Huggingface的方式安装
在Huggingface个人目录下有一个token号,这个tokens号要在服务器登陆的过程中进行添加;
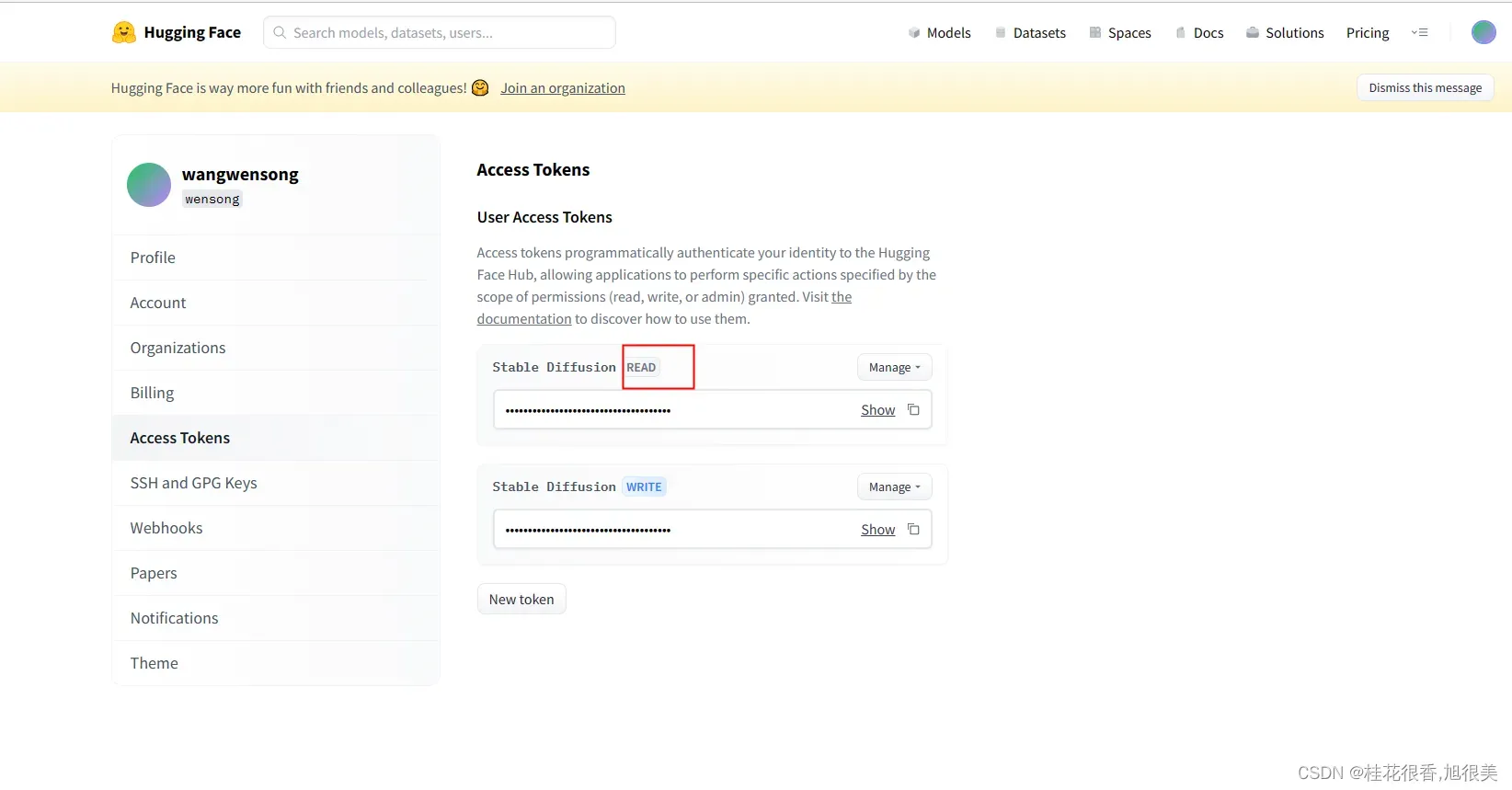
1,在服务器登陆要输入huggingface登陆:
huggingface-cli login
# READ 权限的就够了
运行完命令,按照提示将之前的token复制过来,然后 Y ,回车,登陆成功!
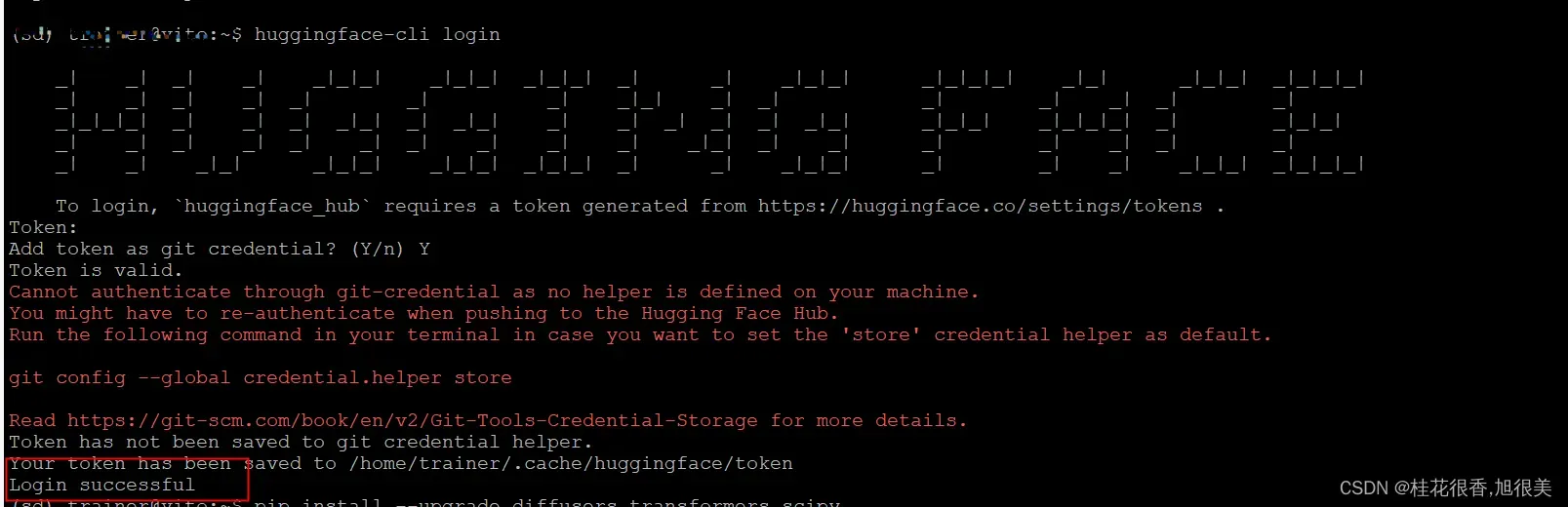
2,相关包安装
pip install --upgrade diffusers transformers scipy
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
pip install accelerate # 这个加速包可以不装,但是他一直提示看着难受的就装了
3,运行模式
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-1"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token=True)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
哈哈,报错,error key ‘sample’
打印下pipe看看

只有两个key:images 和 nsfw_content_detected
那改成 images试试
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-1"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token=True)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["images"][0]
image.save("astronaut_rides_horse.png")
第一次运行会下载模型,需要点时间,生成的时候显存大概占用12G

成功了,看下生成的怎么样。

马马虎虎,还有很大优化空间。
补充
显卡显存不足10G的话可以改成float16 precision
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-1"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
#pipe = StableDiffusionPipeline.from_pretrained(model_id, use_auth_token=True)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["images"][0]
image.save("astronaut_rides_horse.png")
#To swap out the noise scheduler, pass it to from_pretrained:
要交换噪声调度器,将其传递给from_pretrained:
import torch
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
model_id = "CompVis/stable-diffusion-v1-1"
# Use the K-LMS scheduler here instead
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, use_auth_token=True)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["images"][0]
image.save("astronaut_rides_horse.png")

哈哈啊哈啊
PS:huggingface-cli: command not found
参考
CompVis/stable-diffusion-v1-1(Hugging Face)
模型方法–Stable Diffusion
CompVis/stable-diffusion(github)
Stable Diffusion with 🧨 Diffusers
文章出处登录后可见!
已经登录?立即刷新