论文地址:https://proceedings.neurips.cc/paper/2019/file/3416a75f4cea9109507cacd8e2f2aefc-Paper.pdf
Abstract
提出问题:注意力机制是否可以成为视觉模型的独立原始元素,而不仅仅是卷积之上的增强。
作者验证了自注意力机制确实可以是一个有效的独立层。用应用于ResNet模型的自注意形式替换所有空间卷积实例的简单过程,产生了一个完全自我注意的自注意模型,并且取得了较好的性能。
1 Introduction
在这项工作中,我们提出了这样一个问题,即基于内容的交互(自注意力机制)是否可以作为视觉模型的主要原语,而不是作为卷积的增强。为此,我们开发了一个简单的局部自注意层,它可以用于小的和大的输入。我们利用这个独立的注意层来建立一个完全注意视觉模型,该模型在图像分类和目标检测方面都优于卷积基线,同时具有参数和计算效率。此外,我们还进行了一些消融研究,以更好地理解独立的关注。我们希望这一结果将激发新的研究方向,重点是探索基于内容的交互,作为一种改善视觉模型的机制。
2 Background
本文提出了一种独立的自我注意层,可以用来代替空间卷积和建立一个完全注意模型。
与卷积类似,给定一个像素![]() ,首先提取位置为
,首先提取位置为![]() 的像素局部区域,空间范围k以
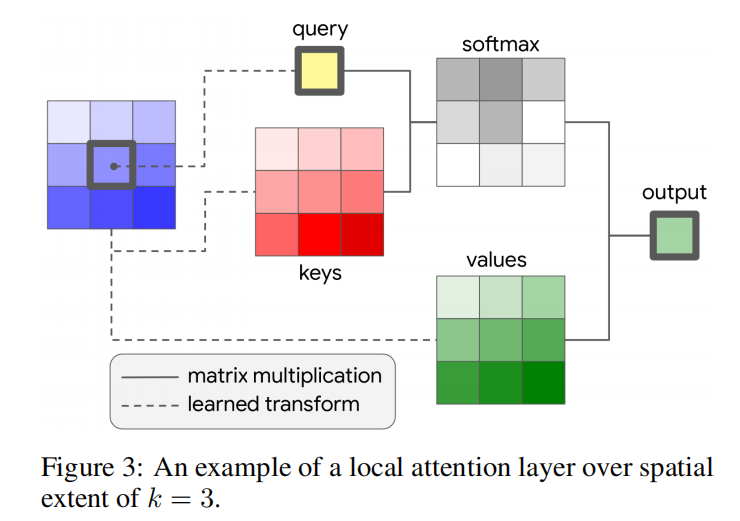
的像素局部区域,空间范围k以为中心,我们称之为memory block。这种形式是局部注意而非全局的,后者在所有像素之间进行了全局注意。全局注意只能在输入应用显著的空间降采样后才能使用,因为它的计算成本昂贵,这阻止了它在完全注意模型中的所有层中使用。
计算像素输出![]() 的单头注意力计算如下(见图3):
的单头注意力计算如下(见图3):
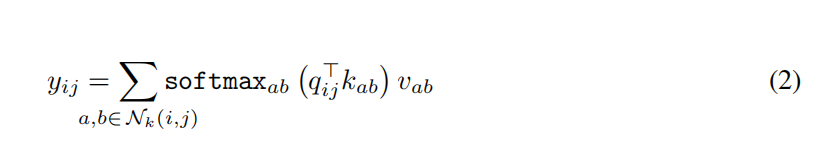
位置编码:基于图像中像素(ij)的绝对位置的正弦编码可以使用,但早期的实验表明,使用相对位置编码可以获得显著更好的精度。使用二维相对位置编码,相对注意。相对注意首先定义ij到每个位置![]() 的相对距离。相对距离是跨维度进行因子分解的,因此每个元素
的相对距离。相对距离是跨维度进行因子分解的,因此每个元素![]() 接收两个距离:一个行偏移量a−i和一个列偏移量b−j(见图4)。行和列偏移量分别与编码
