夕小瑶科技说 原创
作者 | 卖萌酱
文心一言的这波更新,是真的杀疯了。
笔者测试了刚刚更新的文心一言,发现效果相比上一版又有了一个质的飞跃,内容创作、推理、代码等诸多维度的能力都有了肉眼可见的效果提升。
更加王炸的是,文心一言领先国内一众竞品,率先来到生态位奇点,正式发布了文心一言插件和集AI应用开发、部署、交流于一体的大模型社区。
作为AI开发者,从此不必再羡慕隔壁的Discord社区和ChatGPT插件生态了。
今天之后,我们终于可以基于比ChatGPT更强大的国产大模型,比Pytorch更快更稳的国产框架底座,去开发服务国人的大模型插件和大模型应用了!
昨日,笔者跟小伙伴一起参加了百度举办的WAVE SUMMIT 2023深度学习开发者大会,会上,百度CTO王海峰等多位高管从AI的发展趋势、大模型的技术应用、框架的生态布局和AI原生应用等角度阐述了 “我们将迎来怎样的AI原生时代” 。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
Hello, GPT4!
而作为AI开发人员,笔者也自去年ChatGPT发布后就一直在思考:
通用大模型解决了所有问题吗?
除了大模型插件,我们还需要什么?
大模型时代,算法工程师该怎样开发AI应用?
解决AI任务的最快路径不再是大量标注数据+大量模型训练了,那么,怎样的开发套件能最适合新的开发范式?
大模型这么重,部署成本极高、推理速度挑战极大,普通人开发的AI应用又将如何面向大量用户提供服务?
在这场发布会后,笔者心中的答案清晰了很多。
人类之所以强大,不仅是因为人类聪明,更重要的是人类学会了制作工具、使用工具来拓展自己的能力。
同样的,通用大模型是AI原生时代的大脑,它无法解决所有的问题,但当通用大模型的指令理解能力、思维链推理能力、信息整合能力优化到足够强之后,便具备了“使用工具”扩展自身能力的可能性。
而最新版的文心一言,就在国内大模型中绝对领先,能力率先优化到了足以掌握工具使用的水平。如今,新版的文心一言已经熟练掌握超过200个创作体裁,内容丰富度是初期的1.6倍、思维链长度是初期的2.1倍,知识点覆盖是初期的8.3倍。
于是,文心一言有了“插件”的概念,开始了邀测,并于昨日的WAVE SUMMIT发布会上重磅推出了自己的插件生态,同时发起了开发者共创生态的号召。

“插件时代”来了
笔者有幸拿到了文心一言当前内置的全部5个官方原生插件的内测,包括览卷文档(长文档分析、摘要、润色、改写等)、E言易图(数据洞察图表生成)、说图解画(基于图片的交互)、一镜流影(文字转视频)和百度搜索:
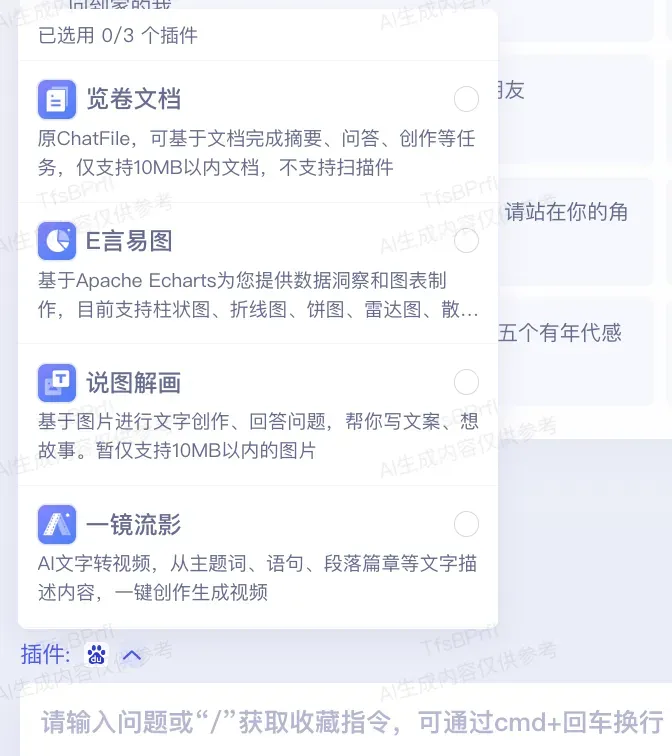
话不多说,一起来随笔者感受下官方原生插件的惊艳!
