——————————————————
写在前面:本人研一小白,处于懵懂,潜心向老师师兄师姐学习的阶段,第一次发博客,也是一时兴起(向师兄学习,很羡慕师兄师姐们的能力和水平),因为是个人的笔记,当时记得时候也查阅了许多预备知识,有一些杂乱,主要还是按照论文章节记的。推一下一作大神在b站的会议直播录像,在有一定知识储备后听完会有一种通透的感觉
https://www.bilibili.com/video/BV15S4y1q7mE/?spm_id_from=333.337.search-card.all.click
原文:https://readpaper.com/paper/4563630863456149505
同时也十分感谢笔记中提到的博主们的文章,特别是朽一大佬,个人觉得他的讲解是mvsnet及后续工作最好的
这是他的博客页
https://blog.csdn.net/qq_43027065?type=blog
再次说明,本人能力有限,您可以带着批判的角度来阅读这篇小笔记,引用可能也不规范,如有问题请不吝赐教
——————————————————
TransMVSNet阅读笔记
笔记分为三个模块,一、分析题目 摘要 结论的写作手法。二、对其他部分出现的名词及概念进行整理。三、对方法部分进行概述,重点在于串联公式,形成总体的流程图。
Title
TransMVSNet: Global Context-aware Multi-view Stereo Network with Transformers
- 对自己方法的命名(起个好听的名字好让后来人记住):TransMVSNet
- 任务,主要工作:Multi-view Stereo Network
- 方法特点:Global Context-aware、with Transformers
- 难点:回溯成特征匹配任务之后,弱纹理和重复纹理,非郎伯体表面的问题都会干扰,所以打算通过transfomer对全局特征编码交互,解决这些问题。
Abstract
- 首句:一句话总结了论文的工作最大的特点,即基于对**multi-view stereo (MVS)**. 特征匹配(这也是方法的核心)的探索提出的
- 第二句:通过类比MVS回到**特征匹配**任务的本质,为了更好的进行特征匹配,引出了Feature Matching Transformer,FMT是这个网络的核心模块,利用类间类内注意力去增强图片间和图片内的长距离上下文信息。
- 第三句:对论文方法进行补充。FMT的附加模块**Adaptive Receptive Field 自适应感受野模块ARF**:。作用:确保有一个平滑的特征范围;并通过特征通道连接不同节点,以跨越不同尺度的转换特征和梯度(通过调整参数实现的)
- 第四句:更多的细节,成对特征相关性去衡量特征的相似性,采用降低模糊性的focal loss加强监督
- 第五句:强调自己的创新型,提出结论(实验结果)
1. Introduction
逻辑线:MVS本质是一对多的特征匹配任务,最近的一些研究[22,25]已经证明了长距离全局背景在特征匹配任务中的重要性。然而,鉴于上述的MVS过程,有两个主要问题。
(a)卷积提取的是局部特征。 卷积特征的局部性妨碍了对全局信息的感知,全局信息对于MVS在一些具有挑战性的区域(例如贫乏的纹理、重复的图案和非朗伯特表面)进行鲁棒的深度估计是至关重要的
(b) 此外,当计算匹配成本时,要比较的特征只是分别从每个图像本身提取,也就是说,潜在的图像间的对应关系没有被考虑到。(???没懂)
提出transformer和他进行结合
一、MVS network
论文给出的解释:
1.MVS想通过一系列校准的图像重现稠密的3D表示
2.MVS通常通过CNN提取图像特征,并且通过平面扫描算法(这个算法中会将原图像扭到参考视图)建造成本量(最后被正则化/标准化,并用来估计最终的深度)。
3.MVS本质是一对多的特征匹配任务,会对参考图像的每个像素沿着所有源图像的表极线搜索,找到一个匹配成本最低的最佳深度(一对多????猜想:一个像素找多个源图像,最后找到一个最佳深度)
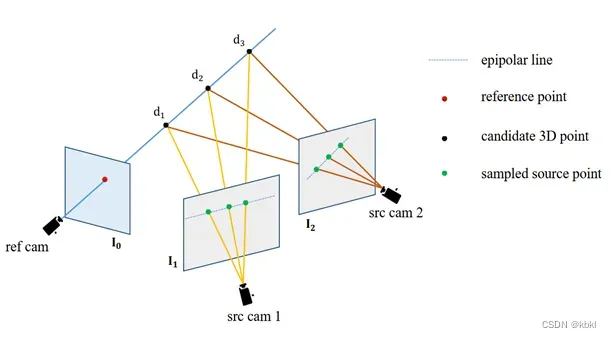
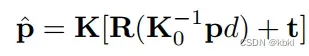
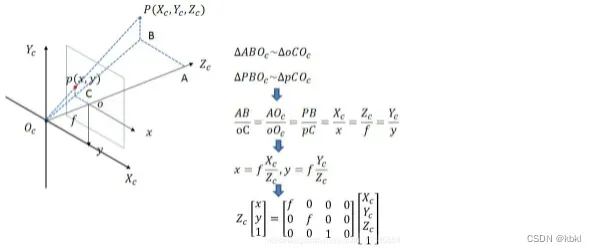
具体对每个像素的深度求取就是这张图,图下公式是单应性变换的过程,p为参考图像像素,p尖为对应的源图像像素,其中相机内外参是给定的,只有深度不知道。
将深度按一个范围取值,然后分别通过单应性变换计算像素,最后得到一个像素的区间,在图中这些像素就在这个极线上,对比极线上像素和参考图像像素的特征相似度,得到最匹配的像素,此时的对应深度值就是最后预测的深度值,也因此后面论文就把MVS类比为特征匹配任务了
查找的资料source image,可以成为待映射图
特征级怎么预测的特征上的信息?
