百度飞桨202210更新的表格识别模型SLENET(Structure Location Alignment Network)。
官方给出的优化点如下:
PP-LCNet:CPU 友好型轻量级骨干网络
CSP-PAN:轻量级高低层特征融合模块
SLAHead:结构与位置信息对齐的特征解码模块
在PubTabNet英文表格识别数据集上的消融实验如下:
| 策略 | Acc | TEDS | 推理速度(CPU+MKLDNN) | 模型大小 |
|---|---|---|---|---|
| TableRec-RARE | 71.73% | 93.88% | 779ms | 6.8M |
| +PP-LCNet | 74.71% | 94.37% | 778ms | 8.7M |
| +CSP-PAN | 75.68% | 94.72% | 708ms | 9.3M |
| +SLAHead | 77.70% | 94.85% | 766ms | 9.2M |
| +MergeToken | 76.31% | 95.89% | 766ms | 9.2M |
在PubtabNet英文表格识别数据集上,和其他方法对比如下:
| 策略 | Acc | TEDS | 推理速度(CPU+MKLDNN) | 模型大小 |
|---|---|---|---|---|
| TableMaster | 77.90% | 96.12% | 2144ms | 253.0M |
| TableRec-RARE | 71.73% | 93.88% | 779ms | 6.8M |
| SLANet | 76.31% | 95.89% | 766ms | 9.2M |
以上数据来自官方github主页。
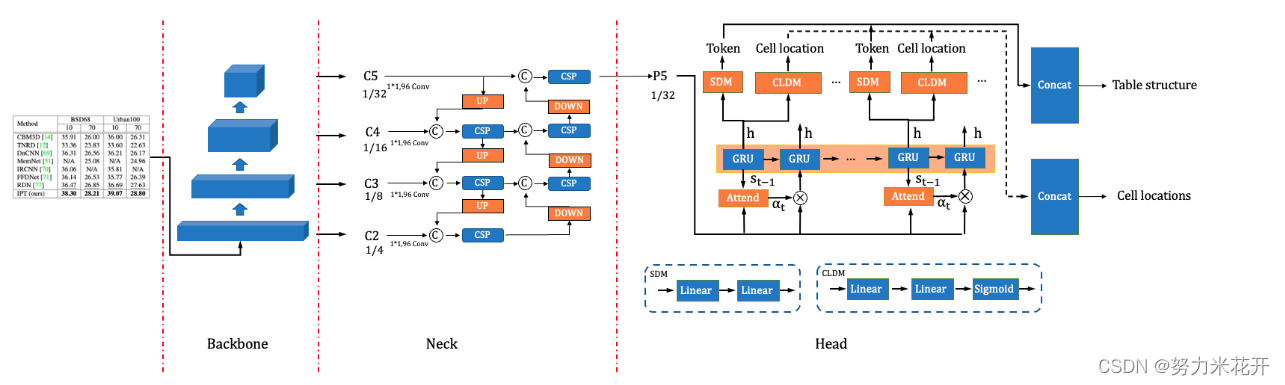
下面详细介绍一些网络的结构
图片前处理
首先看一下前处理操作
主要的图片前处理操作包括
ResizeTableImage {'max_len': 1000, }
PaddingTableImage 'size': [1000, 1000]
NormalizeImage {
'std': [0.229, 0.224, 0.225],
'mean': [0.485, 0.456, 0.406],
'scale': '1./255.',
'order': 'hwc'
}
ToCHWImage
KeepKeys {'keep_keys': ['image', 'shape']}
从上面的配置就可以看出对图片的预处理操作,具体就不展开了。
Backbone层-CPU友好型轻量级骨干网络PP-LCNet
网络代码保存在ppocr/modeling/backbones/PPLCNet中。
主要的结构是类似典型的FPN网络,但是在细节上做了一些处理。熟悉FPN网络的同学可以直接通过下面的配置信息看到网络的结构。
PP-LCNet是结合Intel-CPU端侧推理特性而设计的轻量高性能骨干网络,该方案在图像分类任务上取得了比ShuffleNetV2、MobileNetV3、GhostNet等轻量级模型更优的“精度-速度”均衡。PP-StructureV2中,我们采用PP-LCNet作为骨干网络,表格识别模型精度从71.73%提升至72.98%;同时加载通过SSLD知识蒸馏方案训练得到的图像分类模型权重作为表格识别的预训练模型,最终精度进一步提升2.95%至74.71%。
