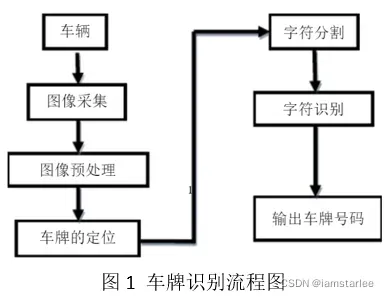
本次大报告利用MATLAB函数功能,设计和实现了一个车牌识别系统。车牌识别系统的基本原理为:将手机拍摄到的包含车辆牌照的图像输入到计算机中进行预处理,再对牌照进行搜索、检测、定位,并分割出包含牌照字符的矩形区域,然后对牌照字符进行二值化并将其分割为单个字符,然后将其逐个与创建的字符模板进行匹配,匹配成功后输出车牌号码的数字。车牌识别的工作流程如下图:
一、 图像预处理
预处理的具体操作是规整大小、噪声滤波、规整为统一大小便于后续处理的参数设置,提高定位精确度以及识别正确率。规整大小函数为imresize(I,[row,col])
接着进行图像平滑滤波。RGB图像的平滑滤波,需要将R、G、B三个色道分别提取出来,分别滤波。这里采用3×3的中值滤波算子,对三个色道分别滤波,然后使用cat函数将三色道整合起来。
代码
%% 加载图片
I=imread('Lisence.jpg');
figure(1),imshow(I);title('original image');%显示车牌原图
%% RGB 转 Gray
I1=rgb2gray(I);
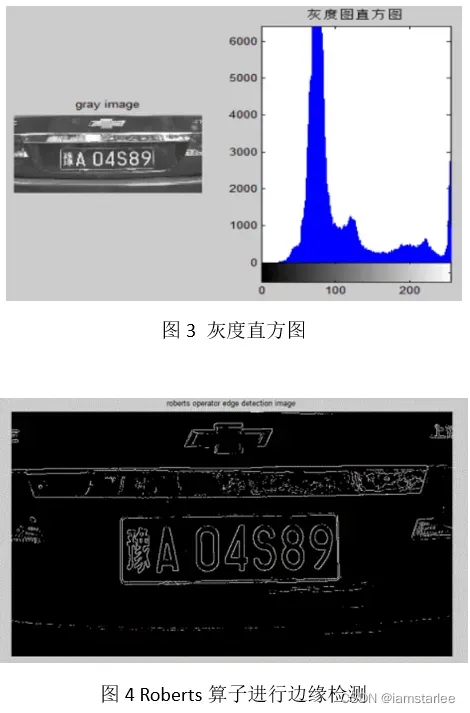
figure(2),subplot(121),imshow(I1);title('gray image');
figure(2),subplot(122),imhist(I1);title('the histogram of the picture');
%% 使用 roberts 算子进行边缘检测
I2=edge(I1,'roberts',0.18,'both');% select the threshold=0.18
figure(3),imshow(I2);title('roberts operator edge detection image');
%% 腐蚀操作
se=[1;1;1];
I3=imerode(I2,se);%对图像进行腐蚀操作,即膨胀的反操作
figure(4),imshow(I3);title('corrosion image');
%% 平滑图片
se = strel('rectangle',[25,25]);
I4 = imclose(I3,se);%图形聚类、填充图形
figure(5),imshow(I4);title('smoothing image');
%% pick out the small objects
I5=bwareaopen(I4,2000);%remove the part smaller than 2000
figure(6),imshow(I5);title('remove the small objects');


二、 车牌定位
车牌定位依据的是车牌蓝色底色的特点,即颜色区分法,因此,确定车牌底色的蓝色RGB值范围非常重要。先打开一幅车牌图片,查看下车牌底色的RGB值。车牌底色为蓝色,因此B值较高,R和G值较小,初步考虑车牌底色RGB范围应是:R<=RT, G<=GT, B>=BT (RT,GT,BT分别为RGB三色道的颜色阈值)从网络上查询相应资料,并实际取点查看RGB色值,最终确定的判断门限。

代码
%% 车牌定位
[y,x,z]=size(I5);
myI=double(I5);
tic % begin timing
Blue_y = zeros(y,1); % generate a zero matrix of y*1
for i=1:y
for j=1:x
if(myI(i,j,1)==1)
Blue_y(i,1)=Blue_y(i,1)+1;
end
end
end
[temp, MaxY]=max(Blue_y);
PY1=MaxY;
while(Blue_y(PY1,1)>=5&&(PY1>1))
PY1 = PY1-1;
end
PY2 = MaxY;
while(Blue_y(PY2,1)>=5&&(PY2<y))
PY2 = PY2+1;
end
IY=I(PY1:PY2,:,:);
%行方向车牌区域确定
%X方向
Blue_x=zeros(1,x);
for j=1:x
for i=PY1:PY2
if(myI(i,j,1)==1)
Blue_x(1,j)=Blue_x(1,j)+1;
end
end
end
PX1 = 1;
while(Blue_x(1,PX1)<3&&(PX1<x))
PX1=PX1+1;
end
PX2=x;
while((Blue_x(1,PX2)<3)&&(PX2>PX1))
PX2=PX2-1;
end
PX1=PX1-1;
PX2=PX2+1;
dw=I(PY1:PY2-8,PX1:PX2,:);
t=toc;
figure(7),subplot(121),imshow(IY),title('Line direction areas');
figure(7),subplot(122),imshow(dw),title('positioning color images');
三、 车牌区域处理
对分割出的彩色车牌图像进行灰度转换、二值化、均值滤波、腐蚀膨胀以及字符分割以从车牌图像中分离出组成车牌号码的单个字符图像,对分割出来的字符进行预处理(二值化、归一化),然后分析提取,对分割出的字符图像进行识别给出文本形式的车牌号码。

