1.字符串
字符串∶简称为串,是由零个或多个字符组成的有限序列。一般记为![]() 。
。
字符串的长度︰字符串中字符的数目n称为字符串的长度。
空串:零个字符构成的串也称为「空字符串」,它的长度为0,可以表示为” “。
子串∶字符串中任意个连续的字符组成的子序列称为该字符串的「子串」。并且有两种特殊子串,起始于位置为0、长度为k的子串称为「前缀」。而终止于位置n -1、长度为k的子串称为「后缀」。
主串:包含子串的字符串相应的称为「主串」。
举个例子:
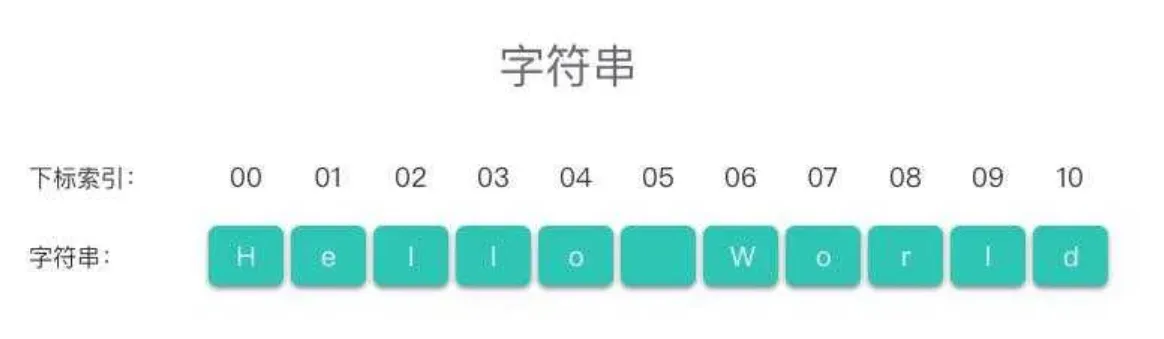
str="Hello world"在示例代码中,str是一个字符串的变量名称,Hello World则是该字符串的值,字符串的长度为11。该字符串的表示如下图所示∶
2.字符串的比较
2.1字符串的比较操作
字符串之间的大小取决于它们按顺序排列字符的前后顺序。比如字符串 str1 = “abc” 和 str2 = “acc”,
它们的第一个字母都是 a,而第二个字母,由于字母 b 比字母 c 要靠前,所以 b < c,于是我们可以
说 “abc” < “acd” ,也可以说 str1 < str2。
字符串之间的比较是通过组成字符串的字符之间的「字符编码」来决定的。而字符编码指的是字符在对
应字符集中的序号。
对于两个不相等的字符串,我们可以以下面的规则定义两个字符串的大小:
从两个字符串的第 0 个位置开始,依次比较对应位置上的字符编码大小。
如果 str1[i] 对应的字符编码等于 str2[i] 对应的字符编码,则比较下一位字符。
如果 str1[i] 对应的字符编码小于 str2[i] 对应的字符编码,则说明 str1 < str2。比如:”abc” <
“acc”。
如果 str1[i] 对应的字符编码大于 str2[i] 对应的字符编码,则说明 str1 > str2。比如:”bcd” >
“bad”。
如果比较到某一个字符串末尾,另一个字符串仍有剩余:
如果字符串 str1 的长度小于字符串 str2,即 len(str1) < len(str2)。则 str1 < str2。比如:”abc” < “abcde”。
如果字符串 str1 的长度大于字符串 str2,即 len(str1) > len(str2)。则 str1 > str2。比如:”abcde” > “abc”。
如果两个字符串每一个位置上的字符对应的字符编码都相等,且长度相同,则说明 str1 == str2,比如:”abcd” == “abcd”。
按照上面的规则,我们可以定义一个 strcmp 方法,并且规定:
当 str1 < str2 时,strcmp 方法返回 -1。
当 str1 == str2 时,strcmp 方法返回 0。
