一、缺陷检测任务
缺陷检测的任务通常可以分为三个主要阶段,包括缺陷分类、缺陷定位和缺陷分割。
1.缺陷分类
缺陷分类是检测过程的第一步,目的是将检测到的缺陷区域分类为不同的类别,通常是根据缺陷的性质或类型进行分类。分类的类别包括异色、空洞和经线。这一阶段的目标是确定缺陷的类型,以便后续的处理。
2.缺陷定位
缺陷定位是在确定缺陷的类型的基础上,进一步标注出缺陷在图像中的准确位置。这意味着需要在图像中识别出缺陷所在的区域,通常以边界框或者图像中心点的相对位置进行表示。缺陷定位为后续的处理提供了关键信息,使得可以进一步分析缺陷的尺寸、形状和位置。
3.缺陷分割:
缺陷分割是逐像素地将缺陷从背景中分离出来,形成缺陷区域的精确掩膜。通常涉及使用图像分割算法,如语义分割或实例分割,以将缺陷与周围背景分开。这允许更详细的分析和处理缺陷区域。
二、缺陷检测方法
1. 有监督方法
有监督方法通常需要带有标签的训练数据,这些标签包括缺陷的类别、位置等信息。在这种方法中,模型在训练阶段使用带有标签的数据来学习缺陷的特征和模式。这意味着模型知道什么是正常和异常的图像区域,并且可以进行分类、定位和分割缺陷。有监督方法通常在数据标注充分的情况下效果很好,但需要大量标记的数据。
2. 无监督方法
无监督方法不依赖于带有标签的训练数据,而是依赖于对正常数据的学习。模型通过学习正常区域的特征和分布来检测异常。这种方法在处理大规模数据或者缺乏带有标签的数据时非常有用。无监督方法可以自动检测与正常情况不符的异常情况,但对于不同类型的缺陷可能表现不如有监督方法。
3.算法比较
选择哪种方法通常取决于数据的可用性和问题的性质。如果有足够的标记数据和明确定义的缺陷类别,有监督方法通常是更可靠的选择。无监督方法可以用于发现未知的异常情况,但可能会产生误报,因为它无法准确区分不同类型的缺陷。
有时候,也可以结合这两种方法,例如使用有监督方法来识别已知类型的缺陷,并使用无监督方法来检测未知类型的异常。这种混合方法可以提高缺陷检测的鲁棒性
三、识别网络
1. 目标识别网络
目标检测是计算机视觉领域中的核心任务,它旨在确定图像中目标的位置和类别。基于深度学习的目标检测方法通常可分为两大类:两阶段(two-stage)网络和一阶段(one-stage)网络,它们在结构和工作原理上有一些关键差异。
-
两阶段网络(以Faster R-CNN为代表):
两阶段网络的主要特点是分为两个阶段:首先,生成候选框(即提出框或区域建议),然后在这些候选框上进行目标检测。这些网络通常包括两个主要组件:区域提出网络(Region Proposal Network,RPN)和目标检测网络。RPN负责生成可能包含目标的候选框,并将它们提供给目标检测网络,进一步进行分类和定位。两阶段网络通常在准确性上表现出色,特别是对于小目标或密集目标的检测。然而,其计算复杂度较高,速度相对较慢。 -
