内容
- 1、需求解读
- 2、YOLOv5算法简介
- 3、YOLOv5算法详解
- 3.1 YOLOv5网络架构
- 3.2 YOLOv5实现细节详解
- 3.2.1 YOLOv5基础组件
- 3.2.2 输入端细节详解
- 3.2.3 基准网络细节详解
- 3.2.4 Neck网络细节详解
- 3.2.5 Head输出端细节详解
- 4、YOLOv5网络代码实现
- 5、YOLOv5效果展示与分析
- 5.1、YOLOv5客观效果展示与分析
- 5.2、YOLOv5主观效果展示与分析
- 6、总结与分析
- 参考
- 预防措施
1、需求解读
YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,检测性能得到进一步的提升。虽然YOLOv5算法并没有与YOLOv4算法进行性能比较与分析,但是YOLOv5在COCO数据集上面的测试效果还是挺不错的。大家对YOLOv5算法的创新性半信半疑,有的人对其持肯定态度,有的人对其持否定态度。在我看来,YOLOv5检测算法中还是存在很多可以学习的地方,虽然这些改进思路看来比较简单或者创新点不足,但是它们确定可以提升检测算法的性能。其实工业界往往更喜欢使用这些方法,而不是利用一个超级复杂的算法来获得较高的检测精度。本文将对YOLOv5检测算法中提出的改进思路进行详细的解说,大家可以尝试者将这些改进思路应用到其它的目标检测算法中。
2、YOLOv5算法简介
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
3、YOLOv5算法详解
3.1 YOLOv5网络架构
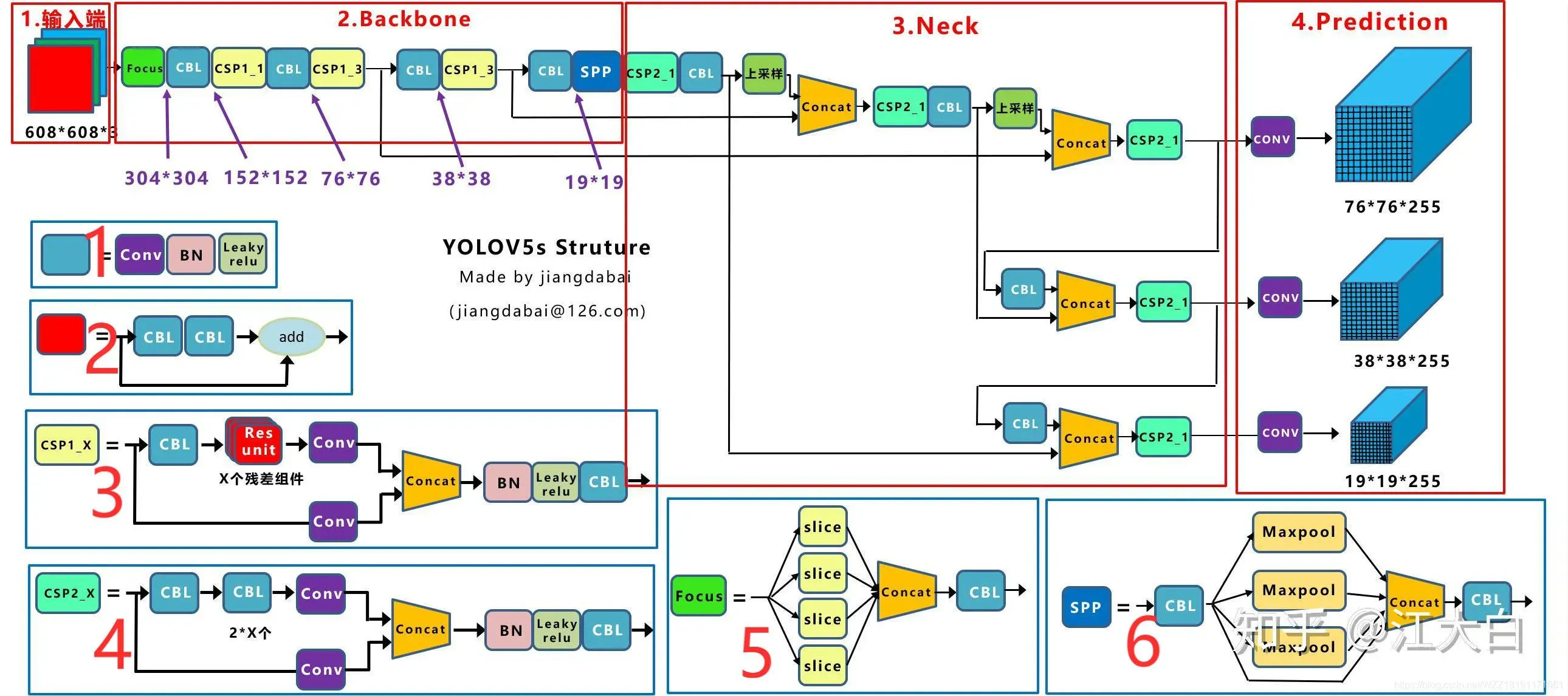
