
论文链接:
https://arxiv.org/abs/2306.04050
随着以ChatGPT、GPT-4为代表的AI大模型逐渐爆火进入公众视野,各行各业都开始思考如何更好的使用和发展自己的大模型,有一些评论甚至认为大模型是以人工智能为标志的第四次产业革命的核心竞争产品。例如在5月26日的北京中关村2023论坛上,百度公司创始人、CEO李彦宏发表了题为《大模型改变世界》的演讲。在这次演讲中,李彦宏提出:“百度要做第一个把全部产品重做一遍的公司”。这意味着,大模型现有的能力,已经可以向传统的互联网应用和方法发出挑战。
本文介绍一篇来自得克萨斯A&M大学的工作,在本文中,作者瞄准的领域是传统的文本压缩算法。作者巧妙地发挥了现有大模型的文本预测能力,例如使用LLaMA-7B对输入的前几个token预测其下一个位置的文本,并且对大模型预测英语熵(entropy of English)的渐近上限进行了全新的估计,估计结果表明,在大模型加持下,该估计值明显低于目前常用方法的估计值。基于这一发现,作者提出来一种基于大模型的英语文本无损压缩算法LLMZip,LLMZip巧妙的将大型语言模型的文本预测能力与无损压缩方案相结合,实现了高效的文本压缩性能,经过一系列的实验表明,LLMZip已经超过了目前最为先进的文本压缩算法,例如BSC、ZPAQ和paq8h。

一、引言
目前以ChatGPT为代表的大模型主要在自然语言领域中的学习和预测等两个方面取得了非常惊人的成就。实际上,学习、预测和压缩三者之间有着非常密切的联系。早在1951年,信息论之父和人工智能先驱克劳德・香农(C.E.Shannon)发表了一篇名为《Prediction and Entropy of Printed English》的论文[1],在该文中,香农以英语语言为例,深度探索了预测和压缩之间的联系,并且对英语预测熵的上下界进行了估计,下图从香农1951年论文手稿中摘录。
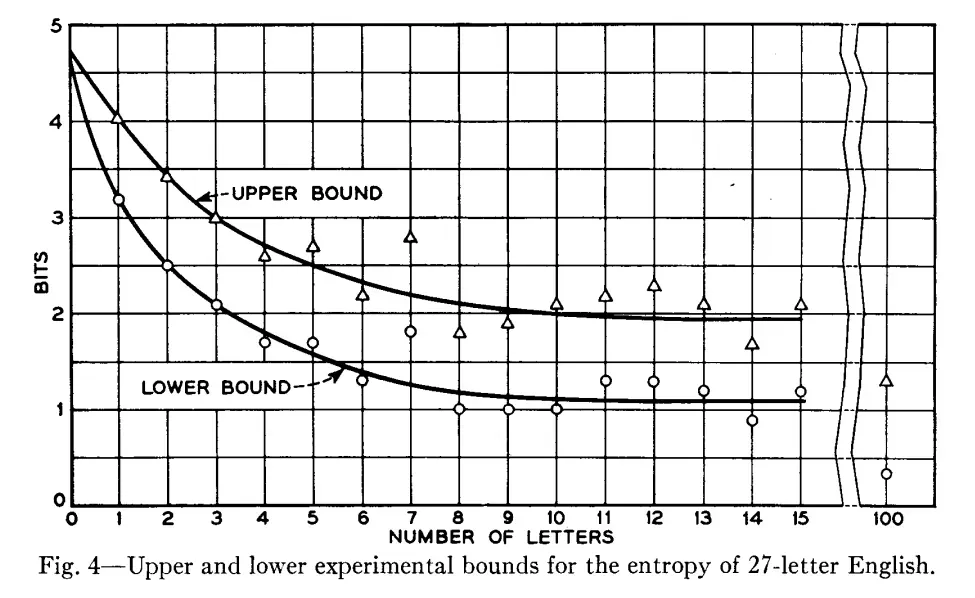