一阶段网络(以SSD或YOLO为代表):
一阶段网络直接利用深度卷积神经网络中提取的特征图来同时预测目标的位置和类别,而无需额外的候选框生成步骤。这些网络通常更快速,适用于实时应用,但在目标小而密集的情况下可能会失去一些准确性。SSD(Single Shot MultiBox Detector)和 YOLO(You Only Look Once)是一阶段网络的代表,它们通过密集地分析图像中的多个位置来检测目标。
选择两阶段还是一阶段网络通常取决于应用需求。两阶段网络在准确性上具有优势,适用于要求高准确性的任务,例如医学影像或自动驾驶。一阶段网络更适合要求实时性能的应用,如实时物体检测和跟踪。此外,还有一些改进型的网络结构和混合型方法,旨在兼顾准确性和速度,以满足不同的应用场景。
2.小目标检测问题
在工业表面缺陷检测中,面临的最大的问题是部分缺陷偏小,因为小尺寸的缺陷通常在图像中具有低信噪比,难以精确检测,引入以下的几种办法,可以对小目标检测进行优化:
-
特征金字塔结构:
特征金字塔结构允许网络在不同尺度下检测目标,从而提高多尺度检测的准确率。这可以通过在网络中引入多尺度的特征图来实现,使网络能够同时处理不同大小的目标。 -
图像尺寸放大:
增加图像尺寸可以使小目标变得更大,从而提高它们的可检测性。这通常需要在训练和测试期间对图像进行插值或重采样,以增加分辨率。然而,需要注意的是,这可能会增加计算成本。 -
ROI Align替代ROI Pooling:
ROI Align 是一种精确的感兴趣区域(ROI)池化方法,可以在较小的目标上提供更准确的特征。与传统的ROI Pooling 不同,ROI Align 考虑了像素级的插值,提高了对小目标的精确性。
- 超分辨率技术:
使用生成对抗网络(GAN)或其他超分辨率技术,可以将小目标的特征图增强到更高分辨率。这可以帮助网络更好地捕捉小目标的特征,从而提高检测准确性。
四、分割网络
分割网络在表面缺陷检测任务中是将任务转化为对缺陷与正常区域进行语义分割,甚至实例分割。这种方法不仅可以提供精细的缺陷区域分割,还能够获取缺陷的位置、类别以及多个几何属性,如长度、宽度、面积、轮廓、中心等。FCN 和 Mask R-CNN常被应用在表面缺陷中:
1.FCN (Fully Convolutional Networks)