上图展示了YOLOv5目标检测算法的整体框图。对于一个目标检测算法而言,我们通常可以将其划分为4个通用的模块,具体包括:输入端、基准网络、Neck网络与Head输出端,对应于上图中的4个红色模块。YOLOv5算法具有4个版本,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种,本文重点讲解YOLOv5s,其它的版本都在该版本的基础上对网络进行加深与加宽。
- 输入端-输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
- 基准网络-基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
- Neck网络-Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
- Head输出端-Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。YOLOv4利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
3.2 YOLOv5实现细节详解
3.2.1 YOLOv5基础组件
- CBL-CBL模块由Conv+BN+Leaky_relu激活函数组成,如上图中的模块1所示。
- Res unit-借鉴ResNet网络中的残差结构,用来构建深层网络,CBM是残差模块中的子模块,如上图中的模块2所示。
- CSP1_X-借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成而成,如上图中的模块3所示。
- CSP2_X-借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成,如上图中的模块4所示。
- Focus-如上图中的模块5所示,Focus结构首先将多个slice结果Concat起来,然后将其送入CBL模块中。
- SPP-采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合,如上图中的模块6所示。
3.2.2 输入端细节详解
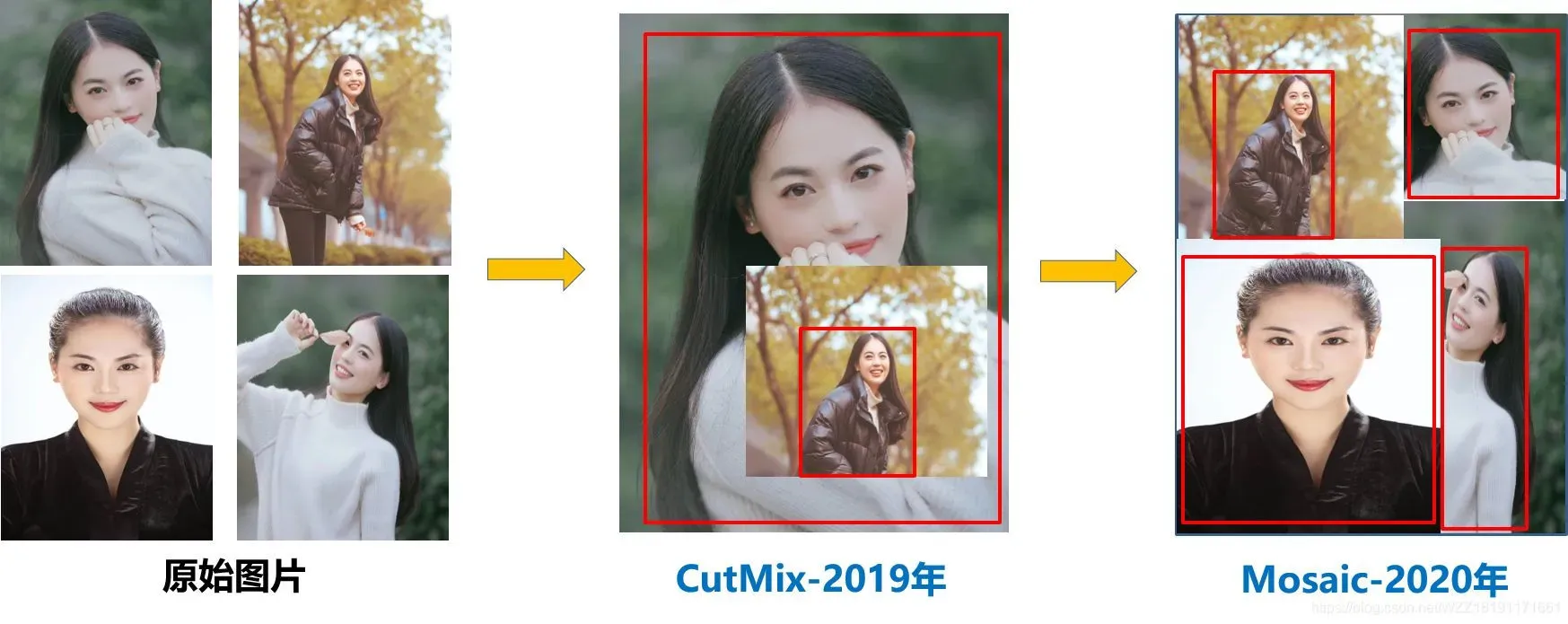
- Mosaic数据增强-YOLOv5中在训练模型阶段仍然使用了Mosaic数据增强方法,该算法是在CutMix数据增强方法的基础上改进而来的。CutMix仅仅利用了两张图片进行拼接,而Mosaic数据增强方法则采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,具体的效果如下图所示。这种增强方法可以将几张图片组合成一张,这样不仅可以丰富数据集的同时极大的提升网络的训练速度,而且可以降低模型的内存需求。
- 自适应锚框计算-在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。在YOLOv3和YOLOv4检测算法中,训练不同的数据集时,都是通过单独的程序运行来获得初始锚点框。YOLOv5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,具体的指令为parser.add_argument(’–noautoanchor’, action=‘store_ true’, help=‘disable autoanchor check’),如果需要打开,只需要在训练代码时增加–noautoanch or选项即可。
