内容
- 前言
- 0、导入需要的包
- 1、fitness
- 2、ap_per_class、compute_ap
- 2.1、ap_per_class
- 2.2、compute_ap
- 3、ConfusionMatrix
- 4、bbox_iou
- 5、box_iou
- 6、wh_iou
- 7、plot_pr_curve
- 8、plot_mc_curve
- 总结
前言
源码:YOLOv5源码.
导航:【YOLOV5-5.x 源码讲解】整体项目文件导航.
注释版全部项目文件已上传至GitHub:yolov5-5.x-annotations.
这个文件存放的是计算mAP、混淆矩阵、IOU相关的函数,在看之前需要大家了解基本的目标检测指标,mAP的定义,计算方式等知识。相对来说这个文件的代码难度还是相对挺高的,需要不断的debug,debug,debug!
0、导入需要的包
import math # 数学函数模块
import warnings # 发出警告
from pathlib import Path # Path将str转换为Path对象 使字符串路径易于操作的模块
import matplotlib.pyplot as plt # matplotlib画图模块
import numpy as np # numpy数组操作模块
import torch # pytorch框架
1、fitness
这个函数是用来通过指标加权的形式求出最终的mAP,用这个mAP作为模型好坏的标准。
fitness函数代码:
def fitness(x):
"""通过指标加权的形式返回适应度(最终mAP) 在train.py中使用
Model fitness as a weighted combination of metrics
判断模型好坏的指标不是mAP@0.5也不是mAP@0.5:0.95 而是[P, R, mAP@0.5, mAP@0.5:0.95]4者的加权
一般w=[0,0,0.1,0.9] 即最终的mAP=0.1mAP@0.5 + 0.9mAP@0.5:0.95
"""
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
# (torch.tensor).sum(1) 每一行求和tensor为二维时返回一个以每一行求和为结果(常数)的行向量
return (x[:, :4] * w).sum(1)
一般会在train.py中调用来衡量模型的好坏:
2、ap_per_class、compute_ap
这两个函数是用来计算每个类在各个IOU阈值下的mAP的,代码还是比较复杂的,有些花里胡哨的矩阵操作。要想读懂下面两个函数首先要理解目标检测的一些基本指标:b站大佬:目标检测mAP计算以及coco评价标准。还可以再看下这个知乎提问:目标检测中的mAP是什么含义?。其次还要先理解这几个复杂的python/numpy操作:【python numpy】a.cumsum()、np.interp()、np.maximum.accumulate()、np.trapz().
mAP计算流程
- 前向传播 + NMS
- 选出每个类别的correct(TP)
- 将上述选中的所有类的TP按照conf降序排列
- for 每个类 :
1、计算这个类的Recall 和 Precision
2、for 每个iou阈值 计算该类别下每一个iou阈值(0.5~0.95 10个)下的mAP(调用compute_ap函数)

两种mAP计算方式
这里实现了两种mAP的计算方法:
- interp: 101-point interpolation
- continuous: Interpolating all points
具体的可以看:github 源码readme解释
没有vpn的也可以看这篇博文:详解对象检测网络性能评价指标mAP计算
2.1、ap_per_class
这个函数用于计算每一个类在10个IOU阈值下的AP指标(average precision) 绘制P-R、P-conf、R-conf、F1-conf曲线等。
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=()):
"""用于val.py中计算每个类的mAP
计算每一个类的AP指标(average precision)还可以 绘制P-R曲线
mAP基本概念: https://www.bilibili.com/video/BV1ez4y1X7g2
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
:params tp(correct): [pred_sum, 10]=[1905, 10] bool 整个数据集所有图片中所有预测框在每一个iou条件下(0.5~0.95)10个是否是TP
:params conf: [img_sum]=[1905] 整个数据集所有图片的所有预测框的conf
:params pred_cls: [img_sum]=[1905] 整个数据集所有图片的所有预测框的类别
这里的tp、conf、pred_cls是一一对应的
:params target_cls: [gt_sum]=[929] 整个数据集所有图片的所有gt框的class
:params plot: bool
:params save_dir: runs\train\exp30
:params names: dict{key(class_index):value(class_name)} 获取数据集所有类别的index和对应类名
:return p[:, i]: [nc] 最大平均f1时每个类别的precision
:return r[:, i]: [nc] 最大平均f1时每个类别的recall
:return ap: [71, 10] 数据集每个类别在10个iou阈值下的mAP
:return f1[:, i]: [nc] 最大平均f1时每个类别的f1
:return unique_classes.astype('int32'): [nc] 返回数据集中所有的类别index
"""
# 计算mAP 需要将tp按照conf降序排列
# Sort by objectness 按conf从大到小排序 返回数据对应的索引
i = np.argsort(-conf)
# 得到重新排序后对应的 tp, conf, pre_cls
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes 对类别去重, 因为计算ap是对每类进行
unique_classes = np.unique(target_cls)
nc = unique_classes.shape[0] # 数据集类别数 number of classes
# Create Precision-Recall curve and compute AP for each class
# px: [0, 1] 中间间隔1000个点 x坐标(用于绘制P-Conf、R-Conf、F1-Conf)
# py: y坐标[] 用于绘制IOU=0.5时的PR曲线
px, py = np.linspace(0, 1, 1000), [] # for plotting
# 初始化 对每一个类别在每一个IOU阈值下 计算AP P R ap=[nc, 10] p=[nc, 1000] r=[nc, 1000]
ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
for ci, c in enumerate(unique_classes): # ci: index 0 c: class 0 unique_classes: 所有gt中不重复的class
# i: 记录着所有预测框是否是c类别框 是c类对应位置为True, 否则为False
i = pred_cls == c
# n_l: gt框中的c类别框数量 = tp+fn 254
n_l = (target_cls == c).sum() # number of labels