香农认为,可以通过对一段文本中的下一个单词进行预测,我们就可以估计出当前文本所含的信息量,如果预测效果很好的话,就可以将该预测模型转换为一个良好的压缩算法。这一思想在后来的信息论中发挥了重要作用,目前很多用于语音、图像和视频压缩的算法都明确或隐含地利用了这一思想。这种压缩方法的性能在很大程度上取决于预测器的效果,本文作者认为,每当模型预测能力取得重大进展时,我们都有必要研究最新的预测模型对压缩方法是否有影响。因此作者很快就想到,能否使用LLaMA和GPT-4等大模型来得到更好的文本压缩结果和更准确的英语熵估计。作者在实验中选用了LLaMA系列模型中的LLaMA-7B版本,实验数据集选用text8,在text8数据集中的1MB子集中,LLMZip得到的熵估计上界为0.709位/字符,明显低于香农论文中的估计上界。此外,在text8的100KB子集中,LLMZip可以达到0.98位/字符的压缩率,这明显优于目前的SOTA方法。
二、本文方法
2.1 LLMZip的压缩建模
本文所遵循的压缩建模方式与1951年香农提出的估计英语熵的思想几乎相同,主要区别是本文使用了现代的可变长度的单词token来作为基础元素,并且使用大型语言模型来作为预测器,而不是让人来预测句子中的下一个元素。作者使用了一个例子来说明本文的压缩建模方式,给定一个英文文本:“My first attempt at writing a book”。
LLMZip的目标是将这个句子转换为长度尽可能短的比特序列,以便可以从比特序列中重建得到原始序列。LLMZip首先使用分词器(tokenizer)将该句子拆分成一系列tokens。随后使用具有记忆功能的语言模型对先前的M个token进行观察,然后对句子的下一个token进行预测,具体来说,模型会为下一个token的出现概率生成一个排序好的候选列表,如下图所示。

上图中下一个位置的可能选项有“reading”、“writing”、“driving”、“cooking”等词,LLMZip的做法是计算该句子实际单词(writing)在这个列表中的排名,该排名被定义为R5,作者规定排名顺序从0开始,即概率最大的词排名为 0,第二个最有可能的词排名为1,依此类推,在这个例子中,“writing”的排名是R5 = 1。
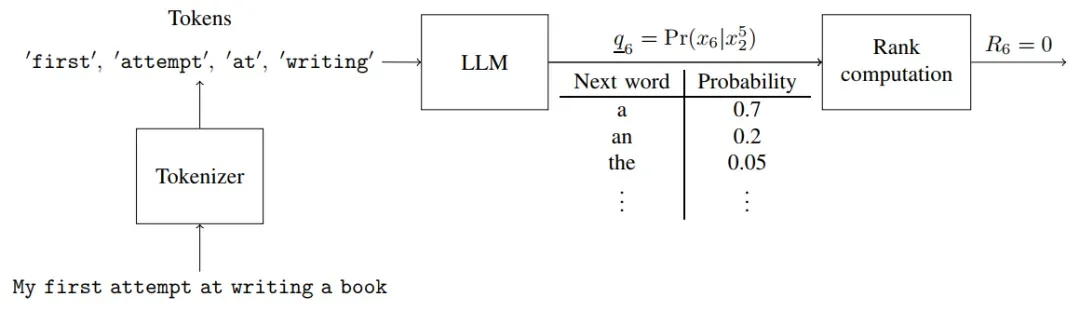