- 自适应图片缩放-针对不同的目标检测算法而言,我们通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO系列算法中常用的尺寸包括416*416,608 *608等尺寸。原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLOv5算法的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。具体的实现步骤如下所述。
步骤1-根据原始图片大小与输入到网络图片大小计算缩放比例。
步骤2-根据原始图片大小与缩放比例计算缩放后的图片大小。
步骤3-计算黑边填充数值。
如上图所示,416表示YOLOv5网络所要求的图片宽度,312表示缩放后图片的宽度。首先执行相减操作来获得需要填充的黑边长度104;然后对该数值执行取余操作,即104%32=8,使用32是因为整个YOLOv5网络执行了5次下采样操作,即;最后对该数值除以2,即将填充的区域分散到两边。这样将416*416大小的图片缩小到416*320大小,因而极大的提升了算法的推理速度。
必须注意的是:
(1)该操作仅在模型推理阶段执行,模型训练阶段仍然和传统的方法相同,将原始图片裁剪到416*416大小;(2)YOLOv3与YOLOv4中默认填充的数值是(0,0,0),而YOLOv5中默认填充的数值是(114,114,114);(3)该操作仅仅针对原始图片的短边而言,仍然将长边裁剪到416。



3.2.3 基准网络细节详解
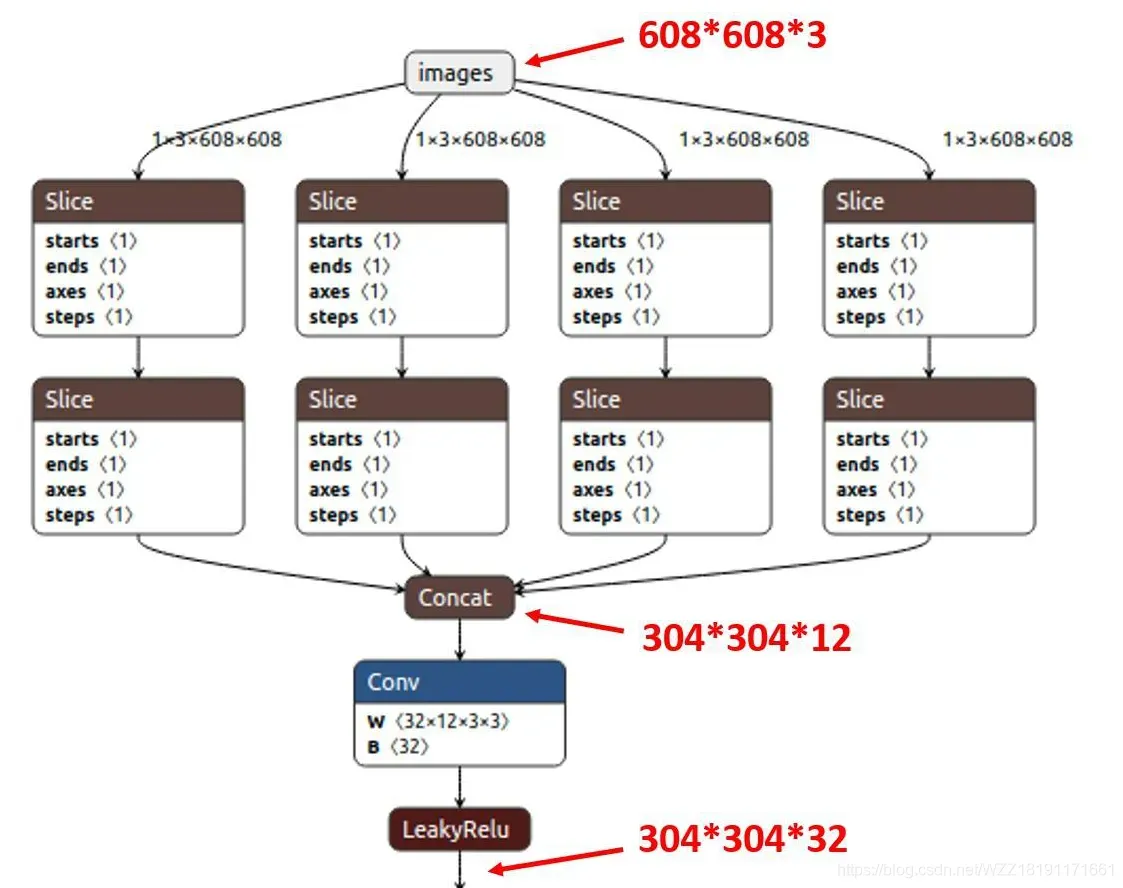
