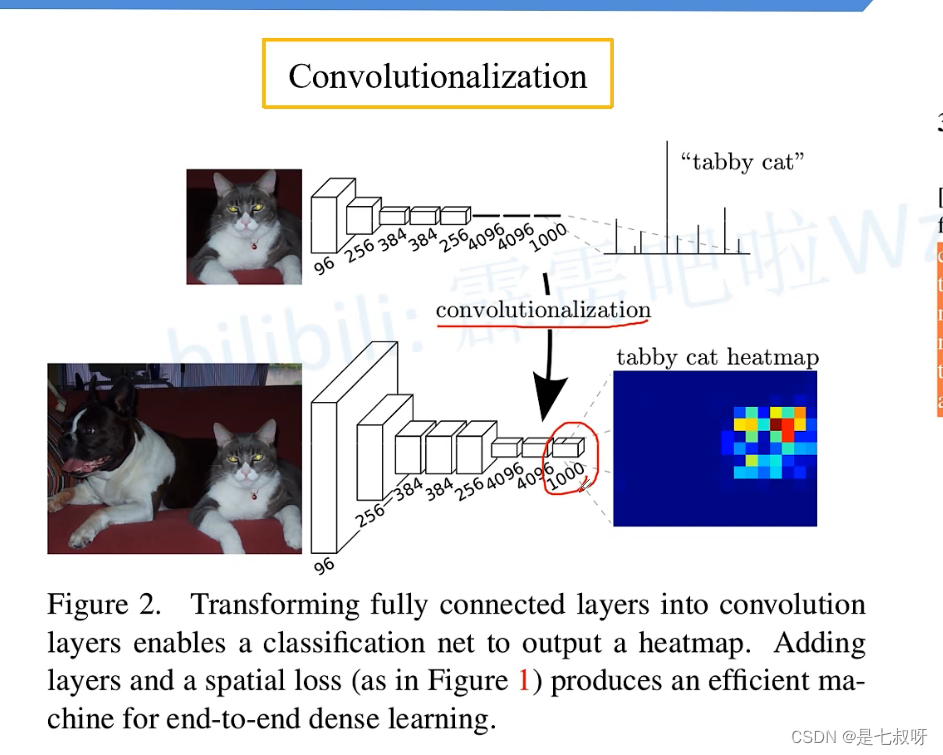
而换为卷积层之后,最后得到的是1000通道的2D图像,可以可视化为heat map图。
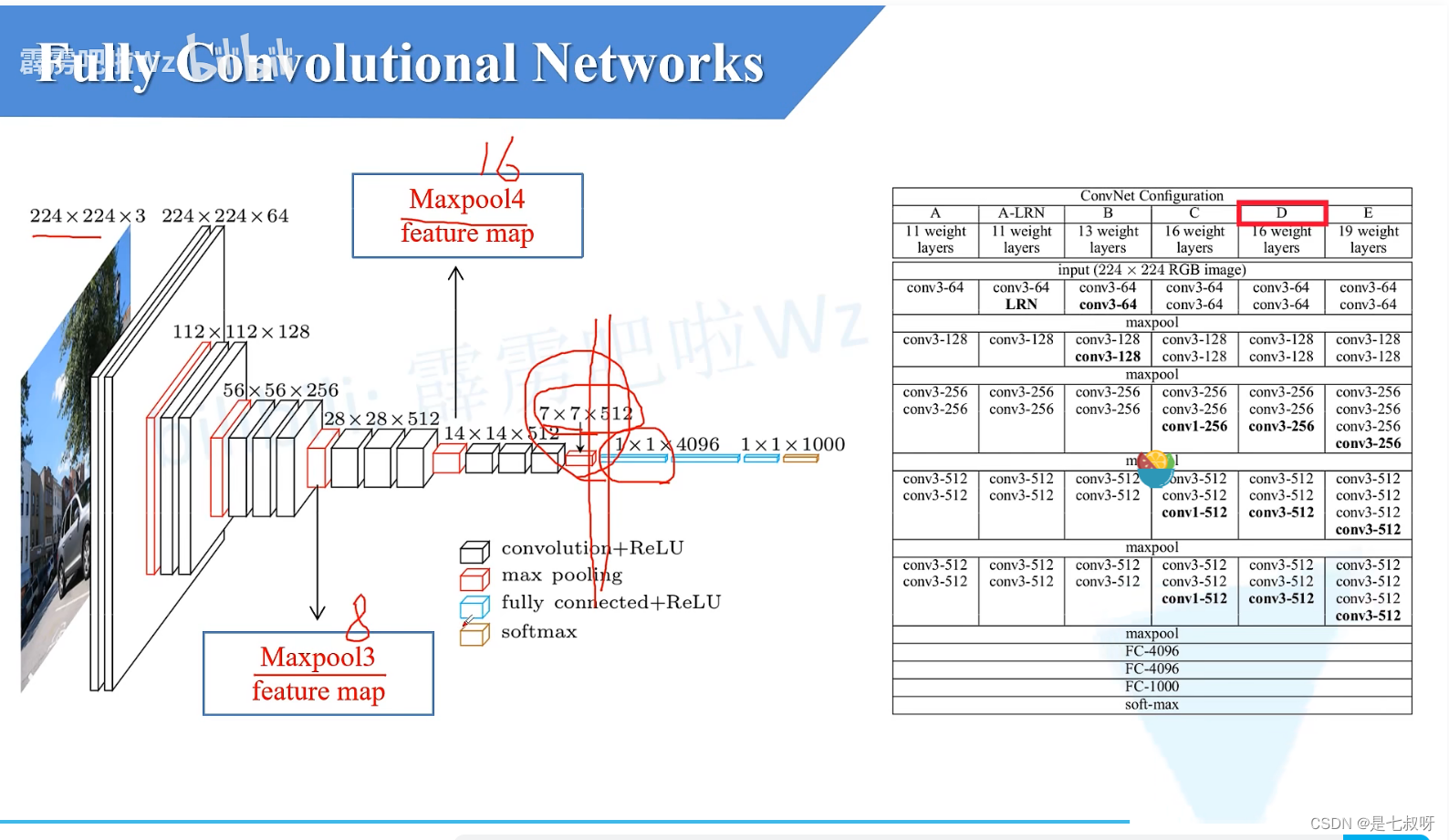
三、回顾VGG16
一般说的vgg16是D:
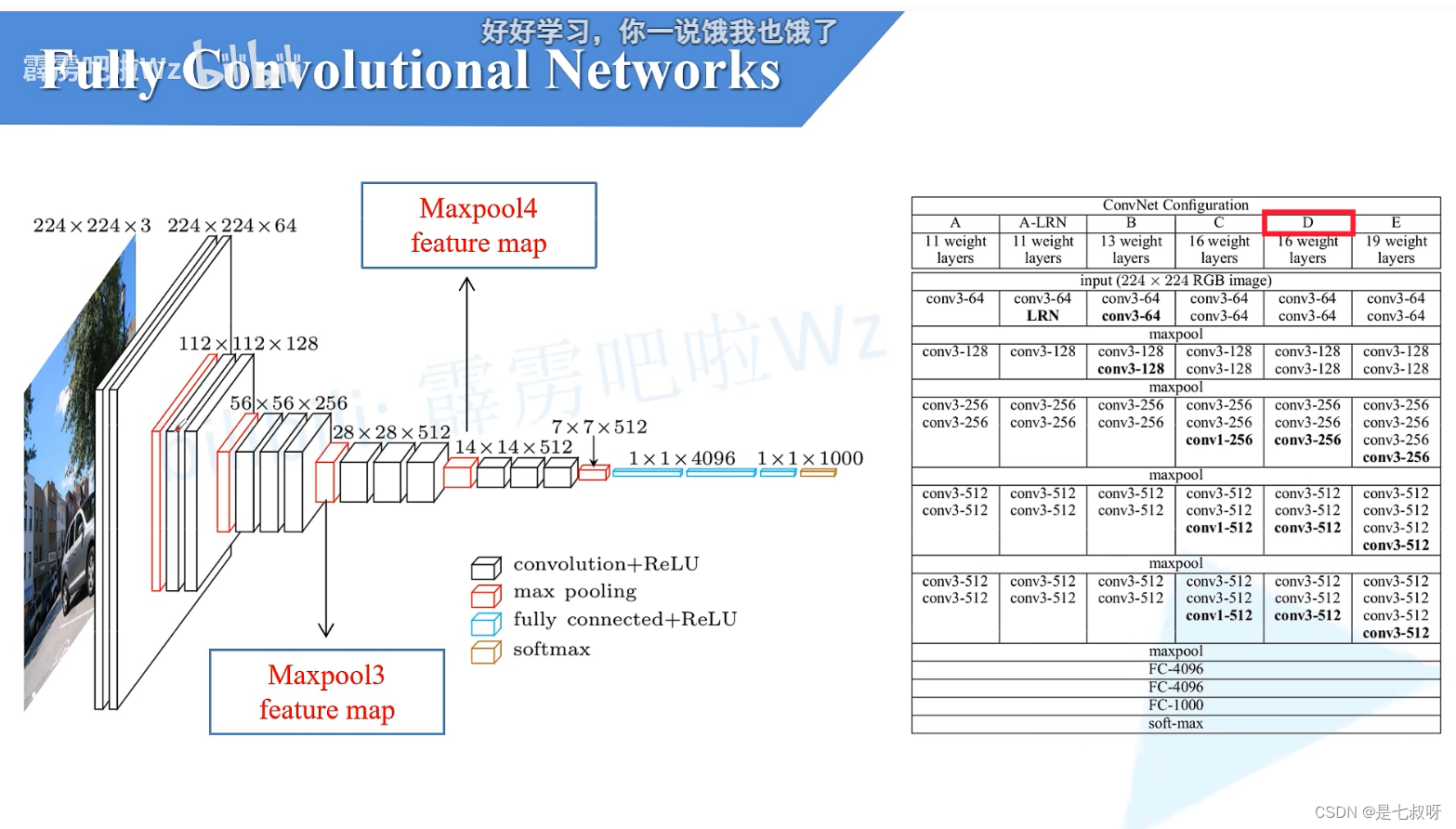
全连接操作前后:77512(通道)
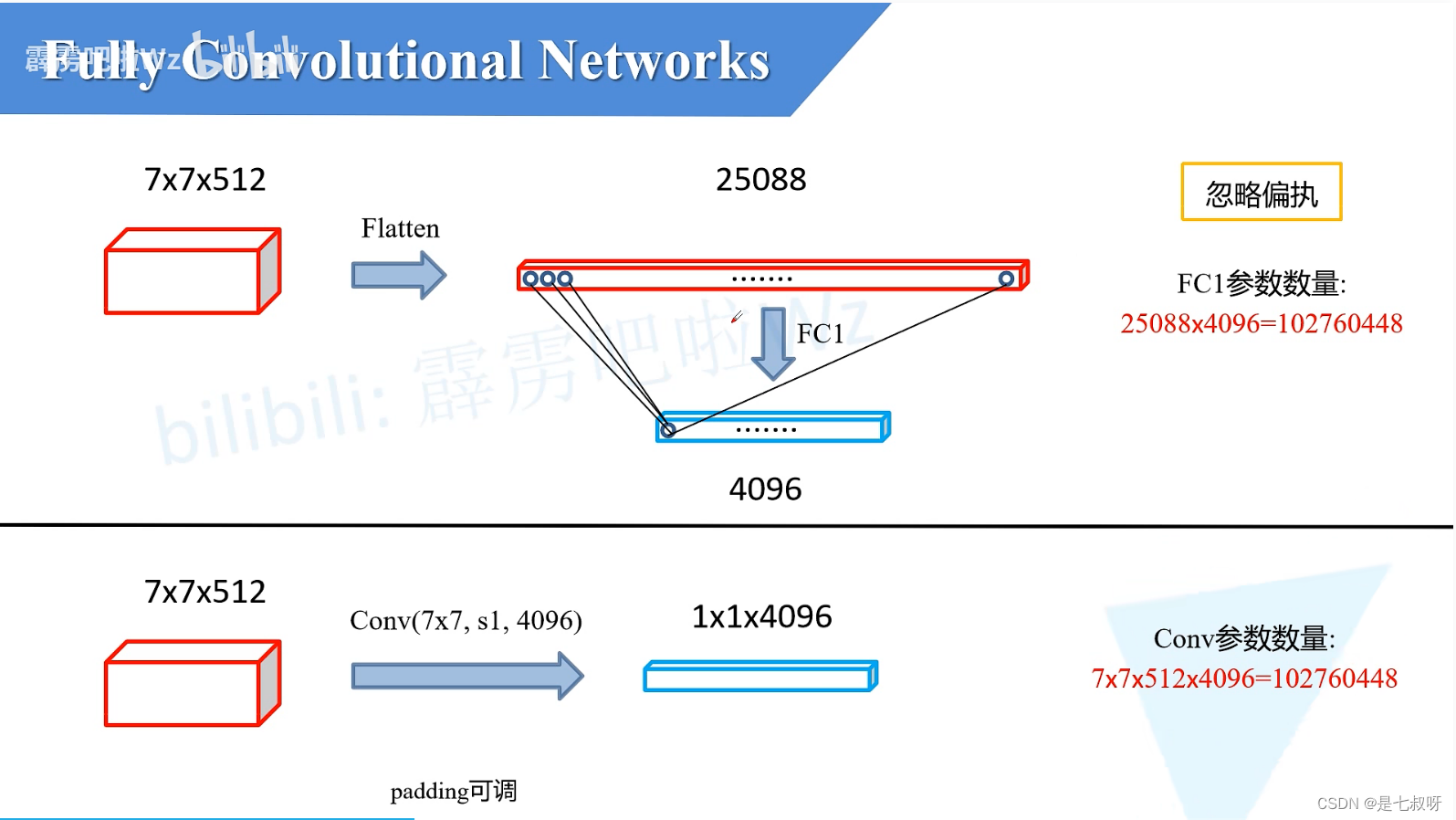
全连接FC1计算:计算对应某一个结点的输出,将该节点与上一层某一个结点的权重与输入对应节点数值相乘,再求和
FC1参数:25088*4096=102760448
下层使用7*7的卷积核、stride=1,4096个卷积核的一个卷积层
Conv参数:77512*4096=102760448
,一共4096个卷积核,FC也是4096个节点。