一镜流影——文字转视频
我们知道,做一个品牌营销视频是一件商业价值很高,但同时也是难度很大、流程繁琐、非常耗时的工作。于是,笔者果断选择了难度最大的一镜流影(文字转视频)插件进行测试。
比如,我们让文心一言生成一个推广牛奶品牌“鲜草之源”的营销视频:
文生视频
这个效果,让笔者彻底惊住了。
什么?原来做视频已经是门槛这么低的事情了吗?而且还是一个从画面、文案到配音都挑不出毛病的品牌营销视频!
笔者也体验过ChatGPT的生态下的一些文生视频的插件,但发现普遍偏玩具级,难以生成真正有用的视频。但百度文心一言官方出品的这个文生视频的插件,着实让笔者惊艳住了。
不得不说,官方yyds。。。
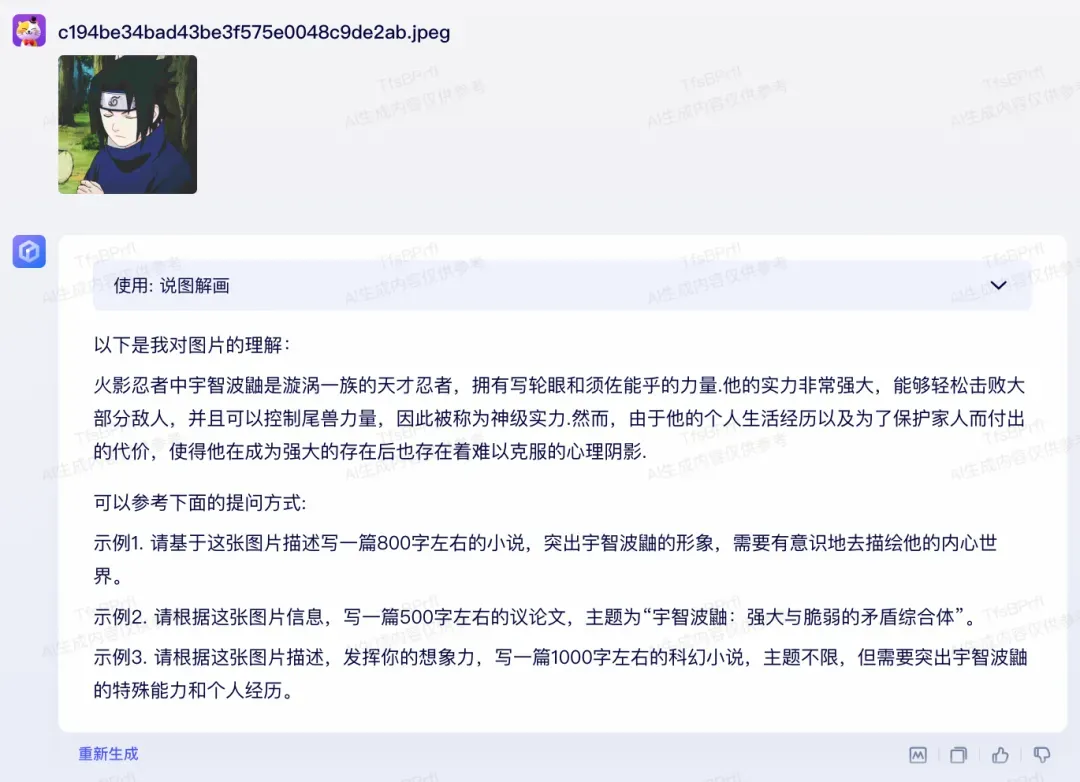
说图解画——看图说话
