介绍
该模型是该团队在论文中提出的
通过
等在
, 而且它已经成为计算机领域的首选模式
目前
放弃序列结构
收养
–
该模型可以并行训练,并且可以充分利用训练材料的全局信息,并进行添加
该模型在所有任务中都得到了显著改进
. 本文制作了大量的图表,以便更清楚地说明该系统的工作原理
以及相关组件的操作细节。本文最后给出了完整的可运行代码示例。
注意机制
其核心机制是
–
.
–
该机制的本质来自人类视觉注意机制。当人们感知事物时,他们往往更关注场景中的突出物体。为了合理利用有限的视觉信息处理资源,人们需要选择视觉区域的特定部分,然后将注意力集中在它上。注意机制的主要目的是将注意权重分配给输入,即决定输入的哪个部分需要注意,并将有限的信息处理资源分配给重要部分。
Self-Attention
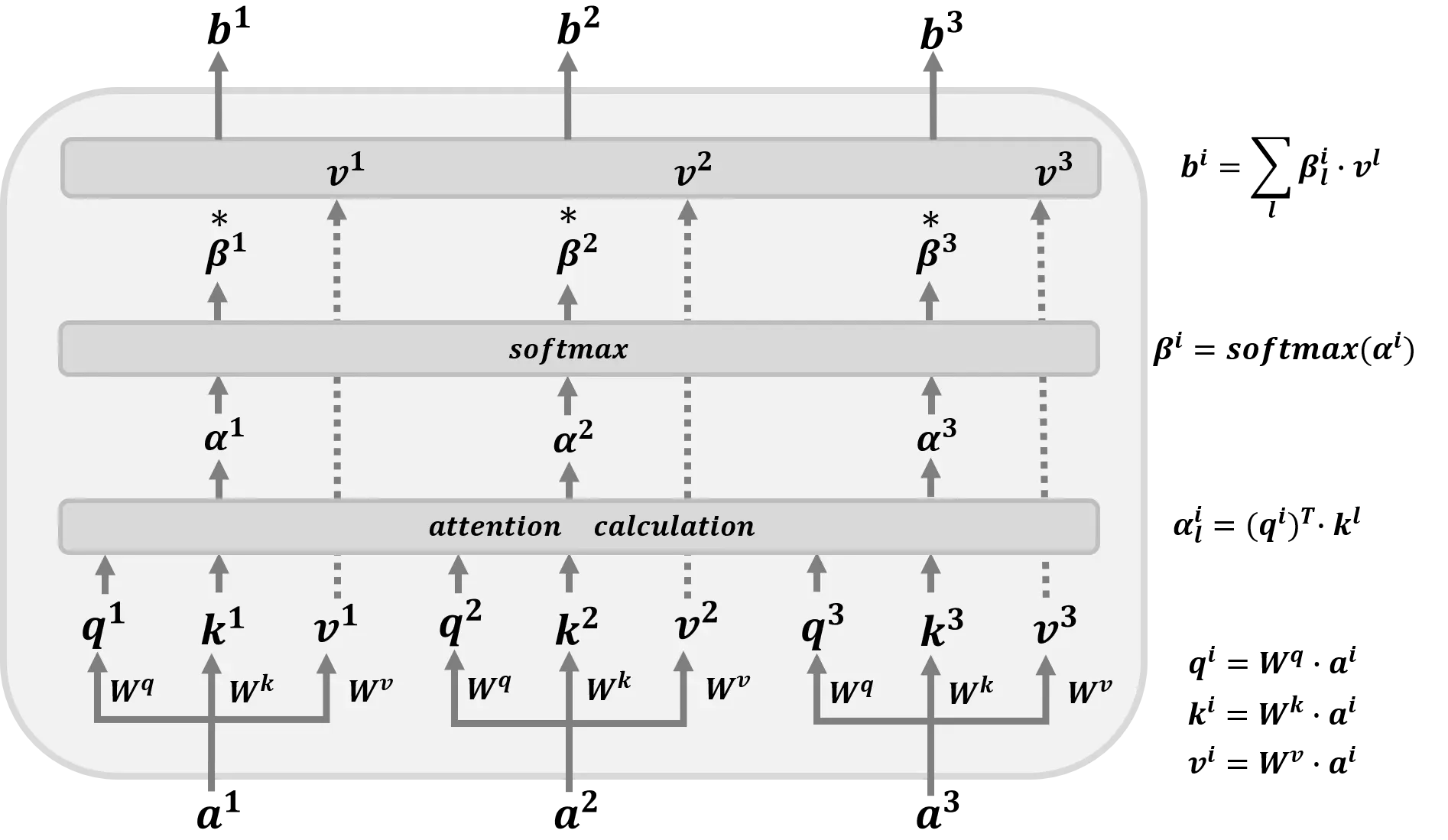
–
工作原理如上图所示。考虑到输入