四、 字符分割
在汽车牌照自动识别过程中,字符分割有承前启后的作用。它在前期牌照定位的基础上进行字符的分割,然后再利用分割的结果进行字符识别。字符识别的算法很多,因为字符之间间隔较大,不会出现字符粘连情况,所以此处理采用的方法为寻找连续有文字的块,若长度大于某阈值,则认为该块有两个字符组成,需要分割。一般分割出来的文字要进行进一步处理,以满足下一步字符识别的需要。但是对于车牌的识别,并不需要太多的处理就已经可以达到正确识别的目的。在此只进行了归一化处理,然后进行后期处理。

代码
%% 字符分割与识别
% 车牌的进一步处理
imwrite(dw, 'dw.jpg');
a = imread('dw.jpg');%读取
b = rgb2gray(a);
imwrite(b,'gray_license_plate.jpg');
figure(8);subplot(321),imshow(b),title(车牌灰度图像);
g_max=double(max(max(b)));
g_min=double(min(min(b)));
T=round(g_max-(g_max-gmin)/3); %T为二值化的阈值
[m,n]=size(b);
d=(double(b)>=T); %d=二值图像
imwrite(d,'binary_license_plate.jpg');
subplot(322),imshow(d),title('before filtering binary license plate');
% 均值滤波前
% 滤波
h=fspecial('average',3);
% 建立预定义的滤波算子,average为均值滤波,模板尺寸为3x3
d=im2bw(round(filter2(h,d))); %使用指定的滤波器h对h进行d即均值滤波
imwrite(d,'after_average_license_plate.jpg');
% 对图像进行操作
% 膨胀或腐蚀
se = strel('square',3); % 使用一个3x3的正方形结果元素对象创建的图像进行膨胀
se = eye(2); %eye(n) returns the n-by-n identity matrix 单位矩阵
[m,n] = size(d);%返回矩阵b的尺寸信息,并存储在m,n中
if bwarea(d)/m/n >= 0.365 %计算二值图像中对象的总面积与整个面积相比是否大于0.365
d=imerode(d,se); %如果大于0.365则图像进行腐蚀
elseif bwarea(d)/m/n <= 0.235
d = imdilate(d,se); %如果小于则实现膨胀操作
end
imwrite(d,'expansion_or_corrosion_the_license_plate.jpg');
subplot(324),imshow(d),title('expansion or corrosion the license plate');
% 字符分割
% 寻找连续有文字的块,若长度大于某阈值,则认为该块有两个字符,需要分割
% 首先创建子函数qiege和getword,然后调用子程序,将车牌的字符分割并且进行归一化
d = qiege(d);
[m,n]=size(d);
subplot(325),imshow(d),title(n);
k1=1;k2=1;s=sum(d);j=1;
while j~=n
while s(j)==0
j=j+1;
end
k1=j;
while s(j)~=0 && j<=n-1
j=j+1;
end
k2=j-1;
if k2-k1>=round(n/6.5)
[val,num]=min(sum(d(:,[k1+5:k2-5])));
d(:,k1+num+5)=0; % 分割
end
end
% 再分割
d=qiege(d);
% 切割出7个字符
y1=10;y2=0.25;flag=0;word1[];
while flag==0
[m,n]=size(d);
left=1;wide=0;
while sum(d(:,wide+1))~=0
wide=wide+1;
end
if wide<y1 %认为是左侧干扰
d(:,[1:wide])=0;
d=qiege(d);
else
temp=qiege(imcrop(d,[1,1,wide,m]));
[m,n]=size(temp);
all=sum(sum(temp));
two_thirds=sum(sum(temp([round(m/3):2*round(m/3)],:)));
if two_thirds/all>y2
flag=1;word1=temp; % 第一个字符
end
d(:,[1:wide])=0;d=qiege(d);
end
end
[word2,d]=getword(d); % 分割第二个字符
[word3,d]=getword(d); % 分割第三个字符
[word4,d]=getword(d); % 分割第四个字符
[word5,d]=getword(d); % 分割第五个字符
[word6,d]=getword(d); % 分割第六个字符
[word7,d]=getword(d); % 分割第七个字符
figure(9);
subplot(271),imshow(word1),title('1');
subplot(272),imshow(word2),title('2');
