内容
1、Data Augmentation
2、Auto Learning Bounding Box Anchors-自适应锚定框
3、Backbone-跨阶段局部网络(CSP,Cross Stage Partial Networks)
4、Neck-路径聚合网络(PANET)
5、Head-YOLO 通用检测层
6、Network Architecture
7、Activation Function
8、Optimization Function
9、Cost Function
Summary
写在最后:
yolo5代码测试请查看:https://blog.csdn.net/l641208111/article/details/109249075
YOLO V5的作者并没有发表论文,对yolo5分析只能从源码进行分析;相比于yolo4,yolo5在原理性方法没有太多改进,
但是在速度与模型大小上比yolo4有较大提升,可以认为是通过模型裁剪后的工程化应用(即推理速度和准确率增加、模型尺寸减小)。
从以下几个方面说明yolo5的改进之处:
- Data Augmentation
- Auto Learning Bounding Box Anchors
- Backbone
- Neck
- Head
- Network Architecture
- Activation Function
- Optimization Function
- Benchmarks
1、Data Augmentation
YOLO V4使用了多种数据增强技术的组合,对于单一图片,使用了几何畸变,光照畸图像,遮挡(Random Erase,Cutout,Hide and Seek,Grid Mask ,MixUp)技术,对于多图组合,作者混合使用了CutMix与Mosaic技术。除此之外,作者还使用了Self-Adversarial Training (SAT)来进行数据增强。
YOLOV5会通过数据加载器传递每一批训练数据,并同时增强训练数据。数据加载器进行三种数据增强:缩放,色彩空间调整和马赛克增强。据悉YOLO V5的作者Glen Jocher正是Mosaic Augmentation的创造者,故认为YOLO V4性能巨大提升很大程度是马赛克数据增强的功劳,也许你不服,但他在YOLO V4出来后的仅仅两个月便推出YOLO V5,不可否认的是马赛克数据增强确实能有效解决模型训练中最头疼的“小对象问题”,即小对象不如大对象那样准确地被检测到。
2、Auto Learning Bounding Box Anchors-自适应锚定框
yolo3中的锚框是预先利用kmeans定义好的,yolo4沿用了yolo3;
yolo5锚定框是基于训练数据自动学习的。个人认为算不上是创新点,只是手动改代码改为自动运行。
对于COCO数据集来说,YOLO V5 的配置文件*.yaml 中已经预设了640×640图像大小下锚定框的尺寸:
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8
对于自定义数据集来说,由于目标识别框架往往需要缩放原始图片尺寸,并且数据集中目标对象的大小可能也与COCO数据集不同,因此YOLO V5会重新自动学习锚定框的尺寸。
3、Backbone-跨阶段局部网络(CSP,Cross Stage Partial Networks)
YOLO V5和V4都使用CSPDarknet作为Backbone从输入图像中提取丰富的信息特征。CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,具体做法是:将梯度的变化从头到尾地集成到特征图中,减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。

CSPNe思想源于Densnet,复制基础层的特征映射图,通过dense block 发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。CSPNet思想可以和ResNet、ResNeXt和DenseNet结合,目前主要有CSPResNext50 and CSPDarknet53两种改造Backbone网络。
4、Neck-路径聚合网络(PANET)
YOLO V5和V4都使用PANET作为Neck来聚合特征。Neck主要用于生成特征金字塔,增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。
在PANET之前,一直使用FPN(特征金字塔)作为对象检测框架的特征聚合层,PANET在借鉴 Mask R-CNN 和 FPN 框架的基础上,加强了信息传播。
PANET基于 Mask R-CNN 和 FPN 框架,同时加强了信息传播。该网络的特征提取器采用了一种新的增强自下向上路径的 FPN 结构,改善了低层特征的传播。第三条通路的每个阶段都将前一阶段的特征映射作为输入,并用3×3卷积层处理它们。输出通过横向连接被添加到自上而下通路的同一阶段特征图中,这些特征图为下一阶段提供信息。同时使用自适应特征池化(Adaptive feature pooling)恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配。
5、Head-YOLO 通用检测层
模型Head主要用于最终检测部分,它在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量。yolo5在通用检测层,与yolo3、yolo4相同。
最后三个特征图是不同缩放尺度的Head被用来检测不同大小的物体,每个Head一共(80个类 + 1个概率 + 4坐标) * 3锚定框,一共255个channels。
6、Network Architecture
yolo4和yolo5基本相同的网络架构,都使用CSPDarknet53(跨阶段局部网络)作为Backbone,并且使用了PANET(路径聚合网络)和SPP(空间金字塔池化)作为Neck,而且都使用YOLO V3的Head。YOLO V5 s,m,l,x四种模型的网络结构是一样的。原因是作者通过depth_multiple,width_multiple两个参数分别控制模型的深度以及卷积核的个数。
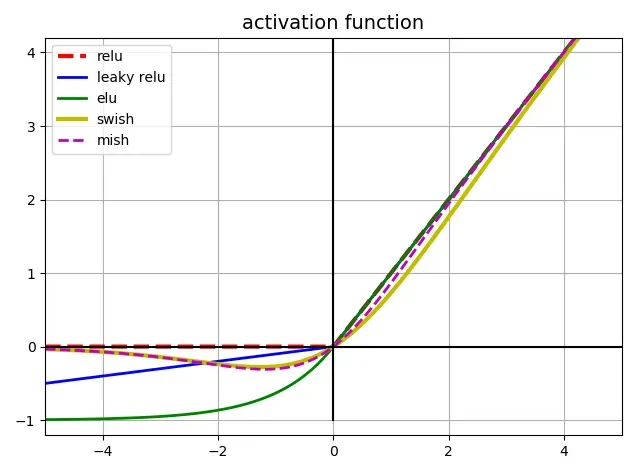
7、Activation Function
yolo5的作者使用了 Leaky ReLU 和 Sigmoid 激活函数。yolo5中中间/隐藏层使用了 Leaky ReLU 激活函数,最后的检测层使用了 Sigmoid 形激活函数。而YOLO V4使用Mish激活函数。
8、Optimization Function
YOLO V5的作者提供了两个优化函数Adam和SGD(默认),并都预设了与之匹配的训练超参数。
YOLO V4使用SGD。
YOLO V5的作者建议是,如果需要训练较小的自定义数据集,Adam是更合适的选择,尽管Adam的学习率通常比SGD低。但是如果训练大型数据集,对于YOLOV5来说SGD效果比Adam好。
实际上学术界上对于SGD和Adam哪个更好,一直没有统一的定论,取决于实际项目情况。
9、Cost Function
YOLO 系列的损失计算是基于 objectness score, class probability score,和 bounding box regression score.