矢量
然后对输入向量进行线性变换
通过矩阵
获得
矢量
,
矢量
和
矢量
, 即
如果矩阵
,
,
,
, 还有
然后获得了
向量和
向量用于计算注意力得分。本文使用的注意力计算公式是点积比例公式
本文假设
矢量
和
矢量
独立且相同分布,平均值为
差异是
, 此时
th分量
注意向量
是
以及方差的具体计算公式
详情如下
制作注意力得分矩阵
, 还有
注意力得分向量
获得标准化的注意力分布
经过
层,就是
最后使用得到的注意力分布向量
和
矩阵
以获得最终输出
(然后是
制作输出矩阵
, 有
Multi-Head Attention
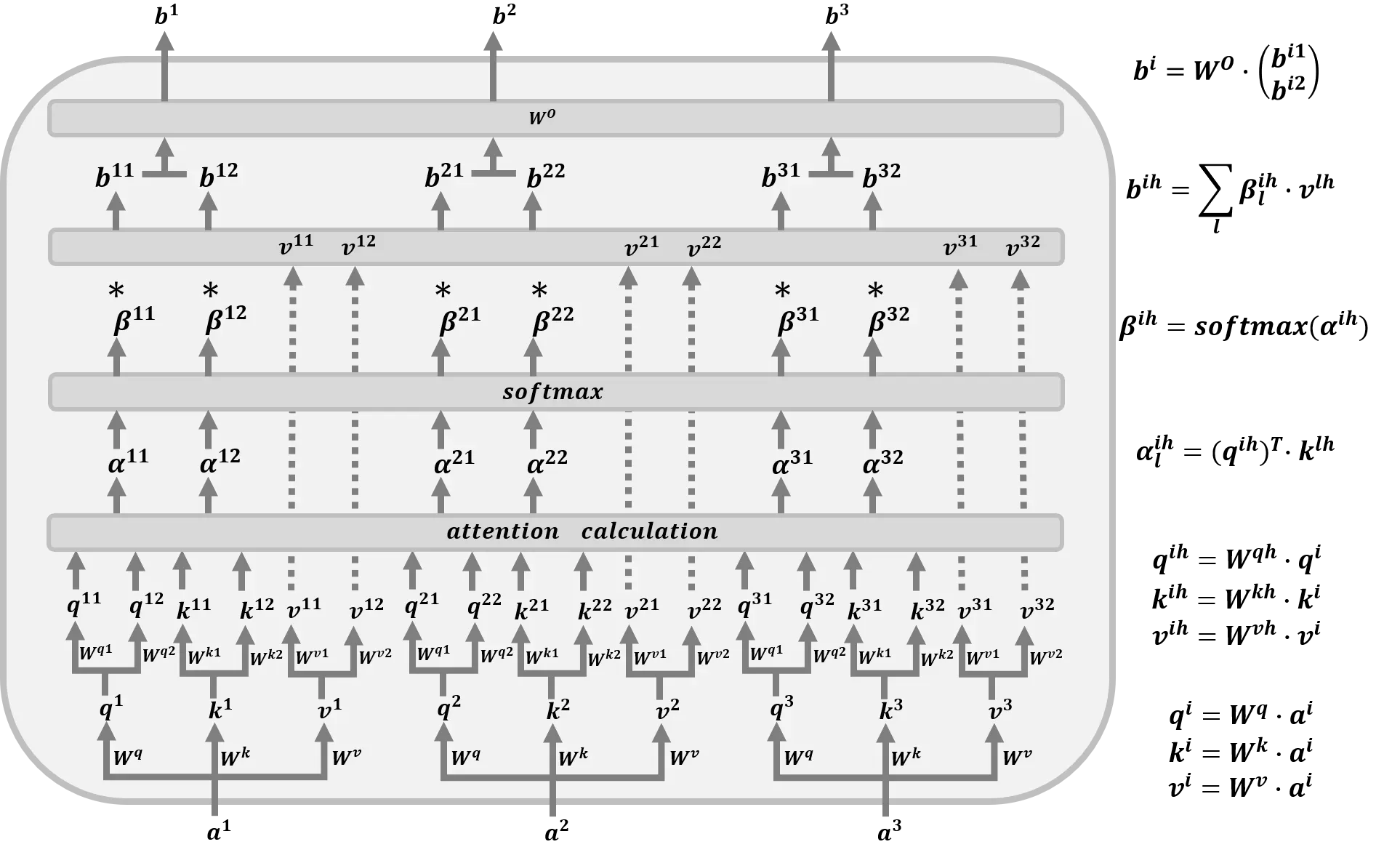
以下各项的工作原理:
非常类似于
–
. 为方便图形可视化,请设置
–
到
-. 如果
–
即将
–
, 然后
下一步中的分支数为
. 给出输入
矢量
然后对输入向量执行第一次线性变换
