自从ChatGPT发布以来,人们看到了AGI时代的曙光,但是由于ChatGPT是闭源的,只能在官网体验和使用API进行访问,据OpenAI CEO说是出于AGI的安全性考虑,这样大大限制了很多研究人员和机构对于AGI的研究进展。Meta公司反其道行之,今年2月24日发布了半开源大语言模型LLaMA(中文意为“羊驼”),这是一组包含 7 到 650 亿个参数的基础大型语言模型,因其参数量远小于GPT-3,效果却仍能优于后者一度在圈内引起热议。之所以是半开源,是因为LLaMA模型的权重需要申请的。下面对LLaMA以及其扩展的模型进行简单总结:
一、LLaMA

论文地址:https://research.facebook.com/file/1574548786327032/LLaMA–Open-and-Efficient-Foundation-Language-Models.pdf
1.1)介绍
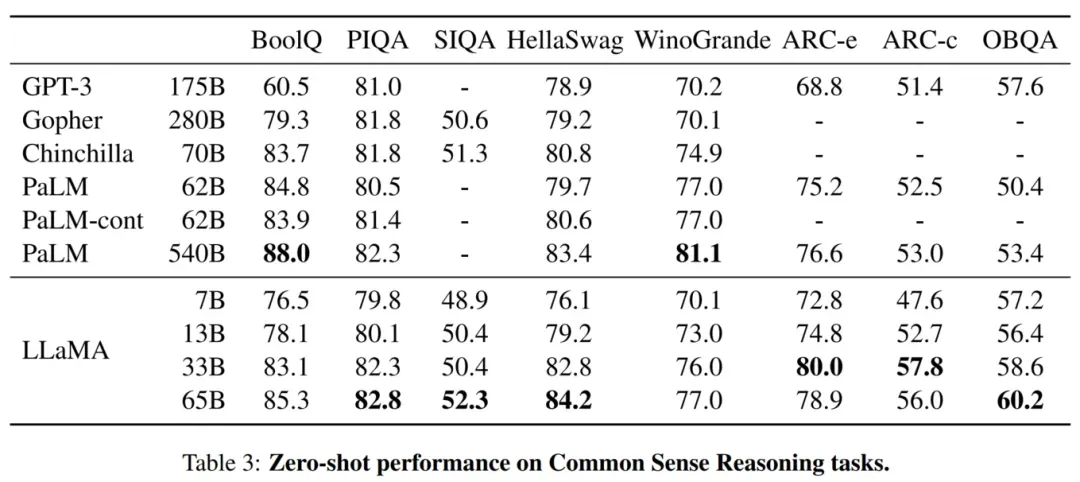
LLaMA,是Meta AI最新发布的一个从7B到65B参数的基础语言模型集合。在数以万亿计的token上训练模型,并表明有可能完全使用公开的数据集来训练最先进的模型,而不需要求助于专有的和不可获取的数据集。LLaMA-13B在大多数bechmark上超过了GPT-3(175B),而LLaMA-65B与最好的模型Chinchilla70B和PaLM-540B相比具有竞争力。
1.2)预训练数据
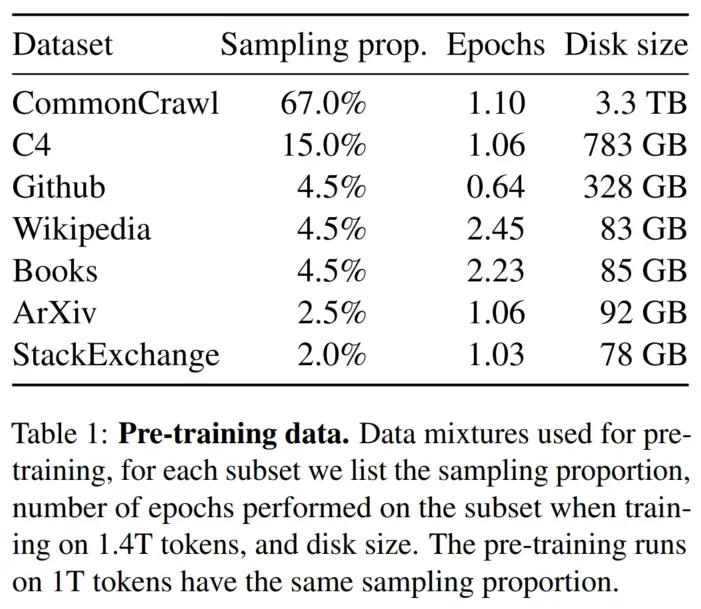
使用SentencePiece库的BPE算法进行数据切分,并且用bytes对不知道的UTF-8编码进行处理,最终得到的1.4T的token。
1.3)模型的架构与参数
模型架构采纳了其他模型中的一些改进,包括:
-
Pre-normalization,来自GPT-3,可以稳定训练。
-
normalize输入而非输出
-
使用RMSNorm
-
-
SwiGLU,来自PaLM,替换了ReLU来获得更好的效果。维度使用的是2/3*4d而不是PaLM中的4d。
-
Rotary Embedding,来自GPTNeo,替换了绝对位置编码。
其他的模型超参数见下表。
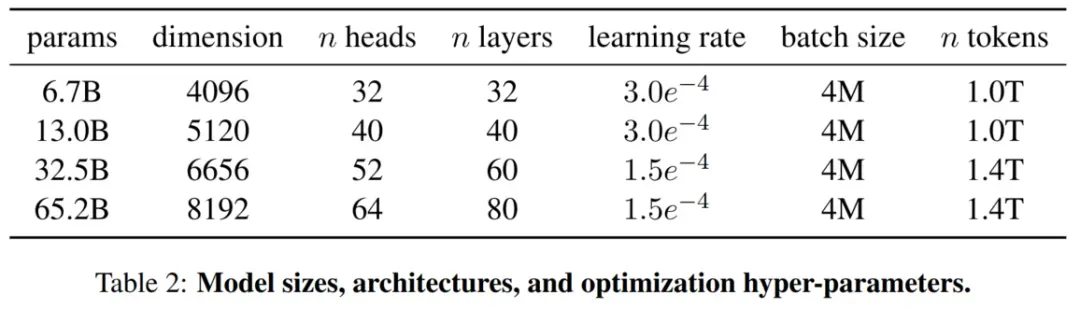
optimizer使用AdamW, beta1=0.9,beta2=0.95。使用cosine learning rate schedule, 最终的learning rate是最高值的十分之一,weight decay 是0.1,2000步warmup。
1.4)模型的性能
1.5)高效实现
-
使用了xformer中的高效的casual multi-head attention实现来内存占用的运行时间。灵感来自Paper
