参考文献:
Speech Recognition (option) – Alignment of HMM, CTC and RNN-T哔哩哔哩bilibili
2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 Alignment – 7 – 知乎 (zhihu.com)
本次省略所有引用论文
目录
一、E2E 模型和 CTC、RNN-T 的区别
E2E 模型的思路
-
实际上,对于端对端模型来说,比如 LAS,它在解码的时候都是去寻找一个 token 序列,使得 P of Token Sequence Y given Acoustic features vectors X 最大。
-
为什么这么说?我们来简单看一下 LAS 的结构,每一次我们都是输出一个概率分布,我们就可以将这个概率分布作为输出 token 的概率,因此将最后所有 token 的概率相乘,结果就是 P(Y|X)。
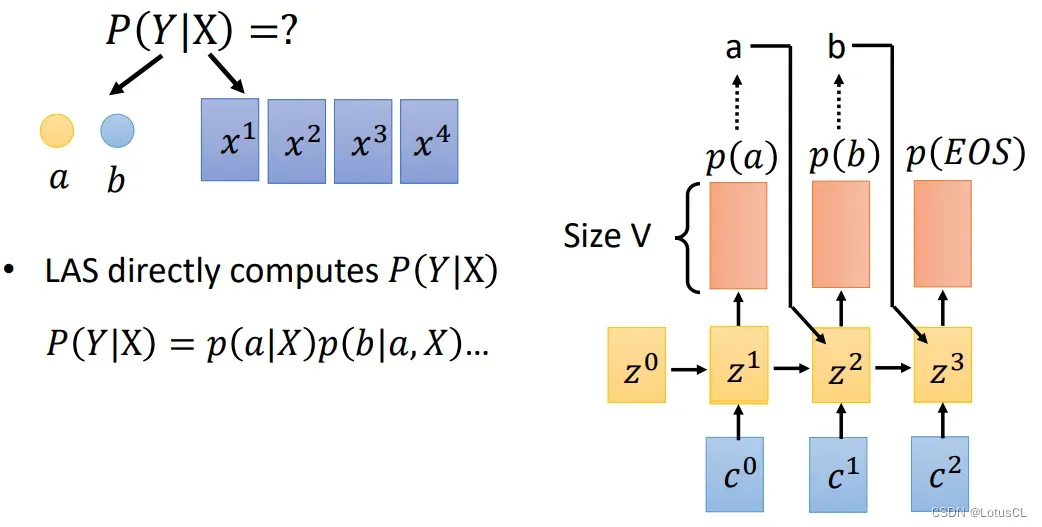
-
当然,在解上面那个式子的时候,我们也并不是直接找出每一个概率分布中最大的 token,而是采用束搜索等策略去找最优解。而在训练过程中,我们也可以将训练目标带入上面的式子。假设 Y^hat 就是最终正确的结果,那么训练目标就是找一个最优的模型参数,来让P(Y^hat|X)越大越好。
