文章目录
不同参数量下算力需求
| 模型参数量(亿) | 数据量 | 并行卡数(如A100) | 时间(天) | 算力(P/天) | |
|---|---|---|---|---|---|
| 1 | 10 | 300 billion token | 12 | 40 | 312Tx12=3.7P; |
| 2 | 100 | 300 billion token | 128 | 40 | 312Tx128=40P; |
| 3 | 1000 | 1 trillion token | 2048 | 60 | 312Tx2048=638P; |
| 4 |
典型大模型下算力需求
| 模型参数量(亿) | 数据量 | 时间(天) | 算力(P/天) | 金额 | |
|---|---|---|---|---|---|
| 盘古 | 2.6B | 600G | 3 | 110 | |
| 盘古 | 13B | 600G | 7 | 110 | |
| ChatGPT | 13 | 300 billion token | 27.5 | 27.5 | 一次模型训练成本超过1200万美元 |
| GPT-3 XL | 13 | 300 billion token | 27.5 | 27.5 | |
| GPT-3 | 1746 | 300 billion token | 1 | 3640 | 一次模型训练成本超过460万美元 |
| GPT-3.5 | 1 | 3640 |
注:ChatGPT训练所用的模型是基于13亿参数的GPT-3.5模型微调而来
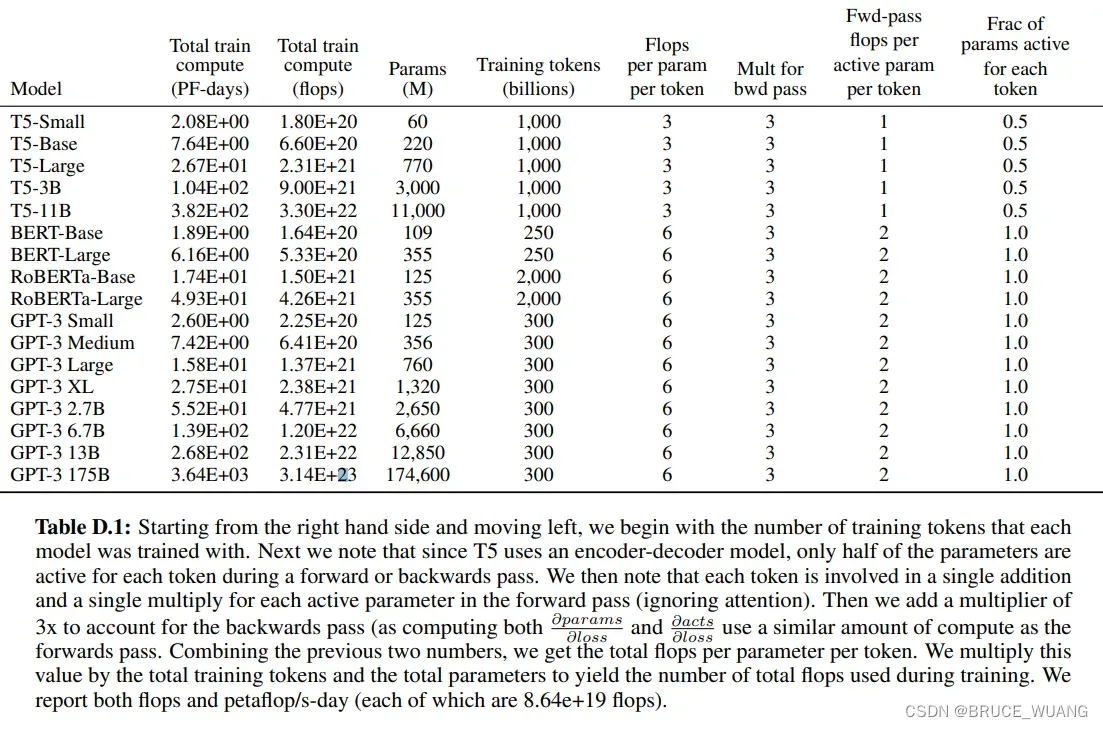
来源:https://arxiv.org/abs/2005.14165
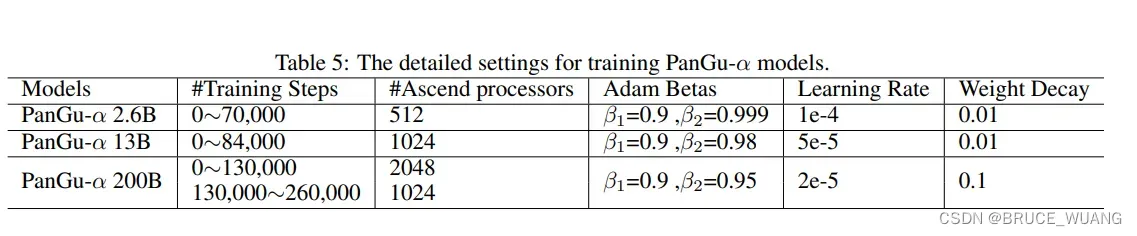
来源:https://arxiv.org/abs/2104.12369

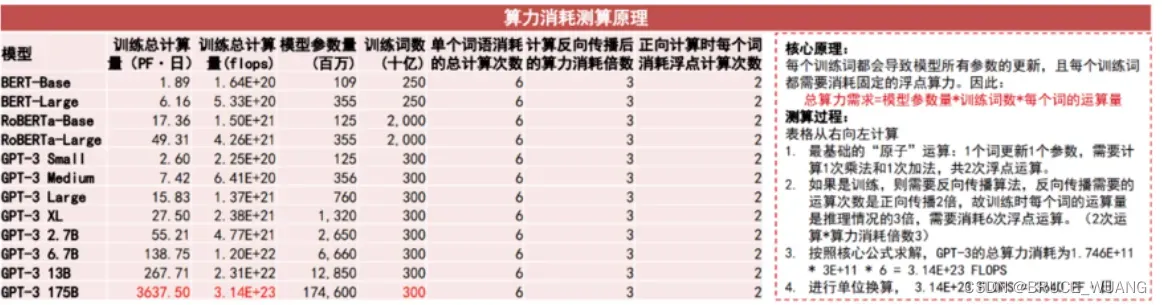
常见小模型参数量
来源: https://github.com/Lyken17/pytorch-OpCounter
| Model | Params(M) | MACs(G) |
|---|---|---|
| alexnet | 61.10 | 0.77 |
| vgg11 | 132.86 | 7.74 |
| vgg11_bn | 132.87 | 7.77 |
| vgg13 | 133.05 | 11.44 |
| vgg13_bn | 133.05 | 11.49 |
| vgg16 | 138.36 | 15.61 |
| vgg16_bn | 138.37 | 15.66 |
| vgg19 | 143.67 | 19.77 |
| vgg19_bn | 143.68 | 19.83 |
| resnet18 | 11.69 | 1.82 |
| resnet34 | 21.80 | 3.68 |
| resnet50 | 25.56 | 4.14 |
| resnet101 | 44.55 | 7.87 |