目标:是预测图片上每个像素的深度信息
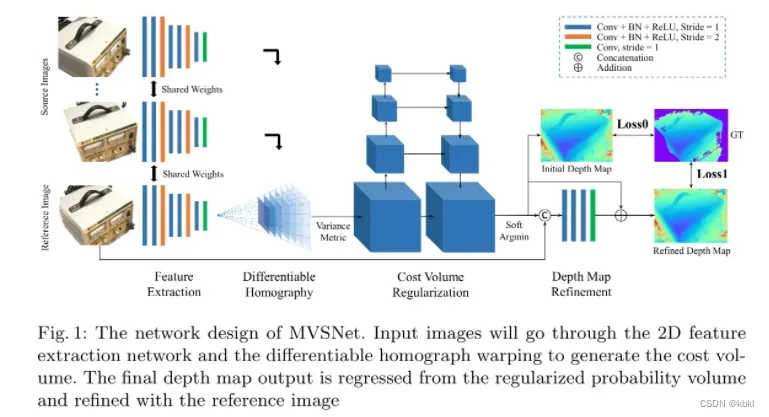
MVSNet本质是借鉴基于两张图片cost volume的双目立体匹配的深度估计方法,扩展到多张图片的深度估计,而基于cost volume的双目立体匹配已经较为成熟,所以MVSNet本质上也是借鉴一个较为成熟的领域,然后提出基于可微分的单应性变换的cost volume用于多视图深度估计。
(1)输入一张reference image(为主) 和几张source images(辅助);
(2)分别用网络提取出下采样四分之一的32通道的特征图;
(3)采用立体匹配(即双目深度估计)里提出的cost volume的概念,将几张source images的特征利用单应性变换( homography warping)转换到reference image,在转换的过程中,类似极线搜索,引入了深度信息。构建cost volume可以说是MVSNet的关键。
具体costvolume上一个点是所有图片在这个点和深度值上特征的方差,方差越小,说明在该深度上置信度越高。
(4)利用3D卷积操作cost volume,先输出每个深度的概率,然后求深度的加权平均得到预测的深度信息,用L1或smoothL1回归深度信息,是一个回归模型。
(5)利用多张图片之间的重建约束(先输出每个深度的概率)(photometric and geometric consistencies)来选择预测正确的深度信息,重建成三维点云。

https://blog.csdn.net/qq_43027065/article/details/116641932这篇讲的很详细,完全可以看这篇理解。
cost volume 成本空间
https://blog.csdn.net/weixin_45245063/article/details/115768016
视锥:就是指相机的拍摄范围,我们知道相机的拍摄范围是一个锥形,沿视锥方向的点在成像上是一个点,与笛卡尔坐标系不同,这对计算深度方便。
单应性变换(Homography):两张拍摄的图片不会是你把图片上下放,就点点重合的,因为有视差和旋转的存在。单应性变换就是根据相机的内参、外参,把一张图片中的点映射到,如果在另一个相机位姿下拍摄,应该成像的位置。
它是基于视锥计算的。把特征提取步骤计算的 N张图片–一张 reference image的特征图,多张 source image(不是全部图片的特征图,而是选取几张,例如2、3张图片)使用单应性变换,变换到与reference image平行的成像平面,把变换后的特征图转为特征向量V,Cost Volume就是这些V的方差。如果越小,那么表示特征越接近。
Cost Volume每个元素存储的就是这 N 张图相同视锥方向、深度、像素坐标下的匹配程度,称为置信度。经过Regularization后,Cost Volume变为概率体P,每个元素与原先意思相同,只不过Regularization后剔除噪音。

构建cost volume的方式有很多,文中用的是方差,但是最后都是想表示不同图的特征相似性
视差
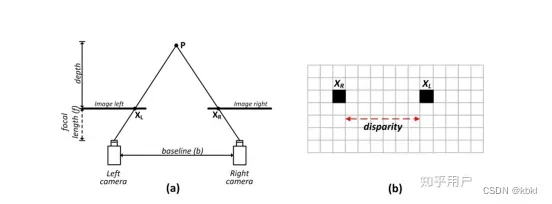
https://www.zhihu.com/question/297481800/answer/1236412702
cost-volume在计算机视觉中特指计算机视觉中的立体匹配stereo matching问题中的一种左右视差搜索空间。
左右相机一般有固定的距离(基线距离),且是保持水平放置的,也就是说左右相机的中心点连线应与地面保持水平。这样的话可想而知,左右视图的视野相交区域内,左视图的任何一点在右视图中都能找到一个同名点(也即代表的都是同一个事物的像素点,例如同一辆车子的同一个前轮的圆心),也很容易想到,左视图中的同名点与右视图中的同名点,在水平方向上的x坐标必然是差几个像素的d,这个距离d就叫做水平视差。左视图中的x1同名点对应右视图中的x2同名点,那么x2-x1=d,d>0。因为前面已经说过,左右相机中心点连线与地面保持水平,所以y2-y1=0。
视差最大的区域必然出现在图片的中央靠下边界区域,从该区域向四周呈放射状分布,越远越小。假设水平视差d的最大值为D(D属于正整数空间),那么shape为(H, W)的左右视图,的所有像素的右视图相对于左视图的全部视差可能值d也就取值于一个正整数集合{0,1,2…D}
若将该正整数集合在视差图的信道维度上进行逐像素表达,那么左右视图对应的shape同为(H,W)的视差图就是一个shape为(H,W,D)的搜索空间,也即cost-volume。这个合适的视差D的特点,就是对应的cost小
表示两个特征的相似程度的方法:点积

https://blog.csdn.net/Bruce_0712/article/details/108580474
双线性插值:
对于找不到的对应点(对应点超出了特征图宽高边界),用插值填充。
epipolar line 极线
对极几何一定是对二幅图像而言,对极几何实际上是“两幅图像之间的对极几何”,它是图像平面与以基线为轴的平面束的交的几何(这里的基线是指连接摄像机中心的直线),以下图为例:对极几何描述的是左右两幅图像(点x和x’对应的图像)与以CC’为轴的平面束的交的几何!