CTC、RNN-T 模型的思路
-
对于 CTC 和 RNN-T,由于 token 序列和声学特征序列的长度不同,直接计算 token 序列对应的声学特征序列的概率是做不到的。它们额外的需要对齐操作。
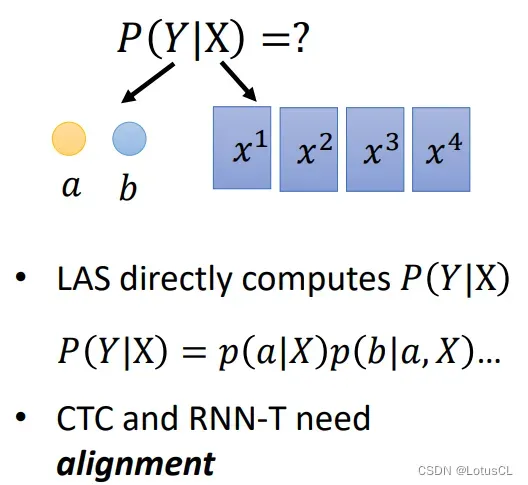
-
以 CTC 为例,假设输出的 token 序列为 “ab”,声学特征序列有 4 个,由于二者长度不同,所以我们需要让 a 和 b 进行复制,或者在其中插入 ∅ 符号,让它的长度变得和输入的声学特征序列长度一致,才能计算P(Y|X)。
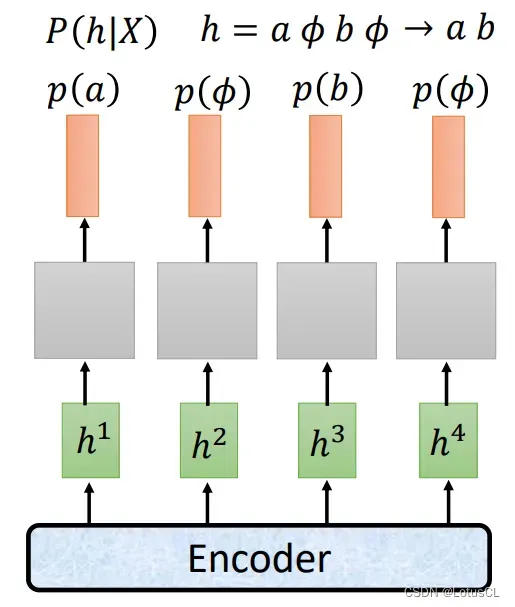
-
因此实际上,CTC 和 RNN-T 只能计算某一种对齐方式的概率,而难以计算产生某一个 token 序列的概率。那我们应该怎么办?这里采取的解决方法是借鉴 HMM 的做法,将所有可能的对齐方式的概率都加起来,当作最终这个 token 序列的概率,公式如下。此外,训练和解码过程都可以参考之前端对端模型的方式。
二、待解决的问题
-