主要的特点是:
- 结合了mobilenet的关键结构deepwise conv和point_wise作为基础的结构单元,减少参数
- 在最后的一层中采用SEnet的关键结构,用于从512层的block6中获得比较重要的通道权重。
- 下面的配置中,每个列表元素分别表示(卷积尺寸、输出通道、输出通道,步长,是否使用SE模块),block5和block6中选择了5*5卷积来进一步扩大感受野
主干网络是一个自上而下的,通道数量逐渐增多,感受野逐步增大,分辨率逐渐减小的主干网络。最终的输出为block3-block6,构成一个列表输出到neck层。
"blocks2":
# k, in_c, out_c, s, use_se
[[3, 16, 32, 1, False]],
"blocks3": [[3, 32, 64, 2, False], [3, 64, 64, 1, False]],
"blocks4": [[3, 64, 128, 2, False], [3, 128, 128, 1, False]],
"blocks5":
[[3, 128, 256, 2, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False],
[5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False]],
"blocks6": [[5, 256, 512, 2, True], [5, 512, 512, 1, True]]
}
Neck层-轻量级高低层特征融合模块CSP-PAN
对骨干网络提取的特征进行融合,可以有效解决尺度变化较大等复杂场景中的模型预测问题。
早期,FPN模块被提出并用于特征融合,但是它的特征融合过程仅包含单向(高->低),融合不够充分。CSP-PAN基于PAN进行改进,在保证特征融合更为充分的同时,使用CSP block、深度可分离卷积等策略减小了计算量。在表格识别场景中,我们进一步将CSP-PAN的通道数从128降低至96以降低模型大小。最终表格识别模型精度提升0.97%至75.68%,预测速度提升10%。
—–以上描述来自官方的github介绍
输入为block3-block6层的输出,输入的通道数量分别为[64,128,256,512]
输出为一个包含96个通道的feature map。网络默认采用DWlayer(也就是deepwise+pointwise层,不过这里的激活函数默认leaky_relu),用于减少参数量。
四个输入层首先各自通过一个普通1*1卷积层+BN+hardwish激活函数,将每层的输出通道数量都统一为96。
CSP-PAN网络在backbone网路的基础上进行了依次自上而下的特征融合,又进行了依次自下而上的特征融合。通过融合低级与高级信息来增强不同 scale 的特征。因为它由分离的、仅需要最小计算量的(深度可分离卷积)卷积构成,所以即使增加了额外的自下而上的融合操作,计算量也没有增加很多。
在自上而下的上采样过程采用最近邻插值法实现,比如
;
;
原本的block6的特征层保存,记为.
这样就可以得到CSP网络中自上而下的特征列表[inner1,inner2,inner3,inner4].
