该论文发表在CVPR 2022上
目录
主要任务
DiffusionCLIP的主要任务就是利用CLIP和Diffusion模型做图像处理(这里的处理指按照指定的命令修改图像风格,或者修改图像所包含的内容)。
读这篇文章之前,我们可以回顾一下CLIP模型的结构和功能 CLIP, 总结一下就是,做文本和图像在特征空间上的特征对齐,可以作为预训练模型应用到下游的CV任务/多模态任务上。
回顾一下 Diffusion Model,Diffusion Model 主要通过添加噪音的Forward过程和去除噪音的Reverse过程来训练生成模型,从而模型具有从高斯分布的噪音中采样真实图像的能力。但是由于Forward过程和Reverse过程有随机的变量,因此将一个图像映射成一个噪音向量后,并不能保证可以从这个噪音空间中恢复出原图,本文也提出了方法解决上述问题。
方法介绍
DDPM/DDIM回顾
这里可以先把DDPM理解为不确定地Forward和Reverse过程,而DDIM是确定性地Forward和Reverse过程。
(DDIM/DDPM存疑-需要查看原论文)
首先,论文回顾一下经典的两个Diffusion Model模型,DDPM [1] 和DDIM[2]
DDPM的逆向过程为:
(1)
其中 .
模型架构
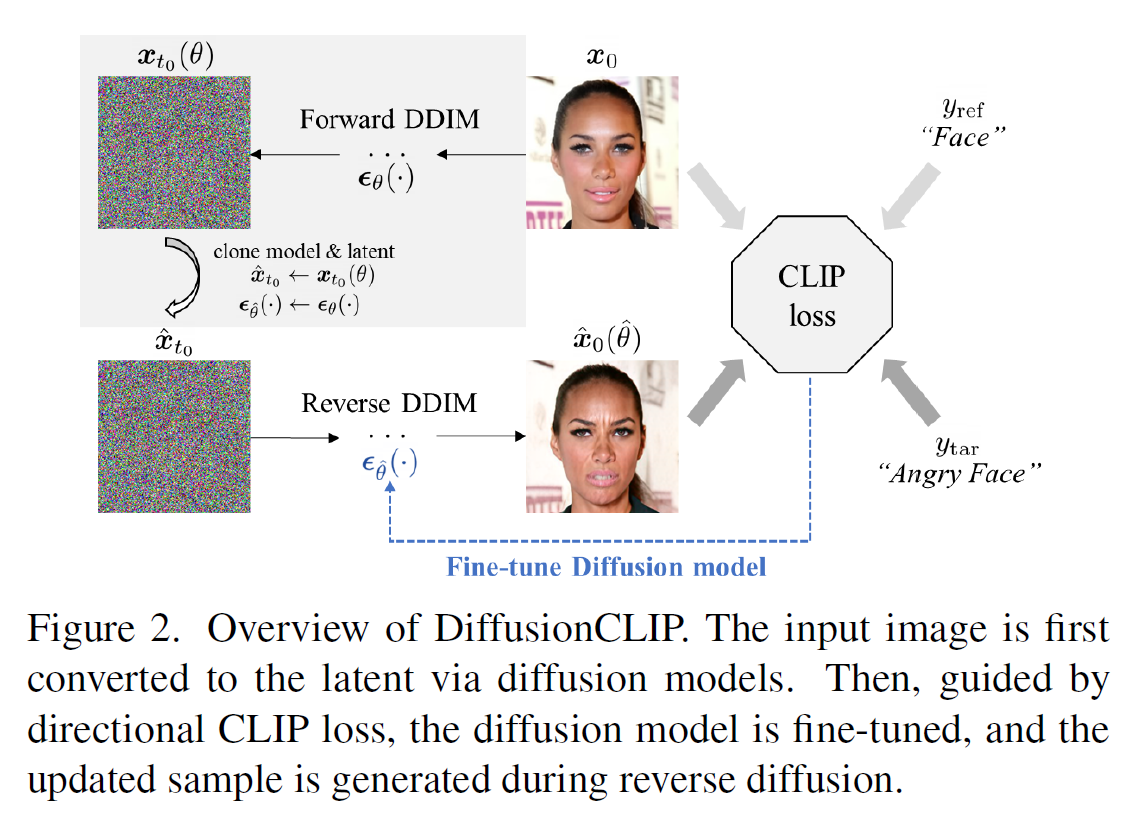
模型架构如上所示:
首先图片经过Diffusion Forward Step 转换成噪音数据,这个阶段利用的模型是预训练的模型,其参数是不能更改的。在Reverse Step,我们需要修改数据内容,因此需要根据Loss调整 的参数。
由上可见,其实修改图像的效率不是很高,如果模型复杂的话,那么计算量将会更大。并且,forward过程可以不用完全执行,可以diffusion到一定阶段,保留图像的一些语义信息,这样也会更利于 reverse过程中生成的图像保留原始图像的语义。
Loss设计
那么如何用CLIP来设计loss调整图像呢?
