写在前面
本文重点:
- 了解线程概念,理解线程与进程区别与联系。
- 学会线程控制,线程创建,线程终止,线程等待。
- 了解线程分离与线程安全。
- 学会线程同步。
- 学会使用互斥量,条件变量,posix 信号量,以及读写锁。
- 理解基于读写锁的读者写者问题。
一、线程概念
💦 什么是线程

基本上很多操作系统的书上对线程的解释是:线程是进程的一个执行分支,是在进程内部运行的一个执行流。而到具体一款操作系统,我们将从是什么、为什么、怎么办三个角度来解释线程。
我们先来谈线程是什么的问题?对于上图,我们当然很熟悉,现在就可以明确了,这里是一张用户级页表,内核页表就不画了,我们都知道可执行程序在磁盘中无非就是代码或数据,更准确点表述,代码也是一种数据,程序一运行,实际就会将其加载到物理内存,因为每个进程都有地址空间和页表,所以可以通过用户页表映射物理内存的方式,来找到磁盘或内存中的数据。
当然这个图已经不是重点了,如果想创建一个进程,那么这个进程也应有自己独立的 task_struct、mm_struct、用户页表。那如果今天创建 “ 进程 ”,不独立创建 mm_struct、用户页表,也不进行 I/O 将程序的代码和数据加载到内存,只创建 task_struct,然后让新的 PCB 指向和老的 PCB 指向同样的 mm_struct,然后把代码分成多份,然后通过当前进程的资源的合理的分配,让 CPU 执行不同 PCB 时访问的是不同的代码,都能使用进程的一部分资源 (这如何做到当然是后话了,无非就是在系统层面上这里一定可以做到把不同代码分配给不同执行流,只要划分用户级页表就就可以让不同的 PCB 看到页表的一部分,此时就只能看到进程资源的一部分了),站在资源的角度,地址空间其实是进程 pcb 的资源窗口,以前是只有一个窗户和一个人,现在是有多个窗户和多个人。此时每个 PCB 被 CPU 调度时,执行的粒度一定是要比原始进程执行的粒度要更小,此时我们称比进程执行粒度更小的为Linux线程,这是 Linux 线程的原理。至此,我们有诸多问题和矛盾如下:
-
什么叫做线程?如何理解线程是在进程的内部运行?什么叫做线程是进程的一个执行分支?那什么又是进程呢 ❓
在回答前三者问题之前,我们要先回答后者:站在数据结构角度,现在仅仅的 PCB 已经代表不了进程了,其中我们要明确进程就是 task_struct + mm_struct + 用户级页表 + 物理内存中映射的代码和数据;站在 OS 系统角度,进程是
承担分配系统资源的基本实体。在创建第 2 个,第 3 个线程时,对应的线程它们所需的资源早就申请好了,而这些资源是曾经进程就已经申请好的资源,这就是所谓承担,OS 在分配资源时,不是以一个独立线程去分配,而是先由进程分配资源,然后每个线程再向进程要资源。好比生活中,你可以向你爸妈要钱,当你不要时,这个钱也早就被你爸妈赚到了,而你爸妈赚的是社会的钱,社会就相当于整个 OS,而你爸妈构建的这一个家庭就是承担分配社会资源的基本实体,基本实体就像一套房不是一人一套,而是一个家庭一套,电视也不是一人一个,而是一个家庭一个。所以当明确了后者的概念后,前三者的问题就迎刃而解了,所以子女等是在家庭内部运行,所以线程是在进程的内部运行。所以子女等是家庭的基本单位,所以线程是 OS 调度的基本单位。所以子女等是一个家庭的执行分支,所以线程是进程的一个执行分支。也就是说一个进程被创建好后,后续内存可能存在多个执行流,即
多线程。此时站在数据结构角度还要再明确进程就是 task_struct + task_struct + task_struct + … … + mm_struct + 用户级页表 + 物理内存中映射的代码和数据。而其中内部的一个执行流只能称为线程。所以我们再以现在角度看以前在进程控制、基础 I/O、进程通信中都在谈的进程,其实都没有问题,只不过以前进程内部只有一个执行流罢了。
-
Linux 线程 VS 其它平台的线程
其中上面所谈的本质就是 Linux 线程的基本原理。站在 CPU 角度,对比历史的进程,当然没有区别,CPU 看到的还是一个一个的 PCB,只不过 CPU 执行时,“ 可能 ” 执行的 “ 进程流 ” 已经比历史的更加轻量化了!这当然很好理解,同一个效率的不同进程,前者只有 1 个执行流,而后者有 4 个执行流,且进行了合理的资源分配,所以当执行后者时,可能就会比前者更加轻量化 (注意 5 个 PCB 在 CPU 的等待队列中排队,CPU 在调度时都是按照 1 个 PCB 为单位正常调用,它不关心你前者和后者有几个 PCB)。再者,假设后者两个执行流要进行切换,上下文数据也少不了切换,但 mm_struct、用户页表、代码和数据完全不用管,这相对历史进程切换就显得更加轻量化了。
Linux 下其实是没有真正意义上的线程概念的!而是用进程来模拟的!换言之,我们 Linux 下的进程往往比其它平台上的进程更加轻量化,因为有可能它是只有一个线程的进程,有可能它是有多个线程的进程,所以我们把 Linux 下的进程称为
轻量级进程,所以从今天起,在 Linux 系统角度,我们不区分它是线程还是进程,而统一轻量级进程,所以从今天起,在 Linux 系统角度就不谈进程调度了,而统一轻量级进程调度或线程调度。Windows 具有真正意义上的线程概念!系统中一定存在着大量的进程,而进程:线程 = 1:n,所以系统也一定存在大量的线程,且不比进程少,OS 也一定要管理线程,怎么管理呢?先描述,在组织!所以支持真线程的系统一定要先描述线程
TCB(Thread Control Block),所以其内部一定是 PCB && TCB 共生,系统中已经存在了大量的 PCB,还要存在更大量的 TCB,然后 TCB 还要和 PCB 产生某些关系以证明该线程是该进程内的一个执行流,这样一来 OS 既要进程管理,又要线程管理,这样一定会使得该 OS 设计的很复杂,其中在描述 TCB 时一定也需要和 PCB 类似的各种属性。但实际我们发现线程同进程也是一种执行流,所以一定的是 PCB 和 TCB 在描述时会存在着大量重复的属性。所以可以看到 Windows 确实存在多线程,只不过代价很大,而 Linux 看到后,不管你是什么线程,你同样也是执行流,所以就把进程和线程统一了,所以 Linux Kernel 中没有线程 TCB 的概念。所以 Windows 在 OS 层面下一定提供了相关线程控制的接口,而 Linux 下虽然设计的更简单了,但它不可能在 OS 层面提供线程控制的相关系统调用接口,最多提供了轻量级进程相关的系统调用接口,如 vfork、clone,但我们不了解,实际在应用层 Linux 下有一套系统级别的原生线程库 pthread,原生线程库就是在应用层实现的库,这里需要慢慢体会。其实 C++、Python 等支持多线程的这些语言是有自己原生写好的线程的,且底层一定是用到下面要讲的 pthread。
-
小结
- 在一个程序里的一个执行路线就叫做线程 (thread)。更准确的定义是:线程是一个进程内部的控制序列。
- 一切进程至少有一个执行线程。
- 线程在进程内部运行,本质是在进程地址空间运行。
- 在 Linux 系统中,在 CPU 角度,看到的 PCB 都要比传统的进程更加轻量化。
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流。
💦 线程的优点
优点其实没啥说的, 只要理解前 3 个即可,后面的其实多进程也可以做到,只不过多线程更加轻量化,后面的用多了,也就理解了。
-
创建一个新线程的代价要比创建一个新进程小得多。
-
与进程之间的切换相比,线程之间切换,需要操作系统做的工作很少。
-
线程占用的资源要比进程少。
-
能充分利用多处理器的可并行数量。
-
在等待慢速 I/O 操作结束的同时,程序可执行其它的计算任务。
好比一个线程用来下载电影的同时,另一个线程用来播放电影,利用合理的分配,让线程快速切换,使用户得到更好的体验。
-
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现。
-
I/O 密集型应用,为了提高性能,将 I/O 操作重叠,线程可以同时等待不同的 I/O 操作。
💦 线程的缺点
因为所有 PCB 共享地址空间,理论上,每个线程都能访问进程的所有资源,所以这里还有一个好处是线程间通信的成本很低,同样缺点也很明显,其内部一定存在着临界资源,所以可能需要使用各种同步与互斥机制。当然线程不是越多越好,而是合适就好,如果线程增加的太多,可能 大部分时间 CPU 并不是在计算,而是进行线程切换。好比一家公司,每个人都各自清楚的做着事情,当公司人数过多了后,可能会导致公司效率变低。
-
性能缺失
一个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享同一个处理器,如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失是指增加了额外的同步与调度开销,而可用的资源不变。
-
健壮性降低
编写多线程需要更全面深入的考虑,在一个多线程程序中,因时间分配上的细微偏差或因共享了不该共享的变量而造成的不良影响可能性是很大的,也就是说线程是缺乏保护的。
-
缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些 OS 函数会对整个进程造成影响。
-
编程难度提高
编写调试一个多线程程序比单线程程序困难得多。
💦 线程异常
测试用例 2 演示。
- 单个线程如果出现除 0,野指针问题导致线程崩溃,进程也会随着崩溃。
- 线程是进程的执行分支,线程出现异常,就类似进程出现异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即终止。
💦 线程用途
- 合理的使用多线程,能提高 CPU 密集型程序的执行效率。
- 合理的使用多线程,能提高 IO 密集型程序的用户体验。
二、Linux进程VS线程
-
进程是资源分配的基本单位。
-
线程是调度的基本单位。
-
线程共享进程数据,但也拥有自己的一部分数据。
共享的进程数据包括代码区、字符常量区、全局初始化和未初始化数据、堆区、共享区、命令行参数和环境变量、内核区等等。而一部分数据是不共享的:
-
线程 id
即 LWP。
-
对应寄存器数据
CPU 调度是按 PCB 调度的,每个线程都有自己的上下文数据,所以必须保证每个线程的上下文数据是各自私有的,这也体现了线程是可以切换的。
-
栈
每个线程都有自己的栈结构,下面会说,这也体现了线程是独立运行的。
-
errno
-
信号屏蔽字
多线程中 block 表是私有的。
-
调度优先级
-
-
除此之外
同一个地址空间,Text Segment、Data Segment 等都是共享的,如果定义一个函数,那么在各个线程中都可以调用,如果定义一个全局变量,在各个线程中也都可以访问到,除此之外各线程还共享以下进程资源和环境:
-
文件描述符表。
注意在多进程中不共享文件描述符表,在管道我们说过两个进程可以指向同一个文件,其中并是说它们共享文件描述符表,而是它们表中的内容是一样的,而多线程是可以共享文件描述符表的。
-
每种信号的处理方式,或者自定义的信号处理函数。
handler 表是线程共享的。
-
当前工作目录。
-
用户 id 和 组 id。
-
-
进程和线程的关系图