通过矩阵
获得
矢量
,
矢量
和
矢量
. 然后,通过矩阵对“向量”进行第二次线性变换“获得”和“类似地,通过矩阵对“向量”进行第二次线性变换”和“获得”和“和”,并通过对“向量”进行第二次线性变换“注意向量”⒲ 由公式计算⒲ 注意向量⒲, 哪里⒲ 注意向量之后⒲ 是标准化的,注意力向量⒲ 计算如下:,即
每人
使用获得的注意力分布向量
和
矩阵
以获得最终输出
还有
二
向量
按以下方式拼接在一起,则
给定参数矩阵
输出矩阵是
总而言之,有
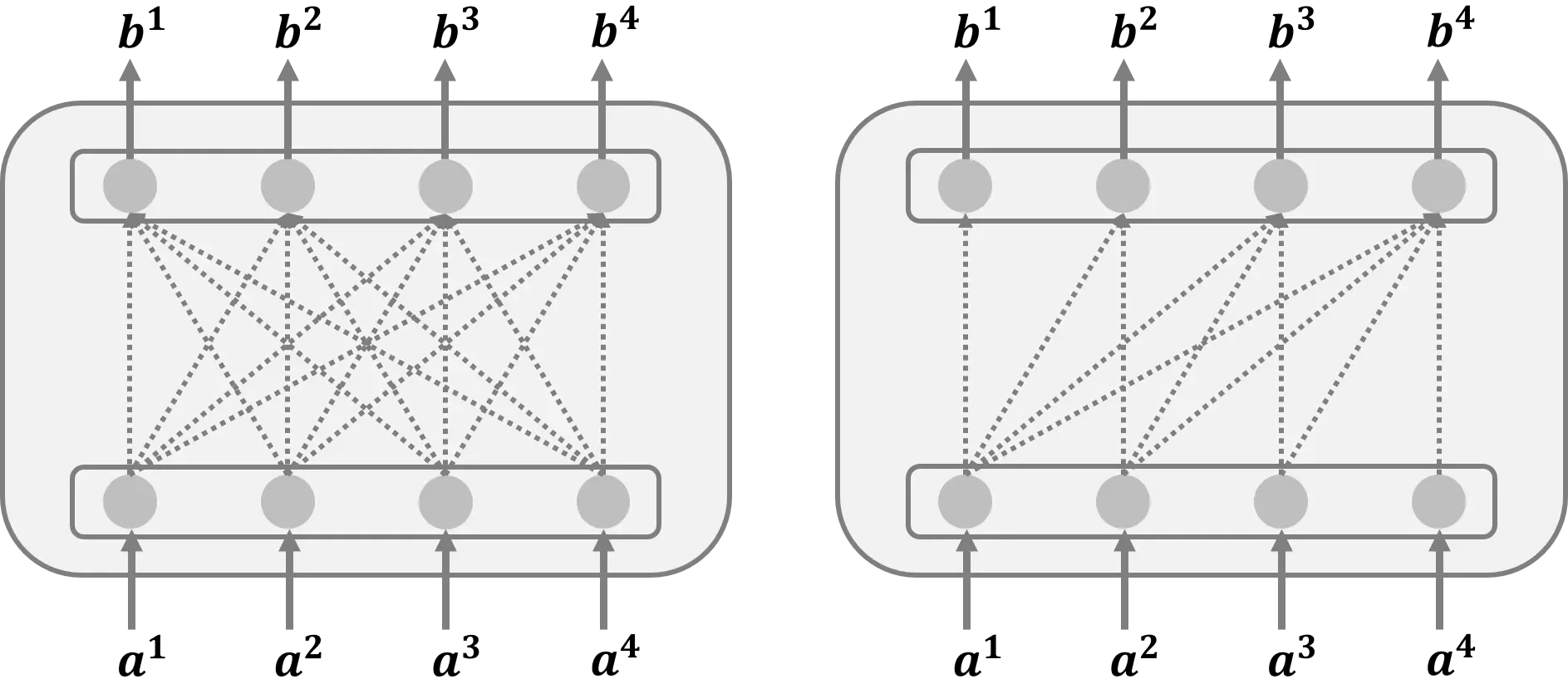
Mask Self-Attention
如下图左半部分所示,输出向量 属于
–
集成输入向量的所有信息
. 可以看出
–
支持实际编程中的并行操作。如下图右半部分所示,输出向量
–
仅使用输入向量的信息
关于已知的部分。例如
只与
;
关于
和
;
关于
,
和
;
关于
,