- Focus结构-该结构的主要思想是通过slice操作来对输入图片进行裁剪。如下图所示,原始输入图片大小为608*608*3,经过Slice与Concat操作之后输出一个304*304*12的特征映射;接着经过一个通道个数为32的Conv层(该通道个数仅仅针对的是YOLOv5s结构,其它结构会有相应的变化),输出一个304*304*32大小的特征映射。
- CSP结构-YOLOv4网络结构中,借鉴了CSPNet的设计思路,仅仅在主干网络中设计了CSP结构。而YOLOv5中设计了两种CSP结构,以YOLOv5s网络为例,CSP1_X结构应用于Backbone主干网络中,另一种CSP2_X结构则应用于Neck网络中。CSP1_X与CSP2_X模块的实现细节如3.1所示。
3.2.4 Neck网络细节详解
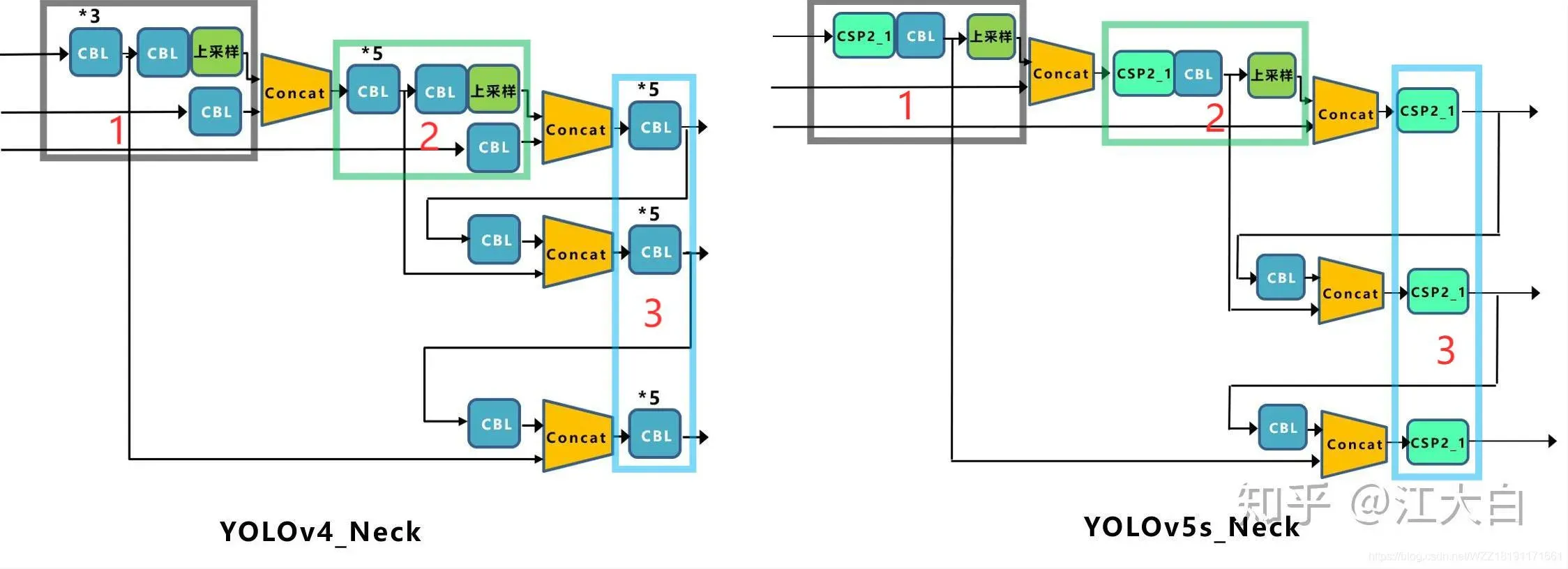
- FPN+PAN-YOLOv5的Neck网络仍然使用了FPN+PAN结构,但是在它的基础上做了一些改进操作,YOLOv4的Neck结构中,采用的都是普通的卷积操作。而YOLOv5的Neck网络中,采用借鉴CSPnet设计的CSP2结构,从而加强网络特征融合能力。下图展示了YOLOv4与YOLOv5的Neck网络的具体细节,通过比较我们可以发现:(1)灰色区域表示第1个不同点,YOLOv5不仅利用CSP2_\1结构代替部分CBL模块,而且去掉了下方的CBL模块;(2)绿色区域表示第2个不同点,YOLOv5不仅将Concat操作之后的CBL模块更换为CSP2_1模块,而且更换了另外一个CBL模块的位置;(3)蓝色区域表示第3个不同点,YOLOv5中将原始的CBL模块更换为CSP2_1模块。
3.2.5 Head输出端细节详解
- GIoU_Loss-YOLOv5中采用GIoU_Loss做Bounding box的损失函数,更多的细节请参考
这个博客
.