# n_p: 预测框中c类别的框数量 695
n_p = i.sum() # number of predictions
# 如果没有预测到 或者 ground truth没有标注 则略过类别c
if n_p == 0 or n_l == 0:
continue
else:
# Accumulate FPs(False Positive) and TPs(Ture Positive) FP + TP = all_detections
# tp[i] 可以根据i中的的True/False觉定是否删除这个数 所有tp中属于类c的预测框
# 如: tp=[0,1,0,1] i=[True,False,False,True] b=tp[i] => b=[0,1]
# a.cumsum(0) 会按照对象进行累加操作
# 一维按行累加如: a=[0,1,0,1] b = a.cumsum(0) => b=[0,1,1,2] 而二维则按列累加
# fpc: 类别为c 顺序按置信度排列 截至到每一个预测框的各个iou阈值下FP个数 最后一行表示c类在该iou阈值下所有FP数
# tpc: 类别为c 顺序按置信度排列 截至到每一个预测框的各个iou阈值下TP个数 最后一行表示c类在该iou阈值下所有TP数
fpc = (1 - tp[i]).cumsum(0) # fp[i] = 1 - tp[i]
tpc = tp[i].cumsum(0)
# Recall=TP/(TP+FN) 加一个1e-16的目的是防止分母为0
# n_l=TP+FN=num_gt: c类的gt个数=预测是c类而且预测正确+预测不是c类但是预测错误
# recall: 类别为c 顺序按置信度排列 截至每一个预测框的各个iou阈值下的召回率
recall = tpc / (n_l + 1e-16) # recall curve 用于计算mAP
# 返回所有类别, 横坐标为conf(值为px=[0, 1, 1000] 0~1 1000个点)对应的recall值 r=[nc, 1000] 每一行从小到大
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # 用于绘制R-Confidence(R_curve.png)
# Precision=TP/(TP+FP)
# precision: 类别为c 顺序按置信度排列 截至每一个预测框的各个iou阈值下的精确率
precision = tpc / (tpc + fpc) # precision curve 用于计算mAP
# 返回所有类别, 横坐标为conf(值为px=[0, 1, 1000] 0~1 1000个点)对应的precision值 p=[nc, 1000]
# 总体上是从小到大 但是细节上有点起伏 如: 0.91503 0.91558 0.90968 0.91026 0.90446 0.90506
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # 用于绘制P-Confidence(P_curve.png)
# AP from recall-precision curve
# 对c类别, 分别计算每一个iou阈值(0.5~0.95 10个)下的mAP
for j in range(tp.shape[1]): # tp [pred_sum, 10]
# 这里执行10次计算ci这个类别在所有mAP阈值下的平均mAP ap[nc, 10]
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
if plot and j == 0:
py.append(np.interp(px, mrec, mpre)) # py: 用于绘制每一个类别IOU=0.5时的PR曲线
# 计算F1分数 P和R的调和平均值 综合评价指标
# 我们希望的是P和R两个越大越好, 但是P和R常常是两个冲突的变量, 经常是P越大R越小, 或者R越大P越小 所以我们引入F1综合指标
# 不同任务的重点不一样, 有些任务希望P越大越好, 有些任务希望R越大越好, 有些任务希望两者都大, 这时候就看F1这个综合指标了
# 返回所有类别, 横坐标为conf(值为px=[0, 1, 1000] 0~1 1000个点)对应的f1值 f1=[nc, 1000]
f1 = 2 * p * r / (p + r + 1e-16) # 用于绘制P-Confidence(F1_curve.png)
if plot:
plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names) # 画pr曲线
plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1') # 画F1_conf曲线
plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision') # 画P_conf曲线
plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall') # 画R_conf曲线
# f1=[nc, 1000] f1.mean(0)=[1000]求出所有类别在x轴每个conf点上的平均f1
# .argmax(): 求出每个点平均f1中最大的f1对应conf点的index
i = f1.mean(0).argmax() # max F1 index
# p=[nc, 1000] 每个类别在x轴每个conf值对应的precision
# p[:, i]: [nc] 最大平均f1时每个类别的precision
# r[:, i]: [nc] 最大平均f1时每个类别的recall
# f1[:, i]: [nc] 最大平均f1时每个类别的f1
# ap: [71, 10] 数据集每个类别在10个iou阈值下的mAP
# unique_classes.astype('int32'): [nc] 返回数据集中所有的类别index
return p[:, i], r[:, i], ap, f1[:, i], unique_classes.astype('int32')
这个函数会在val.py调用: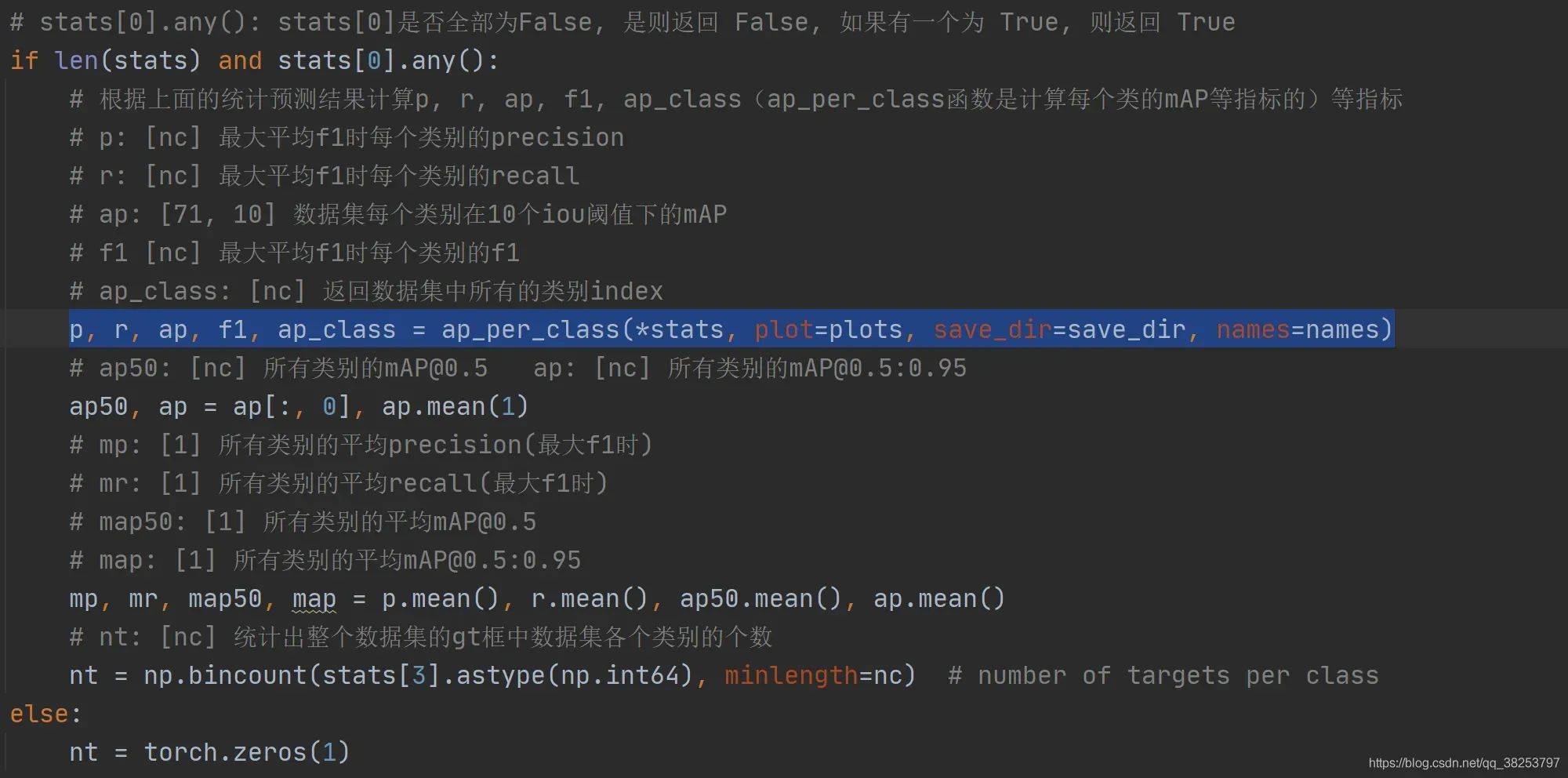
2.2、compute_ap
这个函数用于计算某个类别在某个iou阈值下的mAP。在上面的ap_per_class函数中被调用。
def compute_ap(recall, precision):
"""用于ap_per_class函数中
计算某个类别在某个iou阈值下的mAP
Compute the average precision, given the recall and precision curves
:params recall: (list) [1635] 在某个iou阈值下某个类别所有的预测框的recall 从小到大
(每个预测框的recall都是截至到这个预测框为止的总recall)
:params precision: (list) [1635] 在某个iou阈值下某个类别所有的预测框的precision
总体上是从大到小 但是细节上有点起伏 如: 0.91503 0.91558 0.90968 0.91026 0.90446 0.90506
(每个预测框的precision都是截至到这个预测框为止的总precision)
:return ap: Average precision 返回某类别在某个iou下的mAP(均值) [1]
:return mpre: precision curve [1637] 返回 开头 + 输入precision(排序后) + 末尾
:return mrec: recall curve [1637] 返回 开头 + 输入recall + 末尾
"""
# 在开头和末尾添加保护值 防止全零的情况出现 value Append sentinel values to beginning and end
mrec = np.concatenate(([0.], recall, [recall[-1] + 0.01])) # [1637]