说图解画插件的效果也非常惊艳。比如笔者上传了一张《火影忍者》动漫角色宇智波佐助的剧图,文心一言说图解画插件不仅可以精准的认出佐助,而且给出了非常到位的人物描述。
除此之外,还有E言易图(数据洞察图表生成),以及早期开始内测的百度搜索和览卷文档插件。
而现在,不止官方插件,昨天文心一言还正式启动了大模型插件开发的邀请测试,并向广大开发者提供了插件开发工具集。开发者可以自由进行信息服务类、工具类、基于大语言模型创新类等各种类型的插件开发了。
当然,如果你觉得单纯的开发插件、为大模型拓展能力边界不够过瘾,那么,我相信这次WAVE SUMMIT上重磅发布的“星河大模型社区”一定会让你眼前一亮。
星河大模型社区:承载AI原生应用的爆发
飞桨开发者社区AI Studio中文名是“星河社区”,寓意“文心加飞桨,翩然赴星河”。说起AI Studio,相信很多读者小伙伴都不陌生了,它已是中国最大的AI开发者社区,凝聚了609万个开发项目。
如今,AI Studio进行了全新升级,正式推出星河大模型社区。百度希望和所有的开发者一起,在飞桨和文心的加持下,共建星河社区,共赴通用人工智能的星辰大海。
星河大模型社区不仅提供了丰富的功能方便开发者进行交流,而且面向AI开发者推出了一体化的大模型开发体验,目前上线的大模型创意应用已达到300多个!
老规矩,先放传送门:
https://aistudio.baidu.com/community
围绕大模型应用开发,星河大模型社区展开了非常丰富的功能。进到首页,能看到“频道”、“应用”和“创意坊”三个子栏。
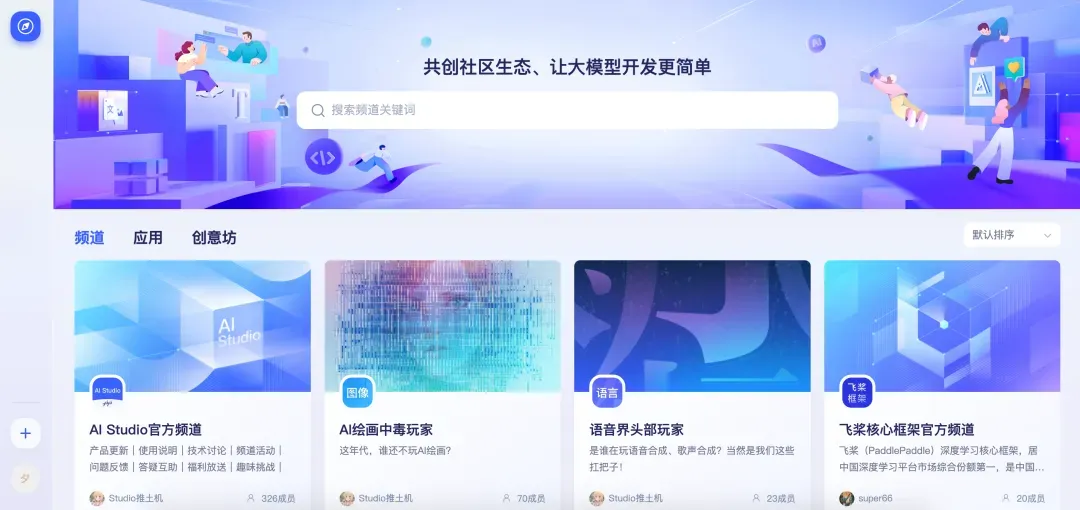
你可以进到感兴趣的频道,与志同道合的小伙伴交流大模型开发和使用心得。你可以作为普通用户,在频道内向广大的开发者发需求,求帮助,也可以主动分享你的开发成果推荐给频道内的用户使用。