三、 Linux线程控制
💦 POSIX 线程库
POSIX 和 System -V 都是用于系统级接口的 IPC(进程间通信) 标准,它们可以用于多进程和多线程之间的通信,POSIX 是可移植操作系统接口,由 IEEE 制定的一系列标准,旨在提高 OS 之间的互操作性,而 System 是 AT&T 公司开发的,它是 Unix 的一种版本。相比 System -V,POSIX 是一个比较新的标准,语法也相对简单,而 System -V 年代久远,不过也因此有许多系统支持,使用更加广泛。由于没有固定标准,所以不同 OS 之间存在一些差异,在不同通信方式中,两者都有利弊。好比,在信号量方面,POSIX 在无竞争条件下不会陷入内核,而 System -V 则是无论何时都要陷入内核,因此后者性能略差。在消息队列方面,POSIX 实现尚未完善,System -V 仍是主流。在多线程中,基本使用的是 POSIX,而在多进程中则是 System -V。
pthread 是 POSIX 线程库的一部分,它提供了一组 API,用于在多线程环境中创建和管理线程,是一种轻量级进程。pthread 库囊括的东西很多,最经典的是现在所谈的线程库和后面网络所谈的套接字。
- 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以 pthread_ 开头。
- 要使用这些函数库,需要包含 <pthread.h>。
- 编译链接时需要 -l 指定 pthread 库。
- 系统中是默认已经安装了 pthread 库。
💦 创建线程
#include<pthread.h>
int pthread_create(pthread_t* thread, const pthread_attr_t* attr, void*(*start_routine)(void*), void* arg);
compile and link with -pthread.
pthread_creat:
用于创建线程,它是一个回调函数,若线程创建成功,则会执行start_routine,编译和链接时需要引入pthread.
thread:
输出型参数,代表线程id.
attr:
线程属性,一般设置为nullptr.
start_routine:
想让线程执行的任务,它是一个返回值void*,参数void*的一个函数指针.
arg:
回调函数的参数,若线程创建成功,执行start_routine时,会把arg传入start_routine.
-
测试用例 1:
makefile:
mythread:mythread.cc g++ $^ -o $@ -std=c++11 -lpthread .PHONY:clean clean: rm -f mythreadmythread.cc:
#include <iostream> #include <unistd.h> #include <pthread.h> using namespace std; void* thread_run(void* args) { while(true) { cout << (char*)args << endl; sleep(2); } return nullptr; } int main() { //新线程 pthread_t tid; pthread_create(&tid, nullptr, thread_run, (void*)"thread 1"); //主线程 while(true) { cout << "main thread is running..." << endl; sleep(1); } return 0; }
-
注意在编译时需要 -l 在默认路径下指定 pthread 动态库,否则在编译时会报错,在指定 pthread 库后,ldd 就可以看到成功了。
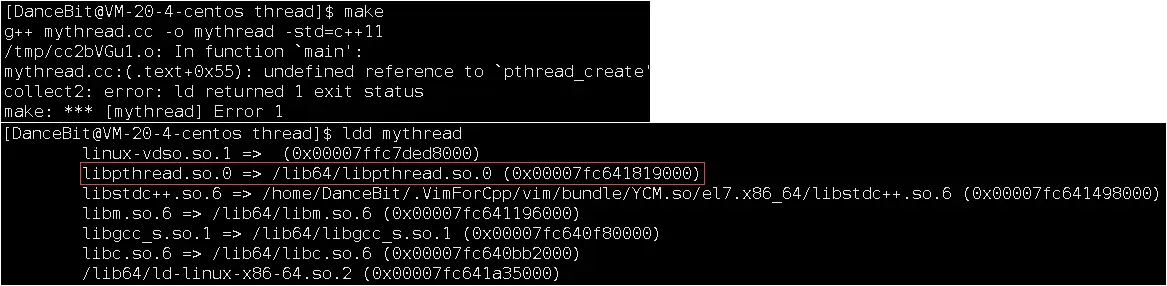
-
可以看到主线程每 1 秒执行 while 循环,新线程每 2 秒执行回调函数 (其实严格来说新线程是指主线程调用 pthread_create 时,pthread_create 再去调用 start_routine 的情况)。我们以前是
ps ajx来查看一个进程的相关信息,而现在可以ps -aL查看轻量级进程,我们发现后者的 PID 是相同的,这就说明两个 mythread 本质是属于一个进程,而每一个线程也需要唯一标识,所以LWP用来标识线程的唯一性,PID标识进程唯一性。这里还可以看到的是第一组 PID 和 LWP 的值是相同的,如果进程内部是单执行流时,此时 ps ajx 和 ps -aL 查看时 PID 和 LWP 的值是一样的,所以在多线程之前 PID 和 LWP 的意义是一样的,至此现在统一了,调度进程 CPU 看的是 LWP。那么也说明了如果 PID 和 LWP 两个值是相同的,则对应的 LWP 对应的 ID 就是主线程。最后当我们杀死新线程时,也会影响主线程,说明它们是共生的。
-
-
测试用例 2:
这里让新线程执行野指针操作,我们发现它会影响整个进程。线程是进程的一个执行分支,野指针等异常操作导致线程退出的同时,也意味着进程触发了该错误,进而导致进程退出。这也就是线程会使用代码健壮性降低的一个表现。
#include <iostream> #include <unistd.h> #include <pthread.h> using namespace std; void* thread_run(void* args) { while(true) { cout << (char*)args << endl; sleep(2); //野指针 int* p; *p = 100; } return nullptr; } int main() { pthread_t tid; pthread_create(&tid, nullptr, thread_run, (void*)"thread 1"); while(true) { cout << "main thread is running..." << endl; sleep(1); } return 0; }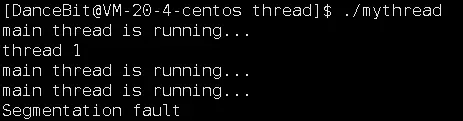
-
测试用例 3:
注意 <cstdio> 是 C++ 中的一个标准库,其中也提供了一些 C 语言中的函数,一般是 C/C++ 混编的时候使用,当然一般也可以不用,因为 C++ 兼容 C。上面说 thread 是输出型参数,代表线程 id,可是我们发现 thread 的 id 和 LWP 表示的 id 很不一样。其实 LWP 是 OS 在底层管理轻量级进程时所使用的,而 thread 是在应用层上 pthread 库中所使用的。当我们再以 %p 格式输出时发现 tid 中的内容是一些地址,一会再说。
#include <iostream> #include <cstdio> #include <unistd.h> #include <pthread.h> using namespace std; void* thread_run(void* args) { while(true) { cout << (char*)args << endl; sleep(2); } return nullptr; } int main() { //新线程 pthread_t tid0; pthread_t tid1; pthread_t tid2; pthread_t tid3; pthread_creat(&tid0, nullptr, thread_run, (void*)"thread 1"); pthread_creat(&tid1, nullptr, thread_run, (void*)"thread 1"); pthread_creat(&tid2, nullptr, thread_run, (void*)"thread 1"); pthread_creat(&tid3, nullptr, thread_run, (void*)"thread 1"); //主线程 cout << "########################" << endl; //C++格式控制相对麻烦,所以使用C,再包含<cstdio.h> printf("%p\n", tid0); printf("%p\n", tid1); printf("%p\n", tid2); printf("%p\n", tid3); cout << tid0 << endl; cout << tid1 << endl; cout << tid2 << endl; cout << tid3 << endl; cout << "########################" << endl; while(true) { cout << "main thread is running..." << endl; sleep(1); } return 0; }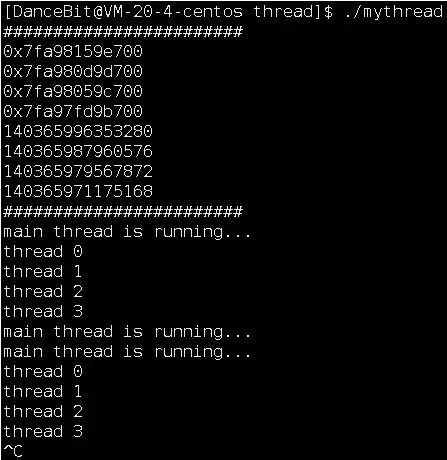
💦 线程ID及进程地址空间布局和原生线程库的理解
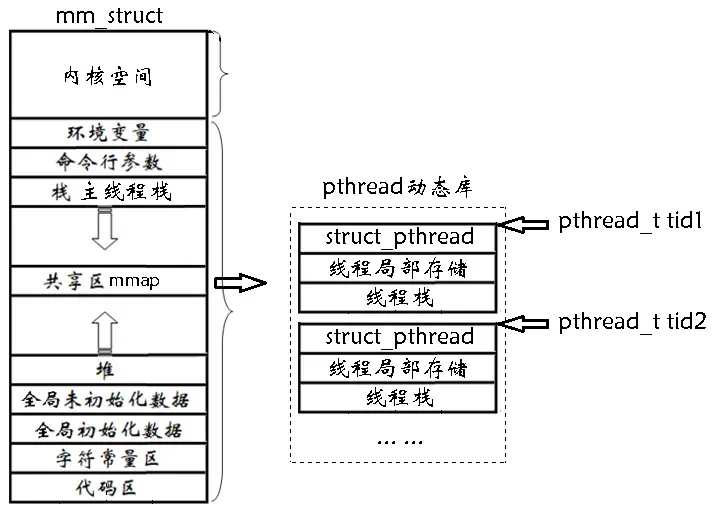
至此我们需要明确:
-
Linux OS 没有真正意义上的线程,而是用进程 PCB 模拟的,这样就称之为轻量级进程,其本身没有提供类似线程创建、终止、等待、分离等相关 System Call 接口,但是会提供轻量级进程的接口,如 clone,因为它比较复杂,所以我们暂时不了解它,所以为了更好的适配,系统基于轻量级进程的接口,模拟封装了一个用户层的原生线程库 pthread。这样,系统通过 PCB 来进行管理,用户层也得知道线程 ID、状态、优先级等等其它属性用来进行用户级线程管理。
-
pthread_create 函数会产生一个线程 ID,存放在第一个参数指向的地址中,该线程 ID 和前面说的线程 ID LWP 不是一回事。前面讲的线程 ID 属于进程调度的范畴,因为线程是轻量级进程,是 OS 调度器的最小单位,所以需要一个数值来唯一表示该线程。pthread_create 函数的第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线程 ID,属于
NPTL线程库的范畴,线程库的后续操作,就是根据该线程 ID 来操作线程。 -
原生线程库是一个库,它在磁盘上就是一个
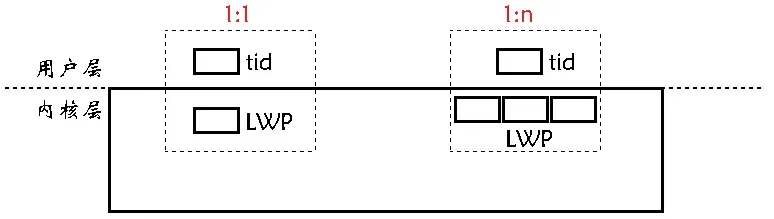
libpthread.so文件,运行时加载到内存,然后将这个库映射到共享区,此时这个库就可以被所有线程执行流看到了。此时有两个 ID 概念,一个是在命令行上看到的 LWP,一个是在用户层上看到的 tid。前者是在系统层面上供 OS 调度的,后者是 pthread_create 获得的线程 ID,它是一个用户层概念,本质是一个地址,就是 pthread 库中某一个起始位置,也就是对应到共享区中的某一个位置。所以线程数据的维护全都是在 pthread 线程库中去维护的,上图所示,其中会包含每个线程的局部数据,struct pthread 就是描述线程的 TCB,线程局部存储可以理解是不会在线程栈上保存的数据,我们在上面说过线程会产生各种各样的中间数据,如上下文数据,此时就需要独立的栈去保存,它就是线程栈。而下图中拿到的 tid 就是线程在共享区中线程库内的相关属性的起始地址,所以只要拿到了用户层的 tid,就可以在库中找到线程相关的属性数据,很明显 tid 和 LWP 是 1:1 的,而主线程不使用库中的栈结构,直接使用地址空间中的栈区,称为主线程线。
实际上在很多 OS 在设计线程时都是用户级线程,用户级线程就是把相关的属性数据放在用户层,真正的调度还是得由一个相关的执行流来处理的,这叫做 1:1,这是 Linux 所采用的。当然在用户层只有一个执行流,但 OS 为了完成你的这个任务,可能会在内核层创建多个执行流去做的,这就叫 1:n。用户级线程是怎么和内核级线程关联的呢,可以简单的理解成用户级线程只要把代码交给内核级线程代码就可以跑了,创建用户级线程就是创建 LWP,退出用户级线程就是退出 LWP,再把库中的相关数据关掉,只要在用户层的操作可以和内核层对应起来就行了,就像白帮中一名警察派了一个卧底潜伏于黑帮,然后警察指派任务给卧底,警察是可以控制卧底的,警察就是用户级线程,卧底就是内核级线程,它们的关系是 1:1 的,内核级进程是与系统是强相关的,如果让用户直接去用它倒也可以,不过用户就要去了解它,成本较高,所以就需要存在用户级进程,让用户更好的使用,同时警察可以站在他的角度向老百姓解释的很清楚,而卧底站在他的角度就解释不清楚。所以 Linux 中要有原生线程库的原因是 Linux 本身没有提供真正意义上的线程,自然也就没有真正意义上的线程控制接口,只能是轻量级进程来模拟,而用户要操作轻量级进程,就得向用户解释更多东西,不是所有人都能理解这种现象的,而用户作为一个东西被偷的人,只需要你把东西找回来就行了,也就是用户仅仅需要知道怎么操作线程就行了。所以需要存在一个用户级线程库才供用户使用,就如同这个世界不是只有老百姓和恶人,而需要有一个警察的角色。
💦 线程终止
#include<pthread.h>
void pthread_exit(void* retval);
compile and link with -pthread.
retval:
用于传递线程的退出状态,在主线程中,pthread_join()可以等待新线程结束,并将新线程的退出状态存储在tret指针.
#include<pthread.h>
pthread_t pthread_self(void);
compile and link with -pthread.
This function always succeeds,returning the calling thread's ID.
pthread_self:
谁调的,就获取谁的线程ID.
#include<pthread.h>
int pthread_cancel(pthread_t thread);
compile and link with -pthread.
pthread_cancel:
取消指定thread线程.
-
测试用例 4:
#include <iostream> #include <cstdio> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 5 void* ThreadRoutine(void* args) { int i = *(int*)args; delete (int*)args; int cnt = 0; while(cnt < 5) { cout << "thread index: " << i << " count: " << cnt << endl; sleep(1); cnt++; } cout << "thread: " << i << " quit" << endl; //return nullptr; //exit(0); pthread_exit((void*)10); } int main() { pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { int* p = new int(i); pthread_creat(tids + i, nullptr, ThreadRoutine, p); } while(true) { cout << "main thread is running..." << endl; sleep(1); } return 0; }-
return 终止线程

-
pthread_exit 终止线程

-
测试用例 4.1
pthread_cancel 取消线程 (同终止)。
一般是主线程去终止新线程。
#include <iostream> #include <cstdio> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 2 void* ThreadRoutine(void* args) { int i = *(int*)args; delete (int*)args; while(true) { cout << "thread index: " << i << " thread id: " << pthread_self() << endl; sleep(1); } //exit(0); //pthread_exit((void*)10); return nullptr; } int main() { pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { int* p = new int(i); pthread_create(tids + i, nullptr, ThreadRoutine, p); cout << "create thread: " << tids[i] << " success" << endl; } sleep(5); for(auto i = 0; i < NUM; i++) { pthread_cancel(tids[i]); cout << "thread: " << tids[i] << " already cancel!" << endl; sleep(1); } while(true) { cout << "main thread is running... main thread id: " << pthread_self() << endl; sleep(1); } return 0; }
-
exit 终止线程
exit 是用来终止进程的,不能用于终止线程。对于终止线程最常用且最推荐的就是两种方式是 return 和 pthread_exit。

-
测试用例 4.2
注意,通常 pthread_cancel 是用于主线程去对新线程终止。
#include <iostream> #include <cstdio> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 2 pthread_t main_thread; void* ThreadRoutine(void* args) { int i = *(int*)args; delete (int*)args; while(true) { cout << "thread index: " << i << " thread id: " << pthread_self() << endl; sleep(1); pthread_cancel(main_thread);//新线程取消主线程 //pthread_cancel(pthread_self());//新线程取消自己 } //exit(0); //pthread_exit((void*)10); //return nullptr; } int main() { pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { int* p = new int(i); pthread_create(tids + i, nullptr, ThreadRoutine, p); cout << "create thread: " << tids[i] << " success" << endl; } main_thread = pthread_self(); while(true) { cout << "main thread is running... main thread id: " << pthread_self() << endl; sleep(1); } return 0; }新线程取消主线程,发现主线程变成僵局进程了,且一直都在,因为这个进程没死透:

新线程自己取消自己,发现程序卡住了,这是因为线程在退出之前资源没有被释放,所以为避免这种情况,可以在新线程中添加适当的清理逻辑,以确保线程能够正常退出并释放资源,但其实要自己取消自己的话,建议使用 return 或者 pthread_exit:

-
💦 线程等待
#include<pthread.h>
int pthread_join(pthread_t thread, void** retval);
compile and link with -pthread.
thread:
等待的目标线程.
retval:
输出型参数,可以得到线程退出时的退出码.
同进程,一般线程终止后,必须进行等待,由 main thread 进行等待。因为要防止内存泄漏,资源浪费 (通过线程等待,将曾经线程向进程在地址空间中申请的资源释放,在线程这里一般是说如果不释放相关线程,那么申请新线程时不会复用未释放的线程)。保证主线程最后退出,让新线程正常结束。获得新线程的退出码信息 (而 pthread_create 时调用 start_routine 新线程传入的参数是 void*,且返回的类型是 void*,这样它就是一个通用接口,也意味着新线程可以返回任意类型的数据,此时 pthread_join 时,就会被 retval 拿到)。实际在底层就是 pthread_create 调用 start_routine 后,start_routine 将线程退出码写到对应 PCB 中,然后调用 pthread_join 时就可以从对应 PCB 中读取退出结果到 retval。
我们都知道不可能通过 fun 函数来把 10 拿出去的原因是因为它是值传递,而应该地址传递。同样如果想在一个函数内部返回一个 void* 的值也很简单了。pthread_create 中 start_routine 参数和返回值类型是 void* 我们知道了它是要支持通用接口,而 pthread_join 中 retval 的类型是 void**,然后 pthread_join 会通过你传入的线程 id,去读取对应的 PCB 中的退出码信息,因为退出码信息可能是不同类型的地址,所以要用 void** 来接收,retval 是输出型参数,然后又由它返回 void* 到用户层。

-
测试用例 5
使用随机数种子生成随机数作为新线程所执行的次数,然后主线程在阻塞等待。
#include <iostream> #include <ctime> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 5 void* ThreadRoutine(void* args) { int cnt = rand() % 5 + 5; while(cnt) { cout << "thread: " << pthread_self() << " | count: " << cnt << " | is running." << endl; cnt--; sleep(1); } return nullptr; } int main() { srand((unsigned long)time(nullptr)); pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { pthread_creadte(&tids[i], nullptr, ThreadRoutine, nullptr); cout << "create thread: " << tids[i] << " success." << endl; } cout << "main thread join begin ...!" << endl; for(auto i = 0; i < NUM; i++) { pthread_join(tids[i], nullptr); cout << "thread: " << tids[i] << " | quit... join success." << endl; } cout << "main thread join end ...!" << endl; return 0; }
-
测试用例 6
获取新线程的退出码,不局限于整型,还演示了新线程返回结构体指针类型且被主线程等待获取然后使用其内部变量。
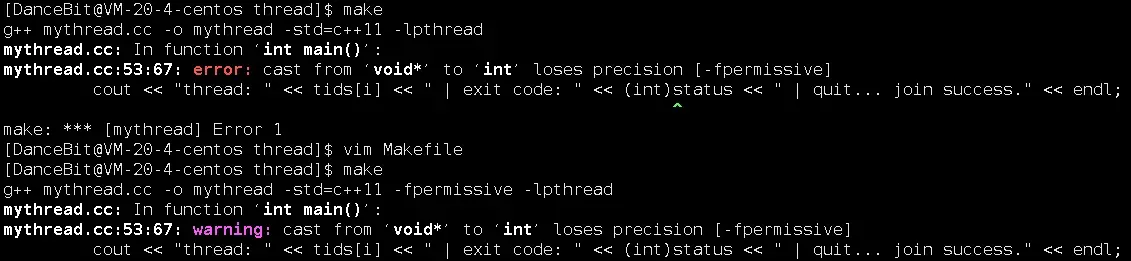
#include <iostream> #include <string> #include <ctime> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 5 struct exit_status { int code; string desc; }; void* ThreadRoutine(void* args) { int cnt = rand() % 5 + 5; while(cnt) { cout << "thread: " << pthread_self() << " | count: " << cnt << " | is running." << endl; cnt--; sleep(1); } //return (void*)10; exit_status* p = new exit_status(); p->code = 10; p->desc = "thread quit normal."; return p; } int main() { srand((unsigned long)time(nullptr)); pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { pthread_create(&tids[i], nullptr, ThreadRoutine, nullptr); cout << "create thread: " << tids[i] << " success." << endl; } cout << "main thread join begin ...!" << endl; void* status = nullptr; for(auto i = 0; i < NUM; i++) { pthread_join(tids[i], &status); //cout << "thread: " << tids[i] << " | exit code: " << (int)status << " | quit... join success." << endl;//error:void* to int loses precision.需要编译时[-fpermissive]. exit_status* p = (exit_status*)status;//否则即((exit_status*)status)->code cout << "thread: " << tids[i] << " | exit code: " << p->code << " | exit string: " << p->desc << " | quit... join success." << endl; } cout << "main thread join end ...!" << endl; return 0; }在输出 status 时会报丢失精度的错误,使用 -fpermissive 后就由 error 到 warning 了。
-
测试用例 6.1
整型:

-
测试用例 6.2
结构体:

-
-
测试用例 7
线程异常退出呢。我们知道进程退出时是包含了退出码和退出信号,且有三类情况:a) 代码跑完,结果正确 b) 代码跑完,结果不正确 c) 代码没有跑完,程序崩溃。其中 a 和 b 是属于退出码,c 是属于信号。但是在线程这里,主线程 pthread_join 时并不需要考虑 c 线程崩溃的情况,因为进程中一旦线程崩溃,那么整个进程也随之崩溃,此时不单单只是线程的问题,而是进程的问题,此时 pthread_join 将毫无意义,此时进程的退出信息就会由它的父进程 bash 处理,然后由 OS 发送信息终止进程,所以对于线程只考虑它的 a 和 b 退出码。
void* ThreadRoutine(void* args) { int cnt = rand() % 5 + 5; while(cnt) { cout << "thread: " << pthread_self() << " | count: " << cnt << " | is running." << endl; cnt--; sleep(1); if(4 == cnt) { int a = 0; a /= a; } } return (void*)10; }
-
测试用例 8
三种退出线程方式的退出码。可以看到 return 和 pthread_exit 是一样的,而 pthread_cancel 的退出码是 -1。
#include <iostream> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 5 void* ThreadRoutine(void* args) { int cnt = rand() % 5 + 5; while(cnt) { cout << "thread: " << pthread_self() << " | count: " << cnt << " | is running." << endl; cnt--; sleep(1); } return (void*)11;//1 //pthread_exit((void*)11);//2 } int main() { srand((unsigned long)time(nullptr)); pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { pthread_create(&tids[i], nullptr, ThreadRoutine, nullptr); } sleep(1);//3 为让新线程完全跑起来 for(auto i = 2; i < NUM; i++) { pthread_cancel(tids[i]); cout << "cancel " << tids[i] << " success." << endl; } cout << "main thread join begin..." << endl; void* status = nullptr; for(auto i = 0; i < NUM; i++) { pthread_join(tids[i], &status); cout << "thread: " << tids[i] << " | exit code: " << (int)status << " | quit... join success." << endl; } cout << "main thread join end..." << endl; return 0; }-
测试用例 8.1
return 和 pthread_exit:

-
测试用例 8.2
pthread_cancel:

-
注意这里要让新线程完全跑起来再 pthread_cancel,不然有可能会出现新线程被创建了,但是还没有被调度,就被 pthread_cancel,此时就出现了一些时序的问题 (去掉 sleep 后即可验证),这块在设计上确实是有点小问题的。

-
-
测试用例 9
线程自己取消自己,若 pthread_cancel 后没有休眠,返回的是 11,若休眠,返回的是 -1。这里说明了 pthread_cancel 是有一定延时性的,并不是被立即受理的,所以建议 pthread_cancel 在线程执行中取消最好,且由 mian thread 来取消 other thread。
#include <iostrream> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 5 void* ThreadRoutine(void* args) { int cnt = rand() % 5 + 5; while(cnt) { cout << "thread: " << pthread_self() << " | count: " << cnt << " | is running." << endl; cnt--; sleep(1); } pthread_cancel(pthread_self()); sleep(3); return (void*)11; } int main() { srand((unsigned long)time(nullptr)); pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { pthread_create(&tids[i], nullptr, ThreadRoutine, nullptr); } cout << "main thread join begin..." << endl; void* status = nullptr; for(auto i = 0; i < NUM; i++) { cout << "thread: " << tids[i] << " | exit code: " << (int)status << " | quit... join success." << endl; } cout << "main thread join end..." << endl; return 0; }-
测试用例 9.1
不休眠:

-
测试用例 9.2
休眠:

-
实际上线程被 pthread_cancel 后,线程退出码会被设置为 PTHREAD_CANCELED,也就是 -1,它是一个宏。

-
💦 分离线程
#include<pthread.h>
int pthread_detach(pthread_t thread);
compile and link with -pthread.
pthread_detach:
用于创建线程,它是一个回调函数,若线程创建成功,则会执行start_routine,编译和链接时需要引入pthread.
thread:
输出型参数,代表线程id.
- 默认情况下,新创建的线程是 joinable 的,线程退出后,需要对其进行 pthread_join 操作,否则无法释放资源,从而造成内存泄漏。
- 如果不关心线程的返回值,join 则是一种负担,这个时候,可以使用分离,此时就告诉系统,当线程退出时,自动释放线程资源,这就是线程分离的本质。
- joinable 和 pthread_detach 是冲突的,也就是说默认情况下,新创建的线程是不用 pthread_detach。
- 就算线程被分离了,也还是会和其它线程影响的,因为它们共享同一块地址空间。
-
测试用例 10
注意没有线程替换这种操作,但是可以在线程中执行进程替换系列函数,这里可以看到新线程内替换后,新线程中的部分代码没有执行,且主线程的大部分代码压根就没有执行。我们当然知道这是因为新线程内部执行进程替换函数,这看起来像是把新线程中的代码替换了,但实际会把主线程中的代码也替换了,因为主线程和新线程共享地址空间,所以新线程内部进程替换后,所有的线程包括主线程都会被影响。所以轻易不要在多线程中执行进程替换函数。
#include <iostream> #include <unistd.h> #include <pthread.h> using namespace std; #define NUM 1 void* ThreadRoutine(void* args) { cout << "new thread is running execl begin..." << endl; execl("/bin/ls", "ls", "-a", "-l", nullptr); cout << "new thread is running execl end..." << endl; } int main() { srand((unsigned long)time(nullptr)); pthread_t tids[NUM]; for(auto i = 0; i < NUM; i++) { pthread_create(&tids[i], nullptr, ThreadRoutine, nullptr); } sleep(3); cout << "main thread join begin..." << endl; void* status = nullptr; for(auto i = 0; i < NUM; i++) { pthread_join(tids[i], &status); cout << "thread: " << tids[i] << " | exit code: " << (int)status << " | quit... join success." << endl; } cout << "main thread join end..." << endl; return 0; }
-
测试用例 11
这里主线程中加上 sleep,那么主线程是 pthread_join 分离后的新线程。看到现象,主线程休眠一秒后,开始等待,同时新线程刚执行一次循环后也退出了,pthread_join 返回的是 22,说明等待失败了,然后返回,进程终止。其实一个线程被设置为分离状态,则该线程不应该被等待,如果被等待了,结果是未定义的,至少一定会等待出错。当然还可以主线程把新线程分离,此时再 pthread_join 时,新线程一定是分离的,所以这是一种更稳妥的做法,也不需要加 sleep 了。而这两种方案,都不应该再 pthread_join 了,因为新线程被设置分离后,其资源将会自动被回收。
#include <iostream> #include <unistd.h> using namespace std; void* ThreadRoutine(void* args) { //pthread_detach(pthread_self()); int cnt = 5; while(cnt) { cout << "thread: " << pthread_self() << " cnt: " << cnt-- << endl; sleep(1); } return (void*)10; } int main() { pthread_t tid; pthread_create(&tid, nullptr, ThreadRoutine, nullptr); //sleep(1); pthread_detach(tid); int ret = pthread_join(tid, nullptr); cout << "main thread ret: " << ret << endl; return 0; }-
测试用例 11.1
新线程内分离:

-
测试用例 11.2
主线程内分离:

-
测试用例 11.3
主线程内分离新线程,新线程中野指针,主线程内休眠 3 秒钟是为了能在退出前让新线程执行野指针。看到现象,就算新线程被分离了,但是如果该线程出错崩溃,也是会影响主线程的。
void* ThreadRoutine(void* args) { int cnt = 5; while(cnt) { cout << "thread: " << pthread_self() << " cnt: " << cnt-- << endl; sleep(1); if(cnt == 3) { int* p; *p = 100; } } return (void*)10; } int main() { pthread_t tid; pthread_create(&tid, nullptr, ThreadRoutine, nullptr); sleep(3); pthread_detach(tid); int ret = pthread_join(tid, nullptr); cout << "main thread ret: " << ret << endl; return 0; }
-
五、线程互斥
-
测试用例 12
模拟抢票逻辑,当多线程对全局变量进行 – – 操作时,一定不是原子或安全的,因为 tickets 是临界资源,表面上 tickets – – 只是一条语句,实际转换为汇编语言时执行时至少有三条语句:a) tickets 从内存读到 CPU 的相关寄存器 b) CPU 对 ticket – – c) 再把 tickets 写回内存。或者也可以说 if 判断条件为真后,代码可能并发切换到其它线程,因为 usleep 漫长的等待过程中,可能会有多个线程进入该临界区,所以 tickets – – 就不是原子的。实际多线程在切换时,极有可能出现因为数据交叉操作,而导致数据不一致的问题,而 OS 中可能从内核态返回用户态的时候就会进行线程间切换。
取出 ticket – – 部分的汇编代码,- – 操作并不是原子的,而是对应三条汇编指令:
- load,将共享变量 ticket 从内存加载到寄存器中。
- update,更新寄存器里面的值,执行 – – 操作。
- store,将新值从寄存器写回共享变量 ticket 的内存地址。

#include <iostream> #include <pthread.h> #include <unistd.h> #include <cstdio> using namespace std; #define NUM 5 int tickets = 2000; void* ThreadRoutine(void* args) { while(1) { if(tickets > 0) { //printf("%p: get a ticket: %d\n", pthread_self(), tickets--); //usleep(30000);//毫秒,也就是0.03秒 usleep(30000); printf("%p: get a ticket: %d\n", pthread_self(), tickets); tickets--; } else { break; } } printf("%p: quit, tickets: %d\n", pthread_self(), tickets); return nullptr; } int main() { pthread_t tids[5]; for(int i = 0; i < NUM; i++) { pthread_create(tids + i, nullptr, ThreadRoutine, nullptr); } for(int i = 0; i < NUM; i++) { pthread_join(tids[i], nullptr); } return 0; }如下图,线程 A 将 tickets: 1000 从内存读到 CPU;然后 ticket – -;因为某种原因,还没等线程 A 把 tickets 写回内存,就被 CPU 剥离,在剥离之前 CPU 上一定有线程 A 的临时数据或者说是上下文数据,然后将上下文数据保存在线程内部;紧接着 CPU 开始调度线程 B,线程 B 将 tickets: 1000 从内存读到 CPU;因为线程 B 的运气比较好,所以 tickets – – 了 500 次;然后因为时间片到了,就把 tickets: 500 写回内存;然后 CPU 继续调度线程 A,此时将线程 A 中保存的上下文数据恢复到 CPU 对应的寄存器中;再继续执行第 3 步,把 tickets: 999 写回物理内存。

-
测试用例 12.1
未出现原子性问题:


-
测试用例 12.2
出现原子性问题:
当第 1 个线程 if 判断成功后,执行到 usleep,陷入内核休眠并执行第 2 个线程,以此类推。后来第 1 个线程醒来后,输出并 – -,以此类推。这样就有可能出现多个线程都在 if 判断中,这样就有可能会出现减到负数的情况。要解决这种问题,所以就引出了线程互斥。


💦 互斥量 mutex 和互斥量接口
要解决以上的问题需要做到:
- 代码必须要有互斥行为,当代码进入临界区执行时,不允许其它线程进入该临界区。
- 如果多个线程同时要求执行临界区的代码,并且临界区没有线程执行,那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行,那么该线程不能阻止其它线程进入临界区。
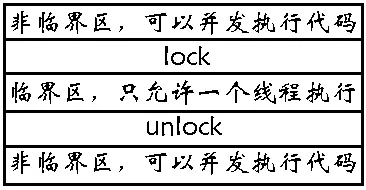
而要做到这三点,就需要一把锁,Linux 上提供的这把锁叫做互斥量。
#include<pthread.h>
int pthread_mutex_init(pthread_mutex_t* restrict mutex, const pthread_mutexattr_t* restrict attr);
int pthread_mutex_destroy(pthread_mutex_t* mutex);
int pthread_mutex_lock(pthread_mutex_t* mutex);
int pthread_mutex_trylock(pthread_mutex_t* mutex);
int pthread_mutex_unlock(pthread_mutex_t* mutex);
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
mutex:
初始化或释放的锁.
attr:
锁的属性,设置nullptr,即不管.
notice:
一般lock初始化有两种方案,其一,在全局定义时直接使用PTHREAD_MUTEX_INITIALIZER宏初始化;其二,使用pthread_mutex_init初始化,对于前者初始化不用destroy.
-
测试用例 13
这里就完成了线程互斥的操作。线程是绝对可以随时被切换的,但是线程是 “ 拿着锁 ” 走的,线程不回来,锁没法释放,期间任何线程不在的时候,当然也可以申请锁,只不过不会成功。对其它拥有锁的线程,执行临界区的时候,要么不执行(没有申请锁),要么执行完毕(释放锁),这就间接完成了原子性。此外定义的全局 lock,一定需要被所有线程先看到,所以本质 lock 也是一种临界资源,难道再加一层锁吗?那谁又来保护它呢?所以只需要保证 lock,unlock 时是原子的即可,也就是说在这过程中只会有一个线程对 lock 变量进行操作。
#include <iostream> #include <pthread.h> #include <unistd.h> #include <cstdio> using namespace std; #define NUM 5 //定义全局锁 pthread_mutex_t lock; int tickets = 200; void* ThreadRoutine(void* args) { while(true) { //加锁--只允许一个线程执行 pthread_mutex_lock(&lock); if(tickets > 0) { usleep(30000); printf("%p: get a ticket: %d\n", pthread_self(), tickets); tickets--; //解锁 pthread_mutex_unlock(&lock); } else { //解锁 pthread_mutex_unlock(&lock); break; } } printf("%p: quit, tickets: %d\n", pthread_self(), tickets); return nullptr; } int main() { //初始化锁 pthread_mutex_init(&lock, nullptr); pthread_t tids[5]; for(int i = 0; i < NUM; i++) { pthread_create(tids + i, nullptr, ThreadRoutine, nullptr); } for(int i = 0; i < NUM; i++) { pthread_join(tids[i], nullptr); } //释放锁 pthread_mutex_destroy(&lock); return 0; }-
测试用例 13.1
关闭加解锁,出现了原子性问题:

-
测试用例 13.2
打开加解锁,运行速度明显变慢了,且因为互斥,没有出现原子性问题:

-
测试用例 13.3
注意,这样是有问题的,因为一个线程已经锁定互斥量,其它线程申请互斥量,但没有竞争到互斥量,那么 pthread_lock 调用时会陷入阻塞,看到的现象就是执行流被挂起,等待直到互斥量解锁。也就是说这里当一个线程执行到 tickets == 0 时,会走到 else,break 出循环,此时加锁却没有解锁,现在会一直处于阻塞状态,其它线程都在等待。


-
💦 互斥量原理
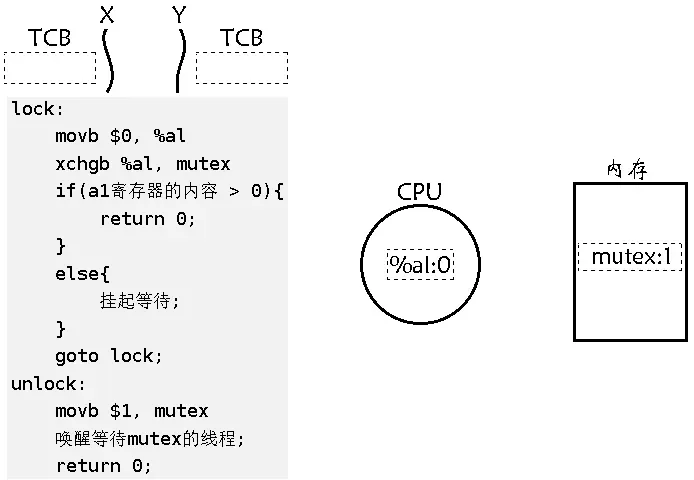
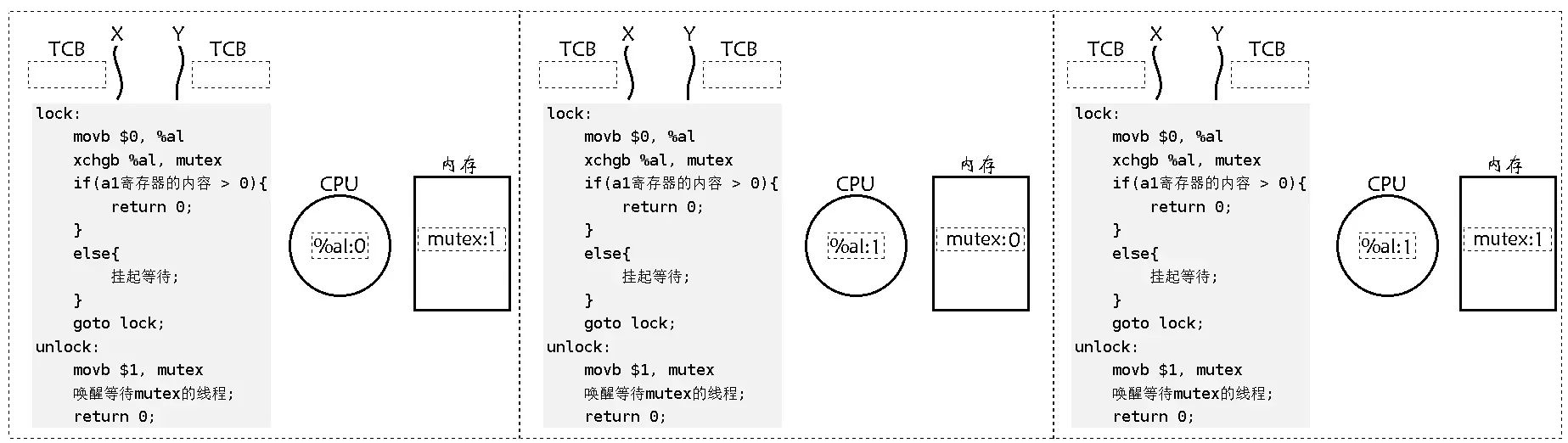
经过上面的例子,大家想必已经意识到了单纯的 i++ 或者 ++i 都不是原子的,有可能会出现数据不一致问题。为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,就保证了原子性,即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时,另一个处理器的交换指令只能等待总线周期。也就是说锁的原子性实现是由寄存器级别的,如下是 lock 和 unlock 的伪代码以及理解:
lock:
movb $0, %al
xchgb %al, mutex
if(a1寄存器的内容 > 0){
return 0;
}
else{
挂起等待;
}
goto lock;
unlock:
movb $1, mutex
唤醒等待mutex的线程;
return 0;
-
mutex 就是一个内存中的变量,和定义 int 没太大区别,假设 mutex 默认是 1。
-
线程 X 执行 movb $0, %al 将 %al 寄存器清零。在这个过程中线程 Y 当然也有可能执行这条语句,这没问题,因为线程在剥离时会作上下文数据的保存,线程在切换时就会把上下文数据保存于 TCB 中。
-
线程 X 执行 xchgb %al, mutex 将寄存器 %al 中的值 0 和内存的值 mutex:1 交换,这意味着 mutex 里面的值被交换到了对应线程中的上下文中,就相当于变成线程私有的。是的,在汇编代码上只要一条语句就完成交换了,因为它只是一条语句,所以交换过程一定是原子的。具体 xchgb 是怎么完成的,可以去了解了解它的汇编原理,简单提一下就是在体系结构上有一个时序的概念,在一个指定周期中,去访问总线时,汇编指令能被 CPU 接收到,是因为汇编指令会在特定的时间放在总线上的,而总线是可以被锁住的,这在硬件上实现比较简单,所以即使 xchgb 汇编翻译成二进制的时候,是对应多条语句的,但是它依旧不影响,因为硬件级别把总线锁住了,所以它虽然在汇编翻译成二进制时依旧是有多条语句的,但是因为总线被锁住了,所以不会出现原子性问题。