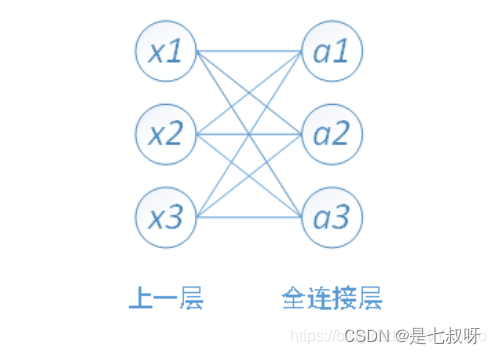
PS:全连接层
全连接层的输入是一维数组,多维数组需先进行Flatten进行一维化处理,然后连接全连接层。全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。全连接图结构如下:
全连接层参数计算
权值参数=输入一维数组大小*全连接层输出结点数
偏置参数b=全连接层输出结点数
eg:
输入有[5044]个神经元结点,输出有500个结点,则一共需要5044*500=400000个权值参数W和500个偏置参数b
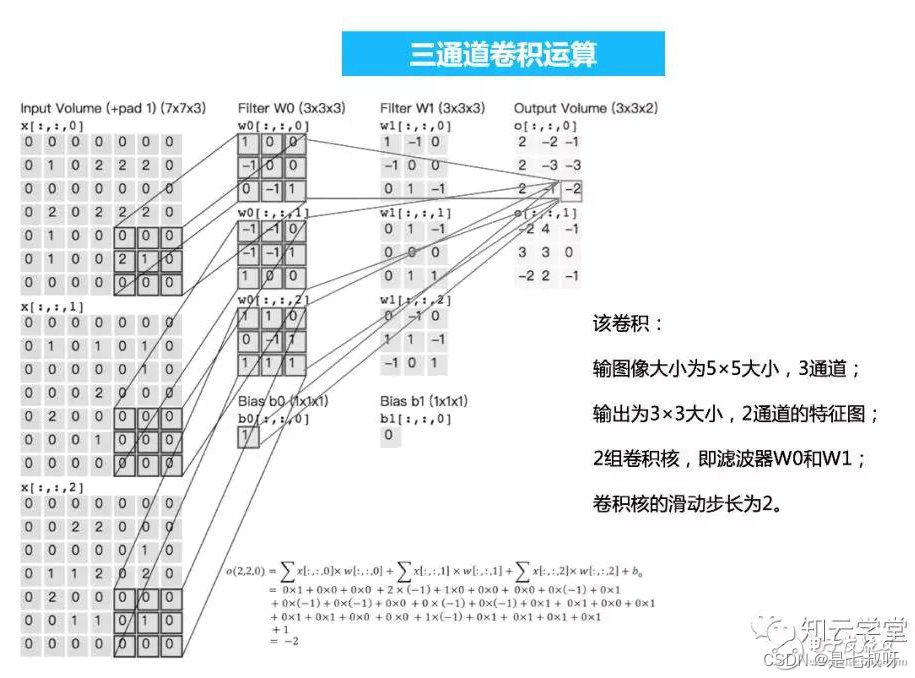
卷积和全连接层
卷积跟全连接都是一个点乘的操作,区别在于卷积是作用在一个局部的区域,而全连接是对于整个输入而言,那么只要把卷积作用的区域扩大为整个输入,那就变成全连接了,我就不给出形式化定义了。所以我们只需要把卷积核变成跟输入的一个map的大小一样就可以了,这样的话就相当于使得卷积跟全连接层的参数一样多。