这里提到的CSPLayer结构如下所示。

其中的short_conv和main_conv都是简单的
输出通道数量为输入的一半,用于进一步提取特征。其中main_conv输出进入一个DarknetBottleneck结构中,这个结构通过一个卷积进一步压缩特征,然后通过一个deepwise+pointwise结构,其中deepwise的卷积尺寸为
,进一步提升了特征的感受野区域。最终将main_conv和short_conv中的特征进行concat融合。
CSP结构将原来DenseNet中对于全部feature map的重复梯度计算降低了一半。
Head层-结构与位置信息对齐的特征解码模块SLAHead
TableRec-RARE的TableAttentionHead如下图a所示,TableAttentionHead在执行完全部step的计算后拿到最终隐藏层状态表征(hiddens),随后hiddens经由SDM(Structure Decode Module)和CLDM(Cell Location Decode Module)模块生成全部的表格结构token和单元格坐标。但是这种设计忽略了单元格token和坐标之间一一对应的关系。
PP-StructureV2中,我们设计SLAHead模块,对单元格token和坐标之间做了对齐操作,如下图b所示。在SLAHead中,每一个step的隐藏层状态表征会分别送入SDM和CLDM来得到当前step的token和坐标,每个step的token和坐标输出分别进行concat得到表格的html表达和全部单元格的坐标。此外,考虑到表格识别模型的单元格准确率依赖于表格结构的识别准确,我们将损失函数中表格结构分支与单元格定位分支的权重比从1:1提升到8:1,并使用收敛更稳定的Smoothl1 Loss替换定位分支中的MSE Loss。最终模型精度从75.68%提高至77.7%。
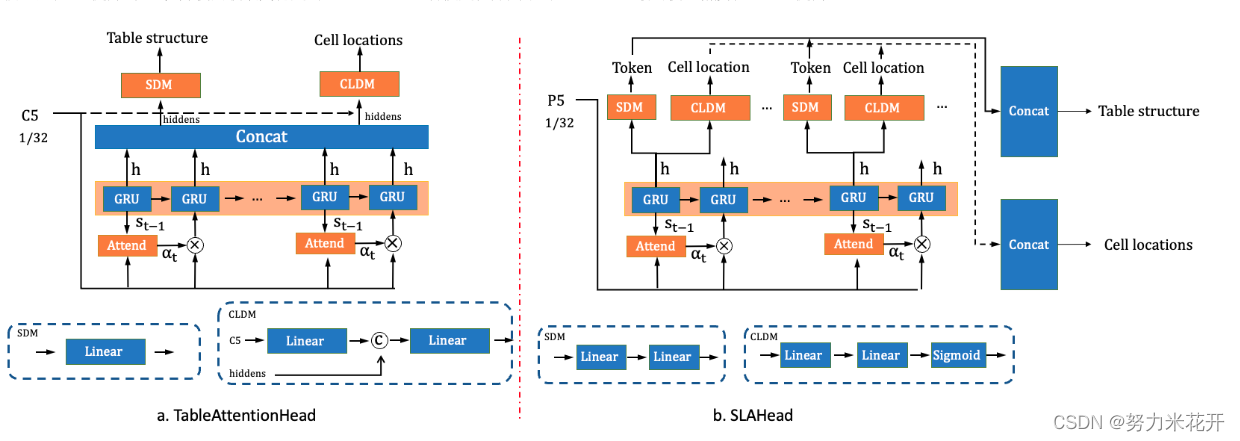
上述内容来自官方介绍
网络的核心部分是一个这是一个典型的RNN网络结构单元。因此预测表格结构任务是一个预测xml元素序列的任务。
只采用Head层的最后一层输出作为head层的输入。因此输入为[B,C,H,W]的特征图,通过转换轴等方式变为[B,H*W,C],这样的序列就变为[B,T,C]的输入,可以将第二个轴看为是时间片,每个时间片的特征为C-embedding。
那么怎么体现输入的注意力机制呢?
通过下面的结构实现,假设每个时间可能的输出xml元素类型有N个分类选项。
<thead>
<tr>
<td>
</td>
</tr>
</thead>
<tbody>
</tbody>
<td
colspan="5"
>
colspan="2"
colspan="3"
rowspan="2"
colspan="4"
colspan="6"