首先,我们应该如何穷举所有可能的对齐方式?实际上,CTC 和 RNN-T 与 HMM 的穷举方式相同。
-
其次,我们应该如何将所有对齐方式的概率进行相加?
-
然后,我们应该如何训练这些模型?HMM 采用的是 forward 算法,而 CTC 和 RNN-T 使用的是梯度下降法,那么对于很多个对齐方式加起来的概率结果,我们要怎样算梯度呢?
-
最后,我们应该如何进行推断与解码,去解决我们的目标式子呢?

三、对齐方式介绍
-
HMM,CTC 和 RNN-T 要做的对齐有相似的地方,也有不同。我们假设输入有 6 个声学特征向量(长度 T=6),以 character 为 token 单位(虽然对 HMM 来说这个单位还是太大了),输出是 “c”, “a”, “t”(长度 N=3)。

-
对于 HMM 来说,它要做的事情就是将 cat 3个字母进行重复,让重复后的长度等于声学特征向量序列长度。

-
对于 CTC 来说,它有两种方式,一种是对 cat 3个字母进行复制,也可以在其中插入 符号,最终使得长度等于声学特征向量序列长度。(参考它的推理过程,是将 ∅ 符号拿掉,将 ∅ 符号之间重复的字母缩减为一个字母)

-
对于 RNN-T,则是在其中加入和声学特征向量序列长度相同个数的 ∅ 符号。