mpre = np.concatenate(([1.], precision, [0.])) # [1637]
# Compute the precision envelope np.flip翻转顺序
# np.flip(mpre): 把一维数组每个元素的顺序进行翻转 第一个翻转成为最后一个
# np.maximum.accumulate(np.flip(mpre)): 计算数组(或数组的特定轴)的累积最大值 令mpre是单调的 从小到大
# np.flip(np.maximum.accumulate(np.flip(mpre))): 从大到小
# 到这大概看明白了这步的目的: 要保证mpre是从大到小单调的(左右可以相同)
# 我觉得这样可能是为了更好计算mAP 因为如果一直起起伏伏太难算了(x间隔很小就是一个矩形) 而且这样做误差也不会很大 两个之间的数都是间隔很小的
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# Integrate area under curve
method = 'interp' # methods: 'continuous', 'interp'
if method == 'interp': # 用一些典型的间断点来计算AP
x = np.linspace(0, 1, 101) # 101-point interp (COCO) [0, 0.01, ..., 1]
# np.trapz(list,list) 计算两个list对应点与点之间四边形的面积 以定积分形式估算AP 第一个参数是y 第二个参数是x
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
else: # 'continuous' # 采用连续的方法计算AP
# 通过错位的方式 判断哪个点当前位置到下一个位置值发生改变 并通过!=判断 返回一个布尔数组
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
# 值改变了就求出当前矩阵的面积 值没变就说明当前矩阵和下一个矩阵的高相等所有可以合并计算
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
return ap, mpre, mrec
3、ConfusionMatrix
这个代码的官方解释关于TP、FP、FN的解释和我学到的理解不一样,不知道为什么?比如TP不是应该是Positvie(iou>threshold) 而且还检测正确(pred class=gt class)才可以吗,它这里iou>threshold就是TP,不是很奇怪吗?所以关于这部分代码的理解只是我个人的理解,如果有任何不同的意见欢迎下面讨论。

ConfusionMatrix函数代码:
class ConfusionMatrix:
"""用在val.py中计算混淆矩阵
Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
混淆矩阵: 定义 更新 return 绘制 print打印
"""
def __init__(self, nc, conf=0.25, iou_thres=0.45): # 个人觉得这里iou_thres应该改成0.5(和后面计算mAP对应)
"""
params nc: 数据集类别个数
params conf: 预测框置信度阈值
Params iou_thres: iou阈值
"""
# 初始化混淆矩阵 pred x gt 其中横坐标/纵坐标第81类为背景类
# 如果某个gt[j]没用任何pred正样本匹配到 那么[nc, gt[j]_class] += 1
# 如果某个pred[i]负样本且没有哪个gt与之对应 那么[pred[i]_class nc] += 1
self.matrix = np.zeros((nc + 1, nc + 1))
self.nc = nc # number of classes
self.conf = conf
self.iou_thres = iou_thres
def process_batch(self, detections, labels):
"""
:params detections: [N, 6] = [pred_obj_num, x1y1x2y2+object_conf+cls] = [300, 6]
一个batch中一张图的预测信息 其中x1y1x2y2是映射到原图img的
:params labels: [M, 5] = [gt_num, class+x1y1x2y2] = [17, 5] 其中x1y1x2y2是映射到原图img的
:return: None, updates confusion matrix accordingly
"""
# [10, 6] 筛除置信度过低的预测框(和nms差不多)
detections = detections[detections[:, 4] > self.conf]
gt_classes = labels[:, 0].int() # 所有gt框类别(int) [17] 类别可能会重复
detection_classes = detections[:, 5].int() # 所有pred框类别(int) [10] 类别可能会重复 Positive + Negative
# 求出所有gt框和所有pred框的iou [17, x1y1x2y2] + [10, x1y1x2y2] => [17, 10] [i, j] 第i个gt框和第j个pred的iou
iou = box_iou(labels[:, 1:], detections[:, :4])
# iou > self.iou_thres: [17, 10] bool 符合条件True 不符合False
# x[0]: [10] gt_index x[1]: [10] pred_index x合起来看就是第x[0]个gt框和第x[1]个pred的iou符合条件
# 17 x 10个iou 经过iou阈值筛选后只有10个满足iou阈值条件
x = torch.where(iou > self.iou_thres)
# 后面会专门对这里一连串的matches变化给个实例再解释
if x[0].shape[0]: # 存在大于阈值的iou时
# torch.stack(x, 1): [10, gt_index+pred_index]
# iou[x[0], x[1]][:, None]): [10, 1] x[0]和x[1]的iou
# 1、matches: [10, gt_index+pred_index+iou] = [10, 3]
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
if x[0].shape[0] > 1:
# 2、matches按第三列iou从大到小重排序
matches = matches[matches[:, 2].argsort()[::-1]]
# 3、取第二列中各个框首次出现(不同预测的框)的行(即每一种预测的框中iou最大的那个)
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
# 4、matches再按第三列iou从大到小重排序
matches = matches[matches[:, 2].argsort()[::-1]]
# 5、取第一列中各个框首次出现(不同gt的框)的行(即每一种gt框中iou最大的那个)
matches = matches[np.unique(matches[:, 0], return_index=True)[1]] # [9, gt_index+pred_index+iou]
# 经过这样的处理 最终得到每一种预测框与所有gt框中iou最大的那个(在大于阈值的前提下)
# 预测框唯一 gt框也唯一 这样得到的matches对应的Pred都是正样本Positive
else:
matches = np.zeros((0, 3))
n = matches.shape[0] > 0 # 满足条件的iou是否大于0个 bool
# a.transpose(): 转换维度 对二维数组就是转置 这里的matches: [9, gt_index+pred_index+iou] -> [gt_index+pred_index+iou, 9]
# m0: [1, 9] 满足条件(正样本)的gt框index(不重复) m1: [1, 9] 满足条件(正样本)的pred框index(不重复)
m0, m1, _ = matches.transpose().astype(np.int16)
for i, gc in enumerate(gt_classes):
j = m0 == i
if n and sum(j) == 1:
# 如果sum(j)=1 说明gt[i]这个真实框被某个预测框检测到了 但是detection_classes[m1[j]]并不一定等于gc 所以此时可能是TP或者是FP
# m1[j]: gt框index=i时, 满足条件的pred框index detection_classes[m1[j]]: pred_class_index
# gc: gt_class_index matrix[pred_class_index,gt_class_index] += 1
self.matrix[detection_classes[m1[j]], gc] += 1 # TP + FP 某个gt检测到了 但是有可能分类分错了 也有可能分类分对了
else:
# 如果sum(j)=0 说明gt[i]这个真实框没用被任何预测框检测到 也就是说这个真实框被检测成了背景框
# 所以对应的混淆矩阵 [背景类, gc] += 1 其中横坐标第81类是背景background
self.matrix[self.nc, gc] += 1 # background FP +1 某个gt没检测到 被检测为background了
if n:
for i, dc in enumerate(detection_classes):
if not any(m1 == i):
# detection_classes - matrix[1] = negative 且没用对应的gt和negative相对应 所以background FN+1
self.matrix[dc, self.nc] += 1 # background FN
def matrix(self):
# 返回这个混淆矩阵
return self.matrix
def plot(self, normalize=True, save_dir='', names=()):
"""
:params normalize: 是否将混淆矩阵归一化 默认True
:params save_dir: runs/train/expn 混淆矩阵保存地址
:params names: 数据集的所有类别名
:return None
"""
try:
import seaborn as sn # seaborn 为matplotlib可视化更好看的一个模块
array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-6) if normalize else 1) # 混淆矩阵归一化 0~1
array[array < 0.005] = np.nan # 混淆矩阵中小于0.005的值被认为NaN
fig = plt.figure(figsize=(12, 9), tight_layout=True) # 初始化画布
sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # 设置label的字体大小
labels = (0 < len(names) < 99) and len(names) == self.nc # 绘制混淆矩阵时 是否使用names作为labels
# 绘制热力图 即混淆矩阵可视化
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
# sean.heatmap: 热力图 data: 数据矩阵 annot: 为True时为每个单元格写入数据值 False用颜色深浅表示
# annot_kws: 格子外框宽度 fmt: 添加注释时要使用的字符串格式代码 cmap: 指色彩颜色的选择
# square: 是否是正方形 xticklabels、yticklabels: xy标签
sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
xticklabels=names + ['background FP'] if labels else "auto",
yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
# 设置figure的横坐标 纵坐标及保存该图片
fig.axes[0].set_xlabel('True')
fig.axes[0].set_ylabel('Predicted')
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
except Exception as e:
print(f'WARNING: ConfusionMatrix plot failure: {e}')
def print(self):
# print按行输出打印混淆矩阵matrix
for i in range(self.nc + 1):
print(' '.join(map(str, self.matrix[i])))
注意一:【关于上述四步matches处理的详细解释】
1、cat gt_index+pred_index+iou
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()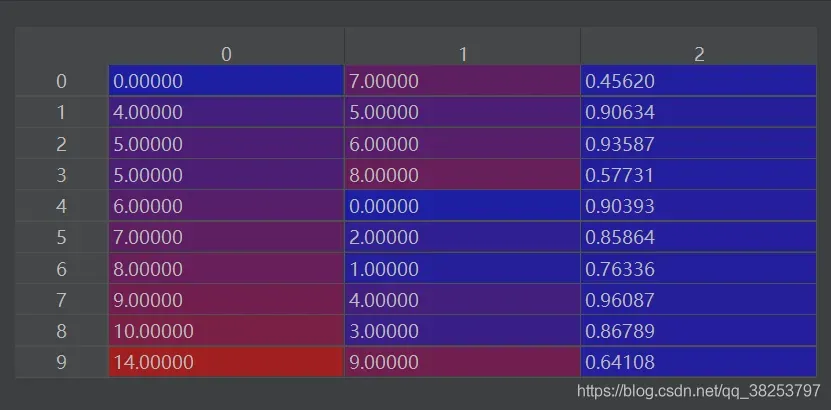
2. 按第三列iou从大到小重排序
matches = matches[matches[:, 2].argsort()[::-1]]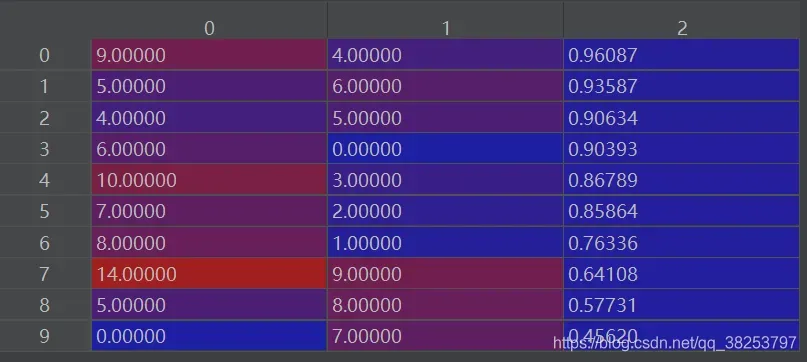
3. 按顺序取第二列中各个框首次出现(不同预测的框)的行(即每一种预测的框中iou最大的那个)
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]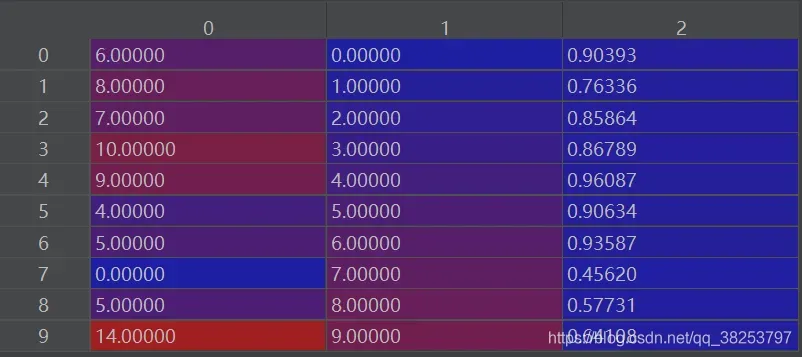
4. matches再按第三列iou从大到小重排序
matches = matches[matches[:, 2].argsort()[::-1]]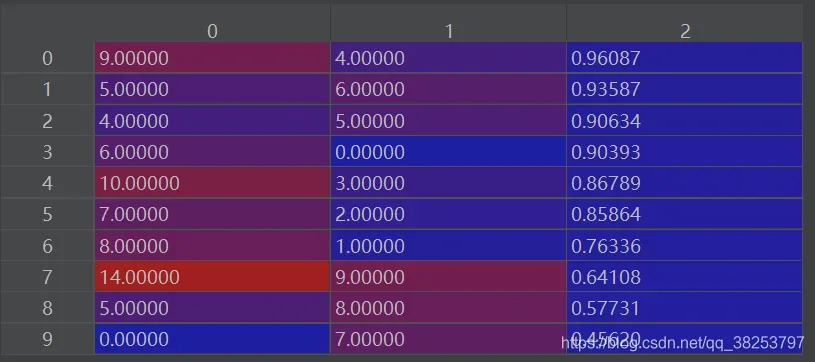
5.按顺序取第一列中各个框首次出现(不同gt的框)的行(即每一种gt框中iou最大的那个)
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]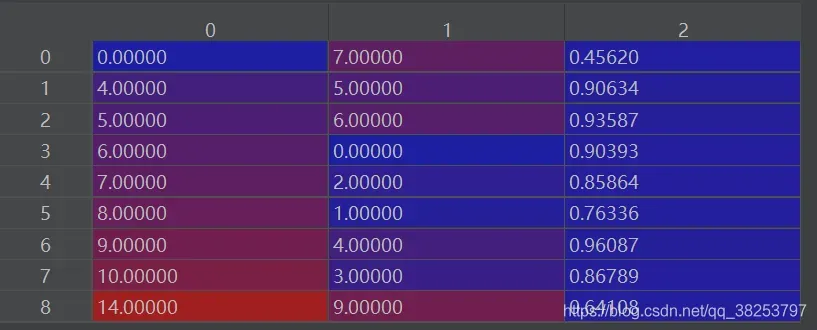
经过这5步处理 最终得到每一种预测框与所有gt框中iou最大的那个 可以看到gt框是唯一的 预测框也是唯一的
个人认为这一步得到的matches对应的pred都是Positvie 而之前的置信度筛选得到的detections是Postive + Negative.
注意二:【TP 、 FP的选择】
self.matrix[detection_classes[m1[j]], gc] += 1
关于这行代码,官方给的解释是再在筛选TP,但是我觉得这里并不只是TP。TP首先要是 正样本Positive + 检测
正确True 才可以。而这里Positive肯定是成立的,但是当sum(j) == 1时,只能说明这个真实框被某个预测框检测到了,但是这里并没有比较两者的class,也就是说这个预测框也可能是检测错误的。所以说,我认为这里应该是TP + FP.