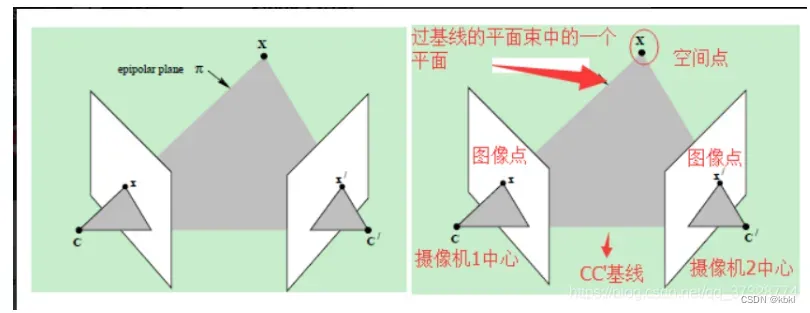
直线OL-X被左相机看做一个点,因为它和透镜中心位于一条线上。然而,从右相机看直线OL-X,则是像面上的一条线直线eR-XR,被称为epipolarline极线。从另一个角度看,极面X-OL-OR与相机像面相交形成极线。
二、plane sweep algorithm 平面扫描算法
https://blog.csdn.net/double_ZZZ/article/details/112577320
平面扫描法通过将一组图像投影到一个平面假设上,然后再投影到参考图像上来匹配参考图像。通过这个步骤卷曲的图像将和参考图像比较测量图像的不相似度,这将通过一个小的匹配窗口来评估。如果测试的平面假设接近参考图像中一个像素的真实深度,则对应的差异值会较低。测试许多平面假设,取每个像素的最佳匹配平面所产生的深度,然后生成参考图像的深度图。
平面扫描法将重建的三维结构局部逼近为平面,在论文中就是把源图像扭曲到参考图像,并通过模拟的最佳深度,得到参考图像的深度图。如果平面假设的法线方向与实际的表面方向没有很好的对齐,则变形后的图像相对于参考图像会出现局部畸变,即使是匹配patch也会增加其不相似度评分。这可以通过对准场景中的主要方向来克服。
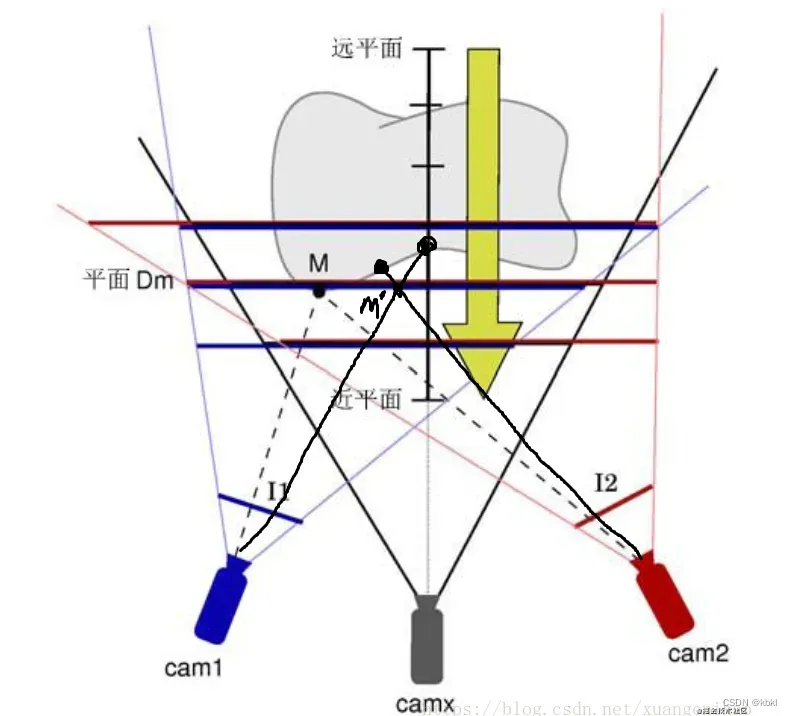
核心思想
如果平行平面足够密集,物体表面的任意一点p一定位于某平面Di上,可以看到p的相机看到点p必定是同一颜色;假设与p在同一平面的另一点p’,不位于物体表面,则投影到每个相机上呈现的颜色不同, 于是Plane Sweeping算法假设:
对于平面上任意一点p,其如果投影到每个相机上的颜色均相同,那么可以说这个点很大概率是物体表面上的点
三、世界坐标系、相机坐标系、图像坐标系、像素坐标系&相机内参 外参
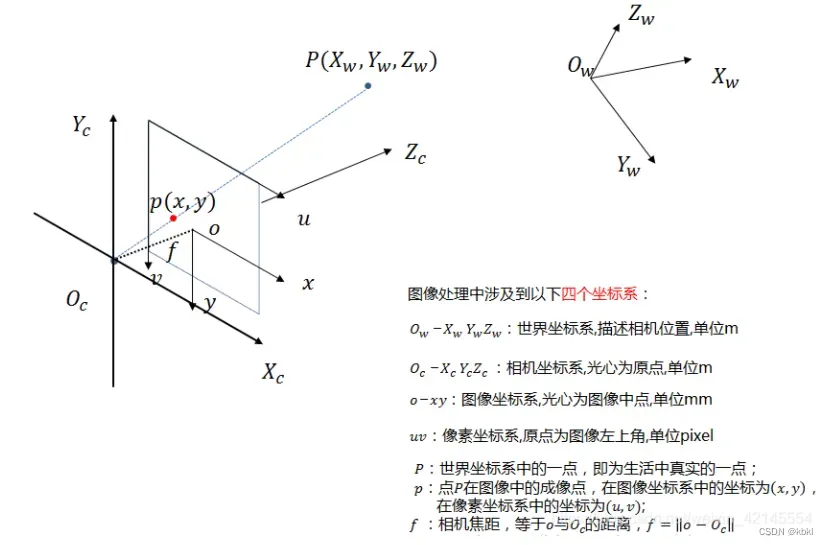
世界坐标系(World Coordinates)
由于摄像机可安放在环境中的任意位置,在环境中选择一个基准坐标系来描述摄像机的位置,并用它描述环境中任何物体的位置,该坐标系称为世界坐标系。
相机坐标系(Camera Coordinates)
相机坐标系也叫视点坐标系(Eye Coordinates)视点坐标是以视点(光心)为原点,以视线的方向为Z+轴正方向的坐标系。世界坐标系到相机坐标系只涉及旋转和平移,所以是刚体变换,不涉及形变。
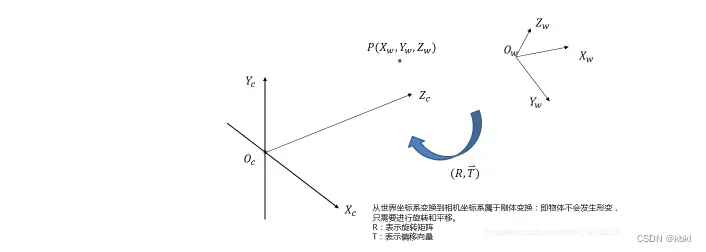
从世界坐标系到相机坐标系的转换关系如下所示:
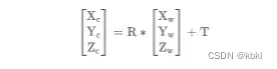
用齐次坐标表示(齐次坐标好表示)
这种由视点变化导致的视觉效果变化,是跟我们的眼睛结构是有关的,在几何学上有个术语叫:投影空间(我们看到的世界万物都是投影在我们的视网膜上的)。
所以就有了这个问题:怎么解决欧氏几何平行线,在投影几何上不成立的这个问题,所以就有了齐次坐标的概念。齐次坐标一言难尽,它相当于是在欧氏几何的坐标系上硬加了一个变数,用这个变数 w 加上原来的坐标,用于解决在投影空间上原本平行的两条线变得不平行的问题假设我们把线上的每个点的x 坐标都加上变数 w , 每个点都发生了位移,我们再把纸拿起来从侧面去观察,假设正好这个 w 的值的规律是能够让两条线投影到我们的视网膜上变成平行的:
原文链接:https://blog.csdn.net/weixin_38989369/article/details/125318191
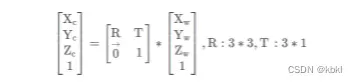
图像坐标系(Image coordinate)
从相机坐标系到图像坐标系,属于透视投影关系,从3D转换到2D。如图所示此时相机坐标与图像坐标的关系表示为
像素坐标系(Pixel coordinate )
以图像左上角为原点建立以像素为单位的直接坐标系u-v。像素的横坐标u与纵坐标v分别是在其图像数组中所在的列数与所在行数。(在OpenCV中u对应x,v对应y)图像坐标到像素坐标如下图所示

内参(固定的):像素点u0v0,对距离求x,y偏导。外参(根据世界坐标系定的):世界坐标系转换为相机坐标系的平移旋转
四、单应矩阵
只知道两个像素点坐标(就是两张图片)和平面距离内参(n,d)法向量和距离,最后想表示相机坐标系下的a与b的坐标的关系。
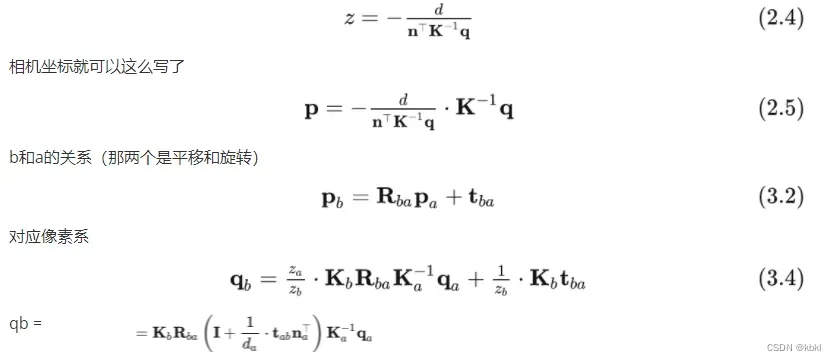
可见,加入 3D 点的平面参数后,可由 a 系下像素坐标完全计算出对应的 b 系下像素坐标。
单应矩阵Hab就是qa前的系数
五、3d卷积2d卷积