当 str1 > str2 时,strcmp 方法返回 1。
2.2字符串比较代码
def strcmp (str1, str2):
index1, index2 = 0,0
while index1< len(str1 ) and index2< len(str2):
if ord(str1 [index1] )== ord(str2 [ index2 ]):
index1 += 1
index2 += 1
elif ord(str1[ index1])< ord(str2 [index2]):
return -1
else:
return 1
if len (str1)< len(str2) :
return-1
elif len(str1)> len (str2):
return 1
else:
return 02.3字符串的字符编码
以计算机中常用字符使用的 ASCII 编码为例。最早的时候,人们制定了一个包含 127 个字符的编码表
ASCII 到计算机系统中。ASCII 编码表中的字符包含了大小写的英文字母、数字和一些符号。每个字符
对应一个编码,比如大写字母 A 的编码是 65,小写字母 a 的编码是 97。后来又针对特殊字符,将
ASCII 扩展到了 256 位。
ASCII 编码可以解决以英语为主的语言,可是无法满足中文编码。为了解决中文编码,我国制定了
GB2312、GBK、GB18030 等中文编码标准,将中文编译进去。但是世界上有上百种语言和文字,各
国有各国的标准,就会不可避免的产生冲突,于是就有了 Unicode 编码。Unicode 编码最常用的就
是 UTF-8 编码,UTF-8 编码把一个 Unicode 字符根据不同的数字大小编码成 1 ~ 6 个字节,常用的
英文字母被编码成 1 个字节,汉字通常是 3 个字节。
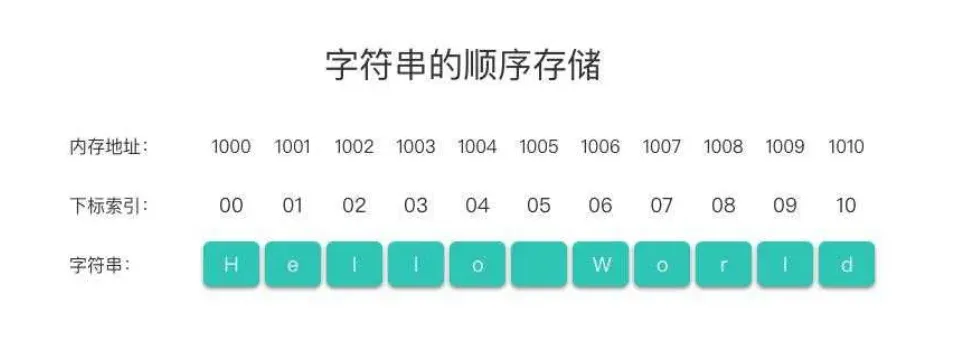
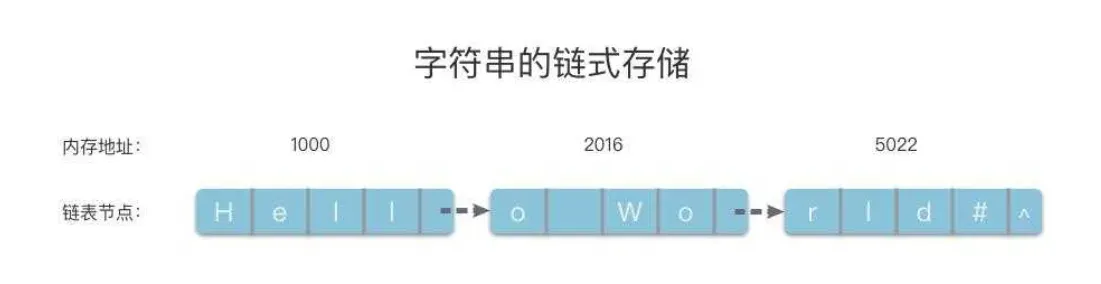
2.4字符串的存储结构
字符串的存储结构跟线性表相同,分为「顺序存储结构」和「链式存储结构」。
3.字符串匹配问题
字符串匹配:又称「模式匹配」。可以简单理解为,给定字符串 T 和 p,在主串 T 中寻找子串 p。主
串 T 又被称为「文本串」,子串 p 又被称为「模式串」。
在字符串问题中,最重要的问题之一就是字符串匹配问题。而按照模式串的个数,我们可以将字符串匹
配问题分为:「单模式串匹配问题」和「多模式串匹配问题」。
3.1单模式串匹配问题
单模式匹配问题︰给定一个文本串T = tt2….tn,再给定一个特定模式串p = PPp2..pn。要求从文本串T找出特定模式串p的所有出现位置。
根据在文本中搜索模式串方式的不同,可以将单模式匹配算法分为以下三种:
基于前缀搜索方法∶在搜索窗口内从前向后(沿着文本的正向)逐个读入文本字符,搜索窗口中文本和模式串的最长公共前缀。著名的KMP算法和更快的 Shift-Or算法使用的就是这种方法。
基于后缀搜索方法:在搜索窗口内从后向前(沿着文本的反向)逐个读入文本字符,搜索窗口中文本和模式串的最长公共后缀。使用这种搜索算法可以跳过一些文本字符,从而具有亚线性的平均时间复杂度。最著名的 BM 算法,以及 Horspool 算法、Sunday 算法都使用了这种方法。
基于子串搜索方法:在搜索窗口内从后向前(沿着文本的反向)逐个读入文本字符,搜索满足「既是窗口中文本的后缀,也是模式串的子串」的最长字符串。与后缀搜索方法一样,使用这种搜索方法也具有亚线性的平均时间复杂度。这种方法的主要缺点在于需要识别模式串的所有子串,这是一个非常复杂的问题。Rabin-Karp 算法、BDM 算法、BNDM 算法 和 BOM 算法使用的就是这种思想。其中,Rabin-Karp 算法使用了基于散列的子串搜索算法。
3.2多模式串匹配问题
多模式匹配问题∶给定一个文本串![]() ,再给定一组模式串
,再给定一组模式串![]() ,其中每个模式串
,其中每个模式串![]() 是定义在有限字母表上的字符串
是定义在有限字母表上的字符串![]() 。要求从文本串T中找到模式串集合Р中所有模式串
。要求从文本串T中找到模式串集合Р中所有模式串![]() 的所有出现位置。
的所有出现位置。
模式串集合Р中的一些字符串可能是集合中其他字符串的子串、前缀、后缀,或者完全相等。解决多模式串匹配问题最简单的方法是利用「单模式串匹配算法」搜索r遍。这将导致预处理阶段的最坏时间复杂度为![]() ,搜索阶段的最坏时间复杂度为
,搜索阶段的最坏时间复杂度为![]() 。
。
如果使用「单模式串匹配算法」解决多模式匹配问题,那么根据在文本中搜索模式串方式的不同,我们也可以将多模式串匹配算法分为以下三种∶
基于前缀搜索方法∶搜索从前向后(沿着文本的正向)进行,逐个读入文本字符,使用在P上构建的自动机进行识别。对于每个文本位置,计算既是已读入文本的后缀,同时也是P中某个模式串的前缀的最长字符串。著名的AC自动机算法、Multiple Shift-And算法使用的这种方法。
基于后缀搜索方法∶搜索从后向前(沿着文本的反向)进行,搜索模式串的后缀。根据后缀的下一次出现位置来移动当前文本位置。这种方法可以避免读入所有的文本字符。Set Horspool算法、wu-Manber算法使用了这种方法。
基于子串搜索方法︰搜索从后向前(沿着文本的反向)进行,在模式串的长度为min(len(p’))的前缀中搜索子串,以此决定当前文本位置的移动。这种方法也可以避免读入所有的文本字符。Multiple BNDM算法、SBDM算法、SBOM算法都使用了这种方法。
文章出处登录后可见!