-
当线程 X 交换完后,线程 Y 突然切换进来了,在此之前就会把线程 X 的上下文数据保存于线程 X 的 TCB 中,然后把线程 Y 中上一次在 TCB 中保存的上下文数据恢复到 CPU (当然,这里没有),然后线程 Y 执行 movb $0, %al 将 %al 寄存器清零,执行 xchgb %al, mutex 将寄存器 %al 中的值 0 和内存的值 mutex:0 交换。所以线程 Y 再往下走就会 else 挂起等待。
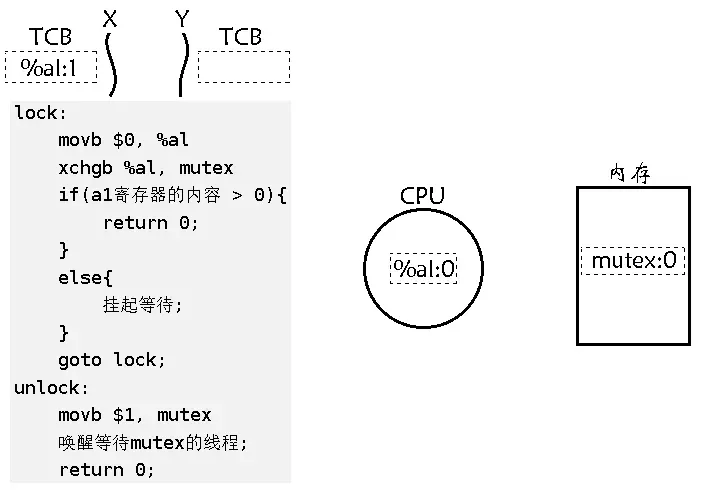
-
再线程切换到线程 X,把线程 Y 中的上下文数据保存于自己的 TCB,然后线程 X 把自己在 TCB 中保存的上下文数据数据恢复到 CPU,再执行 if,就可以访问临界区中的代码了,然后访问临界区成功,并返回。
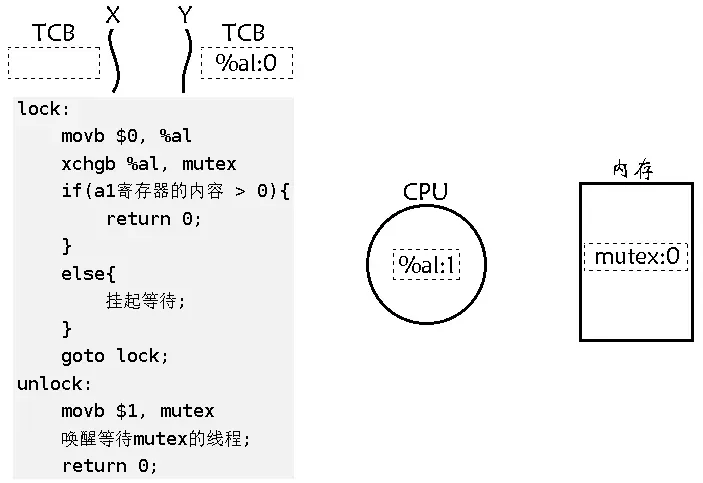
-
然后线程 X 去执行 unlock 中的 movb $1,mutex 把内存中的 mutex 值又置为 1,然后唤醒等待 mutex 的线程 Y,成功返回,这样线程 X 就完成了解锁,unlock 也一定是原子的,因为能执行 unlock 的一定是曾经 lock 过的,所以 unlock 是不是原子性的已经不是重点了。最后切换到线程 Y,将上下文数据恢复,继续往下执行 goto lock,将寄存器 %al 清零, 然后将其与内存中的 mutex 值交换,成功访问临界区资源返回,然后把 mutex 值置为 1,没有唤醒的 mutex 线程,然后成功解锁。注意这里以不用管寄存器中的 %al:1,因为下次在申请锁时会先把 %al 置 0。
-
注意:
-
这里的 %al 是寄存器数据,是线程的上下文数据,代表的是线程私有。
-
mutex 互斥锁,本质就是内存中的一个内存空间,空间里面的值是 1,是可以被所有的线程读取并访问的。
-
综上,在交换的时候能保证只有一个 1。为什么一定要 swap/exchange 或者 xchgb 呢,mov %al, mutex 不行吗?一定不行,虽然 mov 也是一条汇编,但是它是拷贝,和交换是不一样的,拷贝会把 mutex 的值拷贝到寄存器中,这样一来,就不能保证只有一个 1 了,其它线程依然可以在一个线程正在访问临界区时也访问临界区,所以需要 swap/exchange 或者 xchgb 指令,以保证在多线程执行时,每个线程的上下文中,只有一个 1,这样就可以保证了原子了。
-
💦 可重入VS线程安全
1. 概念
- 线程安全:多个线程并发同一段代码时,不会出现不同的结果,或者说,线程安全需要保证在多线程环境下不会出现数据竞争的问题。常见对全局变量或者静态变量进行操作,并且没有锁保护的情况下,会出现该问题。
- 重入:同一个函数被不同执行流调用,当前一个流程还没有执行完,就有其它的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,就是不可重入函数。
2. 常见的线程不安全的情况
- 不保护共享变量的函数。
- 函数状态随着被调用,状态发生变化的函数。
- 返回指向静态变量指针的函数。
- 调用线程不安全函数的函数。
3. 常见的线程安全的情况
- 每个线程对全局变量或者静态变量只有读取的权限,而没有写入的权限,一般来说这些线程是安全的。
- 类或者接口对于线程来说都是原子操作。
- 多个线程之间的切换不会导致该接口的执行结果存在二义性。
- 一句话,一个线程执行某段代码时不会影响其它线程,这就是线程安全的。
4. 常见不可重入的情况
- 调用了 malloc/free 函数,因为 malloc 函数是用全局链表来管理堆的。
- 调用了标准 I/O 库函数,标准 I/O 库的很多实现都以不可重入的方式使用全局数据结构。
- 可重入函数体内使用了静态的数据结构。
5. 常见可重入的情况
- 不使用全局变量或静态变量。
- 不使用 malloc 或者 new 开辟出来的空间。
- 不调用不可重入函数。
- 不返回静态或全局数据,所有数据都有函数的调用者提供。
- 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据。
6. 可重入与线程安全联系
-
这两个概念有些类似,但只要记住线程安全指的是一个线程不会影响另一个线程,可重入指的是函数被多个执行流进入没有出现任何问题的状态。
-
函数是可重入的,那就是线程安全的。
-
函数是不可重入的,那就不能由多个线程使用,有可能引发线程安全问题。
-
如果一个函数中使用了全局变量,那么这个函数既不是线程安全也不是可重入的。
7. 可重入与线程安全区别
-
可重入函数是线程安全函数的一种。
-
线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
如一个函数中使用了全局变量,那么这个函数既不是线程安全的也不是可重入的,因为多个线程同时访问这个函数时,会出现对全局变量的竞争,导致结果不可预期。而如果对临界资源的访问加锁,则这个函数是线程安全的,但不一定是可重入的。
-
如果将对临界资源的访问加上锁,则这个函数是线程安全的,但如果锁一直未释放则会产生死锁,因此是不可重入的。
六、死锁
💦 概念
死锁是一种常见的锁,死锁是指在一组进程或线程中的各个进程或线程均占有不会释放的资源,它们申请锁而不释放锁,进而导致多个执行流互相等待的状态。死锁通常发生在两个或多个进程或线程之间竞争资源的情况,当一个进程或线程持有一个资源并请求另一个进程或线程持有的资源时,如果另一个进程或线程也持有该进程所需的资源并请求第一个进程或线程的资源,就有可能发生死锁。就像小明和小红身上各有 5 毛钱,想买 1 块钱的辣条,小明对小红说把你的 5 毛钱给我,我来买,小红也对小明说把你的 5 毛钱给我,我来买,此时他们既想要申请对方的 5 毛钱,又不想妥协释放自己的 5 毛钱。这种状态就叫做死锁。
💦 死锁四个必要条件
只要产生了死锁,一定有如下四个条件:
-
互斥条件:一个资源每次只能被一个执行流使用。
本质上引入互斥就是为了保护临界资源,由并行变成了串行,保证了原子性。但是也带了新的问题 —— 死锁。因为互斥只要存在就会产生申请资源阻塞的情况,就有可能出现死锁。
-
请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放。
人话就是请求你的锁给我,我的锁不释放。小明和小红都想要对方的 5 毛钱,却又都不妥协自己的 5 毛钱,这也是请求与保持条件。
-
不剥夺条件:一个执行流已获得的资源,在未使用完之前,不能强行剥夺。
-
循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系。
一般而言,你要我的资源,而我要别人的资源,是不会造成死锁的。而你要我的资源,我也要你的资源,就可能会造成死锁,因为我们是竞争关系。
💦 避免死锁
-
破坏死锁的四个必要条件任何一个
互斥条件很难被破坏,因为它要求一次只有一个进程或线程使用资源,一般也建议能不用锁就不用锁;请求与保持就是释放相对应的锁资源;不剥夺条件就是可以根据优先级设计一个算法,就算一个执行流未使用完资源,也可以被剥夺;循环等待条件就是若干执行流之间在申请和释放锁资源时不要形成回路。
-
加锁顺序一致
-
避免锁未释放的场景
-
资源一次性分配
💦 避免死锁算法
实际解决死锁是有一些算法的:
-
死锁检测算法(了解)
死锁检测算法是一种利用进程状态的变化来识别死锁的方式,能够提高系统的并发性和效率。这种算法主要有两种形式:一种是预防式,它在进程申请资源时就进行干预,以防止系统进入不安全状态;另一种是事后处理,它允许系统进入不安全状态,然后通过某种算法检测并恢复。具体来说,死锁检测需要用某种数据结构来保存资源的请求和分配信息,并提供一种算法,利用上述信息来检测系统是否已进入死锁状态。如果检测到系统已经发生死锁,可以采取相应的措施解除死锁,如资源剥夺法、撤销进程法或进程回退法等。值得注意的是,死锁检测通常在资源有向图(也称为资源分配图)上进行。因此,理解和掌握如何有效地在资源有向图上进行死锁检测和解除,对于提高系统的性能和稳定性至关重要。
-
银行家算法(了解)
银行家算法,是由艾兹格·迪杰斯特拉在 1965 年为 T.H.E 系统设计的一种避免死锁产生的算法。这个算法不仅适用于操作系统给进程分配资源,还可以用于其他需要进行资源分配和调度的场景。该算法主要使用了四个数据结构:
可利用资源向量Available、最大需求矩阵Max、分配矩阵Allocation以及需求矩阵Need。这些数据结构分别记录了系统中当前可用的资源数量、每个进程对资源的最大需求量、系统已经分配给每个进程的资源数量以及每个进程还需要的资源数量。在实现过程中,银行家算法首先检查系统是否处于安全状态,如果是,则允许进程继续申请资源;否则,将拒绝进程的请求。如果系统进入不安全状态,则需要采取相应的措施使系统返回到安全状态。总的来说,银行家算法是一种既简单又有效的死锁避免方法,它通过合理的资源分配和调度来防止系统进入不安全状态,从而避免了死锁的发生。
七、线程同步

很明显线程同步和线程互斥是相对的。对于上面的模拟抢票实现,当然可能存在某个线程竞争锁的能力特别强,每次申请都是它优先申请到锁资源,其它线程没有机会拥有锁,我们称这种问题为饥饿问题,这样就会出现该线程一直在循环进行申请锁、检测(抢票)、释放锁,即使票已经没有了,因为释放锁后并没有 break 出循环。饥饿问题本身并没有错,只是说不合理。就像你从墙边拿了钥匙去单间自习室中自习,一会出来了,刚把钥匙挂在墙边,看到有很多人在排队,你想好不容易抢到了单间自习室,划不来啊,于是你刚放下钥匙又拿起了钥匙进去自习,一会又出来了放钥匙了,看到人还是很多,心想把明早的也自习算了,于是又拿着钥匙去自习了,反反复复。你本质能反反复复的进去自习,是因为你离钥匙最近,理论上虽然没问题,但是却不合理。所以你作为自习室的管理者,就规定了如果从单间自习室出来,把钥匙挂在墙上后,不能立即申请钥匙,如果你要再次申请,必须排到队列的尾部。排队的本质其实是让我们获取锁在安全的前提下,按照某种顺序进行申请和释放,这就叫做线程同步的过程。同步不是严格意义上解决数据正确或错误的问题,而是解决不合理的问题。所以我们经常会一起听说互斥和同步两个概念,因为光有互斥还无法保证执行流进行合理的临界资源访问。
💦 条件变量
-
条件变量是一个原生线程库提供的一个描述临界资源状态的对象或变量。
如上在抢票时发现票已经售完了,就不应该再申请锁了,而应该等有票了再申请。比如中午你问你妈有没有吃的,你妈说没有,过了两秒,你又问你妈有没有吃的,你妈又说没有,反反复复,这样当然没错,只是不合理,实际上你妈告诉你没有吃的时候,就等同于临界资源中没有票了,而合理的是,你不要着急的去问你妈或申请锁,而应该跟你妈说有吃的了叫我,然后你就在一旁等待,直到你妈唤醒你,然后你再问。所以需要条件变量来描述临界资源状态,之前之所以不断的轮询申请锁、检测、释放锁,本质就是我们并不知道临界资源的状态。
又如下图,当右边正在放苹果时,左边的来拿了,此时左侧的人不一定能拿到苹果,因为正在放这个动作包含了放前、放中、放后,所以这就叫做二义性问题。所以使用锁来解决这种问题,无论你要放还是拿苹果都需要加锁,其过程是原子的,这样就解决了二义性问题。那么问题又来了,拿苹果的比较皮索,放苹果的又比较麻利,然后放苹果的加锁,然后放苹果,然后解锁,两人都是瞎子,放苹果的也并不知道苹果有没有被拿苹果的拿走,所以放苹果的又开始加锁,然后检测到苹果没有被拿走,然后又释放锁,拿苹果的人实在是太慢了,放苹果的人反反复复加锁、检测、解锁了很多次依旧检测到盒子里的苹果,没有任何有效的动作,放苹果的人的这样一个周期很快,而导致拿苹果的人就算要去拿了也竞争不过放苹果的人,以上帝视角看放苹果的人就是在不断的申请释放,而拿苹果的人想拿却竞争不过放苹果的人。反复强调了这种现象当然没有错,只是不合理,所以合理的是放苹果的人加锁、放苹果、解锁、然后敲一下铃铛,就去睡觉了,此时拿苹果的人就知道了 (即使拿苹果的人很慢,但他一定可以拿到苹果),一定时间后,拿苹果的人开始加锁、拿苹果、解锁,敲铃铛,也去睡觉了,此时放苹果的人也知道拿苹果的人把苹果拿走了,放苹果的人就可以继续的往盒子里放苹果了。我们就称这里的铃铛为
条件变量,这里的铃铛就是描述盒子的状态,它对应的就是临界资源,所以条件变量就是描述临界资源的状态。所以有了条件变量就可以不用频繁的通过申请和释放锁的方式,以达到检测临界资源的目的。
-
当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,什么也做不了。
-
例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中,这种情况就需要用到条件变量。
-
接口
#include<pthread.h> int pthread_cond_init(pthread_cond_t* restrict cond,const pthread_condattr_t* restrict attr); int pthread_cond_destroy(pthread_cond_t* cond); int pthread_cond_signal(pthread_cond_t* cond); int pthread_cond_broadcast(pthread_cond_t* cond); int pthread_cond_timedwait(pthread_cond_t* restrict cond,pthread_mutex_t* restrict mutes,const struct timespec* restrict abstime); int pthread_cond_wait(pthread_cond_t* restrict cond,pthread_cond_t* restrict mutex); pthread_cond_t cond=PTHREAD_COND_INITIALIZER; init: 初始化cond,并设置属性attr. destroy: 销毁条件cond. signal: 唤醒指定条件变量下等待的一个线程. broadcast: 唤醒所有在该条件变量下等待的线程(少用). timedwait: 指定的时间范围内等待条件变量下的线程(少用). wait: 指定的条件变量下进行等待,一定要入cond的队列,mutex用于在锁中阻塞挂起时,会自动释放锁,唤醒时,会自动获取锁(生产者消费者中详谈). notice: 一般cond初始化有两种方案,其一,在全局定义时直接使用PTHREAD_COND_INITIALIZER宏初始化;其二,使用pthread_cond_init初始化,对于前者初始化不用destroy. -
测试用例 14
创建了三个线程去执行 r1 函数,又创建了一个线程去执行 r2 函数,并且由这个线程去控制那三个线程,也就是说由 r2 函数控制 r1 函数。可以看到 r1 中并没有 sleep,但是却 sleep,正是因为 r2 中的 sleep 控制了 r1。本质 r2 就是敲铃铛的人,r1 就是等铃铛的人,r1 醒来的频率取决于 r2 敲铃铛的频率。注意线程 1 2 3 谁先运行是由调度器决定的,它们一创建出来,就要去等待了,谁先到谁就先等,后面的都得在后面排队 3 2 1,当唤醒一个线程,那个线程执行完后就得去队尾排队 2 1 3。
#include <iostream> #include <pthread.h> #include <unistd.h> using namespace std; //定义全局条件变量和锁 pthread_cond_t cond; pthread_mutex_t mutex; void* r1(void* args) { while(true) { pthread_cond_wait(&cond, &mutex);//暂不考虑 cout << (char*)args << ": " << "act..." << endl; } return nullptr; } void* r2(void* args) { while(true) { //pthread_cond_broadcast(&cond); pthread_cond_signal(&cond); sleep(1); } return nullptr; } int main() { //初始化条件变量和锁 pthread_cond_init(&cond, nullptr); pthread_mutex_init(&mutex, nullptr); pthread_t tid1, tid2, tid3, tid4; pthread_create(&tid1, nullptr, r1, (void*)"thread 1"); pthread_create(&tid2, nullptr, r1, (void*)"thread 2"); pthread_create(&tid3, nullptr, r1, (void*)"thread 3"); pthread_create(&tid4, nullptr, r2, (void*)"thread 4"); pthread_join(tid1, nullptr); pthread_join(tid2, nullptr); pthread_join(tid3, nullptr); pthread_join(tid4, nullptr); //销毁条件变量和锁 pthread_cond_destroy(&cond); pthread_mutex_destroy(&mutex); return 0; }-
测试用例 14.1
pthread_cond_signal:

-
测试用例 14.2
pthread_cond_broadcast:

-
💦 同步概念与竞态条件
- 同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步。
- 竞态条件:因为时序问题,而导致程序异常,我们称为竞态条件。在线程场景下,这种问题也不难理解。
💦 条件变量使用规范
等待条件变量:
pthread_mutex_lock(&mutex);
while(条件为假)
pthread_cond_wait(&cond, &mutex);
pthread_mutex_unlock(&mutex);
唤醒条件变量
pthread_mutex_lock(&mutex);
pthread_cond_signal(&cond);//唤醒条件变量
pthread_mutex_unlock(&mutex);
八、生产者消费者模型

如图可以看到生活中,学生就是消费者角色,而工厂才是真正的生产者角色,那么超市是什么?为什么需要超市?—— 超市是交易场所;你家附近不一定有工厂,而且工厂的定位是大规模生产,你也不可能找工厂生产 5 包方便面,如果工厂也承担了超市的角色,它就不仅要考虑生产的任务,还要考虑并收集消费者的需求,实际对工厂是一种负担,有了超市就可以将生产环节和消费环节进行了解耦 (这里的解耦是一种松耦合关系,比如你找工厂生产 5 包方便面,工厂立马生产,预计 1 个小时,此时你正在等待,当工厂生产好后,你拿到了方便面,此时当没有人来消费时,工厂正在等待,这是串行。换言之,工厂永远是学生来了需求就满足需求,没有需求就等待不生产,工厂和学生互相等待,这就叫做强耦合关系。而超市出现后,工厂就一点也不关心学生要几包方便面了,而只要把方便面生产出来放进超市任务就完成了,学生要方便面的时候直接去超市买就行了。也就是说就算没有学生消费,工厂也会生产;就算没有工厂生产,学生也会消费;学生也不用在等工厂生产了;工厂也不用在等学生消费了;工厂生产的很快,学生消费的很慢,超市就可以让工厂生产的慢些;学生消费的很快,工厂生产的很慢,超市就可以让工厂生产的快些,此时消费和生产就可以同时进行了,这叫并行,此时学生和工厂就叫做松耦合关系)。
生产者消费者模型遵守 321 原则 (注意,这里书上没有,别对面试官说 321 原则,只是为了方便记忆和理解):
-
3
存在 3 种关系:
- 生产者和生产者 —— 竞争或互斥
- 消费者和消费者 —— 竞争或互斥
- 生产者和消费者 —— 同步和互斥
我们都清楚超市可以被生产者和消费者同时访问,所以超市是一种临界资源。消费者可以有多个,生产者也可以有多个,所以多个生产者之间一定是
竞争关系这很好理解,多个消费者之间其实也是竞争关系 (假如世界末日,超市只有一包方便面,你和你的室友都想买,这就是竞争关系,这个例子并不极端,因为通常超市物资都是比较丰富的,这并不难理解,因为现实中我们也见过比如日本核污水排放时,大家抢盐的事件),而在计算机中表述竞争关系就是互斥。工厂和学生是同步和互斥的关系 (比如学生去超市问售货员买方便面,售货员说卖完了,过了十分钟又去问售货员买方便面,售货员又说卖完了,反反复复,因为没有人主动通知学生,所以学生只能通过轮询检测的方式去检测超市里有没有方便面,这样没错,但是不合理。相反,工厂生产的特别快,去超市补货,因为工厂并不知道超市还有没有空间,所以就反反复复的检测,这样没问题,只是不合理。一定是有了商品让消费者过来,有了空间让生产者过来。所以最合理的状态是工厂供货完,让学生过来消费,学生消费完,让工厂过来供货,这就是同步;当然光有同步还不够,因为有可能出现工厂正在供货,学生就过来消费了,此时工厂可能是供货前/中/后,所以同苹果的例子,可能会出现二义性问题,所以还需要互斥)。 -
2
存在 2 种角色:
- 生产者
- 消费者
一般进行生产和消费的是线程或进程。
-
1
1 种交易场所:超市,在编码上通常指的是一段内存空间,它是临界资源 (它一定是在内存中开辟的,一个线程往其放数据,另一个线程往其拿数据,所以它可能是你自己定义的数组、队列、链表、管道 …)。
💦 为何要使用生产者消费者模型
生产者消费者模型就是通过一个容器来解决生产者和消费者强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力,这个阻塞队列就是用来给生产者和消费者解耦的。
💦 生产者消费者模型优点
- 解耦
- 支持并发
- 支持忙闲不均
💦 基于BlockingQueue的生产者消费者模型
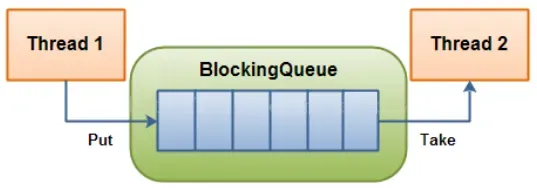
Thread1 就是生产者,Thread2 就是消费者,如果在生活中来回搬运的是方便面产品,那么在计算机中被进行搬运最多的一定是数据,而这里只有一个生产者和一个消费者,所以不用维护生产者和生产者、消费者和消费者之间的互斥关系。而所谓的阻塞队列,队列是有上限的,当队列不满足生产或者消费条件的时候,对应的线程就应该阻塞,具体在多线程编程中阻塞队列是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出。简单来说就是 BlockingQueue 空就不让消费者消费,满就不让生产者生产 (以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时也会被阻塞)。
💦 C++ queue模拟阻塞队列的生产消费模型
为了比较清晰的展示这里不同的现象,所以这里从测试用例 15 到 19 都是层层递进的补充实现,可能代码有些冗余。
-
测试用例 15
.hpp 文件我们在 C++ 模板中谈过,它是 C++ 程序的头文件,你可以认为它既是 .h,也是 .cpp,其中就包含了声明和实现,这种文件通常用于模板类的头文件。
对于 Put 和 Get 的参数,这里有一个命名规则,通常如果是 const Type& 就是输入型参数;如果是 Type* 就是输出型参数;如果是 Type& 就是输入输出型参数,并简单实现了生产的过程和消费的过程;
至此代码的基本结构就搭建好了:makefile 实现好了自动化构建项目;block_queue.hpp 文件中封装了一个 BlockQueue 类,并使用了类模板,bq 是这个队列 (使用 STL 下的 queue 定义),cap 是 bq 的容量,显示定义了构造函数 (初始化列表初始化 cap) 和析构函数。cp.cc 文件是主函数的实现,new 好 bq 空间后,创建了两个线程,去执行对应的 consumer 和 producter 方法 (生产的数据先暂定 100,后面有生成策略),并把 bq 队列传入,然后等待两个线程,最后 delete bq 空间。
可以看到程序一运行,就只有 consumer 线程运行,直到最后出现了段错误,这是因为 BlockQueue 本身就是临界资源,此时就有可能出现 consumer 正在拿数据时 (拿前/中/后),producter 就来放数据了,或者 producter 正在放数据的时候 (放前/中/后), consumer 就来拿数据了,此时就会出现二义性,并且 queue 底层有各种各样的指针操作,所以这里出现了段错误也是可以理解的,所以需要加锁实现互斥。
makefile:
cp:cp.cc g++ $^ -o $@ -std=c++11 -lpthread .PHONY:clean clean: rm -f cpblock_queue.hpp:
#pragma once #include <iostream> #include <queue> using std::cout; using std::endl; //临界资源 template<class T> class BlockQueue { private: int cap; queue<T> bq; public: BlockQueue(int _cap):cap(_cap) {} void Put(const T& in)//输入型参数 { //生产的过程 bq.push(in); } void Get(T* out)//输出型参数 { //消费的过程 *out = bq.front(); bq.pop(); } ~BlockQueue() {} };cp.cc:
#include "block_queue.hpp" #define NUM 30 void* consumer(void* g) { //将g强转 BlockQueue<int>* bq = (BlockQueue<int>*)g; int out = 0; while(true) { bq->Get(&out); cout << "consumer: " << out << endl; } return nullptr; } void* producter(void* p) { //将p强转 BlockQueue<int>* bq = (BlockQueue<int>*)p; //暂时这样,后有生成策略 int in = 100; while(true) { bq->Put(in); cout << "producter: " << in << endl; } return nullptr; } int main() { //开辟空间 BlockQueue<int>* bq = new BlockQueue<int>(NUM); //创建线程,传入bq队列 pthread_t g, p; pthread_create(&g, nullptr, consumer, bq); pthread_create(&p, nullptr, producter, bq); //等待线程 pthread_join(g, nullptr); pthread_join(p, nullptr); //销毁空间 delete bq; return 0; }
-
测试用例 16
可以看到加上锁后,还是出现了和测试用例 15 一样的现象。虽然已经完成了互斥,但是程序一运行,可能 producter 一瞬间就把阻塞队列写满了,consumer 没时间读取,或者 consumer 一瞬间就把阻塞队列读完了,producter 没时间写入。根本原因是如果队列满了,就不应该再写入了,队列空了,就不应该再读取了,而应该阻塞住,所以这里出现了段错误是因为没有对它的满和空做处理,所以需要条件变量,不过在此之前先实现 IsFull() 和 IsEmpty(),先让这里的互斥操作是可以正常跑的。
block_queue.hpp:
#pragma once #include <iostream> #include <queue> #include <pthread.h> using std::cout; using std::endl; //临界资源 template<class T> class BlockQueue { private: int cap; pthread_mutex_t lock;//互斥锁 std::queue<T> bq; public: BlockQueue(int _cap):cap(_cap) { pthread_mutex_init(&lock, nullptr); } void Put(const T& in)//输入型参数 { //生产的过程 pthread_mutex_lock(&lock); bq.push(in); pthread_mutex_unlock(&lock); } void Get(T* out)//输出型参数 { //消费的过程 pthread_mutex_lock(&lock); *out = bq.front(); bq.pop(); pthread_mutex_unlock(&lock); } ~BlockQueue() { pthread_mutex_destroy(&lock); } };cp.cc:
#include "block_queue.hpp" #define NUM 30 void* consumer(void* g) { BlockQueue<int>* bq = (BlockQueue<int>*)g; int out = 0; while(true) { bq->Get(&out); cout << "consumer: " << out << endl; } return nullptr; } void* producter(void* p) { BlockQueue<int>* bq = (BlockQueue<int>*)p; //暂时这样,后有生成策略 int in = 100; while(true) { bq->Put(in); cout << "producter: " << in << endl; } return nullptr; } int main() { BlockQueue<int>* bq = new BlockQueue<int>(NUM); pthread_t g, p; pthread_create(&g, nullptr, consumer, bq); pthread_create(&p, nullptr, producter, bq); pthread_join(g, nullptr); pthread_join(p, nullptr); delete bq; return 0; }
-
测试用例 17
实现了 IsFull() 和 IsEmpty(),让队列不满时才可以生产,不空时才可以消费,否则就阻塞。
block_queue.hpp:
#pragma once #include <iostream> #include <queue> #include <pthread.h> #include <unistd.h> using std::cout; using std::endl; //临界资源 template<class T> class BlockQueue { private: int cap; pthread_mutex_t lock;//互斥锁 std::queue<T> bq; private: bool IsFull() { return bq.size() == cap ? true : false; } bool IsEmpty() { return bq.size() == 0 ? true : false; } public: BlockQueue(int _cap):cap(_cap) { pthread_mutex_init(&lock, nullptr); } void Put(const T& in)//输入型参数 { //生产的过程 pthread_mutex_lock(&lock); if(!IsFull())//不满才可以生产 { bq.push(in); } else { cout << "queue is full, put() should block!" << endl; } pthread_mutex_unlock(&lock); } void Get(T* out)//输出型参数 { //消费的过程 pthread_mutex_lock(&lock); if(!IsEmpty())//不空才可以消费 { *out = bq.front(); bq.pop(); } else { cout << "queue is empty, get() should block!" << endl; } pthread_mutex_unlock(&lock); } ~BlockQueue() { pthread_mutex_destroy(&lock); } };cp.cc:
#include "block_queue.hpp" #define NUM 30 void* consumer(void* g) { BlockQueue<int>* bq = (BlockQueue<int>*)g; int out = 0; while(true) { bq->Get(&out); cout << "consumer: " << out << endl; sleep(1); } return nullptr; } void* producter(void* p) { BlockQueue<int>* bq = (BlockQueue<int>*)p; //暂时这样,后有生成策略 int in = 100; while(true) { bq->Put(in); cout << "producter: " << in << endl; } return nullptr; } int main() { BlockQueue<int>* bq = new BlockQueue<int>(NUM); pthread_t g, p; pthread_create(&g, nullptr, consumer, bq); pthread_create(&p, nullptr, producter, bq); pthread_join(g, nullptr); pthread_join(p, nullptr); delete bq; return 0; }-
测试用例 17.1:
可以看到这里默认调度器执行 consume 是要比 producter 快,所以 consume 就不断的阻塞的申请锁、检测、释放锁,这样没问题,只是不合理。所以需要条件变量实现同步。

-
测试用例 17.2:
让 consume 慢点 (即让 consume 中每次休眠一秒),所以 producter 一下就把队列写满了,所以 producter 就不断的阻塞的申请锁、检测、释放锁,这样没问题,只是不合理。所以需要条件变量。