rowspan="3"
colspan="9"
colspan="10"
colspan="7"
rowspan="4"
rowspan="5"
rowspan="9"
colspan="8"
rowspan="8"
rowspan="6"
rowspan="7"
rowspan="10"
对于输入input为[B,T,C],这里C为96;前一刻的隐藏层pre_hidden为[B,H],其中H为隐藏层的输出通道数量,这里设置为256。那么通过线性结构将输入input转为[B,T,256],实现隐藏层和输入层的通道统一,然后通过一系列的得到每个时间片t对于当前预测序列的重要程度,通过矩阵乘法实现注意力机制,最终输出的维度为[B,C],其中C通道的特征可以看成是通过对T个时间片(也就是H*W个特征图元素)进行了权重筛选之后的得到的最终特征。这个特征并不是GRUCell的输入,这个特征需要concat前一个时刻的预测输出元素的one_hot结果,序列预测输出的one_hot表征为[B,N],因此得到的[B,C+N]才是GRU的输入。
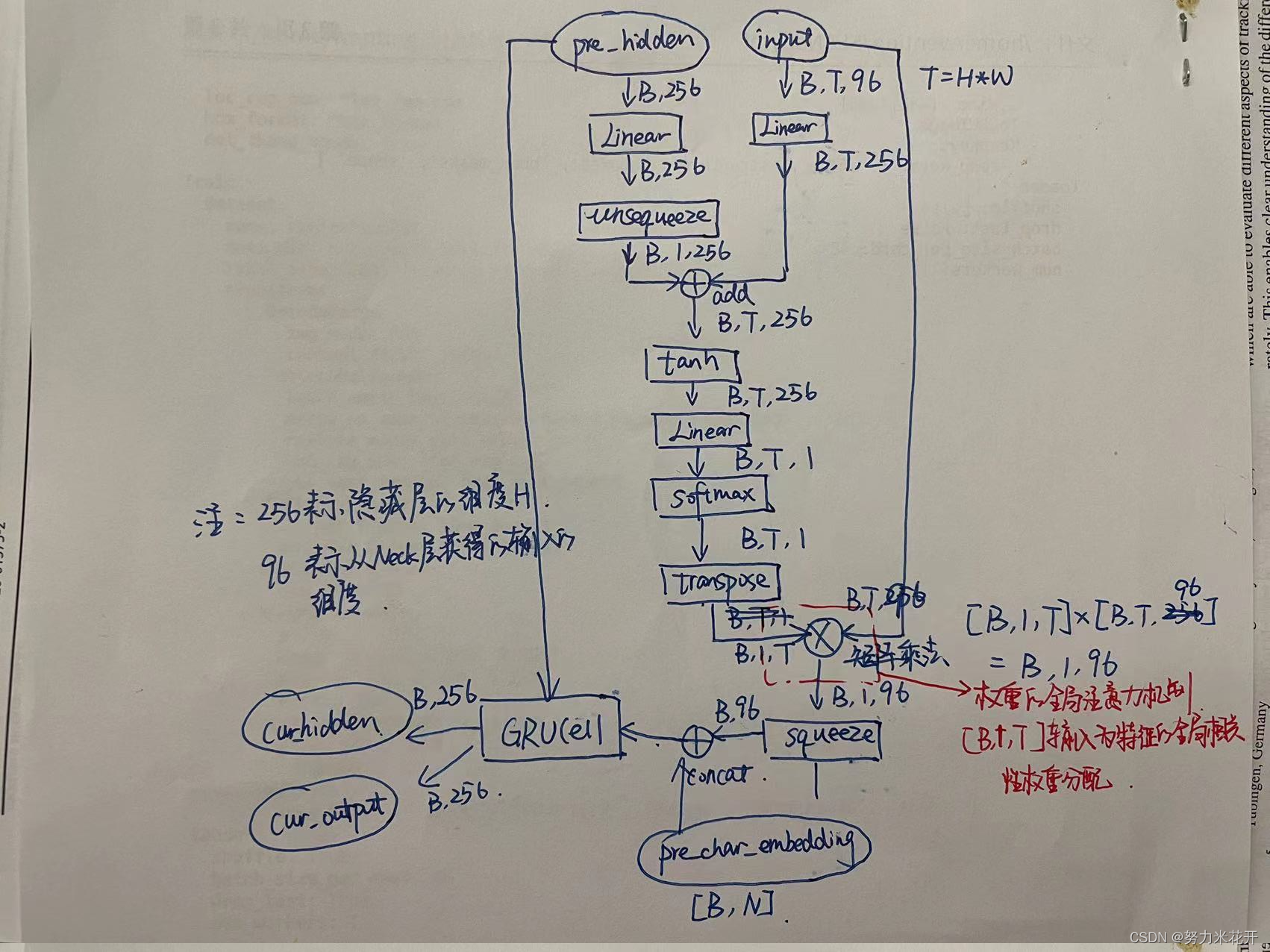
再来重申一遍,GRU的输入有两个,一个是前面提到的[B,C+N]的输入,这个输入既包含了图片特征图的注意力机制输入又包括上一个时间片的预测输入;另一个是上一个时间片的隐藏层输出[B,H]。GRU的输出为当前的隐藏层cur_hidden,维度为[B,H]以及一个当前序列输出output,维度也是[B,H]。