eg:输入是224x224x3 的图像,假设经过变换之后最后一层是[7x7x512]的,那么传统的方法应该将其展平成为一个7x7x512长度的一层,然后做全连接层,假设全连接层为4096×1000层的(假设有1000个分类结果)。 那么用1×1卷积核怎么做呢,因为1×1卷积核相当于在不同channel之间做线性变换,所以:
先选择7×7的卷积核,输出层特征层数为4096层,这样得到一个[1×1×4096]层的
然后再选择用1×1卷积核,输出层数为1000层,这样得到一个[1×1×1000]层这样就搞定了。
四、FCN-32s、16s、8s的区别

上采样倍率为32的模型对应的就是FCN-32s,16s、8s同理。
FCN-32s
FCN原论文中backbone的第一个卷积层padding=100,为了防止图片过小(例如192192)后面的卷积层会报错。
如果图片小于3232的话在卷积过程就会报错。
但是没必要设置,只要输入图片大小大于32*32,我们就可以将padding设置为3。
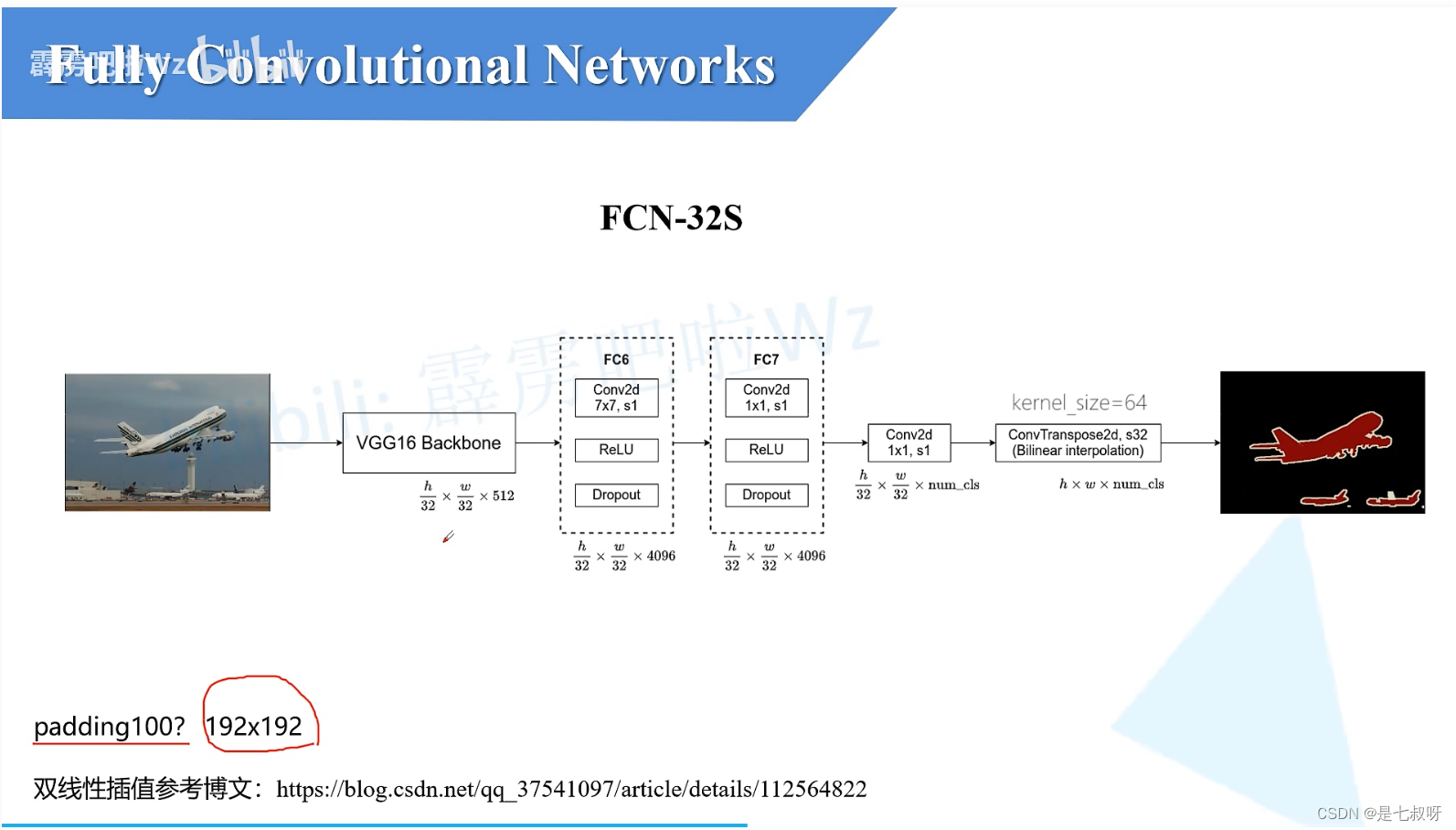
对于FCN-32s:
-
vgg16 backbone输出的特征图大小就为h/32,w/32,512。高度宽度变为原图的1/32。
-
之后经过FC6层:由于我们将FC6卷积层的padding设置为3、卷积核大小7*7,通过FC6之后将不会改变特征图的高和宽;且我们使用了4096个卷积核,所以这里就得到了4096个2D特征图。 -
经过FC7:使用了1*1大小的卷积核,步距也为1,所以输出特征图shape也不会发生变化。 -
之后经过卷积核大小为1*1的卷积层:它的卷积核的个数和我们的分类类别数一样(包含背景,对于voc为20类+1背景),将特征图通道数变为num_cls。 -
之后通过一个转置卷积:这里的s32我们会将特征图上采样32倍【原论文中使用的是双线性插值】,得到特征图大小变为h,w,num_cls。
