LLMs-入门二:基于google云端Colab部署Llama 2
- 1、访问网址
- 2、基础概念
- 3、选择最适合您的 Colab 方案
- 4、基于Colab部署开源模型Llama 2
- 1)在Colab上安装huggingface套件
- 2)申请调用llama2的权限
- 方法一:登录huggingface获取token方式
- 方法二:直接下载现有其他人上传的
- 3)安装transformers和sentencepiece套件
- 4)验证torch是否安装
- 5)基于Transformers库载入如下模型
- 6)加载分词器
- 7)文本处理
- 8)向llama提问题
上篇地址: https://blog.csdn.net/Josong/article/details/133155120
1、访问网址
- 网址https://colab.research.google.com/
2、基础概念
Colab = Colaboratory(即合作实验室),是谷歌提供的一个在线工作平台,用户可以直接通过浏览器执行python代码并与他人分享合作。Colab的主要功能当然不止于此,它还为我们提供免费的GPU。熟悉深度学习的同学们都知道:CPU计算力高但核数量少,善于处理线性序列,而GPU计算力低但核数量多,善于处理并行计算。在深度学习中使用GPU进行计算的速度要远快于CPU,因此有高算力的GPU是深度学习的重要保证。由于不是所有GPU都支持深度计算(大部分的Macbook自带的显卡都不支持),同时显卡配置的高低也决定了计算力的大小,因此Colab最大的优势在于我们可以“借用”谷歌免费提供的GPU来进行深度学习。
综上:Colab = “python版”Google doc + 免费GPU
Jupyter Notebook:在Colab中,python代码的执行是基于.ipynb文件,也就是Jupyter Notebook格式的python文件。这种笔记本文件与普通.py文件的区别是可以分块执行代码并立刻得到输出,同时也可以很方便地添加注释,这种互动式操作十分适合一些轻量的任务。
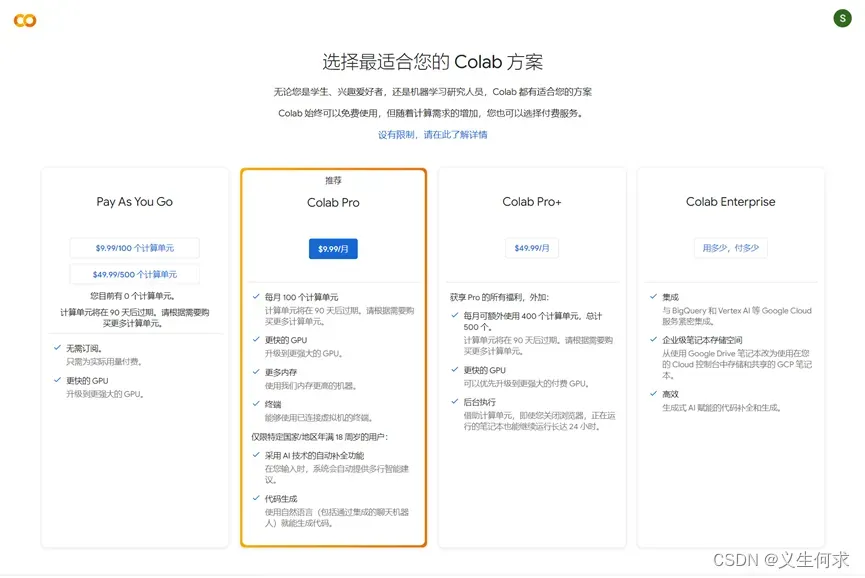
3、选择最适合您的 Colab 方案