二维卷积:一般的二维卷积核有三个维度,窗口大小(h,w)和与输入特征图相同的通道数c,每次卷积得到的是单通道图,即输入特征图为(B,C,H,W)时,输出特征图为(B,1,H,W),用卷积核数量控制输出通道数。(将卷积核数量也看作一个维度时,是4个维度)。
三维卷积:卷积核有四个维度,窗口大小(h,w),与输入特征图相同的通道数c,在depth维度的取值d,每次卷积所有通道参与,部分深度参与(取决于d的值)。若输入特征维度为(B,C,D,H,W),输出维度为(B,1,D,H,W)(深度维度的步长是1,有填充时),同样用卷积核数量控制输出的通道数。
————————————————
原文链接:https://blog.csdn.net/qq_43027065/article/details/116641932
六、non-Lambertian surface 非朗伯体表面
Lambertian表面是指在一个固定的照明分布下从所有的视场方向上观测都具有相同亮度的表面,Lambertian表面不吸收任何入射光.Lambertian反射也叫散光反射,不管照明分布如何,Lambertian表面在所有的表面方向上接收并发散所有的入射照明,结果是每一个方向上都能看到相同数量的能量。
Lambertian反射定义了一个理想的无光表面或者漫反射表面。无论观察者的视角如何,Lambertian表面对观察者表现的亮度都是相同的。
非朗伯体表面:在不同视角下该位置的颜色可能会不同
七、ambiguity-aware 模糊感知
八、Batch-Normalization
激活函数一般都是(-1,1)的,如果值过大过小都会取到极限,会造成梯度消失,收敛缓慢的问题,正则化之后就会有一个比较好的表现。
Batch Normalization, 批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法. 具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律!

公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作.
batch normalization在卷积神经网络中的使用
我们知道在普通的全连接网络中每一层之间的batch normalization就作用于该层的输出,那么在卷积网络中每一层的输出实际上是多维的feature map,这个时候应该如何使用batch normalization呢?假设在某一层卷积网络中,输入batch size为n,该层共有m个filter,输出的feature map大小为ab。那么对于每一个训练实例来说,输出的feature map 维度为mab,对于n个实例输出结果为nmab。这里我们把所有实例在一个filter上的输出结果作为我们batch normalization的作用范围,对于一个filter来说n个实例就会有size为nab的feature map输出,这里的每一个激活值都会进行normalize。
优点:
1.对模型初始化和超参不敏感,减少模型超参数调整,允许使用更大的学习率。
2.可以加快模型收敛速度。保证梯度不消失
3.提高模型泛化能力,抑制模型过拟合。
缺点:
1.对于batch size的大小有要求,如果一个batch太小可能造成方差和均值计算不准,导致训练效果不佳。
2.在RNN上谨慎使用,目前效果存在争议。
原文链接:https://blog.csdn.net/u010325168/article/details/101480936
2. Related Work
在现代深度时代,基于学习的方法已经被引入到MVS的任务中,以获得更好的重建精度和完整性。MVSNet[32]通过微分同构图对相机参数进行编码,以建立三维成本体积,并将MVS任务解耦为每个视图的深度图估计任务。
然而,由于其3D U-Net架构的成本体积正则化,内存和计算成本相当昂贵。(深度最起码几百个,一个特征图的一个通道就这么多)
仍然存在一些挑战性的问题,例如,在非朗伯斯和低纹理区域或严重遮挡区域的稳健估计。
三种方法SuperGlue LoFTR STTR
采用了沿极内和极间线交替的自我关注和交叉关注的变压器,以捕捉特征描述符之间的长程关联。
3. Methodology
给定(输入):参考图片和他的邻居图(源图像 被映射图)以及相机的内外参
模型预测(输出):参考图片I0对齐的深度图。
最终目的:将模型输出的深度图->经过过滤融合得到重建的密集点云
3.1Network Overview
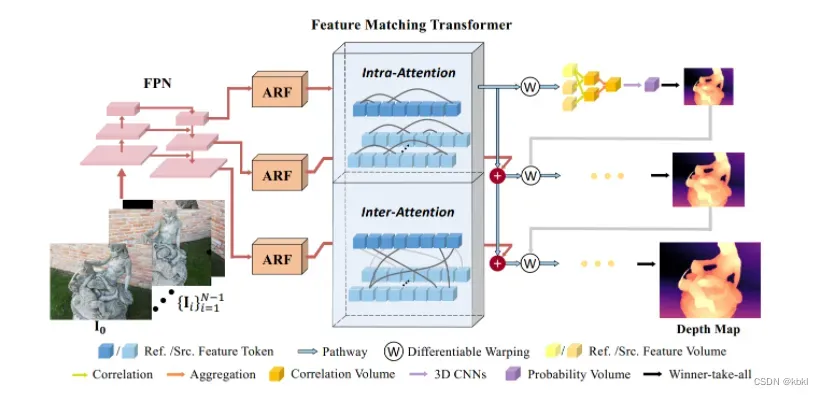
- TransMVSNet首先应用特征金字塔网络(FPN),在提取三个分辨率(从粗到细)的多尺度深度图像特征。