| resnet152 | 60.19 | 11.61 |
| wide_resnet101_2 | 126.89 | 22.84 |
| wide_resnet50_2 | 68.88 | 11.46 |
| Model | Params(M) | MACs(G) |
|---|---|---|
| resnext50_32x4d | 25.03 | 4.29 |
| resnext101_32x8d | 88.79 | 16.54 |
| densenet121 | 7.98 | 2.90 |
| densenet161 | 28.68 | 7.85 |
| densenet169 | 14.15 | 3.44 |
| densenet201 | 20.01 | 4.39 |
| squeezenet1_0 | 1.25 | 0.82 |
| squeezenet1_1 | 1.24 | 0.35 |
| mnasnet0_5 | 2.22 | 0.14 |
| mnasnet0_75 | 3.17 | 0.24 |
| mnasnet1_0 | 4.38 | 0.34 |
| mnasnet1_3 | 6.28 | 0.53 |
| mobilenet_v2 | 3.50 | 0.33 |
| shufflenet_v2_x0_5 | 1.37 | 0.05 |
| shufflenet_v2_x1_0 | 2.28 | 0.15 |
| shufflenet_v2_x1_5 | 3.50 | 0.31 |
| shufflenet_v2_x2_0 | 7.39 | 0.60 |
| inception_v3 | 27.16 | 5.75 |
推理训练算力需求分析
训练
主要以机器视觉应用使能人工智能算力分析为课题,其中的视觉能力训练平台、图像增强模型、目标检测、图像分割、人员跟踪需求。
对人工智能算力需求计算过程如下:
参考业界流行的视频训练算法(表一、第四章),训练一个模型需要2560TFLOPS FP16算力(8卡/周,单卡算力为320 TFLOPS FP16),运算时间为7天左右,且通常需要训练大于8~10次才能找到一个满意的模型。
考虑2天的调测,安装和模型更新时间,则一个模型的训练周一为10天。
综上,至少需占用要2560*8=20480 TFLOPS FP16算力,才能在10天内找到一个满意的训练模型;
按照目标检测,分割,跟踪等常规模型统计,预计一年有30+任务需要分别训练;总算力需求20PFLOPS FP16。
| 序号 | 算法分类 | 算法需求 | 模型参考 | 数据量参考 | 所需算力 (TFLOPS FP16) | 训练时间/周 | 训练次数 |
|---|---|---|---|---|---|---|---|
| 1 | 视频异常检测 | CLAWS | >200G视频数据 | 20480 | 1 | 10 | |
| 2 | 视频异常检测 | C3D | 20480 | 1 | 10 | ||
| 3 | 视频活动分析 | SlowFast | 20480 | 1 | 10 | ||