-
-
测试用例 18
实现条件变量:生产者应该关注 have_space 条件变量,消费者应该关注 have_data 条件变量,然后在构造函数内初始化,析构函数内销毁。这里对生产和消费的过程修改:生产过程中若队列满就不应该生产,而应该在 have_space 条件变量下等待,而一旦等待就会被挂起阻塞,可是当前是在临界区内部,消费线程不可能去消费,更不可能去唤醒生产线程中等待的线程 (这块很重要,因为如果你不理解,就无法理解 pthread_cond_wait 为什么要设计第二个参数互斥锁 mutex),因为它是带着锁挂起阻塞的,所以如果这样执行,程序被会卡住在这,所以 pthread_cond_wait 在设计时就加上了互斥锁,这样阻塞挂起时,会自动释放锁,唤醒时,会自动获取锁。也就是说 pthread_cond_wait 会阻塞挂起的同时,然后把锁释放,当你唤醒时,会自动帮你竞争上锁,这也就是为什么 pthread_cond_wait 第二个参数需要带一把锁的原因。此时再往下走,if 外一定是有空间,要么是 IsFull() 为假,要么是被唤醒了;同样的,对于消费过程若队列空就不应该消费,而应该在 have_data 条件变量下等待。此时再往下走,if 外一定是有数据的,要么是 IsEmpty() 为假,要么是被唤醒了;还有个问题,此时生产过程或消费过程中条件满足就阻塞挂起等待,那么是由谁来唤醒呢?—— 当然不能是自己唤醒自己,也不应该,因为你并不知道自己还要不要生产或者消费。而应该是当消费者挂起时,只有生产者知道有没有数据;当生产者挂起时,只有消费者知道有没有空间。所以还需要 pthread_cond_signal 来唤醒对方;所以同步最理想的状态应该是生产完后唤醒消费者,消费完后唤醒生产者。对于 pthread_cond_signal 写在锁内锁外都可以 (比如生产者中在锁内唤醒消费者,消费者就从条件变量下醒来 (pthread_cond_wait(&have_data, &lock)),这样它就会直接在锁内等待了,然后会自动释放锁,唤醒时,又自动获取锁。同理锁外也是一样)
cp.cc 中设计测试用例:阻塞队列的容量是 NUM 10,消费者中消费的很慢,每 3 秒消费 1 次,生产者中生产的很快 (由调度器决定,没有加以限制);生产者生产的很慢,第 3 秒生产 1 次,消费者消费的很快 (由调度器决定,没有加以限制)。所以这里的现象是生产者一瞬间就把数据生产完放在阻塞队列中,3 秒内生产和消费都不进行,后来消费者每 3 秒消费一次,生产者又生产一次,反反复复;生产者生产一条,消费者才消费,反反复复;此外还可以设置很多策略,比如可以设置当前生产者生产数据于阻塞队列的容量达到二分之一以上,才来消费,这里可以让生产者生产数据慢点,如 sleep 1,此时的现象就是前 5 秒生产者一直在生产,5 秒后,消费者一瞬间把所有数据都消费走,反反复复。这里还要说明的是 pthread_cond_wait 可能会
伪唤醒,比如说生产者中队列是满的,却因为某些原因被唤醒,此时往下执行 push 就会出错,换言之,在唤醒时,条件不一定会满足。此时就将 if 改成 while 就可以预防伪唤醒了,因为 while 本身也有判断的能力,此时当这里被唤醒时,就会再检查一次这里是否为满,如果为满,则继续等待,如果不为满,就生产。所以加上 while 后,不管是正常唤醒还是异常唤醒都会多做一次条件检测,从而让代码更健壮。伪唤醒可以理解:pthread_cond_wait 是系统调用函数,当然可能会失败,所以失败后就返回继续往下走。一般单核处理器出现伪唤醒的可能性比较低,大多数都是多核处理器中,大家下来也可以找找原生线程库中关于这块的官方描述。也有可能对方调用的是 pthread_cond_broadcast(),可能生产者只生产了一条数据,但是却唤醒了所有的消费者线程,比如一个线程先于我唤醒,它竞争锁成功了,然后去消费,而我竞争锁失败了,此时我可能就不在条件变量下等待,而是在锁中等待,然后当它释放锁时,这个锁被我拿到了,此时队列已经为空了,所以就可能出错。
这个代码类似于管道:一个进程往管道里写数据,管道满时,进程就会被阻塞;一个进程往管道里读数据,管道空时,进程就会被阻塞;当时还验证了管道的大小,所以管道的实现是类似阻塞队列的。
block_queue.hpp:
#pragma once #include <iostream> #include <queue> #include <pthread.h> #include <unistd.h> using std::cout; using std::endl; //临界资源 template<class T> class BlockQueue { private: int cap; pthread_mutex_t lock;//互斥锁 pthread_cond_t have_space;//生产者 pthread_cond_t have_data;//消费者 std::queue<T> bq; private: bool IsFull() { return bq.size() == cap ? true : false; } bool IsEmpty() { return bq.size() == 0 ? true : false; } public: BlockQueue(int _cap):cap(_cap) { pthread_mutex_init(&lock, nullptr); pthread_cond_init(&have_space, nullptr); pthread_cond_init(&have_data, nullptr); } void Put(const T& in)//输入型参数 { //生产的过程 pthread_mutex_lock(&lock); while(IsFull())//满了应该wait | if(IsFull())不能预防伪唤醒 { //带着锁在临界区挂起阻塞等待,程序会卡住,因为解不了锁,所以pthread_cond_wait在设计时就加上了互斥锁,当挂起时,自动释放锁,唤醒时,自动获取锁. //pthread_cond_wait(&have_space); pthread_cond_wait(&have_space, &lock); } //此时这里一定有空间 - 要么是IsFull()为假,要么是被唤醒了. bq.push(in); //测试用例18.3 //if(bq.size() >= cap / 2) //{ // pthread_cond_signal(&have_data); //} pthread_mutex_unlock(&lock); //生产完后,唤醒消费者,放在锁外. pthread_cond_signal(&have_data); } void Get(T* out)//输出型参数 { //消费的过程 pthread_mutex_lock(&lock); while(IsEmpty())//空了应该wait | if(IsEmpty())不能预防伪唤醒 { pthread_cond_wait(&have_data, &lock); } //此时这里一定有数据 - 要么是IsEmpty()为假,要么是被唤醒了. *out = bq.front(); bq.pop(); //消费完后,唤醒生产者,放在锁内. pthread_cond_signal(&have_space); pthread_mutex_unlock(&lock); } ~BlockQueue() { pthread_mutex_destroy(&lock); pthread_cond_destroy(&have_space); pthread_cond_destroy(&have_data); } };cp.cc:
#include "block_queue.hpp" #define NUM 10 void* consumer(void* g) { BlockQueue<int>* bq = (BlockQueue<int>*)g; int out = 0; while(true) { sleep(3); bq->Get(&out); cout << "consumer: " << out << endl; } return nullptr; } void* producter(void* p) { BlockQueue<int>* bq = (BlockQueue<int>*)p; //生成策略 int in = 1; while(true) { //sleep(3); bq->Put(in); in++; in %= 100; cout << "producter: " << in << endl; } return nullptr; } int main() { BlockQueue<int>* bq = new BlockQueue<int>(NUM); pthread_t g, p; pthread_create(&g, nullptr, consumer, bq); pthread_create(&p, nullptr, producter, bq); pthread_join(g, nullptr); pthread_join(p, nullptr); delete bq; return 0; }-
测试用例 18.1
生产者生产的很快,消费者消费的很慢:

-
测试用例 18.2
消费者消费的很快,生产者生产的很慢:

-
测试用例 18.3
生产生产数据于阻塞队列的容量达到二分之一以上,才来消费:

-
-
测试用例 19
多生产者,多消费者,还需要额外维护多生产者之间和多消费者之间的互斥关系,需要提前于生产者和消费者之间竞争临界资源。实际这份代码体现不出来并行执行的过程和生产和消费的目的,我们费这么大劲把数据通过缓冲区从一个线程跑到另一个线程,这不闲着蛋疼嘛,根本原因是队列里写的是 1 2 3 这样的整数数据用于测试,换言之,如果 blockqueue 内不是原生数据,而是某种任务,而后面还要对这个任务进行计算,比如消费者在执行某种任务时,生产者同时也在生产数据,这会在信号量环形队列中体现。
block_queue.hpp:
#pragma once #include <iostream> #include <queue> #include <pthread.h> #include <unistd.h> using std::cout; using std::endl; using std::queue; //临界资源 template<class T> class BlockQueue { private: int cap; pthread_mutex_t p_lock;//多生产者竞争锁 pthread_mutex_t g_lock;//多消费者竞争锁 pthread_mutex_t lock;//生产者或消费者竞争锁 pthread_cond_t have_space;//生产者 pthread_cond_t have_data;//消费者 queue<T> bq; private: bool IsFull() { return bq.size() == cap ? true : false; } bool IsEmpty() { return bq.size() == 0 ? true : false; } public: BlockQueue(int _cap):cap(_cap) { pthread_mutex_init(&lock, nullptr); pthread_cond_init(&have_space, nullptr); pthread_cond_init(&have_data, nullptr); pthread_mutex_init(&p_lock, nullptr); pthread_mutex_init(&g_lock, nullptr); } void Put(const T& in)//输入型参数 { pthread_mutex_lock(&p_lock); //生产的过程 pthread_mutex_lock(&lock); while(IsFull())//满了应该wait | if(IsFull())不能预防伪唤醒 { //带着锁在临界区挂起阻塞等待,程序会卡住,因为解不了锁,所以pthread_cond_wait在设计时就加上了互斥锁,当挂起时,自动释放锁,唤醒时,自动获取锁. //pthread_cond_wait(&have_space); pthread_cond_wait(&have_space, &lock); } //此时这里一定有空间 - 要么是IsFull()为假,要么是被唤醒了. bq.push(in); pthread_mutex_unlock(&lock); //生产完后,唤醒消费者,放在锁外. pthread_cond_signal(&have_data); pthread_mutex_unlock(&p_lock); } void Get(T* out)//输出型参数 { pthread_mutex_lock(&g_lock); //消费的过程 pthread_mutex_lock(&lock); while(IsEmpty())//空了应该wait | if(IsEmpty())不能预防伪唤醒 { pthread_cond_wait(&have_data, &lock); } //此时这里一定有数据 - 要么是IsEmpty()为假,要么是被唤醒了. *out = bq.front(); bq.pop(); //消费完后,唤醒生产者,放在锁内. pthread_cond_signal(&have_space); pthread_mutex_unlock(&lock); pthread_mutex_unlock(&g_lock); } ~BlockQueue() { pthread_mutex_destroy(&lock); pthread_cond_destroy(&have_space); pthread_cond_destroy(&have_data); pthread_mutex_destroy(&p_lock); pthread_mutex_destroy(&g_lock); } };cp.cc:
#include "block_queue.hpp" #define NUM 10 void* consumer(void* g) { BlockQueue<int>* bq = (BlockQueue<int>*)g; int out = 0; while(true) { sleep(3); bq->Get(&out); cout << "consumer: " << out << endl; } return nullptr; } void* producter(void* p) { BlockQueue<int>* bq = (BlockQueue<int>*)p; //生成策略 int in = 1; while(true) { //sleep(3); bq->Put(in); in++; in %= 100; cout << "producter: " << in << endl; } return nullptr; } int main() { BlockQueue<int>* bq = new BlockQueue<int>(NUM); pthread_t g, p, g1, p1, g2, p2; pthread_create(&g, nullptr, consumer, bq); pthread_create(&p, nullptr, producter, bq); pthread_create(&g1, nullptr, consumer, bq); pthread_create(&p1, nullptr, producter, bq); pthread_create(&g2, nullptr, consumer, bq); pthread_create(&p2, nullptr, producter, bq); pthread_join(g, nullptr); pthread_join(p, nullptr); pthread_join(g1, nullptr); pthread_join(p1, nullptr); pthread_join(g2, nullptr); pthread_join(p2, nullptr); delete bq; return 0; }
💦 POSIX信号量
这个话题我们已经在进程间通信中谈过了,信号和信号量是不同的概念,就是老婆和老婆饼。之前我们说信号量本质是一个计数器,是用来描述临界资源数目的计数器。我们知道了互斥锁能保护临界资源,条件变量能帮我们知道临界资源的状态,上面也说临界资源必须被互斥访问,只允许一个执行流,在特定的时刻访问临界资源。但其实,临界资源并不是一定只能一个线程同时访问的,这样说,以前的其实并没有错,只是以前临界资源 (阻塞队列)是被当做一个整体来看待的,而这里谈的临界资源是包含很多区域的,所以只要不同线程访问临界资源的区域时不重叠就可以多个线程同时访问。此时,我们最担心的问题是有多个线程访问同一区域 (后面再说),和多出来的线程进入,比如临界区中有 10 个区域,但是却进来了 20 个线程,就像电影院有 100 个位置,却进来了 200 个人,所以为了解决这个问题,就引出了电影票,也就是信号量,电影票是用来描述电影院的座位的,就像信号量就是用来描述临界资源数目的计数器的,所以任何线程,如果想访问临界资源中的某一个,必须先申请信号量,使用完毕,必须释放信号量,申请信号量后,一定能使用临界资源中的某一个,就像电影院买票后,一定有位置给你预订着。
如下面的伪代码,申请信号量叫做 p 操作,释放信号量叫做 v 操作,既然每个进程都得先申请信号量,前提是每个进程都得先看到信号量,此时信号量就是一种临界资源,而系统在设计的时候当然有考虑到,所以 pv 操作其本身就是原子的,所以它就被称为 pv 原语。所以系统也提供了一个信号量 sem_t 类型,我们用的也是 POSIX 下 pthread 库提供的信号量。

#include<semaphore.h>
Link with -pthread
int sem_init(sem_t* sem, int pshared, unsigned int value);
sem:
初始化的信号量.
pshared:
0,即线程之间共享,还有其它选项,不过一般设置为0.
value:
信号量中计数器的初始值.
int sem_destroy(sem_t* sem);
sem:
释放的信号量.
int sem_wait(sem_t* sem);
sem:
p操作,就相当于对值--,如果信号量的值>0,程序就立即返回,如果信号量的值<=0,sem_wait将会阻塞,直到值大于0.
int sem_post(sem_t* sem);
sem:
v操作,就相当于对值++.
💦 基于环形队列的生产消费模型

游戏规定小明永远在小红的前面,且不能超过小红,小明顺时针放苹果,小红顺时针拿苹果。最开始,盘子全是空的,必须让小明安全的执行。后来盘子满了,必须让小红安全的执行,可以看到当盘子为空或者为满时,小明和小红指向的是同一盘子,也就是说盘子不空或者不满时小明和小红指向的是不同的盘子。

既然环形队列为空为满时,都指向同一个位置,那么如何是空还是满?—— consumer == producter 为空;牺牲一个空间,来判断满的情况,即 producter + 1 == consumer 为满;上面所说的游戏规定小明不能超过小红第二圈是为了防止数据还没有被 consumer 消费就被 producter 覆盖了。实际在内存中环形队列并不是真正的环,而是线性的空间,而要实现头尾相接,除了在每个节点中加上一个后驱指针之外,还可以使用模运算。

这里不考虑牺牲一块空间,consumer 关注的是格子里的数据,producter 关注的是空格子。所以我们定义好信号量,此时消费者 P 操作申请信号量,申请失败就会被挂起,然后生产者 P 操作申请信号量成功,sem_space 就被 – – 了,然后生产数据于队列,此时格子是有数据的,所以 V 操作释放信号量,sem_data 就被 + + 了,此时消费者 P 操作申请信号量,sem_data 就被 – – 了,此时格子没有数据了,所以 V 操作释放信号量,sem_space 就被 + + 了。假设生产者一直生产,消费者不消费,最后 sem_space = 0, sem_data = 8;又假设消费者一直消费,生产者不生产,最后 sem_sapce = 8, sem_data = 0。
-
测试用例 20
单生产单消费的情况,是不需要互斥量和条件变量的,所以此时代码的效率一定比较高。
makefile:
ring_cp:main.cc g++ $^ -o $@ -std=c++11 -lpthread .PHONY:clean clean: rm -f ring_cpring_queue.hpp:
#pragma once #include <iostream> #include <pthread.h> #include <vector> #include <semaphore.h> #include <ctime> #include <cstdlib> #include <unistd.h> using std::cout; using std::endl; using std::vector; template<class T> class RingQueue { private: int cap; std::vector<T> ring;//临界资源,引入信号量. int c_index;//生产下标 int p_index;//消费下标 sem_t sem_space;//生产信号量 sem_t sem_data;//消费信号量 public: RingQueue(int _cap):cap(_cap), ring(_cap), c_index(0), p_index(0) { sem_init(&sem_space, 0, _cap); sem_init(&sem_data, 0, 0); } void Put(const T& in) { //生产者 sem_wait(&sem_space);//P sem_space-- ring[p_index] = in; sem_post(&sem_data);//V sem_data++ p_index++;//放里放外都行. p_index %= cap; } void Get(T* out) { //消费者 sem_wait(&sem_data);//P sem_data-- *out = ring[c_index]; sem_post(&sem_space);//V sem_space++ c_index++;//放里放外都行. c_index %= cap; } ~RingQueue() { sem_destroy(&sem_space); sem_destroy(&sem_data); } };main.cc
#include "ring_queue.hpp" void* consumer(void* ring_queue) { RingQueue<int>* rq = (RingQueue<int>*)ring_queue; while(true) { //消费 //sleep(1); int out = 0; rq->Get(&out); cout << "Consume data: " << out << endl; } } void* producter(void* ring_queue) { RingQueue<int>* rq = (RingQueue<int>*)ring_queue; while(true) { //生产 sleep(1); int data = rand() % 20 + 1;//[1, 20] rq->Put(data); cout << "Producter data: " << data << endl;//随机数 } } int main() { srand((unsigned int)time(nullptr)); RingQueue<int>* rq = new RingQueue<int>(10); pthread_t c, p; pthread_create(&c, nullptr, consumer, rq); pthread_create(&p, nullptr, producter, rq); pthread_join(c, nullptr); pthread_join(p, nullptr); return 0; }-
测试用例 20.1
消费者快,生产者慢,生产者每一秒生产一个数据,消费者每一秒消费一个数据。

-
测试用例 20.2
消费者慢,生产者快,生产者一瞬间就把数据写于环形队列,之后消费者每一秒消费一个数据,生产者每一秒生产一个数据。

-
-
测试用例 21
多生产多消费的情况 (三生产三消费),就必须多生产中一把锁竞争,多消费中一把锁竞争,因为 c_index 和 p_index 是被多个生产者和多个消费者共享的,比如有 5 个生产者同时申请到了信号量,此时多个执行流再执行 ring[p_index] = in 时,就有可能会覆盖上一次写的数据。至于 lock,放在 sem_wait() 之前或者 sem_wait() 之后都不会影响执行结果,但是建议是放在后面,因为一个线程在申请锁成功,并执行临界区代码时,其它线程也可以在竞争信号量,当这个线程执行完临界区代码,释放锁后,其它线程就可以直接申请锁了,也就是说 lock 在 sem_wait() 之前时,一个线程在申请信号量,申请锁后,执行临界资源时,其它线程只能看着,直到这个线程释放锁,才能再次申请信号量,换言之,这样效率可能不如前者。
makefile:
ring_cp:main.cc g++ $^ -o $@ -std=c++11 -lpthread .PHONY:clean clean: rm -f ring_cpring_queue.hpp:
#pragma once #include <iostream> #include <pthread.h> #include <vector> #include <semaphore.h> #include <ctime> #include <cstdlib> #include <unistd.h> using std::cout; using std::endl; using std::vector; template<class T> class RingQueue { private: int cap; std::vector<T> ring;//临界资源,引入信号量. int c_index;//生产下标 int p_index;//消费下标 sem_t sem_space;//生产信号量 sem_t sem_data;//消费信号量 pthread_mutex_t p_lock;//生产锁 pthread_mutex_t c_lock;//消费锁 public: RingQueue(int _cap):cap(_cap), ring(_cap), c_index(0), p_index(0) { sem_init(&sem_space, 0, _cap); sem_init(&sem_data, 0, 0); pthread_mutex_init(&p_lock, nullptr); pthread_mutex_init(&c_lock, nullptr); } void Put(const T& in) { //生产者 //pthread_mutex_lock(&p_lock);//lock1 sem_wait(&sem_space);//P sem_space-- pthread_mutex_lock(&p_lock);//lock2 ring[p_index] = in; sem_post(&sem_data);//V sem_data++ p_index++;//放里放外都行,这里尽量使临界区不要太大. p_index %= cap; pthread_mutex_unlock(&p_lock); } void Get(T* out) { //消费者 //pthread_mutex_lock(&c_lock);//lock1 sem_wait(&sem_data);//P sem_data-- pthread_mutex_lock(&c_lock);//lock2 *out = ring[c_index]; sem_post(&sem_space);//V sem_space++ c_index++;//放里放外都行,这里尽量使临界区不要太大. c_index %= cap; pthread_mutex_unlock(&c_lock); } ~RingQueue() { sem_destroy(&sem_space); sem_destroy(&sem_data); pthread_mutex_destroy(&p_lock); pthread_mutex_destroy(&c_lock); } };main.cc
#include "ring_queue.hpp" void* consumer(void* ring_queue) { RingQueue<int>* rq = (RingQueue<int>*)ring_queue; while(true) { //消费 //sleep(1); int out = 0; rq->Get(&out); cout << "Consume data: " << out << endl; } } void* producter(void* ring_queue) { RingQueue<int>* rq = (RingQueue<int>*)ring_queue; while(true) { //生产 sleep(1); int data = rand() % 20 + 1;//[1, 20] rq->Put(data); cout << "Producter data: " << data << endl;//随机数 } } int main() { srand((unsigned int)time(nullptr)); RingQueue<int>* rq = new RingQueue<int>(10); pthread_t c, p, c1, p1, c2, p2; pthread_create(&c, nullptr, consumer, rq); pthread_create(&p, nullptr, producter, rq); pthread_create(&c1, nullptr, consumer, rq); pthread_create(&p1, nullptr, producter, rq); pthread_create(&c2, nullptr, consumer, rq); pthread_create(&p2, nullptr, producter, rq); pthread_join(c, nullptr); pthread_join(p, nullptr); pthread_join(c1, nullptr); pthread_join(p1, nullptr); pthread_join(c2, nullptr); pthread_join(p2, nullptr); return 0; }-
测试用例 21.1
消费者快,生产者慢,这里生产者每一秒生产三个数据,消费者每一秒消费三个数据。