4、YOLOv5网络代码实现
# 检测类
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
# 根据配置的.yaml文件搭建模型
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None): # model, input channels, number of classes
super(Model, self).__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.SafeLoader) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
logger.info('Overriding model.yaml nc=%g with nc=%g' % (self.yaml['nc'], nc))
self.yaml['nc'] = nc # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
logger.info('')
def forward(self, x, augment=False, profile=False):
if augment:
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi[..., :4] /= si # de-scale
if fi == 2:
yi[..., 1] = img_size[0] - yi[..., 1] # de-flip ud
elif fi == 3:
yi[..., 0] = img_size[1] - yi[..., 0] # de-flip lr
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
else:
return self.forward_once(x, profile) # single-scale inference, train
def forward_once(self, x, profile=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPS
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if profile:
print('%.1fms total' % sum(dt))
return x
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
print(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# print('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is Conv and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self
def nms(self, mode=True): # add or remove NMS module
present = type(self.model[-1]) is NMS # last layer is NMS
if mode and not present:
print('Adding NMS... ')
m = NMS() # module
m.f = -1 # from
m.i = self.model[-1].i + 1 # index
self.model.add_module(name='%s' % m.i, module=m) # add
self.eval()
elif not mode and present:
print('Removing NMS... ')
self.model = self.model[:-1] # remove
return self
def autoshape(self): # add autoShape module
print('Adding autoShape... ')
m = autoShape(self) # wrap model
copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
return m
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
# 解析模型
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3]:
c1, c2 = ch[f], args[0]
# Normal
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1.75 # exponential (default 2.0)
# e = math.log(c2 / ch[1]) / math.log(2)
# c2 = int(ch[1] * ex ** e)
# if m != Focus:
c2 = make_pisible(c2 * gw, 8) if c2 != no else c2
# Experimental
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1 + gw # exponential (default 2.0)
# ch1 = 32 # ch[1]
# e = math.log(c2 / ch1) / math.log(2) # level 1-n
# c2 = int(ch1 * ex ** e)
# if m != Focus:
# c2 = make_pisible(c2, 8) if c2 != no else c2
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3]:
args.insert(2, n)
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x if x < 0 else x + 1] for x in f])
elif m is Detect:
args.append([ch[x + 1] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f if f < 0 else f + 1] * args[0] ** 2
elif m is Expand:
c2 = ch[f if f < 0 else f + 1] // args[0] ** 2
else:
c2 = ch[f if f < 0 else f + 1]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
5、YOLOv5效果展示与分析
5.1、YOLOv5客观效果展示与分析
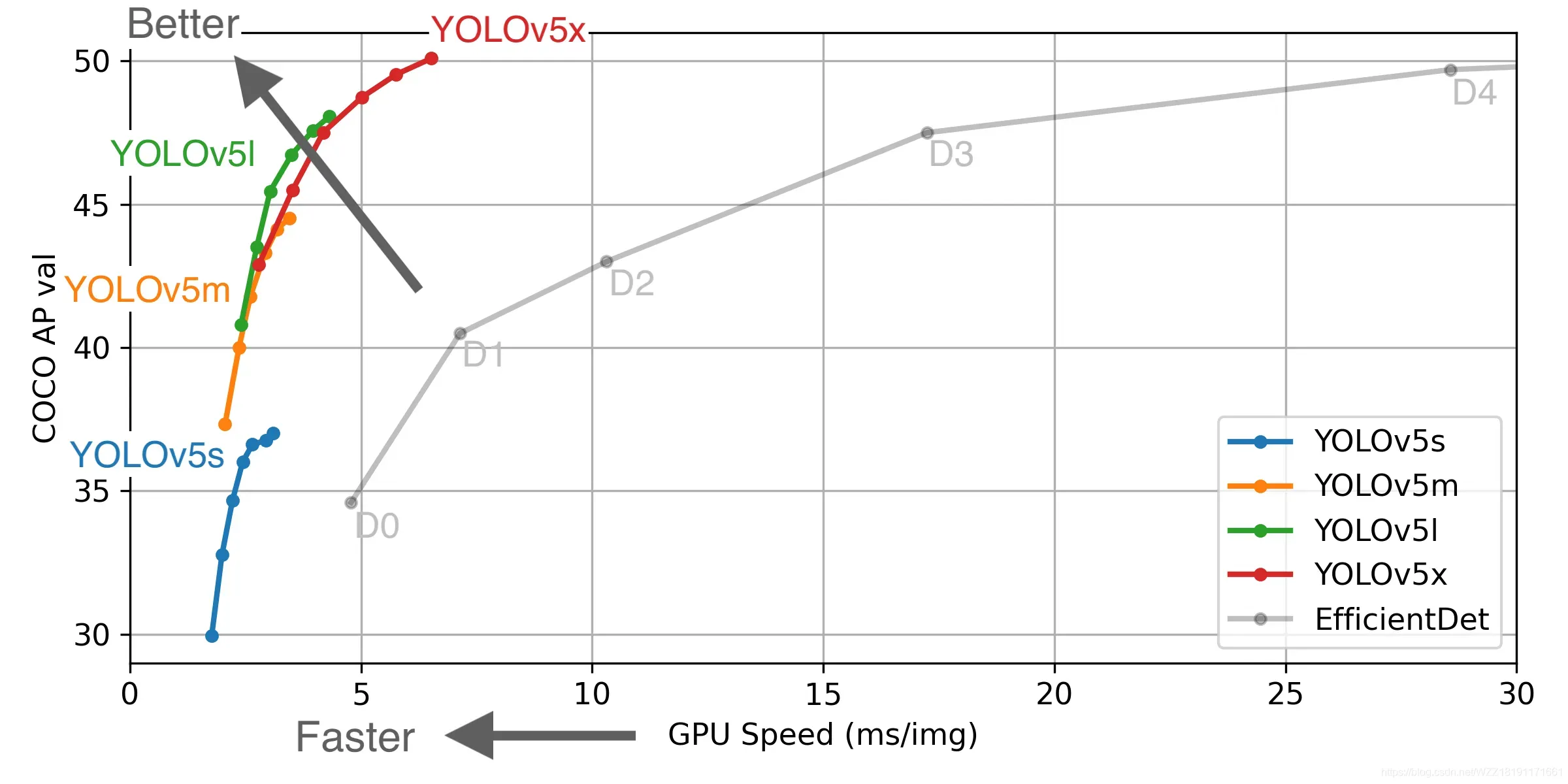
上图展示了不同版本的YOLOv5与EfficientDet检测算法之间的性能比较曲线图。横轴表示的是该算法在GPU上面的推理时间(ms/img),该数值越小越好;纵轴表示的是该算法在COCO测试数据集上面的AP指标,该数值越大越好。通过观察我们可以得出以下的初步结论:(1)与EfficientDet0相比,YOLOv5s不仅可以获得更高的AP指标,而且可以获得更快的推理速度;(2)与EfficientDet4相比,YOLOv5x不仅能够获得更高的AP指标,其推理速度是它的1/5左右。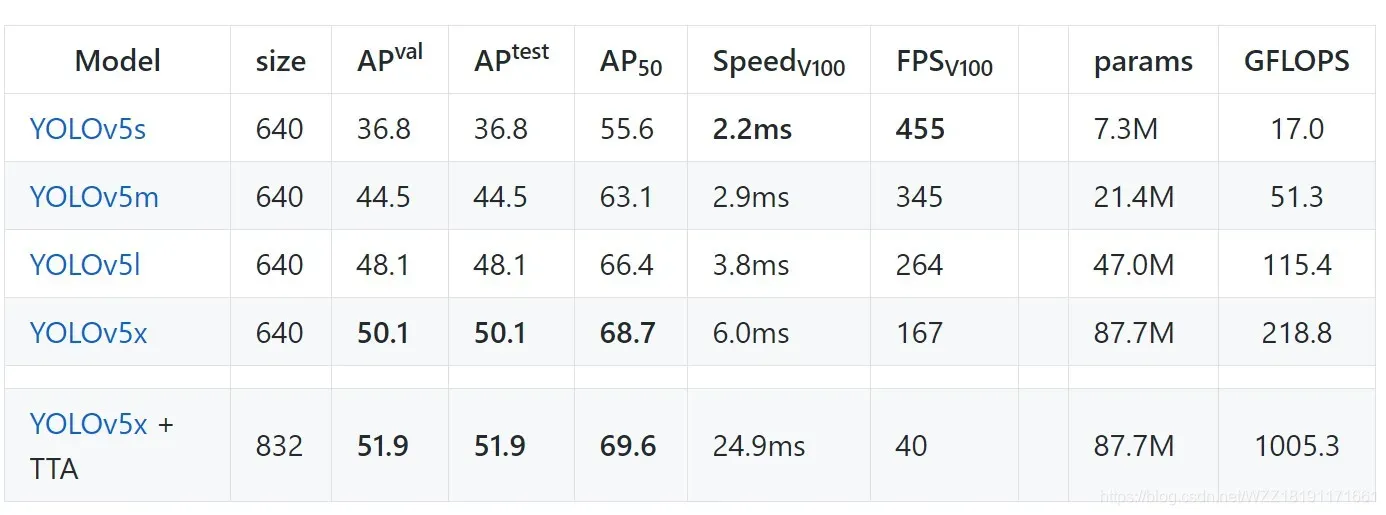
上表展示了不同版本的YOLOv5检测算法在COCO2017验证集与测试集上面的各项指标,具体包括:模型输入大小、AP50指标、Speed、FPS、params与GFLOPS。通过观察我们可以得出以下的初步结论:(1)YOLOv5s的输入图片分辨率为640*640,在COCO测试集与验证集上面的AP指标为36.8,AP50指标为55.6。该算法在V100 GPU上面的推理速度仅仅需要2.2ms,帧率为455FPS,该网络的模型大小仅为7.3M;(2)YOLOv5x的输入图像分辨率为640*640,在COCO测试集与验证集上面的AP指标为50.1,AP50指标为68.7。该算法在V100 GPU上面的推理速度仅仅需要6.0ms,帧率为167FPS,该网络的模型大小为87.7M。(3)我们可以根据现实场景的需要选择合适的模型,如果我们关注速度的话可以选择YOLOv5s模型;如果我们关注精度的话可以选择YOLOv5x模型。
5.2、YOLOv5主观效果展示与分析
yolov5 行人检测_车辆检测_电动车检测识别_交通标志识别
yolo5 车辆行人检测
6、总结与分析
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使得其速度与精度都得到了极大的性能提升,具体包括:输入端的Mosaic数据增强、自适应锚框计算、自适应图片缩放操作;基准端的Focus结构与CSP结构;Neck端的SPP与FPN+PAN结构;输出端的损失函数GIOU_Loss以及预测框筛选的DIOU_nms。除此之外,YOLOv5中的各种改进思路仍然可以应用到其它的目标检测算法中。
参考
[1]博客链接1
预防措施
[1] 该博客是本人原创博客,如果您对该博客感兴趣,想要转载该博客,请与我联系(qq邮箱:1575262785@qq.com),我会在第一时间回复大家,谢谢大家的关注。
[2] 由于个人能力有限,该博客可能存在很多的问题,希望大家能够提出改进意见。
[3] 如果您在阅读本博客时遇到不理解的地方,希望您可以联系我,我会及时的回复您,和您交流想法和意见,谢谢。
[4] 本文中部分图像的版权归江大白所有。
版权声明:本文为博主技术挖掘者原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/WZZ18191171661/article/details/113789486