人工智能(Artificial Intelligence)
定义
个人浅定义:让计算机机器模拟能到学习跟人一样掌握某种技能。类似于弱人工智能(Artificial Intelligence)。如果让计算机跟人类一样具有自主 的情感,具有自主意识。那么可以理解为强人工智能(Artificial Intelligence)。如果出现像钢铁侠这种的,智能化超过人类的,超级人工智能(Artificial Intelligence)。
人工智能(Artificial Intelligence)
- 强人工智能(Artificial Intelligence):认为有可能制造出真正能推理和解决问题的智能机器,这样的机器被认为是有自主意识的
- 弱人工智能(Artificial Intelligence):认为不可能制造出能真正进行推理和解决问题的智能 机器,这些机器只不过看起来像是智能的,但是并不真正拥有智能, 也不会有自主意识
- 超级人工智能(Artificial Intelligence):机器的智能彻底超过了人类,“奇点”2050年到来?
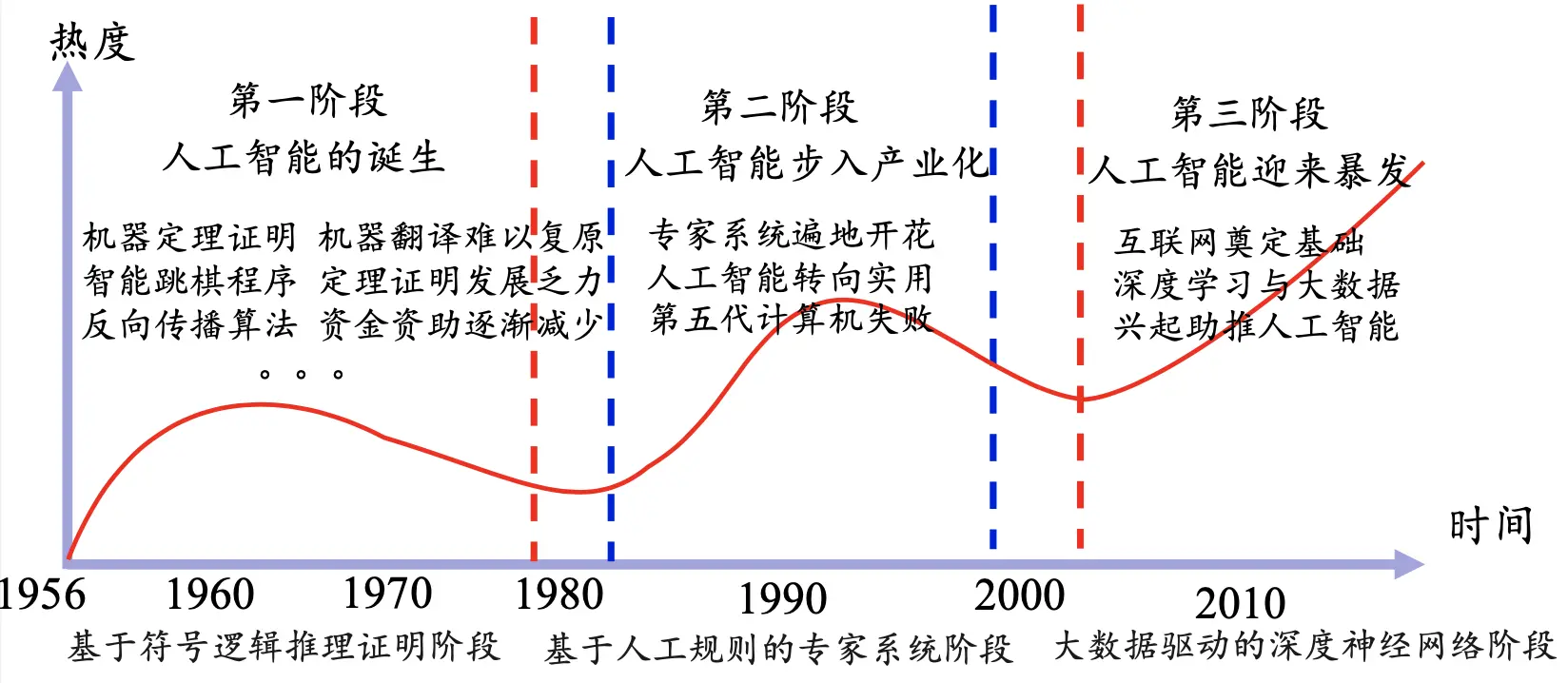
历史
机器学习(machine learning)
定义:从已知数据中获得规律,并利用规律对未知数据进行预测的技术
分类,按照监督方式
-
有监督学习(Supervised learning),有标签有数据,学习已有标签的数据,来对数据进行预测。
-
半监督学习(Supervised learning)(Semi-Supervised Learning),少部分有标签,大部分没标签,也就是少部分已知,大部分未知,利用少部分的这份数据,来对着未知标签进行学习。目钱也归为自监督学习(Supervised learning)一类。
-
无监督任务,没有标签,让计算机自己进行自学,通过相同相似的数据聚合在一起。
-
第一阶段,主要是当时因为感知机(Perceptron)连最简单的异或问题都没法解决,让人们进一步丧失了信心
-
第二阶段,辛顿提出了BP神经网络,解决了此类问题,并且BP网络的应用在大多数问题上证明有效且合适。但是BP网络在深层网络中的表现依然不尽人意,一直成为当时的’卡脖子‘问题。
-
06年辛顿提出了反向传播(Back propagation)算法。后面科学家发现了许多新兴的激活函数(Activation Function),初始化方式等,有效解决了梯度(gradient)爆炸(exploding gradient)和梯度(gradient)弥散问题。
-
知名大牛
- 辛顿 —- 提供饭碗的大大,提出BP和深度网络(deep network)
- 杨乐坤 – 卷积(convolution)神经网络(CNN网络)的大大,辛顿学生
- Bengio – 小花书的作者之一,然后入门表示看不懂。。LSTM是他干的!
- 知名网红老师:吴恩达,入门首选。
-
知名机构
- DeepMind
- OpenAI(人工智能(Artificial Intelligence))
深度学习(Deep learning)
深度学习(Deep learning)定义:一般是指通过训练多层网络结构对未知数据进行分类或回归(Regression),体现深度,直接体现就是层数多了…
深度学习(Deep learning)分类:有监督学习(Supervised learning)方法——深度前馈网络(feedforward network)(deep feedforward network)、卷积(convolution)神经网络(CNN网络)、循环神经网络(RNN网络)等;无监督任务方法——深度信念网、深度玻尔兹曼机(Deep Boltzmann Machine)(Boltzmann machine),深度自编码(code)器(Autoencoder)等。