-
测试用例 21.2
消费者慢,生产者快,这里生产者一瞬间就把数据写于环形队列,之后消费者每一秒消费一个数据,生产者每一秒生产一个数据,消费者每一秒消费二个数据,生产者每一秒生产二个数据。

-
-
测试用例 22
上面的生产者消费者模型的案例其实并没有太大意义,实际更多的是生产和消费各种任务的。这里我们 touch task.hpp,其中定义 Task 类,实现一个累加求和任务 Handler (此时模板的好处就体现了),然后就开始制造任务,生产任务 (其中 Task 类中实现 Show 显示任务),然后消费者开始消费任务,处理任务。
makefile:
ring_cp:main.cc g++ $^ -o $@ -std=c++11 -lpthread .PHONY:clean clean: rm -f ring_cptask.hpp:
#include <iostream> using std::cout; using std::endl; class Task { private: int top; //[1,top] public: Task():top(1){}//无参默认构造 Task(int _top):top(_top)//有参构造 {} int Handler() { int sum = 0; for(auto i = 0; i <= top; i++) { sum += i; } return sum; } void Show() { cout << "生产者: 这个任务是, 累加数据从1~" << top << endl; } ~Task() {} };ring_queue.hpp:
#pragma once #include <iostream> #include <pthread.h> #include <vector> #include <semaphore.h> #include <ctime> #include <cstdlib> #include <unistd.h> using std::cout; using std::endl; using std::vector; template<class T> class RingQueue { private: int cap; std::vector<T> ring;//临界资源,引入信号量. int c_index;//生产下标 int p_index;//消费下标 sem_t sem_space;//生产信号量 sem_t sem_data;//消费信号量 public: RingQueue(int _cap):cap(_cap), ring(_cap), c_index(0), p_index(0) { sem_init(&sem_space, 0, _cap); sem_init(&sem_data, 0, 0); } void Put(const T& in) { //生产者 sem_wait(&sem_space);//P sem_space-- ring[p_index] = in; sem_post(&sem_data);//V sem_data++ p_index++;//放里放外都行. p_index %= cap; } void Get(T* out) { //消费者 sem_wait(&sem_data);//P sem_data-- *out = ring[c_index]; sem_post(&sem_space);//V sem_space++ c_index++;//放里放外都行. c_index %= cap; } ~RingQueue() { sem_destroy(&sem_space); sem_destroy(&sem_data); } };main.cc:
#include "ring_queue.hpp" #include "task.hpp" void* consumer(void* ring_queue) { RingQueue<Task>* rq = (RingQueue<Task>*)ring_queue; while(true) { //sleep(1); //1.消费任务 Task t; rq->Get(&t); //2.处理任务 int ret = t.Handler(); cout << "消费者: handler task done, ret: " << ret << endl; } } void* producter(void* ring_queue) { RingQueue<Task>* rq = (RingQueue<Task>*)ring_queue; while(true) { sleep(1); //1.制造任务[1,2000] int top = rand() % 2000 + 1; Task t(top); t.Show();//显示任务 //2.生产任务 rq->Put(t); } } int main() { RingQueue<Task>* rq = new RingQueue<Task>(10); pthread_t c, p; pthread_create(&c, nullptr, consumer, rq); pthread_create(&p, nullptr, producter, rq); pthread_join(c, nullptr); pthread_join(p, nullptr); return 0; }-
测试用例 22.1
生产者延时 1 秒后,就每秒不断的给消费者派任务。

-
测试用例 22.2
消费者延时一秒后,生产者立马把任务写满于环形队列,之后消费每一秒消费一次,生产者每一秒生产一次。

-
九、线程池
对于线程池还会在网络编程部分谈,之前我们还说过内存池这样的概念,现实中也有很多池:如人才池,你去面试,面试官觉得你有点不太适合公司,同时又觉得你技术有很大的潜力,所以就把你的简历放在了人才池中,面试官可能跟 100 个人也是这样对待,人才池存在的根本原因是,如果没有人才池,公司就必须每次都在社会上发布招聘信息,等别人投简历,筛选简历,面试,这样成本太高了;亦或是备胎池,女神在朋友圈说这个包好漂亮,身为备胎的你就去买包给你的女神,女生就不用再去找备胎了,备胎池存在的根本原因是,如果没有备胎池,女生就需要去加备胎的微信,然后发好人卡,这样成本太高了,所以现在就能明白拥有备胎池的人找男女朋友效率是最高的,所谓渣男渣在哪,就是他可以一次联系到多个,这个时候效率是最高的。以前我们申请空间就是你需要了就 malloc 空间,你又需要了就又 malloc 空间,反反复复,而你直接一次性申请反反复复的这些 malloc 的空间,就叫做内存池。我们都知道申请内存是有成本的,它们的区别在于后者相对前者,后者只有一次用户空间到内核空间的切换,所以内存池的作用就是不用频繁的进行用户到内核,内核到用户的切换,进而提高效率,后面我们再写 C++ 高并发内存池时会仔细谈。
同样的,线程池就是一次预先创建一大批线程,让这些线程处于 “待机” 状态,一旦有数据或者任务,直接可以交给线程去处理。预先创建一大批线程的原因是因为创建线程是有成本的。
-
测试用例 23
关于线程池测试案例我们有 4 个文件 (makefile 自动化构建项目,task.hpp 实现任务,thread_pool.hpp 实现线程池,main.cc 用于测试)。
task.hpp 中的任务是实现随机数的加减乘除模运算,这里的 z 定义为 -1 ,那么正常就赋值,错误就把默认值 -1 输出。 thread_pool.hpp 中定义好了一个 ThreadPool 类,并使用了类模板,num 是指线程池中线程的个数,q 是指放取任务的地点,它就是临界资源,所以需要锁来维护互斥关系 (这里提一下,一般互斥量不建议命名 mutex,而命名 lock)。main.cc 中 new 好 ThreadPool 对象且指定 NUM 个线程,使用 Task 类作为模板,然后调用 InitThreadPool() 方法 pthread_create() NUM 个线程,这里在类内创建的线程,并执行类中的 Routine() 方法,其中线程分离,这样线程结束不用等待,也会自动释放资源,其中检测任务、取任务和处理任务,我们都知道会隐藏的在创建类对象时会传入这个对象的地址以区分其它对象,而类方法中也会隐藏的使用一个 this 指针接收,这个指针的类型就是类*,即 ThreadPool*,可是 pthread_create() 方法中调用 Routine 时传入的参数只有一个,所以就会报错,所以 Routine 不能是写成成员函数,而应该 static 修饰为静态成员函数,此时它就没有 this 指针了。然而新的问题是 static 修饰 Routine 后,类中静态成员函数就不能访问任何非静态成员,只能通过对象的方式来进行内部方法或属性的访问,所以当然不可以访问 lock,所以 Routine 应该把 this 指针即对象传入,然后再把 pthread_mutex_lock(&lock) 和 pthread_mutex_unlock(&lock) 封装成成员函数 LockQueue() 和 UnlockQueue() 就可以访问了,此时静态成员方法就可以通过 this 指针去访问成员了,同样检测是否有任务也要封装 IsEmpty(),同样取放任务要封装 Pop Task() 和 Push Task() (前者是静态成员方法下必须封装,后者则是规范)。所以实际想在内中 static 修饰的成员方法中去访问成员方法,首先需要把 this 指针传给静态成员方法。后来拿到任务后就不需要在临界区中处理了,因为一个线程拿到了任务,就代表这个线程已经访问了临界资源了,也就是拿到了队列,这个队列就已经从多线程共享变成了这个线程私有了,而此时这个线程处理任务期间,其它线程就可以继续获取任务,处理任务了。此时线程怎么知道有任务来了,所以就引入条件变量,同样条件变量 pthread_cond_wait() 和 pthread_cond_signal() 要封装 ThreadWait() 和 ThreadWakeup() (前者是在静态成员方法下必须要封装才能访问,后者要封装则是规范) 才可以访问。此时 PushTask() 时也需要锁来保证互斥,push 后就唤醒条件变量。
注意,Task 类中还需要显示的定义一个无参默认构造函数,因为 thread_pool 类中取任务时定义了一个 T t,此时就需要无参默认构造函数。扩展一下 C++ 中的仿函数 (在 C 语言可以通过回调函数处理),我们在 Task 中实现了一个 void operator()() 仿函数,其中调用 Run(),此时在 ThreadPool 中处理任务时就不用再 t.run() 了,直接 t() 即可。
所以这里现象就是主线程创建了一个 5 个新线程的线程池,随后,就休眠 3 秒,期间线程池已经构建完成,3 秒内主线程没有放任务,所以某个新线程就一直带着锁阻塞等待,3 秒后,主线程拿着锁放了第 1 个任务,然后唤醒条件变量,这个新线程就开始拿任务,然后解锁,此时主线程又可以放任务了,这期间这个新线程也在处理任务,反反复复。
makefile:
thread_pool:main.cc g++ $^ -o $@ -std=c++11 -lpthread .PHONY:clean clean: rm -f thread_pooltask.hpp:
#pragma once #include <iostream> #include <pthread.h> using std::cout; using std::endl; class Task { private: int x; int y; char op;//+-*/% public: Task(){}//无参构造一定要显示的有,因为thread_pool中取任务时构建的对象没有参数. Task(int _x, int _y, char _op):x(_x), y(_y), op(_op){} //void operator()()//仿函数 //{ // Run(); //} void Run() { int z = -1;//正常就赋值,错误就默认输出-1. switch(op) { case '+': z = x + y; break; case '-': z = x - y; break; case '*': z = x * y; break; case '/': if(0 != y) z = x / y; else cout << "Warning: div zero!" << endl; break; case '%': if(0 != y) z = x % y; else cout << "Warning: div zero!" << endl; break; default: cout << "unknow operator!" << endl; break; } cout << "thread [" << pthread_self() << "] handler task done: " << x << op << y << "=" << z << endl; } ~Task(){} };thread_pool.hpp:
#pragma once #include <iostream> #include <queue> #include <pthread.h> template <class T> class ThreadPool { private: int num;//线程池中有num个线程 std::queue<T> q;//临界资源,放取任务的地点. pthread_mutex_t lock;//互斥量 pthread_cond_t cond;//条件变量 public: ThreadPool(int _num):num(_num) { pthread_mutex_init(&lock, nullptr); pthread_cond_init(&cond, nullptr); } void LockQueue() { pthread_mutex_lock(&lock); } void UnlockQueue() { pthread_mutex_unlock(&lock); } bool IsEmpty() { return q.size() == 0; } void PopTask(T* out)//这里用&也就把任务带出去了,但是我们还是遵守命名规则. { //取任务 *out = q.front(); q.pop(); } void PushTask(const T& in) { //放任务 LockQueue(); q.push(in); ThreadWakeup(); UnlockQueue(); } void ThreadWait() { pthread_cond_wait(&cond, &lock); } void ThreadWakeup() { pthread_cond_signal(&cond); } static void* Routine(void* args)//ThreadPool* this, void* args { pthread_detach(pthread_self());//线程分离 ThreadPool* tp = (ThreadPool*)args;//强转对象 while(true) { //pthread_mutex_lock(&lock); tp->LockQueue(); //1.检测是否有任务 //if(q.size() == 0) //{} while(tp->IsEmpty()) { //线程等待 //pthread_cond_wait(&cond, &lock); tp->ThreadWait(); } //2.取任务 T t; tp->PopTask(&t); //pthread_mutex_unlock(&lock); tp->UnlockQueue(); //3.处理任务(此时不需要在临界区处理) //t()//仿函数 t.Run(); } } void InitThreadPool() { for(auto i = 0; i < num; i++) { pthread_t tid; pthread_create(&tid, nullptr, Routine, this); } } ~ThreadPool() { pthread_mutex_destroy(&lock); pthread_cond_destroy(&cond); } };main.cc:
#include "thread_pool.hpp" #include "task.hpp" #include <time.h> #include <string> #include <unistd.h> #define NUM 5 int main() { srand((unsigned int)time(nullptr)); ThreadPool<Task>*tp = new ThreadPool<Task>(NUM); tp->InitThreadPool(); sleep(3); const std::string ops = "+-*/%"; while(true) { int x = rand() % 50 + 1;//[1,50] int y = rand() % 50 + 1;//[1,50] char op = ops[rand() % 5];//[0,4] Task t(x, y, op); tp->PushTask(t); sleep(1); } return 0; }
十、线程安全的单例模式
💦 单例模式
单例模式是一种常见的软件设计模式,它保证一个类只能有一个对象,这个对象被保存于一个静态变量中,并提供一个全局访问点来获取这个对象。在很多服务器开发场景中,经常需要让服务器加载上百 G 的数据到内存中,此时往往需要一种单例的类来管理这些数据,否则没有单例,就可能出现大量冗余的数据,所以一般单例对象是很大的。单例模式的实现有多种,其中最常见的就是懒汉式和饿汉式。
💦 设计模式
设计模式代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。它是软件开发人员在软件开发过程中面临的一般问题的解决方案,这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。设计模式是前辈们对代码开发经验的总结,是解决特定问题的一系列套路,它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。IT 行业这么火,林子大了啥鸟都有,大佬和菜鸡们两极分化的越来越严重, 为了让菜鸡们不太拖大佬的后腿,于是大佬们针对一些经典的常见的场景,给定了一些对应的解决方案,这个就是设计模式。
💦 饿汉实现方式和懒汉实现方式
饿汉和懒汉的本质区别就是你这个单例什么时候被创建,也就是什么时候加载单例对象到内存,一般一个单例对象是很大的,是当服务一启动就创建单例,还是等需要的时候再创建单例,这就是饿汉和懒汉存在的意义。比如吃完饭就去洗碗,这是饿汉,而吃完饭,等下次要吃饭时再洗碗,这是懒汉。最常用的是懒汉,其中懒汉的核心思想就是延时加载,从而能够优化服务器的启动速度。
💦 饿汉方式实现单例模式
class Singleton
{
private:
Singleton(){}//构造函数私有化,防止外部new对象.
Singleton(const Singleton&) = delete;//禁止拷贝构造
Singleton& operator = (const Singleton&) = delete;//禁止赋值重载
public:
static Singleton* GetInstance()//生成唯一的实例对象.
{
static Singleton instance;//成功创建单例
return instance;
}
};
💦 懒汉方式实现单例模式
class Singleton
{
private:
static Singleton* instance;//全局访问点
Singleton(){}//构造函数私有化,防止外部new对象.
Singleton(const Singleton&) = delete;//禁止拷贝构造
Singleton& operator = (const Singleton&) = delete;//禁止赋值重载
public:
static Singleton* GetInstance()//根据全局访问点,生成唯一的实例对象.
{
if(nullptr == instance)
instance = new Singleton();//成功创建单例
return instance;
}
};
Singleton* Singleton::instance = nullptr;//定义初始化静态成员变量
💦 懒汉方式实现单例模式(线程安全版本)
class Singleton
{
private:
static Singleton* instance;//全局访问点
static pthread_mutex_t lock;//互斥锁
Singleton(){}//构造函数私有化,防止外部new对象.
Singleton(const Singleton&) = delete;//禁止拷贝构造
Singleton& operator = (const Singleton&) = delete;//禁止赋值重载
public:
static Singleton* GetInstance()//根据全局访问点,生成唯一的实例对象.
{
if(nullptr == instance)
{
pthread_mutex_lock(&lock);
if(nullptr == instance)//双重if判定,避免不必要的锁竞争.
{
instance = new Singleton();//成功创建单例
}
pthread_mutex_unlock(&lock);
}
return instance;
}
};
Singleton* Singleton::instance = nullptr;//定义初始化静态成员变量
pthread_t lock = PTHREAD_MUTEX_INITIALIZER;//定义初始化静态成员变量
-
测试用例 24
懒汉模式改造与设计:类内定义了一个私有的静态的 ThreadPool<T> 类型的 instance 指针,然后需要再在类外初始化。类内定义了一个公有的静态的 get_instance() 方法,其中调用 get_instance() 后 instance 指针为空才创建单例对象,然后返回这个 instance 指针。把构造函数从 public 拿到 private,构造函数一定要有,因为还是得创建对象,再把拷贝构造和赋值重载 delete,因为要防止可能创造出多个实例。构造是 private 了,之前在构造的时候是有线程池个数 num 的,这里就把 num 成员变量去掉,然后将 num 给 InitThreadPool() 方法传参,所以构造函数就不需要再传参了。最后 main.cc 中就不用再那样创建对象了,而是调用 get_instance() 时才创建对象。
线程安全版本懒汉模式改造与设计:当然上面不是线程安全的,因为一开始可能有多个线程同时进入判断,最后导致创建了多个实例。所以需要加锁,如果这个锁是全局或静态的,那么这里定义锁时直接使用 PTHREAD_MUTEX_INITIALIZER 初始化,这样就不用初始化和释放了,此时还有很多线程也要申请时,多个线程就不会同时进入申请实例了,虽然后面的线程都不会创建实例,但是它们会申请锁,这完全没必要,所以再加一层 if 语句判断。注意静态成员 lock 可以直接在 get_instance() 中初始化的原因是因为它在静态成员函数 get_instance() 中,而如果要在 get_instance() 外初始化的话需要在类外,否则会报错。
代码主要流程就是 main.cc 中延时加载了 10 秒后调用 get_instance(),其中 instance 指针为空,然后去 new 这个类调用构造函数,然后赋值给 instance 指针,返回这个指针,然后再赋值给 tp 指针。再由 tp 去调用 InitThreadPool(5),所以就创建了 5 个线程 … …。
makefile:
thread_pool:main.cc g++ $^ -o $@ -std=c++11 -lpthread .PHONY:clean clean: rm -f thread_pooltask.hpp:
#pragma once #include <iostream> #include <pthread.h> using std::cout; using std::endl; class Task { private: int x; int y; char op;//+-*/% public: Task(){} Task(int _x, int _y, char _op):x(_x), y(_y), op(_op){} void Run() { int z = -1; switch(op) { case '+': z = x + y; break; case '-': z = x - y; break; case '*': z = x * y; break; case '/': if(0 != y) z = x / y; else cout << "Warning: div zero!" << endl; break; case '%': if(0 != y) z = x % y; else cout << "Warning: div zero!" << endl; break; default: cout << "unknow operator!" << endl; break; } cout << "thread [" << pthread_self() << "] handler task done: " << x << op << y << "=" << z << endl; } ~Task(){} };thread_pool.hpp:
#pragma once #include <iostream> #include <queue> #include <pthread.h> template <class T> class ThreadPool { private: //int num; std::queue<T> q; //pthread_mutex_t lock; pthread_cond_t cond; private: static ThreadPool<T>* instance;//get_instance()中判断是否单例,且用于保存唯一实例. //static pthread_mutex_t lock;//get_instance()外 //ThreadPool(int _num):num(_num) ThreadPool()//构造方法必须要有,因为要创建对象. { pthread_mutex_init(&lock, nullptr); pthread_cond_init(&cond, nullptr); } ThreadPool(const ThreadPool<T>&) = delete;//禁止拷贝构造 ThreadPool<T>& operator = (const ThreadPool<T>&) = delete;//禁止赋值重载 public: static ThreadPool<T>* get_instance()//生成唯一单例 { //线程不安全版本 //if(nullptr == instance) // instance = new ThreadPool<T>(); //return instance; //线程安全版本 static pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;//如果这个锁是全局或静态的,那么就可以这样初始化,这样就不用初始化和释放了,此时lock还是静态成员变量,而是静态成员函数中的一个静态变量,所以可以不用在类外初始化. if(nullptr == instance)//双重判定空指针,当想第2次申请实例时,就不会再往下申请锁了,提高效率. { pthread_mutex_lock(&lock);//防止一开始多个线程同时进入申请实例 if(nullptr == instance) { instance = new ThreadPool<T>(); } pthread_mutex_unlock(&lock); } return instance; } //ThreadPool(int _num):num(_num) //{ //pthread_mutex_init(&lock, nullptr); //pthread_cond_init(&cond, nullptr); //} void LockQueue() { pthread_mutex_lock(&lock); } void UnlockQueue() { pthread_mutex_unlock(&lock); } bool IsEmpty() { return q.size() == 0; } void PopTask(T* out) { *out = q.front(); q.pop(); } void PushTask(const T& in) { LockQueue(); q.push(in); ThreadWakeup(); UnlockQueue(); } void ThreadWait() { pthread_cond_wait(&cond, &lock); } void ThreadWakeup() { pthread_cond_signal(&cond); } static void* Routine(void* args) { pthread_detach(pthread_self()); ThreadPool* tp = (ThreadPool*)args; while(true) { tp->LockQueue(); while(tp->IsEmpty()) { tp->ThreadWait(); } T t; tp->PopTask(&t); tp->UnlockQueue(); t.Run(); } } //void InitThreadPool() void InitThreadPool(int num) { for(auto i = 0; i < num; i++) { pthread_t tid; pthread_create(&tid, nullptr, Routine, this); } } ~ThreadPool() { pthread_mutex_destroy(&lock); pthread_cond_destroy(&cond); } }; //static的成员变量instance必须在类外定义初始化,初始化时不需要加static,类内只是声明. template<class T> ThreadPool<T>* ThreadPool<T>::instance = nullptr; //template<class T>//需要在类外定义初始化 //pthread_mutex_t ThreadPool<T>::instance = PTHREAD_MUTEX_INITIALIZER;main.cc:
#include "thread_pool.hpp" #include "task.hpp" #include <time.h> #include <string> #include <unistd.h> #define NUM 5 int main() { srand((unsigned int)time(nullptr)); //ThreadPool<Task>*tp = new ThreadPool<Task>(NUM); //tp->InitThreadPool(); sleep(10);//延时加载 ThreadPool<Task>* tp = ThreadPool<Task>::get_instance();//需要了就获取单例 tp->InitThreadPool(5);//初始化 sleep(3); const std::string ops = "+-*/%"; while(true) { int x = rand() % 50 + 1;//[1,50] int y = rand() % 50 + 1;//[1,50] char op = ops[rand() % 5];//[0,4] Task t(x, y, op); tp->PushTask(t); sleep(1); } return 0; }
十一、STL、智能指针和线程安全
💦 STL中的容器是否是线程安全的
STL 中的容器并不是线程安全的,因为 STL 设计的初衷是将性能发挥到极致,而一旦涉及到加锁来保证线程安全,那么就会对性能造成巨大的影响,而且对于不同的容器,加锁方式也不同,性能可能也不同,例如 hash 表中的锁表和锁桶。因此 STL 在实现时并不保证线程安全,如果需要在多线程环境下使用,往往需要调用者自行保证线程安全。
💦 智能指针是否是线程安全的
智能指针的线程安全性因类型而异:对于 unique_ptr,由于只是在当前代码块范围内生效,因此不涉及线程安全的问题;对于 shared_ptr,其读操作是线程安全的,即多个线程可以同时读取同一个 shared_ptr 指向的对象,这是安全的。然而,其写操作 (修改 shared_ptr 指向) 和引用计数的加减操作则是非线程安全的。这意味着当多个线程尝试写入同一个 shared_pt r或同时对一个对象的引用计数进行加减操作时,可能会引发竞态条件和数据竞争。因此,在使用智能指针时,需要特别注意并发访问和修改的情况,避免出现线程安全问题。若需在多线程环境下使用,可以考虑使用互斥锁或其他同步机制来保护共享数据。
十二、其他常见的各种锁
一般在数据库中会经常的听到这些词,而在 Linux 中就是具体的一把锁,之前学过的二元信号量、互斥量其实都是悲观锁。
-
悲观锁:在每次取数据时,总是担心数据会被其它线程修改,所以会在取数据前先加锁 (读锁,写锁,行锁等),当其它线程想要访问数据时,会被阻塞挂起。
-
乐观锁:每次取数据时,总是乐观的认为数据不会被其它线程修改,因此不上锁,但是在更新数据前,会判断其它数据在更新前有没有对数据进行修改。主要采用版本号机制和 CAS 操作 (所谓版本号机制就是一个线程对应一个版本,你修改呗,我也不怕你修改,这样通过版本来区分每一个线程的修改,这个会在后面学数据库时再接触到。而所谓 CAS 操作是 JAVA 上面的概念,当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新,如果不相等,则失败,失败则重试,一般是一个自旋的过程,即不断重试)。
-
自旋锁、读写锁、公平锁、非公平锁。
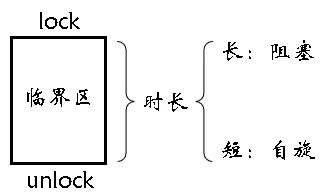
自旋锁其实是一个比较重要的概念,我们谈谈理论再看看系统所提供的相关接口即可。自旋锁的核心机制是利用 CPU 的自旋 (忙等待) 来实现加锁和解锁。当一个线程想要获取已经被其它线程持有的锁时,该线程不会进入阻塞状态,而是持续检测锁是否可用。只有在能够获取到锁的情况下,线程才会停止自旋并继续执行。一旦锁被释放,正在自旋的线程会最优先获得该锁。比如,你打电话叫小美吃饭,小美说我正在写作业,你先在楼下等着,此时若小美只需要 5 分钟就可以把作业写完,那你一定会等,期间可以不断的轮询检测小美的状态,这就是自旋锁自旋检测的过程。但若小美需要 1 个小时才能写完作业,你一定不可能等,而是先去打打篮球,直到小美做完时才打电话叫你去吃饭,这样也是有成本的,本来肚子就饿,对应锁在阻塞时也是有成本的,阻塞时线程要被放在等待队列中,而当条件满足时还需要把这个线程从等待队列放到运行队列中,所以也不是任何场景都适合阻塞的。此时小美需要花多长时间写完作业才去吃饭,决定了你要不要干等。所以锁是要阻塞还是要自旋取决于持有锁的线程在临界区中执行的时长,而究竟是使用阻塞还是自旋,是取决于用户的,因为只有用户知道他自己写的代码,像之前的抢票,采用自旋会更适合。所以自旋锁适用于短时间内的资源互斥,可以避免线程阻塞和消耗,从而具有较高的效率。然而锁被长时间持有或者资源冲突频繁,自旋锁可能会导致 CPU 资源的浪费,甚至可能引发系统崩溃的风险。因此,自旋锁通常用于锁持有时间较短的场景。
#include <pthread.h> int pthread_spin_init(pthread_spinlock_t* lock, int pshared); int pthread_spin_destroy(pthread_spinlock_t* lock); int pthread_spin_lock(pthread_spinlock_t* lock); int pthread_spin_trylock(pthread_spinlock_t* lock); int pthread_spin_unlock(pthread_spinlock_t* lock);可以看到这批接口和我们在上面所认识的接口很类似。实际当我们在调用 spin 自旋锁时,如果没有申请到,虽然它在自旋,但在调用者看来还是在阻塞的现象。
十三、读者写者问题(了解)
在编写多线程时,有一种情况是十分常见的。有些公共数据修改的机会比较少,相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随查找的操作,中间耗时很长,对这种代码加锁,会极大地降低程序的效率,所以读写锁就可以专门处理这种多读少写的情况。注意,写独占,读共享,读锁优先级高。