其他地方就没什么了,注意看这个函数一定要debug,不然根本不知道它在干嘛。
【val.py中调用】
在val.py中定义(初始化): 在val.py中计算混淆矩阵:
在val.py中计算混淆矩阵:
在val.py中画出混淆矩阵:
绘制整体效果: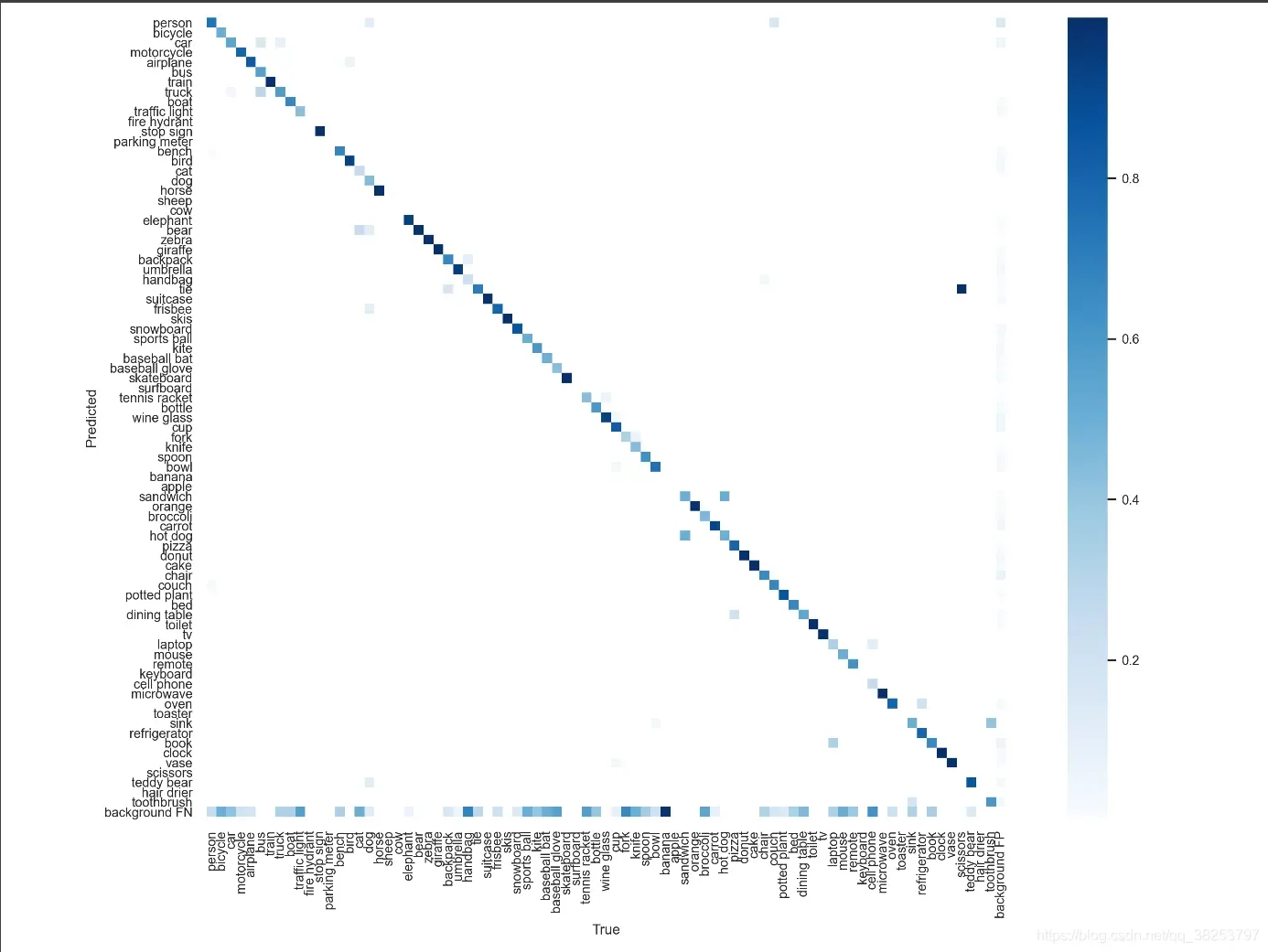
- 类别数小于30,格子显示数字,否则以这种热力图的形式显示;
- 对角线颜色越深(数字越大)越好;
- background FN和background FP颜色越浅(数字越小)越好;
4、bbox_iou
这个函数是用来计算矩阵间的iou的,这个函数实现的计算iou种类有:IoU/GIoU/DIoU/CIoU。代码比较简单的,理解这些iou之间的区别就比较容易看懂。如果有不懂的,可以看我的另一篇博文:【YOLO v4】【trick 3】Bounding Box regression loss: IoU Loss、GIoU Loss、DIoU Loss、CIoU Loss.
bbox_iou函数代码:
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
"""在ComputeLoss的__call__函数中调用计算回归损失
:params box1: 预测框
:params box2: 预测框
:return box1和box2的IoU/GIoU/DIoU/CIoU
"""
box2 = box2.T
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area tensor.clamp(0): 将矩阵中小于0的元数变成0
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # 两个框的最小闭包区域的width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # 两个框的最小闭包区域的height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if DIoU:
return iou - rho2 / c2 # DIoU
elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
else:
return iou # IoU
这个函数通常用在ComputeLoss函数中用于计算回归损失: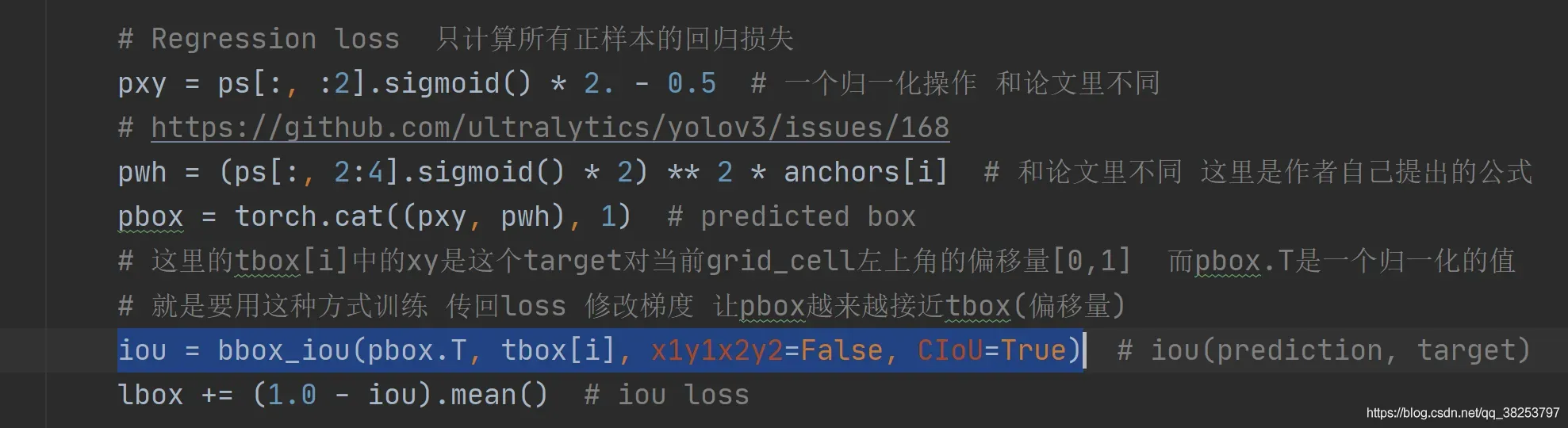
5、box_iou
这个函数只是上面函数的简单版本,这个函数只计算两个矩阵的iou,非常简单。
box_iou函数代码:
def box_iou(box1, box2):
"""用于计算混淆矩阵
https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
:params box1: (Tensor[N, 4]) [N, x1y1x2y2]
:params box2: (Tensor[M, 4]) [M, x1y1x2y2]
:return box1和box2的iou [N, M]
"""