FCN 是一种语义分割方法,它将卷积神经网络(CNN)扩展为全卷积结构,以便能够对输入图像的每个像素进行标签预测。这使得它适用于像表面缺陷检测这样的任务,其中需要对每个像素进行分类,确定它属于正常区域还是缺陷区域,以及缺陷的类别。FCN方法在图像分割领域具有较好的性能,并且可以用于多类别和多尺度的分割任务。
2. Mask R-CNN
Mask R-CNN 是一种实例分割方法,它是 Faster R-CNN 的扩展,除了检测目标,还能够生成每个目标的精确分割掩膜。这使其在缺陷检测任务中非常有用,因为它不仅可以提供缺陷的位置和类别,还能够提供每个缺陷的精确分割掩膜。Mask R-CNN 可以应对多个实例的分割,并且在处理小目标时也表现出色。
3. Yolov5/8实例分割:
在YOLOv5/8中,实例分割方法与传统的实例分割方法(Mask R-CNN)存在明显区别。它采用了不同的方法,以实现实例分割的功能。
主要区别包括:
-
输入特征图选择:
YOLOv5/8中,实例分割采用了Head1中尺寸最大的特征图作为Mask分支的输入。这个选择通常有助于更好地保留目标的细节信息。 -
Mask 生成:
通过 proto_pred 卷积层的处理,YOLOv5/8生成了形状为 (B, mask_channel, H, W) 的 mask_feature。这些掩膜特征用于后续的实例分割。 -
检测框预测分支:
YOLOv5/8的检测框预测分支与标准的YOLOv5 Head结构基本相同,但它在特征图通道上增加了参数,用于生成实例分割所需的掩膜信息。这些参数的数量与 proto_pred 输出的 mask_channel 相同。 -
分割过程:
在分割过程中,首先使用非极大值抑制(NMS)来筛选最终的检测框。接下来,从这些检测框中选择相应数量的掩模参数(coeffs),然后将它们与 mask_feature 相乘并加权,以获得最终的实例分割结果。
五、算法选择
1.使用场景分析
在制造业中,小缺陷的检测是一个具有挑战性的问题,因为它们通常具有较少的像素覆盖,缺乏足够的关注和语义信息。现有的卷积检测方法忽视了上下文的长程依赖,并且缺乏自适应融合策略来利用异构特征。
深度学习方法在检测小缺陷时通常表现较差,因为少数像素的覆盖缺乏细节,如异常值、边缘和纹理,导致语义不足和感知困难。此外,来自实际工业环境的图像通常受到背景光反射、模糊和污垢等污染,使得难以从背景中区分轮廓并专注于小缺陷。
2.YoloV8
2.1.算法简介
Yolov8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
Yolov8各种指标全面超越现有对象检测与实例分割模型,Yolov8主要借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,其本身创新点不多,偏重在工程实践上,具体创新如下:
- 提供了一个全新的SOTA模型(包括P5 640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型)。并且,基于缩放系数提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求。
- Backbone:同样借鉴了CSP模块思想,不过将Yolov5中的C3模块替换成了C2f模块,实现了进一步轻量化,同时沿用Yolov5中的SPPF模块,并对不同尺度的模型进行精心微调,不再是无脑式一套参数用于所有模型,大幅提升了模型性能。
- Neck:继续使用PAN的思想,但是通过对比Yolov5与Yolov8的结构图可以看到,Yolov8移除了1*1降采样层。
- Head部分相比Yolov5改动较大,Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
- Loss计算:使用VFL Loss作为分类损失(实际训练中使用BCE Loss);使用DFL Loss+CIOU Loss作为回归损失。
标签分配:Yolov8抛弃了以往的IoU分配或者单边比例的分配方式,而是采用Task-Aligned Assigner正负样本分配策略。
2.2.算法改进
在表面缺陷检测中测试,现有的Yolov8的目标检测与目标分割对小目标的处理并不理想,但引入BIFPN层之后,算法在小目标检测方面有了很大的提升。BIFPN是Google Brain《EfficientDet: Scalable and Efficient Object Detection》提出。
BIFPN原理介绍:
BIFPN是一种特征金字塔网络,它能够自适应地融合不同尺度的特征并进行上下文信息的传递。通过使用BIFPN,可以提高Yolov8对
小目标的检测精度。
- 特征金字塔网络(FPN)
特征金字塔网络是一种常用的目标检测算法中的模块,它通过自上而下和自下而上的方式融合来自不同层级的特征。这种设计可以提供多尺度的特征表示,从而使得算法能够在不同大小的目标上进行检测。 - 双向特征金字塔网络(BiFPN)
传统的特征金字塔网络在融合特征时只使用了上采样和下采样的操作,而没有引入跳跃连接。受到残差网络的启发,BiFPN引入了跳跃连接,使特征在不同层级之间可以直接传递。这种设计可以更好地保留高层级和低层级特征的语义信息。 - 加权双向特征金字塔网络(BIFPN)