Self-attention does not need o(n^2) memory,并在Flashattention: Fast and memory-efficient exact attention with io-awareness.中使用。这个高效是由不存储注意力权重和不计算被mask的key/query分数来达到的。 -
减少了在反向传播阶段需要重新计算的激活值,具体来说,是将计算量比较大的中间结果存储下来,比如线性层的输出。
-
要实现这个,需要手动实现反向传播函数而不是依赖pytorch的autograd。
-
为了更好的达到这一点,还需要我们多使用模型和序列并行来降低内存占用。
-
还需要尽可能的让激活值的计算和GPU间的通信overlap。
-
在训练65B模型的时候,代码80G内存的2048块A100上每秒每GPU处理380个token。意味着需要21天处理完1.4T token。
1.6)核心结论
-
LLaMA 是一个开源的基础语言模型集合,参数范围从7B到65B,完全使用公开的数据集在数万亿 Token 上训练;
-
LLaMA-13B 在大多数基准上都优于 GPT-3(175B),而模型大小却小了 10 倍以上,LLaMA-65B 与最好的模型 Chinchilla70B 和 PaLM-540B 性能相当;
-
该研究表明,通过完全在公开可用的数据上进行训练,有可能达到最先进的性能,而不需要求助于专有的数据集,这可能有助于努力提高鲁棒性和减轻已知的问题,如毒性和偏见;
-
向研究界发布LLaMA模型,可能会加速大型语言模型的开放,并促进对指令微调的进一步研究,未来的工作将包括发布在更大的预训练语料库上训练的更大的模型。
二、Alpaca以及其扩展模型
2.1)Alpaca
2.1.1)Alpaca介绍

官网地址:https://crfm.stanford.edu/2023/03/13/alpaca.html
模型入口:https://crfm.stanford.edu/alpaca
github地址:https://github.com/tatsu-lab/stanford_alpaca
3月15日,斯坦福发布语言大模型Alpaca,它是由Meta的LLaMA 7B微调而来的全新模型,仅用了52k数据,性能约等于GPT-3.5。关键是训练成本奇低,不到600美元。
具体花费如下:
-
在8个80GB A100上训练了3个小时,不到100美元;
-
生成数据使用OpenAI的API,500美元。
2.1.2)Alpaca微调
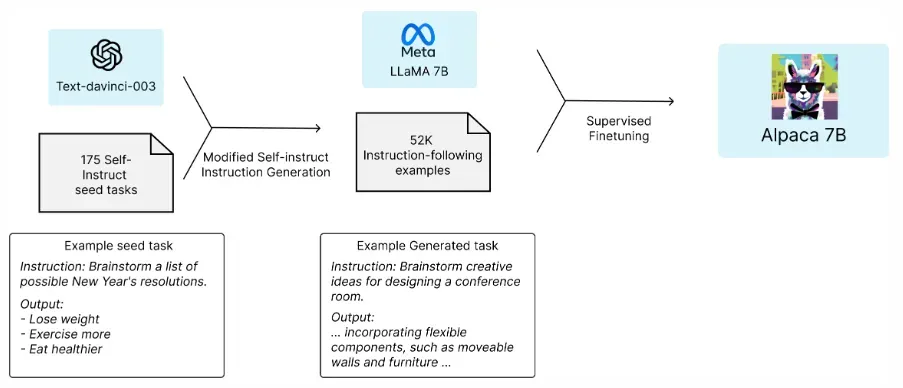
首先使用人工标注的175个「指令-输出」对作为种子,然后,使用这些种子作为上下文示例让text-davinci-003生成更多Prompt。
通过简化生成管道改进了自生成指令的方法,这样大大降低了成本。在数据生成过程中,产生了52K个独特指令和相应的输出,使用OpenAI API的成本不到500美元。