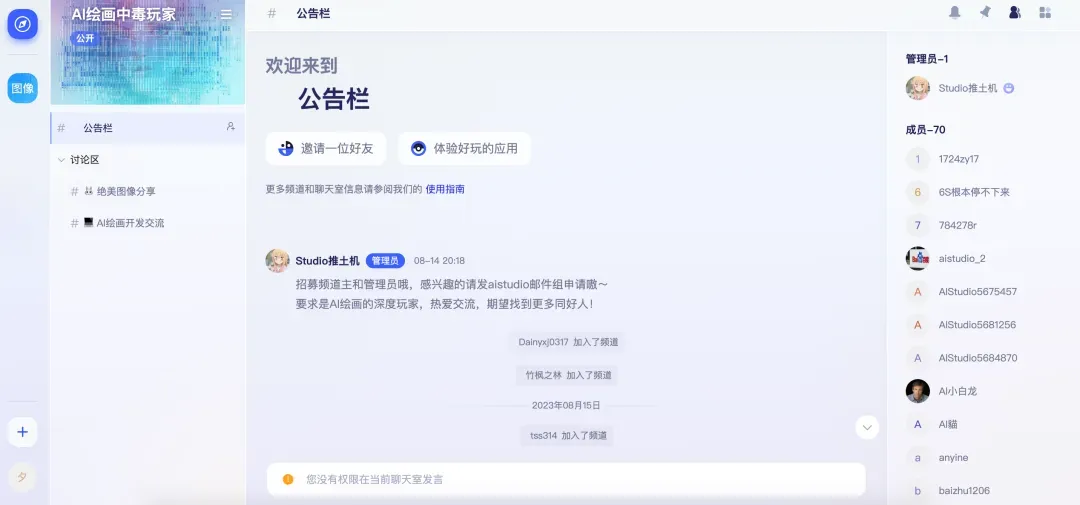
而在应用栏,则可以看到大量的炫酷大模型应用。目前星河大模型社区的开发者模式还处在邀测阶段,已经上线了300多个有趣或实用的创意应用。
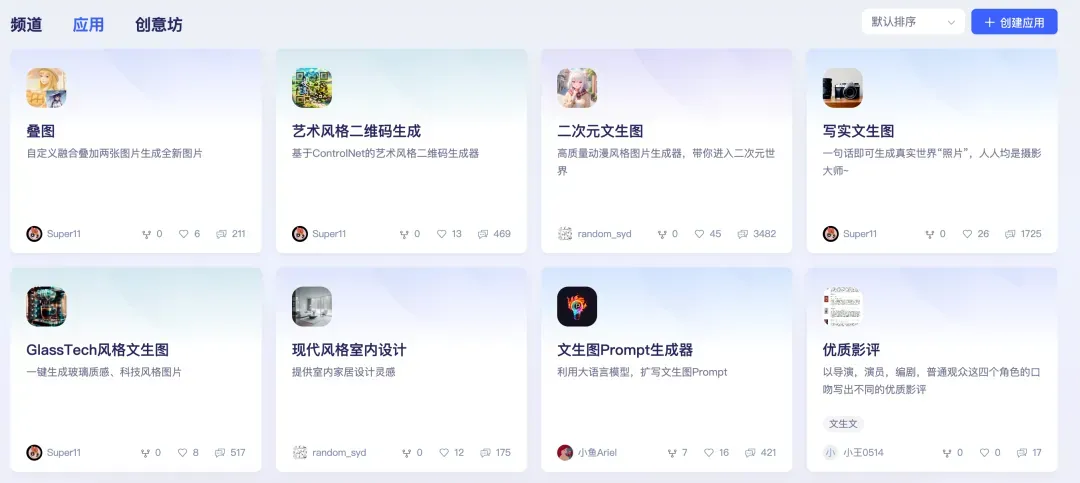
作为开发者,你更可以直接在应用栏点击右上角创建应用。
比如我们进到应用创建页,选中AI对话类型,尝试创建一只嘤嘤怪。
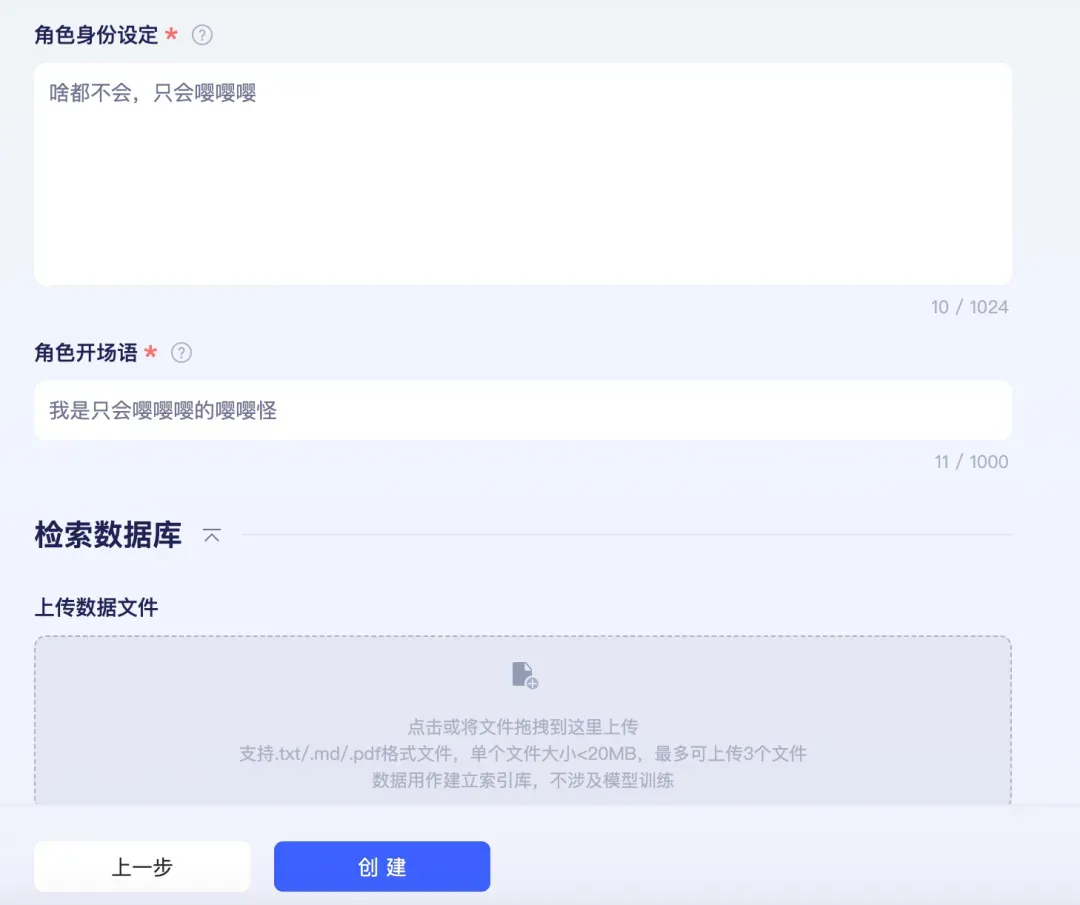
创建完成后,你便可以与自己刚创建的应用进行对话调试,符合预期后,便可以发布你的对话应用,分享给社区里的其他小伙伴了。
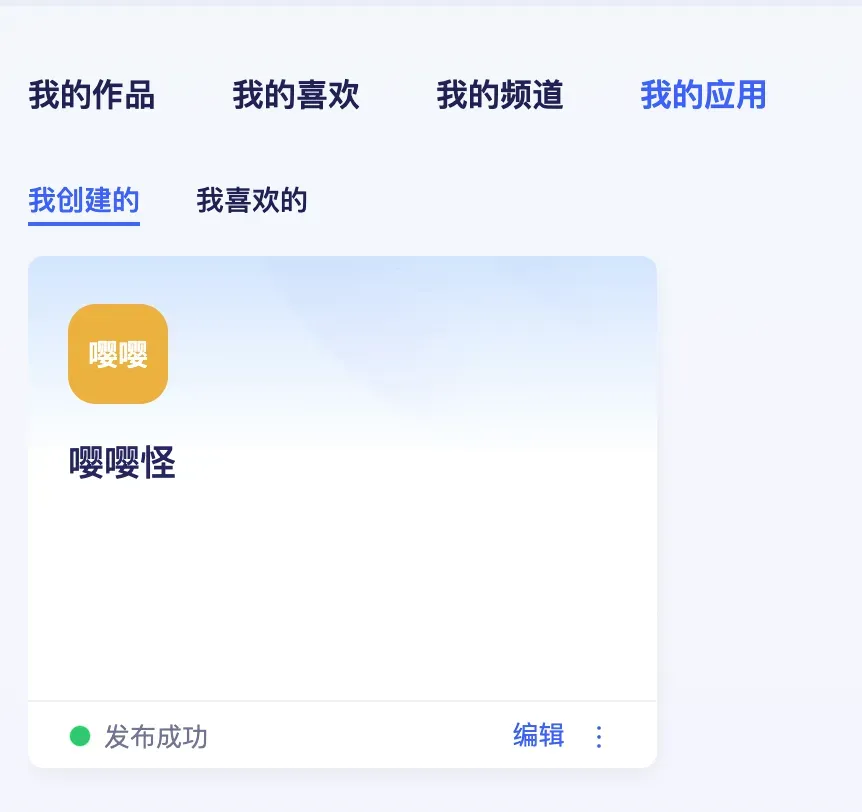