- 特征传入transformer前预处理,使用了第3.4节所述的自适应感受场(ARF)模块,以完善局部特征提取,并确保特征顺利转移到Transformer。
- 为了利用参考图像和源图像自身和互相的全局背景信息,采用特征匹配变换器(FMT–3.2节)来进行内部和之间的关注。
- 为了有效地将转换后的特征从低分辨率传播到更高的分辨率(低分辨率:金字塔塔尖),并使FMT接受来自所有尺度的梯度训练,用第3.3节中描述的特征路径连接所有分辨率。
- 3.5节在讲,对于经FMT处理的N×H’×W’×F的特征图(Cost Volume),建立了一个H’×W’×D’×1的相关体积,以便通过3D CNN进行以下正则化处理(形成的是概率空间,然后再进行softmax处理)。H’、W’和F表示当前阶段特征图的高度、宽度和通道,N表示视图的数量,D’表示相应的深度假设的数量。
- 在得到正则化的概率量后,我们采取赢家通吃的策略来确定最终的预测结果。
- 3.6节,在模糊区域采用了加强惩罚的focal loss,对TransMVSNet进行端到端训练
3.2. Feature Matching Transformer (FMT)
第一句还是讲,之前的MVS work直接就取的卷积网络提取的特征,忽略了全局背景信息和图像间的特征交互。
MVSnet本质上是一对多的特征匹配任务,之前总关注两个视图间的是不是不合理(reference和source)
提出一个专门用在MVS上的Transformer
第3.2.1节介绍了注意力的前言;第3.2.2节进一步描述了所提出的FMT中使用的注意力机制,特别是它专门为MVS定制的;第3.2.3节展示了FMT模块的整体设计。
3.2.1Preliminaries 先验知识
传统的注意力机制这样的,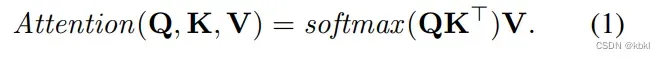
算Q和K间的相似度,然后根据这个权重从V中检索信息。但是QK转置相乘相当于做了个平方再softmax,这个方法计算成本太大了,于是根据Transformers are rnns: Fast autoregressive transformers with linear attention. 改进一下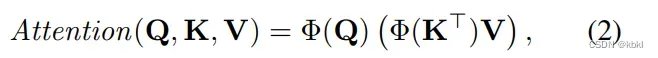
![]()
elu是指数线性单元激活函数,由于通道的数量远小于输入序列的长度,通过它,把计算的复杂性降低到线性,解决了高分辨率上计算注意力成本大的问题。
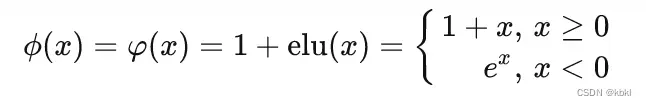
权重,这样还能突出权重吗????
Transformers are rnns: Fast autoregressive transformers with linear attention.
https://blog.csdn.net/qq_36717487/article/details/126142572
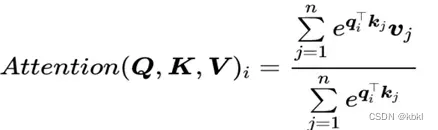
假设Q、K、V为nm维矩阵,
〖“(Q” ·𝐾〗^𝑇)·V 计算时的复杂度为O(nnm)
〖“Q” ·(𝐾〗^𝑇·V) 计算时的复杂度为O(mm*n)
而attention机制中qkv为向量,m=1
意思是降低复杂度,而且激活函数像softmax就行
ELU激活函数(指数线性单元)
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题(x=0的时候,无法更新),不过还是有梯度饱和和指数运算的问题。
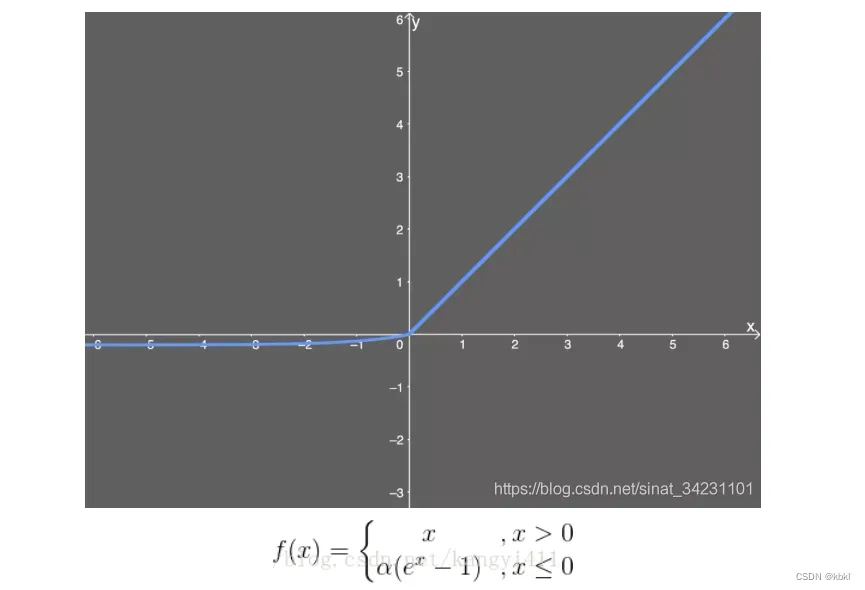
梯度消失:如果有太多的权重都是这样的太大或者太小的值,那么求得的梯度都几乎为0,那么我们根本无法调整网络。如果整个网络只有细微的更新,那么这个算法就不能随计算给网络带来改善,这个网络将毫无意义。
这个梯度几乎为0的现象即为梯度消失问题。
梯度爆炸:是梯度消失的反面,当在成本函数的悬崖上求导数时,便会出现梯度爆炸现象,梯度爆炸使得权重和偏置的值可能会爆发式地增大,进而导致整个网络爆炸。*在一些循环神经网络中,如LSTM和GRU,经常会出现梯度爆炸现象。*
3.2.2 Intra-attention and Inter-attention
图像内的长距离全局上下文聚合:Q和K在时同一图像的特征
图象间的特征交互:注意力层捕捉两视图的交叉关系,Q和K不是同一图像(即不同视角)
FMT中,我们对参考图像和源图像进行图像内的注意力
对源图像进行图象间的注意力(参考图像和每一个源图像),只更新原图像的特征(因为参考特征应该保持不变,因为要测相似性) 这个做了实验,讲的时候可以穿插着讲
3.2.3 FMT Architecture
为什么transformer需要位置编码?