def box_area(box):
# 求出box的面积
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.T) # box1面积
area2 = box_area(box2.T) # box2面积
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
# 等价于(torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 + 1e-16 - inter) # iou = inter / (area1 + area2 - inter)
该函数用于计算混淆矩阵: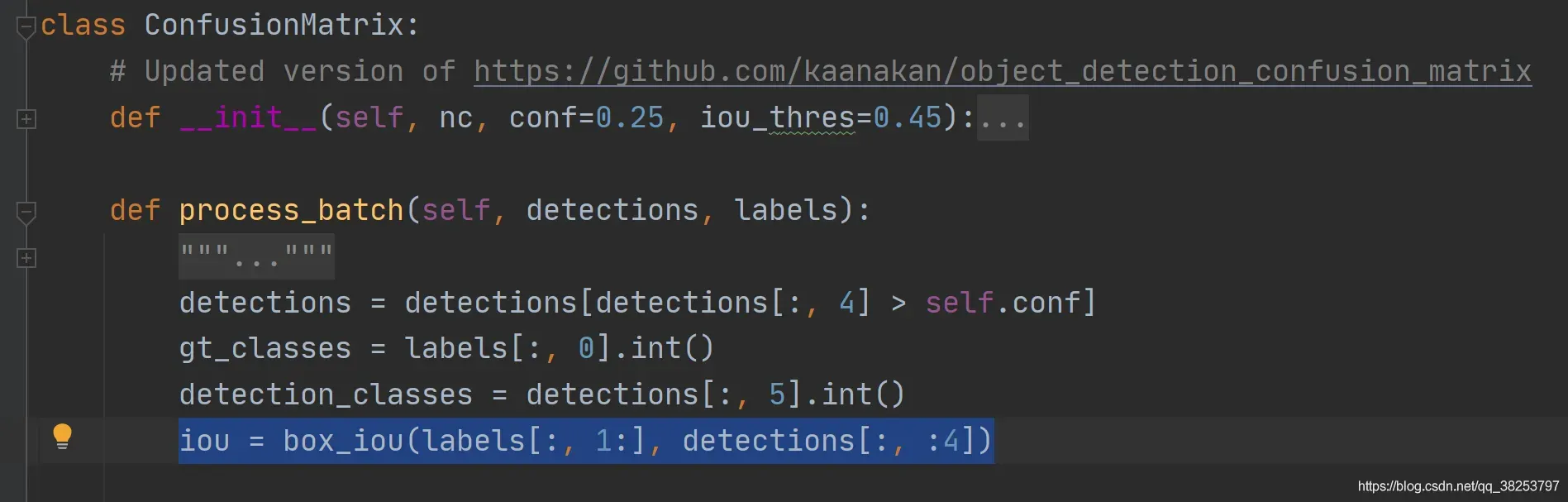
6、wh_iou
这个函数是用于求anchor框和gt框(筛选前)的宽高 iou 的,在老版的build_target中设定为筛选正样本的条件。但是在新版的代码中以及不用这个筛选条件了,现在是使用anchor框和gt框的宽比和高比来当筛选条件。
wh_iou函数代码:
def wh_iou(wh1, wh2):
"""在ComputeLoss类的build_targets函数中被调用(老版正样本筛选条件)
:params wh1: anchors 当前feature map的3个anchor [N, 2]
:params wh2: t[:, 4:6] gt框的wh(没筛选 所有的gt) [M, 2]
:return 返回wh1和wh2的iou(矩阵)
"""
# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
wh1 = wh1[:, None] # [N,2] -> [N,1,2]
wh2 = wh2[None] # [M, 2] -> [1,M,2]
# 这里会利用广播机制使wh1: [N,1,2]->[N,M,2] wh2: [1,M,2]->[N,M,2]
# 相当于 inter = torch.min(w1, w2) * torch.min(h1, h2)
# 计算inter 默认两个bounding box的左上角是重叠在一起的 这样才可以计算 可以自己画个图就明白了
inter = torch.min(wh1, wh2).prod(2) # [N,M]
# iou = inter / (area1 + area2 - inter) 1e-16防止分母为0 prod(2): 宽高相乘(矩阵运算)
return inter / (wh1.prod(2) + wh2.prod(2) + 1e-16 - inter)
用在ComputeLoss类的build_targets函数中当中筛选条件(老版):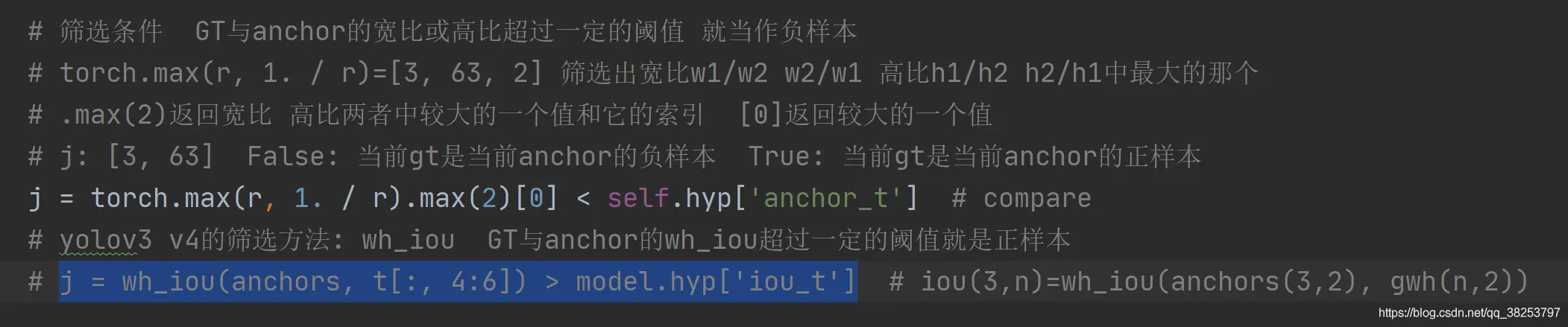
7、plot_pr_curve
这个函数用于绘制PR曲线,会在ap_per_class函数中调用。
plot_pr_curve函数代码:
def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
"""用于ap_per_class函数