通常写者有一个特征是读者特别多,写者特别少。在生活中的黑板报,它也符合 “321” 原则:
-
三
三种关系:读者和读者(没有关系)、写者和写者(互斥)、读者和写者(互斥与同步)。
相比之前的生产者消费者模型,这里很意外的是读者和读者是没有关系,因为写者出完黑板报时,不可能说只能你一个读者看,其它读者都闭上眼睛,想看的后面排队去,其实本质是因为读者和读者不会把数据取走,而消费者和消费者会把数据取走,这也是这两种模型的区别,所以读者和读者没有互斥和同步关系。
-
二
两种角色:读者和写者。
-
一
一个交易场所:黑板。
读者写者模型也有相关的接口:
#include <pthread.h>
int pthread_rwlock_init(pthread_rwlock_t* restrict rwlock,const pthread_rwlockattr_t* restrict attr);
int pthread_rwlock_destroy(pthread_rwlock_t* restrict rwlock);
int pthread_rwlock_rdlock(pthread_rwlock_t* rwlock);//读者加锁
int pthread_rwlock_wrlock(pthread_rwlock_t* rwlock);//写者加锁
int pthread_rwlock_unlock(pthread_rwlock_t* rwlock);//读者写者解锁
伪代码实现:

首先读者可能有多个,实际需要有一个 reader_cnt 计数器,而写者之间是互斥关系,所以不需要计数器,多了一个读者就 ++,然后访问临界资源,少了一个读者就 –,++ — 都需要锁来保护。写者中加锁判断是否有读者,如果有就解锁,然后 goto 继续加锁判断是否有读者,如果没有读者就访问临界资源,此时并没有解锁,访问结束后再解锁。这样就维护了写者与写者、读者与写者之间的关系。
上面说读者很多,写者很少,这是根据场景的。这意味着读者长时间在读,写者可能会写饥饿了,相反写者长时间在写,读者也可能读饥饿了。实际读写锁在处理这种问题时,有两种策略:读者优先和写者优先。上面在谈生产者消费者模型时并没有提及谁优先的原因是生产者和消费者它们的地位是对等的、信赖的,就是说生产者把缓冲区生产满了就不能生产了,必须依靠消费者,同样,消费者把缓冲区消费完了就不能再消费了,必须依靠生产者。生产者消费者模型没有优先的问题本质上是因为不管是谁优先,节奏一定会被对方拖慢,所以一定是保证生产和消费的节奏一致,效率才是最高的,所以不谈优先。而读者写者模型就不一样了,读者和写者之间没有像生产者消费者之间那样太大的信赖性,读者和写者本身是互斥的,那么你想让读者读到老的数据还是新的数据,比如写者写好文章后,文章中有错误,然后想让写者赶快更新文章,让读者看到正确的文章,这叫做写者优先。当然也有一些场景想让读者看到老的数据,比如公司中一些新代码不太稳定,所以想让读者先读老的数据,这叫做读者优先。所以读者优先是指读者和写者一起到来时优先让读者申请到锁,注意,“一起到来” 很重要,因为读者早就比写者到来了,你不可能让写者还优先,一定要明白的是优先的本质是不是总是让你先,而是在某一件事情上有冲突,就像常说的女士优先一定是男士和女士在某一件事情上有冲突;而写者优先是指当写者到来的时候,后续读者就暂时不能进入临界资源进行读取了,所有正在读取的线程执行完毕,写者再进入。
-
测试用例 25
因为现象并不明显,所以这个案例不细谈。
#include <vector> #include <sstream> #include <cstdio> #include <cstdlib> #include <cstring> #include <unistd.h> #include <pthread.h> volatile int ticket = 1000; pthread_rwlock_t rwlock; void* reader(void* arg) { char* id = (char*)arg; while(1) { pthread_rwlock_rdlock(&rwlock); if(ticket <= 0) { pthread_rwlock_unlock(&rwlock); break; } printf("%s: %d\n", id, ticket); pthread_rwlock_unlock(&rwlock); usleep(1); } return nullptr; } void* writer(void* arg) { char* id = (char*)arg; while(1) { pthread_rwlock_wrlock(&rwlock); if (ticket <= 0) { pthread_rwlock_unlock(&rwlock); break; } printf("%s: %d\n", id, --ticket); pthread_rwlock_unlock(&rwlock); usleep(1); } return nullptr; } struct ThreadAttr { pthread_t tid; std::string id; }; std::string create_reader_id(std::size_t i) { //利用ostringstream进行string拼接 std::ostringstream oss("thread reader ", std::ios_base::ate); oss << i; return oss.str(); } std::string create_writer_id(std::size_t i) { //利用ostringstream进行string拼接 std::ostringstream oss("thread writer ", std::ios_base::ate); oss << i; return oss.str(); } void init_readers(std::vector<ThreadAttr>& vec) { for (std::size_t i = 0; i < vec.size(); ++i) { vec[i].id = create_reader_id(i); pthread_create(&vec[i].tid, nullptr, reader, (void *)vec[i].id.c_str()); } } void init_writers(std::vector<ThreadAttr>& vec) { for (std::size_t i = 0; i < vec.size(); ++i) { vec[i].id = create_writer_id(i); pthread_create(&vec[i].tid, nullptr, writer, (void *)vec[i].id.c_str()); } } void join_threads(std::vector<ThreadAttr> const& vec) { //我们按创建的逆序来进行线程的回收 for (std::vector<ThreadAttr>::const_reverse_iterator it = vec.rbegin(); it != vec.rend(); ++it) { pthread_t const& tid = it->tid; pthread_join(tid, nullptr); } } void init_rwlock() { #if 0//写优先 pthread_rwlockattr_t attr; pthread_rwlockattr_init(&attr); pthread_rwlockattr_setkind_np(&attr, PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP); pthread_rwlock_init(&rwlock, &attr); pthread_rwlockattr_destroy(&attr); #else//读优先,会造成写饥饿. pthread_rwlock_init(&rwlock, nullptr); #endif } int main() { //测试效果不明显的情况下,可以加大reader_nr. //但也不能太大,超过一定阈值后系统就调度不了主线程了. const std::size_t reader_nr = 1000; const std::size_t writer_nr = 2; std::vector<ThreadAttr> readers(reader_nr); std::vector<ThreadAttr> writers(writer_nr); init_rwlock(); init_readers(readers); init_writers(writers); join_threads(writers); join_threads(readers); pthread_rwlock_destroy(&rwlock); }
写在后面
至此《Linux 系统编程》的最后一章多线程部分就写完了,由于内容量较大,所以建议定期回顾。
文章出处登录后可见!