有了这个指令遵循的数据集,研究人员利用Hugging Face的训练框架对LLaMA模型进行微调,利用了完全分片数据并行(FSDP)和混合精度训练等技术。
2.1.3)Alpaca评估
为了评估Alpaca,斯坦福研究人员对自生成指令评价集的输入进行了人工评估(由5位学生作者进行)。
这个评价集是由自生成指令作者收集的,涵盖了多样化的面向用户的指令,包括电子邮件写作、社交媒体和生产力工具等。
他们对GPT-3.5(text-davinci-003)和Alpaca 7B进行了比较,发现这两个模型的性能非常相似。Alpaca在与GPT-3.5的比较中,获胜次数为90对89。
鉴于模型规模较小,且指令数据量不大,取得这个结果已经是相当惊人了。
除了利用这个静态评估集,他们还对Alpaca模型进行了交互式测试,发现Alpaca在各种输入上的表现往往与GPT-3.5相似。
2.2)Alpaca-CoT
是多接口统一的轻量级LLM指令微调平台。
官网地址:https://sota.jiqizhixin.com/project/alpaca-cot
GitHub地址:https://github.com/PhoebusSi/Alpaca-CoT
三、BiLLa[1]
3.1)BiLLa介绍
Github 地址: https://github.com/Neutralzz/BiLLa
HuggingFace 模型:
https://huggingface.co/Neutralzz/BiLLa-7B-LLM(语言模型 BiLLa-7B-LLM)
https://huggingface.co/Neutralzz/BiLLa-7B-SFT(指令微调模型 BiLLa-7B-SFT)
注:因 LLaMa 的使用限制,权重下载后不能直接使用,需通过脚本 [1] 转换
BiLLa 是开源的推理能力增强的中英双语 LLaMA 模型。模型的主要特性有:
-
较大提升 LLaMA 的中文理解能力,并尽可能减少对原始 LLaMA
英文能力的损伤;
-
训练过程增加较多的任务型数据,利用 ChatGPT 生成解析,强化
模型理解任务求解逻辑;
-
全量参数更新,追求更好的生成效果。
以下是经过有限的评测分析得出的结论:
-
BiLLa-7B-LLM 中英语言建模能力显著优于 Chinese-LLaMA-7B;
-
BiLLa-7B-SFT中文推理能力显著优于BELLE-LLaMA-Ext-7B等
模型;
-
由 GPT4 打分,BiLLa-7B-SFT 在英文指令上得分显著高于
ChatGLM-6B,中文得分持平,但解题与代码得分更高。
3.2)BiLLa模型训练
该模型以原始 LLaMa 模型为基础,进行了如下三个阶段的训练。
-
第一阶段:扩充中文词表,使用中文预训练语料 Wudao [5]、英文预训练语料 PILE [6]、翻译语料 WMT [7] 的中英数据进行二次预训练。
