整理:AI算法与图像处理
欢迎关注公众号 AI算法与图像处理,获取更多干货:

推荐
微信交流群现已有2000+从业人员交流群,欢迎进群交流学习,微信:nvshenj125

B站最新成果demo分享地址:https://space.bilibili.com/288489574
顶会工作整理Github repo:https://github.com/DWCTOD/CVPR2023-Papers-with-Code-Demo
论文速读
LCM-LoRA:通用stable diffusion 加速模块
标题: LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
论文:https://arxiv.org/pdf/2311.05556.pdf
github:https://github.com/luosiallen/latent-consistency-model
摘要:
潜在一致性模型 (LCM)(Luo 等人,2023)在加速文本到图像生成任务、以最少的推理步骤生成高质量图像方面取得了令人印象深刻的性能。LCM 是从预训练的潜在扩散模型 (LDM) 中提取出来的,仅需要 ∼32 个 A100 GPU 训练小时。该报告进一步扩展了 LCM 在两个方面的潜力:首先,通过将 LoRA 蒸馏应用于稳定扩散模型,包括 SD-V1.5 (Rombach et al., 2022)、SSD-1B (Segmind., 2023) 和 SDXL ( Podell 等人,2023),我们将 LCM 的范围扩展到更大的模型,内存消耗显着减少,实现了卓越的图像生成质量。其次,我们将通过LCM蒸馏获得的LoRA参数确定为通用的稳定扩散加速模块,命名为LCM-LoRA。LCM-LoRA 无需训练即可直接插入各种stable diffusion微调模型或 LoRA,从而成为适用于各种图像生成任务的通用加速器。与之前的数值 PF-ODE 求解器如 DDIM (Song et al., 2020)、DPM-Solver (Lu et al., 2022a;b) 相比,LCM-LoRA 可以被视为插件式神经 PF-ODE 求解器 具有很强的泛化能力
整体框架:
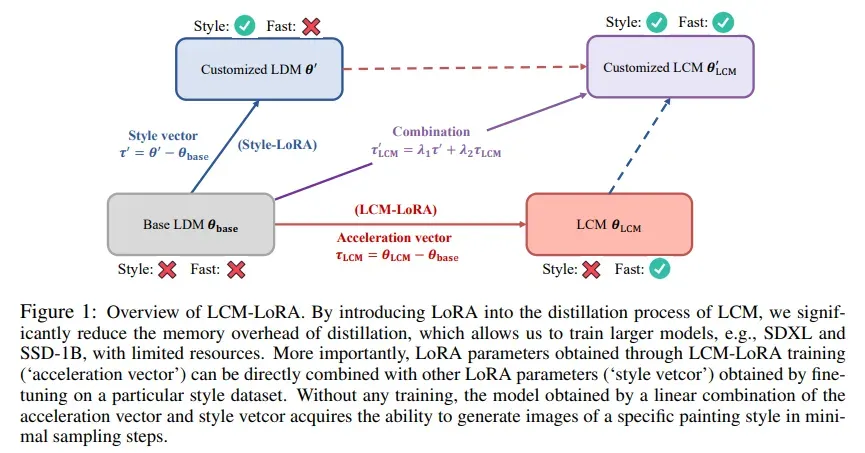
LCM-LoRA 整体框架。通过将LoRA引入LCM的蒸馏过程,我们显着减少了蒸馏的内存开销,这使得我们能够在有限的资源下训练更大的模型,例如SDXL和SSD-1B。更重要的是,通过 LCM-LoRA 训练获得的 LoRA 参数(“加速向量”)可以直接与通过在特定风格数据集上微调获得的其他 LoRA 参数(“风格矢量”)相结合。无需任何训练,通过加速度向量和风格向量的线性组合获得的模型就能够以最少的采样步骤生成特定绘画风格的图像。
算法流程:

效果展示:

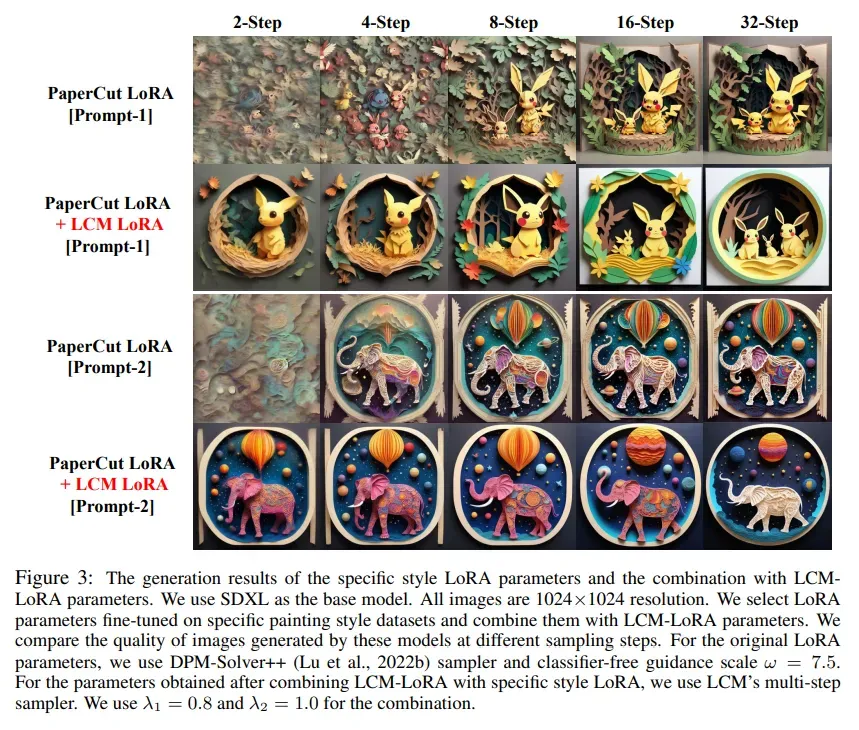
更多细节参考论文原文和GitHub项目,如果有帮助欢迎转发,感谢
工作整理
ICCV 2023
Updated on : 13 Nov 2023
total number : 0
Improved Positional Encoding for Implicit Neural Representation based Compact Data Representation
论文/Paper: http://arxiv.org/pdf/2311.06059
代码/Code: None
WACV 2024
Updated on : 13 Nov 2023
total number : 9
Semantic-aware Video Representation for Few-shot Action Recognition
论文/Paper: http://arxiv.org/pdf/2311.06218
代码/Code: None
MonoProb: Self-Supervised Monocular Depth Estimation with Interpretable Uncertainty
论文/Paper: http://arxiv.org/pdf/2311.06137
代码/Code: metrics.https://github.com/CEA-LIST/MonoProb
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
论文/Paper: http://arxiv.org/pdf/2311.06018
代码/Code: None
A Neural Height-Map Approach for the Binocular Photometric Stereo Problem
论文/Paper: http://arxiv.org/pdf/2311.05958
代码/Code: None
Automated Sperm Assessment Framework and Neural Network Specialized for Sperm Video Recognition
论文/Paper: http://arxiv.org/pdf/2311.05927
代码/Code: https://github.com/ftkr12/rostfine
PolyMaX: General Dense Prediction with Mask Transformer
论文/Paper: http://arxiv.org/pdf/2311.05770
代码/Code: None
GIPCOL: Graph-Injected Soft Prompting for Compositional Zero-Shot Learning
论文/Paper: http://arxiv.org/pdf/2311.05729
代码/Code: None
OmniVec: Learning robust representations with cross modal sharing
论文/Paper: http://arxiv.org/pdf/2311.05709
代码/Code: None
Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation
论文/Paper: http://arxiv.org/pdf/2311.05858
代码/Code: https://github.com/junia3/LayerwiseTTA
NeurIPS 2023
Updated on : 13 Nov 2023
total number : 1
Learning Human Action Recognition Representations Without Real Humans
论文/Paper: http://arxiv.org/pdf/2311.06231
代码/Code: https://github.com/howardzh01/ppma
文章出处登录后可见!