BIFPN在BiFPN的基础上进行了改进,引入了特征金字塔网络中的特征融合操作。具体而言,BIFPN在每个融合节点处引入了一个权重系数,用于控制特征的融合程度。这种设计可以使得网络能够更灵活地适应不同大小目标的检测需求。
下图表示各类网络模型的结构:
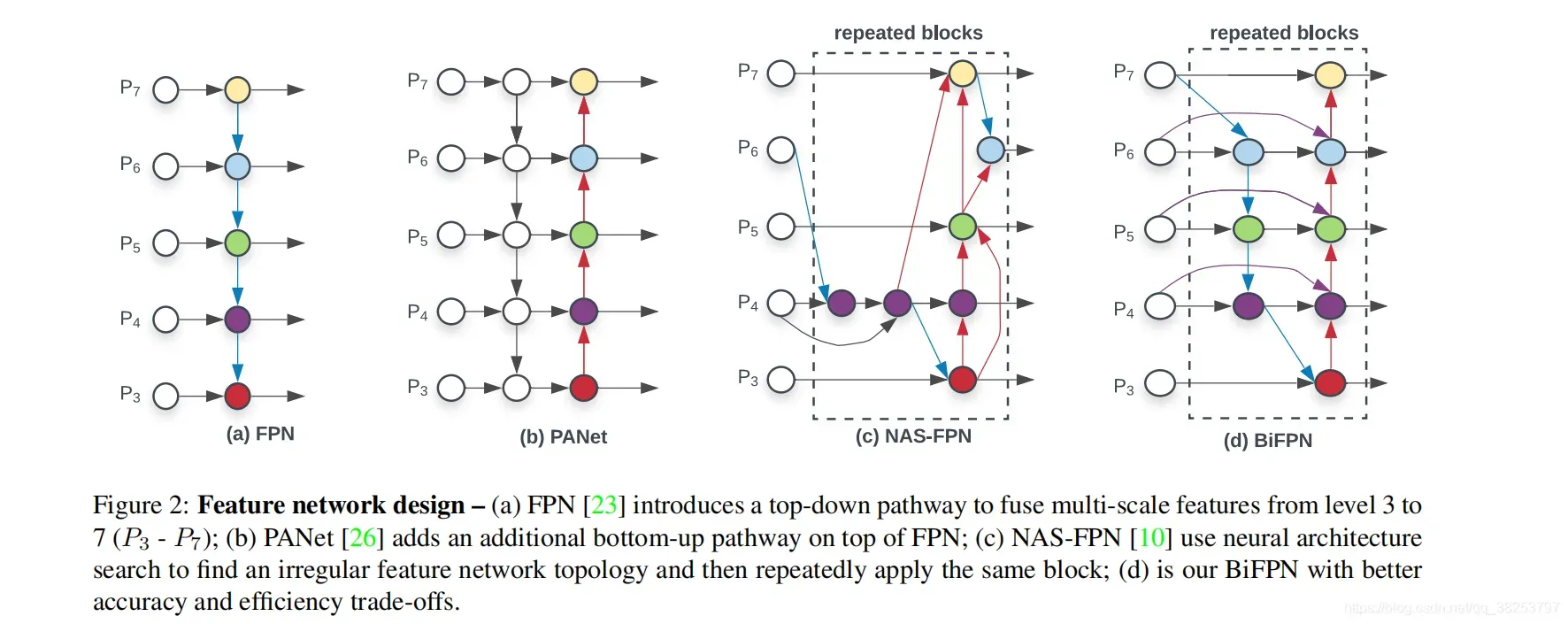
( a ) FPN 引入自上而下的路径来融合从 3 级到 7 级(P3 ‑ P7)的多尺度特征;
( b ) PANet 在 FPN 之上添加了一个额外的自下而上的路径;
( c ) NAS‑FPN 使用神经架构搜索找到不规则的特征网络拓扑,然后重复应用相同的块;
( d ) BiFPN 双向跨尺度连接和加权特征融合,具有更好的准确性和效率权衡。
3.CANet网络
从现有的样本分析,能满足当前的应用场景,可以找到CANet这篇论文:CANet: Contextual Information and Spatial Attention Based Network for Detecting Small Defects in Manufacturing Industry。
CANet是为制造业表面小缺陷而设计的网络。CANet提出发两个针对小目标的解决优化方案:
1、提出了一种基于注意力和上下文建模的网络架构,名为CANet,用于准确检测工业检测中的小缺陷。该网络通过建立远程依赖性和自适应融合来增强特征感知能力,并通过空间注意力编码器和上下文块解码器来重建远程依赖性和聚合上下文信息;
2、提出了一种改进的特征金字塔网络(LaplacianFPN),通过考虑不同层级的多尺度特征的一致性和异质性,实现了非破坏性信息融合。这种融合策略解决了在利用纹理和语义信息检测小缺陷时出现的特征冲突问题。
3.1、研究方法:
CANet提出了一种基于上下文信息和空间注意力的网络,利用空间长程依赖性和上下文信息进行非破坏性多尺度特征融合,来增强图像中小尺寸缺陷的感知能力。如图1所示,网络主要由4个阶段的特征提取器组成,每个阶段由一个CA块构成。在每个CA块中,使用空间注意力编码器(SAE)和上下文块解码器(CBD)来增强对小缺陷的感知能力。然后,将输出馈送到LaplacianFPN,其中使用一致性和异质性融合(CH)模块来自适应融合级别相邻的特征。最后,输出的共享特征通过标准的RPN和RCNN头部进行检测。
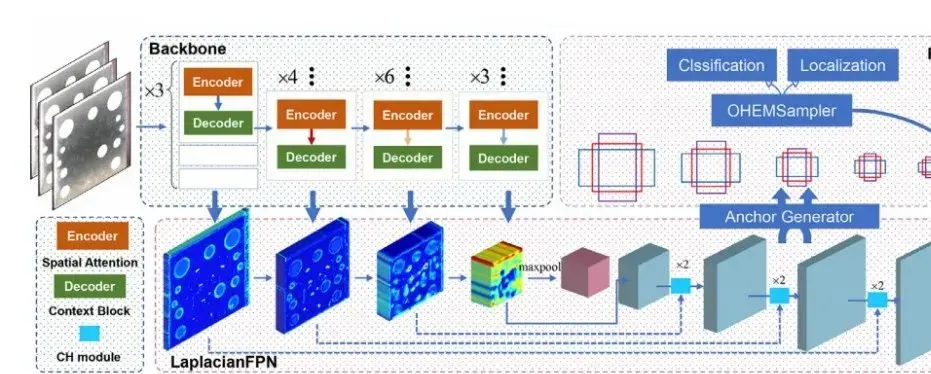
空间注意力编码器(SAE)部分如图2所示,给定一个输入特征X,SAE 首先执行步幅为 2 的平均池化以缩小空间维度。然后通过简化的多重对查询Q、键K和值V执行空间编码头注意,为了实现高效的空间编码,并且降低计算复杂度,本文通过扩展从均匀分布采样的向量p 来生成查询矩阵,而不是经验注意力中特征的卷积。然后,重新映射的Q、K和V都被展平并馈入注意力编码器。注意力编码器通过缩放的点积权重将查询和一组键值对映射到输出。