-
第二阶段:训练数据在第一阶段基础上增加任务型数据,训练过程中两部分数据保持 1:1 的比例混合。任务型数据均为 NLP 各任务的主流开源数据,包含有数学解题、阅读理解、开放域问答、摘要、代码生成等,利用 ChatGPT API 为数据标签生成解析,用于训练提升模型对任务求解逻辑的理解。
-
第三阶段:保留第二阶段任务型数据,并转化为对话格式,增加其
他指令数据(如 Dolly 2.0、Alpaca GPT4、COIG等),进行对齐阶段的微调。
借鉴 BELLE 之前的工作,三阶段的训练均为全量参数的更新,未使用 LoRA。
目前开源的模型,BiLLa-7B-LLM 是第二阶段训练完成的语言模型,BiLLa-7B-SFT 是第三阶段训练完成的指令微调模型。
四、CaMA[2]
通过全量预训练和指令微调提高了中文理解能力、知识储备和指令理解能力
CaMA: A Chinese-English Bilingual LLaMA Model – CaMA: A Chinese-English Bilingual LLaMA Model.’ ZJUNLP

GitHub地址: https://github.com/zjunlp/CaMA
五、ChatLLaMA[3]
5.1)ChatLLaMA模型介绍
3月23日,AI公司Nebuly开源了第一个基于人类反馈强化学习 (RLHF) 的 LLaMA模型:ChatLLama(https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama),允许用户基于预训练的LLaMA模型构建个性化的ChatGPT服务,且训练速度更快,成本更低。
虽然 LLaMA 发布之初就得到众多研究者的青睐,但是少了 RLHF 的加持,从上述评测结果来看,还是差点意思。在 LLaMA 发布三天后,初创公司 Nebuly AI 开源了 RLHF 版 LLaMA(ChatLLaMA)的训练方法。它的训练过程类似 ChatGPT,该项目允许基于预训练的 LLaMA 模型构建 ChatGPT 形式的服务。项目上线刚刚 2 天,狂揽 5.2K 星。
github地址:https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
ChatLLaMA 训练过程算法实现主打比 ChatGPT 训练更快、更便宜,我们可以从以下四点得到验证:
-
ChatLLaMA 是一个完整的开源实现,允许用户基于预训练的 LLaMA 模型构建 ChatGPT 风格的服务;
-
与 ChatGPT 相比,LLaMA 架构更小,但训练过程和单 GPU 推理速度更快,成本更低;
-
ChatLLaMA 内置了对 DeepSpeed ZERO 的支持,以加速微调过程;
-