应用发布后,便可以在社区的应用页找到你发布的应用了。其他用户可以直接访问你的应用,体验相应的功能,甚至还可以通过类似github fork的方式补充提示词,进行二次效果优化。
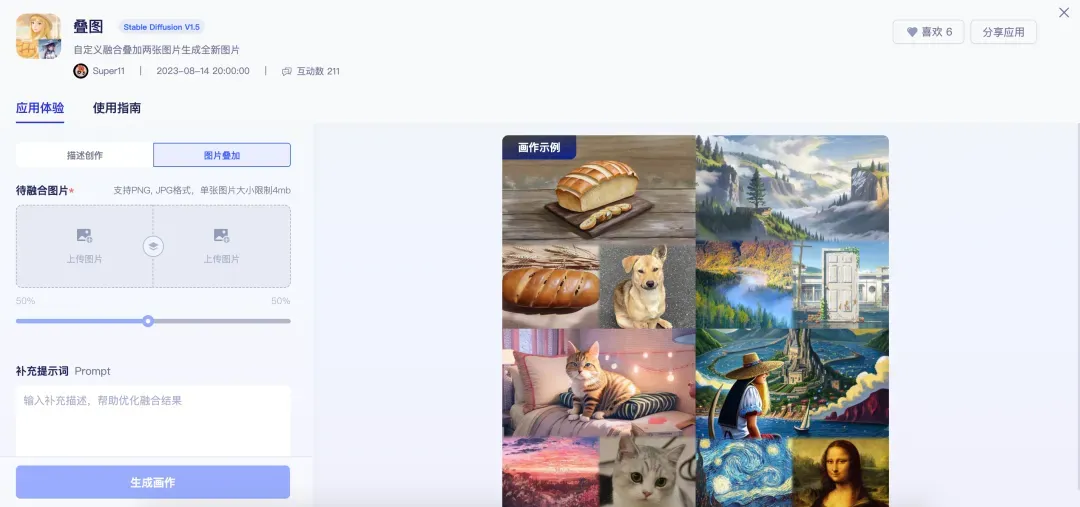
需要注意的是,尽管本文演示的应用较为简单,但星河大模型社区支持的开发维度远不止prompt工程,你还可以外接知识库,甚至未来还会支持模型微调等,将充分打开大模型应用开发的想象力。
此外,星河大模型社区还有一个相当炸裂的“隐藏能力”——底层依托于强大的飞桨框架和雄厚的算力池,自动帮开发者实现了高效率、高并发的模型推理支持。
也就是说,作为AI开发者,你可以将你的绝大部分注意力完全聚焦在应用创意层面,无需过多担心底层的技术优化和算力问题了!