之后特征图经过一个softmax处理就能得到针对每一个pixel的预测类别。
前面的backbone使用的是vgg16的预训练权重,整个结构十分简单,但是效果还是非常不错的。
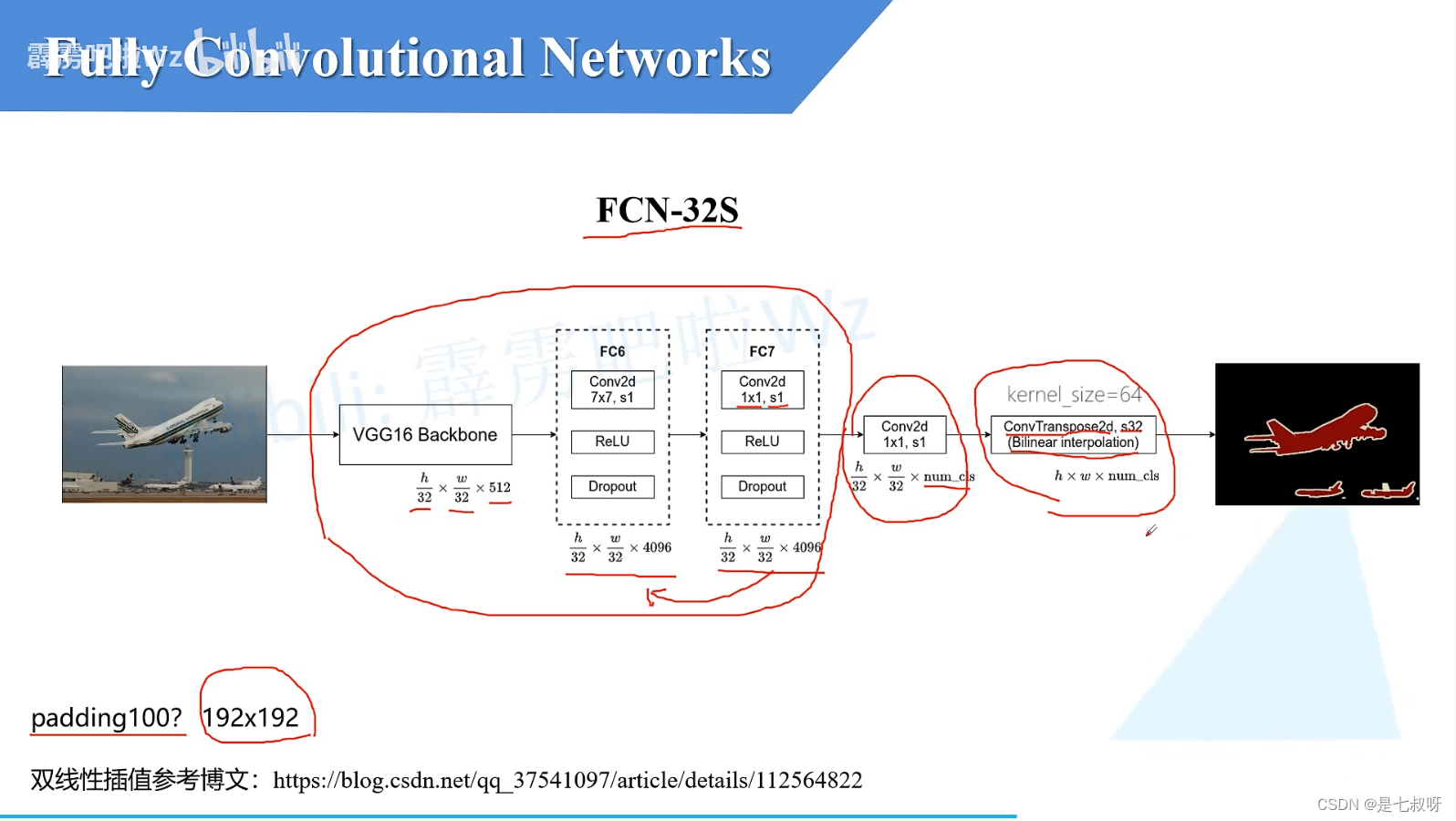
其实这里的转置卷积在原论文中其实是将参数给冻结住了,冻结住意味着其实它就是一个简单的双线性卷积了。
-
所以这里其实可以不使用转置卷积,可以直接使用深度学习框架提供给我们的双线性插值方法。
-
为什么会冻结呢?作者说冻结不冻结作者觉得结果好像没有什么差别,而且冻结参数会少一些。up主觉得冻结不冻节效果一般的原因是这里的上采样倍率太大了,有点强人所难的感觉。有兴趣的可以看一下u-net中的上采样率是多少。
FCN-16s
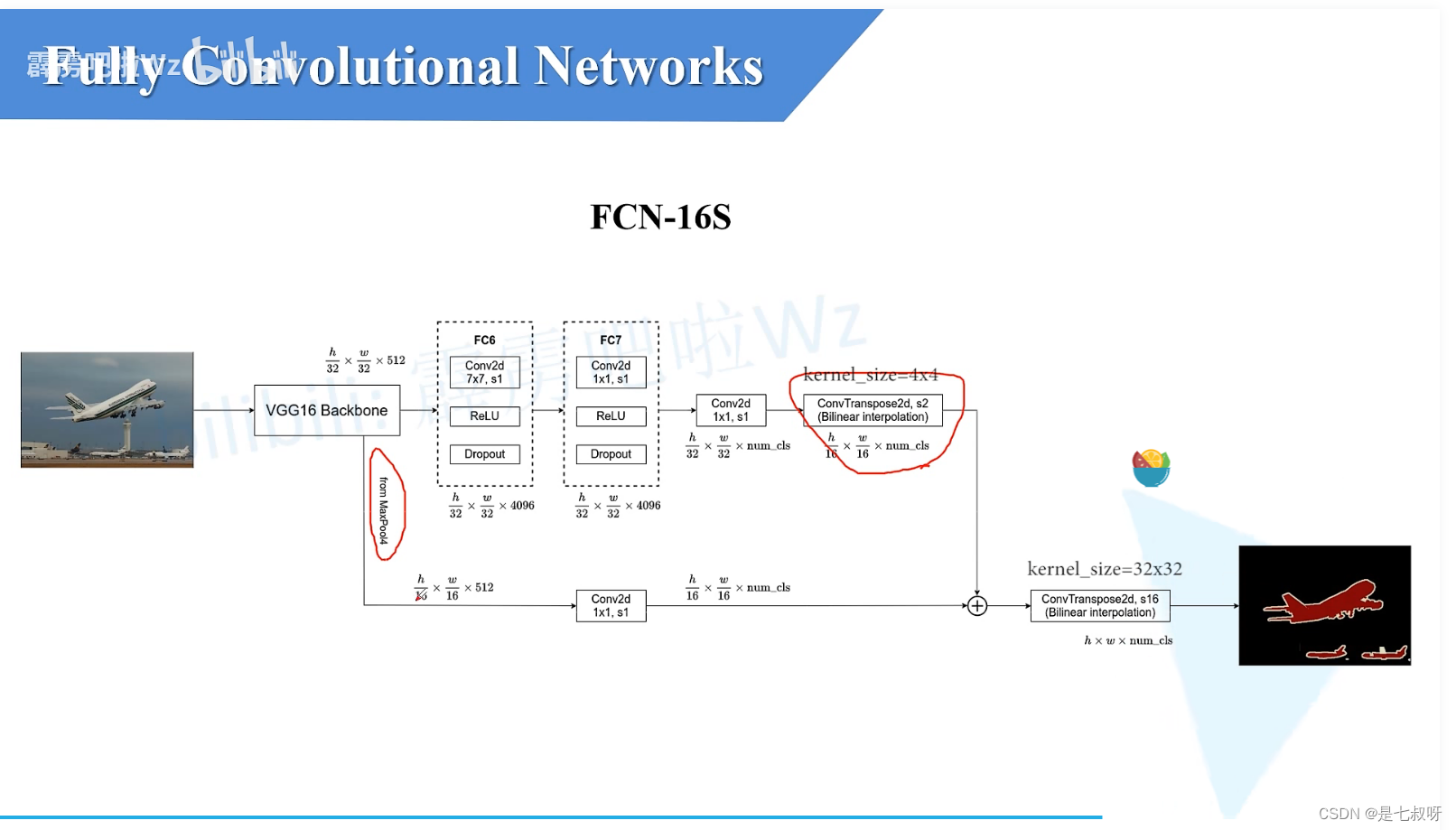
FC6、FC7、Conv2d核32s的一样。
不同点:
- 转置卷积上采样率变为了2倍,之后高和宽变为1/16
