ACE2005数据集介绍、预处理及事件抽取
参考链接:https://www.jianshu.com/p/71ed0d780210(感谢作者鲜芋牛奶西米爱solo,这篇博客介绍的非常详细)
https://zhuanlan.zhihu.com/p/89297862
ACE语料库的获取链接:https://catalog.ldc.upenn.edu/LDC2006T06(收费)
有关ACE英文语料库注释准则的详细内容可参考:https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/english-events-guidelines-v5.4.3.pdf(该路径的上一目录下也可查看到其他语言的注释规则解释)。
ACE2005数据集预处理的参考代码链接:
(1)英文:https://github.com/nlpcl-lab/ace2005-preprocessing
(2)中文:https://github.com/ll0ruc/ace2005chinese_preprocess
https://github.com/yujunhuics/ace2005_Chinese_Processing
使用预训练模型对Ace2005数据集进行事件抽取的参考代码链接:
(1)https://github.com/nlpcl-lab/bert-event-extraction
(2)https://github.com/Hanlard/Transformer-based-pretrained-model-for-event-extraction
1、介绍
ACE2005语料库是语言数据联盟(LDC)发布的由实体,关系和事件注释组成的各种类型的数据,包括英语,阿拉伯语和中文培训数据,目标是开发自动内容提取技术,支持以文本形式自动处理人类语言。ACE语料解决了五个子任务的识别:entities、values、temporal expressions、relations and events。这些任务要求系统处理文档中的语言数据,然后为每个文档输出有关其中提到或讨论的实体,值,时间表达式,关系和事件的信息。
2、ACE2005数据集目录结构如下:
ace_2005_td_v7/
├── data
├── Arabic
├── bn
├── adj
├── NTV20001002.1530.0534.ag.xml
├── NTV20001002.1530.0534.apf.xml
├── NTV20001002.1530.0534.sgm
├── NTV20001002.1530.0534.tab
├── ......
├── fp1
├── NTV20001002.1530.0534.ag.xml
├── NTV20001002.1530.0534.apf.xml
├── NTV20001002.1530.0534.sgm
├── NTV20001002.1530.0534.tab
├── ......
├── fp2
├── NTV20001002.1530.0534.ag.xml
├── NTV20001002.1530.0534.apf.xml
├── NTV20001002.1530.0534.sgm
├── NTV20001002.1530.0534.tab
├── ......
├── FileList
├── nw
├── wl
├── Chinese
├── bn
├── adj
├── CBS20001001.1000.0041.ag.xml
├── CBS20001001.1000.0041.apf.xml
├── CBS20001001.1000.0041.sgm
├── CBS20001001.1000.0041.tab
├── ......
├── fp1
├── CBS20001001.1000.0041.ag.xml
├── CBS20001001.1000.0041.apf.xml
├── CBS20001001.1000.0041.sgm
├── CBS20001001.1000.0041.tab
├── ......
├── fp2
├── CBS20001001.1000.0041.ag.xml
├── CBS20001001.1000.0041.apf.xml
├── CBS20001001.1000.0041.sgm
├── CBS20001001.1000.0041.tab
├── ......
├── FileList
├── nw
├── wl
├── English
├── bc
├── adj
├── CNN_CF_20030303.1900.00.ag.xml
├── CNN_CF_20030303.1900.00.apf.xml
├── CNN_CF_20030303.1900.00.apf.xml.score
├── CNN_CF_20030303.1900.00.sgm
├── CNN_CF_20030303.1900.00.tab
├── ......
├── fp1
├── fp2
├── timex2norm
├── CNN_CF_20030303.1900.00.ag.xml
├── CNN_CF_20030303.1900.00.apf.xml
├── CNN_CF_20030303.1900.00.sgm
├── CNN_CF_20030303.1900.00.tab
├── ......