该库还支持所有的 LLaMA 模型架构(7B、13B、33B、65B),因此用户可以根据训练时间和推理性能偏好对模型进行微调。
5.2)ChatLLaMA模型使用
ChatLLaMA 允许您使用 RLHF 以类似于 ChatGPT 的方式轻松训练基于 LLaMA 的架构。例如,下面是在 ChatLLaMA 7B 的情况下开始训练的代码。
from chatllama.rlhf.trainer import RLTrainerfrom chatllama.rlhf.config import Config
path = "path_to_config_file.yaml"config = Config(path=path)trainer = RLTrainer(config.trainer)trainer.distillate()trainer.train()trainer.training_stats.plot()请注意,在开始微调过程之前,您应该提供 Meta 的原始权重和您的自定义数据集。或者,您可以使用 LangChain 的代理生成您自己的数据集。
python generate_dataset.py六、CAMEL[4]
CAMEL: 从LLaMA衍生并适应临床的模型。CAMEL基于LLaMA进行进一步的微调,使用了MIMIC-III和MIMIC-IV的临床病例,并在临床指导上进行微调。
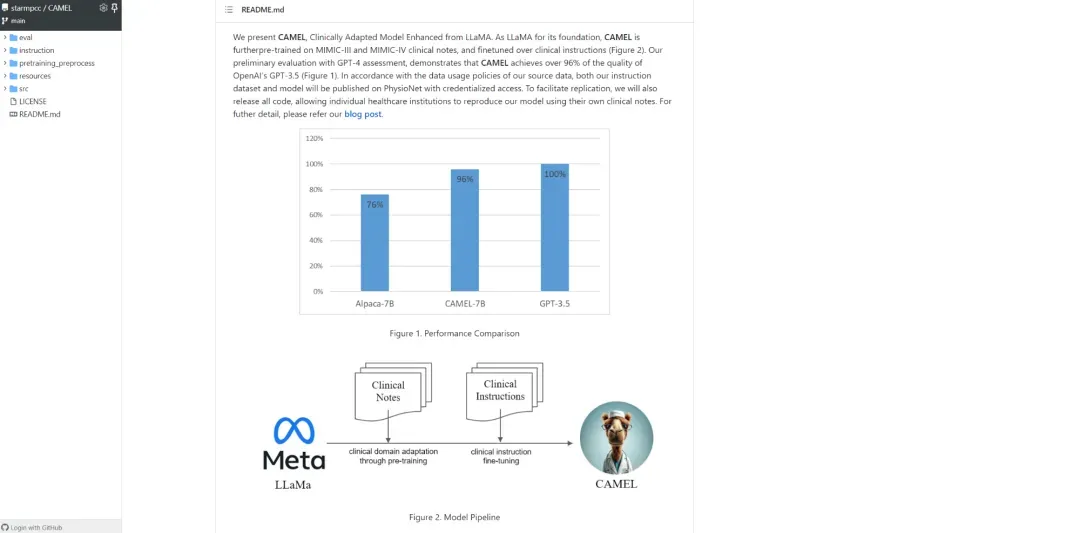
官网地址:https://starmpcc.github.io/CAMEL/
github地址:https://github.com/starmpcc/CAMEL
七、草本[5]
草本大模型原名是华佗,它提出了一个基于LLaMA模型的中医知识微调模型——华驼,它能够在生物医学领域生成更专业、更可靠、更人性化的回答。

论文地址:https://arxiv.org/pdf/2304.06975v1.pdf
代码开源:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
-
在CMeKG中医知识图谱上,生成了8,000多条指令数据,用于对LLaMA模型进行监督微调。这些指令数据包括问答、填空、排序、分类等类型,涉及中医的各个方面。
-
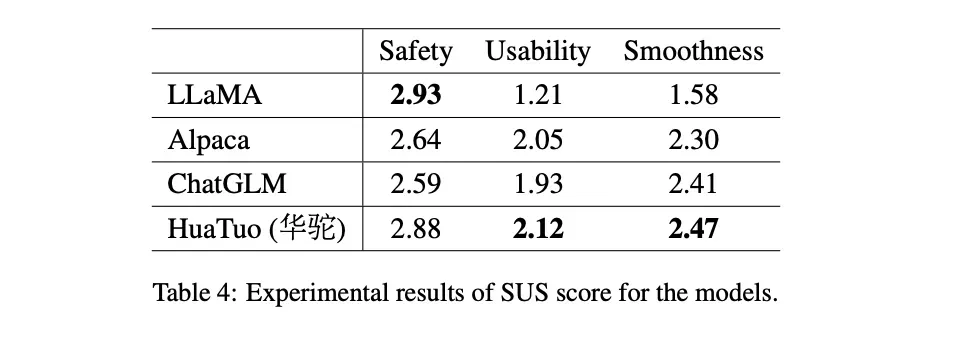
在生物医学领域的回答任务上,比较了华驼模型和其他基准模型的表现。这些基准模型包括ChatGLM-6B、Alpaca和原始LLaMA。使用自动评价指标和人工评价来评估模型生成的回答的质量和可靠性。
八、DB-GPT[6]
DB-GPT:基于vicuna-13b和FastChat的开源实验项目,采用了langchain和llama-index技术进行上下文学习和问答。项目完全本地化部署,保证数据的隐私安全,能直接连接到私有数据库处理私有数据。其功能包括SQL生成、SQL诊断、数据库知识问答等。