接收两个距离:一个行偏移量a−i和一个列偏移量b−j(见图4)。行和列偏移量分别与编码![]() 和
和![]() 相关联,维数为
相关联,维数为![]() 。行和列的偏移编码被连接起来形成
。行和列的偏移编码被连接起来形成![]() 。这种空间相对的注意力现在被定义为
。这种空间相对的注意力现在被定义为
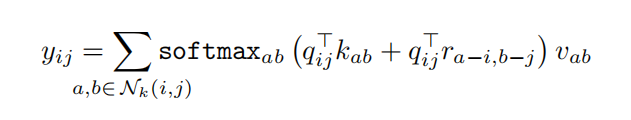

因此,度量查询与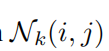 中的一个元素之间的相似性的logit是由元素的内容和元素与查询之间的相对距离来调制的。请注意,通过注入相对位置信息,自我注意也享有平移等方差,类似于卷积。
中的一个元素之间的相似性的logit是由元素的内容和元素与查询之间的相对距离来调制的。请注意,通过注入相对位置信息,自我注意也享有平移等方差,类似于卷积。
注意力机制的参数数量与空间范围的大小无关,而卷积的参数计数随空间范围呈二次增长。与典型的和
值的卷积相比,注意力的计算代价随空间范围的增长也较慢。例如,如果
![]() ,则具有k = 3的卷积层与具有k = 19的注意层具有相同的计算量。
,则具有k = 3的卷积层与具有k = 19的注意层具有相同的计算量。
3 Fully Attentional Vision Models
给定一个局部注意层作为一个原始层,问题是如何构建一个完全的注意架构。我们可以通过两个步骤来实现这一点:
3.1 Replacing Spatial Convolutions
空间卷积定义为与空间范围k > 1的卷积。这个定义排除了1×1卷积,它可以看作是独立应用于每个像素的标准全连接层。在卷积架构中,用注意层替换结构中的空间卷积。当需要空间降采样时,一个2×2的平均池化与stride = 2操作跟随注意层。
这项工作将转换应用于ResNet家族[15]的架构。ResNet的核心构建块是一个bottleneck block 结构1×1投影卷积,3×3空间卷积,1×1投影卷积,其次是残差连接之间的输入和最后卷积的输出块。bottleneck block 重复多次形成ResNet,一个bottleneck block 的输出作为下一个bottleneck block 的输入。所提出的变换将3×3的空间卷积与本文提出的自注意层进行交换。所有其他结构,包括层数和当应用空间降采样时,都被保留下来。