├── FileList
├── bn
├── cts
├── nw
├── un
├── wl
├── docs
├── file.tbl
├── README
├── dtd
├── ace-source-sgml.v1.0.2.dtd
├── ag-1.1.dtd
├── apf.v5.1.1.dtd
└── index.html
以ace_2005_td_v7\data\Chinese\bn\adj\目录下的内容为例,说明其文件格式。
每个注释文件对应四个版本:
(1)原文本文件(.sgm):
所有源文件(包括中文文件)都以UTF-8编码,这些文件使用UNIX样式的行尾。 仅评估开始文本标记
(2)ACE程序格式(APF)文件(.apf.xml):
采用官方ACE注释文件格式;ACE Pilot格式是XML对齐注释的一种形式。有关ACE程序格式的定义链接已失效,若需查找更多相关内容可查看:http://xml.coverpages.org/acePilot.html。
(3)AG 文件(.ag.xml):
LDC注释图格式, LDC的ACE内部注释文件格式,可以使用LDC注释工具包创建的注释文件。
(4)TABLE文件(.tab):
存储以ID识别的ag.xml文件及其对应的apf.xml文件之间映射表。
3、ACE2005的训练集和测试集的详细统计数据:
可以对照第二节中目录结构 ace_2005_td_v7/data/ 进行了解。
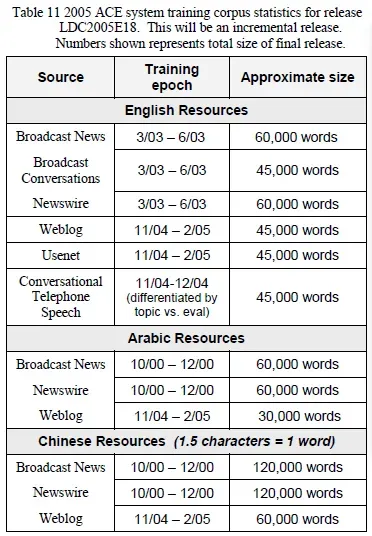
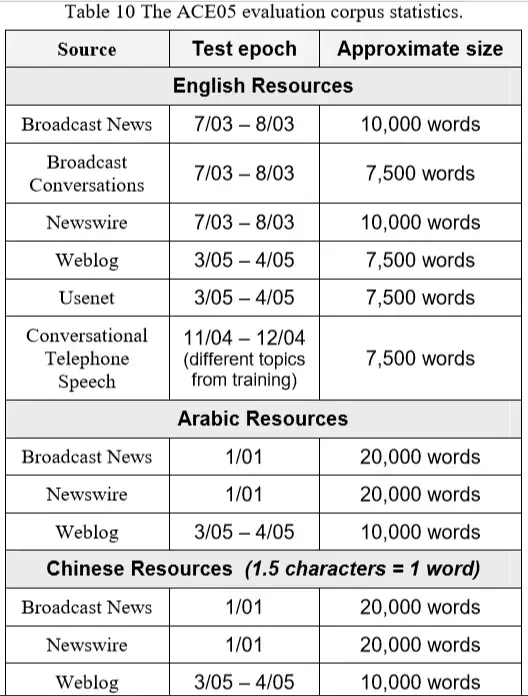
简单查看一下在ace_2005_td_v7\data\Chinese下的数据来源情况:可以看到只有NW、BN以及WL有数据,而BC、UN、CTD没有数据。

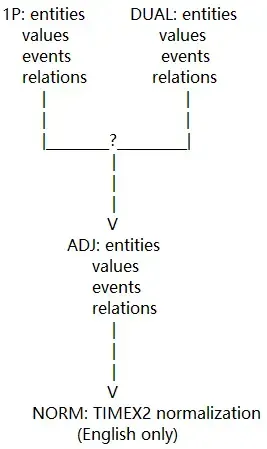
所有的训练数据文件由两个独立的注释器完成双重注释。第一遍完整注释产生fp1,双重第一遍完整注释产生dual(也就是fp2)。单个注释器完成文件的所有任务(实体,值,关系和事件)。之后,由注释人裁定每个文件的fp1和fp2版本之间的差异,产生高质量的黄金标准文件,称为adj。判定后,以TIMEX2值进行标准化(在此只针对英语语料,Chinese和Arabic下没有),称为timex2norm。该流程可描述为如下:
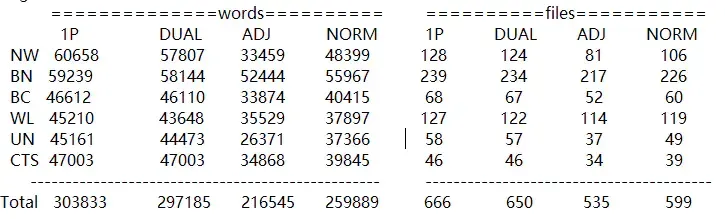
以英语版本为例,目录下对应的文件名称分别为bc,bn,cts,nw,un,wl。这些数据源继而被分类成adj,fp1(即第一遍注释的1p),fp2(即dual),timex2norm。英语数据源的注释状态:
4、ACE数据集任务目标
ACE注释任务对应于三个研究目标:实体检测和跟踪(EDT),关系检测和表征(RDC)以及事件检测和表征(EDC)。第四个注释任务,实体链接(LNK),将对单个实体及其所有属性的所有引用分组到一个复合实体中。
(1)实体检测和跟踪(EDT)
核心注释任务,为所有剩余任务提供基础。后来的ACE任务确定了七种类型的实体:人员,组织,位置,设施,武器,车辆和地缘政治实体(GPE)。每种类型进一步分为子类型(例如,组织子类型包括政府,商业,教育,非营利,其他)。注释器标记了文档中每个实体的所有提及,无论是命名,名义还是代名词。对于每一次提及,注释器都识别出代表实体的字符串的最大范围,并标记每个提及的头部。嵌套提及也被捕获。每个实体根据其类型和子类型进行分类,并根据其特定类别,通用,属性,负面量化或未指定类别进一步标记。在LNK注释任务期间,注释器审查整个文档,以便将同一实体的提及分组在一起; 他们还标记了转喻的案例,其中一个实体的名称用于指代与其相关的另一个实体。
(2)关系检测和表征(RDC)
涉及实体之间关系的识别。此任务已添加到ACE的第2阶段。RDC针对物理关系,包括位置,近处和部分整体; 社会/个人关系,包括商业,家庭和其他; 一系列的就业或会员关系; 工件与代理商之间的关系(包括所有权); 从属关系,如种族; 人与GPE之间的关系,如公民身份; 最后是话语关系。对于每个关系,注释器都识别出两个主要参数(即,链接的两个ACE实体)以及关系的时间属性。由明确的文本证据支持的关系与那些依赖于读者的语境推理的关系不同。
(3)事件检测和表征(EDC)
在EDC中,注释器识别并描述了EDT实体参与的五种类型的事件。目标类型包括交互,移动,转移,创建和销毁事件。注释器为每个事件标记文本提及或锚点,并按类型和子类型对其进行分类。他们根据特定类型的模板进一步确定了事件参数(代理,对象,源和目标)和属性(时间,位置以及其他类似工具或目的)。
5、ACE数据集任务详细介绍
(1)实体检测与识别
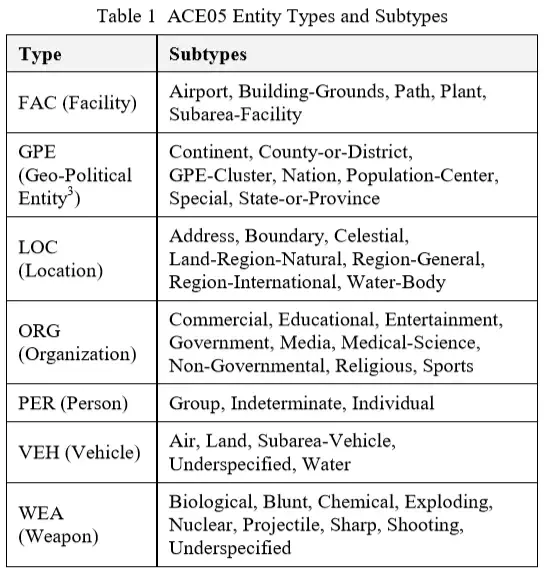
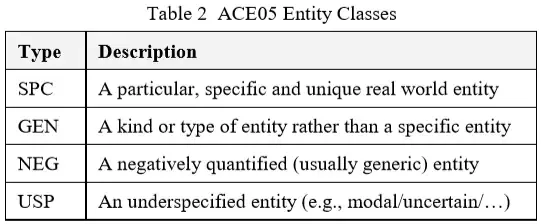
实体提及的每个文档都需要实体输出。此输出包括实体的属性和提及的信息。实体属性当前仅限于实体类型,实体子类型,实体类以及用于引用实体的名称。每个实体提及的输出包括提及类型,其头部的位置和范围,以及可选的提及角色和提及风格(文字或转喻,该属性以apf文件格式编码为名为“metonymy_mention”,为true表示“转喻风格”的引用,false表示“文字”引用,默认为文字),table1与table2列出了ACE实体类型,子类型和类。table3列出了提及类型。