Colab提供5种硬件加速器,如果需要使用A100GPU、V100GPU需要单独付费,其他类型的硬件加速器效果不是很理想,适合的Colab方案如下
4、基于Colab部署开源模型Llama 2
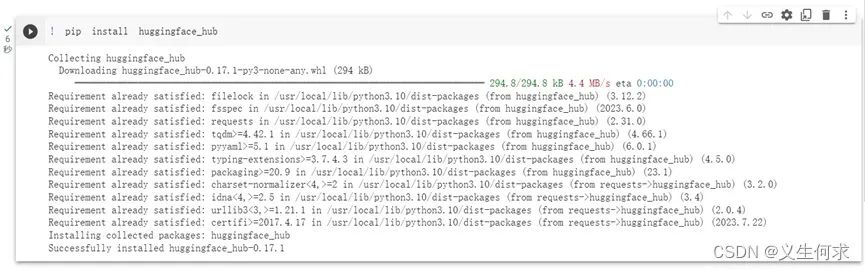
1)在Colab上安装huggingface套件
! pip install huggingface_hub
2)申请调用llama2的权限
方法一:登录huggingface获取token方式
!huggingface-cli login
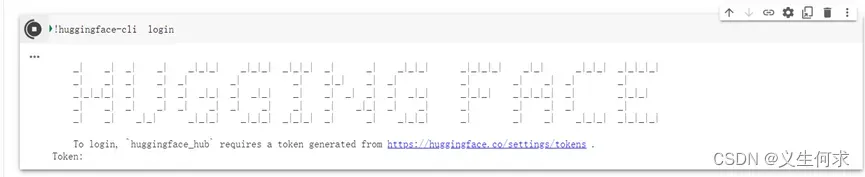 点击https://huggingface.co/settings/tokens 获取tokens地址获取tokens
点击https://huggingface.co/settings/tokens 获取tokens地址获取tokens
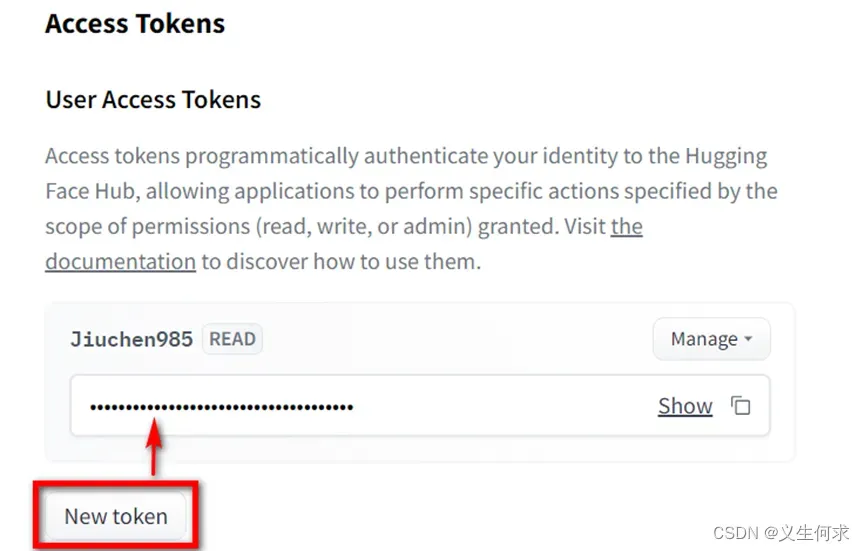
将获取到的token填写到如下页面文本框中
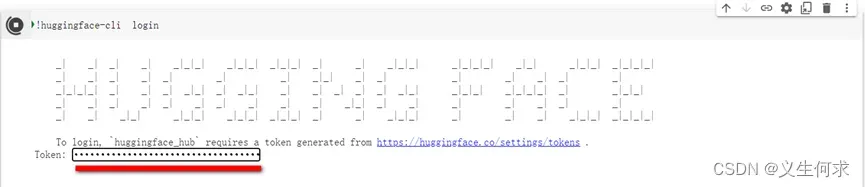
按着后续的提示完成填写,完成后,我们就获得了调用llama2的相关权限了。
方法二:直接下载现有其他人上传的
可以在huggingface上下载其他人上传的llama2版本(可能是原版本,也可能是经过微调的版本),如下图所示
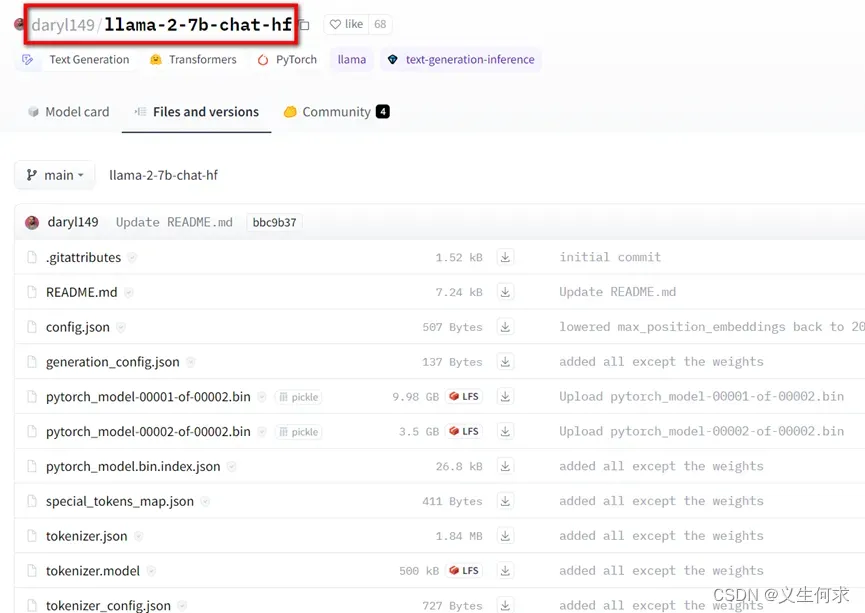
daryl149/llama-2-7b-chat-hf
注:其中“hf”代表的是huggingface可以识别的
该文档后续的介绍都采用“方法二”
3)安装transformers和sentencepiece套件
transformers库是基于pytorch或tensorflow深度学习库的(现在也支持JAX),因此需要安装这两个软件包之一。下面的命令同时安装sentencepiece分词器,如果没有安装pytroch,也会自动安装对应的pytorch版本。
! pip install transformers sentencepiece
4)验证torch是否安装
import torch
5)基于Transformers库载入如下模型