- 下面分支经过maxpool4之后变也为1/16,通道数为512;后接上了一个1*1卷积、卷积核数量为num_cls、步长为1,得到特征图大小1/16、通道数变为num_cls
- 之后进行一个相加操作,转置卷积上采样16倍就得到了原图大小h,w,num_cls
须知:vgg16经过mxpool3之后特征图大小下采样率为8,经过maxpool4后下采样率为16。
FCN-8s
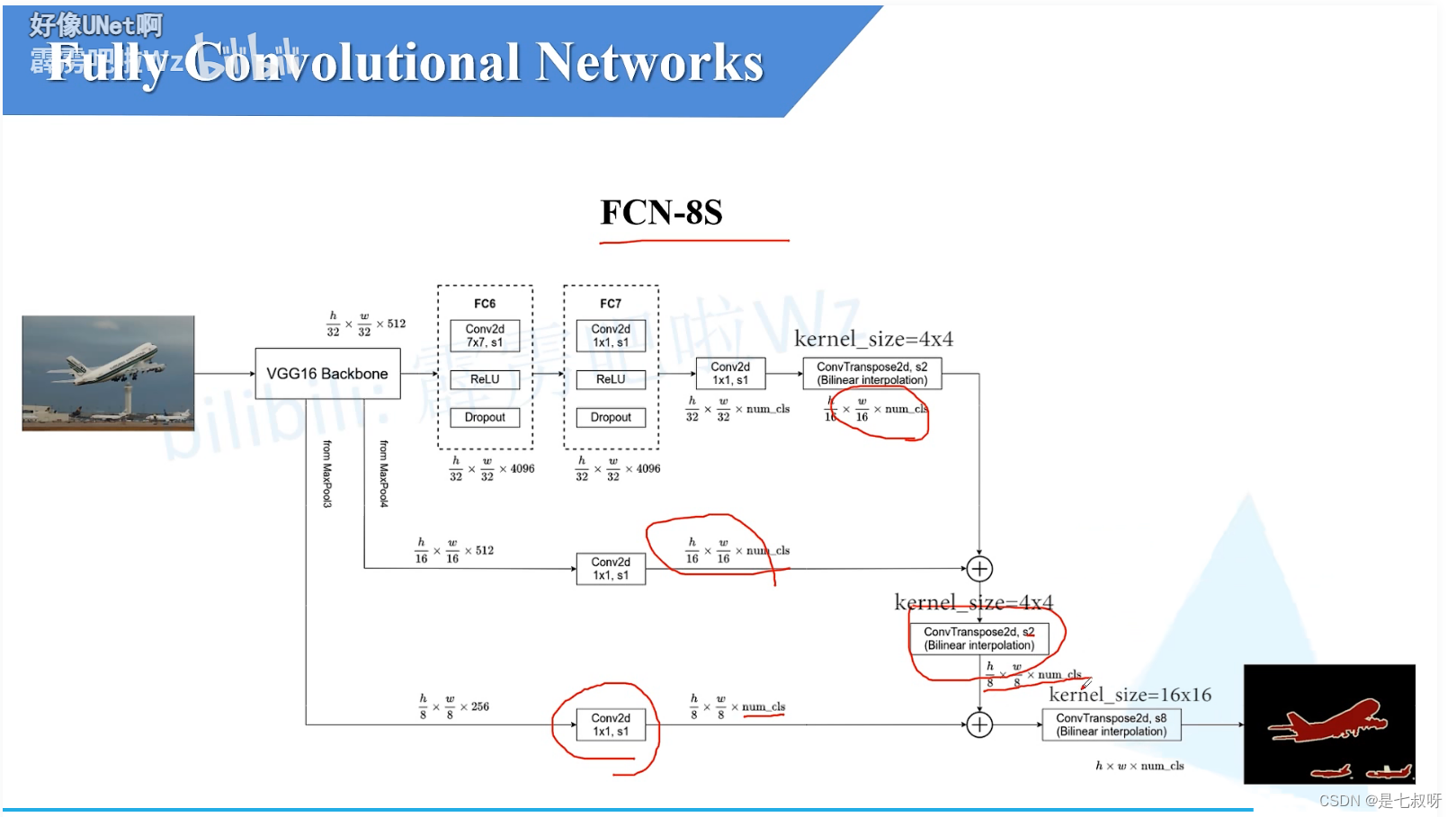
不同点:
- 8s还利用了来自于mxpool3的信息,经过16s类似的1*1卷积层后得到一个1/8,通道数为num_cls的特征图;
- FCN-16s上两层后得到的1/16特征图,经过一个转置卷积上采样,采样率为2倍就能得到一个和maxpool3输出尺寸一样的1/8的特征图
- 一块进行一个相同位置元素的相加操作【进一步的融合】,最后进行一个上采样倍率为8的转置卷积就能得到一个和原图大小一样的特征图大小h,w,num_cls。