Transformer的输入是将句子中的所有单词一次性输入到网络中进行学习,这使得序列的顺序信息丢失。因此我们需要通过其他途径将序列的顺序信息加入到模型中,Transformer提出了一种解决方案就是文章中的Positional Encoding。需要什么样的编码呢?
a)位置编码需要体现一个单词在不同位置的差异;b)位置编码需要有顺序关系,且位置编码不依赖于序列长度;c)位置编码需要被体现在一定的区间内。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
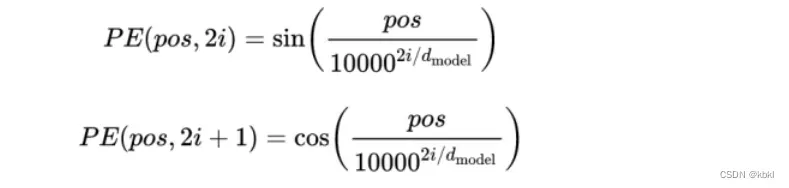
https://blog.csdn.net/Cream_wyx/article/details/118826127
FMT的提出:MVS是一对多的匹配问题,要同时考虑所有视图的上下文,根据FMT捕捉图像内图象间的信息
一对多的理解:双目(两个视角)是一对一的,即左边图像有啥对应右边图像有啥,然后预测深度
多视角的话(MVS)是一个参考图像,对应多个视图然后建深度图
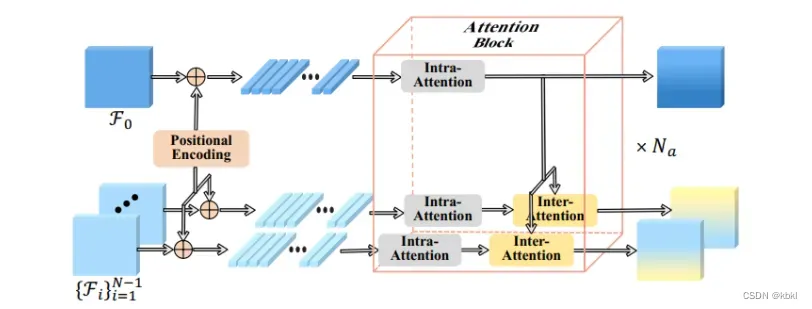
位置编码,增强了位置的一致性,让FMT对不同分辨率的特征图都鲁棒
F表示每个视图的扁平化特征图(一张浅蓝色的图),经过Na个注意力块处理
进入注意力块,参考特征和源特征首先计算具有共享权重的内部注意力,并通过内部注意(全局信息)对各自的特征进行更新,然后计算参考特征和源特征的图像间注意力(单向的),根据参考特征获得的信息更新所有源特征。
谁是qkv?
图像内q k:同一张feature map
图像间q k:不同view,一个来自reference 一个来自某一个source
为什么要根据参考图像更新源图像?
他的思路应该是:每个源和参考相互交互一遍,但是这样不能保证源1和源2是对同一张图像交互的,相似性也就没法比较了
也可以全交互一遍,但是效果不好,时间太长
现在只是在更新图像,没有到构建cost volume呢是吗?
是的
3.3. Transformed Feature Pathway
因为mvs和transformer计算成本都很大,论文只能利用低分辨率下的特征图(就是金字塔顶端)
- 低分辨率更新后的特征如何传到高分辨率,是一个问题
- FMT想在所有图像尺度的监督下进行训练
因此设计了转换的特征通路,就是图二的时候,经过FMT处理的特征图被内插到更高的分辨率,加到下一个图像比例的相应原始特征图中
3.4. Adaptive Receptive Field (ARF) Module
FPN主要关注局部,相对来说局部邻域内的上下文
Transformer通过位置编码将全局上下文信息编码到特征图中,可以理解为具有全局感受野的卷积层
他俩就不搭(具体哪不搭???)在上下文范围方面
为此提出ARF,用来适应的调整提取特征的范围,
具体实现:通过可变形卷积,这卷积针对采样的位置学习了额外的偏移量,而且能根据局部上线问自适应的扩大感受野。
FPN
先验知识
1.感受野
全连接层就是线性层
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图1所示。
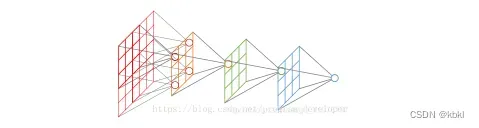
卷积、池化都有一个重要作用就是增大感受野,为什么感受野这么重要呢?