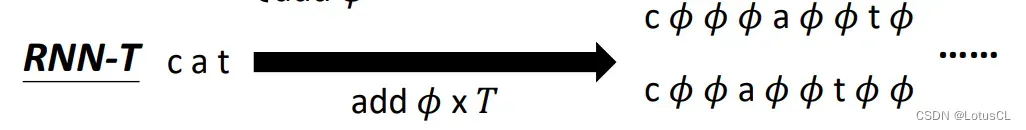
四、穷举方式
穷举 HMM
-
我们应该如何穷举 HMM 的所有对齐方式呢?我们可以将刚刚讲述的 HMM 对齐方式转化为伪函数过程:

-
这里, 字母 c 重复 t1 次,a 重复 t2 次,以此类推
-
此外,由于必须出现所有的字母,所以 ti > 0。
-
-
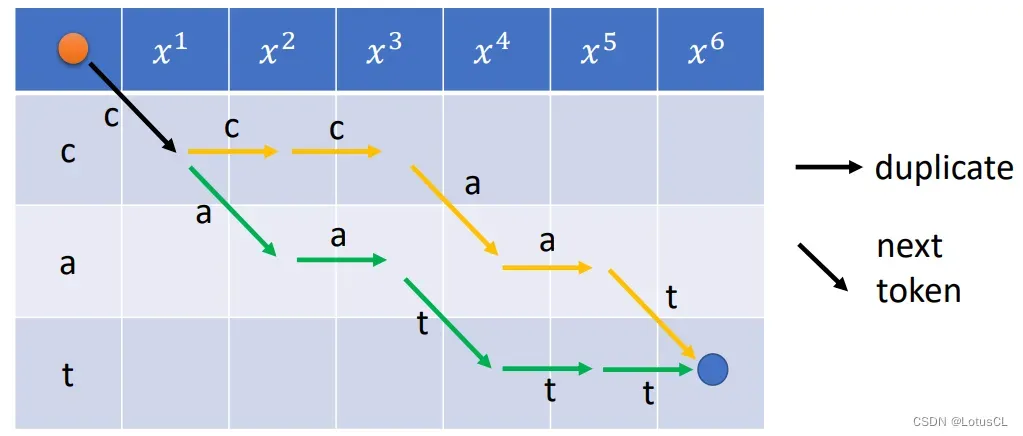
随后,我们就可以以此来绘制状态图(Trellis Graph),状态图如下:
-
我们需要从左上的红点到右下的蓝点。
-
走的方法可以是向右下走,也可以横着走。
-
向右下走代表输出下一个字母,横着走代表复制当前的字母。、
-
-
状态图可以很好地规避非法的对齐方式,非法的对齐方式是走不到终点的。
穷举 CTC
-
CTC 和 HMM 不同的地方在于,它还可以在其中插入 ∅ 符号,开头和结尾都可以插入,我们将这个过程转为伪函数如下:

-
首先是开头就可以输出 ∅ 符号,也可以选择不输出
-
其次就是每轮输出当前符号,和 ∅ 符号的数量
-
并且 token 数量和 ∅ 数量加在一起需要等于声学特征向量序列长度。
-
-
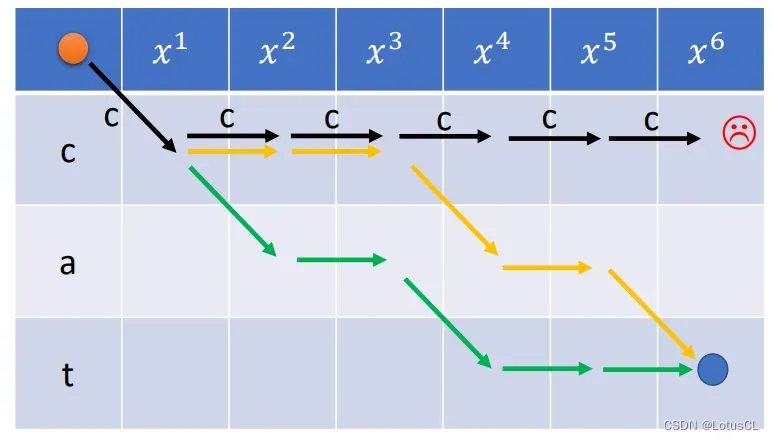