3.2 Replacing the Convolutional Stem
CNN的初始层,被称为stem,在学习局部特征中起着关键作用,之后层使用这些特征来识别全局对象。由于输入图像很大,stem通常与核心块不同,专注于使用空间降采样的轻量级操作。例如,在一个ResNet中,stem是一个7×7的卷积与stride=2,然后是3×3的最大池化与stride=2。
在stem层,内容由RGB像素组成,这些像素单独缺乏空间相关的信息。这一特性使得学习边缘检测器等有用的特性对于基于内容的机制变得困难。我们早期的实验验证了,与使用ResNet的卷积stem相比,使用公式3中描述的自注意形式表现不佳。
卷积的基于距离的权重参数化使他们能够很容易地学习边缘检测器和其他更高层所必需的局部特征。为了在不显著增加计算的情况下弥补卷积和自注意之间的差距,我们通过空间变化的线性变换在1×1卷积(WV)中注入基于距离的信息。新的值变换是![]() ,其中多个值矩阵
,其中多个值矩阵![]() 通过因子的凸组合组合,这些因子是像素在其邻域
通过因子的凸组合组合,这些因子是像素在其邻域![]() 的位置的函数。位置相关因子类似于卷积,卷积学习依赖于邻近区域像素位置的标量权值。然后由具有空间感知值特征的注意层组成,然后是最大池化。为简单起见,注意力接受域与最大池化窗口对齐。
的位置的函数。位置相关因子类似于卷积,卷积学习依赖于邻近区域像素位置的标量权值。然后由具有空间感知值特征的注意层组成,然后是最大池化。为简单起见,注意力接受域与最大池化窗口对齐。
4 Experiments
4.1 ImageNet Classifification
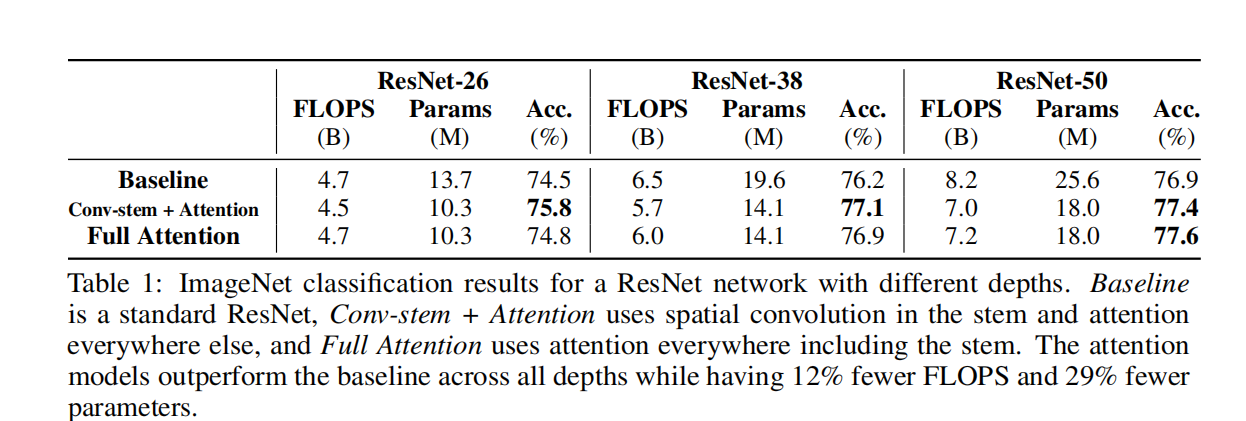
Setup 我们在ImageNet分类任务[55]上进行了实验,该任务包含128万张训练图像和5万张测试图像。使用ResNet-50 [15]模型的每个bottleneck block 内部的自注意层替换空间卷积层的过程来创建注意模型。多头自注意层使用了k=7和8个注意头的空间范围。使用了如上所述的位置感知注意杆。stem在原始图像的每个4×4的空间块内执行自我注意,然后进行批处理归一化和4×4 最大池化操作。
