1.泛化能力
1、下面哪一项可以作为模型好的标准?
- 错误率低
- 精度高
- 召回率高
- 以上指标都可以,但视具体任务和使用者需求而异
2、我们希望模型在未见样本上表现好,这一能力通常被称作模型的什么能力?
- 泛化能力
- 建模能力
- 学习能力
- 拟合能力
3、在评价模型性能时,我们更希望它____(泛化能力强/训练误差为0)
泛化能力强
2.过拟合和欠拟合
1、模型在“未来”样本上的误差被称作
- 泛化误差
- 经验误差
- 学习误差
- 训练误差
2、有的情况下,模型学习到了训练数据满足的特有性质,但这些性质不是一般规律,这种现象被称之为
- 欠拟合
- 过拟合
- 欠配
- 以上三个选项都不是
3、在训练模型时,只需要保证模型的训练误差最小即可。____(是/否)
否
3.三大问题
1、模型选择有哪些关键问题?
- 评估方法
- 性能度量
- 比较检验
- 以上三个选项都是关键问题
2、为了说明模型在统计意义上表现好,我们最需要考虑
- 评估方法
- 性能度量
- 比较检验
- 以上三个选项都不需要考虑
比较检验主要是用于判断模型是否在统计意义上表现良好;其余A选项的评估方法,主要用于衡量模型在未来的表现好坏;B选项性能度量是针对具体问题给定的度量标准,对不同问题不太一样(如欺诈问题,10次欺诈99990次非欺诈,如果全分类为非欺诈,虽然精度很大,但是对该问题没有意义)。
3、在没有“未来数据”的情况下,我们____(能/不能)通过训练集对泛化误差进行估计。
能
在没有“未来数据”的情况下,我们可以划分训练数据(以留出法为例),使用验证集上的经验误差作为对泛化误差的估计。
4.评估方法
1、下列什么方法可以用来获得从原始数据集中划分出“测试集”?
- 留出法
- 交叉验证法
- 自助法
- 以上三个选项都可以
2、下面哪一项不是留出法的注意事项?
- 需要保持训练集和测试集数据分布的一致性
- 只需要进行一次划分
- 测试集不能太大,不能太小
- 以上选项都是
A和C均为注意事项,错误主要出现在D选项。针对B选项,西瓜书第25页有提到,“在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作 为留出法的评估结果。”可以得到B选项不是留出法的注意事项。
3、训练集与测试集____(应该互斥/可以不互斥)
应该互斥
测试集如果与训练集不互斥,则因为部分测试数据在训练集中见过,测试误差的估计会受到干扰,变得不精确。
5.调参与验证集
1、调参以什么集合上的性能作为评价标准?
- 训练集
- 测试集
- 验证集
- 以上选项都可以
2、当我们使用一个多项式函数去逼近数据集时,下面哪一个说法是正确的?
- 多项式的次数是超参数
- 多项式的系数是超参数
- 多项式的次数必须通过数据去学习
- 以上说法都是正确的
在使用多项式逼近数据集时,会人工赋予多项式次数(x的多少次方),然后通过训练数据学习多项式的系数(y=wx+b的w和b);因此多项式的次数是超参数,而多项式的系数不是超参数。超参数虽然可以通过学习得到,但一般由人工决定,C选项太过绝对。
3、超参数一般由____(人工/学习)确定
人工
6.性能度量
1、“好”模型取决于下列哪些因素?
- 算法
- 数据
- 任务需求
- 以上选项都是
2、收购西瓜的公司希望把瓜摊的好瓜都尽量收走,请问他的评价标准是?
- 错误率
- 精度
- 查准率
- 查全率
3、回归任务的性能度量之一均方误差 添加系数后
会影响判断那个模型是最好的。___(是/否)
否
7.比较检验
1、以下什么检验是基于列联表的?
- 交叉验证t检验
- McNemar检验
- 以上检验都是基于列联表的
- 以上检验都不是基于列联表的
2、下面关于交叉验证t检验错误的是?
- 适用于模型采用k折交叉验证的评估方法
- 基于成对t检验
- 无法判断统计显著性
- 需要用到模型评估时k折交叉验证的k个结果
3、两种算法在某种度量下取得评估结果后,可以直接比较以评价优劣。____(是/否)
否
8.章节测试
1、在训练集上的误差被称作
- 泛化误差
- 经验误差
- 测试误差
- 以上三个选项都不对
2、当学习任务对数据分布的轻微变化比较鲁棒且数据量较少时,适合使用什么样的数据集划分方式?