主要应用
CV:目标目标检测,姿态估计,图像分割、分类。
语音:语音合成,识别
NLP:文字,情感,翻译
~~~ 忘了,还有个TTS
数学基础
张量(Tensor)基本知识
张量(Tensor):万物皆可张量(Tensor),
标量———> 0 维度张量(Tensor)

向量———> 1维度张量(Tensor)
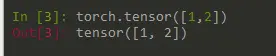
矩阵(matrix)———> 2 维度张量(Tensor)
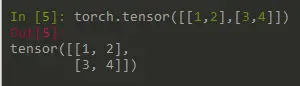
张量(Tensor)———> 3 维度以及以上,张量(Tensor)
以一张RGB 的224*224图像为例。
矩阵(matrix)的秩:
矩阵(matrix)列向量中的极大线性无关(linearly independent)组的数目,记作矩阵(matrix)的列秩,同样可以定义行秩。行秩=列秩=矩阵(matrix)的秩,通常记作rank(A)。
矩阵(matrix)的逆
若矩阵(matrix)A为方阵,当 rank(A_{n×n})<nrank(A n×n)<n时,称A为奇异矩阵(matrix)或不可逆矩阵(matrix);
若矩阵(matrix)A为方阵,当 rank(A_{n×n})=nrank(A n×n)=n时,称A为非奇异矩阵(matrix)或可逆矩阵(matrix)。

奇异矩阵(matrix)求逆(invert)比较难,,利用这个原理,最简单的解决办法可以利用最小二乘法(The least square method)。
矩阵(matrix)的广义(Lagrangian generalized Lagrangian)逆矩阵(matrix)
- 如果矩阵(matrix)不为方阵或者是奇异矩阵(matrix),不存在逆矩阵(matrix),但是可以计算其广义(Lagrangian generalized Lagrangian)逆矩阵(matrix)或者伪逆(Moore-Penrosepseudoinverse Moore-Penrose)矩阵(matrix);
- 对于矩阵(matrix)A,如果存在矩阵(matrix) BB 使得 ABA=AABA=A,则称 BB 为 AA 的广义(Lagrangian generalized Lagrangian)逆矩阵(matrix)。
矩阵(matrix)分解(decompose)
机器学习(machine learning)中常见的矩阵(matrix)分解(decompose)有特征分解(eigendecomposition)(decompose)和奇异值(singular value)分解(decompose)(Singular Value Decomposition)。
先提一下矩阵(matrix)的特征值(eigenvalue)和特征向量(Feature vector)的定义:


矩阵(matrix)特征分解(eigendecomposition)(decompose)
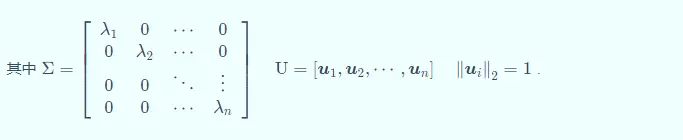


总结其实:一个向量可以有在维度内的多个正交(orthogonal)向量组合而成,是不是有点像高中的,一个向量可以由多个向量线性组合(linear combination)组成。
