MixMatch: A Holistic Approach to Semi-Supervised Learning
官方代码—tensorflow版本
pytorch版
纸
2.1以上的内容都是简介,概述这里就不进行讲解。
2.1 Consistency Regularization 一致性正则
这个技巧是什么意思,就是说对一张图片进行2种不同的数据增强后,给模型预测,预测的y1和y2,这y1和y2的结果要一致。为什么说是正则,因为添加了扰动噪声,为什么说一致性,因为预测出来的y1和y2要一致。
那在半监督中这y1和y2的loss如何计算?论文中:
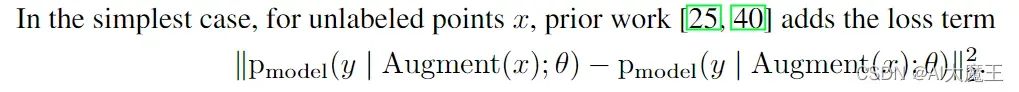
就是y1和y2用MSE_loss均方差loss 在pytorch中是F.mse_loss。
代码实现:Lu = F.mse_loss(output_u,trg_u)
pytorch版的这个更加粗暴

2.2 Entropy Minimization—熵最小化
信息熵越小,包含的信息量越大
分类模型在计算loss的时候才用交叉熵loss;如果输出的值比较implicitly(含蓄模糊)那么对计算loss的时候有影响。所以论文中提出自己的方法”sharpening(类似图片的锐化操作)“
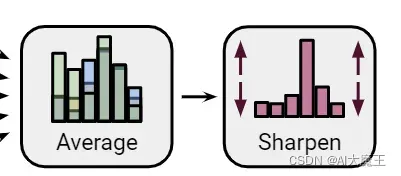
pt = p**(1/args.T)
targets_u = pt / pt.sum(dim=1, keepdim=True)
targets_u = targets_u.detach() 2.3 Traditional Regularization — 传统的正则方法
简单的说就是论文说他会用到L2正则去优化模型参数和mixup数据增强
3 MixMatch
从这里开始,论文的方法将正式开始。
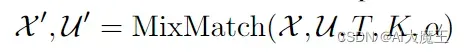
X是标注了的数据图片,X′ 是X进行数据增强后的图片,U是没标注的数据图片,U′是对U进行数据增强后的进行猜测后的标签(也就是进行了模型预测),T,K,a都是超参数
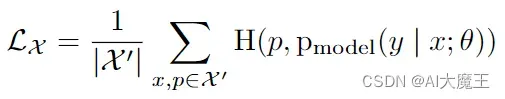
说的是标注了的图片如何求loss是用交叉熵
Lx = -torch.mean(torch.sum(F.log_softmax(outputs_x, dim=1) * targets_x, dim=1))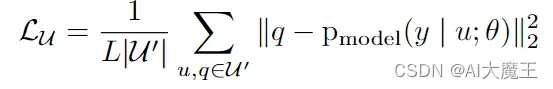
说的是没标注的图片如何求loss
Lu = torch.mean((probs_u - targets_u)**2)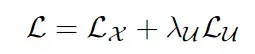
总的loss就等于两者相加
def linear_rampup(current, rampup_length=args.epochs):
if rampup_length == 0:
return 1.0
else:
current = np.clip(current / rampup_length, 0.0, 1.0)
return float(current)
Loss = Lx+Lu* linear_rampup(epoch)3.1 Data Augmentation—数据增强
有标签的数据,只做一次增广, ˆxb = Augment(xb),没有标签的数据,要做 K 次增广,ub,k = Augment(ub),k ∈(1,…,K)
3.2 Label Guessing—标签猜测
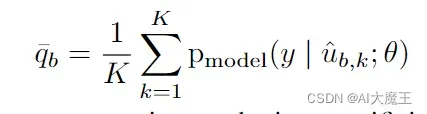
对无标注的数据进行猜测,先进行K次数据增强,然后用模型预测这K个,然后进行求平均
outputs_u = model(inputs_u)
outputs_u2 = model(inputs_u2)
p = (torch.softmax(outputs_u, dim=1) + torch.softmax(outputs_u2, dim=1)) / 2
整个算法流程algorithm
Sharpening
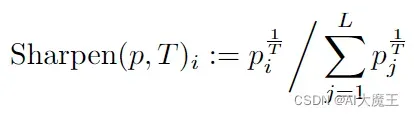
sharpening是如何实现的呢
pt = p**(1/args.T)
targets_u = pt / pt.sum(dim=1, keepdim=True)3.3 MixUp
我个人觉得这部分是本文的主要内容
