排序
排序作为最基本的算法,其应用广泛,变化多样,在不同情景下有不同应用。下面介绍几种应用比较多的排序原理。
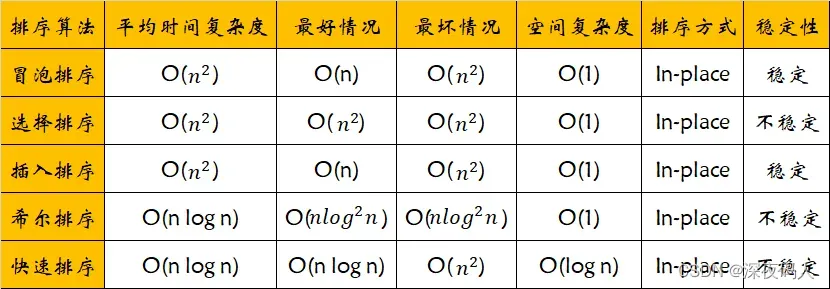
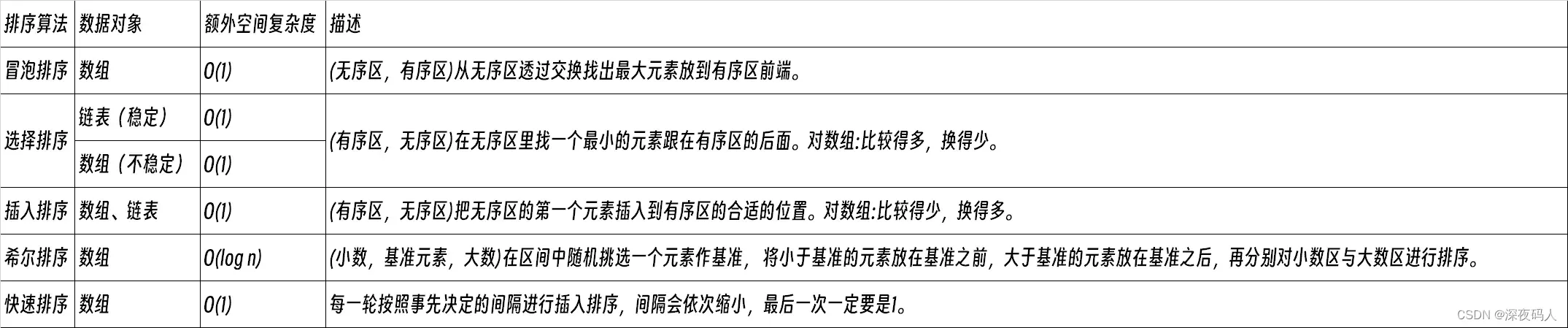
1.冒泡排序
冒泡排序是最简单的排序算法,思路简单,容易理解。
冒泡排序是一种简单的交换排序,它的基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止。

void BubbleSort0(int arr[], int n)
{
int i, j;
for(i = 0; i < n; i++)
{
for(j = i + 1; j < n; j++)
{
if(arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
以上代码并不算是标准的冒泡排序代码,因为其并未满足“两两比较相邻记录”,只是简单的交换排序。
以下为标准冒泡排序代码:
void BubbleSort1(int arr[], int n)
{
int i, j;
for(i = 0; i < n; i++)
{
for(j = n - 1; j >= i; j--)
{
if(arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
可以看出,冒泡排序不论原数据是否有序,都会进行循环和判断,在数据量较大时效率非常低,最理想状况下时间复杂度为O(n),最坏情况下,即待处理数据为逆序时此时需要
因此总时间复杂度为O(n^2)
优化
从痛点下手,让它在有序时适时跳过,可以大大降低有序时的时间消耗
void BubbleSort2(int arr[], int n)
{
int flag = 1;
while(n-- && flag)
{
flag = 0;
for(int i = 0; i < n; i++)
{
if(arr[i + 1] < arr[i])
{
flag = 1;
int temp = arr[i + 1];
arr[i + 1] = arr[i];
arr[i] = temp;
}
}
}
}
但其逆序效率低问题依旧难以解决。
2.选择排序
选择排序简单来说就是通过n-i次关键词的比较,从n-i+1个记录中找出关键词最小的记录,并和第i(1<= i <= n)个记录交换。