- 留出法
- 交叉验证法
- 自助法
- 以上三个选项都可以
本题关键是考虑“数据量较少”,此时无论是使用留出法还是交叉验证法,都会使得训练集数据量进一步变少,而使用自助法则不会有这样的问题(不改变样本数量);其次考虑“对数据分布轻微变化比较鲁棒”,说明使用自助法时带来的训练数据分布变化不会有太多负面影响。综上,本题应该选C。
3、我们通常将数据集划分为训练集,验证集和测试集进行模型的训练,参数的验证需要在____上进行,参数确定后____重新训练模型。
- 训练集 需要
- 训练集 不需要
- 验证集 需要
- 验证集 不需要
4、当西瓜收购公司去瓜摊收购西瓜时既希望把好瓜都收走又保证收到的瓜中坏瓜尽可能的少,请问他应该考虑什么评价指标?
- 精度
- 查全率
- 查准率
- F1度量
本题希望“既” 把好瓜都收走,“又”要求坏瓜尽可能的少,所以需要一个综合考虑查全率、查准率的性能度量,而F1度量恰好对查全率、查准率均有所考虑,因此本题选D。
5、两种算法在某种度量下取得评估结果后不能直接比较以评判优劣的原因中,正确的是
- 测试性能不等于泛化性能
- 测试性能随着测试集的变化而变化
- 很多机器学习算法本身有一定的随机性
- 以上均正确
6、训练模型时,选择经验误差最小的模型会存在什么风险。____(过拟合/欠拟合)
过拟合
7、对于从数据 通过最小二乘拟合的不带偏置项的线性模型
,其训练误差(均方误差)为____ (保留三位小数)
1.000
8、使用留出法对数据集进行划分时,为了保持数据分布的一致性,可以考虑什么采样。____(分层采样/随机采样/有放回采样)
分层采样
9、当我们使用留出法对数据集进行划分后,在训练集上通过两个不同的算法训练出2个模型,并通过测试集上的性能评估得到表现最好的模型,这一模型可以直接推荐给用户。 ____(是/否)
否
10、考虑一个三分类数据集,其由30个西瓜,30个苹果,30个香蕉构成。先有一个学习策略为预测新样本为训练集中样本数目最多类别的分类器(存在多个类别样本数量一样多时则随机选择一个类别预测),请问通过什么评估方式会导致其平均准确率为0。____(留出法/交叉验证,每一折样本数大于1/留一法)
留一法
11、当我们使用留一法进行评估时会出现什么问题。____(训练模型与使用整个数据集训练的模型差异大/经验误差与泛化误差偏差大)
经验误差与泛化误差偏差大
使用留一法时,训练数据集只比之前的全集少一个样本,训练模型与使用整个数据集训练的模型差异不会很大;但是只在一个样本上进行模型评估得到的经验误差,会与模型在真实样本分布上的期望误差(即泛化误差)存在很大的偏差(bias)
12、考虑如下分类结果混淆矩阵,其F1度量为____(保留3位小数)
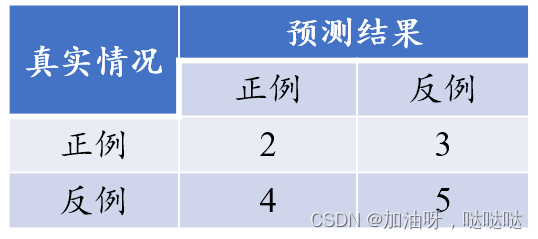
0.364
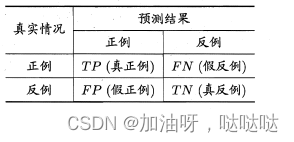
查准率:
查全率:
F1:
13、McNemar检验基于____(成对t检验/卡方检验)
卡方检验
14、假设我们已经建立好了一个二分类模型, 输出是0或1, 初始阈值设置为0.5, 超过0.5概率估计就判别为1, 否则就判别为0 ; 如果我们现在用另一个大于0.5的阈值, 一般来说,下列说法正确的是
- 查准率会上升或不变,查全率会下降或不变
- 查准率会下降或不变,查全率会下降或不变
- 查准率会上升或不变,查全率会上升或不变
- 查准率会下降或不变,查全率会上升或不变
可以考虑特殊,比如把阈值设置为0.99,那么预测为正例的(几乎)肯定全是真正例,查准率上升,但是查全率也一定大打折扣;而若把阈值设置为0,把所有样本全预测为正例,那么查全率为1(上升了),但是查准率会下降,因为预测的正例中真正例比率下降了。
15、对于留出法,下列说法正确的是
- 测试集小的时候,评估结果的方差较大
- 训练集小的时候,评估结果的偏差较大
- 留出法需要对数据集进行多次切分并将结果取平均值
- 以上说法均正确
文章出处登录后可见!