输出output通过两个线性层可以得到[B.N]结构的序列预测输出;也可以通过两个线性层得到[B,8]的单元格坐标输出。这样就得到最终需要的xml结构信息和单元格坐标信息。
对于非训练任务来说,输出output通过两个线性结构转为[B,N],然后通过argmax得到概率最大的那个index作为预测结果,接着通过one_hot编码转为下一个时间片的预测输入;
对于训练任务来说,直接采用GT的对应xml元素的one_hot_enbedding作为下一个时间片的预测输入。
损失函数
损失函数有两个,一个是预测的结构序列T中每个位置的预测损失,假设每个元素的可能值有N个,对于每个位置而言这就是一个多分类任务,因此采用分类损失函数交叉熵损失来计算,取序列元素的损失均值作为最终的structure_los。
第二个损失是每个单元格的坐标预测,这是一个回归任务,因此可以用回归任务的损失函数smooth L1 loss来计算。

最终的损失为两者的权重和
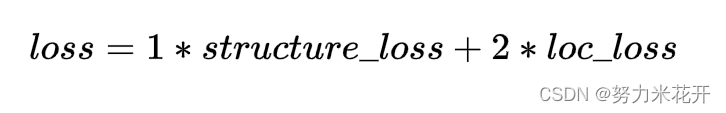
后处理
后处理decoder
后处理的输入为一个dict是来自SLAhead输出outputs.
preds[‘structure_probs’]为一个列表[B,T,N],B为batchsize,T为序列预测长度,N为序列元素可能值的数量,其中每个元素为预测的xml标签元素的预测概率;
