1.流水线介绍
管道将数据挖掘过程的每个步骤存储在工作流中。
在数据挖掘过程中使用管道可以大大降低代码和操作的复杂度,优化流程结构,有效减少常见问题的发生。
流水线通过Pipeline()来实例化,需要传入的属性是一连串数据挖掘的步骤,其中前几个是转换器,最后一个必须是估计器。
以经典的鸢尾花数据为例,通过下面这个简单例子的代码,我们来对比一下管道下的代码使用和不使用的区别。
具体过程是:得到数据后,先对其进行归一化,然后使用最近邻算法进行预测,最后使用交叉校验输出平均准确率。
2.示例
1.导包与获取数据
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
# 获取数据
dataset = load_iris()
# print(dataset)
X = dataset.data
y = dataset.target
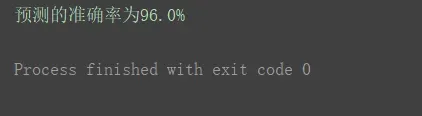
2.使用流水线前
X_transformed = MinMaxScaler().fit_transform(X)
estimator = KNeighborsClassifier()
scores = cross_val_score(estimator, X_transformed, y, scoring='accuracy')
print("预测的准确率为{0:.1f}%".format(np.mean(scores) * 100))
3.使用流水线后
scaling_pipeline = Pipeline([('scale', MinMaxScaler()),
('predict', KNeighborsClassifier())])
scores = cross_val_score(scaling_pipeline, X, y, scoring='accuracy')
print("预测的准确率为{0:.1f}%".format(np.mean(scores) * 100))
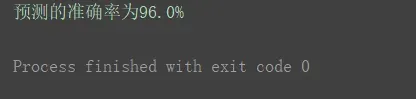
检验准确率也为96.0%,达到了和上边传统写法一样的效果。
版权声明:本文为博主侯小啾原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_48964486/article/details/122934688