过硬的底层技术,全新发布的飞桨开源框架v2.5
“无需担心底层”是每个AI应用开发者的终极梦想,但真正能做到位的AI开发套件其实很少。
已经凝聚起800万开发者、22万企业和80万模型的百度飞桨,在这个问题上是当仁不让的业界典范。
训练速度慢、推理效率低、算力不够用等问题,被很多普通的大模型AI应用开发者深深困扰。
如今,全新发布的飞桨开源框架v2.5显然已经成为了大模型时代算法工程师手中的开发利器。

“文心大模型的训练速度达到优化前的三倍,推理速度相比初版已提升30倍”
这个数字的背后,则是飞桨框架从硬件、网络通信到中间件再到框架层的全链路深度优化,是飞桨自研的端到端自适应混合并行训练技术、模型压缩、推理、服务部署协同优化后的结果。
在大模型训练方面,飞桨与文心联合优化的实践中,百度总结了大模型性能优化方法论:
-
与硬件集群协同优化,提升有效训练时间占比。对于长时间、高负荷的大模型训练而言,降低训练集群的故障率和训练恢复成本无疑是至关重要的。在这一点问题上,新版的飞桨框架做了大量的工作,包括做异常硬件的检测,通信的初始化,以及异步参数耗时的优化等,有效减少了集群的故障。与此同时,出现故障后,还能够做到快速自动恢复。
-
与芯片/存储/网络协同优化,提升训练吞吐速度。这也是飞桨一直以来持续优化的方向。在这个维度上,飞桨框架充分发挥了计算硬件单机基础的数据潜能,集成了数据读取、混合精度、选择性重复计算等计算策略,以及算子优化等方法,把计算的潜能充分地发挥出来。此外,还大幅提升了分布式的扩展效率,这里面又涉及到多维混合并行策略,通信和计算的异步调度,以及流水线调度等一系列底层技术 。
-
与模型算法协同优化,提高收敛效率。特别是在大模型训练中,优化收敛效率和稳定性,可大幅度减少训练时间,达到事半功倍的效果。
而在推理部署阶段,更是延展开了一系列的优化策略。
-
强大的模型压缩、量化方法。大模型的前向计算过程中,激活分布常常面临异常值比较大的问题。这导致量化的时候挑战非常大。对此,飞桨提出了Shift-Smooth Quant方法,这个方法,可以让整个量化损失可以得到大幅减小,相应的整个模型效果也会得到提升。
-
迭代生成Token Generation的优化。我们知道现在主流的大语言模型都是自回归模型,涉及到的迭代生成Token Generation的阶段是显著的访存密集型场景。对此,飞桨在这个阶段做了深入的混合量化,使得大模型的效果在访存受限的场景下也会更好。
-
prompt变长输入的处理。在prompt输入端,飞桨也做了深入优化。由于模型的输入是变长的,一个batch内的样本长度分布可能差异很大。对此,飞桨针对这个变长率先推出了动态插入的批处理技术,通过这个技术就可以更好地提升GPU的资源利用率,根据这个动态变化做好服务的调度。
除此之外,还有飞桨发起的硬件生态共创计划,与硬件伙伴实现联合优化,才是一个大模型能够实现极限推理性能的保障。

通过这些硬核的底层技术支撑,得以构成了支撑大模型研发的大模型套件。真正用过飞桨开发套件的开发者不难发现,飞桨系的开发套件相对于学术界流行的Hugging Face PEFT等同类工具,其性能会有更大的领先优势。
说到这里,你可能想问,飞桨升级这么大,文心一言也升级这么大,作为开发者的我们,开发范式是不是也该升级一下了?
Comate
没错,在Coding问题上,这次WAVE SUMMIT还重磅发布了智能编程助手ComateX和Comate Stack工具套件,实现了代码解释、代码生成、行间注释生成、单元测试用例等能力。
话不多说,直接上Demo:
comate x,
由于最新发布的“文心一言”,代码能力提升幅度相当大,Comate系列产品也迎来如此大幅的升级版。
它能够在代码研发的全周期做到帮你想、帮你写和帮你改。不仅能做代码生成、解释,甚至还能自动生成注释、单元测试、文档、命令行和接口等。目前已经支持了30多种编程语言和10多种IDE,甚至包括一些非常小众的编程语言。
如今,Comate产品已经在百度内部广泛使用,有超过100家合作伙伴,处于成熟商业化阶段。ComateX现已面向企业开发者开放,登陆Comate官网申请试用:
🔗 https://comate.baidu.com/
或关注文心大模型或飞桨paddle paddle公众号,回复「Comate 」申请。
听完这场硬核的WAVE SUMMIT发布会,笔者只能说:
中国的AI原生时代已至!
最后,贴上昨日WAVE SUMMIT上百度CTO王海峰的一张PPT:

未来,这张图,这句诗,或许会成为中国版AI原生时代的高度概括。

文章出处登录后可见!