preds[‘loc_preds’] 对每个preds[‘structure_probs’]元素都唯一生成一个八点坐标(四角坐标),如果这个元素恰为[‘’, ‘<td’, ‘’]中的一个,那么这个坐标信息就是单元格的坐标,其他的标签元素的坐标信息没什么作用,毕竟我们只关心单元格的四点坐标。
采用贪心策略,序列每个位置的预测值为概率最大的值对应的xml标签元素index,通过一个字典得到index对应的标签元素内容。
遍历T中的每个标签元素,如果遇到终止符,则退出,遇到忽略值,则忽略。最终输出序列的xml列表和对应位置八点坐标。
后面会有文字检测文字识别结果和表格结果的匹配过程。这里暂时忽略。
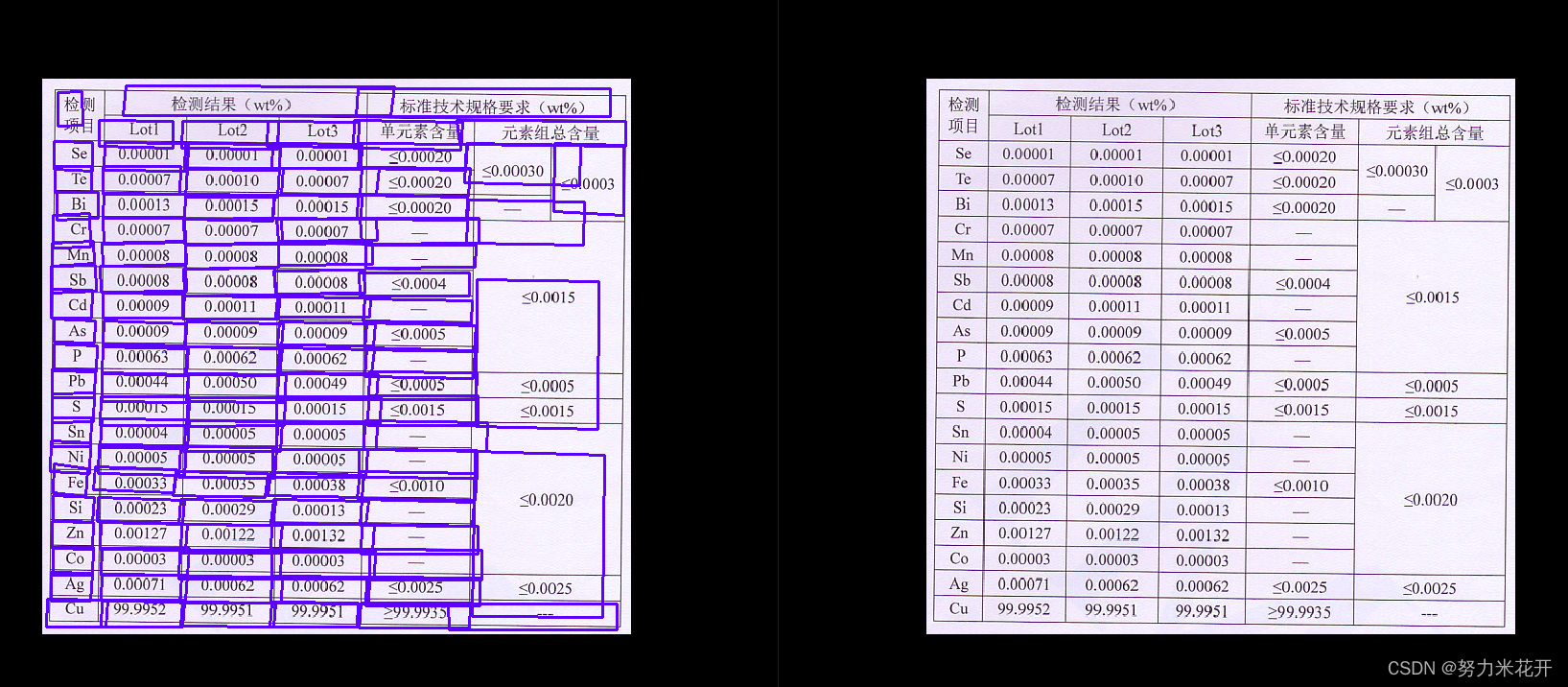
实际使用的效果
实际使用paddle给出的模型,会发现会与不存在很多跨行的表格图片,效果挺好的。但是对于发票这类图片以及一些稍微复杂一些的表格,效果并没有那么出色。还需要自行训练一下。
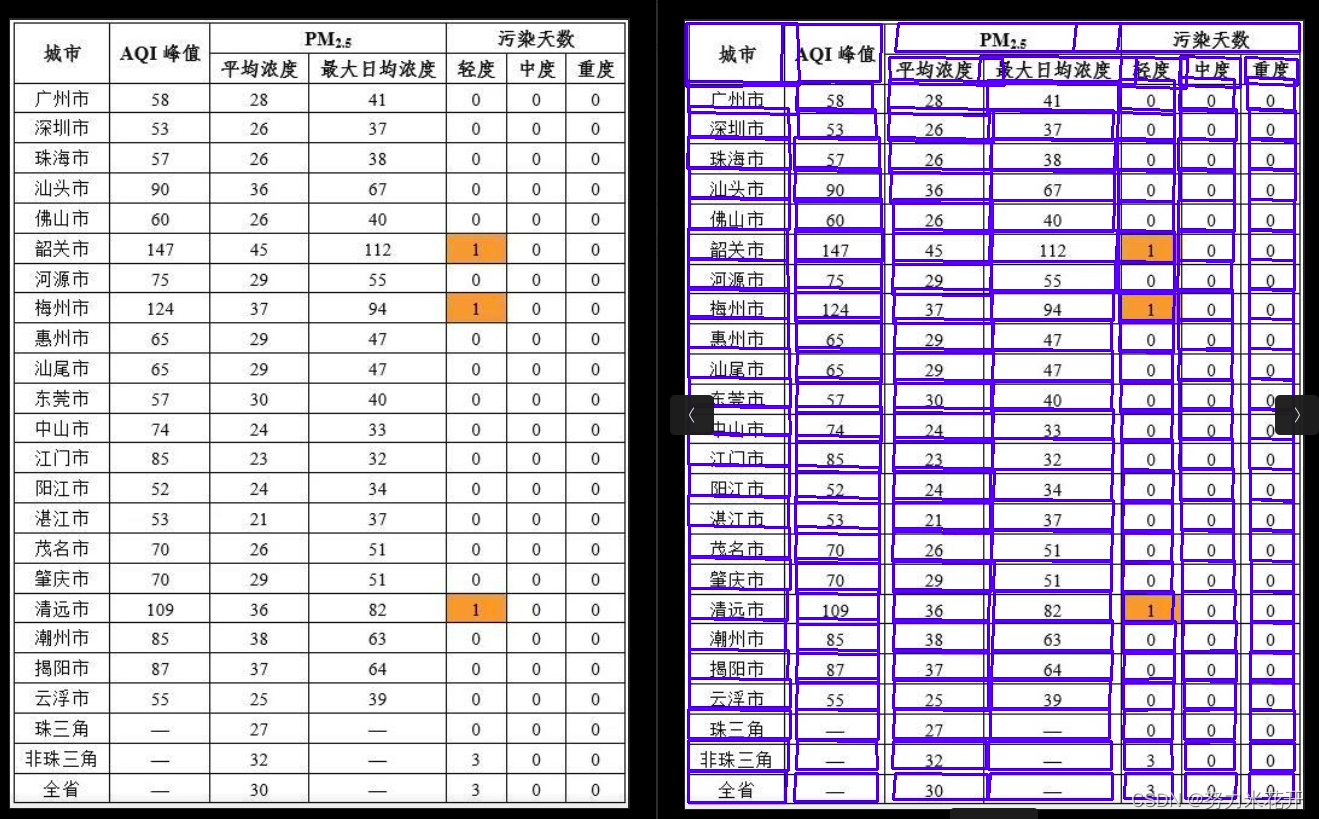
效果不佳的一些例子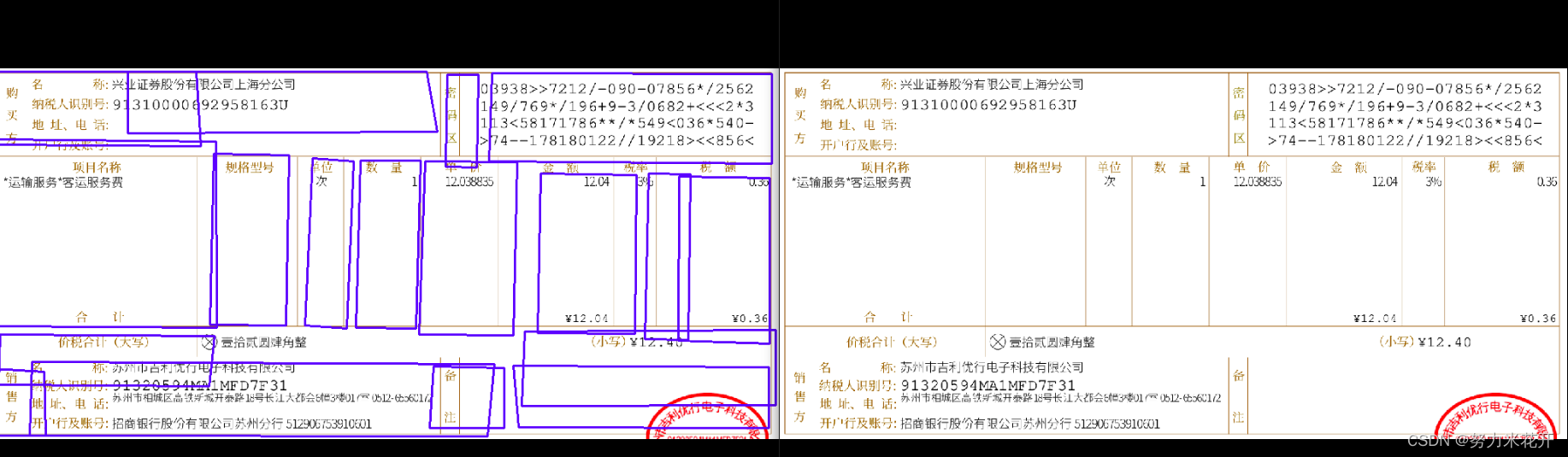
参考文章:
https://github.com/PaddlePaddle/PaddleOCR
文章出处登录后可见!