文章首先定义了, 用来保证模型沿着我们指定的文本内容修改图像。
(2)
其中 ,
分别表示CLIP模型对图像和文本的特征表示。gen表示Diffusion 模型生成图像,tar表示我们想得到的图像风格或者内容,ref表示原图和原描述(如果没有可以简单指定为picture,human等)。
除了风格/内容修改之外,我们还希望生成图像和原图能够对应,因此还需要 ,
这样就可保证在原始内容基本不变的情况下完成风格转换,或者内容修改。
Forward和Reverse过程
因为之前提到了,Diffusion Model在正向或者逆向过程都会引入随机变量,因此很难保证可以从隐空间(高斯噪音空间)恢复出原始图像。
为了首先确定的Reverse过程,文章采用确定的DDIM reverse process,定义如下:
(3)
其中,, 是在
时刻对
的预测。
在Forward过程可以利用ODE近似确定,定义如下:
经过这样修改,Forward过程和Reverse过程都是确定性的过程,(注意ODE近似并不能保证完全相同)。
未知Domain之间的迁移
首先我们需要确定什么是未知Domain。假设我们训练Diffusion模型用的数据是自然图像(相机拍摄图像)。那么油彩画风格的图像,我们的Diffusion模型没有训练过,那么油彩画风格的图像就是未知Domain或Unseen Domain。
下面可以将任务分类:
- 已知Domain -> 已知Domain:这一类任务只需要只需要上图所示的框架就可以解决,是最基础的任务。
- 已知Domain-> 未知Domain:这一类任务只需要在y_tar文本添加我们需要的风格描述即可,比如油彩画风格的草原/梵高风格的夜空。因为这些Unseen Domain一般都出现在了CLIP所使用WIT数据集里面。
- 未知Domain-> 已知Domain:首先我们需要用Diffusion Model的Forward过程来进行噪音添加,但是无法应用DDIM的确定性过程,应为确定性过程需要训练好的Diffusion Model的参数。所以只能应用DDPM的Forward过程,这个时候,Forward过程不能执行所有step,需要保留一定的语义。
- 未知Domain->未知Domain:这个步骤需要借用 未知Domain->已知Domain->未知Domain的过程。
详细的论文中的可视化为:

实验结果
实验结果中Recon的结果值得重点关注:

从上面可以看出,DiffusionCLIP的重建能力比较强,相当于完成了一个Encoder,Decoder的功能。
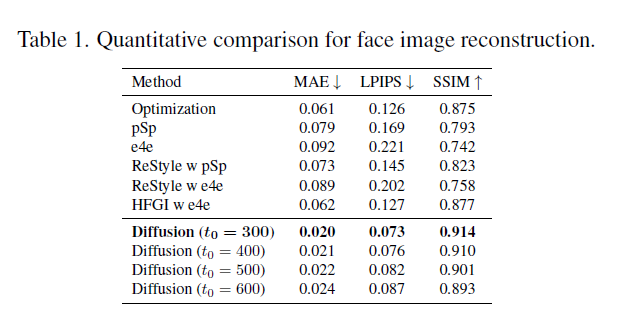
上述是重建能力的量化图表结果。
也有一些其他的数据,不过是用人的问卷作为评价,因此在本博客中不具体说明。
参考文献
- Sohl-Dickstein J, Weiss E, Maheswaranathan N, et al. Deep unsupervised learning using nonequilibrium thermodynamics[C]//International Conference on Machine Learning. PMLR, 2015: 2256-2265.
- Song J, Meng C, Ermon S. Denoising diffusion implicit models[J]. arXiv preprint arXiv:2010.02502, 2020.
文章出处登录后可见!