YOLO V5使用 GIOU Loss作为bounding box的损失。
YOLO V5使用二进制交叉熵和 Logits 损失函数计算类概率和目标得分的损失。同时我们也可以使用fl _ gamma参数来激活Focal loss计算损失函数。
YOLO V4使用 CIOU Loss作为bounding box的损失,与其他提到的方法相比,CIOU带来了更快的收敛和更好的性能。
- 训练时间
YOLO V5的训练非常迅速,在训练速度上远超YOLO V4。对于Roboflow的自定义数据集,YOLO V4达到最大验证评估花了14个小时,而YOLO V5仅仅花了3.5个小时。
- 型号尺寸
V5x: 367MB,V5l: 192MB,V5m: 84MB,V5s: 27MB,YOLOV4: 245 MB
YOLO V5s 模型尺寸非常小,降低部署成本,有利于模型的快速部署。
- 推理时间
在单个图像(批大小为1)上,YOLOV4推断在22毫秒内,YOLOV5s推断在20毫秒内。而YOLOV5实现默认为批处理推理(批大小36),并将批处理时间除以批处理中的图像数量,单一图片的推理时间能够达到7ms,也就是140FPS,这是目前对象检测领域的State-of-the-art。我使用我训练的模型对10000张测试图片进行实时推理,YOLOV5s 的推理速度非常惊艳,每张图只需要7ms的推理时间,再加上20多兆的模型大小,在灵活性上堪称无敌。但是其实这对于YOLO V4并不公平,由于YOLO V4没有实现默认批处理推理,因此在对比上呈现劣势,接下来应该会有很多关于这两个对象检测框架在同一基准下的测试。其次YOLO V4最新推出了tiny版本,YOLO V5s 与V4 tiny 的性能速度对比还需要更多实例分析。
Summary
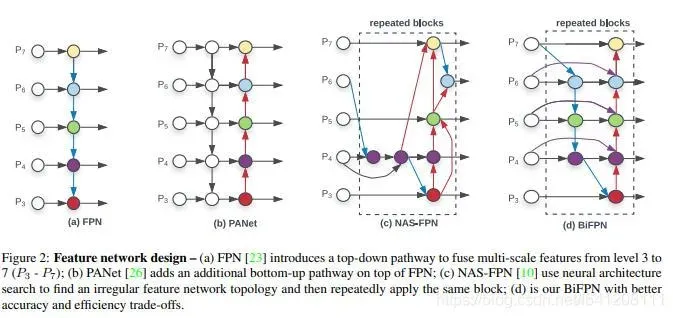
总的来说,YOLO V4 在性能上优于YOLO V5,但是在灵活性与速度上弱于YOLO V5。我个人觉得对于这些对象检测框架,特征融合层的性能非常重要,目前两者都是使用PANET,但是根据谷歌大脑的研究,BiFPN才是特征融合层的最佳选择。谁能整合这项技术,很有可能取得性能大幅超越。
尽管YOLO V5目前仍然计逊一筹,但是YOLO V5仍然具有以下显著的优点:
- 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLO V4采用的Darknet框架,Pytorch框架更容易投入生产
- 代码通俗易懂,集成了大量的计算机视觉技术,非常有利于学习和参考
- 不仅环境易于配置,模型训练也非常快,批量推理产生实时结果
- 能够直接对单个图像、批量图像、视频甚至网络摄像头端口输入执行有效推理
- 能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端
- 最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒
写在最后:
其实很多人都觉得YOLO V4和YOLO V5实际上没有什么耳目一新创新,而是大量整合了计算机视觉领域的State-of-the-art,从而显著改善YOLO对象检测的性能。其实我觉得有的时候工程应用的能力同样也很重要,能有两个这么优秀的技术整合实例供我们免费使用和学习研究,已经不能奢求更多了,毕竟活雷锋还是少啊。先别管别人谁更强,自己能学到更多才是最重要的,毕竟讨论别人谁强,还不如自己强。
最后我想说的是,技术发展如此之快,最终谁会赢得最佳物体检测框架的称号,还不清楚,而我们正处于最好的时代,让我们学习并珍惜。
参考文献:https://www.zhihu.com/question/399884529
版权声明:本文为博主DLANDML原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/l641208111/article/details/109286497