void SelectSort(int arr[], int n)
{
for(int i = 0; i < n; i++)
{
int k = i;
for(int j = i + 1; j <= n; j++)
{
if(arr[j] < arr[k])
{
k = j;
}
}
if(i != k)
{
int temp = arr[i];
arr[i] = arr[k];
arr[k] = temp;
}
}
}

i=1时

9与后面数字比较,1最小,交换0和1处数据;
i=2时

1和8处数据交换;以此类推。
分析其时间复杂度时,我们发现,无论什么情况其比较次数都是n(n-1)/2次,而交换次数,最好时为0次,最差时为n-1次。因此其时间复杂度为O(n^2)。
性能略优于冒泡排序。
3.插入排序
插入排序的基本操作是将一个记录插入到已经安排好的序的有序表中,从而得到一个新的、记录数增1的有序表。
动画演示:

代码:
void InsertSort(int arr[], int n)
{
int i,j,key;
for (i = 1; i < n; i++)
{
key = arr[i];
j = i - 1;
while((j >= 0) && (arr[j] > key))
{
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
复杂度分析:
最好情况时,共比较n-1次,没有移动记录,时间复杂度为O(n)
最坏情况时,比较*(n+2)(n-1)/2次,移动(n+4)(n-1)/2*次
平均时间复杂度依然为O(n^2),但是可以发现,插入排序比冒泡和选择性能高。
4.希尔排序
希尔排序算法又叫缩小增量排序算法,是一种更高效的插入排序算法。和普通的插入排序算法相比,希尔排序算法减少了移动元素和比较元素大小的次数,从而提高了排序效率。
希尔排序算法的实现思路是:
-
将待排序序列划分成多个子序列,使用普通的插入排序算法对每个子序列进行排序;
-
按照不同的划分标准,重复执行第一步;
-
使用普通的插入排序算法对整个序列进行排序。
实现过程:
- 间隔 4 个元素,将整个序列划分为 4 个子序列:

采用插入排序算法分别对 {35, 14}、{33, 19}、{42, 27}、{10, 44} 进行排序,最终生成的新序列为:

- 间隔 2 个元素,再次划分整个序列:

采用插入排序算法分别对 {14, 27, 35, 42} 和 {19, 10, 33, 44} 进行排序:

- 采用插入排序算法对整个序列进行一次排序,过程如下:

代码:
void ShellSort(int arr[], int n)
{
int h = 4;
while(h >= 1)
{
for(int i = h; i < n; i++)
{
for(int j = i; j >= h && arr[j] < arr[j - 1]; j-=h)
{
int temp = arr[j];
arr[j] = arr[j - h];
arr[j - h] = temp;
}
}
h /= 2;
}
}
5.快速排序
快速排序算法是在分治算法基础上设计出来的一种排序算法,和其它排序算法相比,快速排序算法具有效率高、耗费资源少、容易实现等优点。
快速排序算法的实现思路是:
- 从待排序序列中任选一个元素(假设为 pivot)作为中间元素,将所有比 pivot 小的元素移动到它的左边,所有比 pivot 大的元素移动到它的右边;
- pivot 左右两边的子序列看作是两个待排序序列,各自重复执行第一步。直至所有的子序列都不可再分(仅包含 1 个元素或者不包含任何元素),整个序列就变成了一个有序序列。
真正实现快速排序算法时,我们通常会挑选待排序序列中第一个元素或者最后一个元素作为中间元素。
举个例子,使用快速排序算法对 {35, 33, 42, 10, 14, 19, 27, 44, 26, 31} 进行升序排序的过程为:
- 选择序列中最后一个元素 31 作为中间元素,将剩余元素分为两个子序列,如下图所示:

分得的两个子序列是 {26, 27, 19, 10, 14} 和 {33, 44, 35, 42},前者包含的所有元素都比 31 小,后者包含的所有元素都比 31 大,两个子序列还可以再分。
- 重复第一步,将 {26, 27, 19, 10, 14} 看作新的待排序序列:
- 选择最后一个元素 14 作为中间元素,将剩余元素分为 {10} 和 {19, 26, 27} 两个子序列。其中 {10} 仅有一个元素,无法再分;{19, 26, 27} 可以再分。
- 将 {19, 26, 27} 看作新的待排序序列,选择最后一个元素 27 作为中间元素,分得的两个子序列为 {19, 26} 和 {}。其中 {} 是空序列,无法再分;{19, 26} 可以再分。
- 将 {19, 26} 看作新的待排序序列,选择最后一个元素 26 作为中间元素,分得的两个子序列为 {19} 和 {},两个子序列都无法再分。
经过以上 3 步, {26, 27, 19, 10, 14} 子序列变成了 {10, 14, 19, 26, 27},这是一个有序的子序列。
3、重复第一步,将 {33, 44, 35, 42} 看作新的待排序序列:
- 选择最后一个元素 42 作为中间元素,将剩余元素分为 {33, 35} 和 {44} 两个子序列。其中 {33, 35} 可以再分;{44} 仅有一个元素,无法再分。
- 将 {33, 35} 看作新的待排序序列,选择最后一个元素 35 作为中间元素,分得的两个子序列为 {33} 和 {},两个子序列都无法再分。
经过以上 2 步, {33, 44, 35, 42} 子序列变成了 {33, 35, 42, 44},这是一个有序的子序列。
最终,原序列变成了 {10, 14, 19, 26, 27, 31, 33, 35, 42, 44},这是一个升序序列
代码:
void QuickSort(int arr[], int left, int right)
{
if(left >= right)
{
return;
}
int i = left;
int j = right;
int pivot = arr[i];
while(i < j)
{
while(i < j && arr[j] >= pivot)
{
j--;
}
arr[i] = arr[j];
while(i < j && arr[i] <= pivot)
{
i++;
}
arr[j] = arr[i];
}
arr[i] = pivot;
QuickSort(arr, left, i - 1);
QuickSort(arr, i + 1, right);
}
6.qsort函数
库:<stdlib.h>
描述:C 库函数 qsort()是根据二分法写的,其时间复杂度为n*log(n),可以对数组进行排序。
qsort()是一个回调函数,回调函数就是一个通过函数指针调用的函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
下面是 qsort() 函数的声明。
void qsort(void *base, size_t nitems, size_t size, int (*cmp)(const void *, const void*))
base – 指向数组的起始地址,通常该位置传入的是一个数组名。
nitems – 由 base 指向的数组中元素的个数,即需要排序的数量。
size –数组中每个元素占用的空间大小,以字节为单位。
**cmp **– 用来比较两个元素的函数。
对一个长为1000的数组进行升序排序时,int list[1000];
那么base应为list,num应为 1000,width应为 sizeof(int),compare函数随自己的命名,这里我们命名为cmp。
qsort函数写为qsort(list,1000,sizeof(int),cmp);
cmp函数
1.基本形式
int cmp(const void *a ,const void *b)
返回值
cmp()会返回int型返回值。
返回值有三种:
1)返回一个正数,a排在b之后
2)返回0,a,b相等
3)返回一个负数,a排在b之前
形参
1.1 const
关键字const为一个限定词, 可以使编译器有效地保护那些不希望被改变的变量或参数,防止其无意中被代码修改。所以使用const关键字可以避免一些不必要的错误。
const关键字修饰的指针变量
常量指针:指针变量的值一旦初始化就不能改变,不能指向其他的变量,但它指向的变量的值可以被修改。
eg: int const * p;
指向常量的指针:这个指针指向的是一个常量,它指向的值不能被修改。
eg: const int * p;
const关键字修饰的函数形参
字符串拷贝函数: char* strcpy(char *strDest,const char *strSrc);
返回字符串长度函数: int strlen(const char *str);