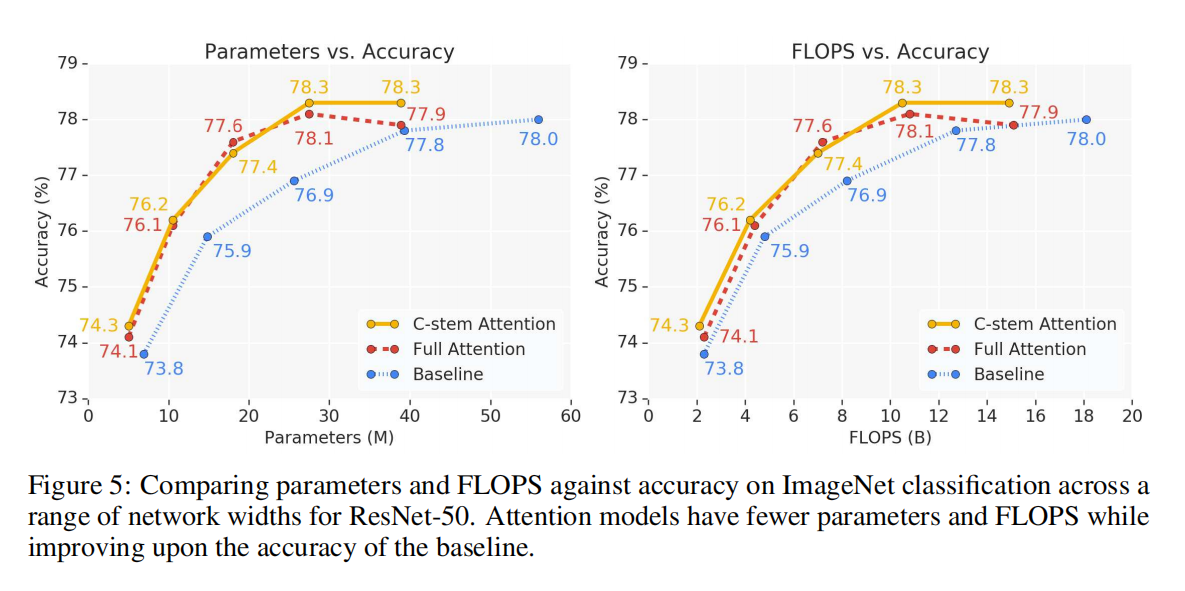
为了研究这些模型在不同计算规模下的行为,我们根据宽度或深度对模型进行了缩放。对于宽度缩放,基本宽度线性乘以所有层中的给定因子。对于深度缩放,从每个层组中删除给定数量的层。有4个层组,每个组的多层层在相同的空间维度上操作。通过空间降采样来划分群体。与50层模型相比,38层和26层模型分别从每层组中去除1层和2层。
Results
 4.2 COCO Object Detection
4.2 COCO Object Detection
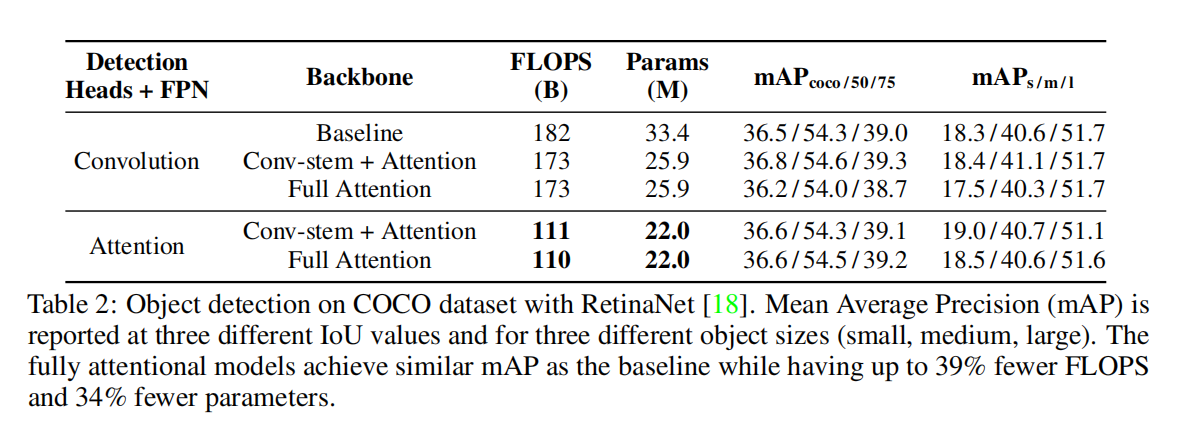
Setup 在本节中,我们将使用RetinaNet体系结构[18]来评估COCO目标检测任务[56]上的注意模型。RetinaNet是一种目标检测模型,它由一个主干图像分类网络、一个特征金字塔网络(FPN)[57]和两个被称为检测头的输出网络组成。我们实验在主干和/或FPN和检测头中使用上面的局部注意。
Results
4.3 Where is stand-alone attention most useful?
Stem 首先,我们比较了attention stem与ResNet中使用的convolution stem的性能。所有其他的空间卷积都被独立的关注所取代。表1、表2和图5显示了ImageNet分类和COCO目标检测的结果。对于分类,convolution stem始终匹配或优于attention stem。对于目标检测,当检测头和FPN也是卷积时,convolution stem表现更好,但当整个网络的其余部分都是完全注意时,convolution stem表现相似。这些结果表明,卷积在stem中使用时始终表现良好。
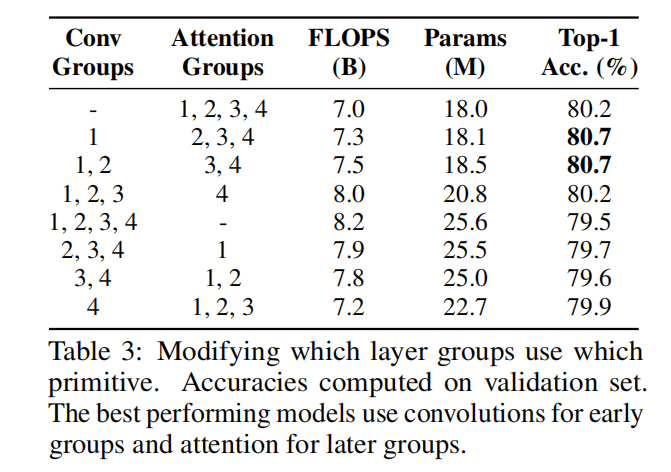
Full network 接下来,我们实验在具有convolution stem的ResNet中的不同层组中使用卷积和独立注意。表3显示,表现最好的模型在早期组中使用卷积,在后期组中使用注意力。这些模型在计算量和参数方面也与完全注意模型相似。相反,当在早期组中使用注意力,而在后期组中使用卷积时,尽管参数计数有了大幅增加,但性能仍会下降。这表明,卷积可以更好地捕获低级特征,而独立的注意层可以更好地整合全局信息。