前面看过感受野的定义,是表示在前几层对应的图像区域的大小,那么为了保证所利用的信息是全局的,而不仅仅是局部信息,我们就应该保证感受野较大。同时,合理计算感受野,可以保证效率,例如,输入图像大小是128*128,如果最后一层的感受野已经可以超过128,我们可以认为在做最后的分类判断时所用到的特征已经涵盖了原始图像所有范围的信息了。如果能够尽可能的降低网络的参数总量,也十分重要。
————————————————
原文链接:https://blog.csdn.net/qq_41076797/article/details/114434415
2.图像浅层特征
- 浅层特征:浅层网络提取的特征和输入比较近,包含更多的像素点的信息,一些细粒度的信息是图像的一些颜色、纹理、边缘、棱角信息。此时的语义信息还比较少。
- 原理:浅层网络感受野较小,感受野重叠区域也较小,所以保证网络捕获更多细节。
- 优缺点:分辨率更高,包含更多位置、细节信息,但是由于经过的卷积更少,其语义性更低,噪声更多。
3.图像深层特征
- 高层信息:深层网络提取的特征离输出较近,一些粗粒度的信息,包含是更抽象的信息,即语义信息
- 原理:感受野增加,感受野之间重叠区域增加,图像信息进行压缩,获取的是图像整体性的一些信息
- 优缺点:具有更强的语义信息,但是分辨率很低,对细节的感知能力较差。
深层网络容易响应语义特征,浅层网络容易响应图像特征。
正片
FPN提出的动机:结合上边说的,高层网络虽然能响应语义特征,但是由于Feature Map的尺寸太小,拥有的几何信息并不多,不利于目标的检测;浅层网络虽然包含比较多的几何信息,但是图像的语义特征并不多,不利于图像的分类。这个问题在小目标检测中更为突出。
思想:把高层的特征传下来,补充低层的语义,这样就可以获得高分辨率、强语义的特征,有利于小目标的检测。
Q:卷积核如何改变的通道数?
卷积核只得不是单纯的一层,它可以是多层而且必须是多层,比如RGB图片,有三个通道,那么一个卷积核就必须同时对这三层卷积,即卷积核与原通道相乘再相加,所以就会有这样一种情况,有多少卷积核就会有多少通道,他会改变通道数。
卷积过程

比如现在是6张图,16个卷积核的话,每个卷积核都会和6张图交互进行卷积,生成16张图也可以理解为16个通道
那么fpn改变通道数的操作就可以理解了
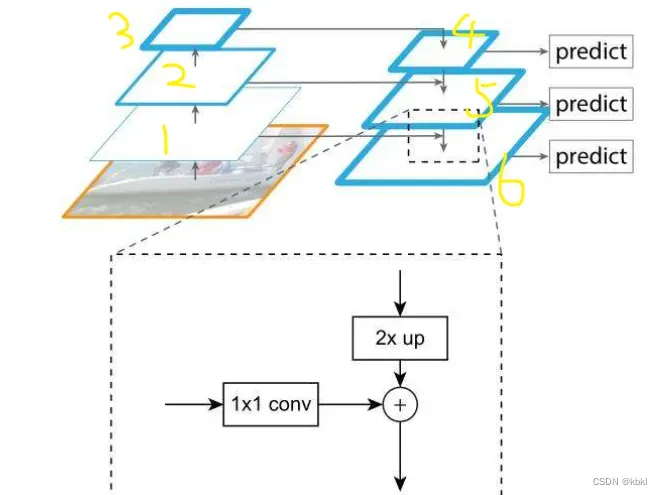
每个阶段有七个卷阶层,最后的输出作为fpn网络的单个一层
这样FPN进行预测,整合一下就得到最后的结果了,与其他方式相比主要保证高分辨率同时也有强语义的特征,可以说是深层和浅层的完美结合。
Faster rcnn利用fpn的过程

FPN三层预测怎么整合的????
3.5. Correlation Volume Construction
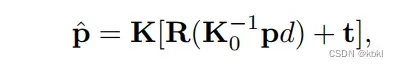
双线性插值的作用:对于找不到的对应点(对应点超出了特征图宽高边界),用插值填充。保证还是原来的像素位置
p处的成对特征相关度为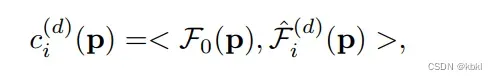
Fi(d)表示在深度d的第i个源图像的特征图。在像素点p处,深度d的第i个源图像与参考图像的特征相关度
我们以其在深度维度上的最大相关性来分配出一个像素级的权重图。然后表示这个相关空间为
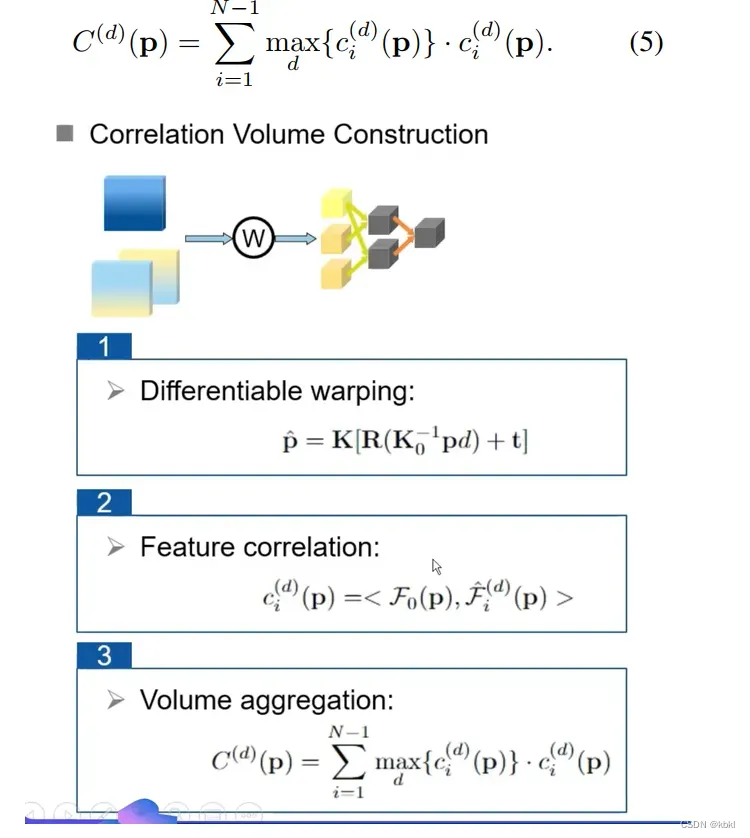
3.6. Loss Function
每个深度估计阶段的focal loss为:

对这个图的解释:采用focal loss可以看到他的权重主要集中再边界上,也就是更注意边界的训练,因此深度图的辨别也更好。
4. Experiments
4.1. Datasets
- DTU[1]是在控制良好的实验室环境下用固定的相机轨迹拍摄的,包含7种不同照明条件下49个视图的128次扫描(物体吧)。 按照MVSNet[32]的设置,我们将数据集分成79次训练扫描、18次验证扫描和22次评估扫描。
- BlendedMVS数据集[34]是一个用于多视图立体训练的大规模合成数据集,包含各种物体和场景。该数据集被分成106个训练扫描和7个验证扫描。
- Tanks and Temples[12]是现实采集的一个数据集,是公开benchmark。它包含一个由8个场景组成的中间子集和一个由6个场景组成的高级子集。 不同的场景有不同的尺度、表面反射和曝光条件
4.2. Implementation Details
我们用PyTorch实现TransMVSNet,并在DTU训练集[1]上进行训练。在训练阶段,我们设定输入图像的数量为N=5,图像分辨率为512×640。对于从粗到细的正则化,深度假设的采样范围为425mm到935mm;每个阶段的平面扫描深度假设的数量分别为48、32和8。分辨率分别是(10.625mm,15.9375mm,63.75mm)
该模型用Adam训练了10个历时,初始学习率为0.001,在6、8、12个历时后分别衰减了0.5倍。在DTU上训练时,我们设定γ=0。在8个NVIDIA RTX 2080Ti GPU上,批次大小为1,训练阶段总共需要约16小时,占用每个GPU的10GB内存。
Dense hybrid recurrent multi-view stereo net with dynamic consistency checking.
