前言
机器学习和人工智能一直被认为是神秘而高级的。我经常听说它们,但由于各种数学概念,它们一直没有付诸实践。
但是,如果不做全职相关的工作开发,自己开一些学习项目可行吗?和现在的各种框架相比,知道能做什么是很好的,即使做的不好。
我从周志华的《人工智能》这本书开始。刚看了开头,觉得挺好看的。一步一步,从一个例子开始,我做了以下笔记。

1. 用常见的例子一步步解释什么是机器学习
先从摘西瓜的例子说起:为什么成熟了,色泽翠绿,根部卷曲,声音浑浊,就可以判断它是好瓜呢?
因为我们吃过很多西瓜,看过很多西瓜,我们可以根据颜色、根、敲的特点做出相当不错的判断。
**过渡带来学习体验:**同样,我们从以前的学习经历中知道,如果我们努力工作,理解概念,做功课,我们自然会取得好成绩。可见,我们能做出有效的预测吗?正是因为我们积累了很多经验,通过运用经验,我们可以在新的情况下做出有效的决策。
**进一步说机器学习:**如果计算机科学是研究“算法”,那么同样可以说机器学习是研究“学习算法”。

2.通过西瓜的例子学习一些相关的术语
1. 以数据表格方式学习
把西瓜的例子总结成下表:
| 序号 | 色泽 | 根蒂 | 敲声 |
|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 |
| 2 | 乌黑 | 稍蜷 | 沉闷 |
| … |
查看表格以了解一些相关术语:
- **数据集:** 整个表的记录集合。
- 示例 (instance) 或样本 (sample):每条记录是关于一个事件或对象(这里是一个西瓜)的描述,称为一个示例 (instance) 或样本 (sample)。有时整个数据集亦称一个”样本”因为它可看作对样本空间的一个采样,通过上下文可判断出”样本”是指单个示例还是数据集。
- **属性 (attribute) 或特征(feature):**表格中的“色泽”、“根蒂”、“敲声”。
- **属性值 (attribute va1ue):**表格中的“色泽”、“根蒂”、“敲声”对应的值。
2. 还记得坐标系么
对于单个记录,通过“颜色”、“根音”和“敲击声”三个属性来识别,如下图所示:
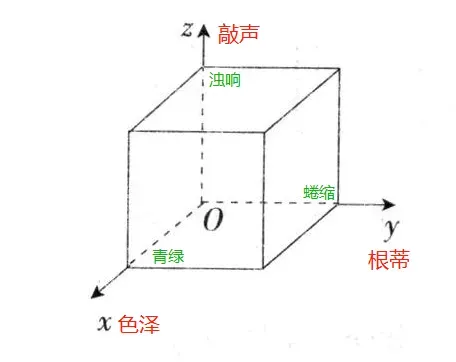
作为坐标轴,每个属性构成一个三维坐标系。记住坐标系,希望没有还给老师。
属性张成的空间称为**“属性空间” (attribute space) “样本空间” (sample space) 或”输入空间”**,即图中的长方体。
当然,实际上一个样本(西瓜)肯定不止这三个属性,这里只是举例。每个属性代表一个坐标轴,那就会组成一个d维空间,d为样本的属性数。
每个西瓜都可在这个空间中找到自己的坐标位置。由于空间中的每个点对应一个坐标向量,因此我们也把…个示例称为一个**“特征向量” (feature vector)。**
3. 训练相关的一些术语
从数据中学得模型的过程称为**“学习” (learning) 或”训练” (training)**;
这个过程通过执行某个学习算法来完成.训练过程中使用的数据称为**“训练数据” (training data)** ;
其中每个样本称为一个训练样本” (training sample),;
训练样本组成的集合称为”训练集” (training set).
学得模型对应了关于数据的某种潜在的规律,因此亦称”假设” (hypothesis);
这种潜在规律自身,则称为**“真相”或”真实” (ground-truth)** ;
学习过程就是为了找出或逼近真相.本书有时将模型称为”学习器” (learner),可看作学习算法在给定数据和参数空间上的实例化.
训练不止需要样本的属性信息,还需要样本的”结果”信息,例如” ((色泽:青绿;根蒂二蜷缩;敲声=浊响),好瓜)” .这里关于示例结果的信息,例如”好瓜”,称为标记 (labe1);
拥有了标记信息的示例,则称为**“样例” (example)**。如下图