Precision-recall curve 绘制PR曲线
:params px: [1000] 横坐标 recall 值为0~1直接取1000个数
:params py: list{nc} nc个[1000] 所有类别在IOU=0.5,横坐标为px(recall)时的precision
:params ap: [nc, 10] 所有类别在每个IOU阈值下的平均mAP
:params save_dir: runs\test\exp54\PR_curve.png PR曲线存储位置
:params names: {dict:80} 数据集所有类别的字典 key:value
"""
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True) # 设置画布
py = np.stack(py, axis=1) # [1000, nc]
# 画出所有类别在10个IOU阈值下的PR曲线
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py.T): # 如果<21 classes就一个个类画 因为要显示图例就必须一个个画
ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
else: # 如果>=21 classes 显示图例就会很乱 所以就不显示图例了 可以直接输入数组 x[1000] y[1000, 71]
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
# 画出所有类别在IOU=0.5阈值下的平均PR曲线
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
ax.set_xlabel('Recall') # 设置x轴标签
ax.set_ylabel('Precision') # 设置y轴标签
ax.set_xlim(0, 1) # x=[0, 1]
ax.set_ylim(0, 1) # y=[0, 1]
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left") # 显示图例
fig.savefig(Path(save_dir), dpi=250) # 保存PR_curve.png图片
pr_curve.png: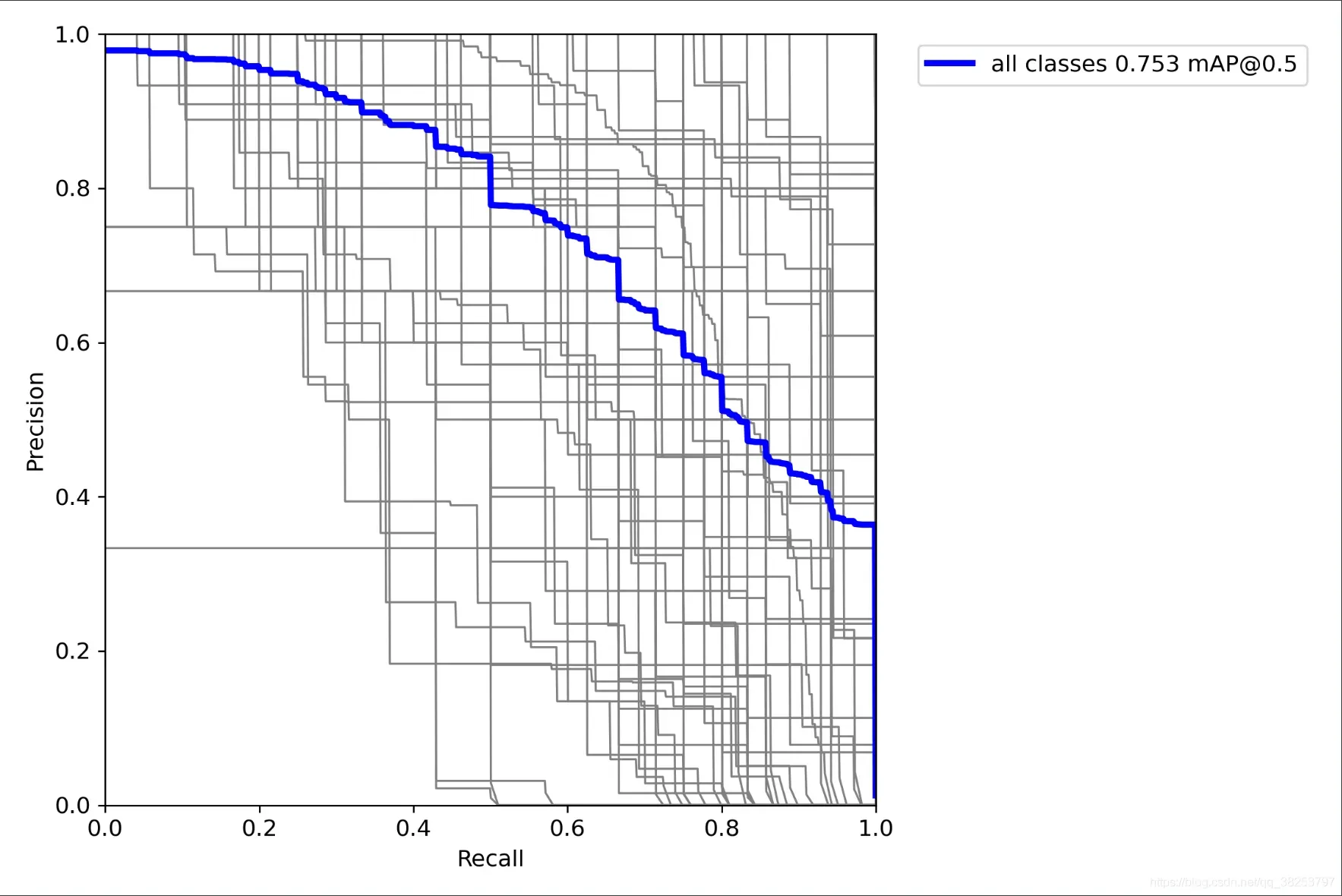
8、plot_mc_curve
这个函数用于绘制 F1-Confidence/P-Confidence/R-Confidence曲线,会在ap_per_class函数中调用。
plot_mc_curve函数代码:
def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
"""用于ap_per_class函数
Metric-Confidence curve 可用于绘制 F1-Confidence/P-Confidence/R-Confidence曲线
:params px: [0, 1, 1000] 横坐标 0-1 1000个点 conf [1000]