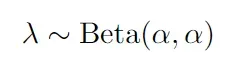
先获取λ 因为a=0.75 那么beta分布为:
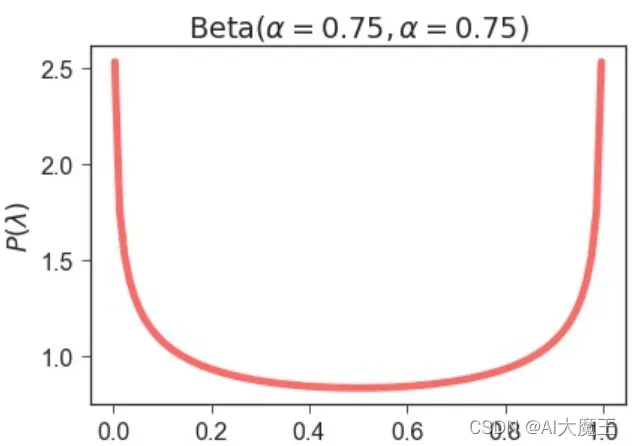
大部分值都是0到1之间
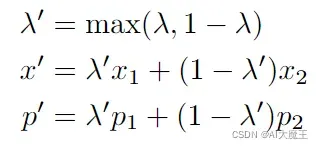
而后用这个公式计算mixup后的x和p
l = np.random.beta(args.alpha, args.alpha)
l = max(l, 1-l)
idx = torch.randperm(all_inputs.size(0))
input_a, input_b = all_inputs, all_inputs[idx]
target_a, target_b = all_targets, all_targets[idx]
mixed_input = l * input_a + (1 - l) * input_b
mixed_target = l * target_a + (1 - l) * target_ball_inputs = torch.cat[有标记的x,无标记的u,无标记的u2]
all_targets = torch.cat[y,无标记的y,无标记的y2]
# model forward
mixuped_logits = model(mixed_input) # [3*N,10]
logits_x = mixuped_logits[:HP.batch_size] # [N,10]
logits_u = mixuped_logits[HP.batch_size:] # [2*N,10]最后分别计算loss最后加起来。然后进行反向传播
3.4 Loss Function–loss函数
这是之前说过的,
3.5 Hyperparameters—超参数
之前前面提到的T=0.5 K=2 a=0.75
λU=np.clip(a=max_v * (step / MAX_STEP), a_min=0, a_max=max_v)
λU 采用不超过a=0.75 随着训练步数的增加而增加到0.75就不增加了
4 Experiments—实验结果
这部分是说在使用了本文的方法之后,取得了令人难以置信的效果,所以无需赘述,简单介绍一下
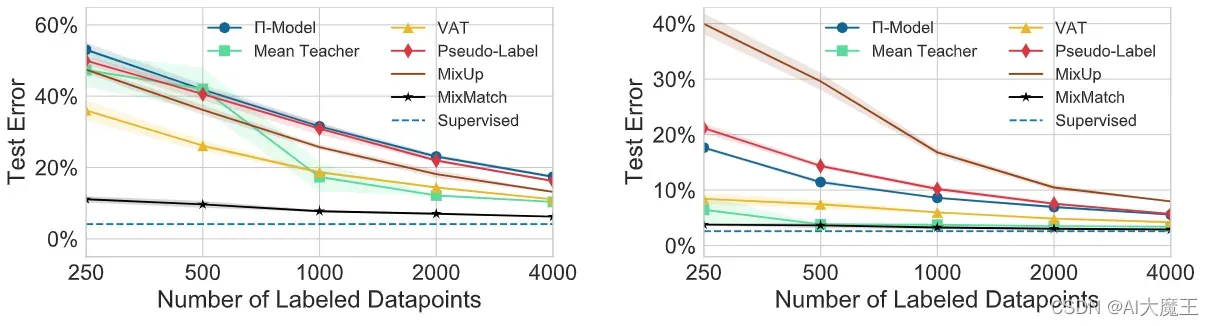
只用了2000个标注好的图片就达到了和全监督训练是差不多的水平。就是非常的牛,非常的state of the art
4.1 Implementation details
这里提了一下,用到了EMA(exponential moving average)指数移动平均
class WeightEMA:
def __init__(self, model, ema_model, alpha=0.999):
self.model = model
self.ema_model = ema_model
self.alpha = alpha
self.params = list(model.state_dict().values())
self.ema_params = list(ema_model.state_dict().values())
self.weight_decacy = 0.0004
for param, ema_param in zip(self.params, self.ema_params):
param.data.copy_(ema_param) # 是把ema_param的产生copy 给param
def step(self):
for param, ema_param in zip(self.params, self.ema_params):
if ema_param.dtype == torch.float32: # model weights only!
ema_param.mul_(self.alpha)
ema_param.add_(param * (1 - self.alpha))
# apply weight
param.mul_((1 - self.weight_decacy))代码
我自己搜索出来的代码上传到了我的github上分享给大家
这个代码和前面大师的pytorch版本也是差不多的。
版权声明:本文为博主AI大魔王原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Carlsummer/article/details/123186276