对于深度过滤和融合,我们遵循[30]中提出的动态检查策略,其中同时应用了置信度阈值和几何一致性。
4.3. Experimental Performance
DTU的实验
评价指标:精确度 完整度
精确度
Accuracy is measured as the distance from the MVS reconstruction to the structured light reference, encapsulating the quality of the reconstructed MVS points.
也可以叫做precision,衡量重建后的点云(R)到ground truth(G)的距离

完整度
Completeness is measured as the distance from the reference to the MVS reconstruction, encapsulating how much of the surface is captured by the MVS reconstruction.

原文链接:https://blog.csdn.net/qq_41340996/article/details/124786530
precision:量化重建的准确性,重建的点与GroundTruth有多接近
recall:量化重建的完整性,重建的点多大程度上覆盖了所有的GroundTruth
**F1分数(F1 Score):**精度和完整度是一对trade-off的指标,因为可以让点布满整个空间来让完整度达到100%,也可以只保留非常少的绝对精确的点来得到很高的精度指标。因此最终评估的指标需要对二者进行融合。假设精度为p,完整度为r,则F1分数为它们的调和平均数
总体是准确率和完整性的平均值,表示模型的整体性能。TransMVSNet在准确性和完整性方面取得了有竞争力的表现,并在总体上大大超过了所有已知方法。能得到一个很好的平衡
Tanks and Temples的实验
评价指标F-score
原始图像分辨率(576 × 768), N = 5 and γ = 2.
高级集:法庭,中级集:马
τ是官方确定的与场景相关的距离阈值,较深的区域表示在τ方面遇到的误差较大。第一行显示法庭场景的召回率(τ = 10mm);第二行显示马场景的精确度(τ = 3mm)。
对BlendedMVS数据集的评估
对BlendedMVS数据集的评估 DTU[1]和Tanks and Temples[12]都对点云应用了评估指标,这样的话gt会变小(有地方转换不准)。深度图是TransMVSNet的直接输出。
BlendedMVS验证数据集[34]上进一步展示深度图的质量,我们设定N=5,图像分辨率为512×640,
并应用[7]中描述的评价指标,其中深度值被归一化,使不同深度范围的深度图具有可比性。
EPE代表端点误差,即预测和gt深度之间的平均l-1距离;e1和e3代表深度误差大于1和大于3的像素比例(%)。与其他方法相比,TransMVSNet取得了令人印象深刻的结果,证明了其产生高质量深度图的能力。
4.4. Ablation Study
baseline CasMVSNet trained with ‘-1 loss
在DTU评估数据集[1]上使用不同组件的定量性能。F.L.是focal loss的缩写。单位是MB为内存占用率(Mem.),G为乘积运算(MAC),秒为推理时间。
应用焦点损失后,整体性能提高了1.7%,而计算成本保持不变。由于线性变换器的计算效率,我们能够利用FMT,在内存和MAC方面没有什么额外的成本,但其推理速度却慢了近1.4倍。有了转换后的特征路径,完整性和整体性能都得到了提升,而其内存占用率几乎没有增加,这表明该路径的有效性和效率。在附加了ARF模块后,整个TransMVSNet能够以很大的幅度实现最先进的性能。ARF模块在各方面都带来了相当大的计算成本。毕竟,推理时间仍在一秒之内,与基于RNN的方法相比,这是可以接受的[28,30,33]。
5. Discussions
作者对TransMVSNet的已知局限性列举如下:
transformer降低了推理的速度
与其他从粗到细的MVS网络类似,我们的方法对推理的超参数很敏感,例如深度假设的数量、深度间隔和深度间隔的衰减因子。
6. Conclusion
- 句1:介绍任务,总结论文工作
- 句2:对方法具体解释
- 句3:附加的一些工作
- 句4句5:总结结论,成果:实验做的多好 展望:希望全局信息得到重视
7.补充工作
点云
余留问题:
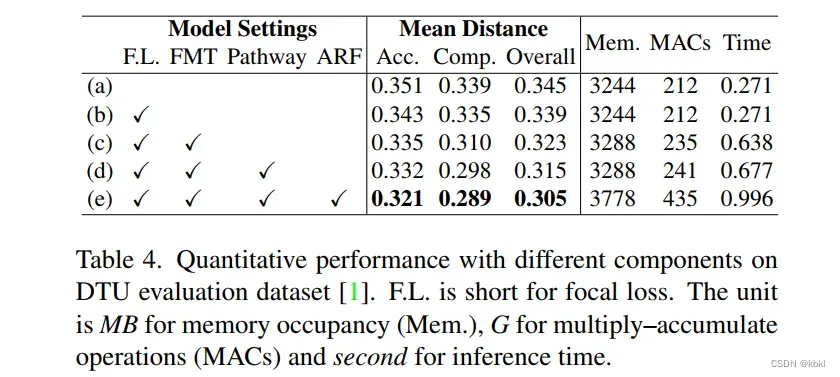
这里是对处理一张图的指标吗,还是求一个深度图呢?
文章出处登录后可见!