4.4 Which components are important in attention?
4.4.1 Effect of spatial extent of self-attention
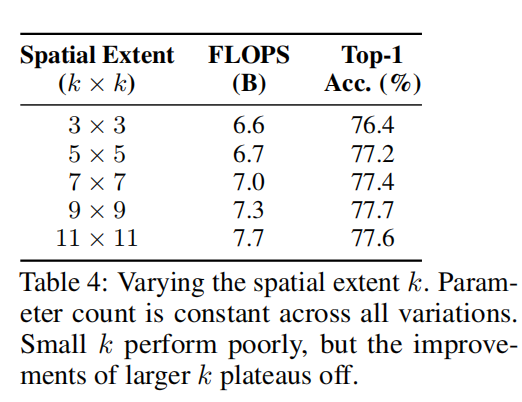
空间范围k的值控制了每个像素可以关注的区域的大小。表4研究了不同空间范围的影响。虽然使用小的k,如k = 3,对性能有很大的负面影响,但在k = 11附近使用更大的k的改进。确切的k值很可能取决于超参数的特定设置,如特征的大小和所使用的注意头的数量。
4.4.2 Importance of positional information
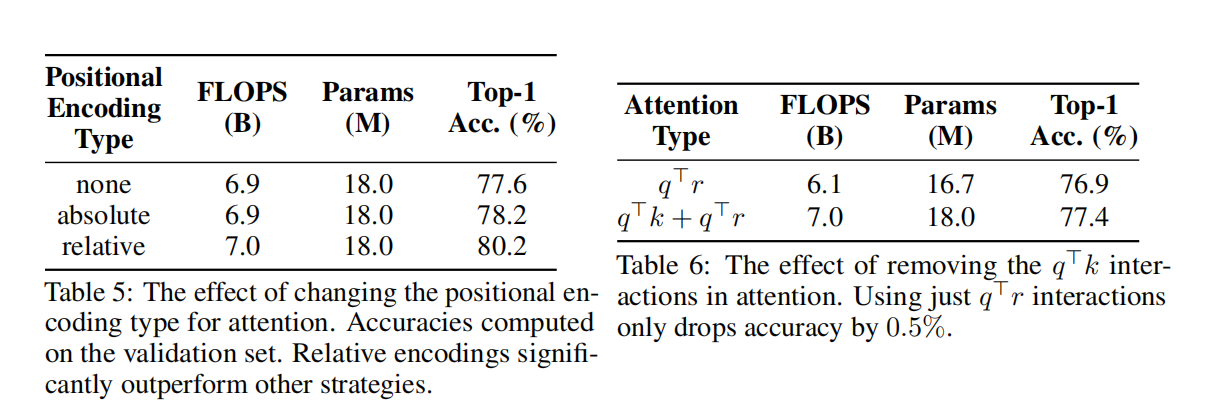
表5列举了可供使用的不同类型的位置编码:没有位置编码,一个依赖于像素[25]的绝对位置的正弦编码,以及相对位置编码。使用任何位置编码的概念都比不使用它更有益,但是位置编码的类型也很重要。相对位置编码比绝对编码好2%。此外,表6还展示了内容相对交互作用(q·r)在注意力中的重要作用。删除content-content(q·k)交互,而仅使用内容相关交互,准确率仅降低0.5%。
4.4.3 Importance of spatially-aware attention stem
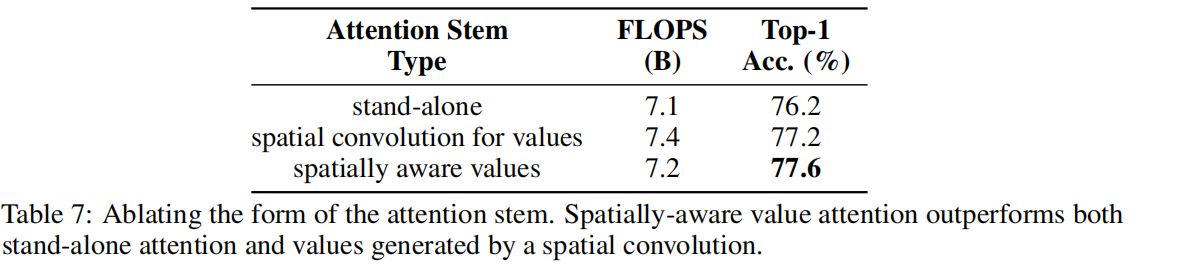
表7比较了在第3.2节中提出的空间感知值。尽管有相似的计算量,但attention stem比stand-alone attention多1.4%,验证了在attention stem中修改注意的效用。此外,对值应用空间卷积,而不是空间感知的点转换混合,会导致更多的计算量,
文章出处登录后可见!