随后模型预测窗口向后推进一个位置,此时需要根据第2到第5个单词来预测出第6个单词,如上图所示,在这个例子中,第6个单词的预测结果恰好是候选列表中排名最靠前的单词,因此排名R6 = 0。以此类推,我们可以发现这样预测下来的排名预测是1,0,0,….这样的包含很多0的数字序列,这种序列通常可以使用标准的无损压缩算法(例如zip,霍夫曼编码)进行压缩。
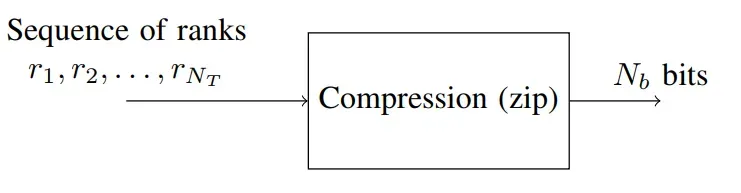
当对输入文本进行重建时,首先需要解压缩得到token排名列表,然后使用与压缩阶段相同的LLM对输入token进行预测,并使用解压得到的排名来确定预测输出,进而得到完整的解压文本。
2.2 LLMZip的压缩比

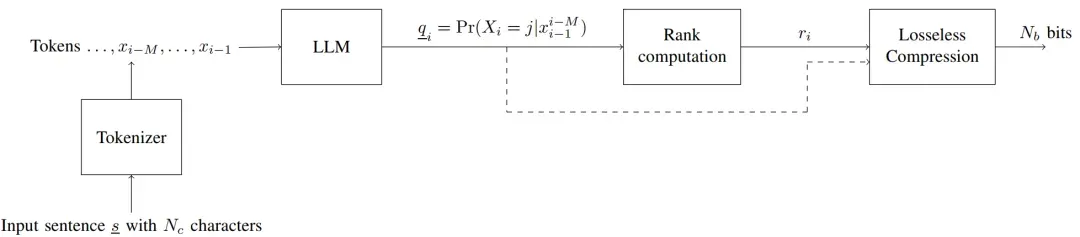
随后作者采用无损压缩算法(例如zlib)来对排名序列压缩到 Nb个比特位,实际上,LLMZip算法真正压缩的目标仅仅是排名序列,因此LLMZip的压缩比p可以计算如下:
2.3 LLMZip中的两种无损压缩方案

三、实验效果
本文的实验在text8数据集上进行,并且使用LLaMA-7B[3]作为大型语言模型,作者从先前的工作中摘录了目前SOTA方法在text8数据集上的最佳压缩性能,例如paq8h算法可以达到1.2 位/字符的压缩率,ZPAQ算法可以达到1.4位/字符的压缩比。作者将这两种算法作为基线对比方法,与LLMZip算法的对比结果如下表所示。
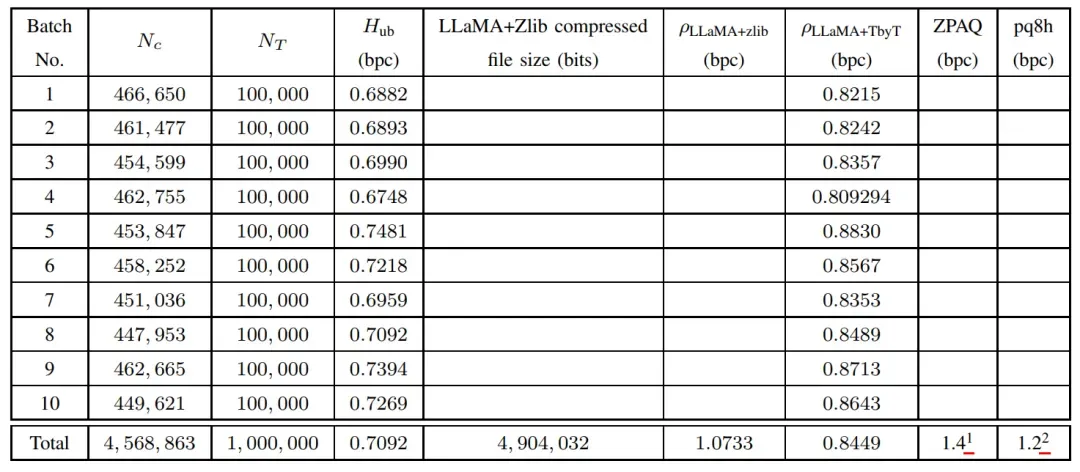
整体数据集被划分为10个不同的批次,每个批次含有100,000个tokens,表中最后一行为每种方法在1M数据量下的平均压缩性能。可以看出,LLMZip的LLaMA+zlib和LLaMA+TbyT版本分别可以达到1.0733位/字符和0.8449位/字符的压缩比,远优于另外两种对比方法。
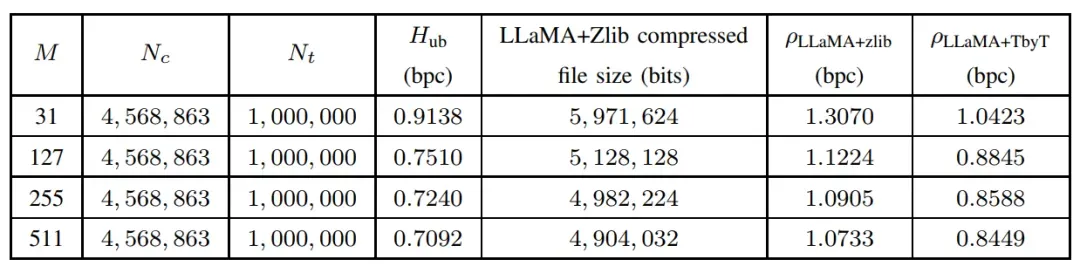
除了简单的压缩比性能对比,作者还进一步分析了LLMZip的压缩性能对大模型内存的依赖性,如上表所示,正如作者所预期的那样,模型的压缩性能随着 的增加和提高,作者还发现,模型的压缩推理时间与输入文本所占内存容量大致呈现线性比例。