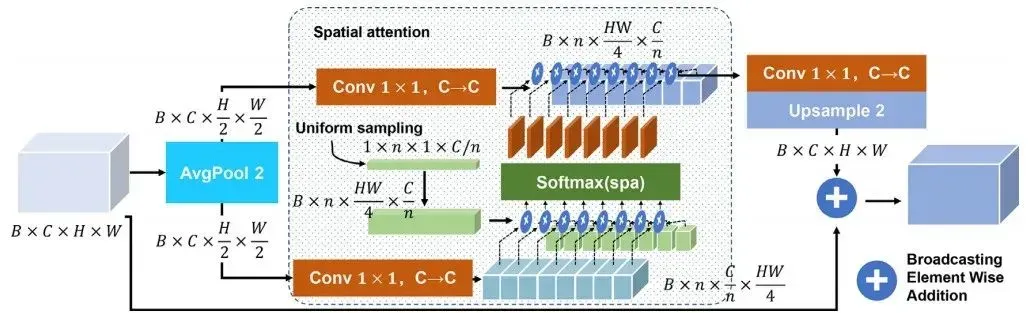
上下文块(CBD)如图3所示,用于在瓶颈之后解码和聚合上下文信息。上下文块首先将特征通道缩小到1,通过1×1卷积形成空间概率图 ;然后将获得的概率图展平,然后输入到 softmax 函数中,沿空间维度 H 和 W 进行概率归一化。最后经过层归一化、ReLU 和具有类似残差连接的卷积之后,生成具有聚合上下文信息作为通道特定偏差的解码输出。
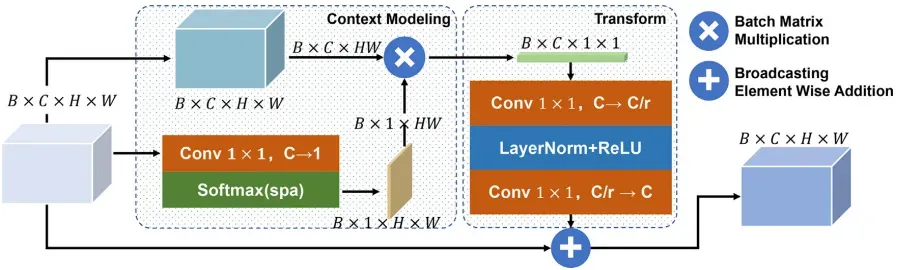
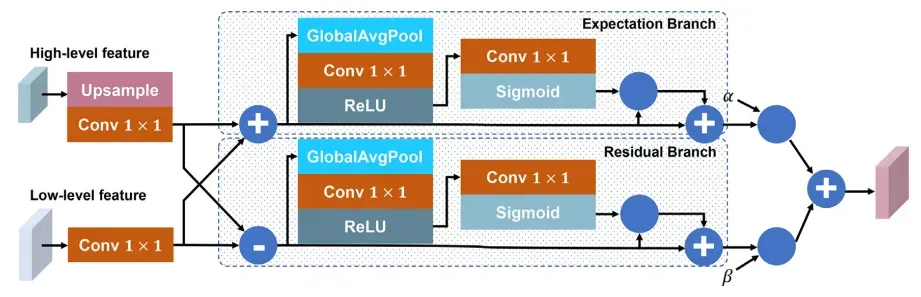
基于一致性和异质性的融合模块(CH)和LaplacianFPN如图4和图5所示,CH模块通过两个并行的期望和残差分支同时对多尺度特征的一致性和异质性进行建模。由于异质性反映了上采样的高层特征与相邻低层特征之间的层次差异,这类似于拉普拉斯金字塔的基本原理,因此本文将设计的基于CH的FPN命名为LaplacianFPN。
对于CH模块,给定一个低级特征 Fl和一个高级特征 Fh,CH 模块首先对齐它们的空间通过对高级特征进行 2× 上采样来调整大小,然后对其进行 1 × 1 卷积。然后期望和残差分支并行地对一致性和异质性进行建模。
对于CH模块,给定一个低级特征 Fl和一个高级特征 Fh,CH 模块首先对齐它们的空间通过对高级特征进行 2× 上采样来调整大小,然后对其进行 1 × 1 卷积。然后期望和残差分支并行地对一致性和异质性进行建模。
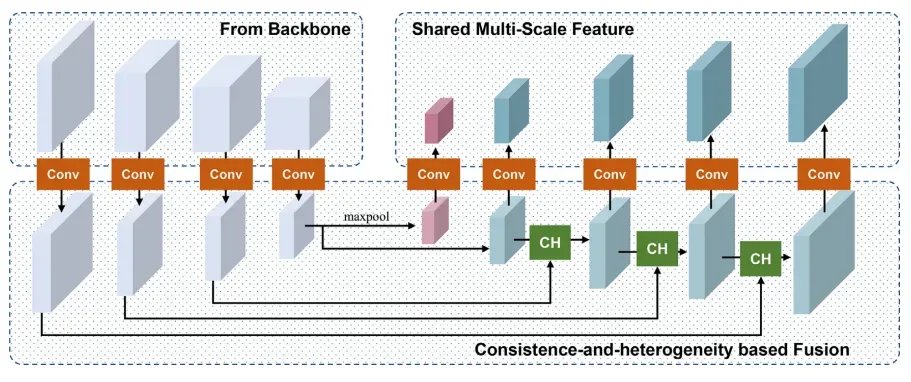
对于LaplacianFPN,主干提取的特征定义为{C2,C3,C4,C5},它们将被输入到颈部LaplacianFPN中进行多尺度融合并产生{P2,P3,P4,P5,P6}。其中,在自上而下的路径中,{P2,P3,P4,P5}是通过CH模块中相应的自下而上层的横向连接产生的,而额外的最高级别P6是通过C5的直接最大池化得到的。
论文的实验部分将提出的CANet部署在NEU-DET和自建 ESD 数据集上进行性能评估。其中,NEU-DET是一个开放的缺陷检测数据集,包含热轧钢板缺陷的六种类型,包括裂纹、夹杂物、斑块、麻点表面、卷入氧化皮和划痕,每种类型有300张图像。总共有4189 个带注释的 groundtruth框。ESD数据集是从真实的工业环境中收集的,由497张图像组成,分辨率为3620×3700。手动标记的缺陷实例有6075个,属于划痕和斑点2类。