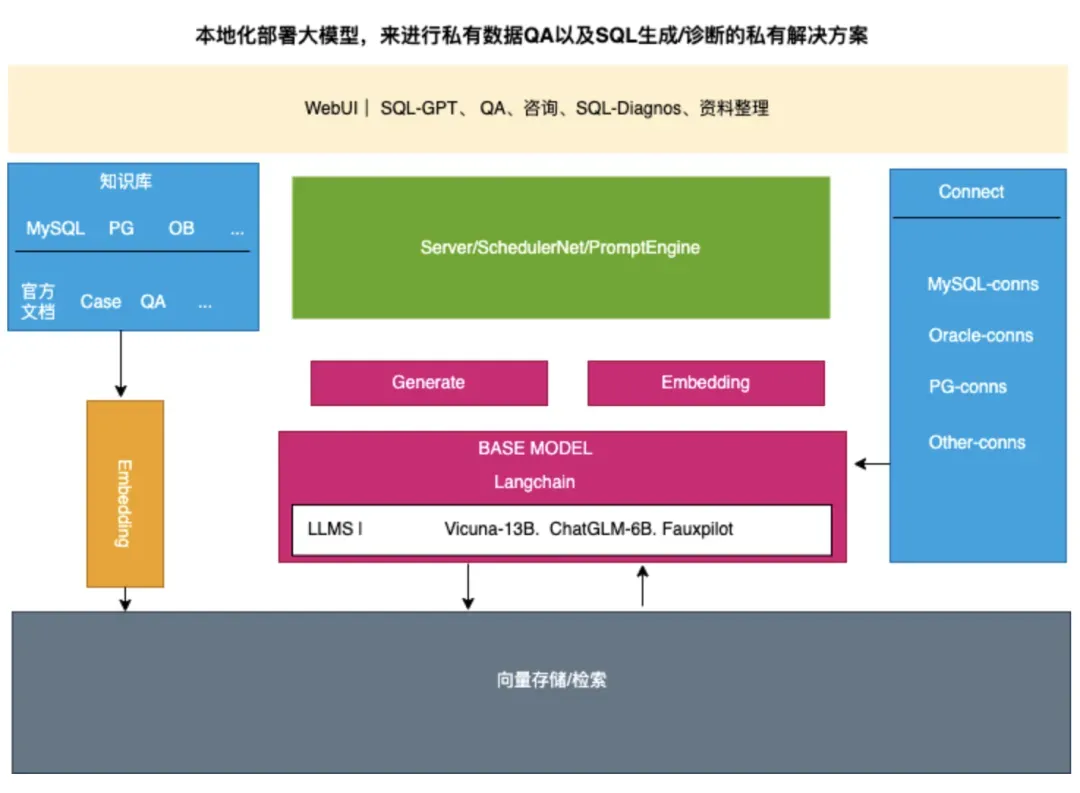
DB-GPT – A Open Database-GPT Experiment, which based on vicuna-13b and fastchat, meanwhile it use langchain and llama-index for in-context learning and QA’ magic.chen
一个数据库相关的GPT实验项目, 模型与数据全部本地化部署, 绝对保障数据的隐私安全。同时此GPT项目可以直接本地部署连接到私有数据库, 进行私有数据处理。
DB-GPT 是一个实验性的开源应用程序,它基于FastChat,并使用vicuna-13b作为基础模型。此外,此程序结合了langchain和llama-index基于现有知识库进行In-Context Learning来对其进行数据库相关知识的增强。它可以进行SQL生成、SQL诊断、数据库知识问答等一系列的工作。
GitHub地址: https://github.com/csunny/DB-GPT
九、ExpertLLaMA
9.1)ExpertLLaMA介绍
ExpertLLaMA:一个使用ExpertPrompting(https://arxiv.org/abs/2305.14688)构建的开源聊天机器人,其能力达到ChatGPT的96%。
ExpertLLaMA通过在普通指令中添加专家身份描述,产生高质量、详细的专家级回答。本项目提供了方法简介、52,000个专家数据集样本、52,000个基线数据集样本、52,000个对应每个具体指令的专家身份描述、基于专家数据集训练的ExpertLLaMA检查点以及与Vicuna、LLaMA-GPT4等现有模型的评估结果

GitHub地址:https://github.com/OFA-Sys/ExpertLLaMA
9.2)ExpertLLaMA微调的大致步骤如下:
a)首先使用gpt-3.5-turbo模型对 52k Alpaca instructions数据使用ExpertPrompting方法进行数据增强,增强后的数据在github地址的data目录下;

b)然后使用这些增强后的指令跟随数据对LLaMA-7B进行微调。
9.3)ExpertLLaMA训练脚本如下:
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \ --model_name_or_path <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \ --data_path ./data/expertllama.json \ --bf16 True \ --output_dir <your_output_dir> \ --num_train_epochs 3 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 4 \ --gradient_accumulation_steps 8 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 2000 \ --save_total_limit 1 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --fsdp "full_shard auto_wrap" \ --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \ --tf32 True9.4)ExpertLLaMA模型加载:
模型加载可以参考Vicuna,是LLaMA原始模型权重和ExpertLLaMA权重的合并,脚本可以参考:https://github.com/lm-sys/FastChat#vicuna-weights
Step1:下载LLaMA-7B官方模型权重,然后转换成huggingface transformers格式,参考地址:https://huggingface.co/docs/transformers/main/model_doc/llama
Step2:下载ExpertLLaMA权重,参考地址:https://huggingface.co/OFA-Sys/expertllama-7b-delta/tree/main或者设置OFA-Sys/expertllama-7b-delta
Step3:运行./model/apply_delta.py脚本
python3 apply_delta.py --base-model-path {your_base_model_path} --target-model-path {your_target_model_path} --delta-path {downloaded_delta_weights}本地部署脚本如下:
python3 gen_demo.py --expertllama_path {your_target_model_path}十、FreedomGPT
FreedomGPT是由AI风险投资公司Age of AI开发,它使用Electron 和 React构建,它是一个桌面应用程序,允许用户在他们的本地机器上运行LLaMA。它与ChatGPT不同,ChatGPT遵循OpenAI的使用政策,限制仇恨、自残、威胁、暴力、性方面的内容。而FreedomGPT是一个号称完全自由的 GPT 聊天模型,不带有任何过滤机制,有 Web 版和桌面端。
官网地址:https://freedomgpt.com/
文章出处登录后可见!