我们将状态图进行绘制,如下:
-
我们需要从红点移动向2个蓝点的其中一个。
-
开始出发的时候有两种选择,去 ∅ 行和去字母行。
-
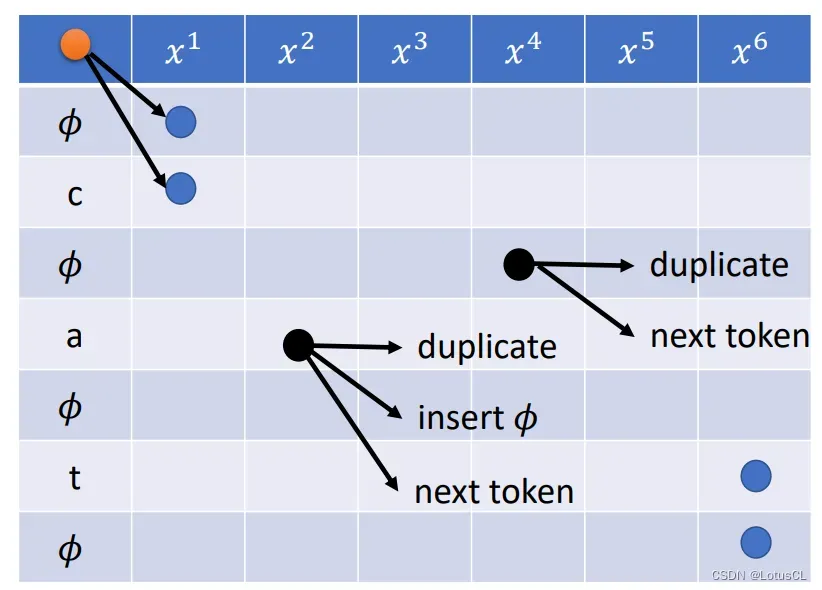
在字母行可以有三种选择:横走复制,右下走插入 ∅,走日即输出下一个字母。
-
-
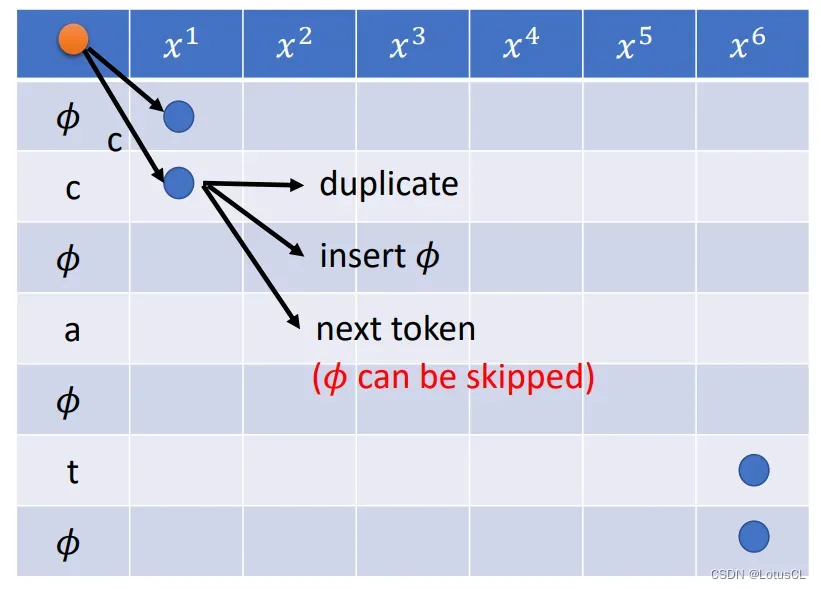
不过,如果一开始选择进入 ∅ 行,则走法与选择又会不一样:
-
相比于在字母行,∅ 行只有两种选择。
-
可以横走复制,可以右下走进入下一个 token,而不可以走日。
-
-
因此我们说,CTC 在不同的 row 有不同的走法。最终的终点也有两种。
-
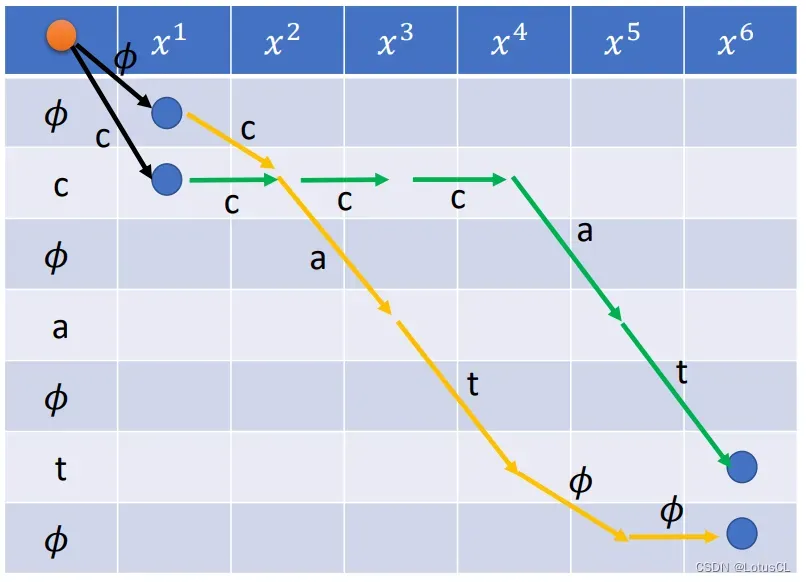
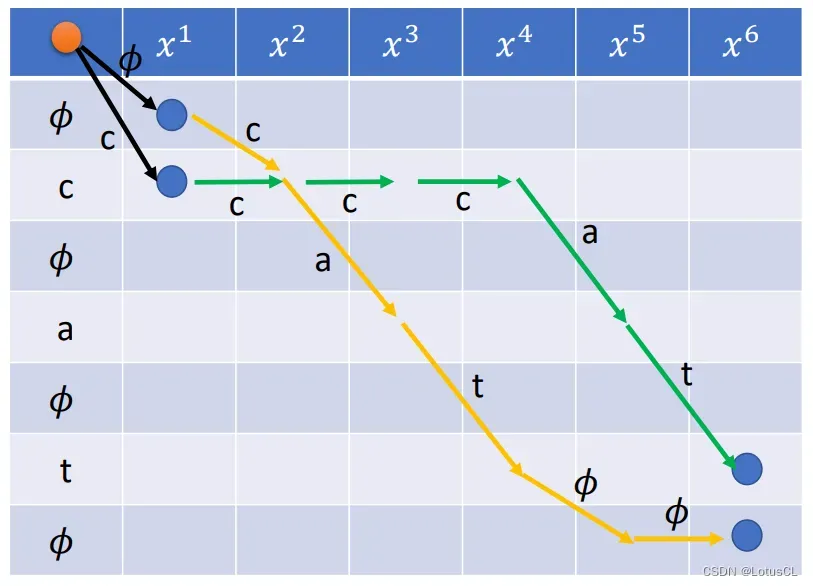
我们举几个合法的对齐方式的例子,并绘制其状态图:
-
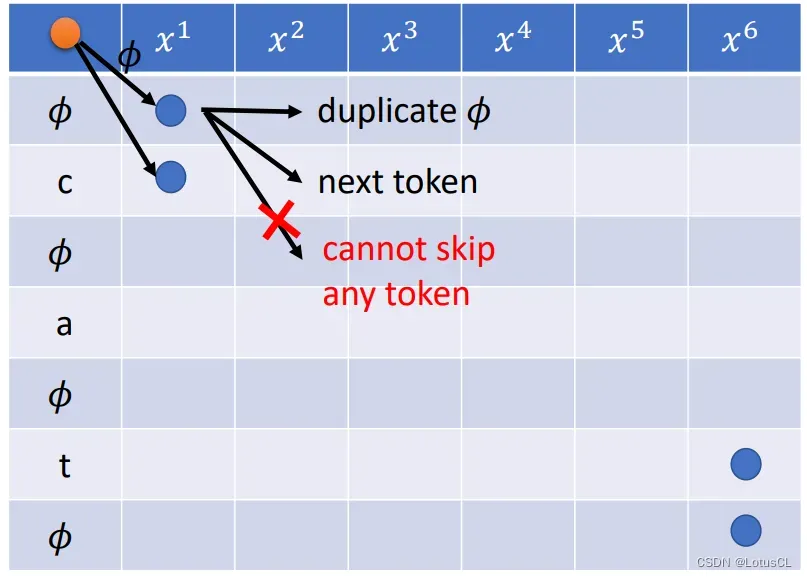
不过,CTC 也有特殊的情况。参考 CTC 在推理时采取的策略,如果遇到 token 序列中前后两个 token 相同的话,我们在第一个相同的 token 行中就只有两种走法,比如下面这个输出 ”see“ 的例子:

-
此时,在进入第一个 e 的行中,我们就只能有两种走法
-
可以进行复制,可以插入 ∅ 行,但是不能直接跳到下一个 e 行
-
如果直接进入下一个 e 行,那就代表连续输出两个 e,那么在推断时,CTC 就会将两个 e 融合在一起,最终只输出一个 e。
-
穷举 RNN-T
-
在 RNN-T 中则是插入和声学特征向量序列长度相同的 ∅,也就是 T 个 ∅。我们弄清楚它的规则后(一个声学特征向量可以一直输出 token,让它看个爽,直到输出 ∅ 为止,表示看爽了可以进入下一个向量),就可以将伪代码写出:

-
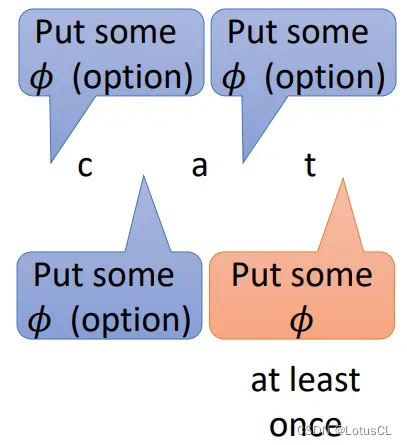
在 cat 三个字母中,我们有 4 个位置可以插入,并且由于 RNN-T 要判断是否结束,所以在 cat 最后的部分我们必须要插入 ∅,因为 RNN-T 看到 ∅ 就表示要进入下一个声学特征向量了
-
每一次,我们都会输出第 n 个 token,并输出一定数量(cn)的 ∅。
-
前几次可以选择不输出 ∅,但是最后一次 cN 必须输出 ∅。
-
cn 加起来的和必须要等于声学特征向量序列长度。
-
-