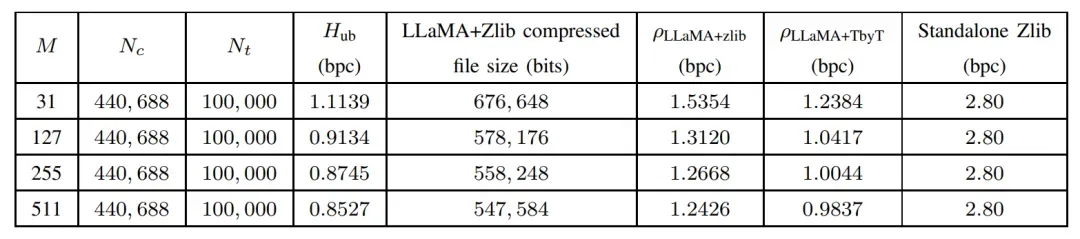
为了验证本文提出的LLMZip方法的鲁棒性,作者还从互联网电子书库中选取了一本近期发布(2023年5月25日)的书籍来对LLMZip方法进行测试。作者从该书中同样提取了100,000个tokens,并且按照text8数据集的标准进行预处理。同时,为了对比基于LLaMA的大模型压缩器与目前常用的标准文本压缩器之间的性能,作者还在该书籍上直接运行了zlib算法,模型的最终测试对比结果如上表所示,可以看到,zlib算法的压缩率为2.8位/字符,这一结果明显低于LLMZip的压缩结果。
四、 总结
本文提出的LLMZip是一种使用大规模语言模型(LLaMA-7B)的新型文本压缩技术,可以极大地提高数据存储和通信的效率,作者进行的实验已经展示出LLMZip惊人的压缩率,结果表明其可以将1MB的文本数据压缩约90%。这得益于现有大语言模型强大的文本预测能力,即根据历史的输入文本来预测下一个位置的单词或token,这种预测能力早在香农时代就被认为是减少文本冗余和高效编码的关键。此外,借助于大模型对长文本数据优越的处理能力,LLMZip还有望提升传统文本压缩方法在长文本情景时的压缩效果。虽然LLMZip目前只支持英文文本压缩,但是随着多语言大模型的快速发展,我们相信LLMZip很快就会在其他语言中进行应用。
参考
[1] Claude E Shannon, “Prediction and entropy of printed english,” Bell system technical journal, vol. 30, no. 1, pp. 50–64, 1951.
[2] Thomas M Cover and Joy A Thomas, Elements of Information Theory, Wiley, New York, 1999.
[3] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample, “Llama: Open and efficient foundation language models,” 2023.
Illustration by unDraw
文章出处登录后可见!