:params py: 对每个类, 针对横坐标为conf=[0, 1, 1000] 对应的f1/p/r值 纵坐标 [71, 1000]
:params save_dir: 图片保存地址
:parmas names: 数据集names
:params xlabel: x轴标签
:params ylabel: y轴标签
"""
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True) # 设置画布
# 画出所有类别的F1-Confidence/P-Confidence/R-Confidence曲线
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py): # 如果<21 classes就一个个类画 因为要显示图例就必须一个个画
ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
else: # 如果>=21 classes 显示图例就会很乱 所以就不显示图例了 可以直接输入数组 x[1000] y[1000, 71]
ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
# 画出所有类别在每个x点(conf)对应的均值F1-Confidence/P-Confidence/R-Confidence曲线
y = py.mean(0) # [1000] 求出所以类别在每个x点(conf)的平均值
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
ax.set_xlabel(xlabel) # 设置x轴标签
ax.set_ylabel(ylabel) # 设置y轴标签
ax.set_xlim(0, 1) # x=[0, 1]
ax.set_ylim(0, 1) # y=[0, 1]
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left") # 显示图例
fig.savefig(Path(save_dir), dpi=250) # 保存png图片
P_curve.png: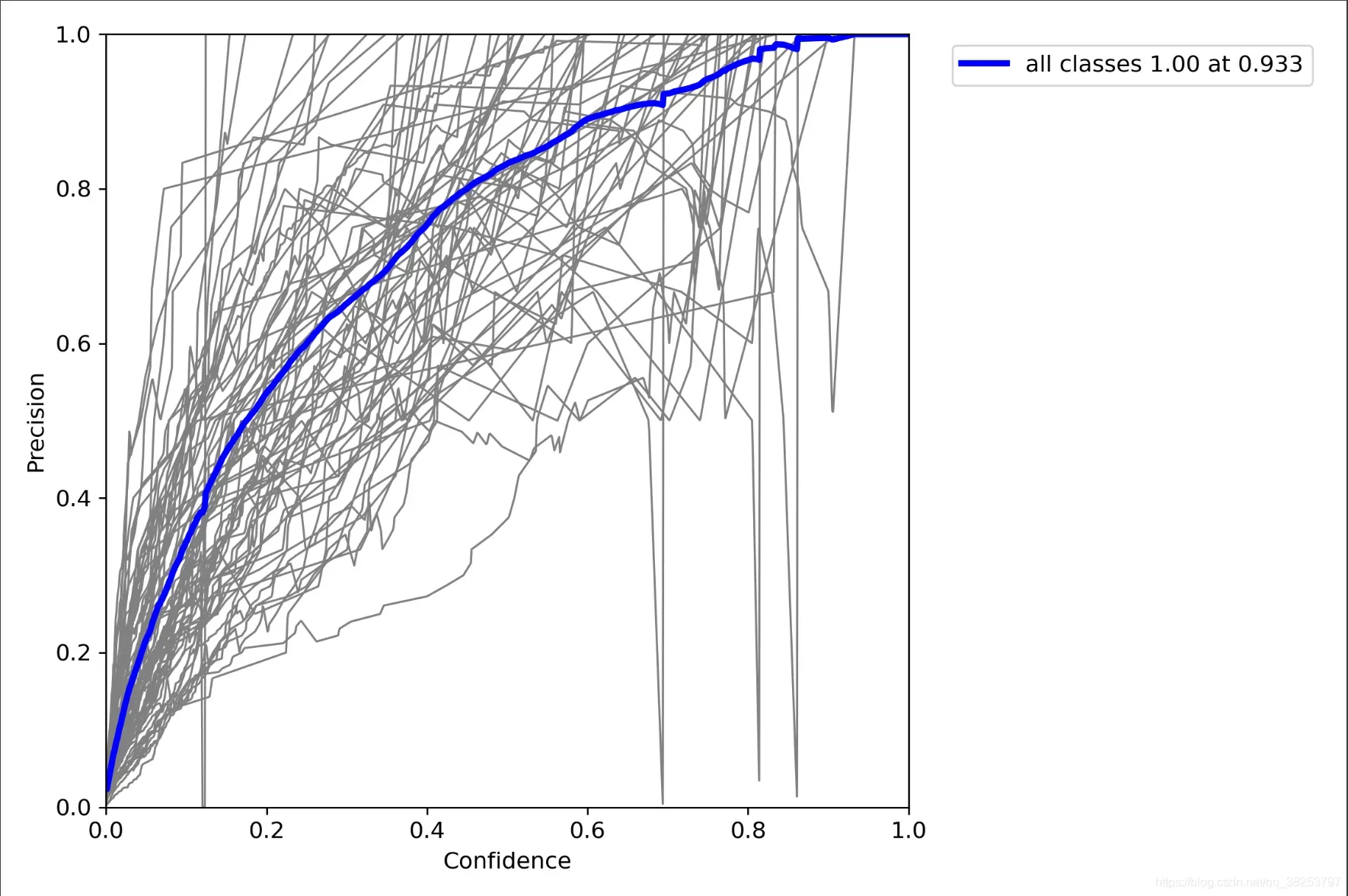
R_curve.png: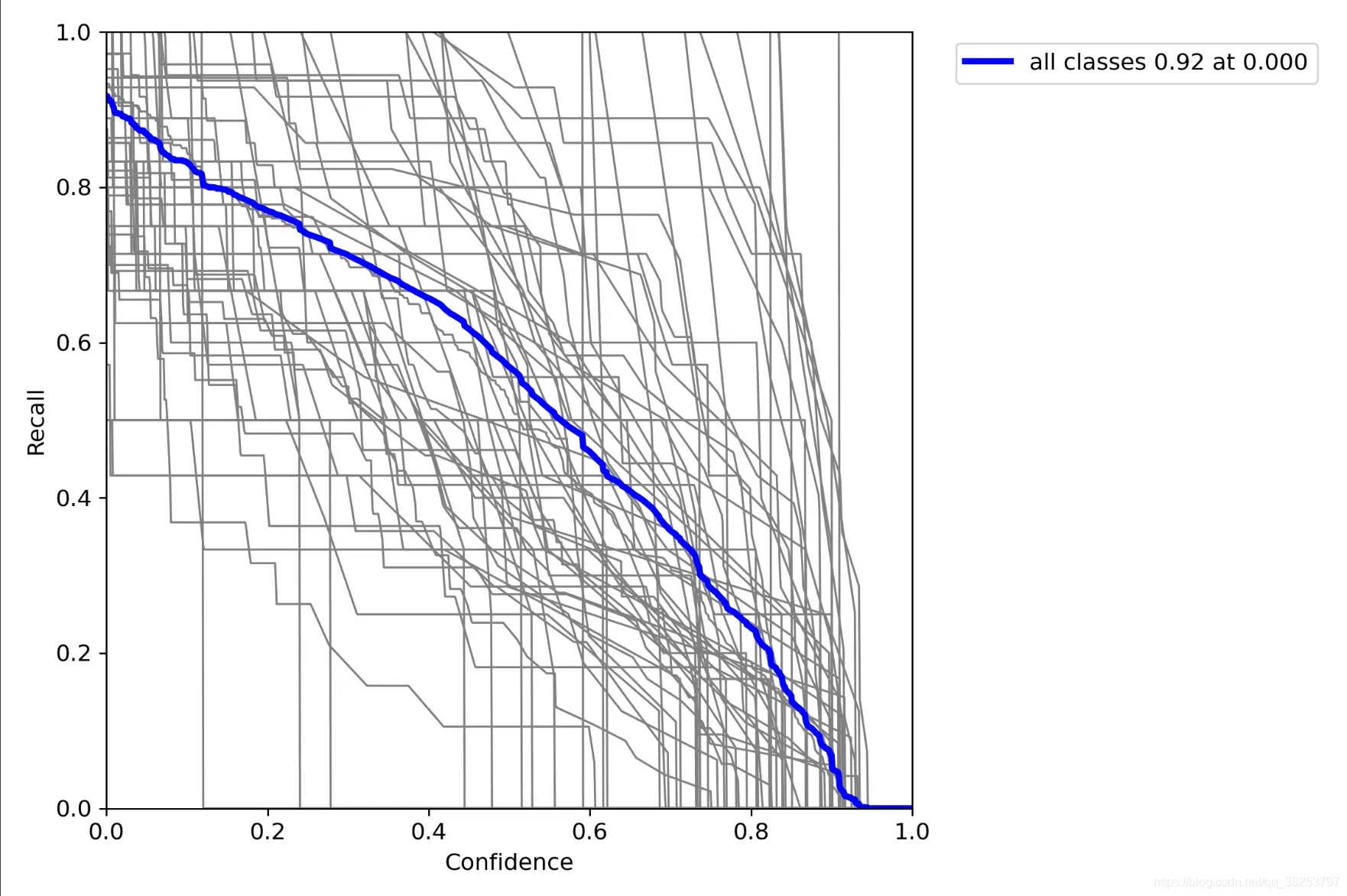
F1_curve.png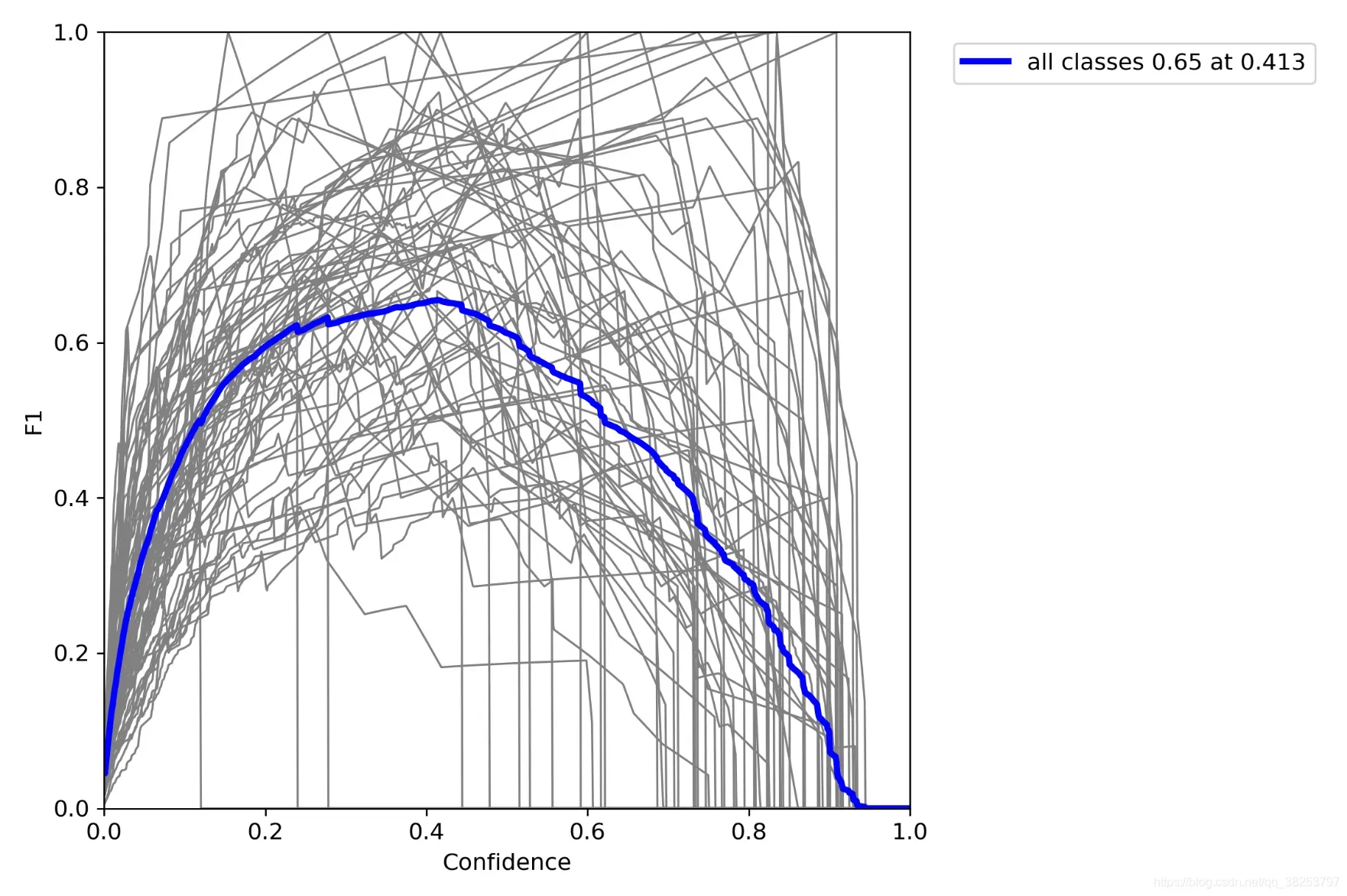
总结
这个脚本的代码较为复杂,而且需要和【YOLOV5-5.x 源码解读】val.py.一起看才能看懂。其中bbox_iou函数比较重要。ap_per_class、compute_ap、ConfusionMatrix三个函数都相对比较难,可能需要自己私下debug加上我的注释才能看的懂,如果看不懂就多debug几次,查看函数库,因为我这几个函数也看的是比较久的。
–2021.08.14 22:29
版权声明:本文为博主满船清梦压星河HK原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_38253797/article/details/119547084