论文将CANet与其他先进的方法在NEU-DET数据集上定量进行比较,结果如表1(a)所示。在NEU-DET数据集中,对于银纹和卷入氧化皮这样的硬缺陷,检测起来更具挑战性,即使对于此类缺陷,本文提出的方法也能产生平衡或有竞争力的结果(银纹和卷入氧化皮分别为 47.0%、59.7%),这证明了检测硬缺陷的有效性。对于ESD数据集, CANet 优于所有其他方法,对于小物体实现了45.7% mAP、88.7% mAP50、20.6% mAPs,分别比同行提高了 1.2%、1.8%、4.7% 。
从论文给出的实验可以看出,CANet有效地注意到了与背景无法区分且受到灰尘、方向等环境污染严重的区域的斑点,并实现了准确的定位和分类,对于大多数缺陷的置信度高于95%。此外,CANet 能够检测被污垢背景严重模糊的划痕、极小尺寸的划痕和斑点、上下文无法区分的缺陷和浅划痕。与其他方法相比,CANet 还平衡了更高的类别置信度和更少的小缺陷漏检。
然后,本文通过消融实验,验证了本文提出的CAblock和LaplacianFPN两个主要模块对于CANet整体的性能的影响,结果表明本文提出的两个模块对于检测工业微小缺陷都有重要贡献。
最后,为了防止模型的过拟合风险,以及增强数据的可信度,本文对 NEU-DET 和 ESD 进行了 5 折交叉验证,结果如表2所示。值得注意的是,我们的 CANet 在具有更多小尺寸缺陷的 ESD 上比 NEU-DET 表现出更大的改进(与 SSD512、Faster RCNN、Faster RCNN 和 Res2Net 相比分别提高了 11.24%、4.82% 和 1.5%)。这表明CANet在提取和利用小缺陷的语义方面更加有效。
3.2、结论:
论文提出了一种用于工业中的微小缺陷检测的CANet。它利用上下文信息和空间注意力来增强对小缺陷的感知能力。CANet 的基本模块 CAblock 集成了空间注意力编码器 (SAE) 和上下文块解码器 (CBD)分别对空间长程依赖性进行编码,并将上下文信息解码为通道特定偏差。此外,我们还提出了基于并行双分支融合策略的 LaplacianFPN,以在考虑一致性和异质性的基础上自适应地聚合多尺度特征。在 NEU-DET 基准和自建 ESD 数据集上进行的实验证明了 CAblock 和 LaplacianFPN 的有效性,以及 CANet 相对于最先进方法的优越性能。它为准确检测工业中的小缺陷检测提供了可行的解决方案。然而,该方法在计算成本、推理速度和内存限制等方面存在局限性,因此不适合有高速要求的环境。
文章出处登录后可见!