模型解释:
- AutoModelForCausalLM:用于加载模型
- AutoTokenizer:自动分词器
- TextStreamer:处理文本的生成过程
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_path = "daryl149/llama-2-7b-chat-hf"
model = AutoModelForCausalLM.from_pretrained(model_path).cuda()
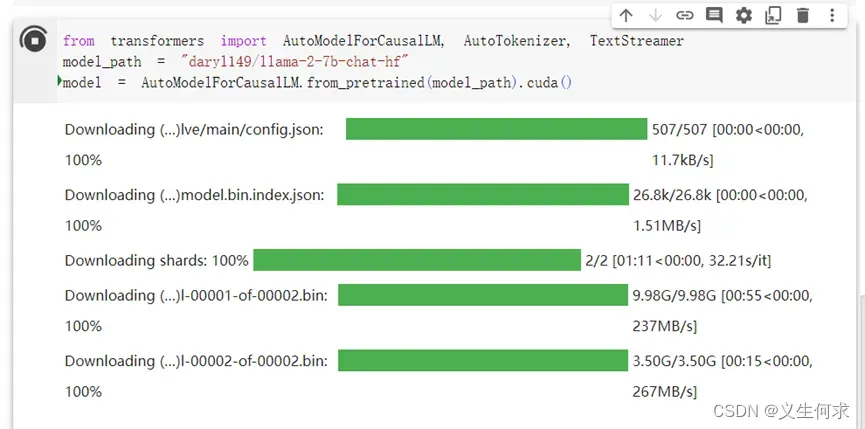
下载该模型需要一些时间,如下图所示
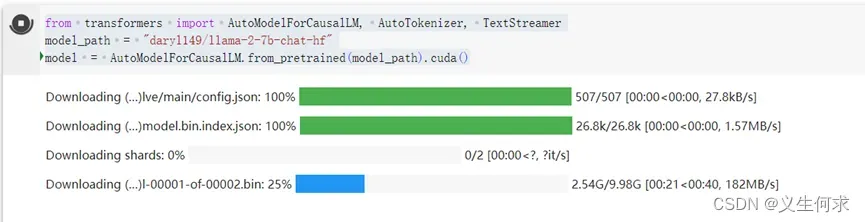
下载完成显示如下
6)加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast = False)

7)文本处理
- “skip_prompt = True”文本处理过程中遇到提示词将跳过提示词
- “skip_special_tokens = True”文本片过程中,在开头或结尾遇到特殊标记时,将自动去调这些特殊标记
streamer = TextStreamer(tokenizer, skip_prompt = True, skip_special_tokens = True)
8)向llama提问题
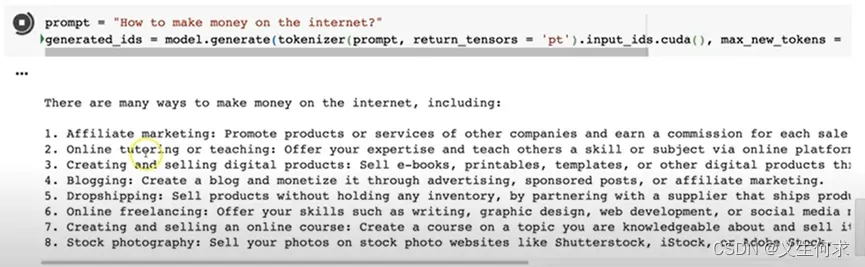
prompt = "How to make money on the internet?"
generated_ids = model.generate(tokenizer(prompty, return_tensors = 'pt').input_ids.cuda(), max_new_tokens = 1000, streamer = streamer)
提问后的回复如下
- max_new_tokens:我们可以通过调整该数的大小,修改输出结果的文字量
以上就是基于Colab部署开源模型Llama 2的全过程
下一篇提前预告:LLMs-入门三:基于JupyterLab部署Llama 2
文章出处登录后可见!