,
和
.
–
在英语中使用过两次
.
- 在里面
当然,如果
输入句子的长度小于指定的长度,它通常是用
为了使长度一致。此时,有必要使用
–
计算注意力分布。
- 输出
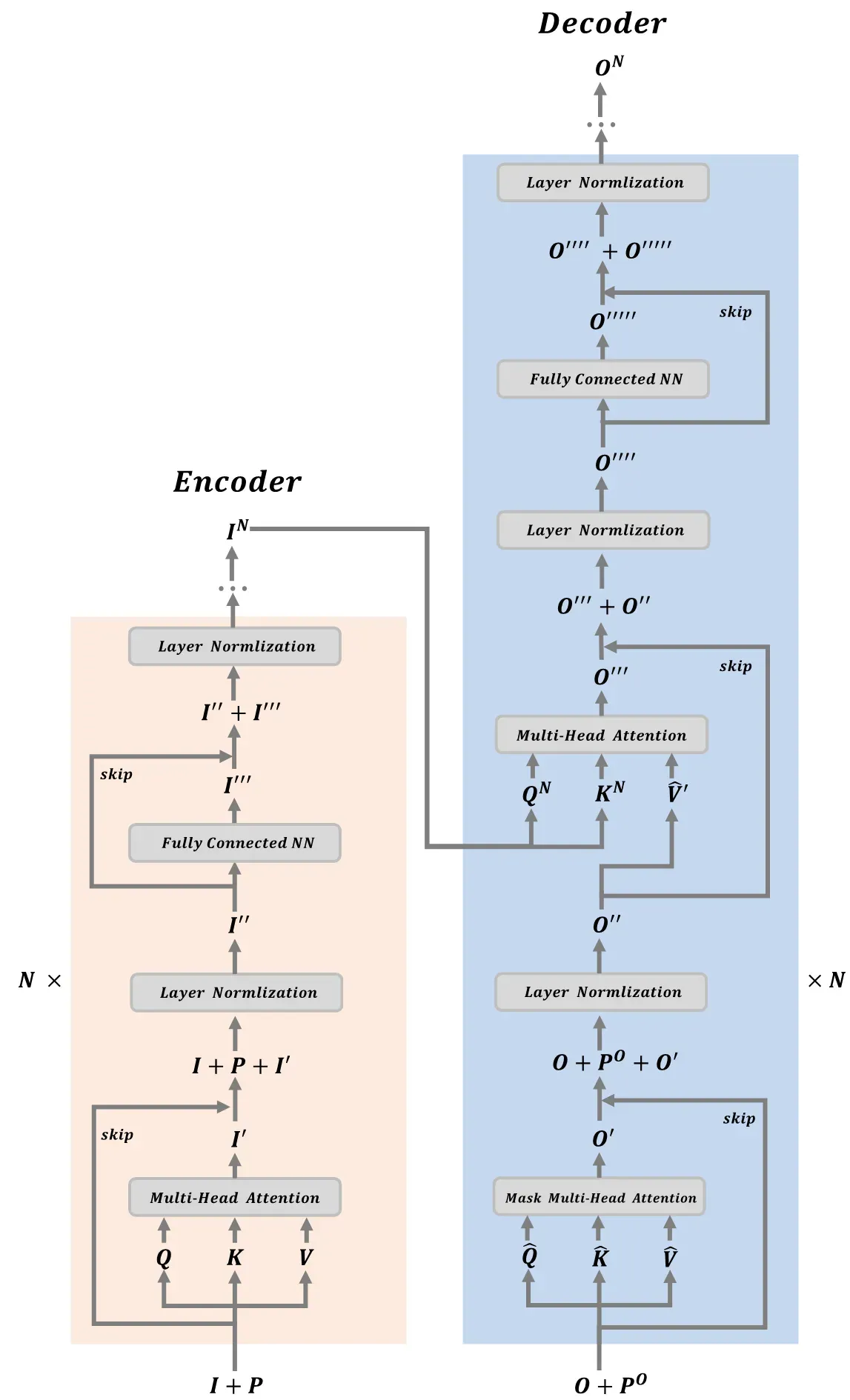
Transformer模型
其核心内容 上文详细剖析了自我注意机制,然后
将介绍模型架构。
该模型由以下部分组成:
和
模块。具体示意图如下。以显示内部操作的详细信息
更清楚地说,下图解释了
从矩阵运算的角度。
模块操作的具体过程如下:
- 输入由两部分组成:文字编码矩阵
位置编码矩阵
, 哪里
表示句子的数量,
表示句子中的最大字数,以及
表示单词向量的维数。位置编码矩阵
表示句子中每个单词的所有位置信息,因为
–
根据单词在句子中的位置进行位置编码;另一种方法是将位置编码作为训练和学习的参数;本文用三角函数对位置进行编码。具体公式如下:
哪里
表示位置编码向量,
表示单词在句子中的位置,以及
表示编码向量的位置索引。
- 输入矩阵
生成矩阵
,
,
, 通过线性变换。在实际编程中,输入
应相应地引入矩阵。
- 输入矩阵
–
模块计算注意力分布以获得矩阵
, 计算公式为
具体计算详见
.
- 在矩阵上执行层规范化
获得
, 具体计算公式如下:
- 输入
输入到完全连接的神经网络中,得到(,然后计算输入之间的残差
对完全连接的神经网络进行分层归一化
.
- 以上是a的工作原理
模块,该模块由
堆叠模块
模块操作的具体过程如下:
- 输入也由两部分组成:文字编码矩阵
位置编码矩阵
. 因为
具有时序关系(即前一步的输出是当前步的输入),也需要输入
计算注意力分布。
- 输入矩阵
生成矩阵
,
, 通过线性变换。在实际编程中,输入
,
- 输入矩阵
–
, 计算公式为
有关具体计算细节,请参阅
–
获得输出矩阵
. 然后,对矩阵执行层规范化
获得
.