subplot(273),imshow(word3),title('3');
subplot(274),imshow(word4),title('4');
subplot(275),imshow(word5),title('5');
subplot(276),imshow(word6),title('6');
subplot(277),imshow(word7),title('7');
[m,n]=size(word1);
% 归一化大小为40x20
word1=imresize(word1,[40,20]);
word2=imresize(word2,[40,20]);
word3=imresize(word3,[40,20]);
word4=imresize(word4,[40,20]);
word5=imresize(word5,[40,20]);
word6=imresize(word6,[40,20]);
word7=imresize(word7,[40,20]);
subplot(278),imshow(word1),title('1');
subplot(279),imshow(word2),title('2');
subplot(2,7,10),imshow(word3),title('3');
subplot(2,7,11),imshow(word4),title('4');
subplot(2,7,12),imshow(word5),title('5');
subplot(2,7,13),imshow(word6),title('6');
subplot(2,7,14),imshow(word7),title('7');
%% 车牌识别
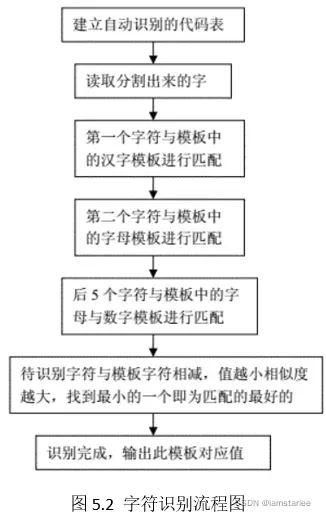
liccode=char(['0':'9', 'A':'Z', '苏豫陕鲁京辽浙']); %建立自动识别字符表
SubBw2=zeros(40,20);
l=1;
for I=1:7
ii=int2str(I);
t=imread([ii,'.jpg']);
SegBw2=imresize(t,[40,20],'nearest');
SegBw2=double(SegBw2)>20;
if I==1 % 第一个汉字识别
kmin=37;
kmax=43;
elseif I==2 %第二位A~Z字母识别
kmin=11;
kmax=36;
else l>=3 % 第三位以后是字母或数字识别
kmin=1;
kmax=36;
end
for k2=kmin:kmax
fname=strcat('字符模板\', liccode(k2), '.jpg');
SamBw2=imread(fname);
SamBw2=double(SamBw2)>1;
for i=1:40
for j=1:20
SubBw2(i,jP)=SegBw2(i,j)-SamBw2(i,j);
end
end
% 以上相当于两幅图相减得到第三幅图
Dmax=0;
for k1=1:40
for l1=1:20
if(SubBw2(k1,l1)>0 | SubBw2(k1,l1)<0)
Dmax=Dmax+1;
end
end
end
Error(k2)=Dmax;
end
Error1=Error(kmin:kmax);
MinError=min(Error1);
findc=find(Error1==MinError);
Code(l*2-1)=liccode(findc(1)+kmin-1);
Code(l*2)='';
l=l+1;
end
figure(10),imshwo(dw),title(['车牌号码', Code], 'Color', 'b');
五、 字符识别
模板匹配是图像识别方法中最具代表性的基本方法之一,它将从待识别的图像或者图像区域f(I, j)中提取的若干特征量与模板T(I, j)相应的特征量逐个进行比较,计算它们之间规格化的相互关联,其中互相关联 最大的一个就表示相似程度最高,可将图像归于此类,也可以计算图像与模板特征量之间的距离,用最小距离法判定所属类。
此处采用相减的方法来求得字符与模板中哪个字符最相似,然后找到相似度最大的输出。汽车牌照的字符一般有七个,大部分车牌第一位是汉字,代表车辆所属省份,紧接着其后的为字母和数字,车牌字符识别与一般文字识别的区别在于它的字符数有限,汉字共约50中,大写英文字母26个,数字10个。为了实验方便,结合本次设计所选汽车牌照的特点,只建立了7个数字、26个字母与10个数字的模板。其他模板设计的方法类似。
首先取字符模板,接着依次取待识别字符与模板进行匹配,将其与模板字符相减,得到的0越多那么就越匹配。把每一幅相减后的图的0值个数保存起来,即为识别出来的结果。

六、 优化
可以考虑使用HSV颜色空间系统,优化代码,添加图片亮度检测环节,判定图片情景的光照条件,依据光照强度的不同,匹配不同的颜色判断系统,进而优化定位判断;引入边缘检测环节,锁定检测的蓝色区域边界大致为长方形的判断为车牌区域以区分图像中的其他蓝色区域;形态学处理的时候进一步添加标准车牌的字符区与边框大小,边框比例,间隔大小,等参数,优化字符串区域提取环节;字符识别匹配环节中,可增加多套字符模板,添加不同角度的字符样板,多次匹配,提高识别正确率等。
参考:数字图像处理——基于matlab的车牌识别
参考:数字图像处理车牌识别课程设计
文章出处登录后可见!