在网上看到最多的是FCN-32的实现。
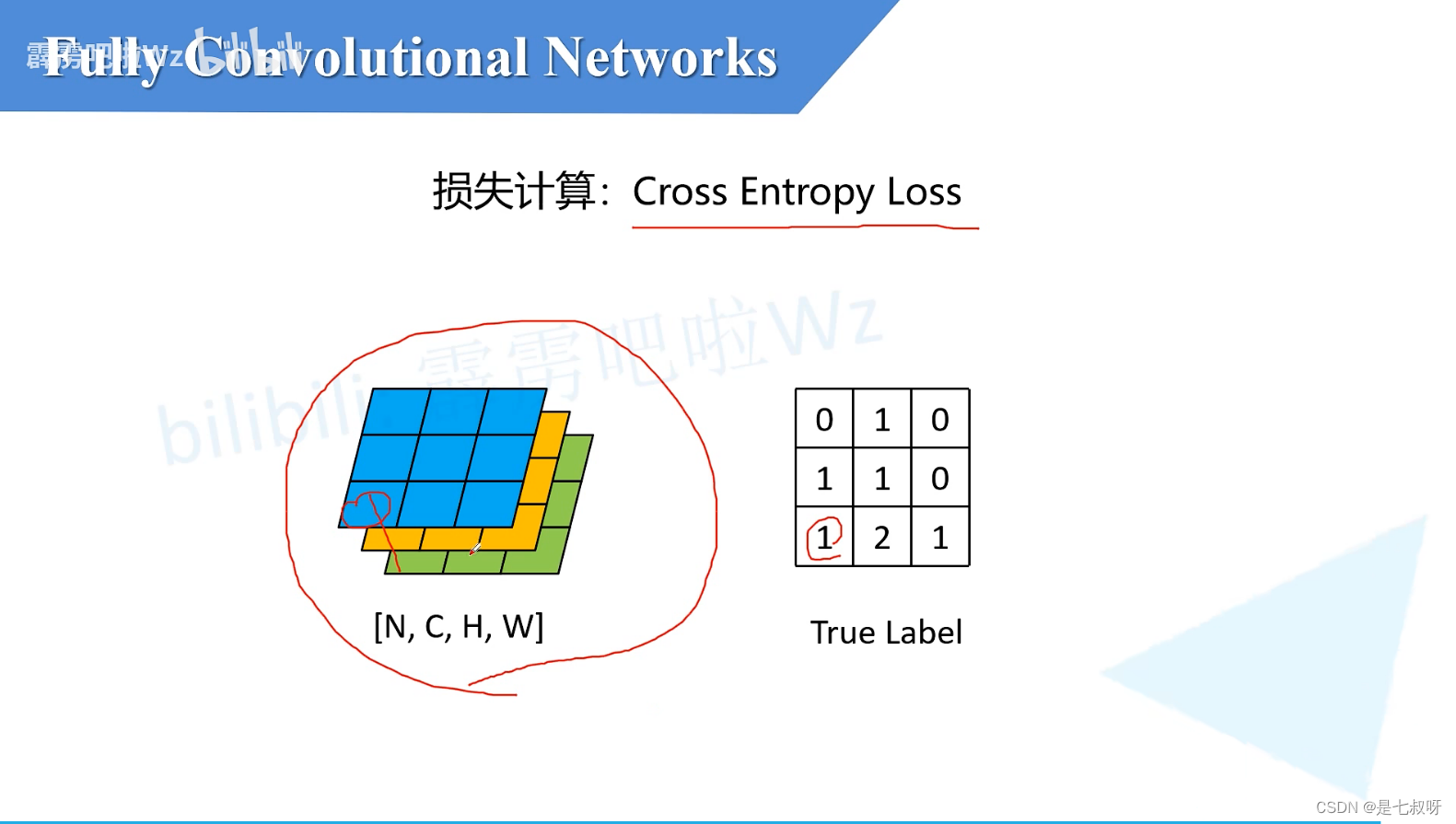
五、损失计算
六、语义分割评价指标

见前言:语义分割前沿
七、代码实现
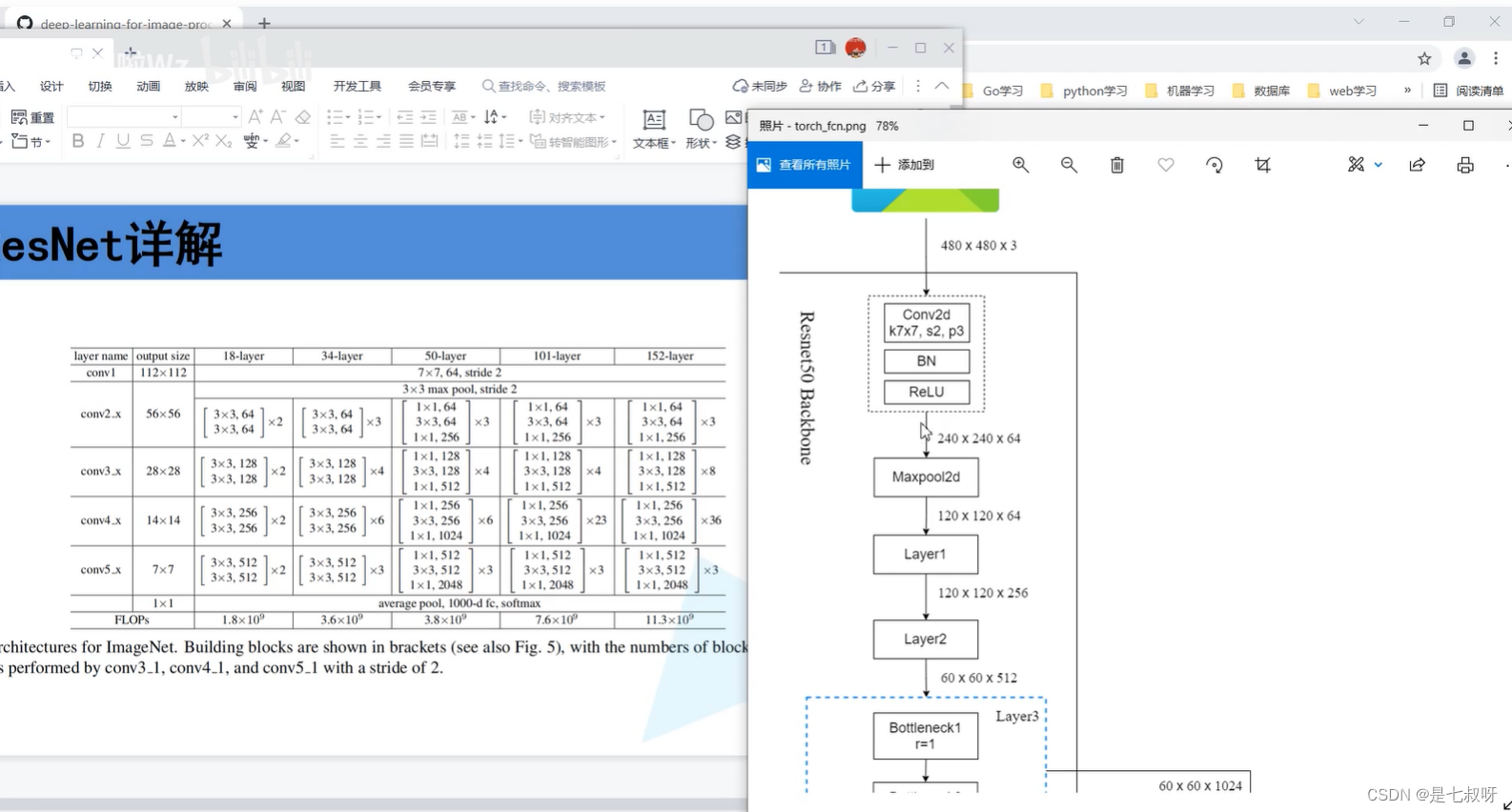
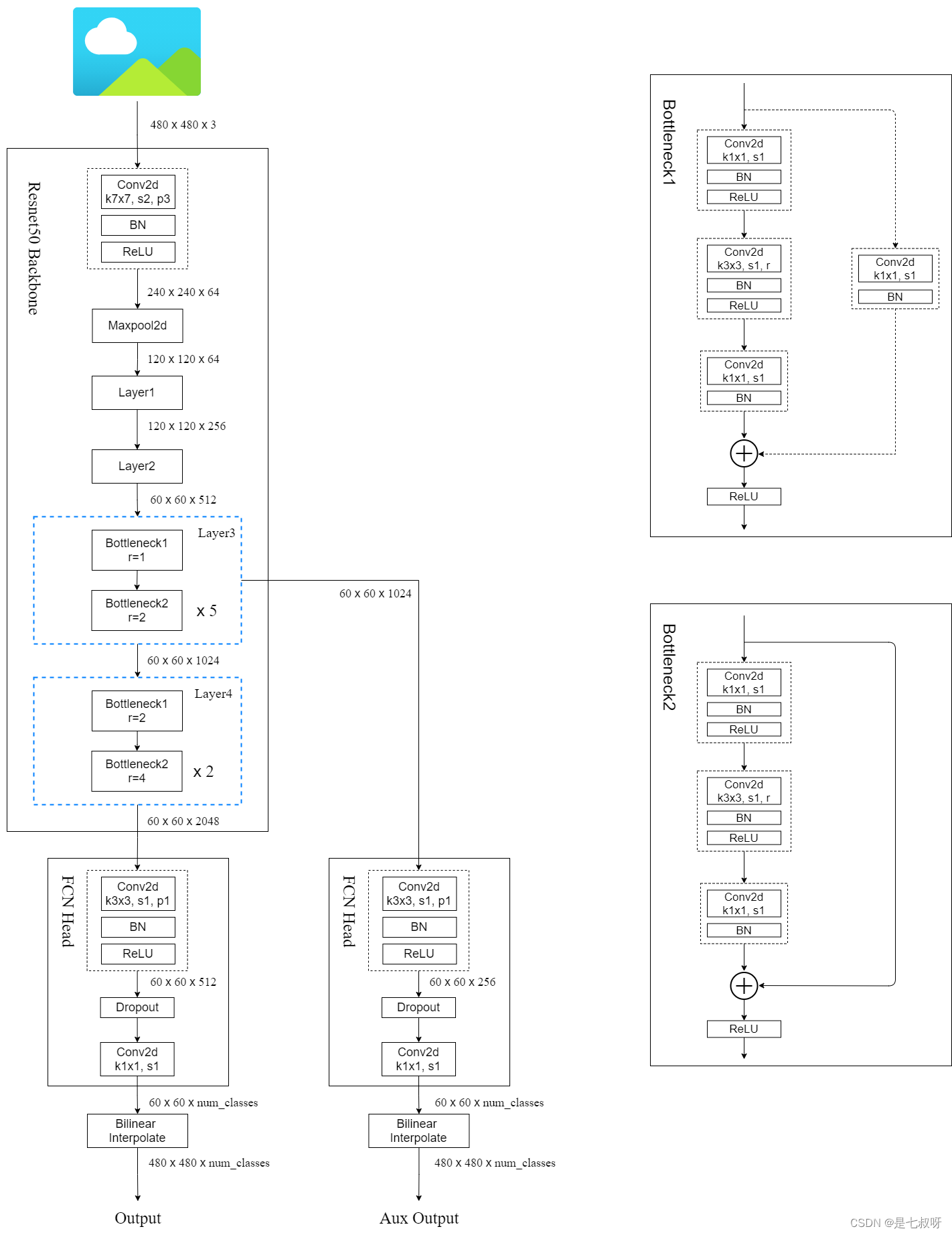
ResNet-50中先经过conv1 7*7的一个卷积
- conv_2:3*3的一个最大池化下采样,再接上3个残差块(对应右图layer1)
- conv_3:4个残差块(对应layer2)
- layer3:这里也有6个残差结构,1个Bottleneck1+5个Bottleneck2
- layer4:3个残差结构,1个Bottleneck1+2个Bottleneck2
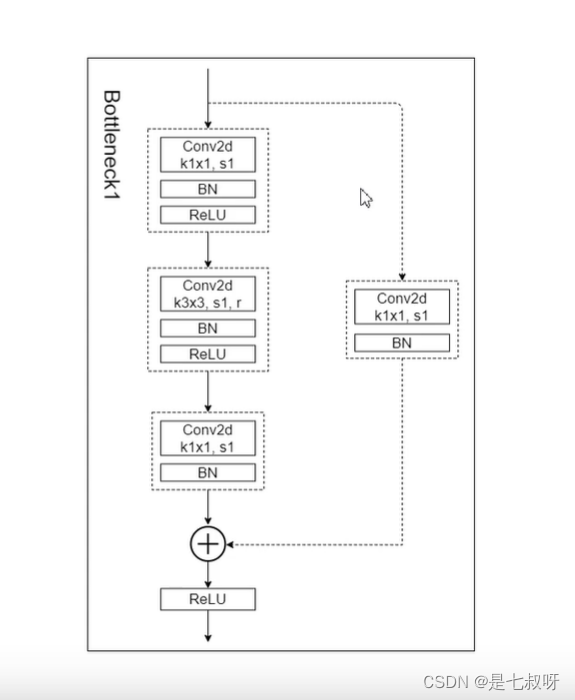
Bottleneck1:
-