- 输出
是通过线性变换得到的
和
, “通过线性变换获得
, 利用矩阵计算交叉注意分布
这里的交叉注意力分布综合了输出结果和中间结果的信息。在实际编程中,
并通过注意力分布表得到输出矩阵
- 然后
- 以上是a的工作原理
代码示例
具体的代码示例如下所示为一个国外博主视频里的代码,并根据上文对代码的一些细节进行了探讨。根据上文中
–
原理示例图可知,严格来看
–
在求注意分布的时候中间其实是有两步线性变换。给定输入向量
第一步线性变换直接让向量
赋值给
,
,
,这一过程以下程序中有所体现,在这里并不会产生歧义。第二步线性变换产生多
,假设
的时候,按理说
要与
个矩阵
进行线性变换得到
个
,同理
要与
个矩阵
进行线性变换得到
个
,
要与
个矩阵
进行线性变换得到
个
,如果按照这个方式在程序实现则需要定义24个权重矩阵,非常的麻烦。以下程序中有一个简单的权重定义方法,通过该方法也可以实现以上多
的线性变换,以向量
为例:
- 首先,向量
被截断并分为
向量,就是
哪里
是吗
是单位矩阵和
- 然后对其执行线性变换
使用相同的权重矩阵
此时,可以发现,在训练过程中,只有权重矩阵
需要更新,多个
可以进行线性变换,
权重矩阵可以表示为:
权重矩阵在哪里
.
import torch
import torch.nn as nn
import os
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (self.head_dim * heads == embed_size), "Embed size needs to be p by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N =query.shape[0]
value_len , key_len , query_len = values.shape[1], keys.shape[1], query.shape[1]
# split embedding into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum("nqhd,nkhd->nhqk", queries, keys)
# queries shape: (N, query_len, heads, heads_dim)
# keys shape : (N, key_len, heads, heads_dim)
# energy shape: (N, heads, query_len, key_len)
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy/ (self.embed_size ** (1/2)), dim=3)
out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim)
# attention shape: (N, heads, query_len, key_len)
# values shape: (N, value_len, heads, heads_dim)
# (N, query_len, heads, head_dim)
out = self.fc_out(out)
return out
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion*embed_size),
nn.ReLU(),
nn.Linear(forward_expansion*embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class Encoder(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
return out
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm = nn.LayerNorm(embed_size)
self.transformer_block = TransformerBlock(
embed_size, heads, dropout, forward_expansion
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, value, key, src_mask, trg_mask):
attention = self.attention(x, x, x, trg_mask)
query = self.dropout(self.norm(attention + x))
out = self.transformer_block(value, key, query, src_mask)
return out
class Decoder(nn.Module):
def __init__(
self,
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
):
super(Decoder, self).__init__()
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[DecoderBlock(embed_size, heads, forward_expansion, dropout, device)
for _ in range(num_layers)]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x ,enc_out , src_mask, trg_mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
out =self.fc_out(x)
return out
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size = 256,
num_layers = 6,
forward_expansion = 4,
heads = 8,
dropout = 0,
device="cuda",
max_length=100
):
super(Transformer, self).__init__()
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length
)
self.decoder = Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length
)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# (N, 1, 1, src_len)
return src_mask.to(self.device)
def make_trg_mask(self, trg):
N, trg_len = trg.shape
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
out = self.decoder(trg, enc_src, src_mask, trg_mask)
return out
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
x = torch.tensor([[1,5,6,4,3,9,5,2,0],[1,8,7,3,4,5,6,7,2]]).to(device)
trg = torch.tensor([[1,7,4,3,5,9,2,0],[1,5,6,2,4,7,6,2]]).to(device)
src_pad_idx = 0
trg_pad_idx = 0
src_vocab_size = 10
trg_vocab_size = 10
model = Transformer(src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx, device=device).to(device)
out = model(x, trg[:, : -1])
print(out.shape)
版权声明:本文为博主鬼道2022原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_38406029/article/details/122050257