采用const关键字修饰函数形参,就是为了保护输入参数。在调用函数的时候,用相应的变量初始化const常量,则在函数体中,按照const所修饰的部分进行常量化,如形参为const int * a,则不能对传递进来的指针所指向的内容进行改变,保护了原指针所指向的内容。
1.2 void类型指针
万能指针,void 指针可以指向任意类型的数据。
void指针只有强制类型转换后才可以正常对其操作。
1.3函数指针 (详见C Primer Plus 14.14 函数与指针)
**1)**指针可以指向变量,那么可以指向函数吗?
函数指针常用作另一个函数的参数,告诉该函数要使用哪一个函数。
**2)**指向变量的指针储存着该变量的地址,函数指针储存着什么呢?
函数也有地址,指向函数的指针中储存着函数代码的起始处的地址。
**3)**函数指针如何声明
(* pf) (char *);//pf是一个指向函数的指针
void ToUpper(char*);//一个带char * 类型参数、返回类型是void的函数
void (*pf) (char*);//pf是一个指向函数的指针
void *pf(char*);//是一个返回字符指针的函数
声明函数指针后,函数名可以用于表示函数的地址,pf可以指向相同形参相同返回类型的函数。
**4)**数据指针可以访问数据,那么函数指针也可以访问函数
void ToUpper(char *);
void ToLower(char *);
void (*pf)(char *);
char mis[] = "Nina Metier";
pf = ToUpper;
(*pf)(mis); // 把ToUpper 作用于(语法1)
pf = ToLower;
pf(mis); // 把ToLower 作用于(语法2)
由上例,(*pf)(mis) 和 pf(mis)等价。(ANSI C标准认为这两种形式等价)
**5)**数据指针常作为函数参数,函数指针也一样
函数指针常常用来作为函数的参数。
void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *,
const void*))
比如,qsort的函数原型,它声明了四个形参:base,nitems,size,cmp。cmp是一个函数指针。
2.具体实现
以比较整形数组为例。
函数qsort要求它的形式参数类型为void *,但我们不能通过void *型的指针访问数组的成员;我们需要指向要比较元素的类型的指针。为了解决这个问题,我们将在比较函数内部把p与q赋给相应对应类型的指针变量。由于常量指针不能赋值给变量,所以在声明对应指针变量时应该加上const关键字。
int cmp(const void *p, const void *q)
{
const int *p1 = p;
const int *q1 = q;
if (*p1 < *q1)
return -1;
else if (*p1 == *q1)
return 0;
else
return 1;
}
int cmp(const void *p,const void *q)
{
if(*(int *)p<*(int *)q)
return -1;
else if(*(int *)p==*(int *)q)
return 0;
else
return 1;
}
int cmp(const void *p,const void *q)
{
return *(int *)p-*(int *)q;
}
(int * )是强制转换,最前面的则是解引用,意思是强制转换成int*的元素后解引用,访问数组的元素。
类比int型数组,想一下对char型数组、double型数组排序的cmp函数如何实现,降序?
1、对int类型数组排序
int num[100];
int cmp ( const void *a , const void *b )
{
return *(int *)a - *(int *)b;
}
qsort(num,100,sizeof(num[0]),cmp);
2、对char类型数组排序(同int类型)
char word[100];
int cmp( const void *a , const void *b )
{
return *(char *)a - *(char *)b;
}
qsort(word,100,sizeof(word[0]),cmp);
3、对double类型数组排序(特别要注意)
因为cmp返回值为int型,若两个小数差距极小,例如:a=0.15 ,b=0.14,将会被强制转换为0返回,不发生交换。
double in[100];
int cmp( const void *a , const void *b )
{
return *(double *)a > *(double *)b ? 1 : -1;
}
qsort(in,100,sizeof(in[0]),cmp);
当然,cmp函数也可以自己写,相当于自定义比较方式。
好了,以上就是C语言中较常用的排序方法啦。
版权声明:本文为博主作者:深夜码人原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_73685411/article/details/128240356