将残差连接的2*2卷积层步距改为1,原来resnet这个分支会进行一个下采样将高和宽缩短为一半,【这里因为语义分割中下采样倍率过大的话,再还原成原图后,这里的效果其实会受影响,所以我们这里就没有必要再做一个下采样了。】
-
此外主干分支3*3卷积的步距也从2改为了1,同时引入了r参数,即膨胀系数。
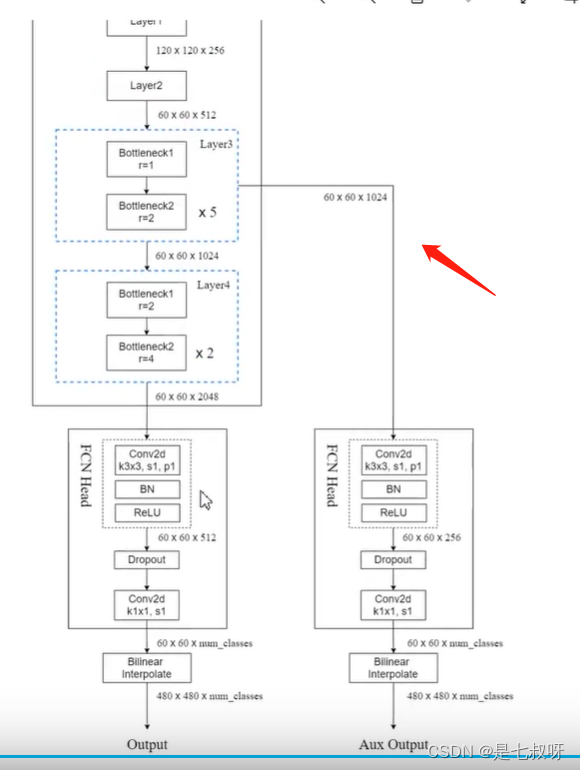
layer3中引出的一条FCN Head,官方回答:为了防止误差梯度没法传递到网络浅层,这里就引入了一个辅助分类器。和google net中辅助分类器是差不多的。
训练的时候是可以使用辅助分类器件的【可用可不用,都可以试一下】,但是最后去预测或者部署到正式环境的时候只用主干的output,不用aux output。
up主的代码地址:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_segmentation/fcn
文章出处登录后可见!