(2)时间检测与识别
ACE时间表达识别和规范化任务(TERN)根据“TIDES 2005标准的时间表达注释”来检测和识别源语言数据中提到的某些时间表达式(以时间x2格式)。要识别的时间表达包括绝对表达式和相对表达式。 此外,还要识别持续时间,事件锚定表达式和时间集。 此信息包含在timex2属性集中。 表5列出了2005年要评估的ACE timex2属性。

(3)关系检测与识别
ACE关系检测和识别任务(RDR)要求检测源语言数据中提到的某些指定类型的关系,并且识别关于这些关系的所选信息并将其合并为每个检测到的关系的统一表示。
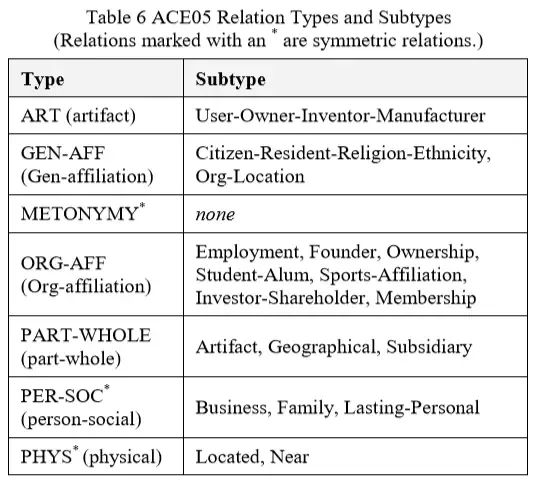
关系提及的输出包括有关关系属性,关系参数和关系提及的信息。 关系属性是关系类型,子类型,模态和时态。关系参数由唯一ID和角色标识。相关的两个实体的角色是“Arg-1”和“Arg-2”,除了对称关系(表6中标识)之外,将这些角色正确分配给它们各自的参数是很重要的。可能只有一个Arg-1实体和一个Arg-2实体。除了两个主要实体参数之外,还可能存在一个或多个temporal(timex2)参数,并且在关系中包含这些参数以便为关系接收完整值。关系提及是表达关系的句子或短语,必须包含两个相关实体的提及。表6中列出了2005年的ACE关系类型和子类型。关系可能只有一种类型和一种子类型。
(4) 事件检测与识别
ACE事件检测和识别任务(VDR)要求检测源语言数据中提到的某些指定类型的事件,并且识别关于这些事件的所选信息并将其合并为每个检测到的事件的统一表示。
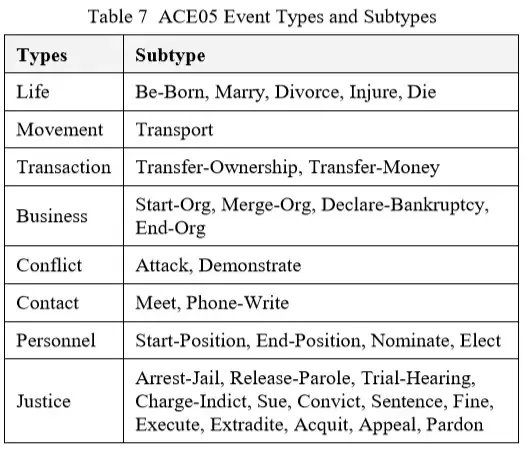
提及事件的每个文档都需要事件输出。此输出包括有关事件属性,事件参数和事件提及的信息。事件属性是事件类型,子类型,模态,极性,通用性和时态。table7中列出了2005年的ACE事件类型和子类型。事件可能只有一种类型和一种子类型。
 每个事件参数由唯一ID和角色标识。与仅允许Arg-1和Arg-2角色中的一个参数的关系不同,事件允许同一角色中的多个参数。事件提及是提及事件的句子或短语,事件提及的范围被定义为提及事件的整个句子。虽然未评估事件提及的识别,但它是允许系统输出事件映射到参考事件的方式之一。因此,正确识别事件提及可能有助于评估。
每个事件参数由唯一ID和角色标识。与仅允许Arg-1和Arg-2角色中的一个参数的关系不同,事件允许同一角色中的多个参数。事件提及是提及事件的句子或短语,事件提及的范围被定义为提及事件的整个句子。虽然未评估事件提及的识别,但它是允许系统输出事件映射到参考事件的方式之一。因此,正确识别事件提及可能有助于评估。
文章出处登录后可见!