| 4 | 视频活动分析 | AlphAction | 20480 | 1 | 10 | ||
| 5 | 图像分类基础网络 | ResNet系列:resnet18, resnet34, resnet50, resnet101 | resnet50, | ImageNet, ~150G图片 | 2560 | 1 | 8 |
| 6 | MobileNet系列:MobileNetV1, MobileNetV2, MobileNetV3 | mobilenetv2, | 2560 | 1 | 8 | ||
| 7 | 人脸识别算法 | 图像分类Backbone,FaceNet | FaceNet NN1, | MS-Celeb-1M LFW, 1万+张图片 Adience, 2万+张图片 Color FERET, 1万+张图片 | 2560 | 1 | 8 |
| 8 | 目标检测 | 一阶段:SSD,yolo系列:yolov3, yolov4, yolov5 | YOLOv3-608, | COCO 2017, >25F数据 | 2560 | 1 | 8 |
| 9 | 二阶段:FasterRCNN | faster rcnn + resnet101, | 2560 | 1 | 8 | ||
| 10 | 分割算法 | yolact, yolact++(unet、unet++) | maskrcnn+resnet50 fpn, | 2560 | 1 | 8 | |
| 11 | MaskRCNN | 2560 | 1 | 8 | |||
| 12 | 人员跟踪 | DensePeds | 100G图片 | 2560 | 1 | 8 | |
| 13 | 底层图像增强 | CycleGAN等 | >10G视频数据 | 2560 | 1 | 8 | |
| 14 | 维护预测算法 | >1G数据 | 2560 | 1 | 8 | ||
| 15 | 洗煤优化算法 | >1G数据 | 2560 | 1 | 8 |
推理
推理服务器算力资源:采用适合张量计算的创新人工智能芯片架构,提供高性能视频解析能力和人工智能算力,用于AI应用场景人工智能算法的推理,系统支持3000路视频流解析;
基于昇腾芯片的AI推理卡,主要用于视频对象和行为分析,需要从视频流中提取对象和行为数据,每块AI推理卡的算力为88T(INT8)。
不同的算法模型对计算能力的要求不同,对于视频分析场景,通过业界主流ISV在该AI推理卡的测试结果来看,在每路视频的分辨率为不低于1080P,帧率不低于25帧,同屏检测目标数不低于5个的情况下,每路视频需要5.5T(INT8)的算力进行解析。单张AI推理卡算力为88T(INT8),所以每张推理卡可支持16路视频的分析。
如当前业务需要接入3000路视频的需求来计算,共需要的AI推理卡的数量为:3000/16≈188块。考虑到数据加工集群建模的并行效率(一般集群的并行效率为90%左右),留出适当的资源后需要的NPU卡的数量为:188/0.9≈209块。
参考
1、https://arxiv.org/abs/2005.14165
文章出处登录后可见!