常见的概率分布(probability distribution)(Distribution)
0-1 分布(Distribution)(请说伯努利分布(Distribution),高大上些):

二项分布(Distribution)
- 重复n次伯努利实验,实验之间相互独立。
- 如果每次试验时,事件发生的概率为p,不发生的概率为1-p,则n次重复独立试验中事件发生k次的概率为

均匀分布(uniform distribution)(Distribution)
均匀分布(uniform distribution)(Distribution),又称矩形分布(Distribution),在给定长度间隔[a,b]内的分布(Distribution)概率是等可能的,均匀分布(uniform distribution)(Distribution)由参数a,b定义,概率密度函数(probability density function)为

高斯(RBM Gaussian RBM)分布(Gaussian distribution)(Distribution) ***
高斯(RBM Gaussian RBM)分布(Gaussian distribution)(Distribution),又称正态分布(normal distribution)(Distribution)(normal),是实数中最常用的分布(Distribution),由均值μ和标准差(standard deviation)σ决定其分布(Distribution),概率密度函数(probability density function)为:

指数分布(exponential distribution)(Distribution)
常用来表示独立随机事件发生的时间间隔,参数为λ>0的指数分布(exponential distribution)(Distribution)概率密度函数(probability density function)为: 
特点:无记忆性
多变量概率分布(probability distribution)(Distribution)
条件概率(conditional probability)
事件X在事件Y发生的条件下发生的概率,P(X|Y)
联合概率
两个事件X和Y共同发生的概率,P(X,Y)
条件概率(conditional probability)和联合概率的关系

贝叶斯公式(重点掌握)

常用统计量
方差:衡量变量与数学期望的偏离程度。

协方差(covariance):其实可以衡量变量与变量之间的相关性(除此之外还有联合概率公式、余弦相似、互信息(Mutual information)等等):
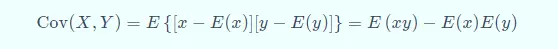
信息论
熵(Entropy)
- 衡量信息的多少。
-
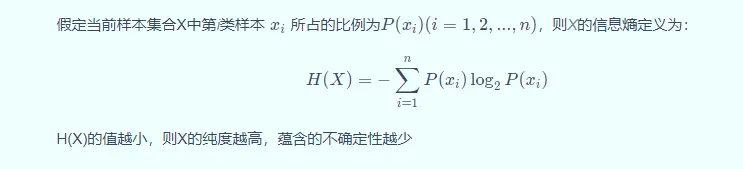
联合熵
两个随机变量(random variable)X和Y的联合分布(Distribution)可以形成联合熵,度量二维随机变量(random variable)XY的不确定性(deterministic):
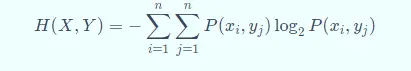
条件熵(Conditional entropy)
在随机变量(random variable)X发生的前提下,随机变量(random variable)Y发生带来的熵,定义为Y的条件熵(Conditional entropy),用H(Y|X)表示,定义为:
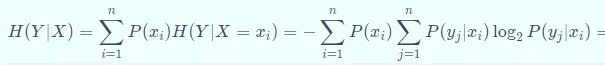
条件熵(Conditional entropy)用来衡量在已知随机变量(random variable)X的条件下,随机变量(random variable)Y的不确定。 熵、联合熵和条件熵(Conditional entropy)之间的关系:
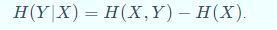
决策树(Decision tree)算法中,就是利用前后熵的信息差异大小,来划分树节点
互信息(Mutual information)
看起来,就是非公共部分
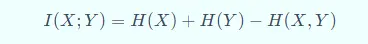
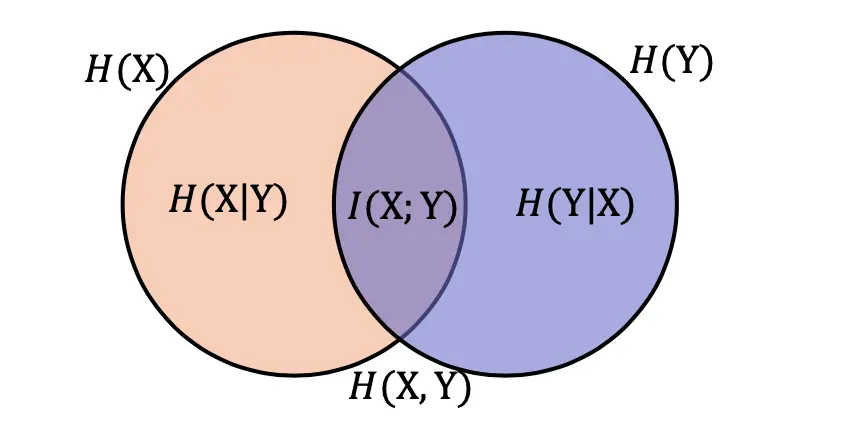
KL散度(KLdivergence)(Divergence),相对熵
相对熵又称KL散度(KLdivergence)(Divergence),是描述两个概率分布(probability distribution)(Distribution)P和Q差异的一种方法,记做D(P||Q)。在信息论中,D(P||Q)表示用概率分布(probability distribution)(Distribution)Q来拟合真实分布(Distribution)P时,产生的信息表达的损耗,其中P表示信源的真实分布(Distribution),Q表示P的近似分布(Distribution)。
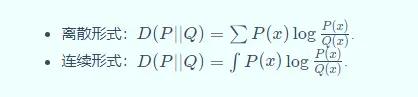
交叉熵(Cross entropy)
多分类(Multi-class classification)常用softmax,二分类(Binary classification)常用sigmoid(Sigmoid).
一般用来求目标与预测值之间的差距,深度学习(Deep learning)中经常用到的一类损失函数(Loss function)度量,比如在对抗生成网络( GAN )中
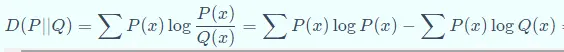
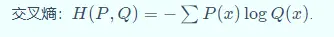
最小二乘估计
最小平方法,是一种数学优化方法。它通过最小化误差的平方和寻找数据的最佳函数匹配。最小二乘法(The least square method)经常应用于回归(Regression)问题,可以方便地求得未知参数,比如曲线拟合、最小化能量或者最大化熵等问题。
优化目标:minw∣∣Xw−y∣∣22\min_{w} || X w – y||_2^2wmin∣∣Xw−y∣∣22
普通最小二乘法(The least square method)的系数估计依赖(dependency)于特征的独立性。当特征与设计矩阵(matrix)(design matrix)x的列相关时具有近似线性的相关性,设计矩阵(matrix)(design matrix)变得接近奇异,因此,最小二乘估计对观察到的目标中的随机误差变得高度敏感,从而产生很大的方差。例如,在没有实验设计的情况下收集数据时,可能会出现这种多重共线性的情况。
参考github:
链接: datawhale.
版权声明:本文为博主小陈phd原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_42917352/article/details/121370504