若我们欲预测的是离散值,例如”好瓜” “坏瓜”,此类学习任务称为**“分类” (classification)**;
若欲预测的是连续值?例如西瓜成熟度 0.95 0.37,此类学习任务称为**“回归” (regression)**.
对只涉及两个类别的**“二分类” (binary classification)** 任务,通常称其中一个类为正类(positive class),另一个类为**“反类” (negative class);**
涉及多个类别时,则称为**“多分类” (multi-class classificatio)**任务。
学得模型适用于新样本的能力,称为”泛化” (generalization)能力.具有强泛化能力的模型能很好地适用于整个样本空间.

3. 假设空间
在数学公理系镜中,基于一组公理和推理规则推导出与之相洽的定理,这是演绎;而”从样例中学习”显然是一个归纳的过程,因此亦称”归纳学习” (inductive learning) .。
我们可以把学习过程看作一个在所有假设(hypothesis) 组成的空间中进行搜索的过程。如下图
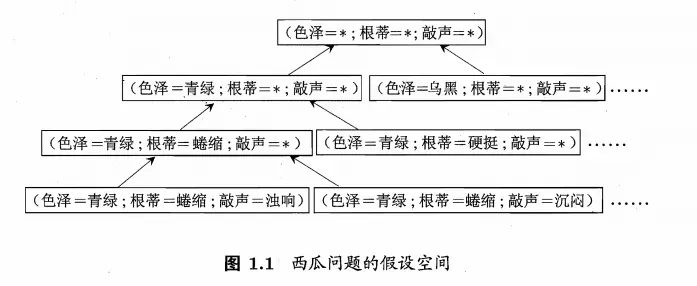
有多少种可能呢,就是一个排列组合。现实问题中我们常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即存在着一个与训练集一致的”假设集合”,我们称之为**“版本空间” (version space)**。
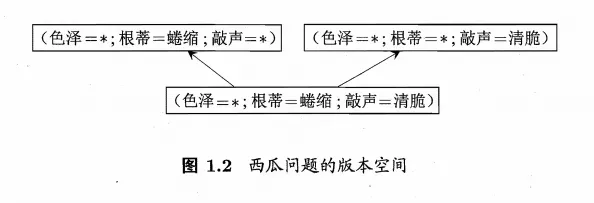

4. 归纳偏好
对于图1.2的西瓜版本空间,对应(色泽口=青绿;根蒂=蜷缩;敲声=沉闷)这个新收来的瓜,如果我们采用的是”好瓜<->(色泽=* )(根蒂=蜷缩)(敲声=*),那么将会把新瓜判断为好瓜,而如果采用了另外两个假设,则判断的结果将不是好瓜。若仅有表1。中的训练样本,则无法断定上述三个假设中明哪一个”更好, 那么计算机就傻了。
怎么办,任何有效的机器学习算法都必须有它的归纳偏好,否则会被假设空间中在训练集上看似“等价”的假设所迷惑,无法产生确定性的学习结果。
那么,有没有一般性的原则来引导算法确立”正确的”偏好呢? “奥卡姆剃刀” (Occam’s razor) 是一种常用的、自然科学研究中最基本的原则,即”若有多个假设与观察一致,则选最简单的那个。
总结
笼统地谈论“什么学习算法更好”是没有意义的,因为当考虑到所有潜在问题时,所有学习算法都同样好。谈算法的相对优劣,必须关注具体的学习问题;在某些问题上表现良好的学习算法在其他问题上可能并不令人满意。学习算法本身的归纳偏好是否匹配问题?往往起决定性作用。
版权声明:本文为博主FlyLolo原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Lolo_cs_dn/article/details/122948760