我们将上述过程转化为状态图,为了保证最后一定以 ∅ 结尾,我们在最后一行的右方又多挖了一个格子:
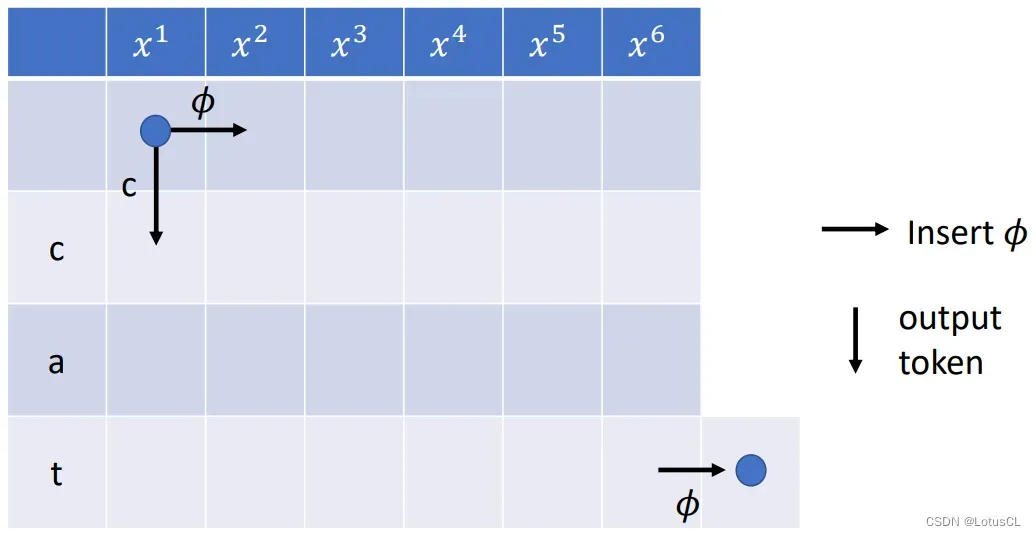
-
我们从左上方的蓝点,需要走到右下方的蓝点
-
一共有两种走法,一种是横走,表示插入 ∅;还有一种是往下走,表示进入下一个 token。
-
由此可见,最后一行向右多了个格子可以保证最后一步一定是横走插入 ∅。
-
-
我们绘制了几条可能的对齐方式,也给了不合法的对齐方式(走出框外):
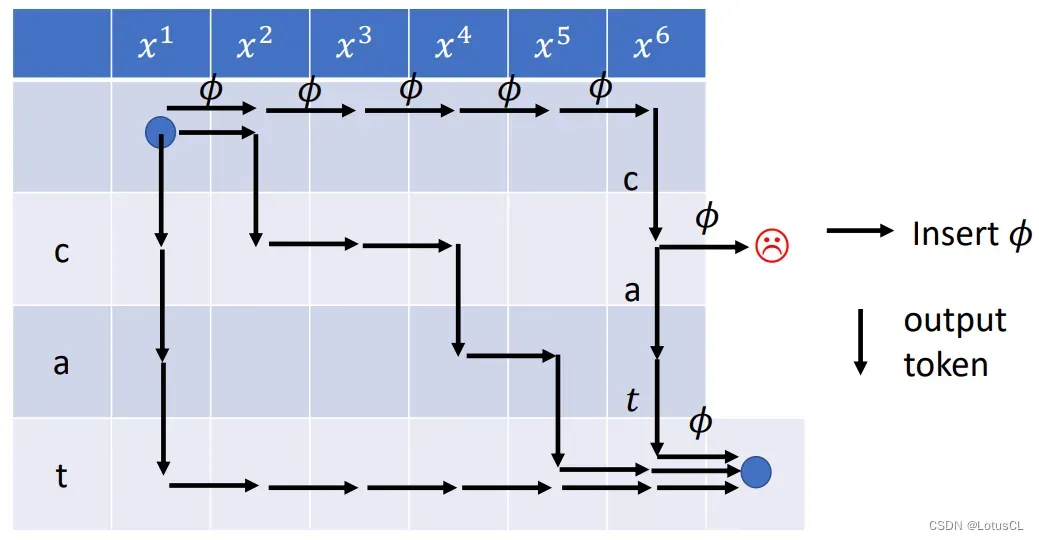
五、总结
-
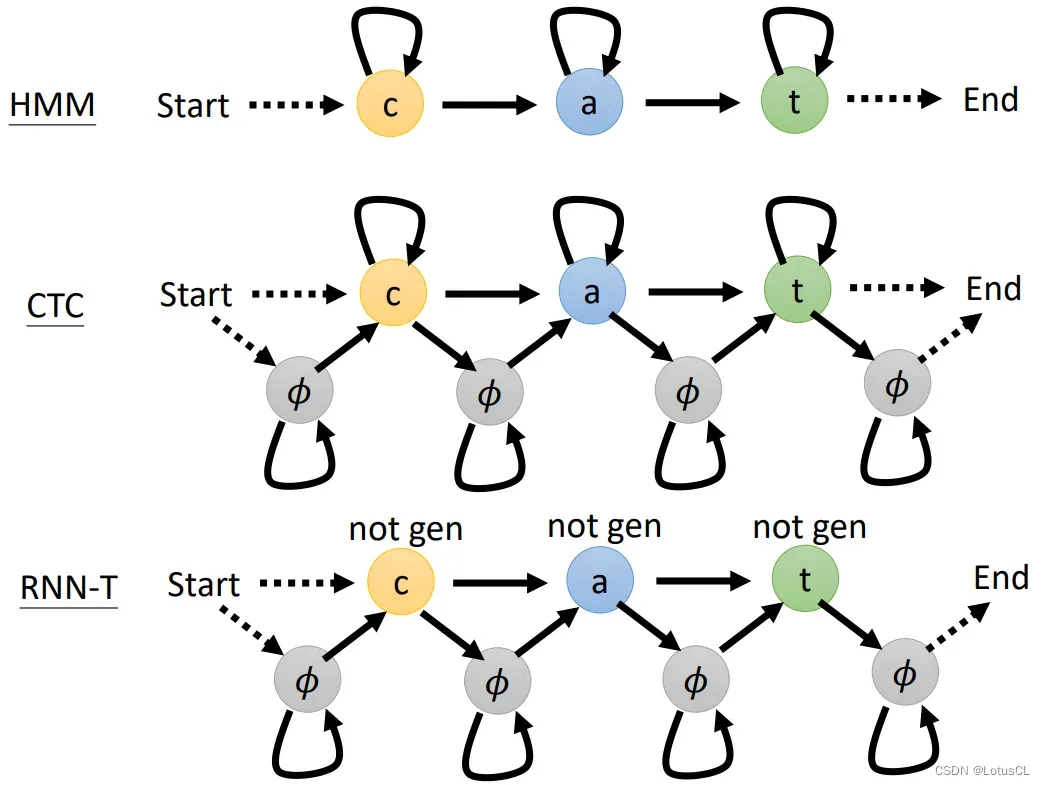
我们将每个模型的状态机图绘制而出进行比对:
-
HMM 从 c 开始,可以进行复制,也可以跳到下一个 token
-
CTC 可以从 ∅ 开始,也可以从 c 开始,也有两种结束方式(从 t 结束、从 ∅ 结束),可以进行复制,也可以选择去 ∅,也可以选择进入下一个 token。
-
RNN-T 则可以从 ∅ 或者 c 开始,不过最后一定以 ∅ 结束。并且每个token 进去以后就需要立马出来,而不可以再次生成当前的 token。
-
文章出处登录后可见!